目录
- CPU
- 1 概述
- 1.1 概念
- 1.2 冯诺依曼架构
- 1.3 常见参数(评估性能)
- 1.4 按指令集分类
- 2 CPU发展
- 2.1 发展史
- 2.2 行业产业链
- 2.3 英特尔 Xeon 至强处理器
- 2.4 AMD Zen架构
- 补充
- 1 寄存器、存储器、内存、缓存、硬盘区别与联系?
- 2 浮点单元
- 参考
本篇记录和梳理服务器方面的知识,目前写的还比较简略,后续会逐步补充。
CPU
1 概述
1.1 概念
CPU(Central Processing Unit,中央处理器)是计算机系统的运算和控制核心,是信息处理、程序运行的最终执行单元。
(后面提到的冯诺依曼结构的运算器和控制器组成计算机的CPU)
CPU的工作流程:获取指令→指令译码→执行指令→获取数据→写回数据
1.2 冯诺依曼架构
-
三个基本原则
数字计算机的数制采用二进制;
计算机应该按照程序/指令顺序执行;
计算机由五个部分组成。 -
五个基本部分
运算器:用于完成各种算术运算、逻辑运算和数据传输等数据加工处理;
控制器:用于控制程序的执行,是计算机的大脑。控制器具有判断能力,能够根据计算结果选择不同的工作流程。
存储器:用于记忆程序和数据,如内存。程序和数据以二进制代码形式不加区别地存放在存储器中,存放位置由地址确定。
输入设备:将数据或程序输入到计算机中。
输出设备:将数据或程序的处理结果展示给用户。 -
基本功能
将需要的程序和数据送入计算机;
具有长期记忆程序、数据、中间结果以及最终运算结果的能力;
能够完成各种算术运算、逻辑运算和数据传输等数据加工处理的能力;
能够根据需要控制程序走向,并根据指令控制机器的各部件协调操作;
能够按照要求将处理结果输出给用户。
1.3 常见参数(评估性能)
一般在市面上购买CPU时所看到的参数一般是以(主频\前端总线\二级缓存)为格式的。例如Intel P6670的就是(2.16GHz\800MHz\2MB)。
- 主频
CPU的时钟频率,指每秒CPU能够运算的次数,主频越高,CPU速度越快,直接决定了CPU性能。
超频:通过提高CPU主频获得更高的性能。
降频:节能模式下,系统CPU进行降频,增强续航。
主频=外频×倍频。
外频:CPU的外部时钟频率,指CPU与主板连接的速度(与数字脉冲信号震荡速度有关)。主板可调外频越多、越高越好,对超频有用。
倍频:外频与主频相差的倍数。其作用是能够使总线工作在相对较低的频率上,而CPU速度无限提升。
-
核数
表示CPU的并行处理能力,核数越多,并行处理速度越快。 -
线程
指处理器的逻辑线程数量,一般一个核数对应一个线程。
超线程:一个物理核对应多个线程,即一个核心分为多个小的核心进行并行计算,实现单核可以并行处理多个事务。 -
缓存
缓存是位于CPU内部的高速存储器,用于临时存放频繁访问的数据和指令,减少从主内存读取数据的时间,加快处理速度。较大的缓存有助于提高性能。
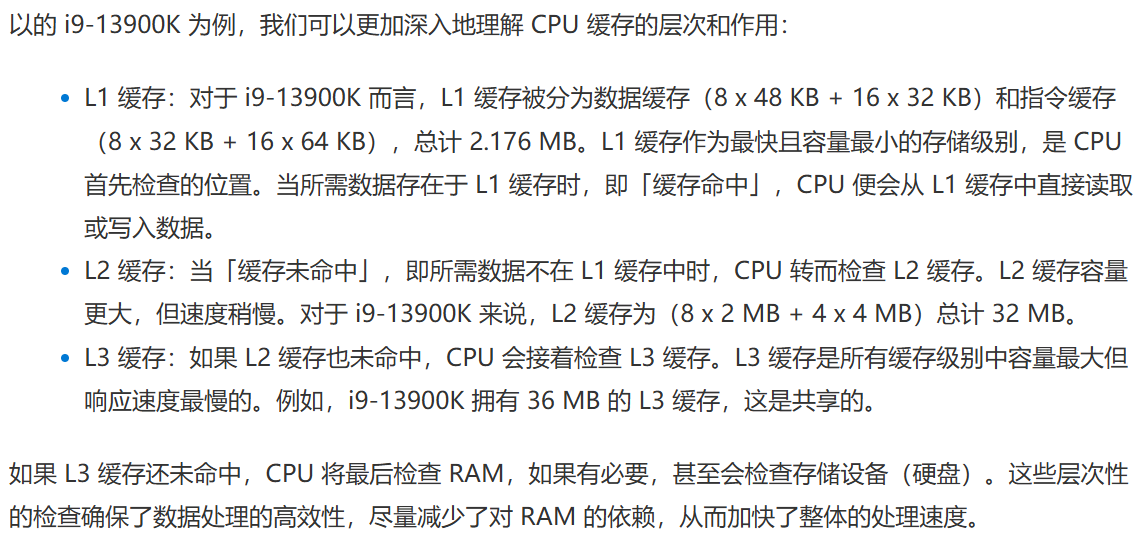
目前由L1、L2、L3等不同级别的缓存,不同级别的缓存在缓存大小、响应速度(延迟)和数据命中率之间找到最佳平衡。
L1缓存:最快但容量最小,通常每个核心分配。容量范围在128KB到2MB之间。
L2缓存:响应速度和容量居中,可以为核心独有,也可以是共享的,容量范围在256KB到32MB之间。
L3缓存:响应速度最慢但容量最大,通常是共享的,容量范围在1MB到128MB之间。
举例说明:
图源:揭秘 CPU 缓存:L1、L2 和 L3 的性能秘密
-
FSB前端总线
表示了CPU和外界数据传输的速度。 -
TDP热设计功耗
当芯片达到最大负荷时热量释放的指标,是电脑的冷却系统必须有能力驱散热量的最大限度。
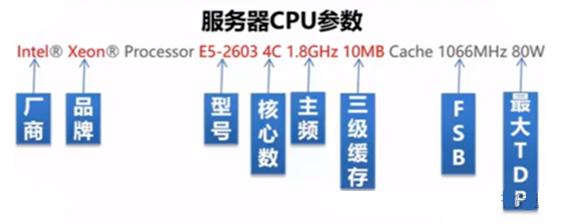
图源:服务器内部细节:CPU、内存、硬盘等
1.4 按指令集分类
- 指令集是什么?
存储在CPU内部,对CPU运算进行指导和优化的硬程序,用来引导CPU进行加减运算和控制计算机操作系统的一系列指令集合。
预先存储的指令越多,CPU就越“聪明”。可以做的“动作”越多。预先存储的指令越先进,CPU就越高级。
其实指令集就是一组汇编指令的集合,不同的CPU使用的指令集不同。
- RISC 与 CISC
RISC 全称Reduced Instruction Set Compute,精简指令集计算机。
CISC 全称Complex Instruction Set Computers,复杂指令集计算机。
CISC既有简单指令也有复杂指令,早期的CPU全部都是CISC架构。
后来人们发现典型程序中80%的语句都是使用计算机中20%的指令,而这20%的指令都属于简单指令;因此花再多时间去研究复杂指令,也仅仅只有20%的使用概率,并且复杂指令会影响计算机的执行速度。既然典型程序的80%都是使用简单指令完成,那剩下的20%语句用简单语句来重新组合一下模拟这些复杂指令就行了,而不需要使用这些复杂指令,于是RISC就出现了。
2 CPU发展
2.1 发展史
CPU从4位到8位、16位、32位处理器,最后到64位处理器,从各厂商互不兼容到不同指令集架构规范的出现,CPU 自诞生以来一直在飞速发展。
CPU的发展通常被分为六个阶段。
① 第一阶段1971-1973,4位和8位低档微处理器时代,代表产品Inter 4004处理器。
1971年,Intel生产的4004微处理器将运算器和控制器集成在一个芯片上,标志着CPU的诞生;
1978年,8086处理器的出现奠定了X86指令集架构, 随后8086系列处理器被广泛应用于个人计算机终端、高性能服务器以及云服务器中。
② 第二阶段1974-1977,8位中高档微处理器时代,代表产品Inter 8080。
③ 第三阶段1978-1984,16位微处理器时代,代表产品Inter 8086。
④ 第四阶段1985-1992,32位微处理器时代,代表产品是Intel 80386。已经可以胜任多任务、多用户的作业。
1989 年发布的80486处理器实现了5级标量流水线,标志着CPU的初步成熟,也标志着传统处理器发展阶段的结束。
⑤ 第五阶段1993-2005,奔腾系列微处理器时代,1995 年11 月,Intel发布了Pentium处理器,该处理器首次采用超标量指令流水结构,引入了指令的乱序执行和分支预测技术,大大提高了处理器的性能, 因此,超标量指令流水线结构一直被后续出现的现代处理器,如AMD的锐龙、Intel的酷睿系列等所采用。
⑥ 第六阶段2005至今,处理器逐渐向更多核心,更高并行度发展。典型的代表有英特尔的酷睿系列处理器和AMD的锐龙系列处理器。为了满足操作系统的上层工作需求,现代处理器进一步引入了诸如并行化、多核化、虚拟化以及远程管理系统等功能,不断推动着上层信息系统向前发展。
注1:CPU执行一条指令需要经过以下阶段:取指->译码->地址生成->取操作数->执行->写回,每个阶段都要消耗一个时钟周期,同时每个阶段的计算结果在周期结束以前都要发送到阶段之间的锁存器上,以供下一个阶段使用。
注2:流水线技术是一种将每条指令分解为多步,并让各步操作重叠,从而实现几条指令并行处理的技术。
程序中的指令仍是一条条顺序执行,但可以预先取若干条指令,并在当前指令尚未执行完时,提前启动后续指令的另一些操作步骤。这样显然可加速一段程序的运行过程。超流水线:以增加流水线级数的方法来缩短机器周期,相同的时间内超级流水线执行了更多的机器指令(以时间换空间)。
超标量:在CPU中有一条以上的流水线,并且每时钟周期内可以完成一条以上的指令(以空间换时间)。
超标量处理器执行指令的方式包括顺序执行(in-order)和乱序执行(out-of-order)。
顺序执行是指指令的执行必须遵循程序中指定的顺序;
乱序执行是指指令在流水线中不遵循程序中指定的顺序执行,一旦某条指令的操作数准备好就可以进行执行。
注3:经典RISC处理器的流水线
1 Fetch 取指令:PC寄存器值作为地址,从I-Cache中取址并存储到指令寄存器。
2 Decode 译码:将指令解码,并根据结果读取寄存器堆,得到指令的源操作数。
3 Execute 执行:根据指令完成计算任务。
4 Memory 访存:访问D-Cache,不访问存储器的指令此阶段不做任何事情。
5 Write Back 回填:如果指令存在目的寄存器,将指令结果写入目的寄存器。
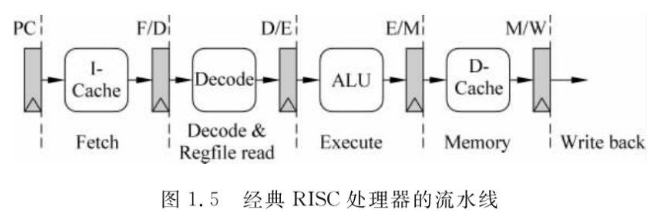
注4:流水线冒险,即在下一个时钟周期中的下一条指令无法执行。分为结构冒险、数据冒险和控制冒险。
数据冒险(数据相关性):当指令在流水线中重叠执行,后面指令需要前面指令的执行结果,而前面的指令尚未写回导致的冲突。
数据相关性的三种情况:RAW read after write 先写后读,WAW write after write 先写后写,WAR write after read 先读后写。
举例:RAW,如果②指令在①指令前,引起逻辑错误。
① R1=R2+R3
② R5=R1+R4
解决方法:处理器核按顺序派遣、顺序写回,则不可能发生WAR相关性造成的数据冲突。
举例:WAW,如果②指令在①指令前,引起逻辑错误。
① R1=R2+R3
② R1=R5+R4
解决方法:采用outstanding instruction track fifo(OITF)模块。
举例:WAR,如果②指令在①指令前,引起逻辑错误。
① R1=R2+R3
② R2=R5+R4
解决方法:采用outstanding instruction track fifo(OITF)模块。
结构冒险(资源冲突):当一条指令需要的硬件部分还在为之前的指令工作,无法为这条指令服务导致的冲突。
同时读写存储器
解决方法:①流水线停顿stall。②设置单独的指令高速缓存和数据高速缓存。
同时读写寄存器
解决方法:前半个周期写,后半个周期读,并且设置独立的读写端口。
控制冒险:如果想要执行某条指令,是由之前指令的运行结果决定,而现在那条之前的指令结果还没产生,导致了控制冒险。
解决方法:流水线停顿;缩短分支延迟;延迟转移。
详见:关于流水线的三种冒险
2.2 行业产业链
行业产业链上游为半导体材料和设备供应环节,主要包括硅晶圆、电子特气、光刻胶、靶材等半导体材料,以及单晶炉、PVD、光刻机、检测设备等半导体设备。
产业链中游为CPU芯片设计、制造及封装测试环节,代表厂商有韦尔股份、紫光展锐、华大半导体、炬芯科技、国民技术、北京君正、龙芯中科、全志科技、国科微、紫光国微、国芯科技等。
产业链下游为CPU芯片应用领域,主要包括PC、平板电脑、通信及智能手机、智能穿戴、汽车电子、工业、医疗等。
2.3 英特尔 Xeon 至强处理器
英特尔 Xeon是英特尔生产的面向服务器和工作站的处理器,其特点是低频多核,多线程运行强,功耗低相对稳定。
Purley平台:Sky Lake 第一代,Cascade Lake 第二代;
Whitley平台:Cooper Lake、Ice Lake 第三代;
Eagle Stream平台:Sapphire Rapids 第四代、Emerald Rapids 第五代
Birch Stream平台:Granite Rapids、Sierra Forest 第六代
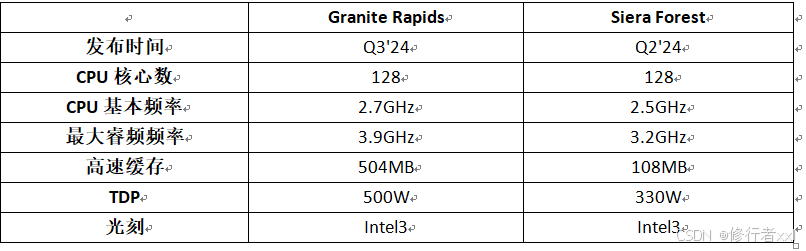
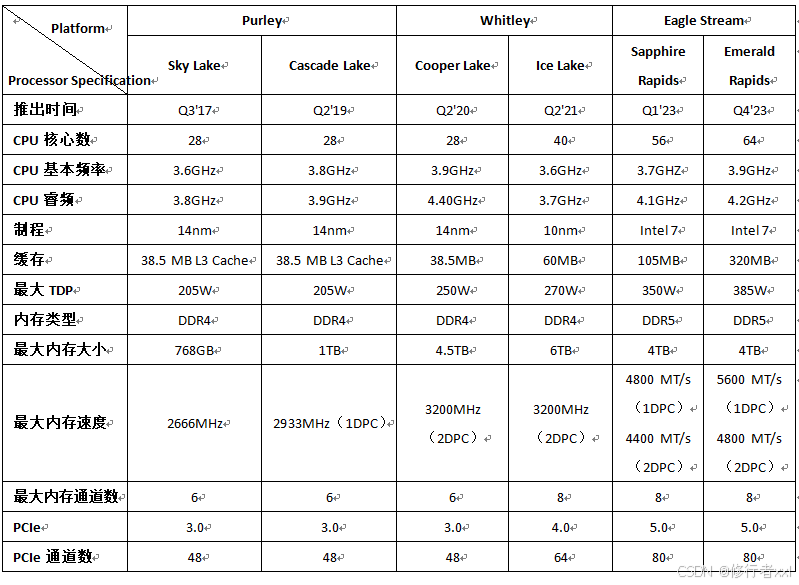
图源:Intel Xeon(至强) 服务器 CPU
由图可见,从第一代到第六代,CPU核数变化较大,从28到128。
注:TDP(Thermal Design Power,散热设计功耗),对应系列CPU在满负荷(CPU 利用率为100%的理论上)可能会达到的最高散热热量,散热器必须保证在处理器TDP最大的时候,处理器的温度仍然在设计范围之内。
TDP设定越大,性能表现越强,但表明CPU在工作时会产生的热量越大。TDP也可以看做是功耗墙,当主板检测到当前处理器功耗达到设定值时,就会进行降频等行为以保障系统整体的稳定性。
对于散热系统来说,就需要将TDP作为散热能力设计的最低指标/基本指标。
以Core i7-8700K处理器为例,它的TDP是95W,指的就是散热器需要提供不低于95W的散热能力。需要注意的是,TDP是热设计功耗,不等于处理器功耗,是处理器损耗的热功耗,英特尔特别强调它不是处理器的最大功耗。
TDP功耗测试不仅是跑基础频率,还不会涉及处理器的 AVX 浮点测试,而浮点单元现在是CPU功耗的大头,跑不同的应用功耗差距极大就是这个因素导致的。尽管TDP不等于实际耗电功率,但它确实提供了一个参考点来估计CPU的功耗水平。
对于高性能CPU,尤其是在高负载情况下,实际耗电功率可能会接近甚至超过TDP值。在低负载或空闲状态下,CPU的实际耗电功率通常远低于其TDP。核心层面的处理器功耗分布:如果不涉及浮点运算,那么处理器中Cache缓存部分消耗了45%的功耗,OOO乱序执行/预测单元消耗21%的功耗,检测网站是否被劫持,再次就是TLB单元了。但是运算要是涉及到了FP浮点单元,情况就不一样了,FP浮点单元的功耗能占到75%,剩下的部分才是缓存、OOO以及TLB等等。
芯片层面的功耗分布:FP浮点单元依然是大头,占比达到了45%,Uncore非核心部分的功耗占比达到了40%,整数单元、OOO、预读、TLB之类的单元就更微不足道了。
英特尔Xeon可扩展处理器编号由4位数字组成:
第一个数字表示处理器级别:8、9表示铂金Platinum,6、5表示金Gold,4表示银Silver,3表示青铜Bronze。
第二个数字表示处理器代次。
铂金Platinum:适用于计算性能和数据处理能力要求高的应用场景:大规模数据中心、高性能计算、企业级数据库。
金Gold:适用于中高端企业级应用,性价比较高。
银Silver:适用于中小型企业或部门级部署:轻量级虚拟化、入门级服务器。
铜Bronze:面向预算有限、性能要求不高:边缘计算节点、个人工作站、基础网络服务。
详见官网:了解可扩展处理器英特尔® 至强®:数字和后缀
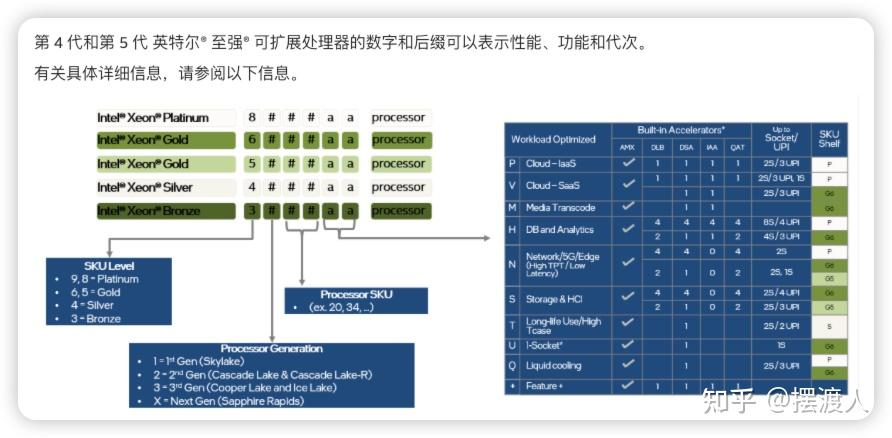
下图为第五代Xeon产品
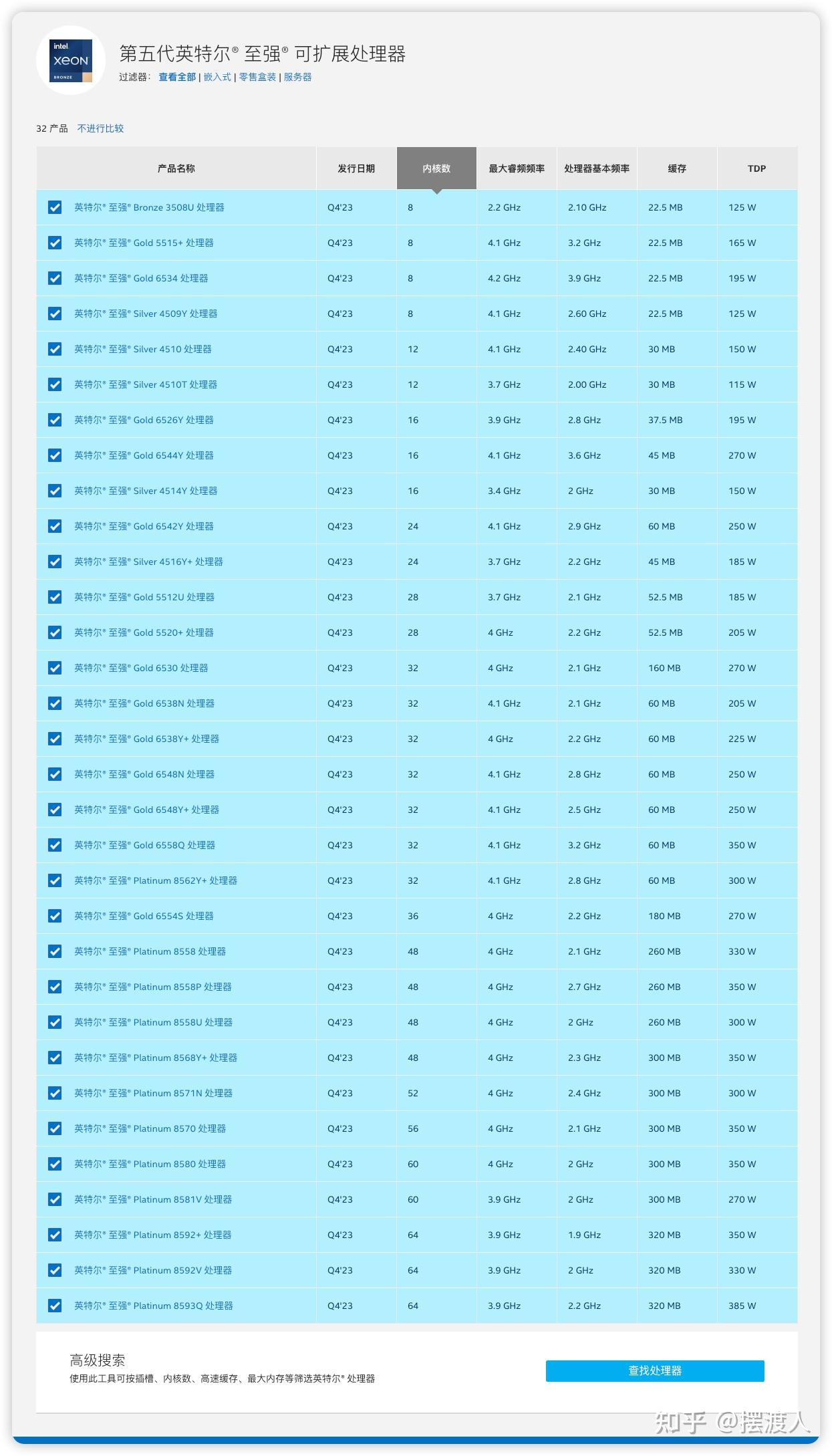
图源:Inter至强处理器命名规则-【学习笔记】
2.4 AMD Zen架构
AMD在2017年正式推出了基于Zen微架构的Ryzen消费端处理器,体现IPC、频率、功耗以及面积四者的平衡。
【处理器与AI芯片】AMD-Zen架构
补充
1 寄存器、存储器、内存、缓存、硬盘区别与联系?
寄存器用于即时计算;缓存用于加速对内存的访问;内存用于运行中的程序和数据;SSD/HDD用于长期数据存储。
数据通常按照“硬盘 -> 内存 -> 缓存 -> 寄存器”的路径被加载到CPU进行处理。这种层次结构的设计旨在优化系统性能,通过将常用数据尽可能靠近CPU来加快处理速度。

CPU内部存在的存储器叫做寄存器,用来暂时存放数据或指令。
内存是CPU能够直接寻址访问的存储空间(不在CPU内部),是CPU与外存通信的桥梁。
RAM,Random Access Memory,随机访问存储器。可读取、可写入,断电后数据消失。
DRAM,动态随机存储。存储单元是由电容和相关元件组成的,电容存在漏电现象,电荷不足会导致存储单元数据出错,所以DRAM需要周期性刷新,以保持电荷状态。DRAM结构较简单且集成度高,通常用于制造内存条中的存储芯片。
SRAM,静态随机存储。存储单元是由晶体管和相关元件做成的锁存器,每个存储单元具有锁存“0”和“1”信号的功能。它速度快且不需要刷新操作,但集成度差和功耗较大,通常用于制造容量小但效率高的CPU缓存。
ROM,Read Only Memory,只读存储器。只能读入,不能写入。即使处于停电状态,这些信息也不会丢失。ROM一般用于存放计算机的基本程序和数据,如BIOS芯片。
Cache,高速缓冲存储器。介于CPU与内存之间,是一个读写速度比内存更快的存储器,用来临时存放最近或最频繁访问的数据和指令。
当CPU向内存读取或者存入数据时,这些数据也会被存储进Cache中。当CPU再次需要访问这些数据时,CPU就从Cache中读取数据,而不是去访问速度较慢的内存,当然了,如果Cache中没有需要的数据,CPU会去访问内存,读取需要的数据。
内存包括由CLK(时钟clock)驱动的寄存器;由SRAM制成的高速缓冲缓存器
电脑开机的时候CPU直接读取BIOS指令,BIOS芯片也是ROM。
2 浮点单元
浮点处理单元(floating point unit,FPU)是运行浮点运算的结构。
FPU通常与CPU集成在一起,用于提供高效的浮点运算能力。
通过使用浮点计算单元,计算机能够在处理需要高精度浮点数运算的应用程序中,如科学计算、图形处理、物理模拟等,提供更加高效和精确的计算能力。
参考
[1] 一文介绍CPU(定义、分类、发展历史、工作原理、应用、国产化)
[2] 冯诺依曼体系
[3] 服务器内部细节:CPU、内存、硬盘等
[4] 中央处理器
[5] (计算机组成原理)RISC与CISC的区别
[6] CPU的发展历史和工作原理
[7] 超标量处理器流水线
[8] 关于流水线的三种冒险
[9] 主存、辅存、内存、外存、存储器是什么?还傻傻分不清楚?看完这一篇就够了
[10] 计算机中CPU、内存、缓存的关系
[11] Inter至强处理器命名规则-【学习笔记】
[12] TDP是什么 CPU TDP和最大功率的关系(转)

)
















——MariaDB使用)
