基于 Apache Doris 构建数据仓库的方案和具体例子。Doris 以其高性能、易用性和实时能力,成为构建现代化数据仓库(特别是 OLAP 场景)的优秀选择。
一、为什么选择 Doris 构建数据仓库?
Doris(原名 Palo)是一个基于 MPP 架构的高性能、实分析型数据库,非常适合作为数据仓库(DW)和即席查询(Ad-hoc Query)的解决方案。
核心优势:
极高性能:
列式存储、向量化执行引擎、预聚合(物化视图)。
支持高并发点查询,响应延迟可低至毫秒级。
简单易用:
兼容 MySQL 协议,使用标准 SQL,学习和使用成本极低。
无需依赖 Hadoop 生态(HDFS/Hive/Spark)的繁重组件,架构简单,运维方便。
实时分析:
支持实时数据导入(如通过 Routine Load 消费 Kafka 数据),从数据产生到可查询可达秒级延迟。
统一化:
一个系统同时支持离线批量数据和实时流式数据的导入与分析,避免了 Lambda 架构的复杂性。
联邦查询:
支持通过 ODBC/MySQL 外表功能查询其他数据源(如 MySQL, PostgreSQL, Elasticsearch, Hive 等),方便地整合现有数据。
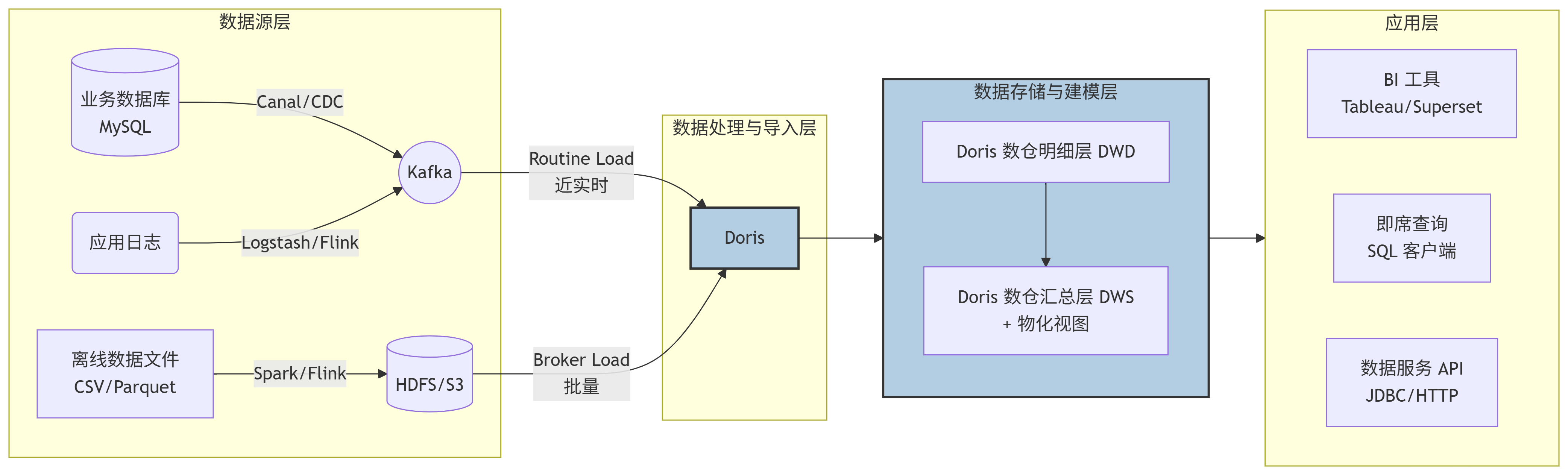
二、典型数据仓库架构方案(基于 Doris)
二、典型数据仓库架构方案(基于 Doris)(文字描述版)
整个数据流向可以清晰地分为四个层级,数据从左向右流动:
数据源层 (Data Sources) -> 数据处理与导入层 (Data Ingestion) -> 数据存储与建模层 (Data Storage & Modeling) -> 数据应用层 (Data Application)
1. 数据源层 (Data Sources)
业务数据库 (MySQL/PostgreSQL等): 通过 Change Data Capture (CDC) 工具(如 Canal, Debezium)实时捕获数据变更,并将变更日志推送到消息队列。
应用日志/点击流: 通过日志收集工具(如 Logstash, Flume)或实时计算框架(如 Flink)进行初步处理后,写入消息队列。
离线数据文件: 来自其他数据处理系统(如 Spark, Hive 作业)的批量数据文件,通常以列式格式(如 Parquet, ORC)存放在分布式文件系统(如 HDFS)或对象存储(如 S3)上。
2. 数据处理与导入层 (Data Ingestion)
这是 Doris 与数据源对接的关键环节,它提供了多种灵活的导入方式:
对于实时数据流 (Kafka): 使用 Routine Load 功能。Doris 可以作为一个消费者,持续地从 Kafka 主题中拉取数据,并近乎实时地(秒级延迟)导入到内部表中。
对于批量数据文件 (HDFS/S3): 使用 Broker Load 功能。Doris 通过部署的 Broker 节点,并行地读取远端存储上的大量数据文件,并高效地导入到内部表中。也可以使用 Spark-Doris-Connector 从 Spark 直接写入。
3. 数据存储与建模层 (Data Storage & Modeling in Doris)
这是 Doris 的核心,数据在这里被有序地组织和管理。
采用经典的数仓分层思想:
明细层 (DWD): 通常创建
Duplicate明细表,存储最细粒度的原始数据,保留所有细节,用于全明细查询和回溯。汇总层 (DWS/ADS): 通常创建
Aggregate或Unique表。更重要的是,可以利用 物化视图 (Materialized View) 在这一层对常用维度和指标进行预聚合,极大提升后续的查询性能。
数据按照分区和分桶策略进行分布式存储,保证查询和导入的效率。
4. 数据应用层 (Data Application)
处理好的数据最终服务于上层应用:
BI 工具 (Tableau, Superset, FineBI): 这些工具通过标准的 MySQL 协议 直接连接到 Doris,执行查询并生成报表和仪表盘。
即席查询 (Ad-hoc Query): 数据分析师和开发人员可以通过任何兼容 MySQL 的客户端(如 MySQL CLI, DBeaver, HeidiSQL)直接编写 SQL 进行探索式分析。
数据服务 API: 后端应用程序可以通过 JDBC 或 HTTP 接口(如 Doris 的 RESTful API)来获取数据,为业务系统提供数据支持。
架构图(Mermaid 代码块)
为了更直观的理解,以下是上述架构的 Mermaid 流程图代码。您可以在支持 Mermaid 的编辑器(如 Typora、Obsidian、GitHub 等)中直接渲染查看:
架构图(纯文本示意图)
如果 Mermaid 仍然无法渲染,请参考以下纯文本描述的数据流图:
text
+------------------+ +-------------------------+ +-----------------------+ | 数据源层 | | 数据处理与导入层 | | 数据存储与建模层 | | | | | | | | MySQL -> CDC -> | ---> | Kafka -> Routine Load ->| ---> | Doris DWD层 | | 日志 -> Flume ->| ---> | | | | | HDFS -> Spark ->| ---> | HDFS -> Broker Load --->| ---> | Doris DWS层 | | | | | | (物化视图加速) | +------------------+ +-------------------------+ +-----------------------+|v +------------------+ +---------------------------------+ +-----------------------+ | 数据应用层 | <--- | MySQL Protocol | <--- | | | | | JDBC / HTTP | | | | BI 工具 | <--- | | | | | 即席查询 | <--- | | | | | 数据API | <--- | | | | +------------------+ +---------------------------------+ +-----------------------+
各层说明:
数据源 (Data Sources):
业务数据库: 如 MySQL、PostgreSQL,通过 CDC(Change Data Capture)工具(如 Canal, Debezium)将增量数据实时送入 Kafka。
应用日志: 通过 Logstash、Flume 或 Flink 处理后写入 Kafka。
离线文件: 来自其他系统(如 Spark/ Hive 作业)的 CSV、Parquet 文件,通常存放在 HDFS 或 S3 上。
数据处理与导入 (Data Ingestion):
实时导入: 使用 Doris 的 Routine Load 功能,持续消费 Kafka 中的消息,实现实时数据接入。
批量导入: 使用 Broker Load 或 Spark-Doris-Connector 将 HDFS/S3 上的大批量数据高效导入 Doris。
数据存储与建模 (Data Storage & Modeling in Doris):
这是核心。Doris 内部采用 星型模型 或 雪花模型 来组织数据。
明细层 (DWD): 创建
Duplicate明细表,存储最细粒度的原始数据,用于全明细查询。汇总层 (DWS/ADS): 创建
Aggregate或Unique表,或者利用物化视图(Materialized View)预聚合常用维度指标,极大提升查询性能。
数据应用 (Data Application):
BI 工具: 通过 MySQL 协议直接连接 Doris,进行可视化分析(Tableau, Superset, FineBI)。
即席查询: 数据分析师使用标准 SQL 客户端直接查询 Doris。
数据服务 API: 应用程序通过 JDBC 或 HTTP 接口(如 RESTful API)从 Doris 获取数据。
三、具体实现例子:电商数据仓库
我们以一个经典的电商场景为例,分析用户行为和订单数据。
步骤 1:创建数据库与表
首先,在 Doris 中创建数据库。
sql
CREATE DATABASE IF NOT EXISTS ecommerce_dw; USE ecommerce_dw;
1. 创建明细表 (DWD 层):dwd_user_behavior
存储用户的所有行为数据(点击、加购、购买等)。
sql
CREATE TABLE IF NOT EXISTS dwd_user_behavior (`user_id` INT COMMENT '用户ID',`item_id` INT COMMENT '商品ID',`category_id` INT COMMENT '商品类目ID',`behavior_type` VARCHAR(20) COMMENT '行为类型: pv, buy, cart, fav',`timestamp` BIGINT COMMENT '行为发生的时间戳',`dt` DATE COMMENT '基于timestamp生成的日期, 用于分区'
) ENGINE=OLAP
DUPLICATE KEY(`user_id`, `item_id`, `timestamp`) -- 明细数据,用Duplicate模型
PARTITION BY RANGE(`dt`) () -- 按天分区
DISTRIBUTED BY HASH(`user_id`) BUCKETS 10
PROPERTIES ("replication_num" = "3"
);2. 创建汇总表 (DWS 层):dws_user_behavior_daily
按用户和天预聚合常用指标。
sql
CREATE TABLE IF NOT EXISTS dws_user_behavior_daily (`user_id` INT COMMENT '用户ID',`dt` DATE COMMENT '日期',`pv_count` BIGINT SUM DEFAULT "0" COMMENT '当日总点击数',`buy_count` BIGINT SUM DEFAULT "0" COMMENT '当日总购买次数',`cart_count` BIGINT SUM DEFAULT "0" COMMENT '当日加购次数',`fav_count` BIGINT SUM DEFAULT "0" COMMENT '当日收藏次数',`last_visit_time` DATETIME REPLACE COMMENT '最后访问时间'
) ENGINE=OLAP
AGGREGATE KEY(`user_id`, `dt`) -- 汇总数据,用Aggregate模型
DISTRIBUTED BY HASH(`user_id`) BUCKETS 10
PROPERTIES ("replication_num" = "3"
);注意:也可以使用物化视图(Materialized View)在明细表上自动维护汇总数据,无需手动创建和更新此表。
步骤 2:数据导入
实时导入用户行为数据(从 Kafka):
假设用户行为日志已经写入 Kafka 的 user_behavior_topic。
sql
CREATE ROUTINE LOAD ecommerce_dw.user_behavior_kafka_load ON dwd_user_behavior
COLUMNS(user_id, item_id, category_id, behavior_type, timestamp, dt=from_unixtime(timestamp, '%Y%m%d')),
ROUTINE LOAD PROPERTIES
("desired_concurrent_number" = "5","max_error_number" = "1000"
)
FROM KAFKA
("kafka_broker_list" = "kafka-host01:9092,kafka-host02:9092","kafka_topic" = "user_behavior_topic","property.group.id" = "doris-dw","property.security.protocol" = "SASL_PLAINTEXT",-- ... 其他Kafka认证配置
);批量导入历史订单数据(从 HDFS):
sql
LOAD LABEL ecommerce_dw.hdfs_order_load_20231027
(DATA INFILE("hdfs://namenode:8020/path/to/orders/*.parquet")INTO TABLE `dwd_orders` -- 假设有订单明细表FORMAT AS "parquet"
)
WITH BROKER "broker_name"
("username" = "hdfs_user","password" = "hdfs_password"
)
PROPERTIES
("timeout" = "3600"
);步骤 3:数据建模与查询
1. 明细查询 (DWD)
查询某个用户的所有原始行为记录。
sql
SELECT * FROM dwd_user_behavior WHERE user_id = 123456 AND dt = '2023-10-27' ORDER BY timestamp DESC LIMIT 100;
2. 汇总分析 (DWS)
基于汇总表,查询每日最活跃的 Top 10 用户,性能极快。
sql
SELECT user_id, dt, pv_count FROM dws_user_behavior_daily ORDER BY pv_count DESC LIMIT 10;
3. 复杂分析
即使没有预聚合,直接查询明细表,Doris 也能提供不错的性能。例如,分析购买转化率(漏斗分析):
sql
SELECTdt,COUNT(DISTINCT user_id) AS total_uv,COUNT(DISTINCT IF(behavior_type = 'buy', user_id, NULL)) AS buy_uv,COUNT(DISTINCT IF(behavior_type = 'buy', user_id, NULL)) / COUNT(DISTINCT user_id) AS conversion_rate FROM dwd_user_behavior WHERE dt >= '2023-10-20' GROUP BY dt ORDER BY dt;
步骤 4:使用物化视图(Materialized View)加速
为 dwd_user_behavior 表创建一个按 category_id 预聚合的物化视图,加速类目分析查询。
sql
-- 创建物化视图 CREATE MATERIALIZED VIEW category_behavior_mv AS SELECTcategory_id,dt,COUNT(*) AS pv,COUNT(DISTINCT user_id) AS uv,SUM(IF(behavior_type = 'buy', 1, 0)) AS buy_count FROM dwd_user_behavior GROUP BY category_id, dt;-- 查询会自动路由到物化视图,速度极快 SELECT category_id, SUM(pv) AS total_pv FROM dwd_user_behavior WHERE dt BETWEEN '2023-10-01' AND '2023-10-31' GROUP BY category_id ORDER BY total_pv DESC LIMIT 10;
Doris 的查询优化器会自动判断是否可以使用物化视图来加速查询,对用户透明。
四、最佳实践与建议
数据模型设计:
谨慎选择分区键(
PARTITION BY)和分桶键(DISTRIBUTED BY)。分区用于管理,分桶用于并行。小表(如维度表)可使用
Unique模型,大事实表根据场景选择Duplicate或Aggregate模型。
物化视图策略:
为最常用且耗时的分组聚合查询创建物化视图。
物化视图是空间换时间的策略,不宜过多,优先考虑公共和高频查询。
资源与监控:
合理设置
replication_num(通常 3 副本保证高可用)。监控 FE/BE 节点的 CPU、内存、磁盘使用情况,以及导入任务的延迟和错误率。
数据生命周期管理:
使用
PARTITION功能,结合动态分区特性,自动创建新分区和删除旧分区(ALTER TABLE ... SET ("dynamic_partition.enable" = "true")),实现数据滚动更新。
总结
Apache Doris 提供了一个 简单、高性能、实时统一 的数据仓库解决方案。通过将实时流和批量数据高效导入,并利用其内置的聚合模型和物化视图等特性,可以轻松构建从明细层到汇总层的数据体系,支撑企业级的高并发即席查询和复杂的多维分析需求,极大地简化了传统大数据架构的复杂度。








)


)




-)

)
