大家好,我是爱酱。本篇将会系统地讲解随机森林(Random Forest)的原理、核心思想、数学表达、算法流程、代码实现与工程应用。内容适合初学者和进阶读者,配合公式和可视化示例。
注:本文章含大量数学算式、详细例子说明及大量代码演示,大量干货,建议先收藏再慢慢观看理解。新频道发展不易,你们的每个赞、收藏跟转发都是我继续分享的动力!
注:随机森林(Random Forest)与决策树(Decision Tree)息息相关,因此不了解决策树的同学建议先去了解一下,爱酱也有文章深入探讨决策树,这里也给上链接。
传送门:
【AI深究】决策树(Decision Tree)全网最详细全流程详解与案例(附Python代码演示)|数学原理、案例流程、代码演示及结果解读|ID3、C4.5、CART算法|工程启示、分类、回归决策树-CSDN博客
一、随机森林是什么?
随机森林是一种集成学习(Ensemble Learning)方法,通过构建大量“去相关”的决策树,并将它们的预测结果进行集成,提升整体模型的准确率和鲁棒性。
-
本质:多个决策树的集成,每棵树都是在“有放回抽样”的数据子集和“随机特征子集”上训练得到。
-
任务类型:既可用于分类(Classification),也可用于回归(Regression)。
-
优点:高准确率、抗过拟合、对异常值和噪声鲁棒、可处理大规模高维数据。
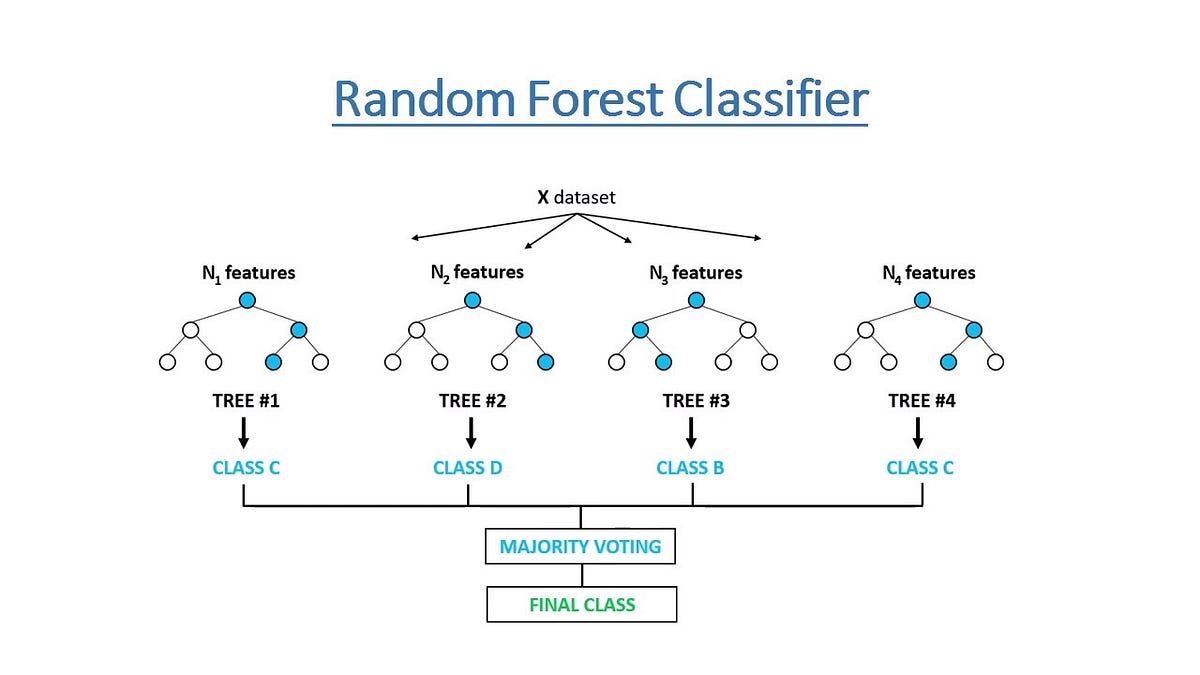
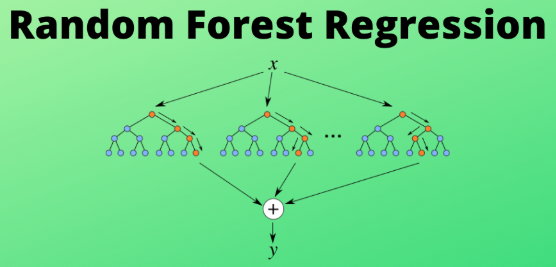
二、随机森林的核心思想
1. Bagging(Bootstrap Aggregating)
-
有放回抽样:从原始训练集随机采样
次,得到
个不同的训练子集(每个子集大小等于原始数据,可重复)。
-
每个子集训练一棵决策树,各树之间相互独立。
2. 随机特征选择(Feature Bagging)
-
每次分裂节点时,不是用全部特征,而是从所有特征中随机选取
个特征,再从这
-
这样可进一步增加树之间的差异性,降低整体模型的方差。
三、随机森林的数学表达
1. 分类任务
-
随机森林由
对输入
做出预测。
-
最终预测为多数投票结果:
2. 回归任务
-
最终预测为所有树预测值的平均:
四、随机森林的算法流程
-
数据采样:对原始训练集做
-
训练树模型:对每个子集训练一棵决策树,每次节点分裂时随机选择部分特征。
-
集成预测:
-
分类:所有树投票,选择票数最多的类别。
-
回归:所有树预测值取平均。
-
-
模型评估:可用OOB(Out-Of-Bag)样本评估模型性能,无需额外验证集。
五、随机森林的主要参数与调优
-
n_estimators:森林中树的数量,通常越多越好,但计算成本增加。
-
max_features:每次分裂时考虑的最大特征数,分类默认
,回归默认
。
-
max_depth:树的最大深度,防止过拟合。
-
min_samples_split / min_samples_leaf:分裂所需的最小样本数,控制树的生长。
-
oob_score:是否使用袋外样本评估模型泛化能力。
六、随机森林的代码实现与可视化
1. 分类随机森林代码示例
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score# 加载Iris数据集
iris = load_iris()
X, y = iris.data, iris.target# 训练随机森林分类器
rf = RandomForestClassifier(n_estimators=100, max_depth=3, random_state=0, oob_score=True)
rf.fit(X, y)# 预测与评估
y_pred = rf.predict(X)
print("训练集准确率:", accuracy_score(y, y_pred))
print("OOB分数:", rf.oob_score_)# 可视化特征重要性
plt.bar(range(X.shape[1]), rf.feature_importances_)
plt.xticks(range(X.shape[1]), iris.feature_names, rotation=45)
plt.ylabel('Feature Importance')
plt.title('Random Forest Feature Importance (Iris)')
plt.tight_layout()
plt.show()
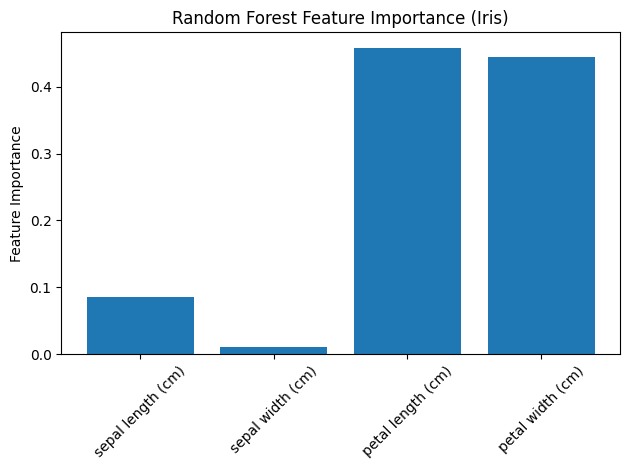
代码说明:
-
用Iris数据集训练100棵树、最大深度为3的随机森林分类器。
-
输出训练集准确率和袋外分数(OOB score)。
-
可视化特征重要性,展示每个特征对模型决策的贡献。
2. 回归随机森林代码示例
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestRegressor# 生成一维回归数据
rng = np.random.RandomState(1)
X = np.sort(5 * rng.rand(80, 1), axis=0)
y = np.sin(X).ravel() + 0.2 * rng.randn(80)# 训练随机森林回归器
rf_reg = RandomForestRegressor(n_estimators=100, max_depth=3, random_state=0)
rf_reg.fit(X, y)# 预测与可视化
X_test = np.linspace(0, 5, 200)[:, np.newaxis]
y_pred = rf_reg.predict(X_test)plt.figure(figsize=(8, 5))
plt.scatter(X, y, color='darkorange', label='Training data')
plt.plot(X_test, y_pred, color='navy', label='Random Forest Regression')
plt.xlabel('X')
plt.ylabel('y')
plt.title('Random Forest Regression Example')
plt.legend()
plt.show()
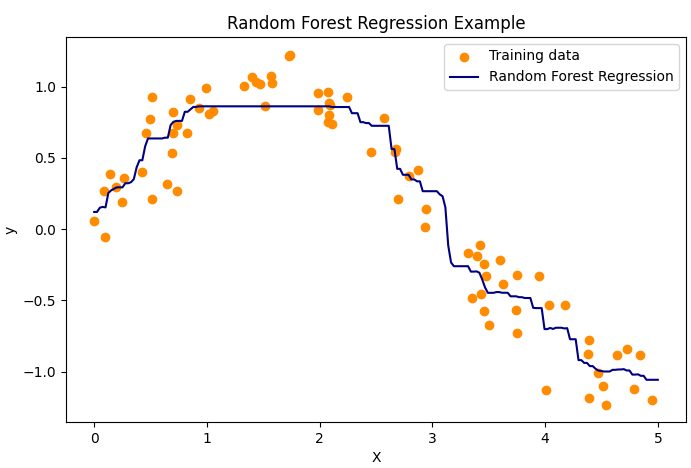
代码说明:
-
用带噪声的正弦数据训练100棵树的随机森林回归器。
-
可视化回归曲线,显示随机森林对非线性关系的强大拟合能力。
七、随机森林与单棵决策树的对比
| 特点 | 单棵决策树 | 随机森林 |
|---|---|---|
| 模型结构 | 一棵树 | 多棵树集成 |
| 拟合能力 | 易过拟合 | 抗过拟合,泛化能力强 |
| 鲁棒性 | 对噪声敏感 | 对噪声和异常值鲁棒 |
| 可解释性 | 强,易于可视化 | 较弱,需看特征重要性 |
| 计算成本 | 低 | 高(树多,需并行/分布式实现) |
| 主要应用 | 基线模型、规则挖掘 | 主流分类/回归、特征选择 |
八、随机森林的优缺点
优点:
-
高准确率,抗过拟合,泛化能力强。
-
对异常值和噪声数据鲁棒。
-
可处理高维数据和大规模数据集。
-
可评估特征重要性,辅助特征选择。
-
支持并行计算,易于扩展。
缺点:
-
单棵树可解释性强,随机森林整体可解释性较差。
-
训练和预测速度较慢,尤其是树数量多时。
-
对于极度稀疏或高相关特征,提升有限。
九、实际应用与工程建议
-
分类与回归:适合金融风控、医学诊断、客户流失预测、价格预测等多种场景。
-
特征选择:利用特征重要性排序,筛选关键变量。
-
异常检测:通过树的投票分布识别异常样本。
-
集成学习基线:作为强基线模型,常用于Kaggle等数据竞赛。
-
工程建议:
-
合理设置树的数量和深度,防止过拟合和计算资源浪费。
-
使用OOB分数快速评估模型泛化能力。
-
可结合GridSearchCV等工具自动调参。
-
十、结论
随机森林作为集成学习的代表算法,凭借其高准确率、强鲁棒性和广泛适用性,已成为机器学习和数据科学领域的主流方法。它不仅能有效提升模型性能,还能辅助特征工程和异常检测。理解随机森林的原理、调参方法和工程应用,有助于你在实际项目中高效落地和持续优化模型。
如需进一步讲解随机森林与Boosting方法的对比、集成学习原理、或实际案例分析,欢迎继续提问!
谢谢你看到这里,你们的每个赞、收藏跟转发都是我继续分享的动力。
如需进一步案例、代码实现或与其他聚类算法对比,欢迎留言交流!我是爱酱,我们下次再见,谢谢收看!

)




)












