二 kafka架构介绍
学习一个系统之前很重要的一点就是先了解这个系统整体的架构,这能够使我们对整个系统有个总体的认识,清楚地知道这个系统有什么能力。这不仅帮助我们学习时快速定位到我们想要的内容,还能避免我们学习过程中在庞大的系统中迷失自己。所以首先我会介绍一下kafka的整体架构,包括这个kafka系统的整体架构,模块组成,模块的功能以及模块之间关系,以及各个模块之间是怎么共同构成这套系统的。kafka官方并不直接提供他们源码的架构图,模块功能和边界,所以这块的内容是我根据kafka各模块的功能,依赖关系自己组织起来的,并且对各模块做了分层方便我们学习。
2.1 kafka架构和模块
kafka4整体由21个模块组成,但是kafka并不像spring那样采用严格的分层架构,模块的划分设计主要还是为了尽可能复用代码并且避免模块直接引入其他不需要的代码,然后很多kafka官方工具和客户端/API的源码也会放在单独的模块中管理。这里我们文章关心的主要kafka broker相关的源码。对于客户端,工具等的代码不会做太多介绍。但是也有必要做一些简单介绍提升我们对于kafka的整体认知,下面简单贴一下kafka4.1的源码,里面就能够清楚地看到我们下面会说地21个模块了。
尽管kafka没有严格地对模块进行分层,这里还是根据各个模块的功能和依赖关系对各个模块进行了归类和分层。以下就是kafka的架构图。
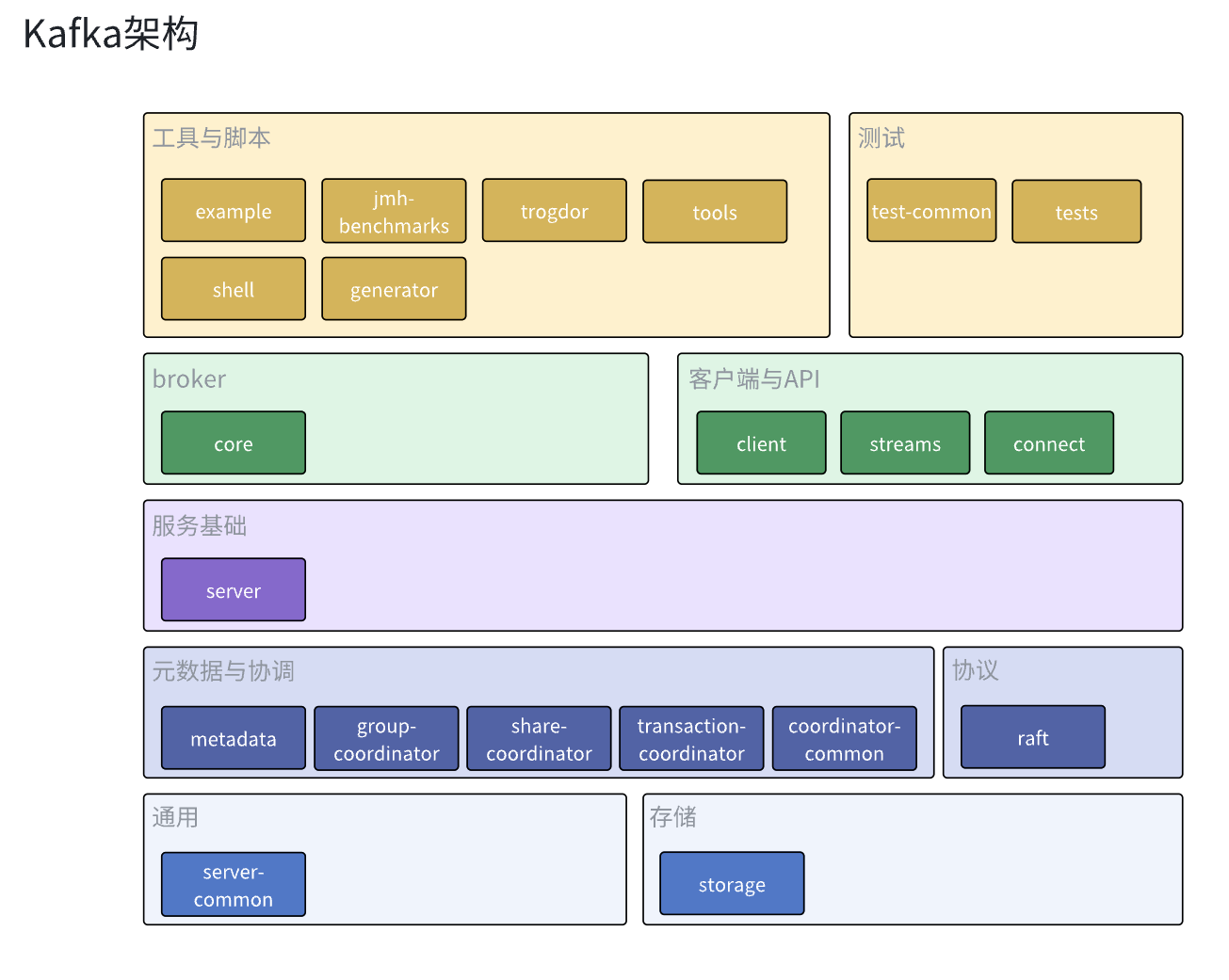
首先最底层的通用模块就是server-common了,这个模块主要负责定义kafka通用抽象,常量和封装公共方法等,kafka服务的其他模块都会依赖这个模块减少代码冗余,除此之外还有负责数据持久化的storage模块。为其他模块提供持久化数据的管理。
然后就是元数据于协调模块,这些模块主要封装了集群内各broker,组内各消费者,事务内各生产者和broker的行为协调逻辑,实现broker分区分配,消费者分区分配和kafka事务的功能,之所以吧元数据和协调放在同一层,是因为metadata模块既封装了元数据相关的管理操作,也实现了集群内broker的协调逻辑,同时其他协调器也会依赖metadata模块的元数据来完成自己的协调功能。如果单独划出元数据层的话,就会错误地忽略掉metadata模块对集群broker协调作用。同时coordinator-common和share-coordinator模块并不是独立的协调器实现,它们只是封装了协调器会用到的公共抽象和通用逻辑,减少代码冗余。与元数据于协调模块同层的就是负责实现kraft逻辑的raft模块了,其实我们也可以认为它也是一个协调模块,负责kraft集群内机器的协调管理。
再往上就是基础服务模块server了,很多可能被他的名字迷惑,觉得是在server里面完成的kafka broker的实现逻辑,其实这是错误的,server主要就是依赖于上面的模块实现了服务通用功能,这些功能并不是Kafka专有的,其他大多数服务都有这些功能,比如服务埋点和监控,配额管理,副本管理等,Kafka把这些逻辑抽离出到server模块上,让core模块能够专心实现Kafka核心的功能。
然后就到了我们的核心模块core了,它依赖其他模块实现了kafka的broker,存放broker的入口程序和核心逻辑,也会调用其他模块完成broker整体的工作。kafka的核心组件acceptor,processor,handler,kafkaApis,requestchannel都是在这里定义和实现的。
然后就是kafka的客户端,工具,脚本和测试模块了,它们都相对比较独立,都是kafka官方提供的方便我们使用,测试kafka的工具。当然kafka也有一些其他的社区维护的工具或者客户端,这里我们就不做太多赘述了。
2.2 模块功能
我们在这个小节会简单介绍一下kafka各个模块,尽管有些模块并不是本文章的的内容,但是还是有必要对他们有个概念,这也能让我们更加有底气地打开kafka源码。
2.2.1 基础层
我们把kafka中提供基础能力的模块划分为基础层,基础层的模块为我们的kafka服务提供通用的抽象和一些常用功能的封装。减少代码冗余性。
server-common模块
server-common 模块为 Kafka 服务端(Broker)相关的多个子系统提供通用的基础设施、工具类和抽象接口。主要就是将多处复用的通用逻辑抽取出来,避免出现代码冗余,提升代码的可维护性。
storage模块
storage模块是Kafka服务端消息持久化存储的核心实现,为Kafka的高吞吐、高可靠消息存储提供底层支撑。它实现了Kafka分区日志的写入、读取、分段、索引、清理、事务、快照等所有与磁盘存储相关的功能,比如管理分区日志(Log)的写入、读取、分段、索引、清理、压缩、删除和消息的物理存储、索引文件、事务索引、快照,支持日志的恢复、截断、校验、异常处理等等。
2.2.2 元数据与协调/协议层
元数据与协调模块负责实现kafka体系内元数据的管理和节点之间的协调逻辑,比如协调消费者组里面的消费者分配某个topic的分区,协调多个broker怎么分配某个topic的分区,协调事务里面的生产者和broker的工作等等。
metadata模块
metadata模块是Kafka服务端集群元数据管理的核心实现,为Kafka的高可用、分布式一致性和动态扩展提供底层支撑。它实现了Kafka集群中所有元数据(如主题、分区、副本、Broker、控制器、ACL、特性等)的存储、更新、分发和管理,以及Controller和Broker的注册和心跳管理,Topic分区分配,迁移等一系列基于元数据的决策逻辑。Metadata模块也是KRaft(Kafka Raft)架构下去中心化元数据管理的基础,提供了KRaft相关元数据的管理,同时它也需要依赖raft模块实现元数据的分布式一致性存储和同步。是Kafka实现高可用和弹性伸缩的关键。
coordinator-common模块
coordinator-common 模块为 Kafka 中所有协调器模块(比如消费组协调器Group Coordinator和事务协调器Transaction Coordinator)提供通用的抽象、工具和基础设施,包括接口、抽象类、工具方法,以及协调器的通用配置、状态管理和持久化等基础能力。它并不直接实现消费组或事务协调的具体逻辑,而是作为消费组协调器Group Coordinator,事务协调器Transaction Coordinator等协调器模块的公共支撑,避免重复实现。
share-coordinator模块
share-coordinator 模块为 Kafka 中的多种协调器(如消费组协调器、事务协调器等)提供共享的实现基础。它在coordinator-common的基础上进一步抽象和复用协调器之间的通用行为或逻辑,比如封装协调器Coordinator之间的通用实现,如状态管理、持久化、协议处理等,提供协调器的抽象基类、接口和工具方法。便于不同类型的协调器共享代码、减少代码冗余。
group-coordinator模块
group-coordinator模块专门实现Kafka消费组协调器的全部功能。它负责管理消费组成员、分区分配、再平衡、消费位移提交等,包括实现管理消费组成员的加入、离开、心跳,实现分区分配、再平衡、消费位移提交与查询,处理消费组相关的协议请求(如JoinGroup、SyncGroup、Heartbeat、OffsetCommit等)等的逻辑,是Kafka高可靠消费和负载均衡的核心。
注意group-coordinator模块的分区分配是指把分区分配给消费者组的消费者,前面metadata模块的分区分配是指把分区分配给不同broker,两边的工作职责不一样,不要弄混。
transaction-coordinator模块
transaction-coordinator模块专门实现Kafka的事务协调器功能。它负责管理生产者的事务生命周期,实现幂等性、事务状态机、事务超时、提交/中止等,实现了管理生产者事务的初始化、提交、终止,维护事务状态机,处理事务超时、恢复,处理事务相关的协议请求(如InitProducerId、AddPartitionsToTxn、EndTransaction等)等逻辑,是Kafka支持Exactly Once语义的关键。
raft模块
raft模块是Kafka实现KRaft(Kafka Raft)协议的核心模块,为Kafka集群提供分布式一致性、高可用和去中心化的元数据管理能力。它实现了Raft分布式一致性协议的全部核心机制,包括Raft协议实现(日志复制、选主(Leader Election)、日志提交、快照、成员变更等),分布式一致性保障,高可用与容错,动态成员管理等等。除此之外raft模块也为metadata、controller等模块提供一致性存储和同步能力,raft是KRaft架构下Kafka元数据存储和同步的基础。替代了原有的ZooKeeper方案
2.2.3 基础服务模块
服务基础层的模块负责提供kafka服务运行时需要的一些基础能力,比如数据埋点和监控,权限控制,限流,这些能力虽然不是kafka的核心实现逻辑但是也是kafka运行必不可少的一部分。
server模块
server模块可以理解为core模块的基础设施库,server模块为Kafka Broker的主服务实现提供了大量的基础能力和子系统实现,包括副本管理、分区分配、指标采集、配额管理、事务支持、延迟操作、日志控制等,这些能力一般是大多数平台都具有的能力而不仅仅是kafka特有的,所以通过将这些通用能力抽离到server模块,主服务实现可以更专注于流程控制和集成,提升了代码的解耦性和可维护性。
2.2.4 broker实现层
这个就是kafka broker的核心逻辑的地方了
core模块
core模块是Kafka的核心实现模块,主要负责Kafka服务端的启动、运行、关闭等主流程控制。它包含了Kafka Broker的主入口、定义和实现了Server,Processor,RequestChannel,KafkaApis等实现Kafka功能的核心组件,实现了服务生命周期管理(启动、关闭、异常处理等)、加载和解析服务端配置,请求的实际处理,服务指标监控等的逻辑。
2.2.5 客户端与API
这些严格意义不算是kafka服务里面的代码,只是官方提供一些对接kafka服务的客户端或者简化kafka使用流程的依赖库。除了官方提供的外我们也可以在社区里面找到很多好用的kafka客户端或者调用框架。
clients模块
clients模块提供Kafka的Java客户端实现,包括生产者,消费者,管理客户端等,供外部应用集成以便于与kafka交互。比如业务服务在引入clients模块后可以很方便地使用KafkaProducer给topic发送消息,使用KafkaConsumer接受并处理感兴趣的topic的消息,使用AdminClient对kafka broker的主题、分区、ACL等进行管理,比如创建或删除topic,获取集群消息等等。
streams模块
streams模块就是对Kafka Streams的实现,Kafka Streams是Apache Kafka官方提供的一个轻量级、分布式、高容错的流处理库,我们可以在Java应用中引入streams模块后很方便地实现对Kafka数据流的实时处理、分析和计算。而且Kafka Streams也支持支持窗口、聚合、连接等流式操作。使用Kafka Streams我们能够很方便地无缝对接Kafka数据进行实时的统计,监控,ETL,数据清洗,实时告警,风控等操作。
connect模块
connect模块实现了Kafka Connect框架,Kafka Connect是Apache Kafka官方提供的一个分布式、可扩展、可管理的数据集成框架。它的主要目标是简化Kafka与外部系统(如数据库、文件系统、云存储、搜索引擎等)之间的数据同步和批量数据流转,让用户无需编写复杂的代码就能实现数据的高效导入和导出。主要提供以下支持。
数据源(Source)到Kafka:自动化地将外部系统(如MySQL、PostgreSQL、Oracle、文件、云存储等)中的数据批量导入Kafka Topic。
Kafka到数据汇(Sink):自动化地将Kafka Topic中的数据批量导出到外部系统(如Elasticsearch、HDFS、S3、数据库等)
数据转换与处理:支持在数据流转过程中进行格式转换、字段过滤、数据清洗等操作(通过Transform机制)。
分布式与容错:支持分布式部署、自动负载均衡、任务容错、状态管理、动态扩缩容等
2.2.6 工具与脚本
这些是kafka官方提供的一些工具,用于帮助管理kafka或者做一些数据诊断,性能校验,又或者是支持kafka提供的脚本等,这些工具有些是kafka内部开发人员会用的,有些是使用kafka运维或者开发人员会用到的,使用这些工具和脚本可以大大提高工作效率。
tools模块
tools模块是Kafka官方提供的命令行工具和测试工具的实现模块,提供了Kafka的命令行工具、运维脚本、诊断工具等,主要用于Kafka集群的管理、运维、性能测试、功能验证等,比如创建topic,管理ACL,测试生产者性能等,Kafka 在发行包的 bin 目录下,提供了大量以 kafka-xxx.sh 命名的脚本,这些脚本本质上就是通过调用 tools 模块来实现的功能。
shell模块
shell模块是Kafka官方实现的一个交互式命令行工具框架,用于以“类Unix Shell”的方式管理和操作Kafka的元数据、集群状态等。本质上就是一个Java实现的交互式命令行工具,根据输入的命令通过Kafka的API与Broker或元数据服务通信,实现元数据的浏览、查询、管理等功能。它提供了类似于文件系统shell(如bash、zsh)的交互体验,操作对象是Kafka的元数据结构,支持常见的shell命令(如ls、cd、pwd、cat、tree、find、help、exit等),但这些命令操作的是Kafka的元数据树,而不是文件系统。
generator模块
generator模块是Kafka源码中的自动化代码生成工具,主要用于根据协议、元数据、消息结构等描述文件,自动生成Kafka内部所需的Java类、协议实现、序列化/反序列化代码、JSON转换器等。比如根据kafka协议针对每种类型/版本的请求的字段生成对应的java类代码,它是开发和构建阶段的辅助工具,通常在Kafka源码编译、协议变更、自动化构建等场景下被调用,是Kafka开发和维护中提升效率的重要工具。
examples模块
examples模块为Kafka用户和开发者提供了丰富的示例代码,帮助大家快速上手Kafka的Producer、Consumer、Streams等API的使用方法。
jmh-benchmarks模块
jmh-benchmarks 模块是 Kafka 项目中的性能基准测试模块,基于 JMH(Java Microbenchmark Harness)框架实现。它用于对 Kafka 的关键组件、算法、数据结构等进行微基准性能测试,帮助开发者评估和优化系统的性能瓶颈。比如提供 Kafka 相关代码的微基准测试用例,评估不同实现、参数、配置下的性能表现。jmh-benchmarks 模块仅用于开发和性能调优阶段,不参与生产环境部署和主流程逻辑。
JMH(Java Microbenchmark Harness)是 OpenJDK 官方的 Java 微基准测试框架,专门用于准确测量 Java 代码的性能。它能有效避免JVM优化带来的测试偏差,支持多线程、参数化、基准分组等高级特性。
trogdor模块
trogdor 是 Kafka 官方自带的集群压力测试与故障注入工具模块。它的主要目标是为 Kafka 集群提供自动化的性能压测、稳定性测试和故障模拟能力,帮助开发者和运维人员在真实或准生产环境下评估 Kafka 的性能极限和容错能力。trogdor 采用“协调器-代理(Coordinator-Agent)”架构,协调器负责任务的全局调度和监控,代理分布在各个节点上,负责实际执行测试任务。任务类型和参数高度可配置,支持自定义扩展。
2.2.7 测试
这部分主要用于kafka代码测试相关
test-common模块
test-common模块的主要作用是为Kafka的各种测试用例提供通用的测试工具类、基类、mock实现、测试辅助方法等。避免在每个测试工程/目录中重复实现通用的测试逻辑,提高测试代码的复用性和维护性。
tests模块
tests严格来说不是一个模块,而是一个目录,主要用于存放Kafka项目的各种测试用例、测试工具、测试脚本(python脚本),测试数据和配置,比如提供Kafka集群的自动化部署、启动、关闭、清理等辅助脚本,测试数据生成、对比、校验等工具,各种测试所需的配置文件、数据文件、模拟环境等等。它是Kafka保证高质量、高可靠性的重要基础设施。













)
与定时爬取网站→邮件通知(价格监控原型))




