通俗说法:在多模态自监督学习中,将共享信息和独有信息分离开来
Abstract
问题: 传统方法通常假设在训练和推理阶段都可以访问所有模态信息,这在实际应用中面对模态不完整输入时会导致性能显著下降。
解决方法:提出了一种面向遥感数据融合和多模态Transformer的全新不完整多模态学习方法,有监督自监督训练都适用
方法简述: 利用多模态Transformer ,结合模态注意力,掩码自注意力机制,整合额外学习得到的token
方法结合重构损失与对比损失
Introduction
传统方法: 为了融合不同模态的互补信息,依赖于基于特定领域知识的人为设计特征和融合策略;
基于CNN的深度方法通常假设所有模态在训练与推理阶段都是完整可用的,这在实际应用中却是一个限制因素,因为数据采集过程中可能存在部分模态缺失。
不完整模态学习: 对缺失模态用生成模型,或者知识蒸馏(幻觉网络)尽管有一定的效果,但是需要为每一类模态分别部署和训练一个模型。
目标:一些新方法致力于训练一个统一模型来应对下游任务中的不完整模态问题,在这种背景下,实现模态不变(modality-invariant)的融合嵌入表示成为提高鲁棒性的重要手段,尤其适用于部分模态缺失的情况。
近年来没有同时满足自监督和允许不完整模态输入
why 自监督:有监督训练泛化能力差,训练大规模数据集成本高
why 不完整模态输入:实际应用场景存在不完整模态
方法简述
贡献:1.提出在多模态Transformer中引入模态注意力与掩码自注意力机制,用于构建跨模态的融合token,以实现适用于不完整模态输入的对比与重构预训练。
2.在下游任务中,我们基于上述机制提出了随机模态组合训练策略,确保模型在推理阶段面对模态缺失时依然具备强性能。
3.再公开的DFC2023 Track2数据集,和自己构建的四模态数据集,与标准多模态Transformer 对比取得了当前最优性能
Conclusion
本问提出了一种适用于多模态遥感数据融合任务的不完整模态学习框架,支持有监督和自监督,我们的方法支持模态不完整的条件下进行模型的训练和推理。
通过引入模态注意力机制与掩码自注意力机制,我们能够在 MultiMAE 框架中利用对比损失与重构损失对网络进行预训练,同时也可以通过随机模态组合训练策略,从零开始训练或在下游任务中对模型进行微调。该策略使网络在推理阶段即便仅接收到部分模态甚至单一模态输入时,也能保持较高的性能。
(通过俩注意力机制,用俩损失函数,和一个随机组合模态的训练策略训练)
RELATED WORKS
多模态遥感数据融合
多模态掩码自动编码器(MultiMAE)
与依赖对比目标的自监督方法不同,MultiMAE 使用一种预训练任务:对每个输入模态的掩码图像块进行重建。
多模态Transformer
METHODOLOGY
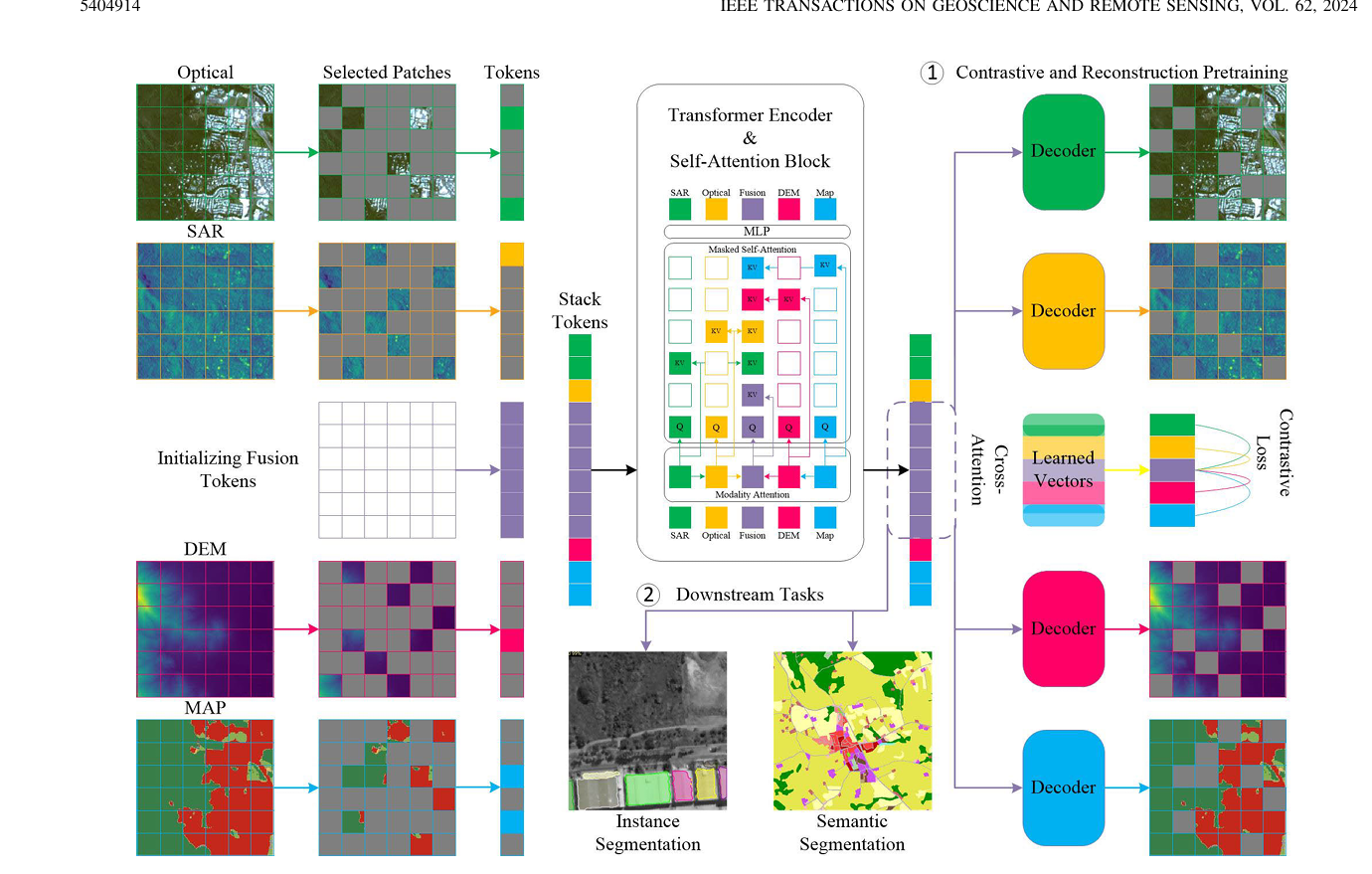
A 网络架构
主体架构采用VIT ,对每个模态划分16*16patch 进入线性层映射为D维,加入位置嵌入,引入融合token
与瓶颈融合token 不同,采用的是空间融合token,数量与patch一样,然后模态自注意力机制把不同模态的信息融合到token,然后拼接送入Transformer 编码器,使用掩码自注意力机制
B 模态注意力

融合token :可学习参数,作为Query 在四种模态中学习怎么融合,整合信息。
C 掩码自注意力机制
目的是让每个模态输出自己纯净的信息,让融合的模态输出的是融合的信息,需要通过掩码来实现

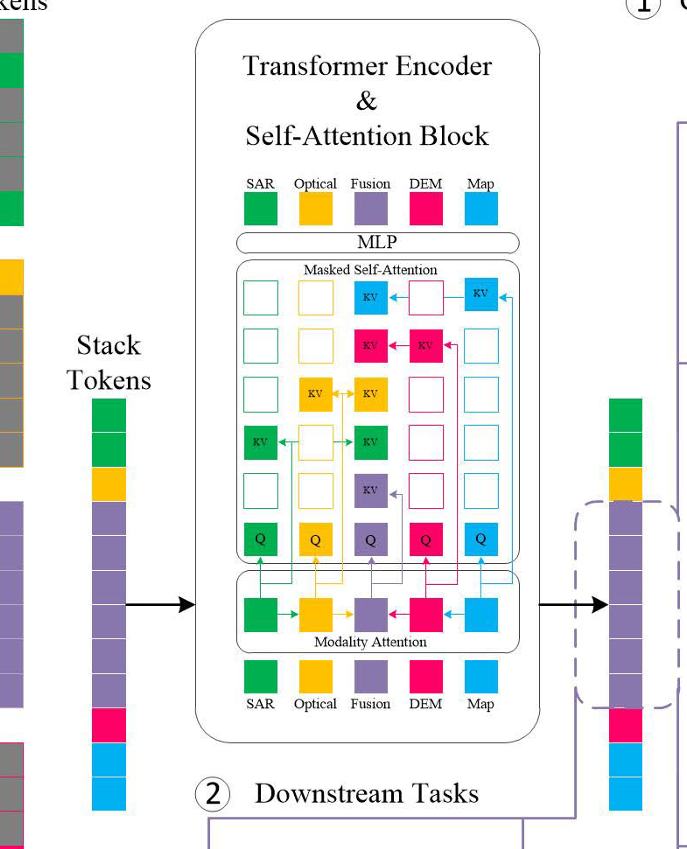
左侧是融合后的token ,重建成5*5的权限矩阵,每个模态只能与自己做SA ,而融合模态要与其他四个做CA
是要设计权限矩阵也就是图中的m,为每个模态计算时只关注每个模态纯净的信息。
D 重构预训练
用融合后的token 去做生成与原图计算损失,并应用于下游任务
使用浅解码器是为了避免decoder过强而抹杀encoder 的学习
理解Transformer :最后算完的token 怎么用?当作库,利用Qeury 不断的和库里的KV 算,进行预测
E 对比学习
为每个模态引入一个class_token ,对最后一个自注意力层输出的token 做CA ,损失函数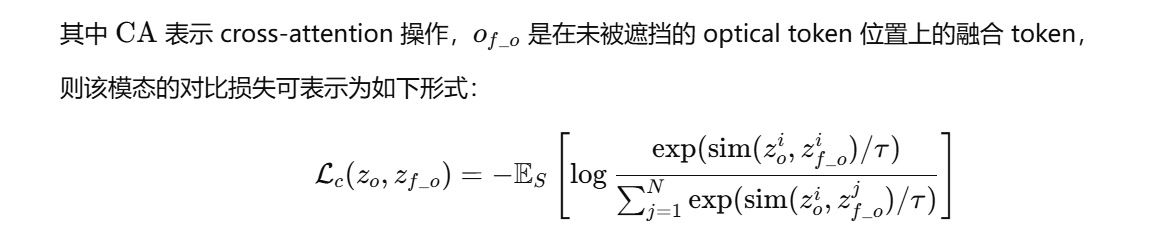
目的是在同一批次的样本中,强迫模型认出哪个融合向量是与当前单模态向量真正“配对”的,并拉近它们的距离
F. Random Modalities Combination
Transformer 容易对任务中占主导地位的模态过拟合,为了提升鲁棒性,提出一种随机模态组合策略,在预训练和下游任务训练中
预训练:patch 随机掩码
下游任务:1.patchdropout 2.随机模态组合
实验
数据集:
DFC2023 Track2 - 建筑物实例/语义分割
四元组数据集 - 土地利用土地覆盖制图
实验部分核心内容提炼
一、 实验目标与设置
核心目标:证明该方法在**模态不完整(有模态缺失)**的情况下,依然能保持强大性能,远超传统方法。
两大任务:实验在两个实际的下游任务上进行,分别是建筑物分割和土地利用覆盖(LULC)制图。
两种范式:对每个任务,都进行了两种模式的评估:
从零开始监督学习:不使用任何预训练权重,直接在任务数据上训练。
预训练后微调:先在大量数据上进行“重建+对比”的自监督预训练,然后用预训练好的模型去微调下游任务。
二、 主要实验结论
模态完整时表现更优:在所有模态都可用的理想情况下,该方法性能已经优于一个简化的对比模型(MultiViT)。
模态不完整时优势巨大(最关键的结论):
当输入模态有缺失时,对比模型(MultiViT)因为严重“偏科”(过拟合)于主导模态(如光学图像),性能会断崖式下跌,甚至完全失效。
而本文提出的方法,得益于**“随机模态组合”的训练策略,即使只输入单一模态(甚至是“非主导”的模态),依然能保持非常高的性能**,展现出极强的鲁棒性。
预训练的有效性因任务而异:
对于建筑物分割任务,一个有趣的发现是“从零开始训练”的模型表现最佳。
而对于土地利用覆盖(LULC)制图任务,经过“重建+对比”双重预训练的模型表现最好。这说明对比学习对于增强该任务的特征有显著帮助。
三、 核心模块有效性验证(消融实验)
作者通过“控制变量法”证明了其提出的每个模块都是必不可少的:
随机模态组合策略:极其重要。如果不使用这个策略,模型在模态缺失时性能会严重下降,证明这个“魔鬼训练法”是提升鲁棒性的关键。
模态注意力 (即交叉注意力):非常有效。如果移除这个模块,性能会显著下降,证明这是融合Token有效汇集各模态信息的关键一步。
掩码自注意力:有益处。虽然它限制了模态间的直接交互,但实验证明它对于保持单模态的“纯净性”和性能至关重要,最终对整体训练过程产生了积极影响。
四、 对模态贡献的分析与洞察
该框架还能帮助分析不同模态对特定任务的贡献度:
对于建筑物分割:光学图像的贡献最大,其次是DSM(高度图),而SAR图像贡献最小,有时甚至会引入噪声。
对于土地利用覆盖制图:DNW地图和Sentinel-2图像贡献最大,而DEM(高程)数据则不太关键。
这个分析表明,该方法不仅性能强大,还能为实际应用中如何选择最优、最经济的模态组合提供决策依据。





)



)
的编程实现方法:1、数据包格式定义结构体2、使用队列进行数据接收、校验解包)

)



——标准库函数大全(持续更新))

![[SKE]Python gmssl库的C绑定](http://pic.xiahunao.cn/[SKE]Python gmssl库的C绑定)
