摘要:基于Yue等学者2019年发表的权威综述,本文系统总结情感分析的技术框架、实战资源与前沿方向,附Python代码示例。
一、情感分析为何重要?
情感分析(Sentiment Analysis)旨在从文本中提取主观态度,在商业、政治、公共安全领域价值显著:
-
商业决策:电商评论分析(如“电池续航长但机身太重”)驱动产品优化
-
政治预测:Twitter情绪分析成功预测欧盟选举倾向(德语区39%积极 vs 5%消极)
-
公共安全:阿拉伯之春期间社交媒体情绪预警社会动荡
论文案例:2016年澳大利亚联邦选举中,对61万条推文的空间情感分析准确预测联盟党领先10%
二、三大技术视角解析
1. 任务导向(Task-Oriented)
| 任务类型 | 典型方法 | 实践建议 |
|---|---|---|
| 情感极性分类 | SVM/朴素贝叶斯(Pang et al. 2002) | 结合NLTK+VADER库 |
| 细粒度方面提取 | 双传播算法(Qiu et al. 2011) | SpaCy依存解析+规则过滤 |
| 时空情感分析 | STWS地理语言指纹模型 | 需融合GPS与文本特征 |
# 使用VADER进行情感极性分析
from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer
analyzer = SentimentIntensityAnalyzer()
text = "The picture quality is amazing but battery drains too fast"
print(analyzer.polarity_scores(text)) # 输出: {'neg': 0.211, 'neu': 0.508, 'pos': 0.281, 'compound': -0.177}2. 粒度导向(Granularity-Oriented)
-
文档级:适用于整体评价(如亚马逊产品评论)
-
句子级:处理复杂语义(反讽识别:SASI算法)
-
词级:依赖情感词典(SentiWordNet/NTUSD)
实战陷阱:文档级分析在跨领域时准确率下降40%(Blitzer et al. 2007),建议采用SFA特征对齐
3. 方法导向(Methodology-Oriented)
| 学习范式 | 代表算法 | 适用场景 |
|---|---|---|
| 监督学习 | CNN-LSTM混合模型(Tang 2015) | 标注数据充足时 |
| 半监督学习 | 协同训练(Co-Training) | 标注成本高场景 |
| 无监督学习 | 情感词典+规则推理 | 领域专业知识驱动 |
三、实战资源清单
1. 核心数据集
| 数据集 | 规模 | 特点 | 获取方式 |
|---|---|---|---|
| TSentiment15 | 2.28亿条推文 | 2015全年跨领域数据 | 学术申请 |
| Amazon Product Reviews | 4领域各2000样本 | 标注精细含方面标签 | 公开下载 |
| MPQA | 692文档 | 标注主观表达式及情感源 | 官网 |
2. 工具与词典
-
综合工具包:
-
LingPipe(支持命名实体与情感联合抽取)
-
SentiStrength(社交文本强度分析,支持多语言配置)
-
-
领域专用词典:
-
金融领域:Financial Sentiment Dictionary
-
中文场景:NTUSD(台大情感词典,含2812积极词)
-
四、未来突破方向:多模态情感分析
传统文本分析的局限性催生多模态融合:
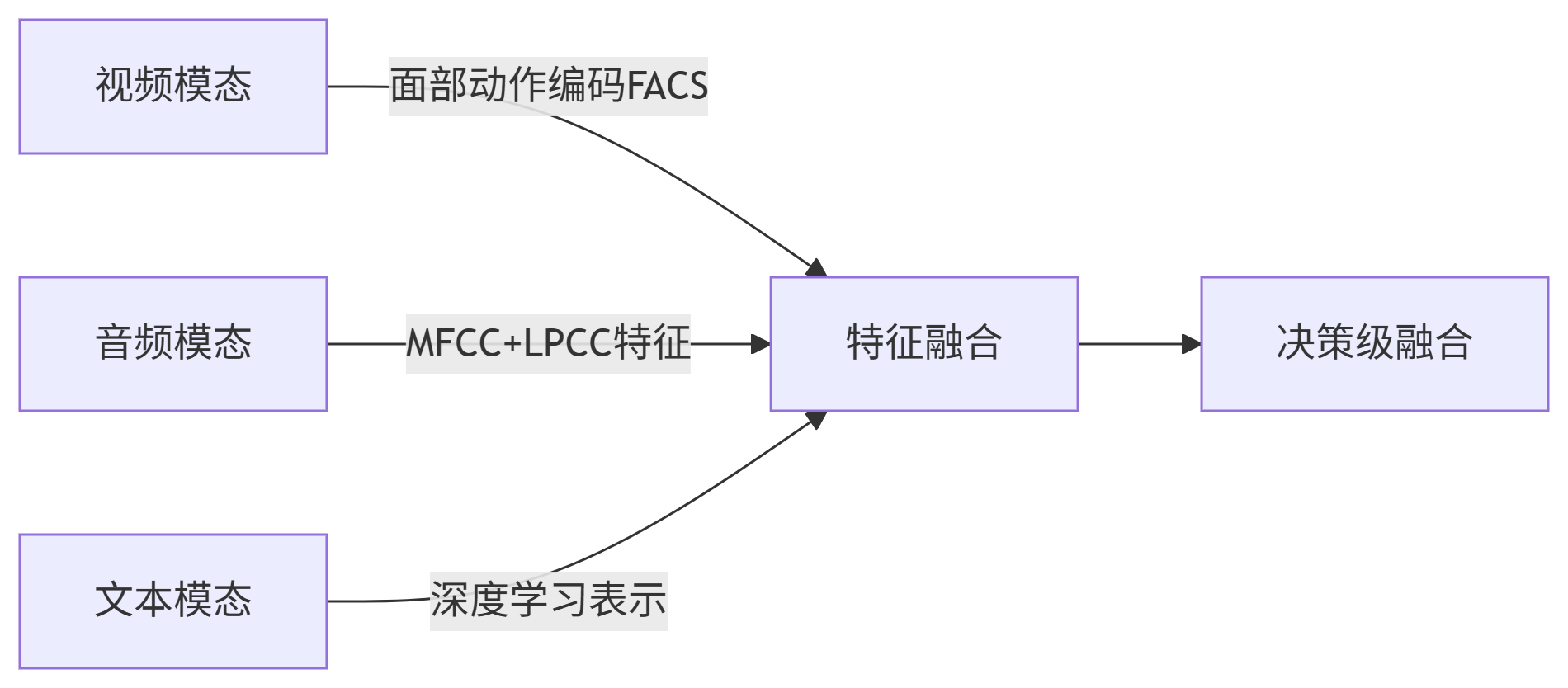
-
前沿进展:
-
多模态数据集ICT-MMMO(视频+音频+文本)
-
特征融合模型:Convolutional MKL(Poria et al. 2016)
-
-
待解难题:
-
模态缺失场景的鲁棒性(如仅视频无音频)
-
跨文化情感表达差异
-
五、结语
情感分析正从单一文本走向多模态融合。研究者需关注:
-
领域适应:跨领域情感词典迁移(如医疗评论分析)
-
细粒度解析:方面级情感联合抽取
-
实时系统:Twitter/抖音流数据处理
论文启示:情感分析需结合心理学与社会学(如PAD情绪模型),纯工程视角难以突破深层语义瓶颈













)


)
|SVM-拉格朗日函数求解上)

