目录
一、InternVL1.5
1、改进
二、InternVL2
1、渐进式扩展
2、多模态扩展
三、InternVL2.5
1、方法
2、数据优化
四、InternVL3
2、方法
3、训练后处理
4、测试时扩展
五、BLIP-3o
一、InternVL1.5
1、改进
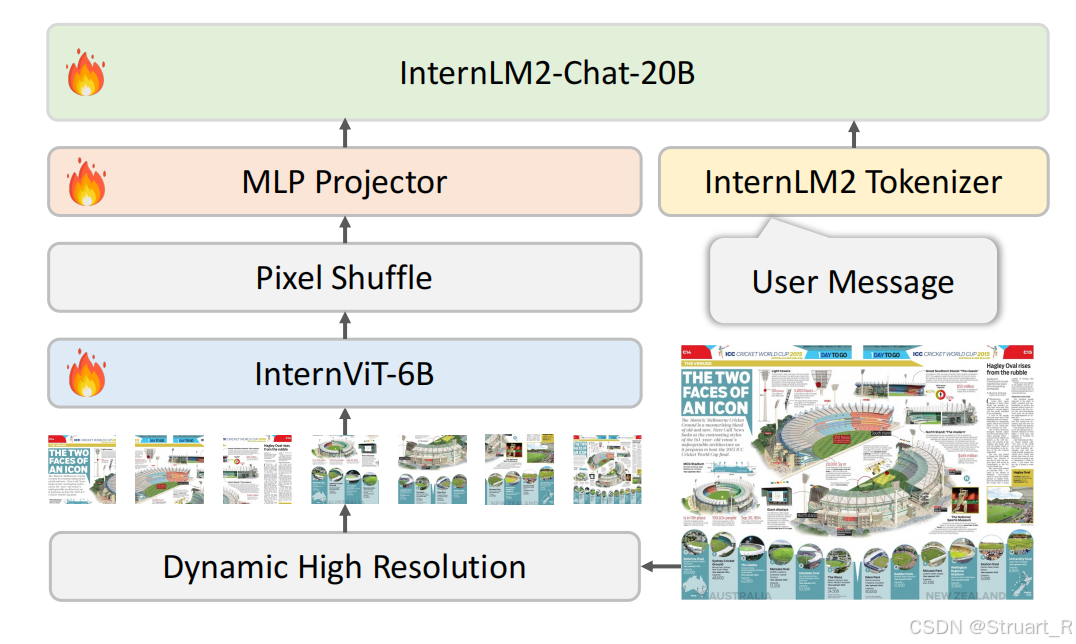
InternVL1.5在InternVL基础上,优化了QLLaMA中间件,转而采用简单的MLP作为图文对齐的桥梁。
视觉编码器:将InternViT-6B的层数从48层优化到45层,并且通过连续学习策略提升视觉理解能力,在高质量图文数据上微调,处理高分辨率图像(448x448)
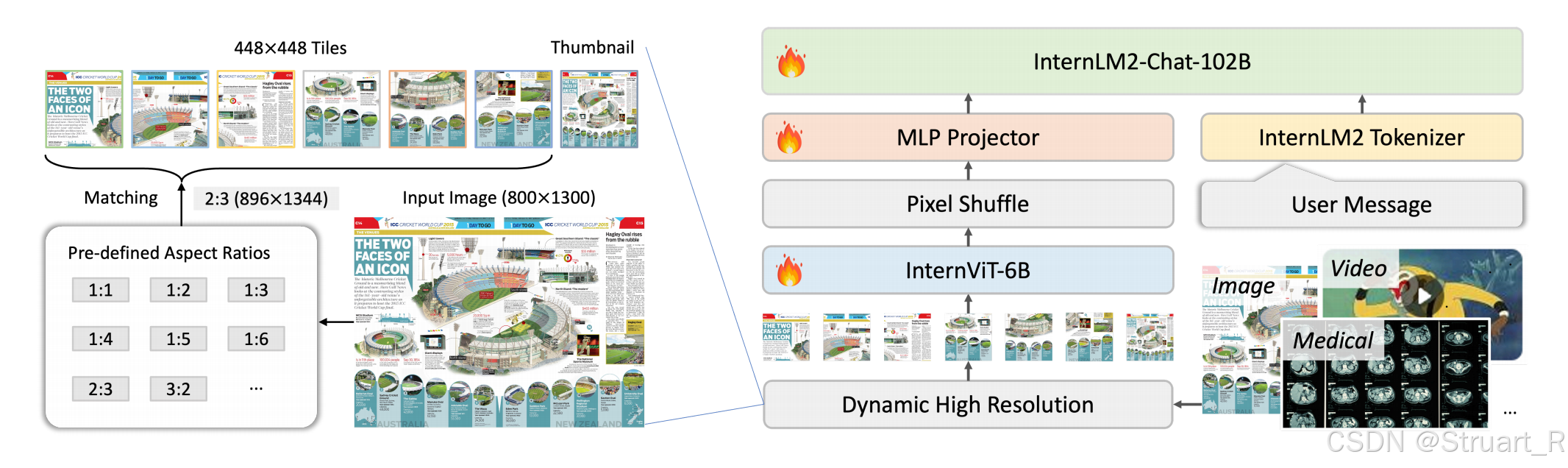
动态高分辨率:根据输入图像宽高比和分辨率,将图像分割为1到40个448x448的图块,最高支持4K分辨率输入。(低分辨率用于场景描述,高分辨率用于文档理解)。训练过程中先使用224x224的分辨率进行训练,再使用448x448分辨率训练。
Pixel Shuffle:为提升高分辨率的扩展性,将像素随机排列为visual tokens数量降低到原来的四分之一。

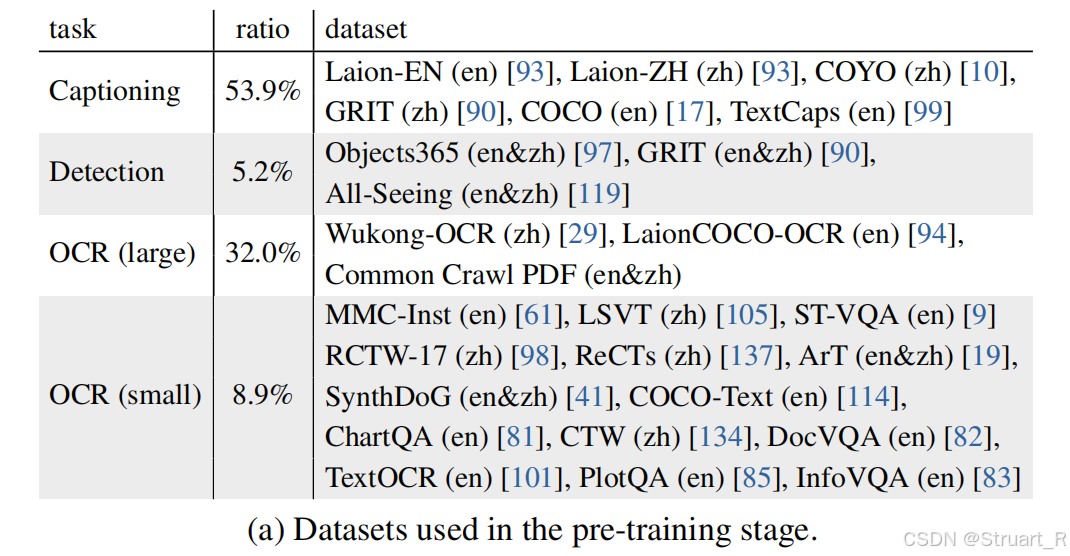
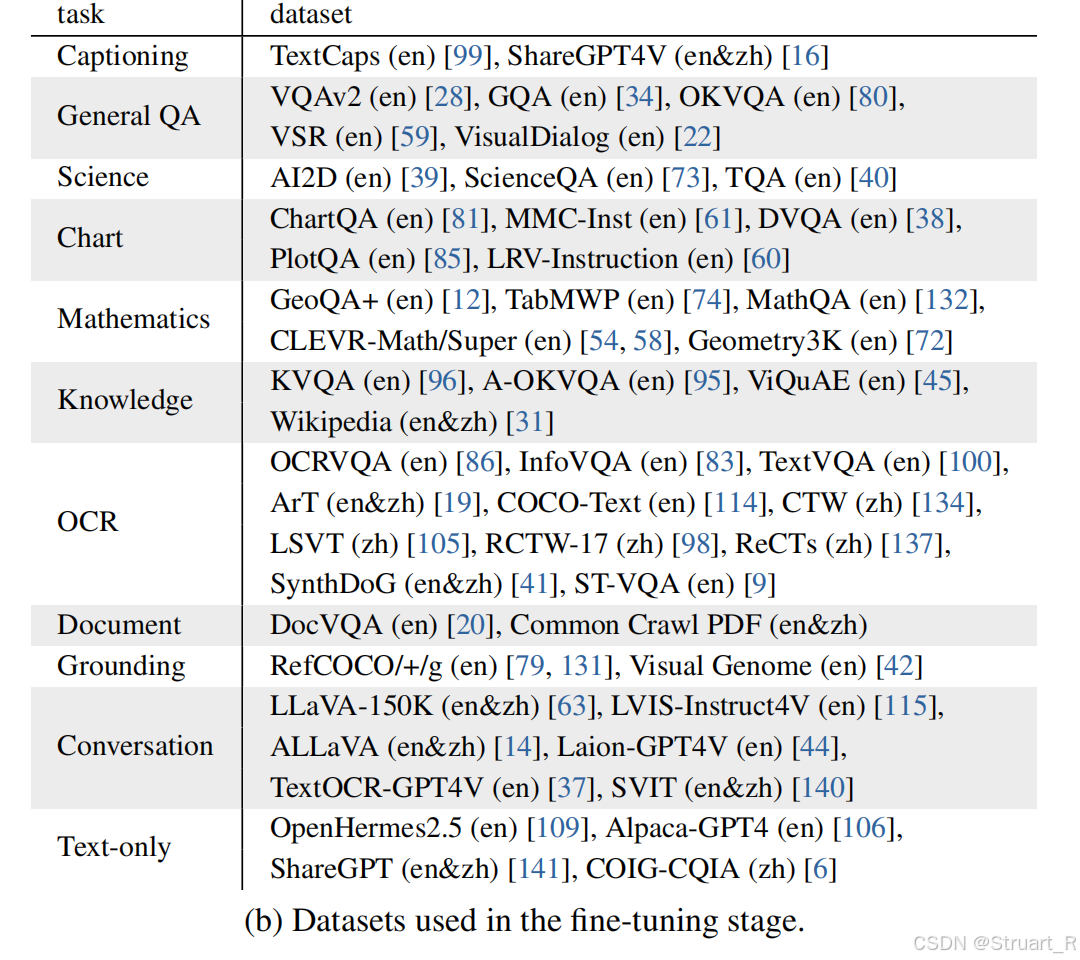
训练过程包含预训练+微调两步,预训练数据采用海量互联网公开数据集弱标注图文对,采用双语数据,数亿级别,只训练InternViT-6B和MLP。微调部分数据包含文档解析、数学推理、多轮对话多任务,百万级别数据量,对所有260亿参数进行全参数调整,确保模态对齐。上下文均为4096tokens。
在InternVL1.2与LLaVA-NeXT对比中提到,二者的LLM部分参数量一致均为34B,vision encoder部分InternVL1.2采用InternViT-6B的6B参数量,LLAVA-NeXT采用CLIP-ViT约300M。由于LLAVA-NeXT训练数据集未公开,所以自己做了一个相似数据集,但由于框架本身问题,LLaVA-NeXT采用了672x672的分辨率,InternVL采用448x448的分辨率。经过作者的训练过后,InternVL1.2在更多的Benchmark下更优,证明了大的vision encoder 参数量可以支撑更复杂的推理的特征信息。
InterVL1.5在OCR任务中效果可以与GPT-4V,Qwen-VL-Max,Gemini ultra1.0这些方法竞争,在多模态评估问题上,还是站不太住。
二、InternVL2
InternVL2在InternVL1.5架构基础上,针对更多模态,更多任务,更大参数量进行了扩展。InternVL2系列也是从2B参数量到108B参数量适应不同的场景应用。
1、渐进式扩展
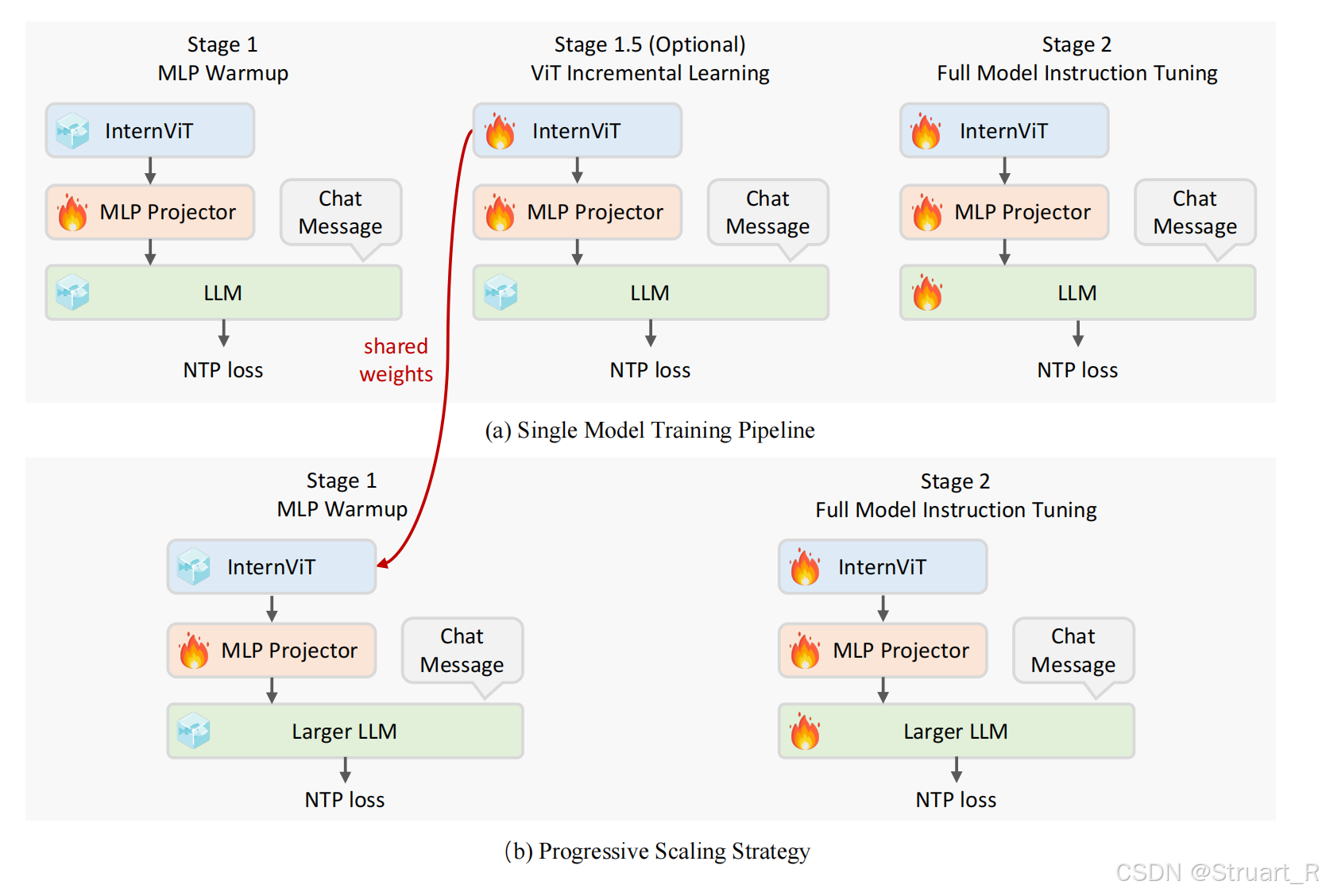
采用从小模型到大模型渐进训练,数据从粗到精迭代的策略。通过这种方式显著降低了大模型训练成本,并且在有限资源下实现高性能。具体来说,先用小规模语言模型(20B参数)训练视觉编码器InternViT,之后将视觉编码器迁移到大规模LLM上,通过这种机制训练效率提升十倍,参数量更大。(这一部分在InternVL2.5论文才提到)
另外提到InternVL2首次实现视觉基础模型与大语言模型的原生对齐。(由于没有论文只有一个technical log不太懂)
2、多模态扩展
支持文本、图像、视频、医疗数据统一输入,并且在以往1.5版本聚焦图文双模态的基础上,增加了视频理解和医疗数据解析。
支持下游任务泛化,通过VisionLLMv2框架链接下游任务解码器支持图像生成、检测框、分割掩码等多样化输出。VisionLLMv2框架图如下。
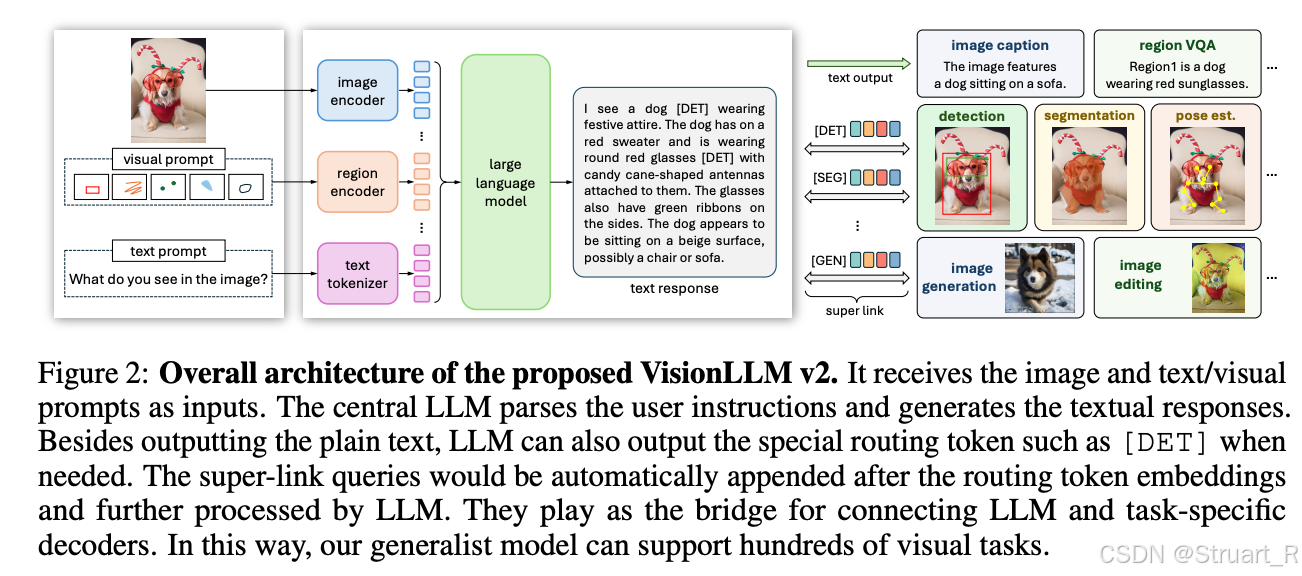
InternVL2的训练第一阶段应该是冻结了InternViT,只训练MLP,第二阶段依然是全参数微调。
三、InternVL2.5
InternVL2.5的架构如出一辙,他的改进在于训练过程和数据。
1、方法
训练过程:由于InternVL2采用的渐进式训练,所以已经预训练了InternViT。第一部分训练MLP,第二部分训练InternViT+MLP,第三部分训练所有参数。
测试时扩展:test-time scaling,在推理阶段动态调整模型行为,通过多次生成结果优化最终输出。通过CoT+Majority Voting实现。通过这种方式,多步验证降低大模型illusion,尤其是在复杂数学问题,长文档分析上。
思维链推理:CoT,Chain-of-Thought,通过多步逻辑推理生成答案,并模拟人类逐步分析问题的过程。在提示词中要求模型先解释推理步骤,再给出最终答案。

2、数据优化
尽管CoT在推理阶段执行,但是其效果高度依赖训练数据的质量,低质量的数据会导致模型在CoT推理过程中陷入循环错误。 以往推理循环的表现如下。

InternVL2.5解决办法,文本数据通过严格过滤训练数据,使用LLM评分来剔除低质量样本,多模态数据采用启发式规则+人工审核的方式。
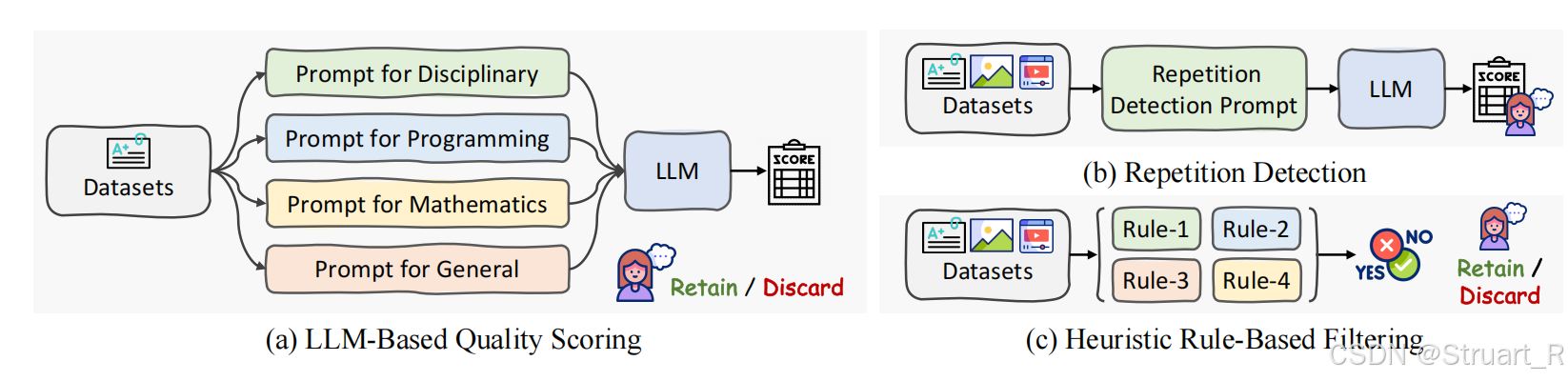
图像数据
(1)动态切片机制:根据输入图像的宽高比和分辨率,动态划分为448x448的像素切片,范围在1-40,每一张图片根据最接近的最优宽高比进行最小化失真,最优宽高比为预定义的35种组合(1:1,2:1,3:2等)
(2)多模态数据统一:由于在对话中可以输入单图,多图,视频数据,所以进行了统一,对于单图数据,多图数据均进行动态切片划分,单图分割为12个切片+全局缩略图,多图分割为总切片12个切片。视频数据简化操作,固定每帧分辨率448x448保证显存承受压力,由于帧数过多,放弃动态切片,用全局理解替换牺牲细节。
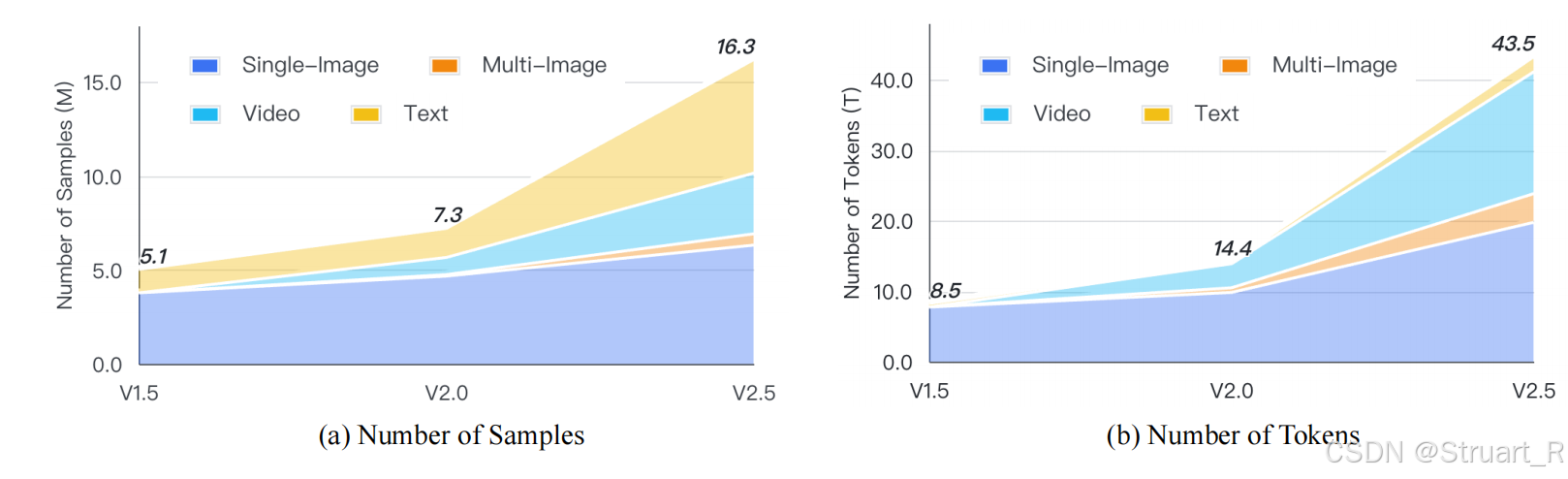
数据量从v1.5到v2.5是逐渐增长的。
通过这一设计InternVL2.5,OCR,多图片理解,多模态理解和幻觉处理,视觉定位,多模态多语言性能,视频理解等任务均达到SOTA。
另外InternViT2.5在图像分类,图像分割指标上也超过以往的1.0,1.2,1.5,2.0,主要是因为参数量,训练数据量扩展。
四、InternVL3
1、概述
以往的InternVL系列都是先训练LLM模块,再将LLM改造成可以支持输入多模态信息的MLLM的“先纯文本预训练->后多模态对齐”的分阶段流程。而InternVL3是通过单阶段联合训练范式的原生预训练,解决了以往MLLM训练后处理的视觉和语言一致性和复杂性挑战,提升了性能和扩展性。这也是第一个原生多模态模型。
创新:可变视觉位置编码,以适应更长的多模态上下文。后训练策略SFT+MPO,test-time缩放原则提升了性能和效率。
InternVL3不仅在原有的多学科推理,文档理解,图像视频理解,现实场景理解,幻觉检测,视觉定位,多语言能力中领先InternVL2.5,同时在工具使用,空间推理,工业图像分析,图形用户界面代理上也取得了新的进展。性能上与开源项目Qwen2.5-VL不相上下,与闭源项目Chatgpt-4o,Gemini-2.5 Pro,Claude3.5-sonnet旗鼓相当。
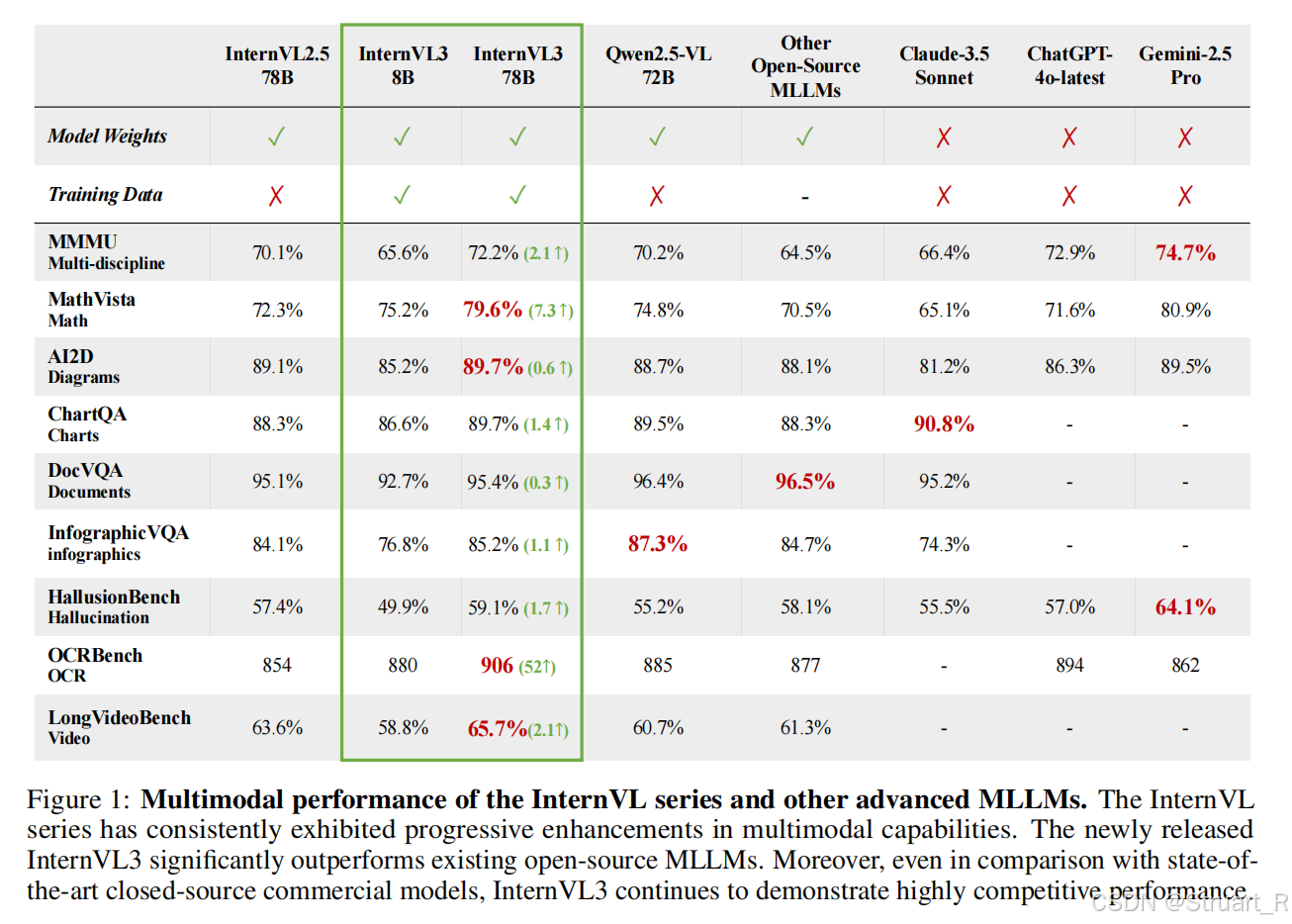
OpenCompass多模态学术排行榜上不同MLLMs的比较。
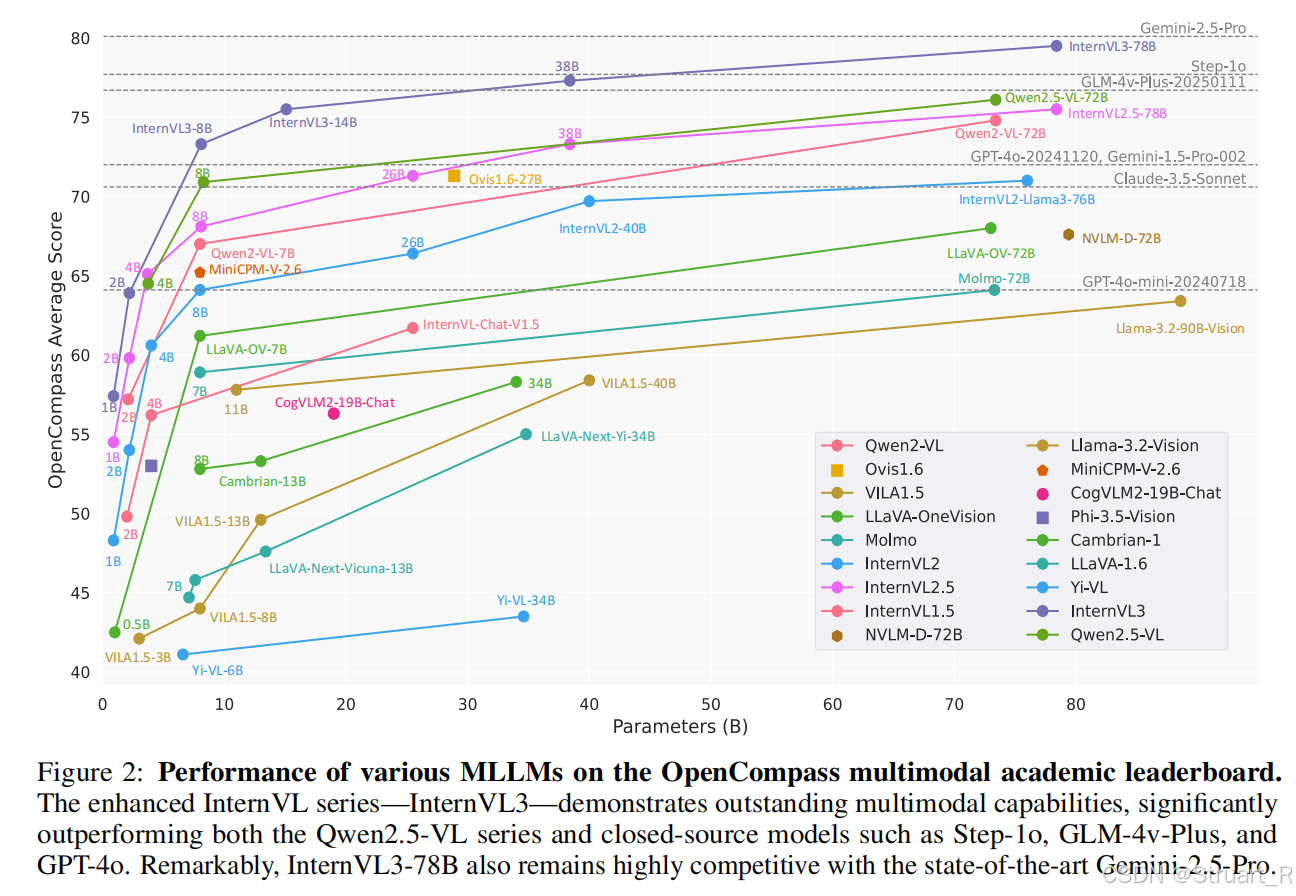
2、方法
整体架构
仍然沿用ViT-MLP-LLM的三阶段架构。
视觉编码器:采用两种预训练视觉模型作为基础,InternViT-300M用于轻量级模型InternVL3-1B;InternViT-6B用于大型模型InternVL3-78B。采用高分辨率优化,Pixel Unshuffle将图像分割成448x448像素图块,并编码为256个tokens,显著降低计算开销。(这一波方法跟之前相同)

语言模型:基于开源LLM初始化,预训练Qwen2.5-72B或InternLM3-8B。
MLP:两层全连接网络,随机初始化权重,并将ViT输出的视觉嵌入投影到LLM嵌入空间中,实现模态对齐。
变量视觉位置编码(V2PE)
由于MLLM中的传统位置编码对视觉令牌使用固定增量+1,导致长序列视频,超出模型的位置窗口限制。V2PE中设置动态增量,对文本token仍然+1,视觉token+,其中
在训练中从离散数据集中随机采样。
具体来说,MLLM中一组token记录为,位置编码记录为
。
函数关系在V2PE中满足:
其中
原生多模态预训练方法
数据混合
(1)多模态数据:图像-文本对,视频帧序列,跨膜态文档(医学,图标,GUI)
(2)纯文本数据:开源语料,数学文本,知识文本
数据比例为纯文本 vs 多模态=1:3(共200B tokens),平衡模态对齐与语言能力。所有输入统一为序列。仅仅通过token计算自回归损失,迫使视觉token编码为语言预测的有效信号。
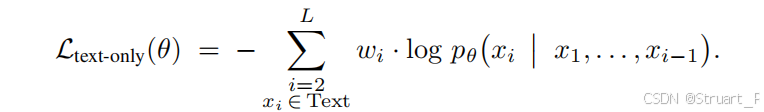
由于token输入中对于长文本或者短文本保证一定的理解,所以以往的方法设计了token平均(偏向长文本)或样本平均(偏向短文本),从而存在梯度偏差,而本文采用了平方平均加权。权重定义为,
为样本token数。
训练过程中ViT+MLP+LLM同步更新,突破传统冻结策略的限制,并全局采用text-only loss。
3、训练后处理
原生多模态训练之后,采用两阶段的后处理训练策略提升模型性能。
监督微调
对数据采用随机JPEG压缩,模拟真实场景下图像退化的问题,并继续沿用平方平均加权,数据采用图像、视频、文本混合输入,并且将训练样本数据量再一次提高(1630w->2170w) ,新增GUI操作,3D场景理解,科学图标解析等数据领域。
混合偏好优化
由于SFT的训练过程中训练时采用真实标签,推理时依赖模型自生成内容,会造成曝光偏差(exposure bias),所以基于300K的偏好对信息(覆盖科学推理,科学问答,OCR复杂场景),并在正例中包含CoT,反例加入错误模式。
损失采用偏好损失(学习人类偏好),质量损失(独立评估响应的绝对质量),生成损失三重融合(以往的LM loss,维持文本生成流畅性)。
4、测试时扩展
提升复杂任务的鲁棒性,引入动态推理优化机制。
采用Best-of-N采样策略,选用VisualPRM视觉过程奖励模型作为评估模型,利用最优响应完成推理和评估任务。
Best-of-N工作流程:对同一问题生成 N 个候选响应(默认 N=8);用 VisualPRM 奖励模型 对每个响应评分;选择 最高分响应 作为最终输出。
五、BLIP-3o









)



:Spring Boot + AI + Vue3 + OSS + DashScope 实现高效语音识别系统(附完整源码))


置信度研究的经典与前沿论文 :温度缩放;语义熵;自一致性;事实与反思;检索增强;黑盒引导;)

对北半球光伏数据进行时间序列预测)
