参考文献:《ARM ArchitectureReference Manual ARMv7-A and ARMv7-R edition》
1、MMU
1.1 背景
早期的内存是比较小的,一般是几十k,不过相应的程序也是比较小的,这时程序可以直接加载到内存中运行。后来为了支持多个程序的并行,内存中出现了固定分区,在编译阶段将不同程序,划分在不同的内存区域上。这种方式存在不少问题:一是内存分区大小与程序大小要匹配,二是地址空间无法动态的增长。于是内存动态分区思想便诞生了,内存上线划出一块区域给操作系统,然后剩余的内存空间给用户进程使用,这样用户程序所使用的内存空间,跟随程序大小及数目进行变动。
不论是静态分析,还是动态分区,都存在一些问题:进程地址空间安全问题、内存使用效率低。为了能够让多程序安全、高效地并行运行,物理内存中需要存放多个程序的代码及数据,这时虚拟内存便诞生了。不得不说虚拟内存是一个伟大的发明,一方面它让每个程序认为自己是独自、连续的使用内存,另一方面,每个程序之间的内存形成了安全隔离,避免程序破坏彼此的内存。
后来随着软件的快速发展,一个程序的大小变得很大,这时物理内存大小跟不上程序大小增加的速度。这样便不能将整个程序加载到物理内存中,一是物理内存没有这么大,二是如果将整个程序加载到内存,为了多程序并行,就需要将大量的数据及代码换入、换出,这导致程序运行效率低下。虚拟内存并没解决高效使用内存的问题,好在程序运行遵循时间、空间局部性原理,进而出现了分页机制。分页机制从根本上解决了高效使用物理内存的问题。每次只需要将几页的代码、数据从磁盘中加载到内存,程序就能正常运行。当程序运行的过程中,需要新的代码、数据会产生缺页异常,这些代码、数据就会从磁盘加载到内存,然后程序从异常恢复正常运行。
对于支持虚拟内存,分页机制的系统,处理器直接寻址虚拟地址,这个地址不会直接发给内存控制器,而是先发给内存管理单元(Memory Manager Unit,MMU)。MMU 就是负责将虚拟地址转换和翻译成物理地址的一个硬件模块,其实 MMU 所做的事,完全可以通过 CPU 来实现。为啥还要一个 MMU 硬件模块呢?就是为了提升虚拟地址到物理地址转换的速度,减少转换所消耗的时间。MMU 包含两个模块TLB(Translation Lookaside Buffer)和TWU(Table Walk Unit)。TLB 是一个高速缓存,用于缓存页表转换的结果,从而缩短页表查询的时间。TWU 是一个页表遍历模块,页表是由操作系统维护在物理内存中,但是页表的遍历查询是由 TWU 完成的,这样减少对 CPU 资源的消耗。
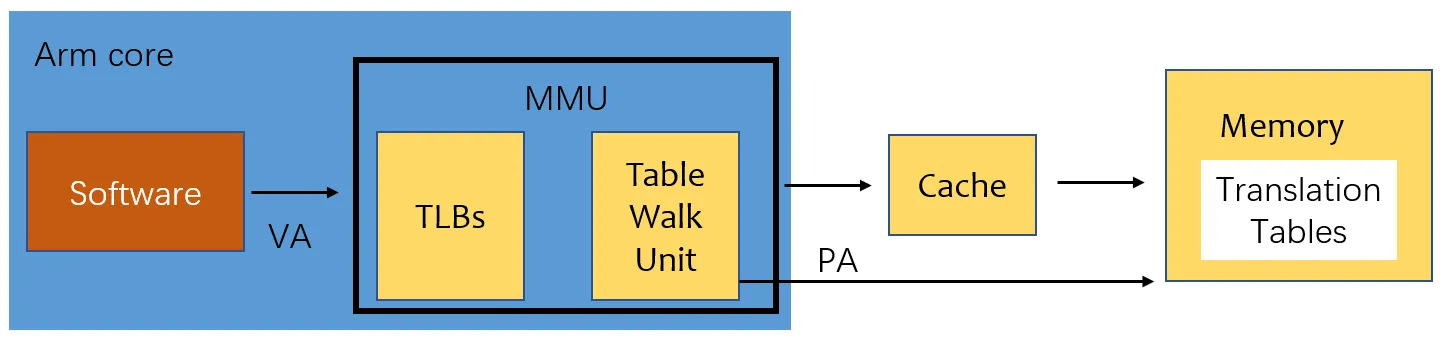
虚拟内存及分页机制的出现,解决了进程地址空间安全性的问题和内存使用效率低的问题,但是也引入了系统性能变差的问题。本来 CPU 可以直接通过访存执行程序,但是现在引入了虚拟地址到物理地址的转换。MMU 硬件模块的出现,就是为了解决这个性能问题。因此,几 G 运行内存的电脑,可以并行运行几十G的多程序,让你在听歌的同时,能够并行处理编辑文档,下载电影,收发邮件等。
1.2 主要功能
- 地址翻译
- 在用户访问内存时,将用户访问的虚拟地址翻译为实际的物理地址,以便 CPU 对实际的物理地址进行访问。
- 访问权限控制
- 可以对一些虚拟地址进行访问权限控制,以便于对用户程序的访问权限和范围进行管理,如代码段一般设置为只读,如果有用户程序对代码段进行写操作,系统会触发异常。
- 引申的物理内存管理
- 对系统的物理内存资源进行管理,为用户程序提供物理内存的申请、释放等操作接口。
2、Translation tables
2.1 Linux 中的页表
Linux 内核通过多级页表管理虚拟地址到物理地址的转换。不同处理器架构可根据需求选择页表级数,主要组件包括:
| 缩写 | 全称 | 作用描述 | 典型x86_64位偏移 |
|---|---|---|---|
| PGD | Page Global Directory | 顶级页表结构 | 47-39位 |
| P4D | Page 4th-level Directory | 第四级目录(4.11新增) | 未固定 |
| PUD | Page Upper Directory | 上层目录 | 38-30位 |
| PMD | Page Middle Directory | 中间目录 | 29-21位 |
| PTE | Page Table Entry | 最终页表项 | 指向物理页帧 20-12位 |
Linux 4.11 之前:
- 最大支持4级页表(PGD→PUD→PMD→PTE)
实际使用级数由 CPU 架构决定:
- 4级:PGD+PUD+PMD+PTE(如x86_64常规4KB页)
- 3级:PGD+PMD+PTE
- 2级:PGD+PTE (常见的 ARMv7)
Linux 4.11 及之后:
- 引入P4D 级(位于 PGD 和 PUD 之间),扩展至 5 级页表
- 新增级数应对48位以上地址空间(如 5 级分页应对 57 位地址)
注意:
PGD、PUD、PMD、PTE 这些,都是 Linux 中的称呼。在不同 CPU 架构手册中,叫法可能各有不同。例如,在 ARMv7 中,对于只支持二级页表的情况下,PGD 称之为 First-level table,PTE 称之为 Second-level table。
在下面的文章中,为了符合 ARM 手册,将 translation table,翻译成转换表,可以理解成,就是页表的含义。
2.2 ARMv7 中的页表
ARMv7-A 定义了两种转换表格式 :
Short-descriptor format
这是一种基础格式,是未包含 大物理地址扩展(LPAE) 的实现中唯一支持的格式。它在转换表中使用了 32 位的描述符条目,并提供了:
- 提供两级地址转换
- 32-bit 输入地址
- 输出地址可高达 40-bit
- 通过使用 supersections 实现 32 位以上地址的支持,最小内存单位为 16MB
- 支持无访问域、客户端域和管理器域
- 32-bit 页表项
Long-descriptor format
这是一种 可选格式。大型物理地址扩展增加了对这种格式的支持。它在转化表中使用了64位的描述符条目,并提供了:
- 最多三级地址查找
- 第二级转换时,输入地址可以高达40位
- 输出地址高达40位
- 4KB assignment granularity across the entire PA range.
- 不支持域,所有存储区都被视为在客户域中
- 64-bit 位页表项
- 固定 4kB 的表大小,除非输入地址被截断
本篇文章,皆以常见的 Short-descriptor format 为例进行讲解。关于 Long-descriptor format ,有兴趣的可以自行阅读 ARM 手册相关内容。
转换表格式,其实就是页表格式。所谓的 descriptor,描述的就是各级 页表 的 页表项
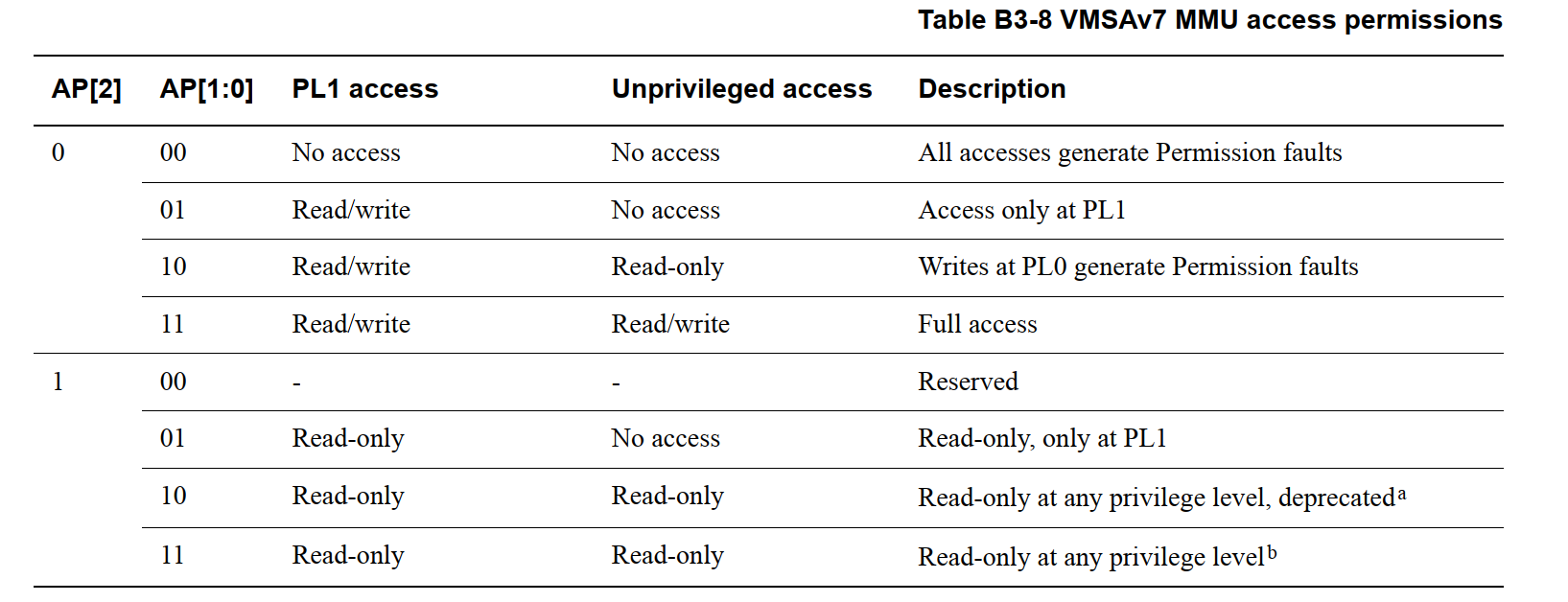
3. Short-descriptor format
3.1 Short-descriptor translation table format descriptors
短描述符转换表格式支持以内存段(memory sections)或内存页(memory pages)为基础的内存映射
- Spersections: 16MB 的内存块(memory block)
- Sections: 1MB 的内存块
- Large pages: 64KB 的内存块
- Small pages: 4KB 的内存块
这其中,除了 Small pages,其余仅使用单个 TLB 表项映射大区域内存。
Short-descriptor format 中是否支持 Spersections 是 implementation DEFINED
当使用 Short-descriptor translation table format 时,内存中保留两级转换表:
First-level table
一级表存储一级描述符,每个描述符包含:
- 段(Section)和超级段(Supersection)的基地址与转换属性
- 大页(Large page)或小页(Small page)的转换属性及指向二级表的指针
Second-level tables
二级表存储二级描述符,包含:
- 大页(Large page)或小页(Small page)基地址与转换属性
在短描述符格式(Short-descriptor format)中,二级表可称为页表(Page tables)
注:每个二级表需占用 1KB 内存空间。一条页表项 4 字节,共有 2^8 个页表项
First-level table 在 Linux 中又叫做一级页表,PGD
Second-level tables 在 Linux 中又叫做二级页表,PTE
转换表中的描述符通常分为以下类型:
- 无效条目/故障条目(Invalid or fault entry)
- 页表条目(Page table entry):指向下一级翻译表
- 页条目/段条目(Page or section entry):定义内存访问属性
- 保留格式(Reserved format)
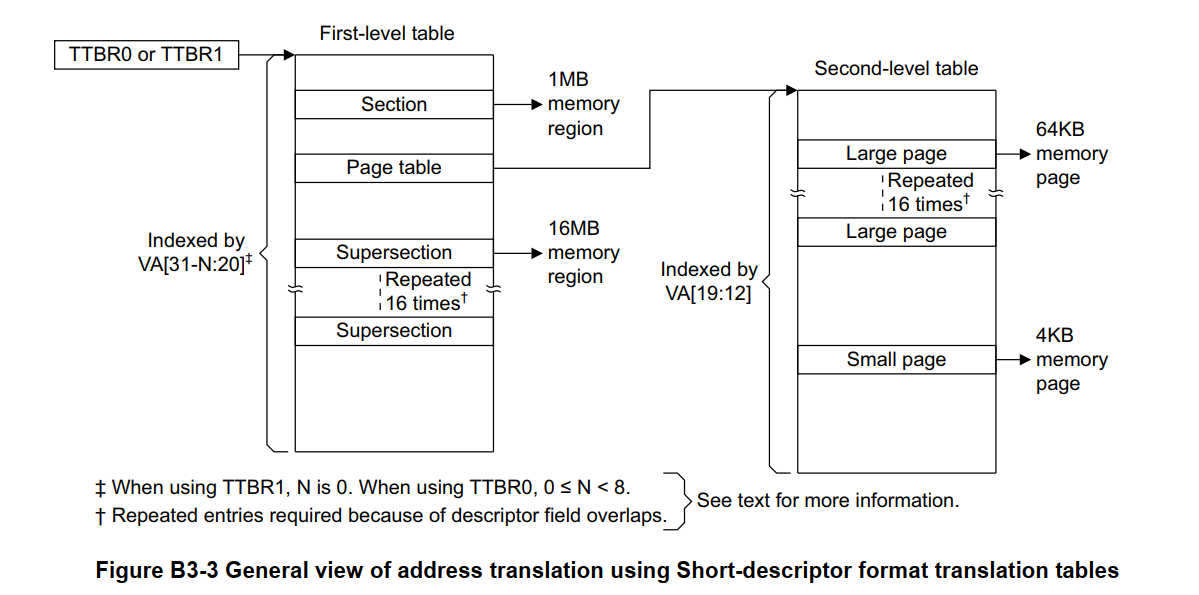
从上图也可以看到,Large pages、 Small pages 才支持二级页表。Spersections 和 Sections 只支持一级页表
3.1.1 一级转换表
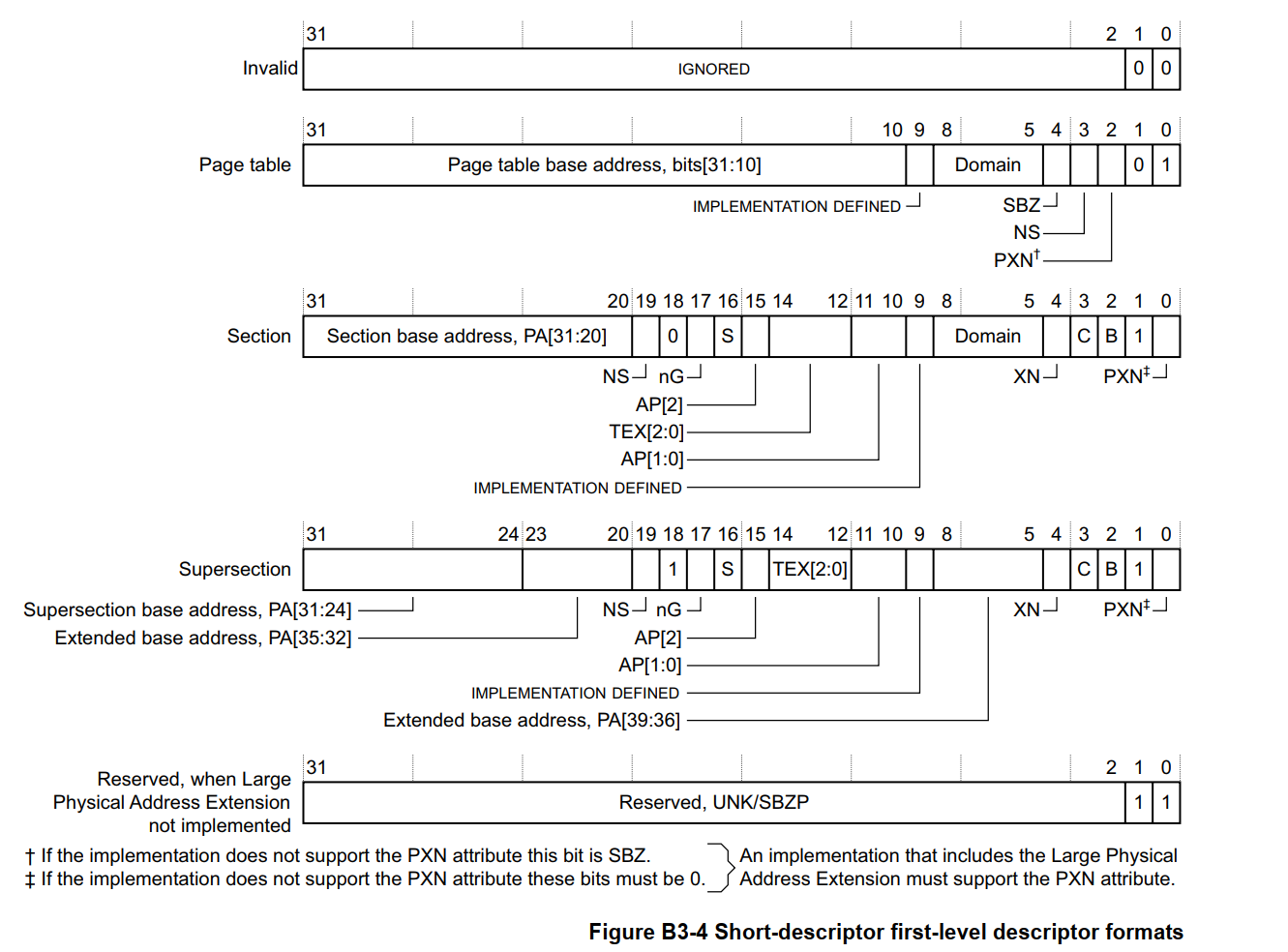
最后两位 bits[1:0] 决定描述符类型
- 0b00, Invalid
- 0b01, Page table
- 0b10, Section or Supersection
- 0b11, Section or Supersection, if the implementation supports the PXN attribute
- 0b11, Reserved, UNK/SBZP, if the implementation does not support the PXN attribute
举个例子,当操作系统全部使用 Section 作为一级页表中的最小寻址单位时,共 12 位地址表示。因为 Section 不涉及到二级页表,所以页表项最多为 212。而页内偏移为 [19:0] ,所以页大小为 220。综上,可以表示的最大虚拟空间大小为:212 * 220
3.1.2 二级转换表
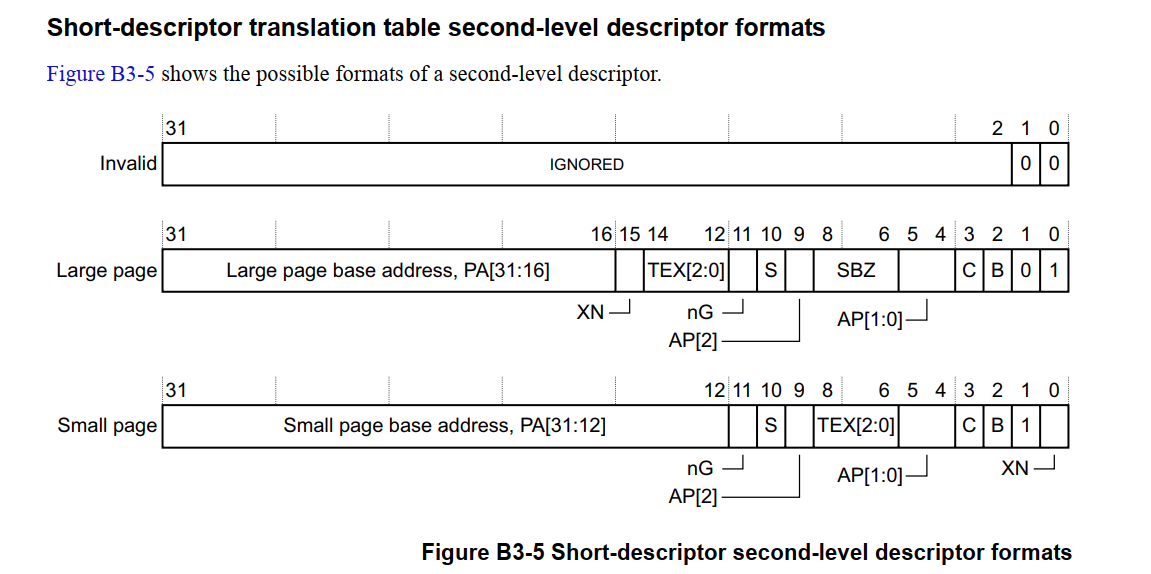
最后两位 bits[1:0] 决定描述符类型
- 0b00, Invalid
- 0b01, Large page
- 0b1x, Small page
举个例子,使用 Small Page 作为二级页表的最小寻址单位时,共 20 位地址表示,所能表示的最大虚拟地址范围就是 220* 212 = 4GB。页内偏移为 [11:0] ,所以页大小为 212
3.2 Short-descriptor translation table format descriptors 中的内存属性
把内存属性单独拿出一个章节来讲,是因为内存属性很重要.。
- TEX[2:0], C, B
- 内存区域属性位
- 详见第 5 章节
- XN bit
- 全局不可执行。如果执行,会触发 Permission fault
- PXN bit, when supported
- Privileged Execute-Never,特权模式不可执行。在支持的情况下,PXN 位决定处理器在 PL1 特权级时是否可执行该内存区域的代码。如果执行,会触发 Permission fault
- NS bit
- NS = Non-Secure,只有在 启用了 TrustZone 安全扩展 的系统中才有意义
- 只会出现在一级页表项中
- 详见 3.4 章节
- Domain
- Domains 是一种粗粒度的内存访问控制机制,属于 ARMv7 MMU 的一部分
- 详见 3.3 章节
- AP[2], AP[1:0]
- 访问权限位
- 详见 3.5 章节
- S bit
- 可共享位。确定寻址区域是否为可共享内存
- nG bit
- 非全局位。确定如何在 TLB 中标记转换
- Bit[18], when bits[1:0] indicate a Section or Supersection descriptor
- 0 Descriptor is for a Section.
- 1 Descriptor is for a Supersection
3.3 Domains
在 ARMv7 的 VMSA 中,仅存在于 Short-descriptor format:
- 总共有 16 个 Domains(编号 0 ~ 15)
- 每个 Section/Page 在页表中被指定属于哪个 Domain(用 4-bit 域表示)(不支持 Supersections)
- 仅有一级页表条目有 Domains 域,二级转换表条目从父级一级页表条目继承域设置
- CPU 中有一个 DACR(Domain Access Control Register),用于配置每个 Domain 的访问权限
DACR 是一个 32-bit 寄存器,每两个 bit 控制一个 domain 的访问权限。每个域的访问权限可以设置为:

| 值 | 含义 | 解释 |
|---|---|---|
| 0b00 | No access | 访问该 domain 的内存会导致 fault |
| 0b01 | Client | 根据页表中的 AP bits 进行访问权限检查(标准权限检查方式) |
| 0b11 | Manager | 不检查访问权限,直接允许访问(相当于绕过 AP 位) |
| 0b10 | 保留(未使用) | 访问该 domain 的内存会导致 fault |
✅ 工作原理总结
访问内存时,ARM 的 MMU 进行如下步骤:
- 使用页表将虚拟地址翻译为物理地址,并获得该页属于哪个 Domain(通过页表项的 bits[8:5])
- 查 DACR 寄存器,查看该 Domain 的访问权限设定
- 根据权限设定决定行为:
- No access → 抛出异常
- Client → 继续检查页表中的 AP(Access Permission)位
- Manager → 直接允许访问(忽略 AP 位)
Domains 域现在不常用了。粒度太粗、管理复杂,ARMv8+ 已废弃 Domain 概念,使用更加细粒度的 EL 权限模型、权限表(PTE) 来管理访问权限。
在 ARMv7 的 VMSA 中,Domains 是 MMU 机制的一部分,不能绕过或关闭。通常可以将所有 domain 设置为 Client,配合合理的页表 AP
3.4 Control of Secure or Non-secure memory access
在 ARMv7 架构中,针对安全(Secure)与非安全(Non-secure)PL1&0 阶段的第 1 阶段地址转换,其转换表基址寄存器(TTBR0、TTBR1)及转换表基址控制寄存器(TTBCR)均采用安全与非安全 双 bank 设计。处理器执行内存访问时所处的安全状态(Security state)将自动选择对应版本的寄存器组。
当 CPU 当前处于 Secure 状态(比如运行 Secure OS 或 TrustZone secure world 中的代码)时:页表中设置的 NS 位会影响这个访问是访问到:
- Secure memory(NS=0)
- 还是 Non-Secure memory(NS=1)
当 CPU 当前处于 Non-secure 状态时(比如运行 Linux 等普通 OS):页表中设置的 NS 位根本不起作用,会被忽略。因为 Non-secure world 不能访问 Secure memory。
3.5 Memory access control
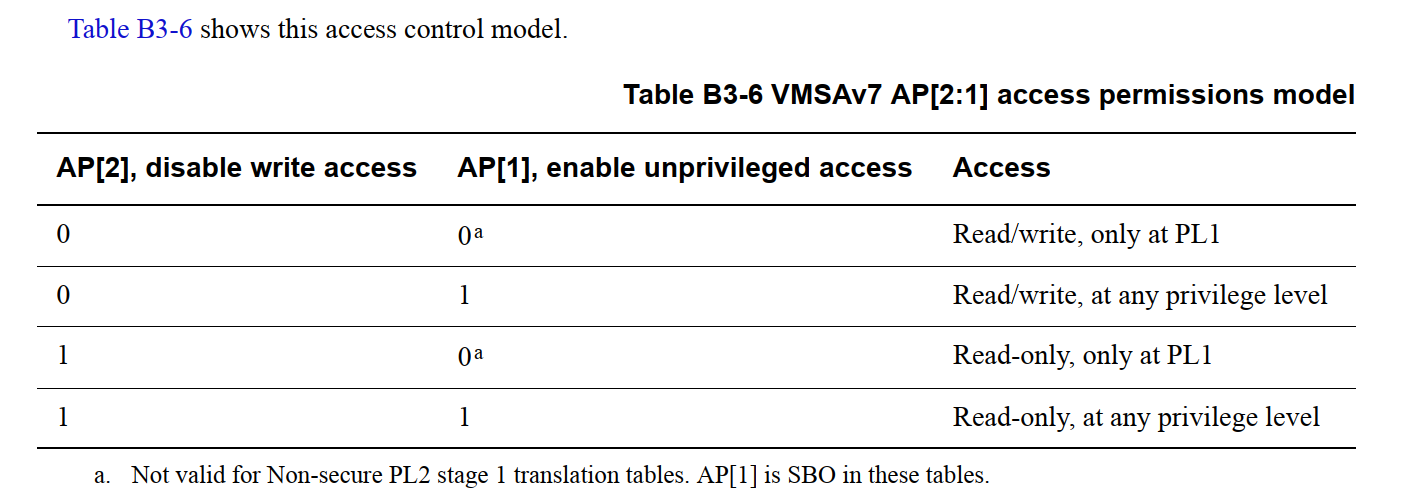
在转换表描述符中,访问权限位(Access permission bits)用于控制对相应内存区域的访问。短描述符转换表格式(Short-descriptor translation table format)支持两种定义访问权限的方式:
- 三比特模式(AP[2:0]):
- 通过 AP[2:0] 三个比特位定义访问权限。
- 两比特模式(AP[2:1] + 访问标志位):
- 通过 AP[2:1] 两个比特位定义访问权限,
- AP[0] 可作为访问标志(Access flag)使用。
系统控制寄存器 SCTLR.AFE 用于选择访问权限的配置模式:
- 若将该位置 1(启用访问标志功能),则自动选择 AP[2:1] 定义访问权限的模式。
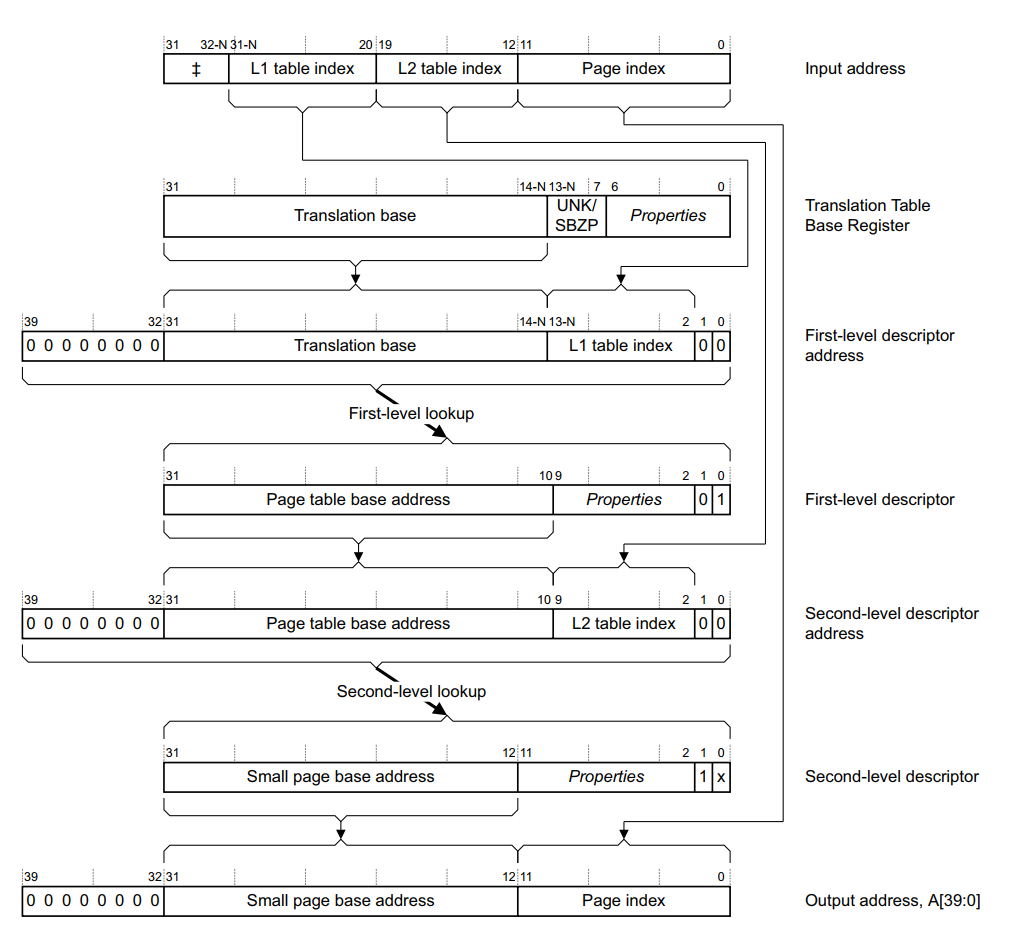
3.6 转换表的工作流程
以 Small page 为例:
- 首先输入的虚拟地址,可以大致分为 3 部分
- 一级页表偏移
- 二级页表偏移
- 页内偏移
- 根据输入地址的范围(也就是 N 的取值,这一块可以先阅读第 4 章节),找到页表基址(TTBR0 or TTBR1)
- 根据 页表基址 + 一级页表偏移,找到一级页表的 “页表项描述符”
- 页表基址,实际上就是 PGD 表的基址;一级页表偏移指的就是 PGD 表中的某个页表项
- 根据上一步找到 “一级页表项描述符” 中包含的二级页表的基址[31:10] + 二级页表偏移,找到二级页表的 “页表项描述符”
- 二级页表的基址,实际上就是 PTE 表的基址;二级页表偏移指的就是 PTE 表中的某个页表项
- 在二级页表项描述符中,就包含了最终的物理地址的 [31:12],再加上 页内偏移,最终就找到了物理地址
- 二级页表项描述符,指的就是 PTE 表中的某个页表项
4、关于页表基址 TTBR
ARMv7 中,有两个存放页表(一级页表)基地址的寄存器,TTBR0 和 TTBR1。那 MMU 进行地址翻译(translation table walk)的时候到底是选择哪一个寄存器的值作为基地址呢?
那么这个时候就需要用到 TTBCR 寄存器,这个寄存器的格式如下图:

其中最后 [2-0] 位(值为N)决定了用 TTBR0 还是 TTBR1,手册里面已经说的很清楚了,这里直接贴出来。

- 当 N == 0 是,使用 TTBR0 作为基址。关闭/禁用 TTBR1 作为基址
- 当 N>0 时,如果给的虚拟地址 [31:32-N] 位都是 0,那么用 TTBR0,一旦这其中的某一位是 1 了,就用 TTBR1。
- 又因为 N 的取值只有 0 到 7,所以每个 N 的取值都对应了一个用 TTBR0 或者 TTBR1 的分界线。
- 比如当 N=2 时,如果给的虚拟地址第 [31:30] 位为 0,即不超过 0x40000000,那么就用 TTBR0,一旦等于或者超过 0x40000000 那么就用 TTBR1。
下面还有一张 N 值不同时,对应的地址分界线图:


理论上,一个页表基址寄存器也是能正常工作,但两个可以带来更好的性能和系统隔离性
为什么需要两个基址寄存器?
✅ 好处 1:用户态和内核态分离
- 操作系统常常希望:
- 用户进程只能访问用户空间
- 内核可以访问全部空间
- 有了两个页表:
- 切换进程时,只需切换 TTBR0(用户空间部分)
- TTBR1(内核空间页表)不变,提升性能并确保安全
✅ 好处 2:性能优化
- 避免频繁清空整个 TLB(Translation Lookaside Buffer):
- 进程切换时只换 TTBR0 → 用户空间换了
- TTBR1 → 内核页表不变,TLB 中内核页表项仍有效
✅ 好处 3:内核共享
- 所有进程共用一套内核映射(TTBR1)
- 每个进程拥有自己独立的用户映射(TTBR0)
5、关于内存属性
除输出地址外,指向内存页或区域的页表项通常还包含用于定义目标内存属性字段(Memory Region Attribute Fields),用于控制:
- 内存类型(如Normal或Device内存)
- 缓存访问策略(如Write-Back、Write-Through)
- 可共享性(Shareable),即多核间的一致性(Coherency)
为深入理解内存属性字段的配置机制,需区分以下两种模式:
- Short-descriptor translation table format (无 TEX 重映射)
- 直接通过TEX[2:0]、C(Cacheable)、B(Bufferable)位组合定义内存行为,适用于大多数标准场景
- Short-descriptor translation table format (启用 TEX 重映射)
- 通过 CP15 寄存器重映射 TEX 位语义,支持更灵活的缓存策略定制,常见于定制化硬件设计
5.1 without TEX remap
使用 Short-descriptor translation table formats 时,可以使用 SCTLR.TRE 禁用 TEX 重映射。
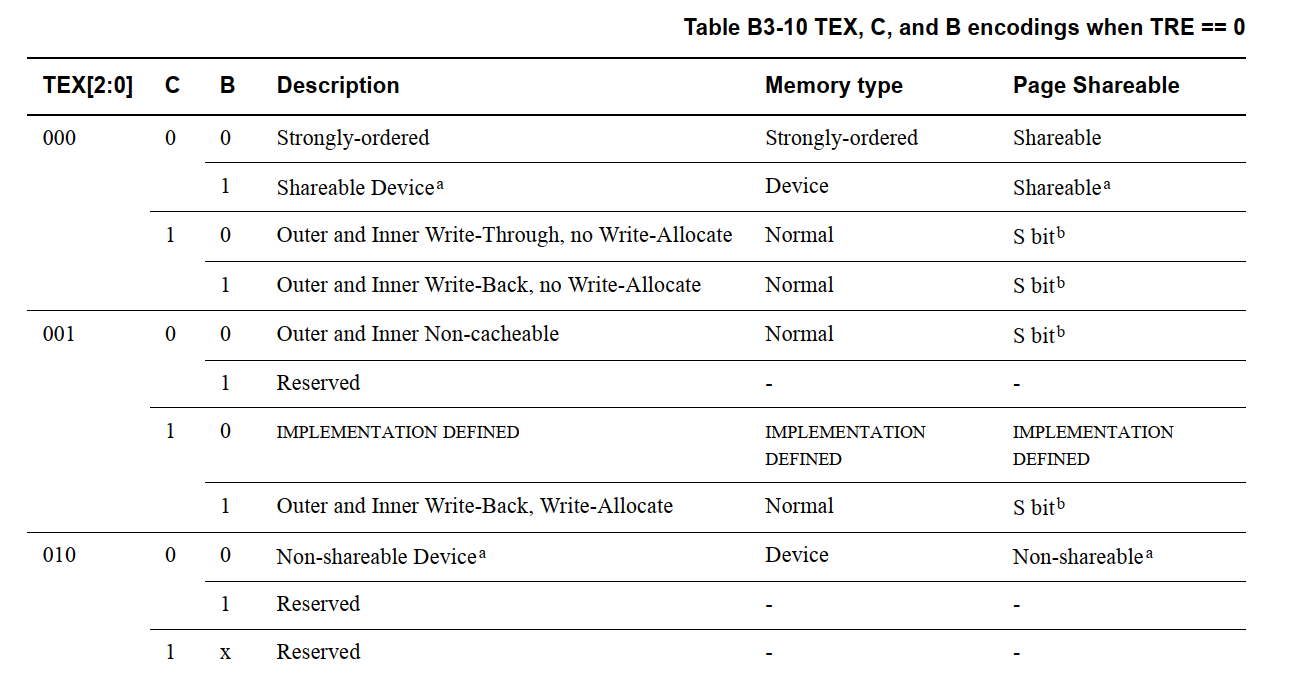

(without TEX remap 场景下的的 Shareability 与 S 位)
转换表项(Translation Table Entry)中还包含一个 S 位(Shareable位),其作用如下:
- 若表项指向设备内存(Device)或强序内存(Strongly-ordered):
- 该位被忽略(无论S=0或1均不生效)
- 若表项指向普通内存(Normal Memory):
- 该位决定内存区域的可共享性(Shareability):
- S=0:该普通内存区域为非可共享(Non-shareable)。
- S=1:该普通内存区域为可共享(Shareable)
- 该位决定内存区域的可共享性(Shareability):

5.2 with TEX remap
当使用短描述符转换表格式(Short-descriptor translation table formats)时,若将系统控制寄存器 SCTLR.TRE 置为1,则启用 TEX 重映射(TEX Remap)功能。在此配置下:
- 软件配置要求
- 定义转换表的软件必须编程设置
PRRR(Primary Region Remap Register)和NMRR(Normal Memory Remap Register),以指定 7 种可能的内存区域属性 - 转换表描述符中的 TEX[0]、C(Cacheable)和 B(Bufferable)位通过索引
PRRR和NMRR来定义内存区域属性。 - 硬件不会使用 TEX[2:1] 位
- 定义转换表的软件必须编程设置
- TEX 重映射生效时的行为
- 对于 TEX[0]、C 和 B 位的 8 种可能组合中的 7 种,其内存区域属性由
PRRR和NMRR的字段定义(如本节所述)。 - 第 8 种组合的含义由具体实现定义(IMPLEMENTATION DEFINED)。
PRRR中的 4 个比特位用于定义该区域是否可共享(Shareable)
- 对于 TEX[0]、C 和 B 位的 8 种可能组合中的 7 种,其内存区域属性由
- 寄存器字段映射关系
- 对于转换表项中TEX[0]、C 和 B 位的所有可能编码组合,表 B3-12 列出了
PRRR和NMRR寄存器中描述内存区域属性的对应字段。
- 对于转换表项中TEX[0]、C 和 B 位的所有可能编码组合,表 B3-12 列出了
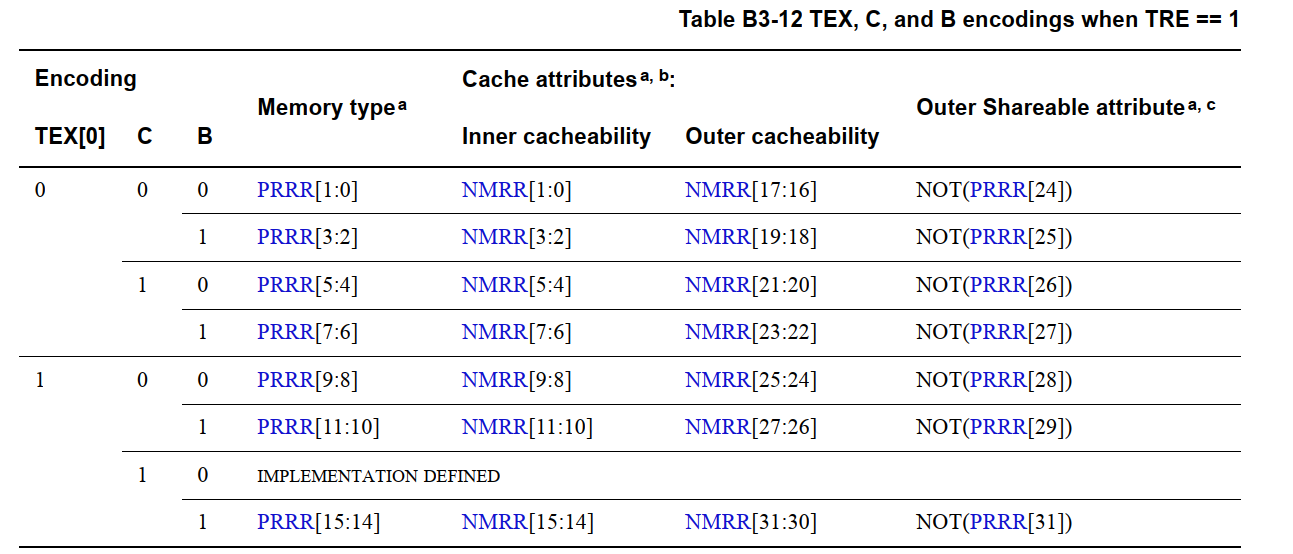
乍一看,有点迷糊,这块不太好理解。总结来说,在 without TEX remap 的场景下,在 PTE 中直接写 TEX[2:0]、B、C 对应的 bit 位,就可以控制页面的内存区域属性。但是在 with TEX remap 情况下,TEX、B、C 的值不再直接表示区域内存属性。所有可能的区域内存属性的值,都在 PRRR 和 NMRR 寄存器中。而 TEX、B、C 三个 bit 组成的 8 种组合,就是在这两个寄存器中的偏移。
PRRR, Primary Region Remap Register, VMSA
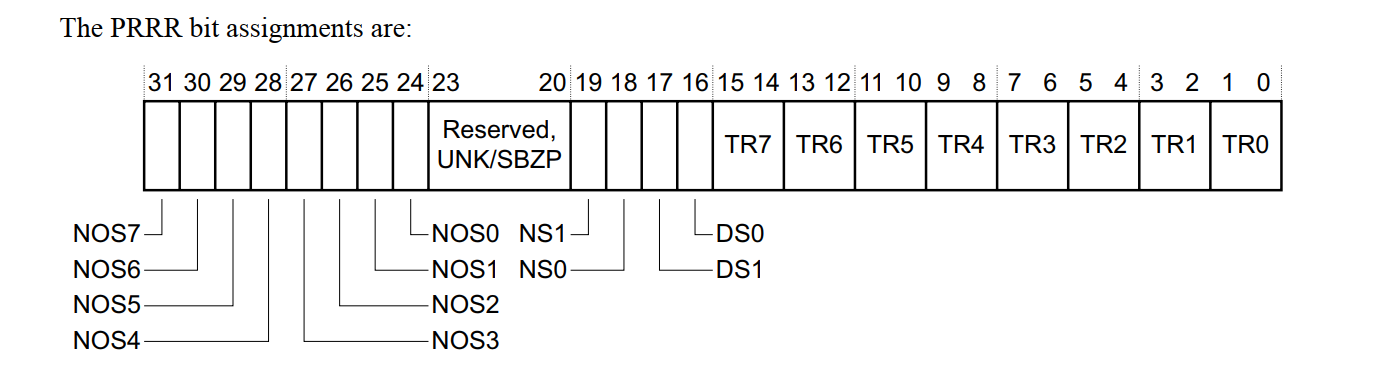
所有 TEX[0]、B、C 可能的组合如下:对应的 n 是几,使用的就是 NOS(n) + TR(n) 的组合

关于 PRRR 寄存器,以下是详细解释:

- NOS 位是控制内存区域的可共享属性。
- NS1, bit[19]
- NS0, bit[18]
- DS1, bit[17]
- DS0, bit[16]
这些位控制的是 Normal memory 和 Device memory 的共享性(shareability)属性,也就是说,它们不是控制缓存方式,而是控制 是否是 shareable 类型。
| 名称 | 控制的情况 | 含义(bit 值) |
|---|---|---|
| NS0 (bit 18) | 页表中 S=0 且是 Normal memory | 0 ➜ Non-shareable 1 ➜ Shareable |
| NS1 (bit 19) | 页表中 S=1 且是 Normal memory | 0 ➜ Non-shareable 1 ➜ Shareable |
| NS0 (bit 18) | 类似逻辑,作用于 Device memory,S=0/S=1 映射 |

- TR 位用于控制内存类型
NMRR, Normal Memory Remap Register, VMSA
关于 NMRR 寄存器这里不再详细解释了,有兴趣的可以自行研究。

6、Linux 下的页表映射
上面讲的都是理论,我们对应到 Linux 源码中,看看内存区域属性是如何配置的。我们查看下 ARM 架构下的 ioremap 的实现。
arch\arm\mm\ioremap.c:
void __iomem *ioremap(resource_size_t res_cookie, size_t size)
{return arch_ioremap_caller(res_cookie, size, MT_DEVICE,__builtin_return_address(0));
}
EXPORT_SYMBOL(ioremap);void __iomem *ioremap_cache(resource_size_t res_cookie, size_t size)
{return arch_ioremap_caller(res_cookie, size, MT_DEVICE_CACHED,__builtin_return_address(0));
}
EXPORT_SYMBOL(ioremap_cache);void __iomem *ioremap_wc(resource_size_t res_cookie, size_t size)
{return arch_ioremap_caller(res_cookie, size, MT_DEVICE_WC,__builtin_return_address(0));
}
关于 MT_DEVICE、MT_DEVICE_CACHED、MT_DEVICE_WC,就是内存区域属性,最终会被翻译成我们在第 5 章节所讲的 TEX、B、C 的值写到 PTE 页表项中。
arch\arm\mm\mmu.c
static struct mem_type mem_types[] __ro_after_init = {[MT_DEVICE] = { /* Strongly ordered / ARMv6 shared device */.prot_pte = PROT_PTE_DEVICE | L_PTE_MT_DEV_SHARED |L_PTE_SHARED,.prot_l1 = PMD_TYPE_TABLE,.prot_sect = PROT_SECT_DEVICE | PMD_SECT_S,.domain = DOMAIN_IO,},[MT_DEVICE_NONSHARED] = { /* ARMv6 non-shared device */.prot_pte = PROT_PTE_DEVICE | L_PTE_MT_DEV_NONSHARED,.prot_l1 = PMD_TYPE_TABLE,.prot_sect = PROT_SECT_DEVICE,.domain = DOMAIN_IO,},[MT_DEVICE_CACHED] = { /* ioremap_cache */.prot_pte = PROT_PTE_DEVICE | L_PTE_MT_DEV_CACHED,.prot_l1 = PMD_TYPE_TABLE,.prot_sect = PROT_SECT_DEVICE | PMD_SECT_WB,.domain = DOMAIN_IO,},[MT_DEVICE_WC] = { /* ioremap_wc */.prot_pte = PROT_PTE_DEVICE | L_PTE_MT_DEV_WC,.prot_l1 = PMD_TYPE_TABLE,.prot_sect = PROT_SECT_DEVICE,.domain = DOMAIN_IO,},............
}
上表中提到的 L_PTE_MT_DEV_SHARED 、L_PTE_SHARED 页表项 PTE 相关的宏,定义在 pgtable-2level.h 头文件中:
arch\arm\include\asm\pgtable-2level.h
/** These are the memory types, defined to be compatible with* pre-ARMv6 CPUs cacheable and bufferable bits: n/a,n/a,C,B* ARMv6+ without TEX remapping, they are a table index.* ARMv6+ with TEX remapping, they correspond to n/a,TEX(0),C,B** MT type Pre-ARMv6 ARMv6+ type / cacheable status* UNCACHED Uncached Strongly ordered* BUFFERABLE Bufferable Normal memory / non-cacheable* WRITETHROUGH Writethrough Normal memory / write through* WRITEBACK Writeback Normal memory / write back, read alloc* MINICACHE Minicache N/A* WRITEALLOC Writeback Normal memory / write back, write alloc* DEV_SHARED Uncached Device memory (shared)* DEV_NONSHARED Uncached Device memory (non-shared)* DEV_WC Bufferable Normal memory / non-cacheable* DEV_CACHED Writeback Normal memory / write back, read alloc* VECTORS Variable Normal memory / variable** All normal memory mappings have the following properties:* - reads can be repeated with no side effects* - repeated reads return the last value written* - reads can fetch additional locations without side effects* - writes can be repeated (in certain cases) with no side effects* - writes can be merged before accessing the target* - unaligned accesses can be supported** All device mappings have the following properties:* - no access speculation* - no repetition (eg, on return from an exception)* - number, order and size of accesses are maintained* - unaligned accesses are "unpredictable"*/
#define L_PTE_MT_UNCACHED (_AT(pteval_t, 0x00) << 2) /* 0000 */
#define L_PTE_MT_BUFFERABLE (_AT(pteval_t, 0x01) << 2) /* 0001 */
#define L_PTE_MT_WRITETHROUGH (_AT(pteval_t, 0x02) << 2) /* 0010 */
#define L_PTE_MT_WRITEBACK (_AT(pteval_t, 0x03) << 2) /* 0011 */
#define L_PTE_MT_MINICACHE (_AT(pteval_t, 0x06) << 2) /* 0110 (sa1100, xscale) */
#define L_PTE_MT_WRITEALLOC (_AT(pteval_t, 0x07) << 2) /* 0111 */
#define L_PTE_MT_DEV_SHARED (_AT(pteval_t, 0x04) << 2) /* 0100 */
#define L_PTE_MT_DEV_NONSHARED (_AT(pteval_t, 0x0c) << 2) /* 1100 */
#define L_PTE_MT_DEV_WC (_AT(pteval_t, 0x09) << 2) /* 1001 */
#define L_PTE_MT_DEV_CACHED (_AT(pteval_t, 0x0b) << 2) /* 1011 */
#define L_PTE_MT_VECTORS (_AT(pteval_t, 0x0f) << 2) /* 1111 */
#define L_PTE_MT_MASK (_AT(pteval_t, 0x0f) << 2)
对于 ARMv7 来说,我们只需要关注上表的后三位。分别对应的就是 TEX[0]、C、B。
6.1 关于 PRRR 和 NMRR 寄存器的值
arch\arm\mm\proc-v7-2level.S
/** Memory region attributes with SCTLR.TRE=1** n = TEX[0],C,B* TR = PRRR[2n+1:2n] - memory type* IR = NMRR[2n+1:2n] - inner cacheable property* OR = NMRR[2n+17:2n+16] - outer cacheable property** n TR IR OR* UNCACHED 000 00* BUFFERABLE 001 10 00 00* WRITETHROUGH 010 10 10 10* WRITEBACK 011 10 11 11* reserved 110* WRITEALLOC 111 10 01 01* DEV_SHARED 100 01* DEV_NONSHARED 100 01* DEV_WC 001 10* DEV_CACHED 011 10** Other attributes:** DS0 = PRRR[16] = 0 - device shareable property* DS1 = PRRR[17] = 1 - device shareable property* NS0 = PRRR[18] = 0 - normal shareable property* NS1 = PRRR[19] = 1 - normal shareable property* NOS = PRRR[24+n] = 1 - not outer shareable*/
.equ PRRR, 0xff0a81a8 // 初始化了 PRRR 寄存器的值
.equ NMRR, 0x40e040e0 // 初始化了 NMRR 寄存器的值
对应的,将 PRRR 翻译结果如下:
| 寄存器偏移 | 对应值 | 属性 |
|---|---|---|
| TR0 | 00 | Strongly-ordered |
| TR1 | 10 | Normal memory |
| TR2 | 10 | Normal memory |
| TR3 | 10 | Normal memory |
| TR4 | 01 | Device |
| TR5 | 00 | Strongly-ordered |
| TR6 | 00 | Strongly-ordered |
| TR7 | 10 | Normal memory |
| 寄存器偏移 | 对应值 | 属性 |
|---|---|---|
| NOS0 | 1 | Memory region is Inner Shareable |
| NOS1 | 1 | Memory region is Inner Shareable |
| NOS2 | 1 | Memory region is Inner Shareable |
| NOS3 | 1 | Memory region is Inner Shareable |
| NOS4 | 1 | Memory region is Inner Shareable |
| NOS5 | 1 | Memory region is Inner Shareable |
| NOS6 | 1 | Memory region is Inner Shareable |
| NOS7 | 1 | Memory region is Inner Shareable |
NMRR 翻译结果如下:
| 寄存器偏移 | 对应值 | 属性 |
|---|---|---|
| OR0 | 00 | Region is Non-cacheable |
| OR1 | 00 | Region is Non-cacheable |
| OR2 | 01 | Region is Write-Back, Write-Allocate |
| OR3 | 11 | Region is Write-Back, no Write-Allocate |
| OR4 | 00 | Region is Non-cacheable |
| OR5 | 00 | Region is Non-cacheable |
| OR6 | 00 | Region is Non-cacheable |
| OR7 | 01 | Region is Write-Back, Write-Allocate |
6.2 案例
函数调用关系链:
ioremap+-> arch_ioremap_caller+-> __arm_ioremap_pfn_caller+-> get_mem_type+-> ioremap_page_range+-> kmsan_ioremap_page_range+->__vmap_pages_range_noflush+->vmap_range_noflush+->vmap_p4d_range+->vmap_pud_range+->vmap_pmd_range+->vmap_pte_range+->set_pte_at+->cpu_v7_set_pte_ext
总结来说,在 ARMv7 架构下,调用 ioremap 接口,默认会将地址映射成 MT_DEVICE 属性。
void __iomem *ioremap(resource_size_t res_cookie, size_t size)
{return arch_ioremap_caller(res_cookie, size, MT_DEVICE,__builtin_return_address(0));
}
EXPORT_SYMBOL(ioremap);
在调用 get_mem_type 接口时,会将 MT_DEVICE 转换成架构相关的内存区域属性相关的宏 :
PROT_PTE_DEVICE | L_PTE_MT_DEV_SHARED | L_PTE_SHARED
static struct mem_type mem_types[] __ro_after_init = {[MT_DEVICE] = { /* Strongly ordered / ARMv6 shared device */.prot_pte = PROT_PTE_DEVICE | L_PTE_MT_DEV_SHARED |L_PTE_SHARED,.prot_l1 = PMD_TYPE_TABLE,.prot_sect = PROT_SECT_DEVICE | PMD_SECT_S,.domain = DOMAIN_IO,},............
}const struct mem_type *get_mem_type(unsigned int type)
{return type < ARRAY_SIZE(mem_types) ? &mem_types[type] : NULL;
}
而这其中,和硬件相关的就是 PROT_PTE_DEVICE | L_PTE_MT_DEV_SHARED
#define L_PTE_SHARED (_AT(pteval_t, 1) << 10) /* shared(v6), coherent(xsc3) */#define L_PTE_MT_DEV_SHARED (_AT(pteval_t, 0x04) << 2) /* 0100 */
以 L_PTE_MT_DEV_SHARED 宏为例,介绍如何通过这个宏,去控制内存区域属性的。
- 对应的 TEX[0]、C、B,组成的 index 值为 0x4
- 对应
RRR、NMRR寄存器中,使用的就是- NOS4 + TR4 + OR4 + IR4 的组合、
最终,会调用 set_pte_at 接口,将这些宏设置到 PTE 页表项中。
该函数的三个入参:
- r0: pte 页表项的地址
- r1: Linux 版二级页表项的内容(也就是
PROT_PTE_DEVICE | L_PTE_MT_DEV_SHARED | L_PTE_SHARED这些值的组合) - r2: 通常是 0,除非需要特殊设置
- 输出 r3:硬件页表项(详情见 6.3 章节)
ENTRY(cpu_v7_set_pte_ext)
#ifdef CONFIG_MMUstr r1, [r0] @ linux version //把 r1(linux 的 PTE)存入 r0 地址bic r3, r1, #0x000003f0 //先清除 r1 的 bit[9:4](通常为 memory type / cache属性)bic r3, r3, #PTE_TYPE_MASK //然后再清除最低 2 位(bit[1:0],即页表项类型 Small Page / Section)orr r3, r3, r2 //将扩展属性(ext)合并进 r3orr r3, r3, #PTE_EXT_AP0 | 2 //设置 AP0 位(Access permission)和最低两位为 0b10,表示 Small Pagetst r1, #1 << 4 //如果原始 PTE 的 bit4 被置位,则设置硬件页表项的 TEX=1orrne r3, r3, #PTE_EXT_TEX(1)eor r1, r1, #L_PTE_DIRTYtst r1, #L_PTE_RDONLY | L_PTE_DIRTYorrne r3, r3, #PTE_EXT_APX //根据页表中的只读和脏页标志,设置 APX(Access Permission Extension)位tst r1, #L_PTE_USERorrne r3, r3, #PTE_EXT_AP1 //如果页表设置了 user-mode 访问权限,设置 AP1(即允许用户空间访问)tst r1, #L_PTE_XNorrne r3, r3, #PTE_EXT_XN //设置执行禁止位(XN)tst r1, #L_PTE_YOUNGtstne r1, #L_PTE_VALIDeorne r1, r1, #L_PTE_NONEtstne r1, #L_PTE_NONEmoveq r3, #0 //这段逻辑是做 PTE 的“有效性”判断:如果不是 Young 或 Valid,或者被标记为 None(无效项),则把 r3 清零(页表项无效)ARM( str r3, [r0, #2048]! ) //真正的“硬件页表项”是写在 r0 + 2048 字节偏移处!THUMB( add r0, r0, #2048 )THUMB( str r3, [r0] )ALT_SMP(W(nop))ALT_UP (mcr p15, 0, r0, c7, c10, 1) @ flush_pte
#endifbx lr
ENDPROC(cpu_v7_set_pte_ext)
6.3 硬件页表项和软件页表项
在 ARM 架构下,尤其是 Linux 运行于 ARMv6/v7 等 MMU 支持的平台时,页表(Page Table)是内存管理的核心组件。为了兼顾内核的抽象管理与硬件 MMU 的访问需求,Linux 使用了“双版本页表”的设计思路,即:
- 软件版本(Software Version)
- 硬件版本(Hardware Version)
这两者虽共享数据结构和逻辑关联,但服务于不同的对象和目的,理解它们的区别对于调试页表异常、实现页表扩展、或阅读内核代码都至关重要。
软件版本页表(Software Version)
软件版本是 Linux 内核自己维护和使用的页表项,它主要用于:
- 内核自身管理的权限与状态位(如 Dirty、Accessed、Writeback)
- Linux 的抽象内存属性(如 L_PTE_DIRTY, L_PTE_YOUNG, L_PTE_RDONLY 等)
- 与用户空间接口(如 mprotect, mmap)之间的语义协同
这些软件位通常嵌入在标准页表项结构中(如 pteval_t),但并不一定直接被 ARM MMU 硬件识别。在 ARM Linux 中,这些位通过宏定义编码进 PTE 中,仅用于 Linux 内核逻辑判断,硬件则会忽略它们。
软件页表项位通常保存在:
- pte_t 类型的结构体中
- 页表内存中的 [r0] 位置(见 cpu_v7_set_pte_ext 中第一条 str r1, [r0])
硬件版本页表(Hardware Version)
硬件版本是写入到 ARM MMU 实际访问的页表内存地址 中的内容。它必须符合 ARM 架构定义的格式,包含如下内容:
- 页表项类型(small page, section, supersection 等)
- 权限位(AP[2:0], APX)
- 缓存控制位(TEX[2:0], C, B)
- 共享属性(S, nG 等)
- 执行权限(XN)
其实就是我们上面所讲到的一些 ARM 寄存器相关的知识
在执行页表设置时,Linux 会将软件版本的页表项翻译成硬件格式并写入对应物理地址供 MMU 使用。
硬件页表项最终保存在:
- 页表物理页中,通常偏移 +2048 字节
- 通过 cpu_v7_set_pte_ext 函数中 str r3, [r0, #2048]! 写入
arch\arm\include\asm\pgtable-2level.h 中的宏,对于硬件版本和软件版本有很好的体现:
/** "Linux" PTE definitions.** We keep two sets of PTEs - the hardware and the linux version.* This allows greater flexibility in the way we map the Linux bits* onto the hardware tables, and allows us to have YOUNG and DIRTY* bits.** The PTE table pointer refers to the hardware entries; the "Linux"* entries are stored 1024 bytes below.*/
#define L_PTE_VALID (_AT(pteval_t, 1) << 0) /* Valid */
#define L_PTE_PRESENT (_AT(pteval_t, 1) << 0)
#define L_PTE_YOUNG (_AT(pteval_t, 1) << 1)
#define L_PTE_DIRTY (_AT(pteval_t, 1) << 6)
#define L_PTE_RDONLY (_AT(pteval_t, 1) << 7)
#define L_PTE_USER (_AT(pteval_t, 1) << 8)
#define L_PTE_XN (_AT(pteval_t, 1) << 9)
#define L_PTE_SHARED (_AT(pteval_t, 1) << 10) /* shared(v6), coherent(xsc3) */
#define L_PTE_NONE (_AT(pteval_t, 1) << 11)//以下都是硬件版本,上面都讲过
/** These are the memory types, defined to be compatible with* pre-ARMv6 CPUs cacheable and bufferable bits: n/a,n/a,C,B* ARMv6+ without TEX remapping, they are a table index.* ARMv6+ with TEX remapping, they correspond to n/a,TEX(0),C,B** MT type Pre-ARMv6 ARMv6+ type / cacheable status* UNCACHED Uncached Strongly ordered* BUFFERABLE Bufferable Normal memory / non-cacheable* WRITETHROUGH Writethrough Normal memory / write through* WRITEBACK Writeback Normal memory / write back, read alloc* MINICACHE Minicache N/A* WRITEALLOC Writeback Normal memory / write back, write alloc* DEV_SHARED Uncached Device memory (shared)* DEV_NONSHARED Uncached Device memory (non-shared)* DEV_WC Bufferable Normal memory / non-cacheable* DEV_CACHED Writeback Normal memory / write back, read alloc* VECTORS Variable Normal memory / variable** All normal memory mappings have the following properties:* - reads can be repeated with no side effects* - repeated reads return the last value written* - reads can fetch additional locations without side effects* - writes can be repeated (in certain cases) with no side effects* - writes can be merged before accessing the target* - unaligned accesses can be supported** All device mappings have the following properties:* - no access speculation* - no repetition (eg, on return from an exception)* - number, order and size of accesses are maintained* - unaligned accesses are "unpredictable"*/
#define L_PTE_MT_UNCACHED (_AT(pteval_t, 0x00) << 2) /* 0000 */
#define L_PTE_MT_BUFFERABLE (_AT(pteval_t, 0x01) << 2) /* 0001 */
#define L_PTE_MT_WRITETHROUGH (_AT(pteval_t, 0x02) << 2) /* 0010 */
#define L_PTE_MT_WRITEBACK (_AT(pteval_t, 0x03) << 2) /* 0011 */
#define L_PTE_MT_MINICACHE (_AT(pteval_t, 0x06) << 2) /* 0110 (sa1100, xscale) */
#define L_PTE_MT_WRITEALLOC (_AT(pteval_t, 0x07) << 2) /* 0111 */
#define L_PTE_MT_DEV_SHARED (_AT(pteval_t, 0x04) << 2) /* 0100 */
#define L_PTE_MT_DEV_NONSHARED (_AT(pteval_t, 0x0c) << 2) /* 1100 */
#define L_PTE_MT_DEV_WC (_AT(pteval_t, 0x09) << 2) /* 1001 */
#define L_PTE_MT_DEV_CACHED (_AT(pteval_t, 0x0b) << 2) /* 1011 */
#define L_PTE_MT_VECTORS (_AT(pteval_t, 0x0f) << 2) /* 1111 */
#define L_PTE_MT_MASK (_AT(pteval_t, 0x0f) << 2)
为什么需要两个版本?
- 可扩展性:软件页表项可以携带更多信息,如“是否访问过”、“是否脏”等,硬件页表项不一定有足够位支持这些信息
- 兼容性:Linux 在不同架构上运行时,仍可以通过抽象的软件表示层实现统一逻辑
- 性能调优:部分页表标志如 young/old, dirty 可由软件策略控制,而不依赖硬件



:Spring Boot + AI + Vue3 + OSS + DashScope 实现高效语音识别系统(附完整源码))


置信度研究的经典与前沿论文 :温度缩放;语义熵;自一致性;事实与反思;检索增强;黑盒引导;)

对北半球光伏数据进行时间序列预测)

![[硬件]运算放大器对相位噪声的影响与设计提示](http://pic.xiahunao.cn/[硬件]运算放大器对相位噪声的影响与设计提示)

)



)


