1 引言
在构建基于知识库的问答系统时,"语义匹配" 是核心难题 —— 如何让系统准确识别 "表述不同但含义相同" 的问题?比如用户问 "对亲人的期待是不是欲?",系统能匹配到知识库中 "追名逐利是欲,那对孩子和亲人的有所期待是不是欲?" 的答案。
2 系统原来的实现方式
原来的系统是用 BERT 生成句向量并实现匹配的。核心逻辑集中在_get_embedding(生成向量)和search(匹配答案)两个方法中。
BERT 本身并不直接输出 "句向量",需要手动从模型输出中提取特征并处理,原来的核心思路是:
- BERT 的每一层隐藏层都包含不同粒度的语义(浅层偏字面,深层偏抽象)
- 融合最后 4 层的特征,并用手动设置的权重([0.15, 0.25, 0.35, 0.25])调整各层的重要性
- 用 [CLS] 标记的向量代表整个句子的语义
生成向量后,需要计算用户问题与知识库中所有问题的相似度
BERT 预训练时通过 NSP 学到的 “句子间语义关联能力”,已经内化为模型参数。这种能力会间接体现在句向量中:
- 例如,BERT 能理解 “亲人” 和 “孩子” 在 “亲近关系” 上的共性,“期待” 和 “期望” 的同义性 —— 这些都是 MLM 和 NSP 任务中学习到的语言知识;
- 系统通过融合 BERT 隐藏层向量,间接利用了这些知识,让生成的句向量具备基础语义区分能力。
“加权融合隐藏层” 是为了弥补原始 BERT 句向量生成能力的不足而设计的关键步骤。它的核心作用是整合 BERT 不同层的语义特征,生成更全面的句向量;
- 浅层(如第 1-4 层):更关注字面信息(如词汇本身、简单搭配)。例如 “对亲人的期待”,浅层可能更关注 “亲人”“期待” 这些词的字面含义;
- 深层(如第 9-12 层):更关注抽象语义(如句子整体意图、逻辑关系)。例如深层能捕捉到 “对亲人的期待” 本质是 “一种情感诉求”。
3 BERT 的痛点
BERT 作为预训练语言模型,在句子级任务中,它有两个明显局限:
3.1 计算效率低下
BERT 本身是为 “词级” 理解设计的(如完形填空、命名实体识别)。
通常获得句子向量的方法有两种:
1.计算所有 Token 输出向量的平均值
2.使用[cLs]位置输出的向量
若要计算两个句子的相似度,需将两个句子拼接成 [CLS] 句子A [SEP] 句子B [SEP] 作为输入,通过模型输出的 [CLS] 向量判断相似度。
计算量随候选集规模线性增长
3.2 句子级语义捕捉不足
BERT 的 [CLS] 向量虽能代表句子语义,但本质是为 “句子对分类” 任务优化的(如判断两个句子是否同义),并非专门为 “单个句子的语义嵌入” 设计。在问答系统中,常出现 “语义相近但表述差异大” 的问题匹配不准的情况。
具体来说,当用 BERT 做 “判断两个句子是否同义” 时,输入格式是固定的:[CLS] 句子A [SEP] 句子B [SEP]。
BERT 输出的 [CLS] 向量(常用来代表整体语义),是 “针对句子 A 和句子 B 的关系” 生成的 —— 它包含的是 “两个句子如何关联” 的信息,而非 “句子 A 单独的语义” 或 “句子 B 单独的语义”。
单独输入句子 A([CLS] 句子A [SEP]),BERT 的 [CLS] 向量缺乏句子 B,生成的向量无法稳定代表句子 A 的语义。
句子对分类任务:输入两个句子,判断它们的关系(如 “是否同义”“是否存在因果关系”“是否矛盾”)。
例:输入 “我喜欢苹果” 和 “苹果是我爱的水果”,模型判断 “同义”(输出分类结果)。单个句子的语义嵌入:为单个句子生成一个向量(数字列表),这个向量需要 “完整代表句子的语义”—— 即 “语义越近的句子,向量越相似”。
例:“我喜欢苹果” 和 “我喜爱苹果” 的向量应该非常接近;和 “我讨厌香蕉” 的向量应该差异很大。
举例:
BERT 就像一台 “双人对比秤”:它擅长测量 “两个人的体重差”(句子对关系),但如果单独测一个人的体重(单个句子向量),结果可能不准(因为它的刻度是为 “对比” 设计的)。
而 “单个句子的语义嵌入” 需要的是 “单人精准秤”:能稳定测量单个人的体重,且两个人的体重数值可以直接比较(比如 “60kg” 和 “61kg” 接近,“60kg” 和 “80kg” 差异大)。
4 Sentence-BERT(SBERT)
Sentence-BERT(SBERT)是专门为 "句子级语义任务" 设计的模型,它在 BERT 基础上做了针对性优化,完美解决了上述问题。
Sentence-BERT(SBERT)的作者对预训练的 BERT 进行修改:
微调+使用 Siamese and TripletNetwork(孪生网络和三胞胎网络)生成具有语义的句子 Embedding 向量。
语义相近的句子,其 Embedding 向量距离就比较近,从而可以使用余弦相似度、曼哈顿距离、欧氏距离等找出语义相似的句子。这样 SBERT 可以完成某些新的特定任务,比如聚类、基于语义的信息检索等
4.1 孪生网络(Siamese)
模型结构
核心思想是 “用两个共享参数的子网络,学习两个输入的相似度”。它不像普通分类网络那样直接输出类别,而是专注于判断 “两个输入是否相似”。
如下图
- 包含两个结构完全相同、参数完全共享的子网络(可以是 CNN、RNN、BERT 等任意网络);
- 两个子网络接收不同输入(如两个句子),分别提取特征;
- 最后通过一个 “对比层” 计算两个特征的相似度,输出 “两个输入是否相似” 的判断。
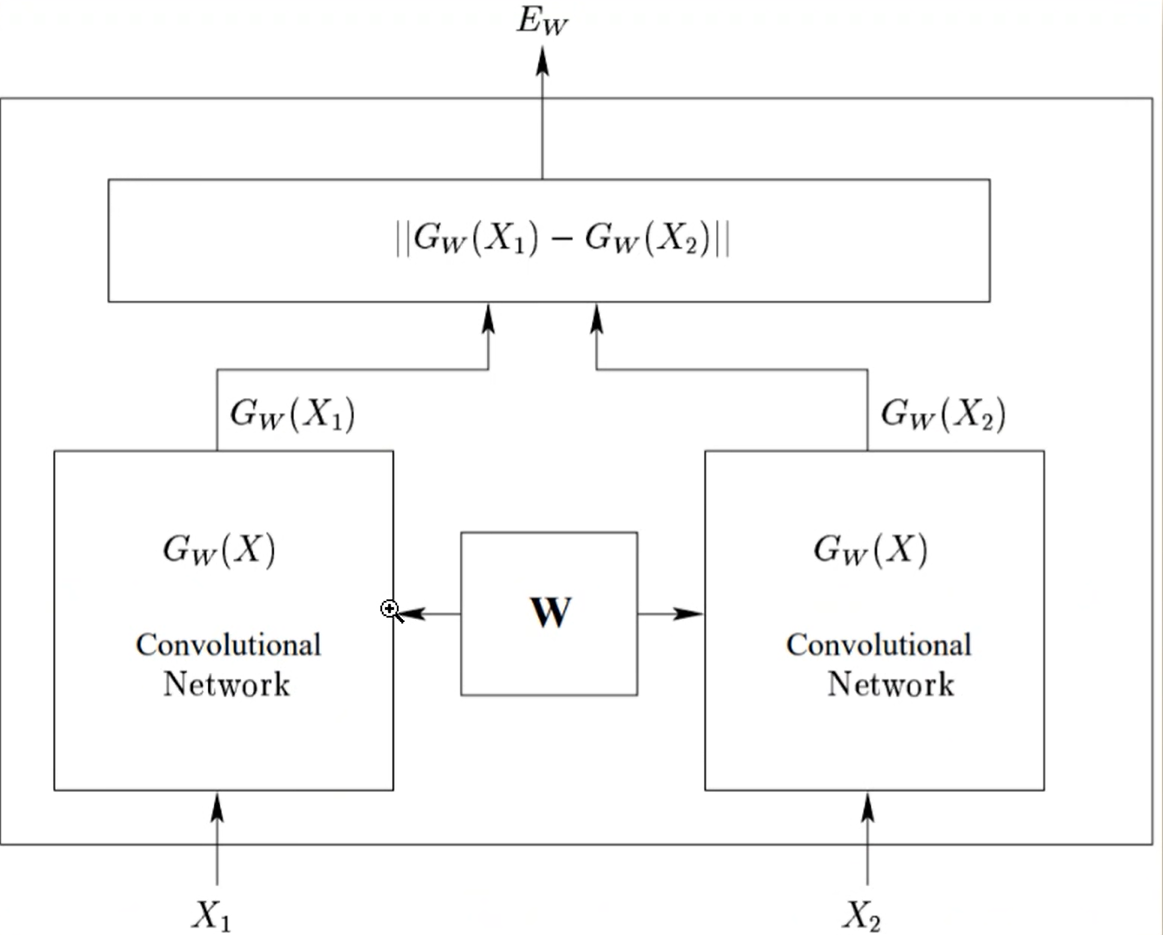
SBERT本质上是 “孪生网络 + BERT + 对比学习” 的组合,专门解决句子语义相似度问题。
SBERT 的两个子网络就是 BERT,通过共享参数提取句子向量。传入两个句子,通过计算损失,反向传播更新参数。对比层用余弦相似度计算向量距离,同时通过对比学习(训练时让相似句子向量更近)优化向量分布;
(注意传入第一个句子时没有办法进行梯度回传更新参数)
损失函数

输入:两个待比较的对象
输入 A:用户问题 “对亲人的期待是不是欲?”
输入 B:知识库问题 “对孩子的期待属于欲望吗?”
特征提取:两个子网络生成特征向量
输入 A 进入子网络 1,生成特征向量 V1(比如通过 BERT 提取的语义向量);
输入 B 进入子网络 2(和子网络 1 结构、参数完全相同),生成特征向量 V2;
关键:因为参数共享,两个子网络对 “相似语义” 的理解标准完全一致(比如 “期待” 和 “期望” 会被映射到相近的向量)。
(这里还是通过计算所有 Token 输出向量的平均值或者使用[cLs]位置输出的向量来获得句向量)
对比:计算向量相似度,输出判断结果
通过 “对比层” 计算 V1 和 V2 的相似度(如余弦相似度、欧氏距离);
若相似度高于阈值(如 0.8),判断为 “相似”(匹配成功);否则为 “不相似”。
5 总结
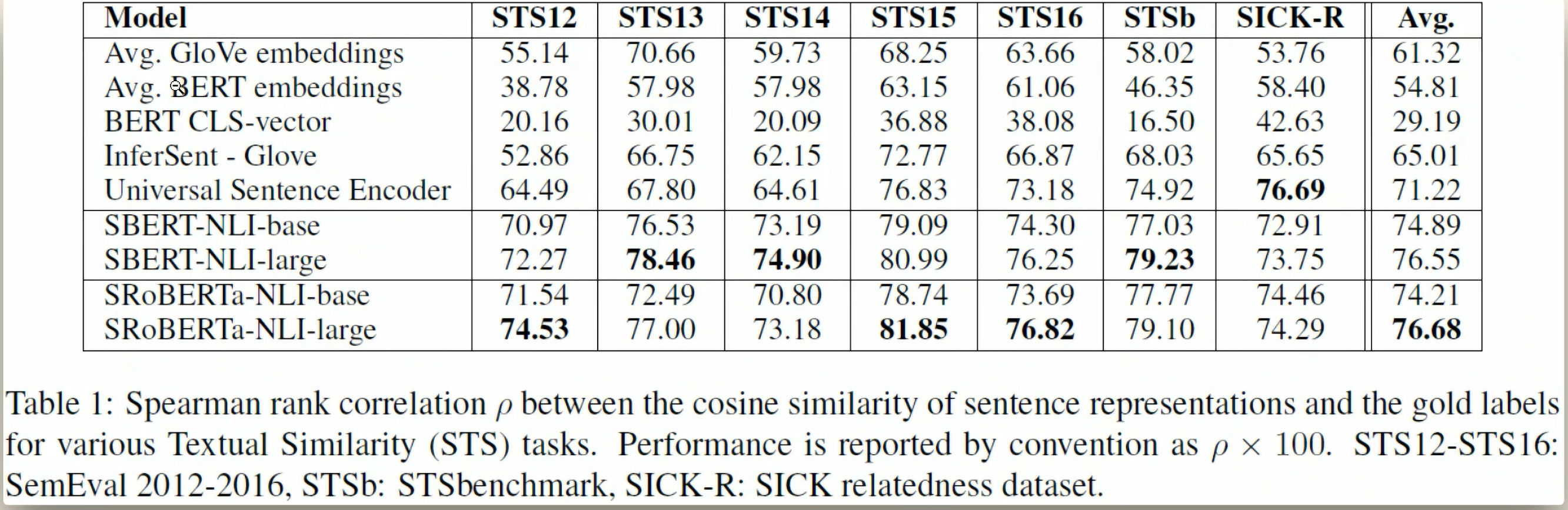
对比原始 BERT 的实现,SBERT 的优势明显:
- 无需手动提取隐藏层(省去
hidden_states[-4:]相关逻辑) - 无需加权融合(模型内置最优融合策略)
- 支持批量编码(
model.encode(questions)直接处理列表)





)


)




)




)
)