目录
1 均值滤波
2 方框滤波
3 高斯滤波
4 中值滤波
5 双边滤波
6 小结
噪声:图像中的一些干扰因素。通常是由于图像采集设备、传输信道等因素造成的,表现为图像中随机的亮度。常见的噪声类型有高斯噪声和椒盐噪声。高斯噪声是一种分布符合正态分布的在噪声,会使图像变得模糊或有噪点。椒盐噪声则是一些黑白色的像素值分布在原图像上。
 |  |  |
| 高斯噪声 | 原图 | 椒盐噪声 |
滤波器也叫卷积核,工作原理也是在原图上进行滑动并计算中心像素点的像素值。分为线性滤波器和非线性滤波器,线性滤波器对领域中的像素进行线性运算,如在核的范围内进行加权求和。常见的线性滤波器有均值滤波、高斯滤波等。非线性滤波器则是利用原始图像与模板之间的一种逻辑关系得到结果,常见的非线性滤波器有中值滤波器、双边滤波器等/
滤波与模糊的练习与区别:
- 都属于卷积,不同滤波方法之间知识卷积核的不同(对线性滤波而言)
- 低通滤波器是模糊,高通滤波器是锐化
- 低通滤波器就是允许低频信号通过,在图像中边缘和噪点都相当于高频部分,所以低通滤波器用于去除噪点、平滑和模糊图像。高通滤波器则反之,用来增强图像边缘,进行锐化处理。
注意:椒盐噪声可以理解为斑点,随机出现在图像中的黑点或白点;高斯噪声可以理解为拍摄图片时由于光照等原因造成的噪声。
1 均值滤波
最简单的滤波处理,取得是卷积核区域内元素的均值,如3x3卷积核:
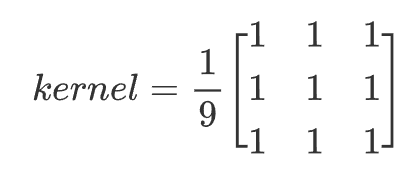
比如有一张4*4的图片,现在使用一个3*3的卷积核进行均值滤波时,其过程如下所示:

对于边界的像素点,则会进行边界填充,以确保卷积核的中心能够对准边界的像素点进行滤波操作。在OpenCV中,默认的是使用BORDER_REFLECT_101的方式进行填充,下面的滤波方法中除了中值滤波使用的是BORDER_REPLICATE进行填充之外,其他默认也是使用这个方式进行填充,通过卷积核在原图上从左上角滑动计算到右下角,从而得到新的4*4的图像的像素值。

案例:
import cv2 as cv
img_old = cv.imread("./images/lvbo2.png")
img = cv.resize(img_old,(480,480))
img_jy = cv.imread("./images/lvbo3.png")
# 均值滤波:cv2.blur(img,ksize)
img_blur = cv.blur(img,(3,3),borderType=cv.BORDER_REFLECT_101)
cv.imshow("img",img)
cv.imshow("img_blur",img_blur)
cv.waitKey(0)
cv.destroyAllWindows()输出:
 |  |
| 原图 | 均值滤波 |
2 方框滤波
方框滤波跟均值滤波很像,如3×3的滤波核如下:
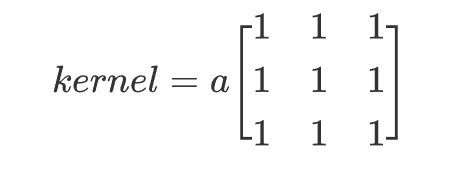
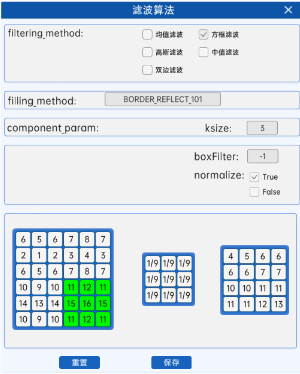
在滤波算法组件中,当参数filtering_method选为方框滤波时,参数component_param为ksize,ddepth,normalize。下面讲解这3个参数的含义:

-
ksize:代表卷积核的大小,eg:ksize=3,则代表使用3×3的卷积核。
-
ddepth:输出图像的深度,-1代表使用原图像的深度。
-
图像深度是指在数字图像处理和计算机视觉领域中,每个像素点所使用的位数(bit depth),也就是用来表示图像中每一个像素点的颜色信息所需的二进制位数。图像深度决定了图像能够表达的颜色数量或灰度级。
-
-
normalize:当normalize为True的时候,方框滤波就是均值滤波,上式中的a就等于1/9;normalize为False的时候,a=1,相当于求区域内的像素和。
 |  |
| normalize=True | normalize=False |
案例:
import cv2 as cv
img_old = cv.imread("./images/lvbo2.png")
img = cv.resize(img_old,(480,480))
img_jy = cv.imread("./images/lvbo3.png")# 方框滤波:cv2.boxFilter(img,ddepth,ksize,normalize)
img_box1 = cv.boxFilter(img,-1,(3,3),normalize=True)# 相当于均值滤波
img_box2 = cv.boxFilter(img,-1,(3,3),normalize=False) # 把区域内的像素值全部相加
cv.imshow("img_box2",img_box2)
cv.waitKey(0)
cv.destroyAllWindows()输出:
 |  |
| 原图 | 方框滤波 |
3 高斯滤波
-
高斯滤波是一种常用的图像处理技术,主要用于平滑图像、去除噪声。它通过使用高斯函数(正态分布)作为卷积核来对图像进行模糊处理。
高斯滤波的卷积核权重并不相同:中间像素点权重最高,越远离中心的像素权重越小。还记得我们在自适应二值化里是怎么生成高斯核的吗?这里跟自适应二值化里生成高斯核的步骤是一样的,都是以核的中心位置为坐标原点,然后计算周围点的坐标,然后带入下面的高斯公式中。
其中,x和 y 是相对于中心点的坐标偏移量,σ 是标准差,控制着高斯函数的宽度和高度。较大的 σ 值会导致更广泛的平滑效果。
卷积核通常是一个方形矩阵,其元素值根据高斯函数计算得出,并且这些值加起来等于1,近似于正态分布,以确保输出图像的亮度保持不变。
其中的值也是与自适应二值化里的一样,当时会取固定的系数,当kernel大于7并且没有设置时,会使用固定的公式进行计算的值:
我们还是以3*3的卷积核为例,其核值如下所示:

得到了卷积核的核值之后,其滤波过程与上面两种滤波方式的滤波过程一样,都是用卷积核从图像左上角开始,逐个计算对应位置的像素值,并从左至右、从上至下滑动卷积核,直至到达图像右下角,唯一的区别就是核值不同。
在滤波算法组件中,当参数filtering_method选为高斯滤波,参数component_param为ksize,sigmaX。下面讲解这2个参数的含义:

ksize:代表卷积核的大小,eg:ksize=3,则代表使用3×3的卷积核。
sigmaX:就是高斯函数里的值,σx值越大,模糊效果越明显。高斯滤波相比均值滤波效率要慢,但可以有效消除高斯噪声,能保留更多的图像细节,所以经常被称为最有用的滤波器。均值滤波与高斯滤波的对比结果如下(均值滤波丢失的细节更多):

案例:
import cv2 as cv
img_old = cv.imread("./images/lvbo2.png")
img = cv.resize(img_old,(480,480))
img_jy = cv.imread("./images/lvbo3.png")# 高斯滤波:cv2.GaussianBlur(img,ksize,sigmax)
img_gauss = cv.GaussianBlur(img,(3,3),0.5)
# cv.imshow("img_gauss",img_gauss)
cv.waitKey(0)
cv.destroyAllWindows()输出:
 |  |
| 原图 | 高斯滤波 |
4 中值滤波
中值又叫中位数,是所有数排序后取中间的值。中值滤波没有核值,而是在原图中从左上角开始,将卷积核区域内的像素值进行排序,并选取中值作为卷积核的中点的像素值,其过程如下所示:
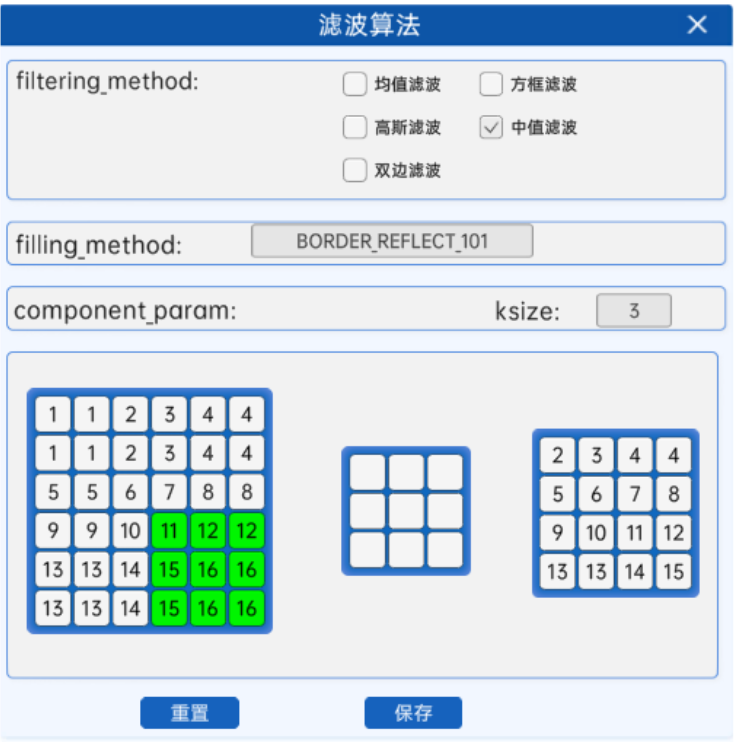
中值滤波就是用区域内的中值来代替本像素值,所以那种孤立的斑点,如0或255很容易消除掉,适用于去除椒盐噪声和斑点噪声。中值是一种非线性操作,效率相比前面几种线性滤波要慢。
比如下面这张斑点噪声图,用中值滤波显然更好:

在滤波算法组件中,当参数filtering_method选为中值滤波,参数component_param为ksize,代表卷积核的大小,eg:ksize=3,则代表使用3×3的卷积核。
案例:
import cv2 as cv
img_old = cv.imread("./images/lvbo2.png")
img = cv.resize(img_old,(480,480))
img_jy = cv.imread("./images/lvbo3.png")
# 中值滤波:cv2.medianBlur(img,ksize)
img_median = cv.medianBlur(img_jy,3)
cv.imshow("img_jy",img_jy)
cv.imshow("img_median",img_median)
cv.waitKey(0)
cv.destroyAllWindows()输出:
 |  |
| 原图 | 中值滤波 |
5 双边滤波
模糊操作基本都会损失掉图像细节信息,尤其前面介绍的线性滤波器,图像的边缘信息很难保留下来。然而,边缘(edge)信息是图像中很重要的一个特征,所以这才有了双边滤波。

可以看到,双边滤波明显保留了更多边缘信息,下面来介绍一下双边滤波。
双边滤波的基本思路是同时考虑将要被滤波的像素点的空域信息(周围像素点的位置的权重)和值域信息(周围像素点的像素值的权重)。为什么要添加值域信息呢?是因为假设图像在空间中是缓慢变化的话,那么临近的像素点会更相近,但是这个假设在图像的边缘处会不成立,因为图像的边缘处的像素点必不会相近。因此在边缘处如果只是使用空域信息来进行滤波的话,得到的结果必然是边缘被模糊了,这样我们就丢掉了边缘信息,因此添加了值域信息。
双边滤波采用了两个高斯滤波的结合,一个负责计算空间邻近度的权值(也就是空域信息),也就是上面的高斯滤波器,另一个负责计算像素值相似度的权值(也就是值域信息),也是一个高斯滤波器。其公式如下所示:
其中,
-
:指以
为中心的邻域的范围
-
:输入的点的像素值,也就是在原始图像中位置
的像素值。
-
:这是权重函数,它决定了位置
-
:表示中心点
-
分子:
-
这是对邻域内所有像素值
的乘积求和。这一步计算了加权后的像素值总和。
-
-
分母:
-
这是对邻域内所有像素的权重
-
-
计算过程:
-
确定邻域:选择一个以
-
计算权重:对于邻域内的每个像素
-
加权求和:将邻域内每个像素值
-
归一化:将加权求和的结果除以权重总和,得到最终的像素值
-
上述公式我们进行转化,假设公式中为
,则有
设,则有
此时可以看到,这与上面的滤波中计算过程已经一模一样了,就代表了第一个点的权重。接下来我们看看
是怎么来的,令
而
可以看到,对于来说,这就是普通的高斯滤波函数,其带入的坐标是坐标值,
是程序输入值,该函数是在空间临近度上计算的。而
是计算像素值相似度,也是高斯函数带入坐标值,然后得到对应点的像素值,进行两个点像素值插值的绝对值的平方。也就是说,双边滤波的核值不再是一个固定值,而是随着滤波的过程在不断发生变化的。
在本实验中的滤波算法组件中,当参数filtering_method选为双边滤波,参数component_param为ksize,d,sigmaColor,sigmaSpace,下面讲解这4个参数的含义:
-
ksize:卷积核的大小
-
d:过滤时周围每个像素领域的直径,这里已经设置了核大小。d=9===>9x9
-
sigmaColor:在color space(色彩空间)中过滤sigma。参数越大,那些颜色足够相近的的颜色的影响越大。较大的
sigmaColor值意味着更大的颜色差异将被允许参与到加权平均中,从而使得颜色相近但不完全相同的像素也能够相互影响。 -
sigmaSpace:在coordinate space(坐标空间)中过滤sigma。这个参数是坐标空间中的标准差,决定了像素位置对滤波结果的影响程度。它定义了在图像的空间域中,一个像素可以影响周围像素的最大距离。换句话说,它控制着滤波器作用的范围大小。
关于2个sigma参数:
简单起见,可以令2个sigma的值相等;
如果他们很小(小于10),那么滤波器几乎没有什么效果;
如果他们很大(大于150),那么滤波器的效果会很强,使图像显得非常卡通化。
关于参数d:
过大的滤波器(d>5)执行效率低。
对于实时应用,建议取d=5;
对于需要过滤严重噪声的离线应用,可取d=9;
案例:
import cv2 as cv
img_old = cv.imread("./images/lvbo2.png")
img = cv.resize(img_old,(480,480))
img_jy = cv.imread("./images/lvbo3.png")# 双边滤波:使用两个高斯核
img_bilate = cv.bilateralFilter(img_jy,9,140,140)
cv.imshow("img_bilate",img_bilate)
cv.waitKey(0)
cv.destroyAllWindows()输出:
 |  |
| 原图 | 双边滤波 |
6 小结
优先高斯滤波,然后均值滤波
斑点和椒盐噪声优先使用中值滤波
去除噪点的同时保留边缘信息使用双边滤波
线性滤波:均值滤波、方框滤波、高斯滤波(速度相对较快)
非线性滤波:中值滤波、双边滤波(速度相对较慢)






简介与简单示例)



)

![[python刷题模板] LogTrick](http://pic.xiahunao.cn/[python刷题模板] LogTrick)

![[2025CVPR-图象分类方向]CATANet:用于轻量级图像超分辨率的高效内容感知标记聚合](http://pic.xiahunao.cn/[2025CVPR-图象分类方向]CATANet:用于轻量级图像超分辨率的高效内容感知标记聚合)




