一、什么是 HTTP 协议
上节说到,应用层的协议需要约定通信的内容和数据格式。我们可以自定义应用层协议,也可以基于现成的应用层协议进行开发。协议的种类很多,最常见的之一就是 HTTP,广泛用于网站和手机 App。准确来说,现在大多使用的是 HTTPS 协议,它在 HTTP 协议上加了安全层。Ps:HTTP 本身不限定数据格式,具体数据格式由应用决定,并通过协议中的 Content-Type 告知。
之前学习的 TCP、UDP、IP、以太网……都是基于二进制格式的协议(格式按照 xxx 个字节来安排)。HTTP 是“超文本传输协议”,是基于文本格式的协议,但文本中包含了视频、音频、图片、链接等更复杂的内容。HTTP 属于应用层协议,传输层依赖 TCP 进行实现(2.0 及其之前的版本;由于 TCP 的传输效率限制,最新版本 3.0 的传输层依赖 UDP 实现,在应用层实现传输的可靠性,但目前不稳定。HTTP 1.1 是最常用的版本)。
HTTP 是典型的一问一答模型,即客户端发起请求,服务器返回响应。在 HTTP 交互过程中,我们需要关心请求、响应的格式。
二、抓包软件
为了观察 HTTP 协议格式,我们需要用到抓包软件。它本质上是一个代理程序,如果是代替客户端做事,就是正向代理;如果是代替服务器做事,就是反向代理。安装了抓包软件后,它就能监听网卡上通过的数据,获取客户端-服务器之间传输数据的详情(客户端-服务器之间有了一个中间站,在服务器之前获取客户端的请求,在客户端之前获取服务器的响应)。
学校里边一般用 wireshark 进行教学,它功能强大,TCP、UDP、IP、以太网数据帧都能抓包,但使用复杂。为了快速上手,我们使用专门的 HTTP/HTTPS 的抓包软件 Fiddler。在工作中,如果想抓包 TCP 等,更常用的是 tcpdump。
下载程序,推荐使用 bing/google 搜索官网。国内搜索引擎容易搜到广告等一些杂乱信息。
Web Debugging Proxy and Troubleshooting Tools | Fiddler
新版要收钱,我们选经典版:

打开安装包,一路 next 即可。Fiddler 默认不开启 HTTPS,我们需要手动开启:
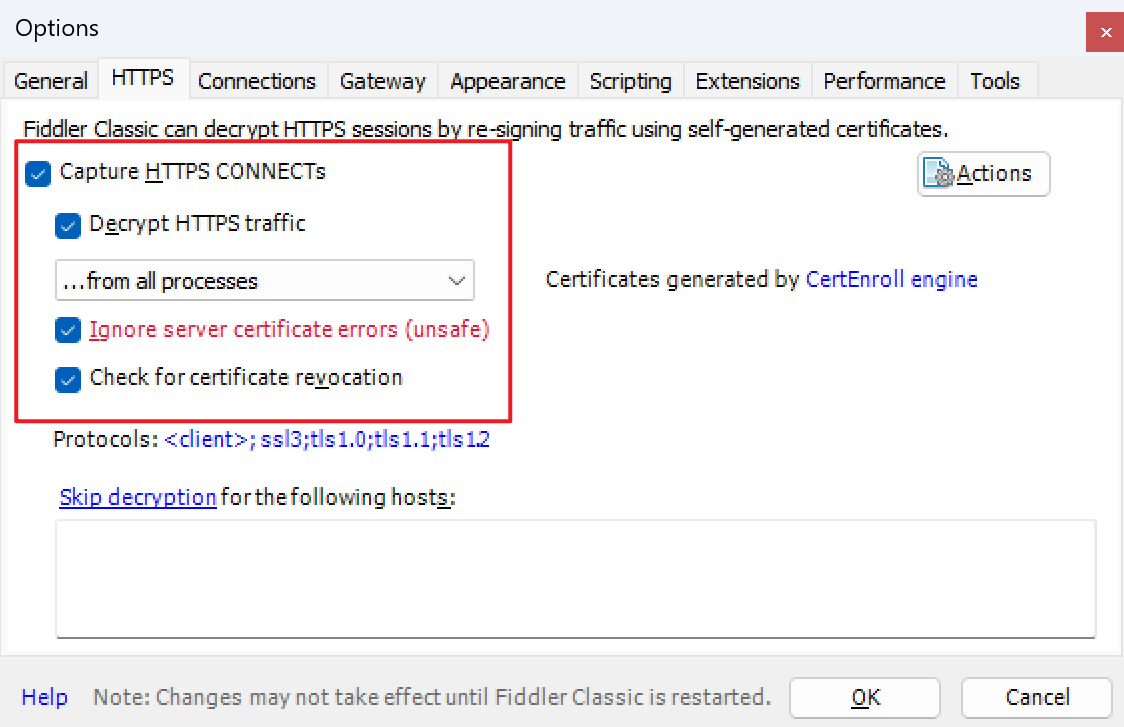
Tools》Options》HTTPS:首次勾选,会弹出是否信任安全证书,选信任。
左侧是 HTTP/HTTPS 请求/响应列表,看到有很多,即使我们没有点击任何东西,后台也会做一些事情。如果什么都没有,看看电脑上是否有其他代理程序。右上是请求详情,右下是响应详情。Raw 是 HTTP/HTTPS 的原始数据。
接下来我们要从列表中找到我们主动触发的请求响应,以在浏览器中搜索 sogou.com 为例:
首先清空列表,删除之前的记录:Crl+x 。然后观察域名,找到 sogou.com。再观察颜色:
- 蓝色:该请求/响应是 HTML 的内容。
- 紫色:该请求/响应是 CSS 的内容。
- 绿色:该请求/响应是 JavaScript 的内容。
网页由三个关键部分组成:
- HTML:网页的结构。(有什么组件)
- CSS:网页的样式。(组件的颜色、大小、位置等)
- JavaScript:网页的交互。(用户点击网页上的组件,网页给出动态反应)
因此,浏览器和服务器之间的 HTTP 交互是一组,分别获取 HTML、CSS、JavaScript、图片音频视频等依赖资源。
如果仅仅是点网页的刷新,很可能没有 CSS、JS 的 HTTP 交互。因为浏览器有一个缓存功能,首次访问网站,浏览器会将 CSS、JS、依赖资源保存到硬盘上;后续再次访问,只从服务器获取 HTML。这样优化的原因是,计算机访问存储设备的速度:cpu/寄存器 > 内存 > 硬盘 > 网络(当是万兆网卡时,网络大概率比硬盘快,但家用设备都达不到万兆)。而访问搜狗主页需要将所有内容加载出来才能正确显示。因此,为了观察到完整的一组 HTTP,使用 “全量获取数据”,Crl+F5 或 Crl+刷新。
三、HTTP 报文格式
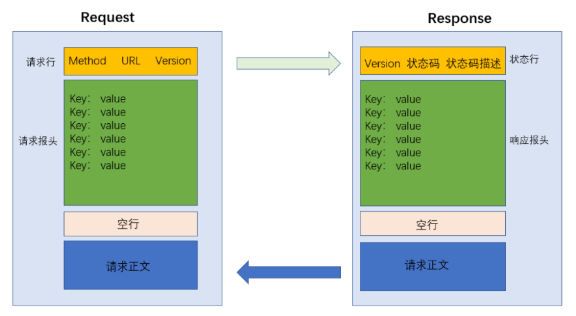
1、整体格式
可以看到,HTTP 的请求/响应的原始数据是行文本,使用记事本打开:
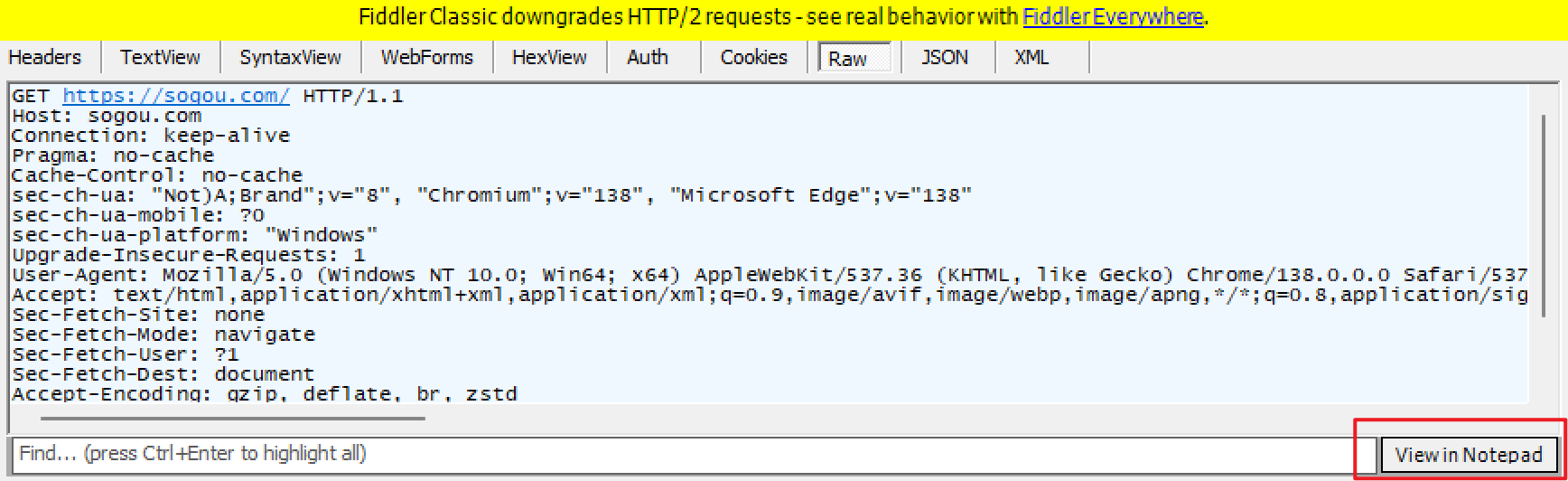
请求:
- 首行(第一行)
- 请求头(header,从第二行开始往后若干行)
- 空行(请求头的结束标志)
- 请求正文(body,请求中可以有,可以没有)
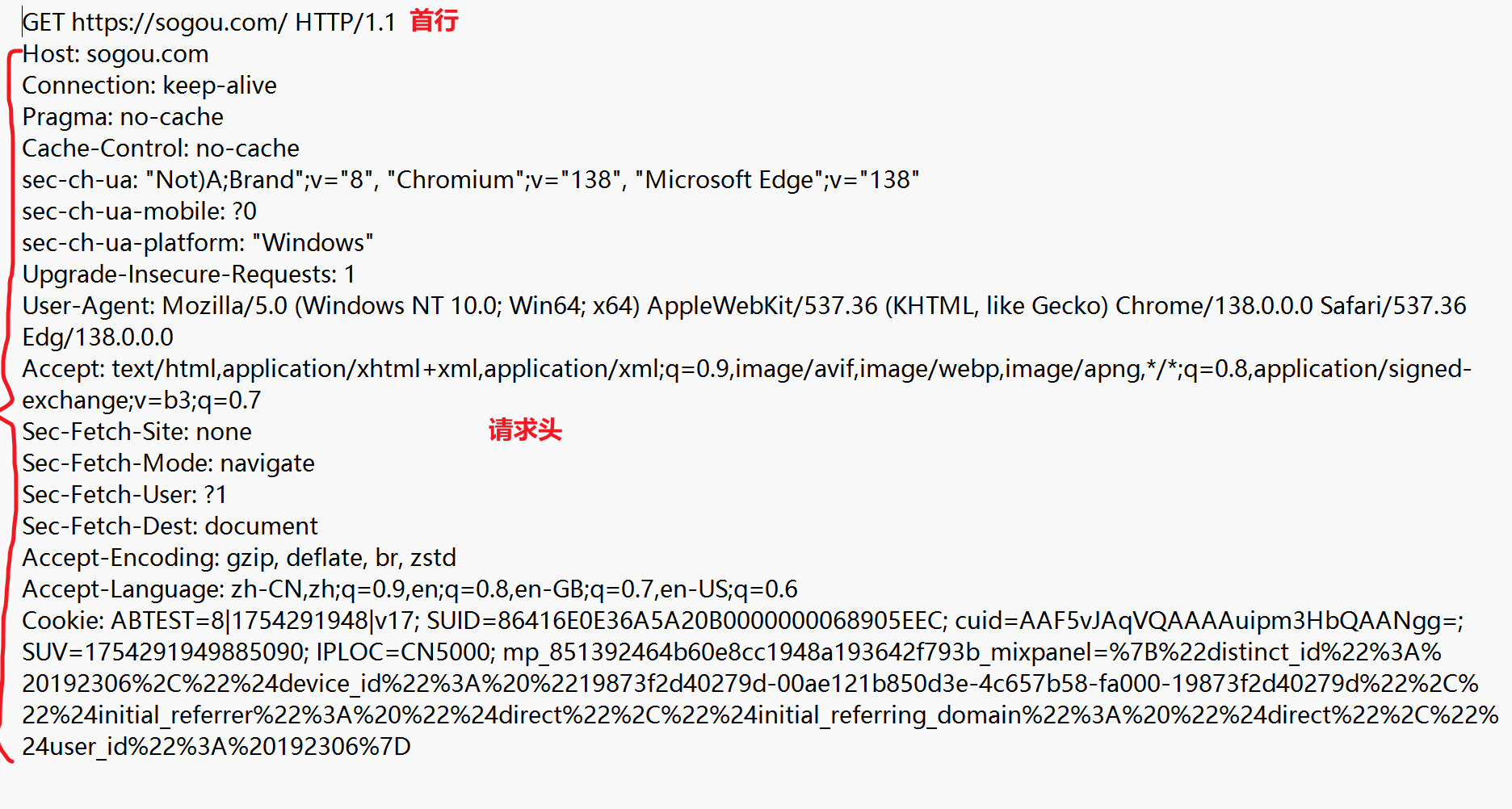
响应:
HTTP 响应可能被压缩,因此文本行中会有一些乱码:Content-Encoding 显示以 gzip 算法压缩。
由于网络通信中最贵的硬件资源是带宽,而 CPU 很便宜,因此就把原始文本压缩成二进制,减少网络传输的内容,数据到了对端再通过 CPU 解压。点击这个部分进行解压:


- 首行
- 响应头
- 空行
- 响应正文(大多数情况有。该正文包含了 HTML 的内容)
之前学的报文格式不要求记忆,用的时候查询一下。但是 HTTP 格式需要重点理解记忆,我们在以后工作中经常需要调试。起手式就是抓包,找出 bug 是前端还是后端的问题:如果是请求错了,就是前端的问题。如果是响应错了,就是后端的问题。如果请求、响应都没错,显示错了,也是前端的问题。
2、首行
请求:
![]()
2.1、URL(请求)
唯一资源定位符(Uniform Resource Locator,URL)描述了网络上某个资源的具体位置。
格式:

- 登录信息:已淘汰,现已没有网站用这种认证方式。
- 服务器地址:服务器 IP 地址,域名。
- 带层次的文件路径:一个机器上的一个程序可能管理很多资源。真实的文件,或者虚拟的动态生成的资源(根据请求计算的响应)。
搜狗的主页是典型的静态资源,有一个固定的 “主页.html” 文件:

搜狗的搜索页是典型的动态资源,根据用户的输入得到不同的结果:
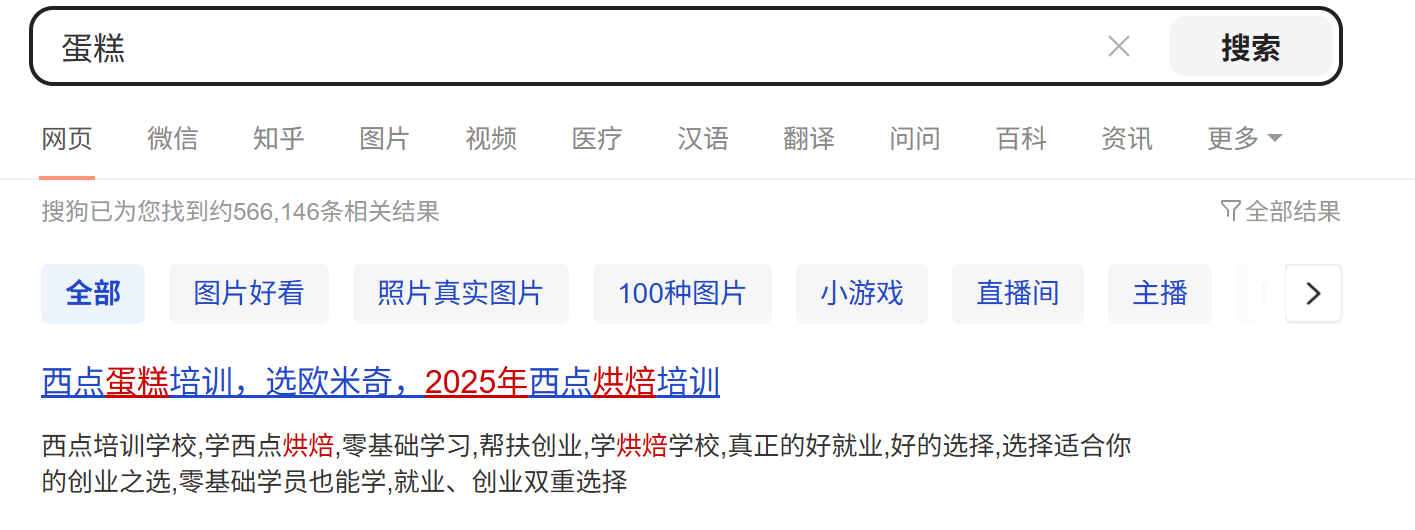
- 查询字符串(query string):请求中的参数,通过参数进一步解释说明。由程序员自定义,键值对格式,= 分隔键和值,& 分隔键值对。
- 片段标识符:标识网页中的某个部分,实现页面内跳转功能。文档类网站会有,如:简介 | Vue.js
URL 可以搭配很多网络协议使用,比如 HTTPS、JDBC。回忆一下,JDBC 中第一步是创建 DataSource,设置 url、user、password。jdbc 的 url:jdbc:mysql://127.0.0.1:3306/数据库名?characterEncoding=utf8&useSSL=false。
https://sogou.com 好像只有域名,实际上端口号、带层次的路径都有省略值,而查询字符串(程序员自定义)、片段标识符(程序员自定义)不是必要的。客户端的端口号是系统分配的空闲端口,服务器的端口号使用的 “知名端口号”,http:// 对应 80;https:// 对应 443。带层次的路径的省略值是 /,即根目录,通常对应网站的主页。
我们可以发现,搜索页的 url 的 query string 部分的一些 value 显示的是用户输入的中文,但复制后显示的是看不懂的编码:

![]()
url 中有一些特殊字符有特殊的含义,比如 =、&、? 等。而中文是由 utf8/gbk 编码,某个汉字的某个字节中可能含有特殊字符的 ascii 编码,导致读取错误。为了避免这种错误,需进行 url encode,将中文/符号按字节加 %。这种 utf8 编码解码的过程有专门库实现,我们在编写程序时要有这种意识。
![]()
2.2、方法(请求)
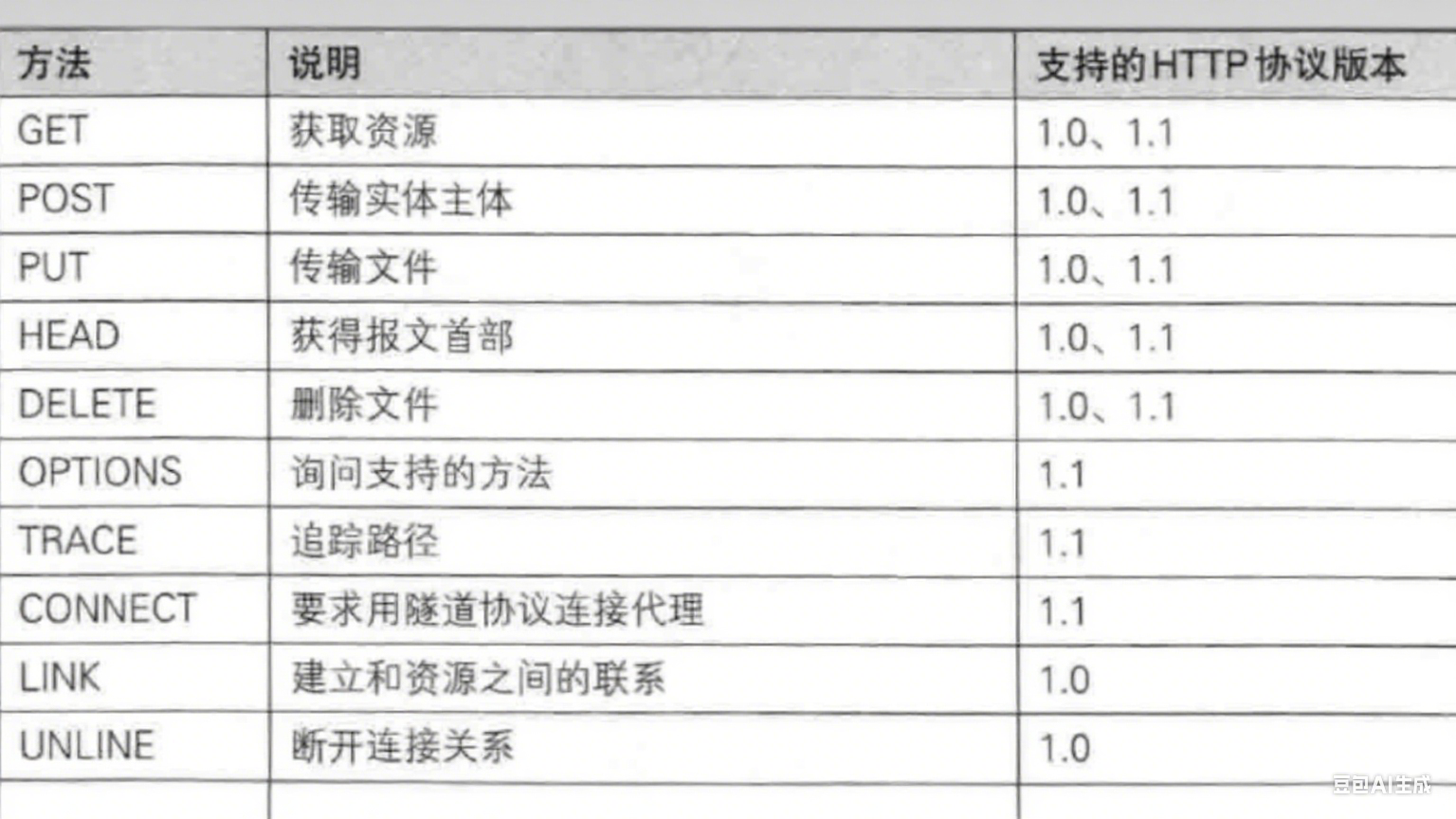
语义:(开发者不一定严格遵守)
- GET:从服务器获取某个资源。
最常用的方法,很多操作都会触发 GET 请求:
(1)浏览器地址栏输入 url、点击收藏夹。
(2)点击网页上的跳转链接。
(3)HTML 间接加载其他资源(通过 link 标签加载 css,通过 script 标签加载 JS,通过 img 标签加载图片等)。
(4)也可通过代码手动构造 GET 请求。
特点:一般没有 body,除非自己构造的 GET 请求故意加上 body。通过路径/query string 向服务器传递数据。
![]()
- POST:向服务器上传某个资源。
(1)登陆时
![]()
body 部分是用户名和密码(经过编码的)。
(2)上传资源时(上传头像为例)
![]()
body 部分是图片,属于二进制文件。但是当前上传的图片比较小,为了便于服务器处理,将二进制通过 base64 转为了文本内容。3 个字节的二进制数据,编码成 4 个 ascii 字符,每个字符有 6 位。
body 可以存二进制,但 url 的 query string 不能,如果非要用它存二进制内容,要用 base64 转成文本。
特点:用 body 传输数据给服务器;通常没有 query string。
- PUT:向服务器上传某个资源(文件)。特点跟 POST 差不多。
- DELETE:删除服务器某个资源。特点跟 GET 差不多。
经典面试题:谈谈 GET 和 POST 的区别。
本质上没有区别,只是两个不同的方法,他们俩可以互相代替。
从使用习惯上,有两个主要区别:
- GET 没 body,通过 query string 传输数据给服务器。POST 有 body,通常不需要 query string 传输数据。(不绝对,也可以自己构造 GET、POST 打破这个习惯)
- 语义上的区别:GET 表示获取,POST 表示提交。(实际上,在实践中会混用)
之所以是习惯上,是因为这两个区别不是绝对的。
当然,网上还有一些其它说法:
- GET 不安全,POST 更安全。因为 GET 是吧密码存 url 里,POST 存 body 里,别人看你屏幕看不到。【错误】安全是通过加密实现的。如果使用 body 存没有加密的密码,黑客也可以抓包获取。
- HTTP 标准文档中,建议 GET 实现成幂等的(请求一定,响应就一定),而 POST 无要求。【但这只是建议,实际不一定遵守,特别是现在的网站很讲究 “个性化”,给不同客户端的响应都是不同的】
- 可缓存,承接幂等。GET 实现幂等,就可以将一定的响应缓存。POST 不实现幂等就不能缓存。
- 传输的数据量。之前有个说法,GET传输的数据量少,因为 url 有长度限制;而 POST 传输的数据量大。【但 HTTP 标准文档中并没有说明 url 的限制。而这个限制在以前是存在的,也是由于浏览器、服务器的实现的限制,不是 url 的限制。现在实际上能看到很长的、保存一个完整图片的 url】
- 数据的类型。GET 通过 query string 只能传输文本;POST 通过 body 能传输问题,也能传输二进制。【query string 虽然不能直接存二进制数据,但能先进行 base64 转成文本】
需要用到 PUT、DELETE 方法的场景:Restful 风格的 HTTP 的 API(应用程序编程接口)设计。有些服务器可以认为是 API 的提供者,给浏览器/前端进行调用。以后我们需要写提供接口的服务器,需要统一设计风格,为的是降低学习成本、提高开发效率。满足以下约束:
- 不同方法表示不同语义:
GET:查询
POST:新增
PUT:修改
DELETE:删除
- 通过 URL 的路径表示操作的资源:
正面例子:不同路径下存放不同的视频文件。
![]()
![]()
反面例子:不管搜索什么,动态响应都存在 search 路径下。
![]()
![]()
- 请求、响应携带的数据,尽量用 json 格式的数据:

- 通过 HTTP 响应的状态码表示失败的原因。
2.3、版本号
最主流的是 HTTP 1.1。
请求在后:
![]()
响应在前:
![]()
2.4、状态码、状态详情(响应)
我们需要了解几个关键的,这个板块属于经典面试题:

- 200 OK:HTTP 层面的成功(访问成功),不是业务层面的成功(注册失败、成功)(会用其它属性标识,比如 body 的 json 引入键值对 code)。2 开头的都是成功,但是成功之间有区别。
- 404 Not Found: 客户端访问的资源不存在。url 里面的层次结构路径不存在。
- 403 Forbidden: 访问被拒绝,没有权限。跟业务有关:1)可以通过 HTTP 403 返回。2)可以通过 HTTP 200 返回,body 的 code 返回出错信息。4 开头都表示客户端出错,打开方式不对。
- 418:彩蛋,一个玩笑。
- 500 Internal Server Error: 服务器挂了,代码抛出异常没有 catch 住。我们写代码常见,知名网站不常见。
- 502 Bad Gateway、504 Gateway Timeout: 网关功能比较简单,不容易挂,通常挂的是网关后面连接的机器。5 开头的都是服务器出错,程序员赶紧修复。
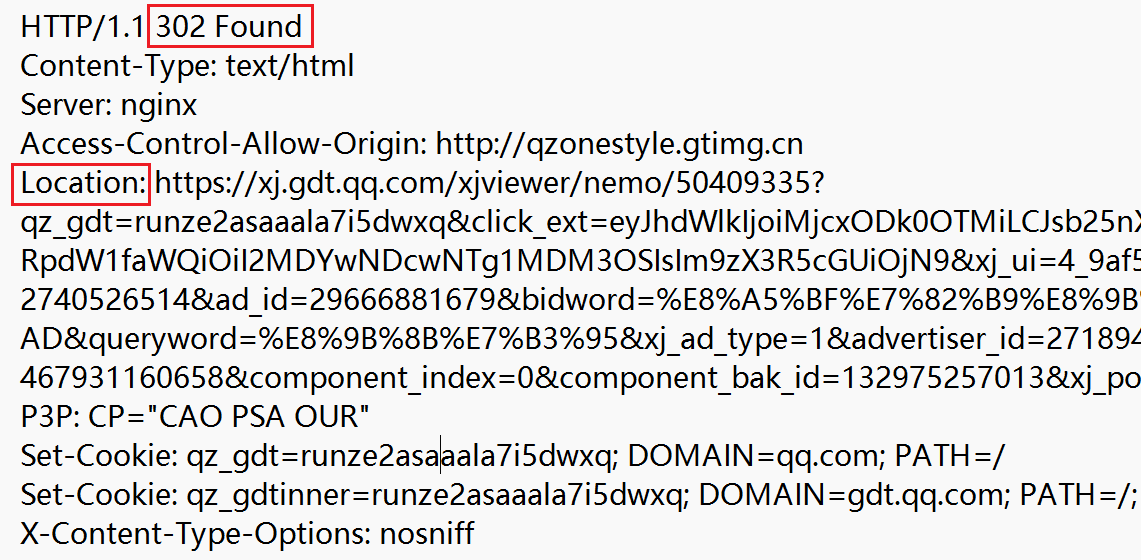
- 301 Moved Permanently、302 Move temporarily: 旧的地址永久、暂时重定向到新的地址。 3 开头的响应一般不需要 body,但是在 header 中需要 Location,表示要跳转到哪个页面。
3、报头
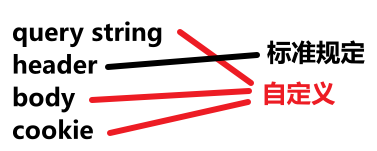
行文本,每一行就是一个键值对,用 :空格 隔开。每个键值对由标准规定,也允许用户自定义。下面讲一些重要的键值对:
3.1、Host
![]()
目标服务器的地址(域名)和端口(知名端口可省略)。HTTPS 会把 header 加密。url 里的地址和端口就可以和 Host 里加密的进行校验。
3.2、Content-Length、Content-Type
![]()
有 body 才有这俩属性。分别代表 body 的长度和数据格式。
Length:HTTP 在传输层通过 TCP 实现,是面向字节流传输,存在粘包问题。body 的长度可以解决这个问题。

分辨一个完整的 HTTP 包:
- 如果没有 body,读到空行结束。
- 如果有 body,读到空行后,再读取 Content-Length 长度的 body。
![]()
常见的 Type 值:浏览器/服务器通过这个值决定 body 如何使用。

如果一个请求/响应有 body,但是没有 Content-Length 或 Content-Type,就是一个非法的请求。商业级的程序具有鲁棒性,就算是非法的也能运行正确。比如没有 Content-Type,就根据 body 猜一个类型;没有 Content-Length,就按照下一个请求一定是 GET/POST 来猜。
3.3、User-Agent

早期浏览器访问的网站是纯文本的,后来加了多媒体(音频、视频、图片),再后来加了交互能能力(JS),再后来有了更复杂的交互体系……为了兼容老版本和新版本,根据客户端的请求中的 User-Agent 来判定用户的浏览器/系统版本,来决定提供哪个版本的网站。现在的浏览器,上面的功能都有,所以 User-Agent 只有一个主要功能:区分 PC 端和移动端。之所以要区分,是因为 PC 屏和手机屏大小不一样。如果 UA 里是 Windows/MacOS,则是 PC 版;如果 UA 里是 Android/IOS,则是手机版。
但是这种规则也不能完全解决问题,因为还有平板这种设备,以及 PC、移动端里都叫鸿蒙系统。目前前端流行一种开发技术 “响应式编程”,只写一套代码,自适应浏览器宽度。
3.4、Referer
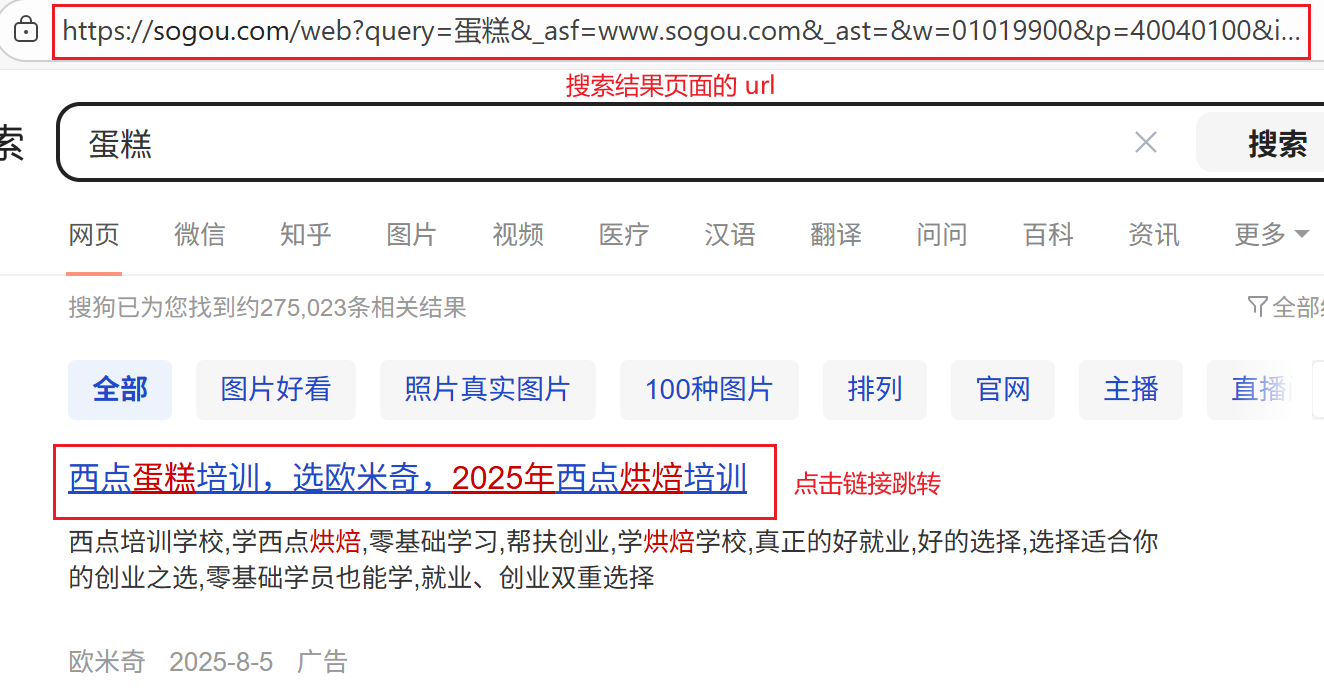
在跳转页面的请求中存在,用于记录从哪个 url 来的。例如,我在“蛋糕”的搜索结果页面中,点击了一个广告链接:
搜索结果:
跳转到广告:
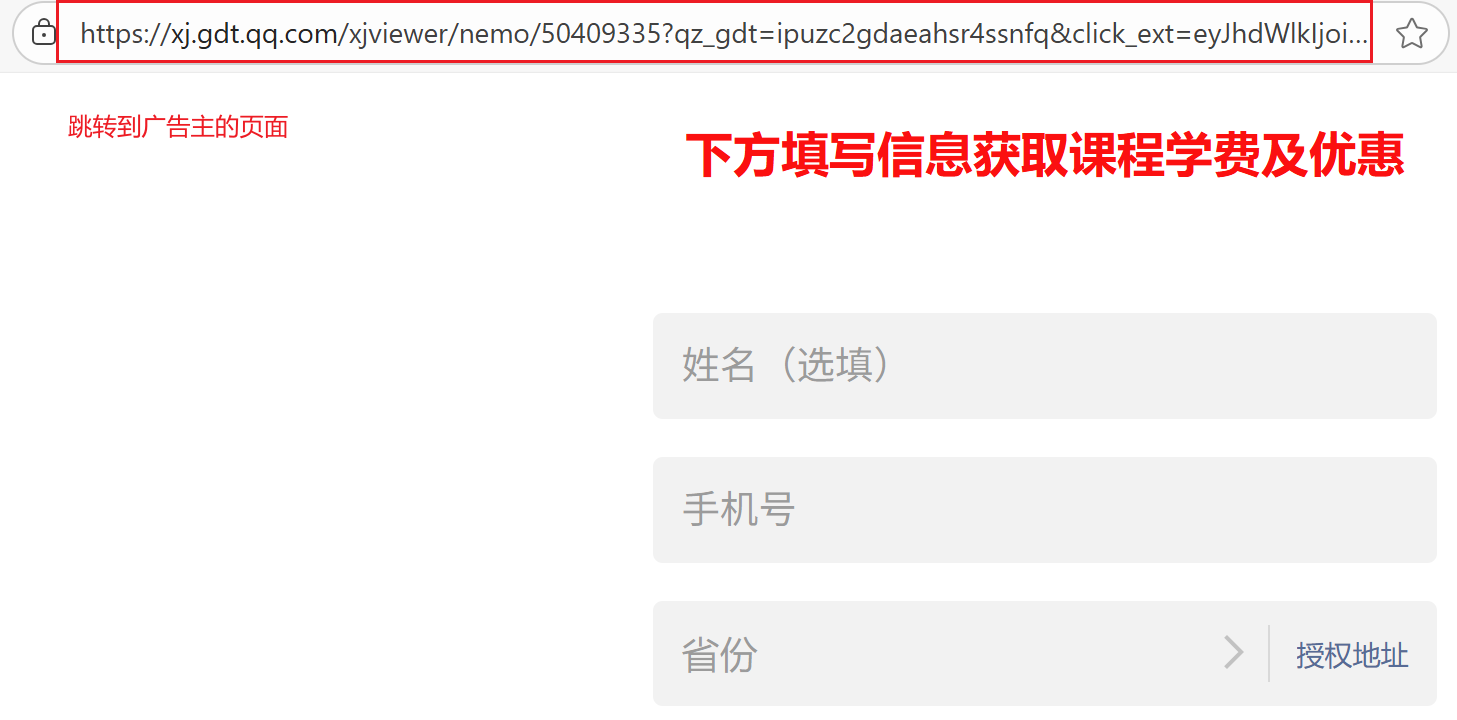
发送的 http 请求:
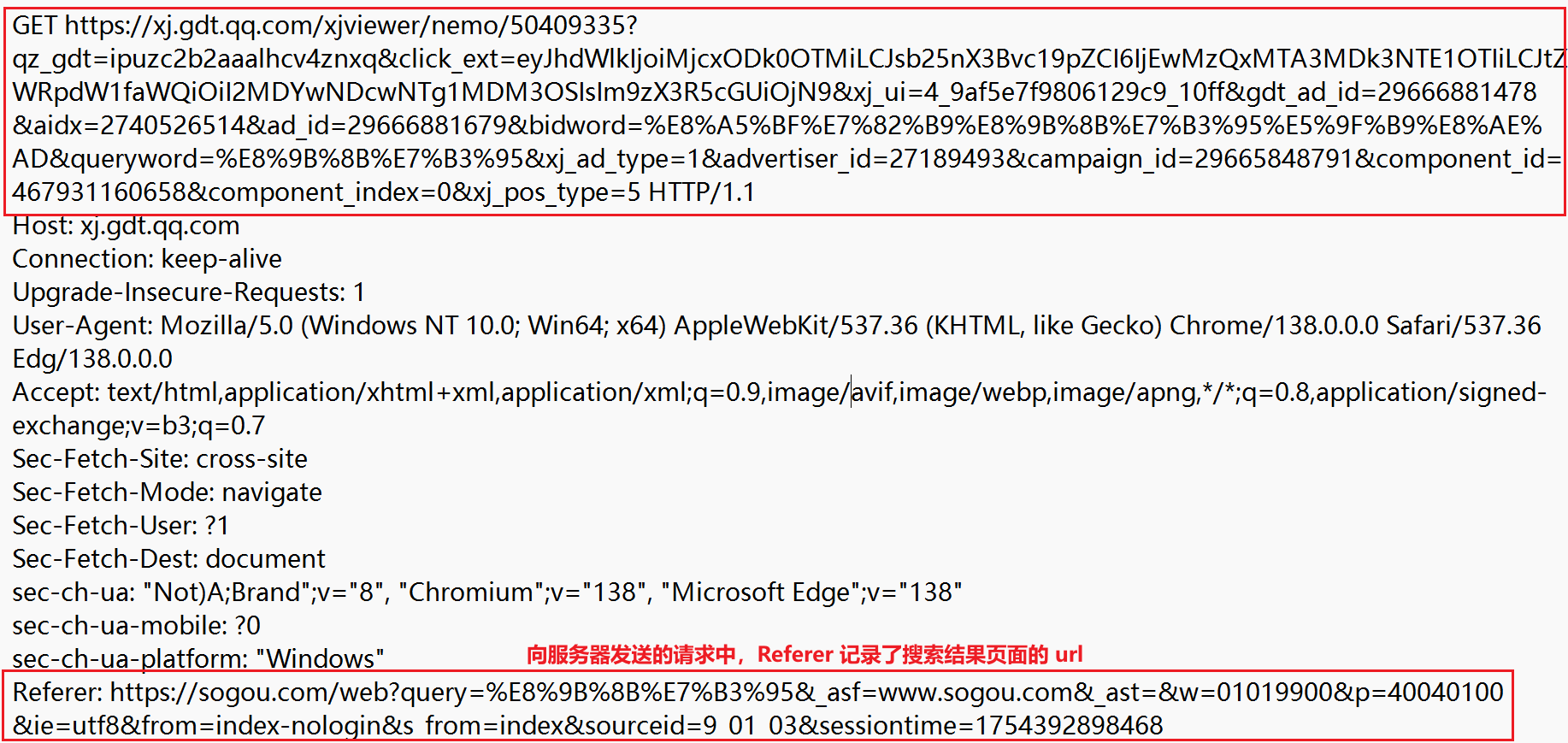
从浏览器搜索、点击收藏夹发送的请求,都包含该键值对。但浏览器的回退功能与此无关,不依赖 HTTP 协议,而是维护了一个栈记录。
Referer 的主要应用场景是“点击计费”。广告主可以在多个平台上投放广告,广告主如何知道用户是从哪个平台点击过来的,就是查看 Referer。广告平台服务器、广告主服务器会分别计数,最后数目对得上才行。
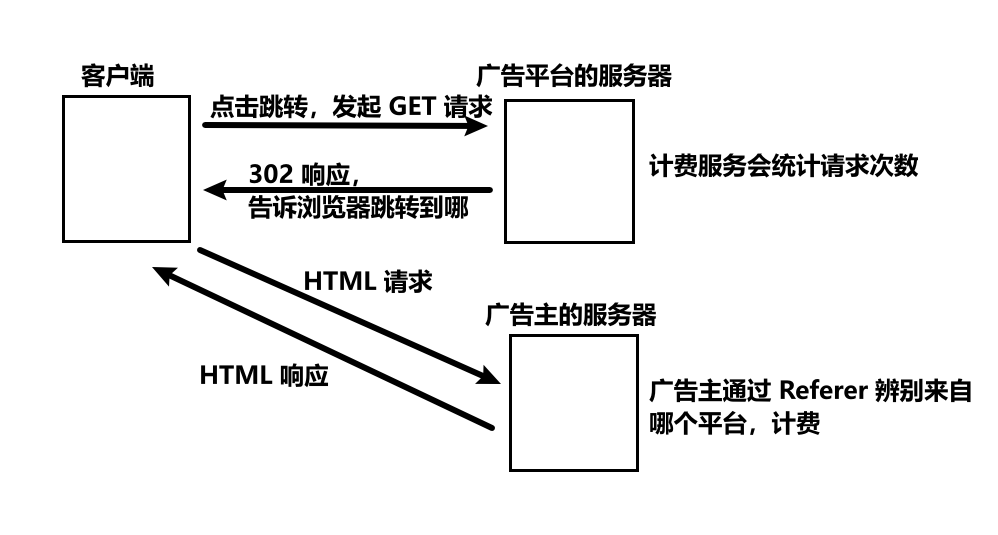
十年前,运营商作为请求的中间必经之路,把请求中的 Referer 改成自己的 url 的行为十分猖獗。虽然各大广告平台跟运营商打赢了官司,但是付出的代价也很大。为了预防这种事的发生,广告平台们加急将基于 HTTP 协议(明文)的服务升级为 HTTPS 协议(含加密层)。
3.5、Cookie
Cookie 的内容就是一些自定义的键值对(;隔开键值对,=隔开键和值):

我们回顾一下,HTTP 协议中,内容是键值对的元素:
Cookie 本质是网站在本地存储数据的机制。手机 app/电脑桌面应用程序,在下载客户端的时候就会把很多数据保存下来,它们有应用商店审核,所以比较安全。但是网站的数据完全是从服务器获取的,没有人审核安全性,很有可能有病毒程序对电脑产生破坏。为了把控安全,浏览器不允许网站访问电脑上的硬盘,也不能调用电脑上的其它程序。那怎么存储网站的一些数据呢?服务器会将数据传给浏览器并保存在硬盘上(这些数据只能是一些简单的键值对,且有过期时间),当再次访问服务器时,就将数据加载到 Cookie 中,通过请求发送到服务器。
访问 sogou.com,查看服务器请求,每个键值对对应一个 Set-Cookie:
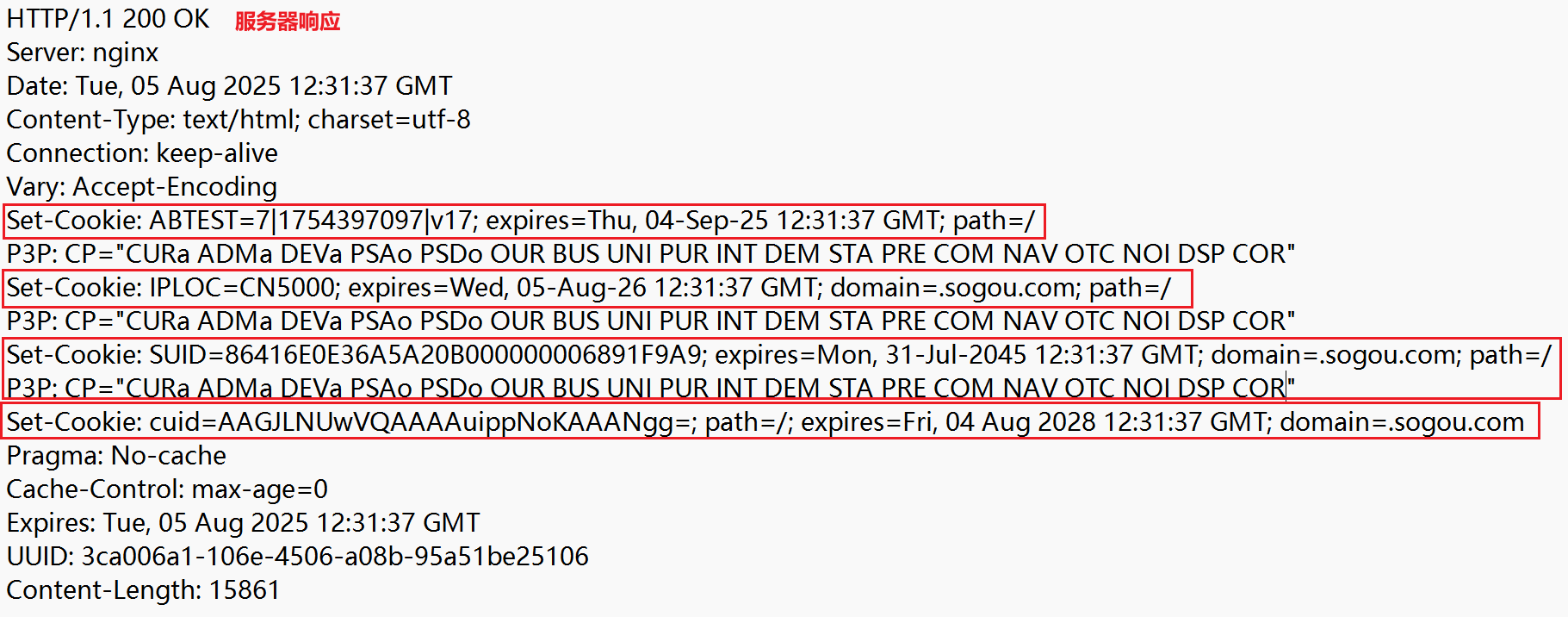
在浏览器中查看所有 Cookie,键值对存储到了本地硬盘(访问搜狗主页,可能会与服务器有多次 HTTP 交互,即多个响应,所以上文一个服务器响应只包含了部分 Cookie):

应用场景:
- 存放有用,但不重要的信息。Cookie 容易丢失。比如 “上次访问时间”(可有可无);流量标签(记录广告点击来自于旧版式还是新版式),做实验性功能(统计哪个版式的流量更好)。
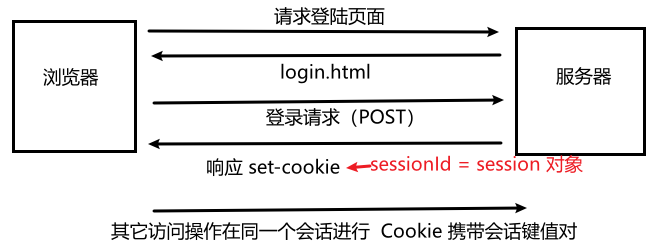
- 保存用户的身份标识。很多网站需要登陆,登陆后服务器会将用户的唯一会话标识存 sessionId 储到 Set-Cookie 中返回,之后用户进行的一些列操作都是在该会话中进行的,当登出时会话结束。会话是有存活时间的,存活时间越短安全性越高,比如支付宝、网银。会话和 Cookie 是两个不同的机制,服务器存储会话中所有的详细信息,客户端/浏览器在 Cookie 中保存会话标识。Cookie 按照域名维度存储,在 A 网站申请的会话标识只能用于 A 网站。
4、正文
主要认识数据格式,在后续实践中进一步体会。

四、构造 HTTP 请求
1、应用场景
- 开发阶段:浏览器的网页中要构造 HTTP 请求,实现前后端交互。
- 测试阶段:模拟前端功能,构造 HTTP 请求测试服务器功能。
2、实现方法
2.1、手动写代码
基于 tcp socket 构造 HTTP GET 请求:按照 HTTP 请求的格式,向 tcp socket 写入字符串。
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.Socket;
import java.net.UnknownHostException;public class httpClient {Socket socket = null;public httpClient(String host, int port) throws UnknownHostException, IOException {// 与目标服务器建立连接socket = new Socket(host, port);}// 构建 GET 请求public void get(String url) {// 构造 HTTP GET 请求:首行+请求头+空行String request = "GET " + url + " HTTP/1.1\n" +"Host: " + socket.getInetAddress().getHostAddress() + ":" + socket.getPort() + "\n" +"\n";try(InputStream inputStream = socket.getInputStream();OutputStream outputStream = socket.getOutputStream()) {// 发送请求outputStream.write(request.getBytes());outputStream.flush();// 接收响应byte[] bytes = new byte[1024*1024];int len = inputStream.read(bytes);String response = new String(bytes, 0, len);System.out.println(response);} catch (IOException e) {e.printStackTrace();}}public static void main(String[] args) {}
}
但这种方法不好测试,因为现在的网站都是 HTTPS 协议,没有可以测试的服务器。我们以后自己写了 HTTP 服务器后,可以用这个方法。
如果是构造 HTTPS 请求,通过 tcp socket 构造很复杂,都是用现成的库实现。
2.2、使用工具
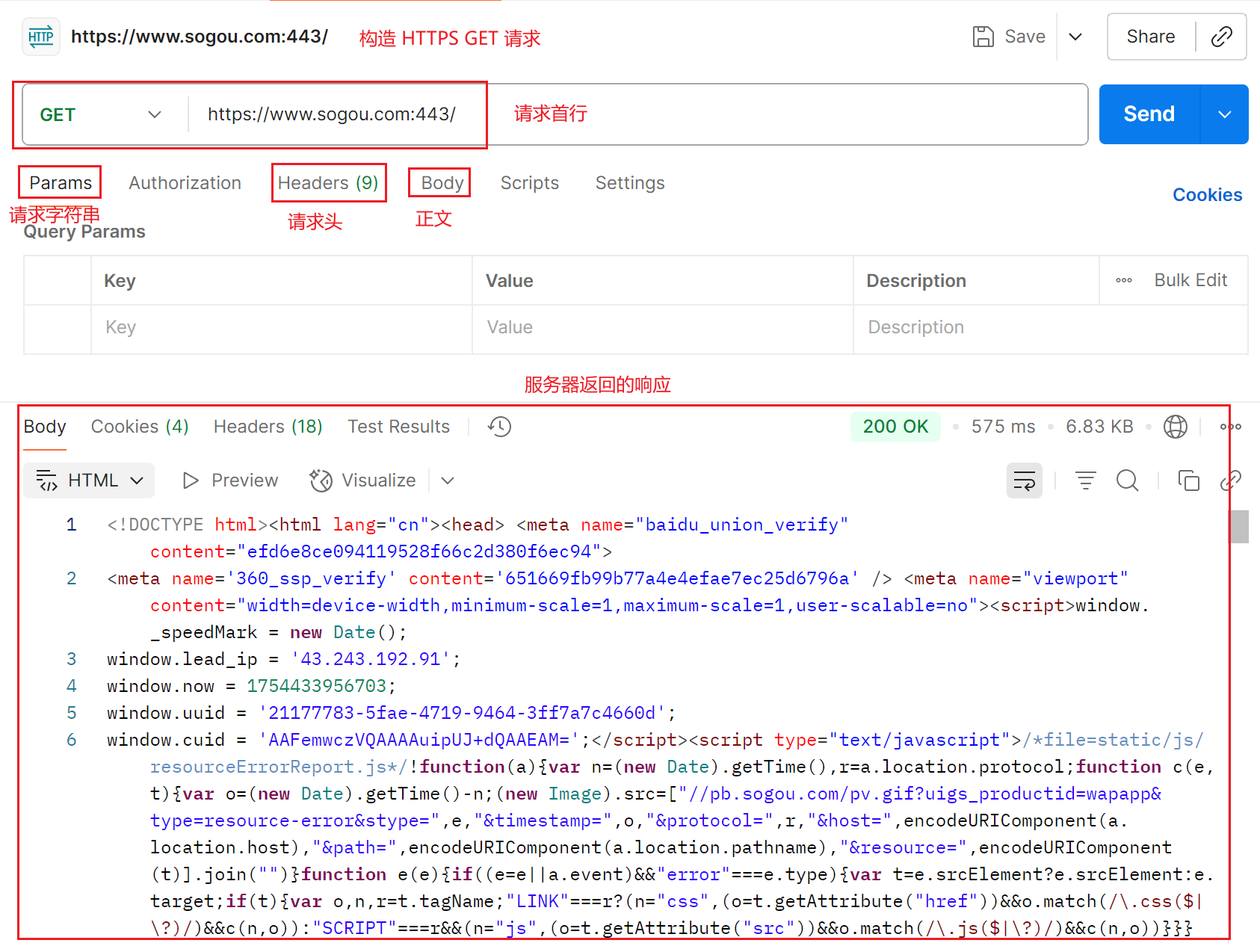
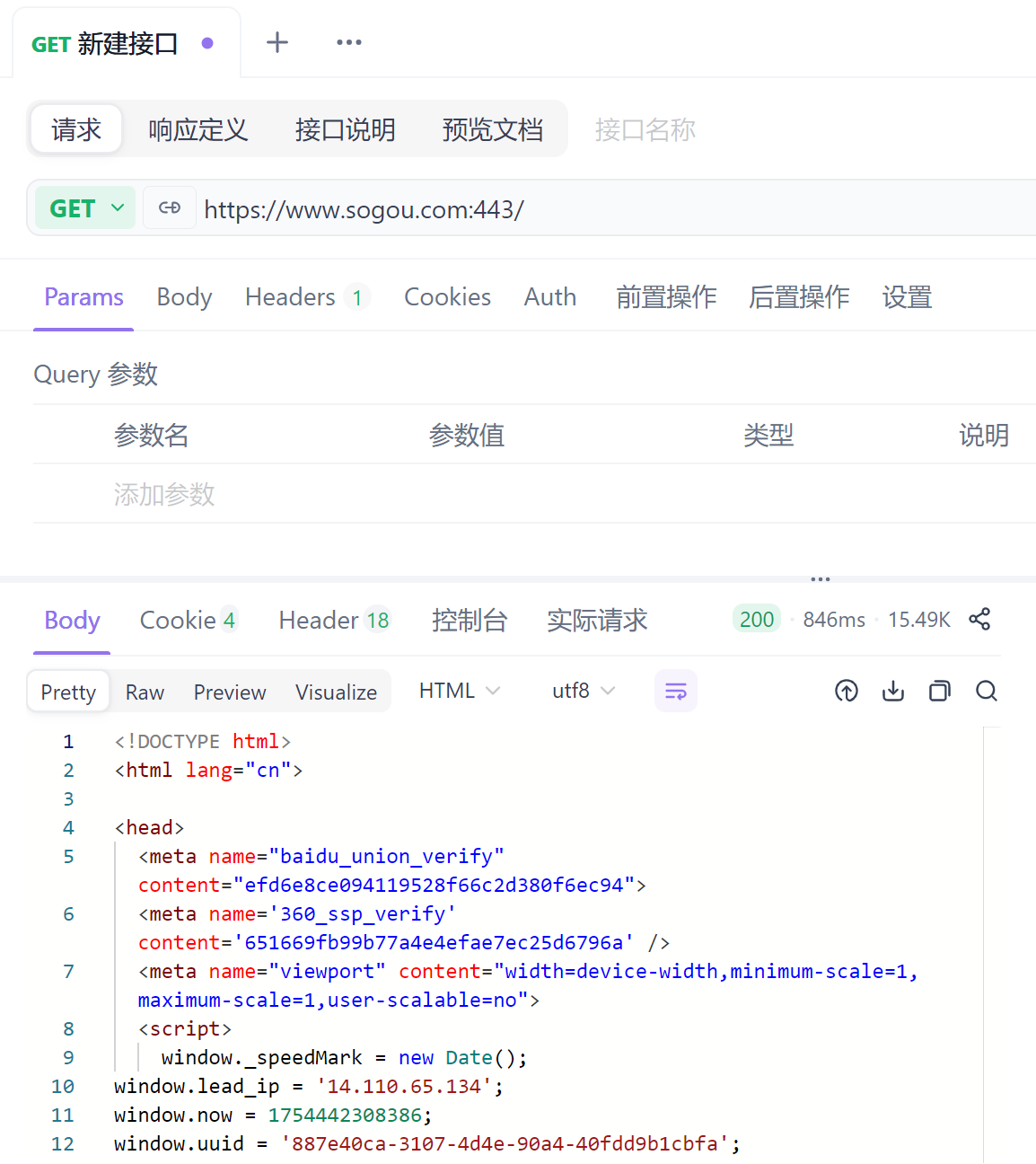
在工作中,特别在测试阶段,更常用现成工具构造 HTTP 请求。最老牌的就是 Postman,然后还有个知名的国产新秀(2020年之后)API fox(相比 Postman 多了团队成员管理)。
Postman:
API fox:
后端把服务器写完了测试,就是用上面的工具。最后前端和后端会坐一起联调测试。
五、HTTPS
1、为什么要升级为 HTTPS
HTTP 是明文传输的,不安全。例子如下:
我们在网页中下载应用时,肯定遇到过这种情况:明明点击下载的是天天音乐,但是下载的链接却是 QQ 浏览器。
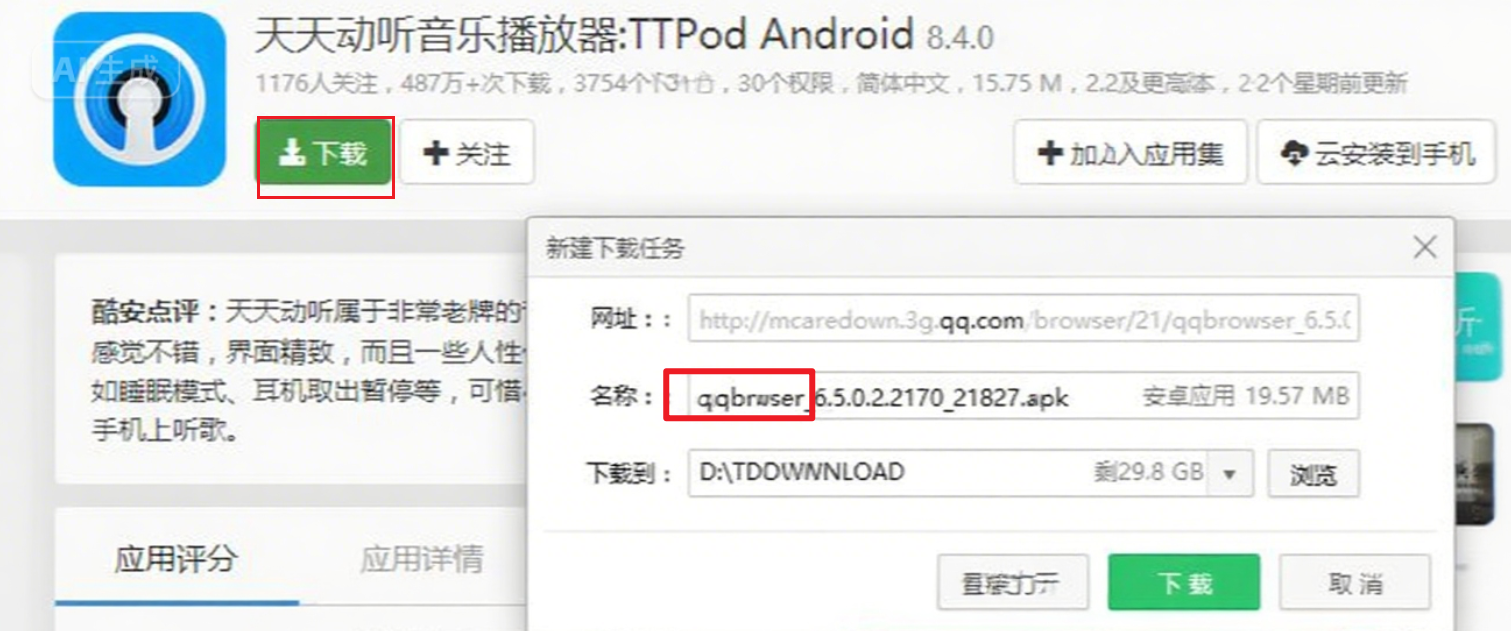
罪魁祸首就是运营商,被金钱蒙蔽了双眼,更改了服务器响应中的下载链接:
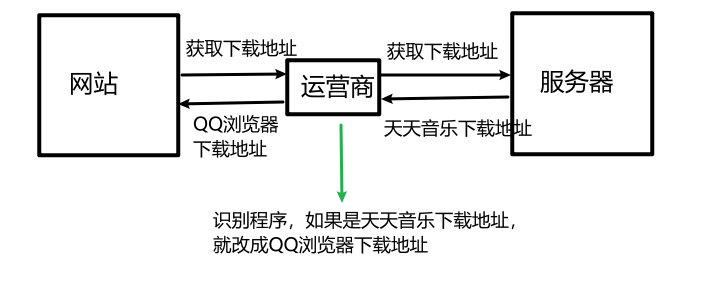
所以我们需要对传输内容进行加密(涉及到密码学,与程序员无关),将明文(原始数据)加密成密文,反操作就是解密。加密解密的过程需要用到密钥。HTTPS = HTTP + SSL(下文讲述的工作过程)/TSL(SSL 升级版,但是核心内容一致)。
军事场景中,密码学就已经很重要了。二战时期,没有计算机,通过无线电报通信(滴答的摩斯电码),这些电报容易被敌人获取。德国就发明了 engima 机,进行高强度加密。英国的图灵大佬发明了 boom 对 engima 的加密电报进行解密。但这不是图灵的真正目标,而是计算机,冯诺依曼邀请他去美国一起研究计算机,他拒绝了。可惜的是因为他喜欢同性被英国政府(当时是政教合一)迫害,因承受不住痛苦而吃了毒苹果自杀。苹果公司的 logo 就是为了纪念图灵。
2、HTTPS 的工作过程
经典面试题
2.1、对称密钥
用同一个密钥对 HTTP 请求/响应(首行不加密,需要知道目的服务器地址)进行加密解密。但是仅仅是对称密钥存在一个问题,服务器与每个客户端的密钥肯定是要不同的,不管是客户端还是服务器生成密钥,都要告诉对方密钥是什么才能解密/加密。这样会引发问题,必定要在网络上传输密钥,那么黑客就能获取密钥。因此,对称密钥也需要加密。如果用另一个对称密钥对密钥加密?不行,也需要传输。
2.2、非对称密钥
非对称密钥就是用来给对称密钥加密的。那为什么不直接用非对称密钥给传输的数据加密?因为非对称加密的计算成本远比对称加密的计算成本高,密钥肯定比 HTTP 报文的数据量小很多。
原理:服务器生成一对公钥和私钥,分别要么解锁,要么加锁。把公钥传输出去,谁都可以获得;私钥只能服务器自己持有。
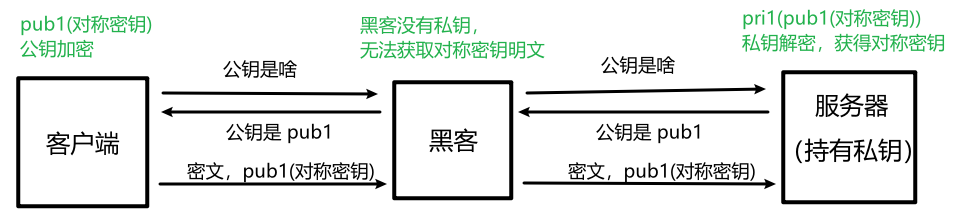
2.3、中间人攻击
狸猫换太子,用黑客自己生成的公钥密钥替换服务器生成的公钥密钥:
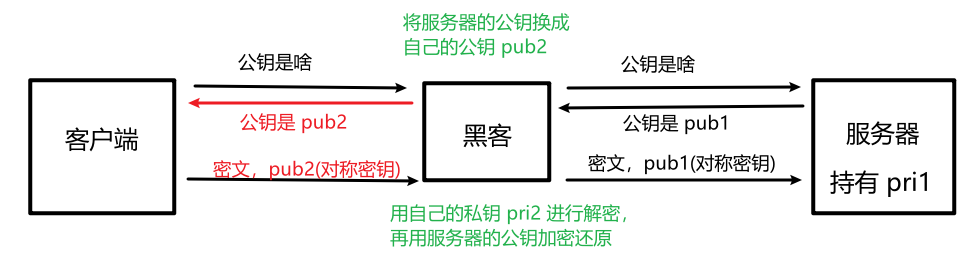
2.4、证书
服务器开发者向第三方公证机构提交资质申请证书,这个证书可以证明公钥是服务器创建的,而不是黑客伪造的,解决中间人攻击。
证书是结构化的字符串,包含属性:

客户端验证证书的合法性,需要依靠数字签名。
数字签名的生成:公证机构针对证书计算校验和,然后用自己生成的公钥私钥中的私钥对验证和进行加密,就得到了数字签名。
数字签名的验证:客户端对证书计算一次校验和 check1,再用公钥解密数字签名得到公证机构计算的校验和 check2,如果 check1 和 check2 对不上就说明证书被篡改过。当不匹配时,浏览器就会弹出 “该网站存在风险”。
问题解答:
1)黑客能否篡改公钥?
不能。check2 会跟 check1 对不上。
2)黑客能否篡改公钥后,把验证和也篡改了?
不能。第一,黑客无法获取公钥,因为是内置在客户端系统中的(也可以通过其它途径安装,如果黑客搞了一个有问题的系统镜像,就会存在风险),无法对验证和进行解密。第二,黑客没有公证机构的私钥,无法对篡改后的验证和进行加密。
3)黑客能否把整个证书替换掉?
不能。证书中包含了服务器的域名,替换掉域名就变了。
关于 fiddler 在开启 HTTPS 抓包时,为什么要信任安装证书的解答:抓包实际上就是中间人攻击。我们需要信任 fiddler 的安装证书,它才能替换掉服务器的证书,允许它进行中间人攻击,拿到对称密钥,把所有的数据解密给我们看。








)
)
![[自动化Adapt] 父子事件| 冗余过滤 | SQLite | SQLAlchemy | 会话工厂 | Alembic](http://pic.xiahunao.cn/[自动化Adapt] 父子事件| 冗余过滤 | SQLite | SQLAlchemy | 会话工厂 | Alembic)



)

 D. K-good)


