背景
虽然模型基本都是表格数据那一套了,算法都没什么新鲜点,但是本次数据还是很值得写个案例的,有征信数据,各种,个人,机构,逾期汇总.....
这么多特征来做机器学习模型应该还不错。本次带来,在实际生产业务中,拿到一大堆的表,怎么对这些数据进行合并,清洗整理,特征工程,然后机器学习建模,评估模型效果。
数据介绍
本次数据主要分这么多表格:
"contest_basic
(基础表-数据集)"
"contest_ext_crd_hd_report
(机构版征信-报告主表)""contest_ext_crd_cd_ln
(机构版征信-贷款)""contest_ext_crd_cd_lnd
(机构版征信-贷记卡)""contest_ext_crd_is_creditcue
(机构版征信-信用提示)""contest_ext_crd_is_sharedebt
(机构版征信-未销户贷记卡或者未结清贷款)""contest_ext_crd_is_ovdsummary
(机构版征信-逾期(透支)信息汇总)""contest_ext_crd_qr_recordsmr
(机构版征信-查询记录汇总)""contest_ext_crd_qr_recorddtlinfo
(机构版征信-信贷审批查询记录明细)""contest_ext_crd_cd_ln_spl
(机构版征信-贷款特殊交易)""contest_ext_crd_cd_lnd_ovd
(机构版征信-贷记卡逾期/透支记录)"
表格里面都有各种的详细的字段
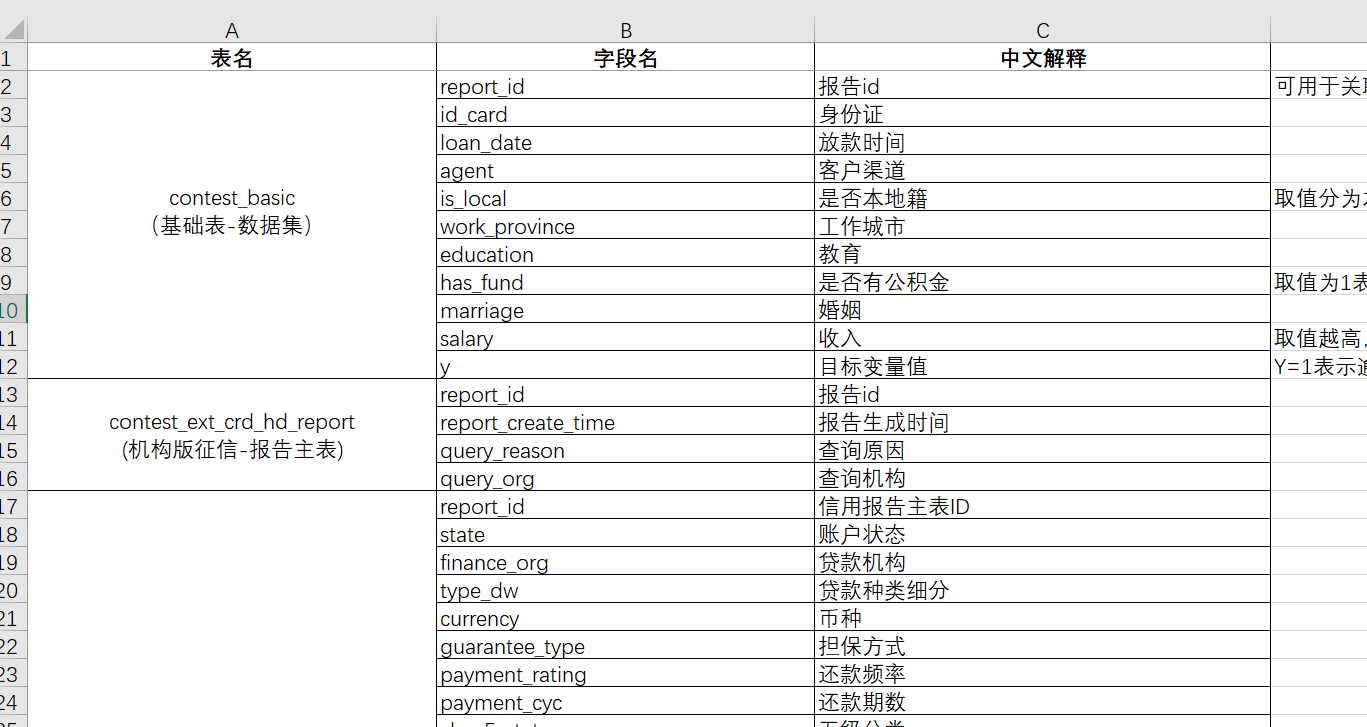
太多了就不详细列举了。数据都放在了“原始数据”这个文件夹里面方便下面代码读取。
当然需要本文的全部案例数据和代码文件的同学还是可以参考:征信风控
实验过程与结果
- 数据预处理(空值处理、异常值处理、变量标注、独热编码......)
- 数据可视化
- 特征工程
- 实验过程
- 实验结果
代码实现
下面开始写代码吧
导入包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import os,randomplt.rcParams["font.sans-serif"] = ["SimHei"] # 设置显示中文字体
plt.rcParams["axes.unicode_minus"] = False # 设置正常显示符号数据的合并整理
读取合并数据文件,由于这个数据里面的征信不同,来源的数据集太多,所以文件会很乱,做机器学习首先得把他们这些数据都合并一起,就得做很多清洗和处理,下面就开始这样合并和整理的过程。
#查看数据文件夹里面的所有数据文件的名称
data_lis=os.listdir('原始数据')
data_lis
#循环读取所有数据,放入列表
def read_and_merge_files(folder_path):# 用于存储所有数据框的列表dataframes = []# 遍历文件夹中的所有文件for filename in os.listdir(folder_path):file_path = os.path.join(folder_path, filename)# 根据文件后缀使用不同的方法读取if filename.endswith('.csv'):df = pd.read_csv(file_path)elif filename.endswith('.tsv'):df = pd.read_csv(file_path, sep='\t')else:continue # 忽略非CSV/TSV文件df.columns=[c.lower() for c in df.columns]print(f"{filename}读取完成,数据形状为{df.shape}")dataframes.append(df)return dataframes读取所有的文件
folder_path = '原始数据' # 替换为文件夹路径
dataframes_list = read_and_merge_files(folder_path)
len(dataframes_list)
所有的数据合并需要按照report_id进行关联,但是有的表可能report_id可能会重复,所以先查看一下
#查看数据信息,report_id有重复
def check_files(dataframes):# 确保至少有一个数据框if not dataframes:raise ValueError("No CSV or TSV files found in the directory.")# 依次检查所有表的report_id数量for i,df in enumerate(dataframes):duplicates = df['report_id'].duplicated().sum()print(f'表{data_lis[i]}中重复的 report_id 数量: {duplicates}')### 查看每个表的重复情况
check_files(dataframes_list) 
对这些重复数据选取最后一条进行合并,表示最新最近的情况
### 合并的时候不需要的字段就过滤掉
unuseless=["query_date","querier",'get_time', #查询,信息更新的日期"scheduled_payment_date", "scheduled_payment_amount", "actual_payment_amount", "recent_pay_date", #本月、最近的应还什么的,没有时效性,去掉"finance_org", "currency", "open_date",'end_date', #日期类都去掉'first_loan_open_month','first_loancard_open_month','first_sl_open_month', 'loan_date','month_dw','report_create_time','payment_state', #一些ID类,编码类 也都去掉'id_card','loan_id','loancard_id','content' ]def merge_files(dataframes):# 使用第一个表(假设是contest_basic)作为左连接底表main_df = dataframes[0]for i,df in enumerate(dataframes[1:]):#按照report_id 去重保留最后一个df=df[[col for col in df.columns if col not in unuseless]]df=df.drop_duplicates(subset='report_id', keep='last')print(f'正在合并数据表:{data_lis[1:][i]}...')# 按照'report_id'列进行左连接name=data_lis[1:][i].split('_')[-1]main_df = pd.merge(main_df, df, on='report_id', how='left',suffixes=('', f'_@{name}')) ## 名称重复的特征后面加上@和数据文件名称print(f'合并之后的数据形状{main_df.shape}')return main_df使用这个函数
threshold = len(df_all) * 0.5df_all = df_all.dropna(axis=1, thresh=threshold)
df_all.shapedf_all=merge_files(dataframes_list)
# 删除缺失率高达50%的列
threshold = len(df_all) * 0.5df_all = df_all.dropna(axis=1, thresh=threshold)
df_all.shape![]()
### 去除一些 id列(唯一编码,对模型没有用),设置report_id为索引
for c in ['id_card','loan_date','loan_id','loancard_id']:if c in df_all.columns:df_all.drop(c,axis=1,inplace=True)
df_all=df_all.set_index('report_id')## 查看数据信息
df_all.info()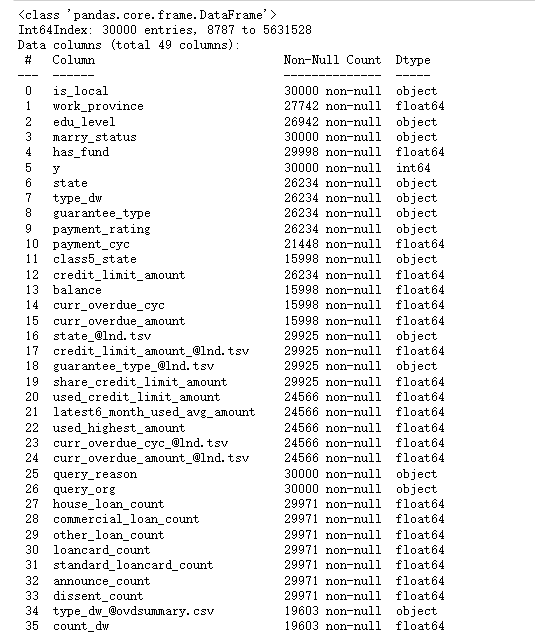
文本的变量很多,需要处理,我们首先查看文本变量的信息
### 查看文本变量的信息
df_all.select_dtypes(include='object').describe().T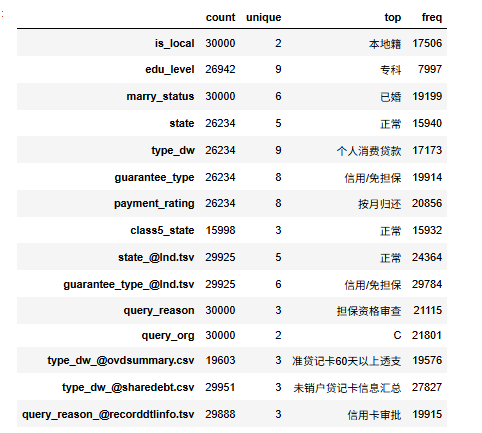
##查看字符变量名称
str_columns=df_all.select_dtypes(include='object').columns.to_list()
str_columns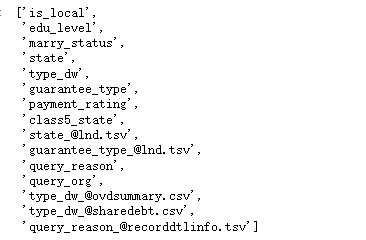
df_all.select_dtypes(exclude='object').describe().T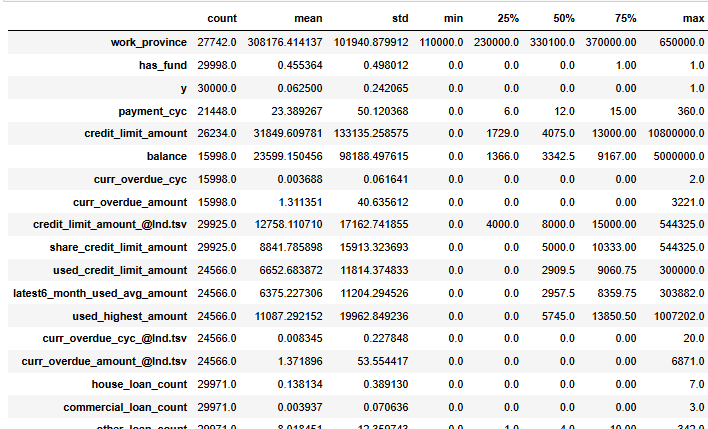
数据洗完了,储存一下吧
### 查看了上述信息,数据合并没问题,进行储存
df_all.to_csv('合并后的数据.csv')数据预处理
数据预处理(空值处理、异常值处理、变量标注、独热编码......)
缺失值查看
### 读取合并的数据
df=pd.read_csv('合并后的数据.csv').set_index('report_id')
df.head(3)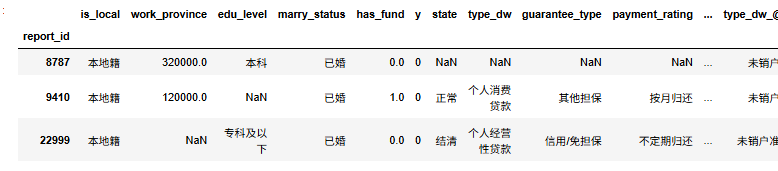
### 查看标签y的比例
df['y'].value_counts()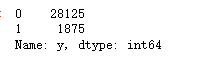
查看数据信息
df.info()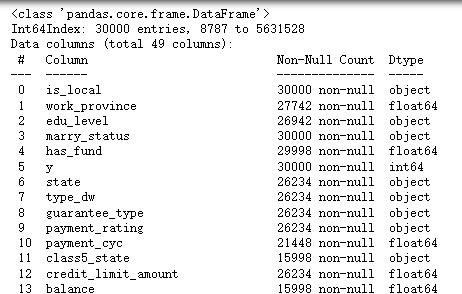
这样看可能不全面不直观,我们观察缺失值情况直接画图就行了
#观察缺失值
import missingno as msno
msno.matrix(df)
可以很清晰的看到哪些列的缺失率比较多,并且这些缺失都是某些样本造成的,可能是合并数据的时候,某些人某些身份证没有这一类的数据。
变量预处理
#取值唯一的变量删除
for col in df.columns:if len(df[col].value_counts())==1:print(col)df.drop(col,axis=1,inplace=True)![]()
这两个变量取值唯一就删除掉了。
#查看数值型数据,
#pd.set_option('display.max_columns', 30)
df.select_dtypes(exclude=['object']).describe()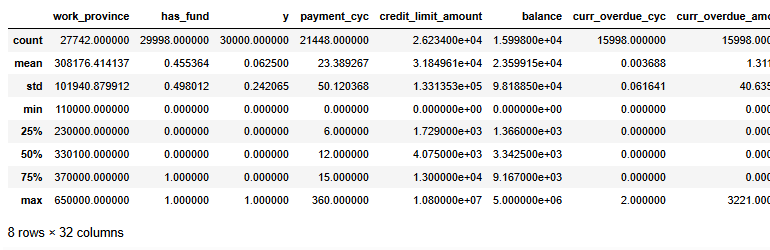
做机器学习当然需要特征越分散越好,因为这样就可以在X上更加有区分度,从而更好的分类。所以那些数据分布很集中的变量可以扔掉。我们用异众比例来衡量数据的分散程度
#计算异众比例
variation_ratio_s=0.05
for col in df.select_dtypes(exclude=['object']).columns:df_count=df[col].value_counts()kind=df_count.index[0]variation_ratio=1-(df_count.iloc[0]/len(df[col]))if variation_ratio<variation_ratio_s:print(f'{col} 最多的取值为{kind},异众比例为{round(variation_ratio,4)},太小了,没区分度删掉')df.drop(col,axis=1,inplace=True) ![]()
##查看非数值型数据
df.select_dtypes(exclude=['int64','float64']).describe()
基本都是可以转为类别型变量
空值处理
缺失值有很多填充方式,可以用中位数,均值,众数。 也可以就采用那一行前面一个或者后面一个有效值去填充空的
#数值型变量使用均值填充
#文本型数据使用众数填充
def fill_missing_values(df):# 选择数值型变量并使用均值填充缺失值for col in df.select_dtypes(include=['int64', 'float64']).columns:mean_value = df[col].mean()df[col].fillna(mean_value, inplace=True)# 选择字符型变量并使用众数填充缺失值for col in df.select_dtypes(exclude=['int64', 'float64']).columns:mode_value = df[col].mode()[0]df[col].fillna(mode_value, inplace=True)return df
df=fill_missing_values(df)查看数据信息
df.info()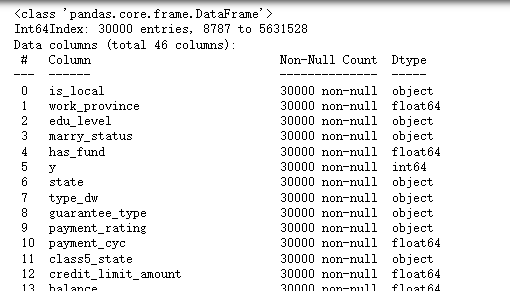
可以看到所有的变量没有缺失值了。
异常值处理
主要是对数值型变量,查看是否有验证的异常值处理
df_number=df.select_dtypes(include=['int64', 'float64'])#X异常值处理,先标准化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
df_number_s = scaler.fit_transform(df_number)可视化一下看看异常值
plt.figure(figsize=(20,8))
plt.boxplot(x=df_number_s,labels=df_number.columns)
#plt.hlines([-10,10],0,len(columns))
plt.show()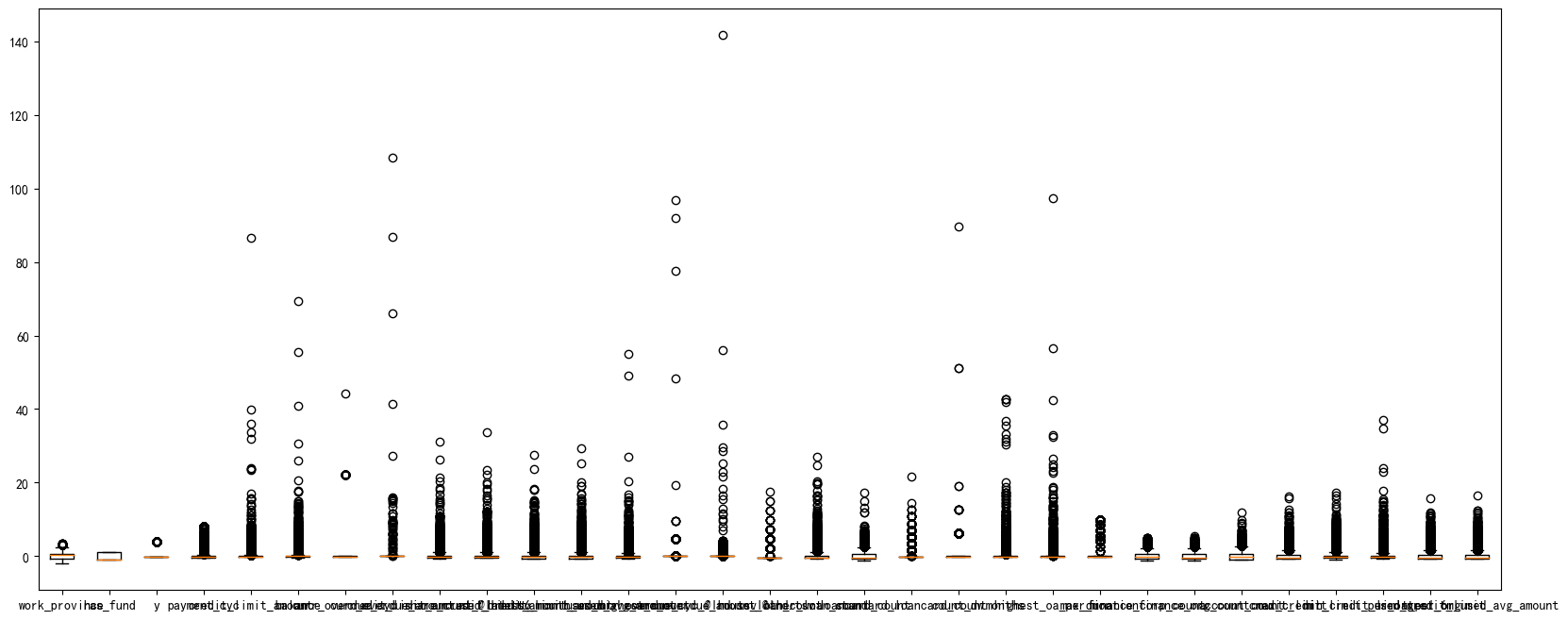
可以看到,很多变量都存在极大值,我们需要进行异常值处理
这个函数传入三个参数,要处理的数据框,异常值多的变量列名,还有筛掉几倍的方差。我下面选用的是10,也是就说如果一个样本数据大于整体10倍的标准差之外就筛掉。
#异常值多的列进行处理
def deal_outline(data,col,n): #数据,要处理的列名,几倍的方差for c in col:mean=data[c].mean()std=data[c].std()data=data[(data[c]>mean-n*std)&(data[c]<mean+n*std)]#print(data.shape)return datadf_number=deal_outline(df_number,df_number.columns,10)
df_number.shape ![]()
### 处理完成后将数据筛选给原始数据
df=df.loc[df_number.index,:]
df.shape![]()
这样,原始3w数据减少了594条
变量标注、独热编码......
由于这里分类变量有点多,并且每个变量的类别的取值也较多,使用独热编码可能造成维度灾难,所以我们这里进行labelencode,因子化处理类别变量
df_category=df.copy()
#选出列表变量
categorical_feature=df.select_dtypes(include=['category','object']).columns.to_list()
for col in categorical_feature:df[col]=df[col].astype('category').cat.codes #因子化
df.shapedf.info() 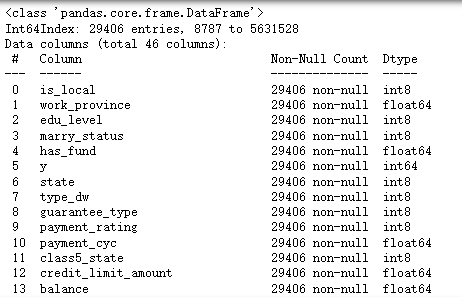
可以看到所有的变量都变成数值型变量了,下面进行可视化
数据可视化
类别变量可视化
### 我们对类别变量画柱状图
len(df_category.select_dtypes(exclude=['int64', 'float64']).columns)# Select non-numeric columns
non_numeric_columns = df_category.select_dtypes(exclude=['int64', 'float64']).columns
f, axes = plt.subplots(4, 4, figsize=(14,14),dpi=256)
# Flatten axes for easy iterating
axes_flat = axes.flatten()
for i, column in enumerate(non_numeric_columns):if i < 15: sns.countplot(x=column, data=df_category, ax=axes_flat[i])axes_flat[i].set_title(f'Count of {column}')for label in axes_flat[i].get_xticklabels():label.set_rotation(90) #类别标签旋转一下,免得多了堆叠看不清# Hide any unused subplots
for j in range(i + 1, 15):f.delaxes(axes_flat[j])plt.tight_layout()
plt.show()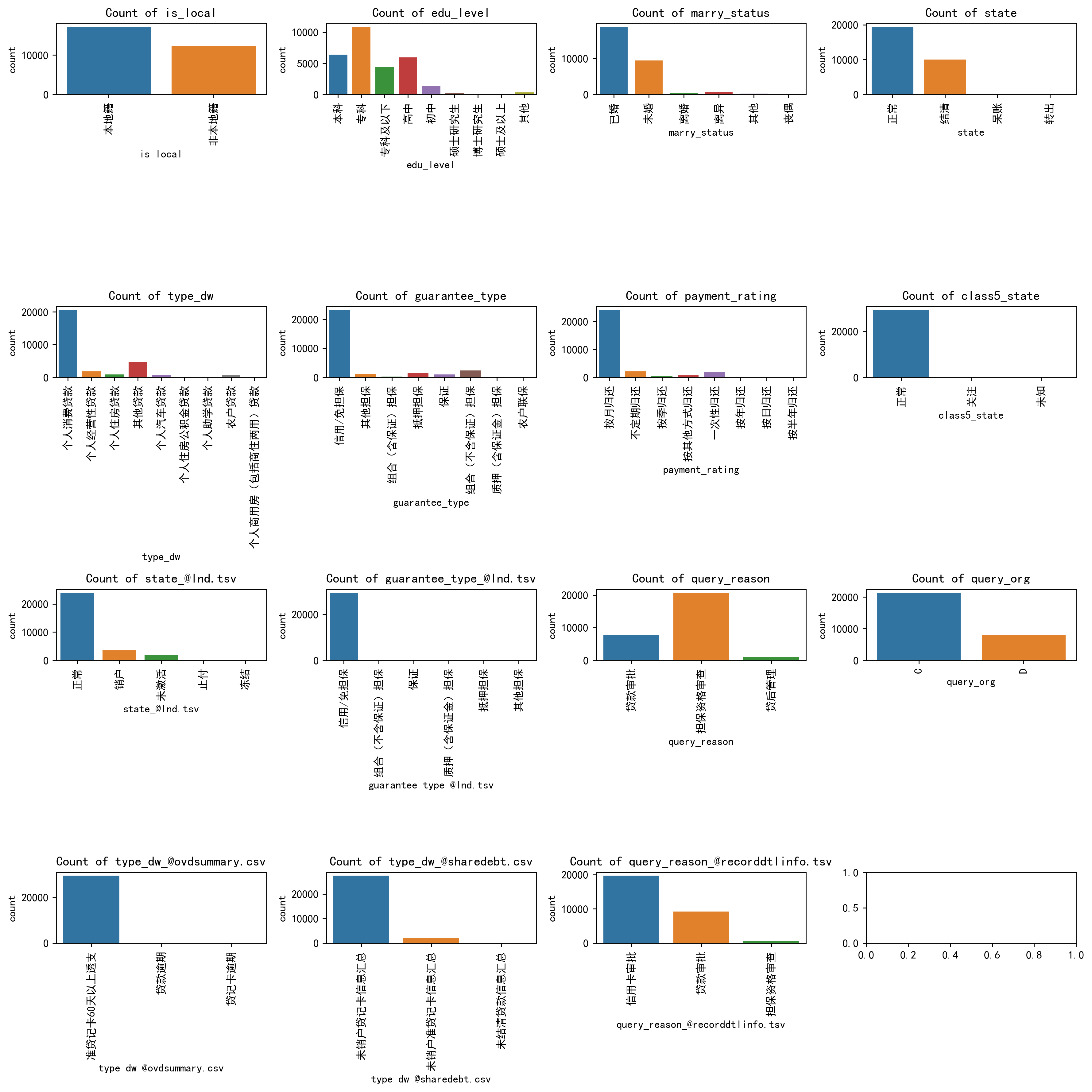
可以很清楚的看到每一个类别变量的哪些类别比较多的类别分布。
数值变量可视化
#画密度图,
num_columns = df.select_dtypes(include=['int64', 'float64']).columns.tolist() # 列表头
dis_cols = 4 #一行几个
dis_rows = len(num_columns)
plt.figure(figsize=(3 * dis_cols, 2 * dis_rows),dpi=256)for i in range(len(num_columns)):ax = plt.subplot(dis_rows, dis_cols, i+1)ax = sns.kdeplot(df[num_columns[i]], color="skyblue" ,fill=True)ax.set_xlabel(num_columns[i],fontsize = 14)
plt.tight_layout()
#plt.savefig('训练测试特征变量核密度图',formate='png',dpi=500)
plt.show()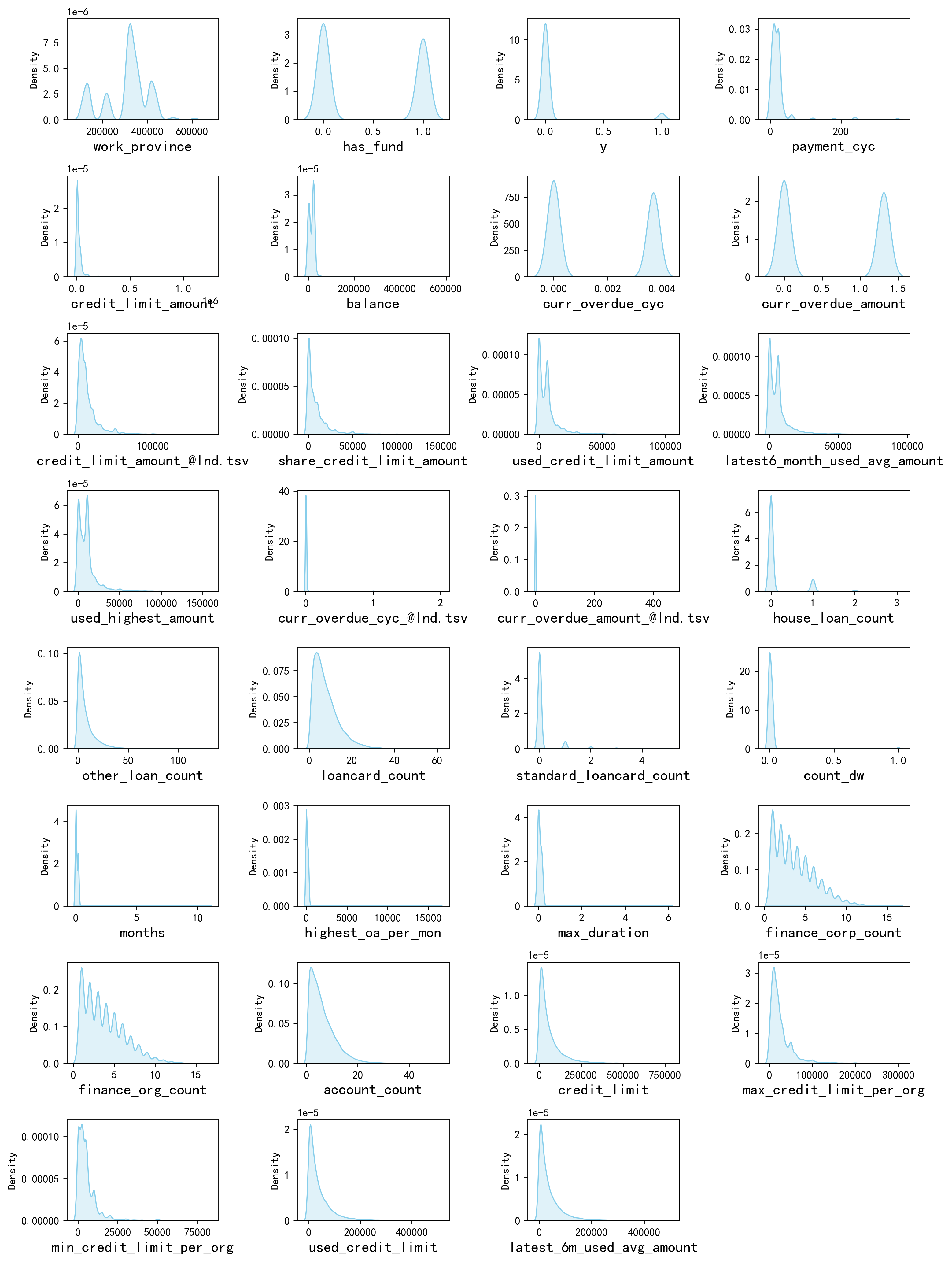
具体的结论就不一个变量一个变量的看了,可以很清楚的看到每一个变量的一些分布的特点。例如他们基本都是右偏分布,也就是说具有一些极大值。
和y进行变量之间的相关性研究
# 将数据按 'edu_level' 和 'y' 进行分组,然后计数
edu_vs_y = df_category.groupby(['edu_level', 'y']).size().unstack()# 将数据按 'marry_status' 和 'y' 进行分组,然后计数
marry_vs_y = df_category.groupby(['marry_status', 'y']).size().unstack()# 创建子图
fig, axes = plt.subplots(1, 2, figsize=(12, 4), dpi=128)# 绘制第一个子图的分组条形图
edu_vs_y.plot(kind='bar', stacked=False, ax=axes[0])
axes[0].set_title('不同教育水平的违约情况')
axes[0].set_xlabel('教育水平')
axes[0].set_ylabel('计数')
axes[0].legend(title='是否违约', loc='upper right')# 绘制第二个子图的分组条形图
marry_vs_y.plot(kind='bar', stacked=False, ax=axes[1])
axes[1].set_title('不同婚姻状态的违约情况')
axes[1].set_xlabel('婚姻状态')
axes[1].set_ylabel('计数')
axes[1].legend(title='是否违约', loc='upper right')# 调整子图之间的间距
plt.tight_layout()# 显示图形
plt.show()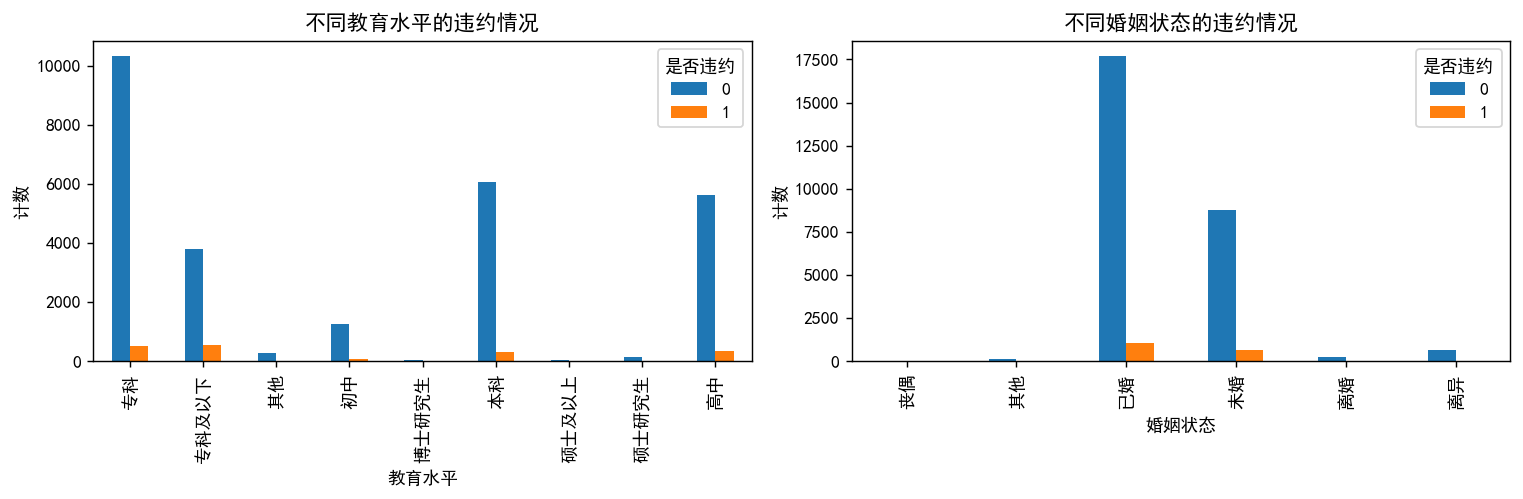
## 看不出明显的区别
计算相关性系数的热力图
corr = plt.subplots(figsize = (18,16),dpi=128)
corr= sns.heatmap(df.corr(method='spearman'),annot=True,square=True)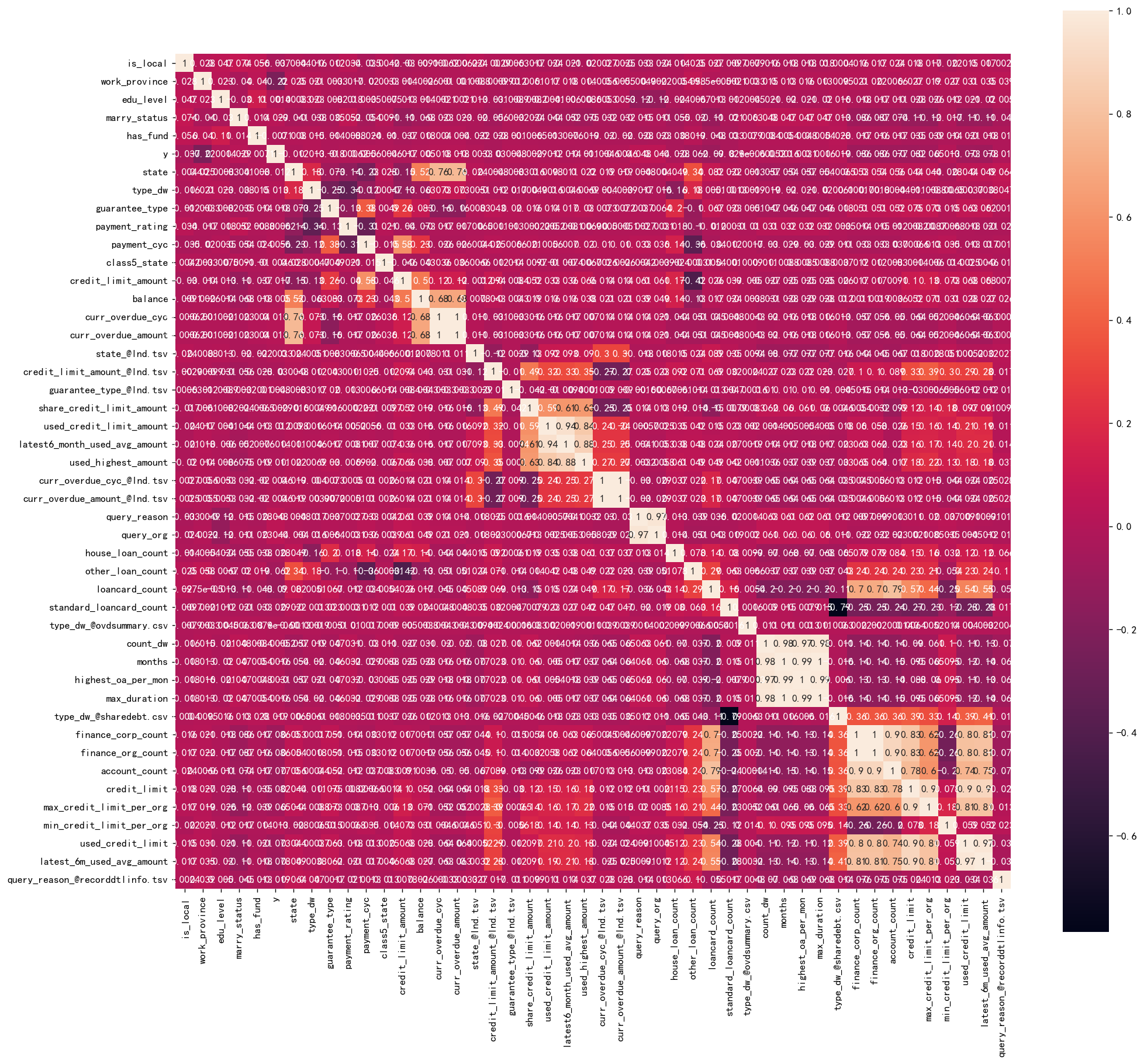
变量有点多,所以说这里就不详细写哪些变量和哪些变量之间的相关性比较高了。
特征工程
## 前面对数据已经进行了很多预处理了,现在就是要对数据进行进行标准化
#首先取出X和y
X=df.drop('y',axis=1)
y=df['y']标准化
# 进行标准化
#数据标准化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X)
X_s = scaler.transform(X)
print('标准化后数据形状:')
print(X_s.shape,y.shape)![]()
实验过程
机器学习——模型选择
我们首先定义分类问题所使用的评价指标:准确率,精准度,召回率,F1值

定义评价指标
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
from sklearn.metrics import cohen_kappa_scoredef evaluation(y_test, y_predict):accuracy=classification_report(y_test, y_predict,output_dict=True)['accuracy']s=classification_report(y_test, y_predict,output_dict=True)['weighted avg']precision=s['precision']recall=s['recall']f1_score=s['f1-score']#kappa=cohen_kappa_score(y_test, y_predict)return accuracy,precision,recall,f1_score #, kappa
训练集测试集划分
#划分训练集和测试集
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X_s,y,stratify=y,test_size=0.2,random_state=0)
print(X_train.shape,X_test.shape,y_train.shape,y_test.shape)### 查看训练和测试集的y的黑白占比
y_train.value_counts(normalize=True)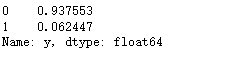
y_test.value_counts(normalize=True)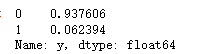
两者比例是类似的,不过样本很不平衡,取值为1的太少了,所以我们要做一点采样处理。
在处理极度不平衡的分类样本时,可以考虑以下几种方法: 欠采样(Undersampling):从多数类别中随机选择一部分样本,使得多数类别的样本数量与少数类别的样本数量相近。这种方法的优点是简单快捷,但可能会丢失一些有用信息。
过采样(Oversampling):从少数类别中随机复制一些样本,使得少数类别的样本数量与多数类别的样本数量相近。这种方法的优点是可以充分利用数据集,但可能会导致过拟合。
SMOTE(Synthetic Minority Over-sampling Technique)算法:是一种常用的过采样方法,它通过对少数类别样本进行插值生成新的样本来扩充数据集。这种方法可以有效地避免过拟合问题。
混合采样(Mixed Sampling):结合欠采样和过采样的优点,既可以减少数据量,又可以充分利用数据集。可以先进行欠采样,然后再对欠采样后的数据进行过采样。
我们首先对样本少的类别,即逾期类别,取值为1 的进行上采样。
from imblearn.over_sampling import RandomOverSampler
os=RandomOverSampler(sampling_strategy=0.1)
X_train_ns,y_train_ns=os.fit_resample(X_s,y)
print("The number of classes before fit {}".format(y.value_counts().to_dict()))
print("The number of classes after fit {}".format(y_train_ns.value_counts().to_dict()))
X_train_ns.shape,y_train_ns.shape![]()
再对样本多的进行下采样,比例为0.2,即0类数量8成,1类数量2成。虽然也不平衡,但是比刚刚那个好多了。。也能训练了。
from imblearn.under_sampling import RandomUnderSampler
rus = RandomUnderSampler(sampling_strategy=0.25)
X_resampled, y_resampled = rus.fit_resample(X_train_ns, y_train_ns)
X_train_ns2,y_train_ns2=rus.fit_resample(X_train_ns,y_train_ns)
print("The number of classes before fit {}".format(y_train_ns.value_counts().to_dict()))
print("The number of classes after fit {}".format(y_train_ns2.value_counts().to_dict()))![]()
查看形状
print(X_train_ns2.shape,y_train_ns2.shape)![]()
##再次重新划分训练集和测试集
X_train,X_test,y_train,y_test=train_test_split(X_train_ns2,y_train_ns2,stratify=y_train_ns2,test_size=0.2,random_state=0)
print(X_train.shape,X_test.shape,y_train.shape,y_test.shape)![]()
### 查看训练和测试集的y的黑白占比
y_train.value_counts(normalize=True)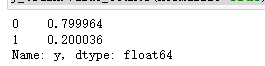
y_test.value_counts(normalize=True)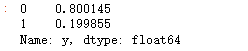
比例大概8:2,比刚刚严重不平衡好很多,可以进行机器学习了
模型训练
#导包
from sklearn.linear_model import LogisticRegression
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import GradientBoostingClassifier
from xgboost.sklearn import XGBClassifier
from lightgbm import LGBMClassifier
from sklearn.svm import SVC
from sklearn.neural_network import MLPClassifier实例化分类器:
#逻辑回归
model1 = LogisticRegression(C=1e10,max_iter=10000)#线性判别分析
model2 = LinearDiscriminantAnalysis()#K近邻
model3 = KNeighborsClassifier(n_neighbors=10)#决策树
model4 = DecisionTreeClassifier(random_state=77)#随机森林
model5= RandomForestClassifier(n_estimators=1000, max_features='sqrt',random_state=10)#梯度提升
model6 = GradientBoostingClassifier(random_state=123)#极端梯度提升
model7 = XGBClassifier(objective='binary:logistic',random_state=1)#轻量梯度提升
model8 = LGBMClassifier(objective='binary',random_state=1,verbose=-1)#支持向量机
model9 = SVC(kernel="rbf", random_state=77)#神经网络
model10 = MLPClassifier(hidden_layer_sizes=(16,8), random_state=77, max_iter=10000)model_list=[model1,model2,model3,model4,model5,model6,model7,model8,model9,model10]
model_name=['逻辑回归','线性判别','K近邻','决策树','随机森林','梯度提升','极端梯度提升','轻量梯度提升','支持向量机','神经网络']训练和评估
df_eval=pd.DataFrame(columns=['Accuracy','Precision','Recall','F1_score'])
for i in range(10):model_C=model_list[i]name=model_name[i]model_C.fit(X_train, y_train)pred=model_C.predict(X_test)#s=classification_report(y_test, pred)s=evaluation(y_test,pred)df_eval.loc[name,:]=list(s)print(f'{name}模型完成')
查看评价指标
df_eval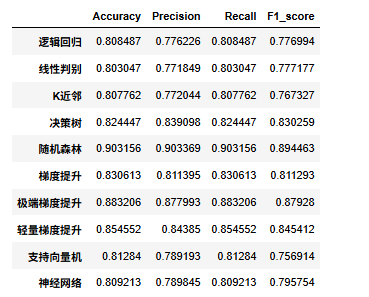
可视化看看
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['KaiTi'] #中文
plt.rcParams['axes.unicode_minus'] = False #负号bar_width = 0.4
colors=['c', 'b', 'g', 'tomato', 'm', 'y', 'lime', 'k','orange','pink','grey','tan']
fig, ax = plt.subplots(2,2,figsize=(10,8),dpi=128)
for i,col in enumerate(df_eval.columns):n=int(str('22')+str(i+1))plt.subplot(n)df_col=df_eval[col]m =np.arange(len(df_col))plt.bar(x=m,height=df_col.to_numpy(),width=bar_width,color=colors)#plt.xlabel('Methods',fontsize=12)names=df_col.indexplt.xticks(range(len(df_col)),names,fontsize=10)plt.xticks(rotation=40)plt.ylabel(col,fontsize=14)plt.tight_layout()
#plt.savefig('柱状图.jpg',dpi=512)
plt.show()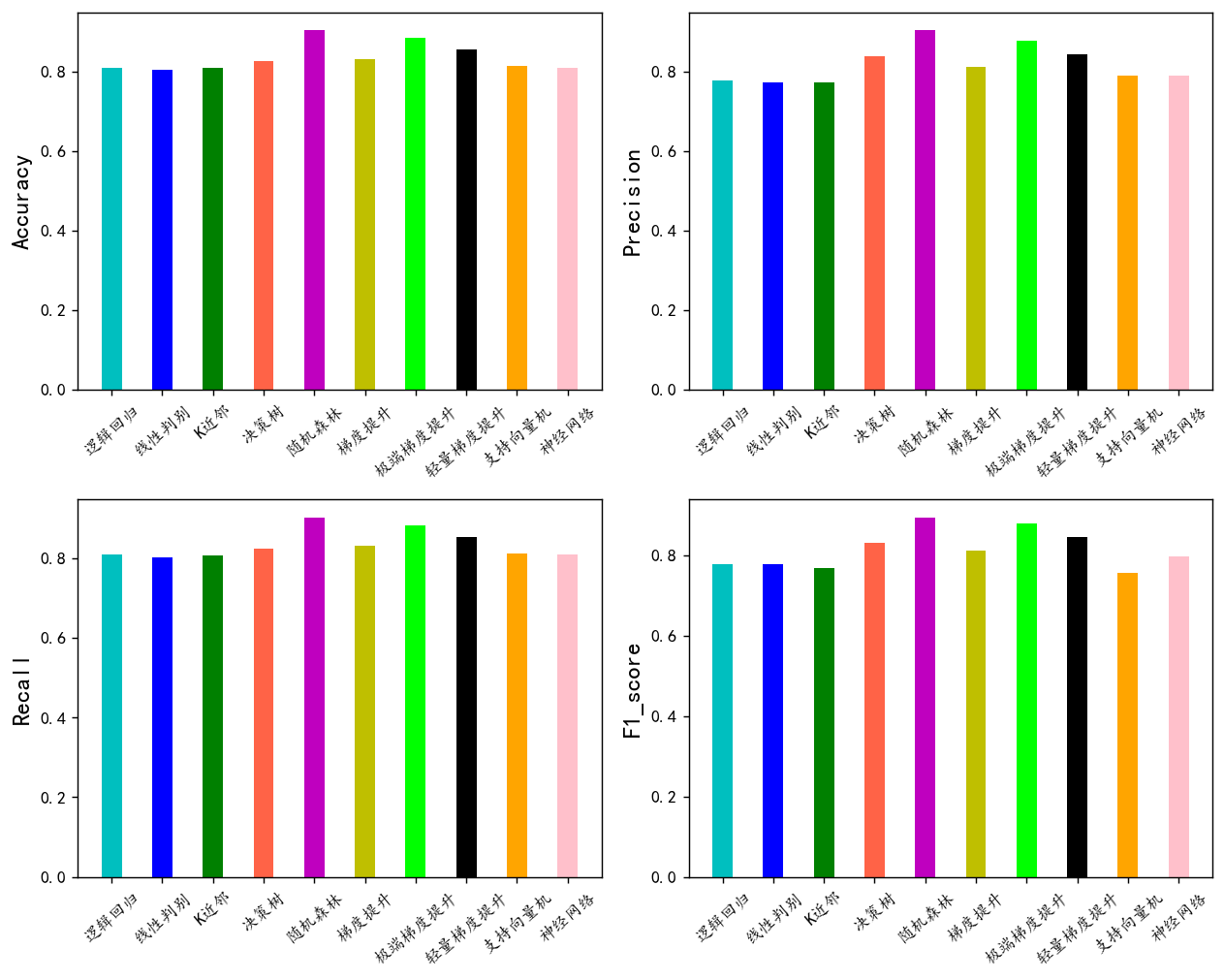
可以看到随机森林模型效果最好,我们选择他作为最终模型
超参数搜索
简单网格化定义几个超参数,搜索一下。对模型的效果进行一定的优化。
水系森林超凡树不太多,我们这里就搜索一下最影响最大的估计器个数吧。
# 网格化搜索最优超参数
from sklearn.model_selection import KFold, train_test_split, GridSearchCV
rf_model = RandomForestClassifier(max_features='sqrt',random_state=10)
param_dict = { 'n_estimators': [100,500,700]}
clf = GridSearchCV(rf_model, param_dict, verbose=1,cv=3)
clf.fit(X_train, y_train)
print(clf.best_score_)
print(clf.best_params_)
将搜索出来的这个超参数代入模型去训练
model=RandomForestClassifier( n_estimators=700 , max_features='sqrt',random_state=10)
model.fit(X_train, y_train)
y_pred=model.predict(X_test)
evaluation(y_test,y_pred)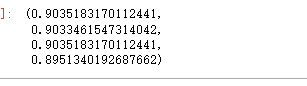
超参数 可以看到整体的准确率精准度召回率f1值,都稍微提高了一些。
实验结果
AUC,ROC,KS
信贷场景是一个经典的2分类问题,就是判断它是不是会违约,从而做出要不要给他贷款的决策。2分类问题就逃不开要计算roc曲线,计算auc值和ks。 用如下的代码画出roc曲线跟pr曲线。
from sklearn.metrics import roc_curve, auc, precision_recall_curve
y_pred_proba = model.predict_proba(X_test)[:, 1]
# 计算ROC曲线和AUC值
fpr, tpr, _ = roc_curve(y_test, y_pred_proba)
roc_auc = auc(fpr, tpr)
# 计算PR曲线
precision, recall, _ = precision_recall_curve(y_test, y_pred_proba)# 创建1*2的子图
plt.figure(figsize=(10, 4),dpi=128)# 绘制ROC曲线
plt.subplot(1, 2, 1)
plt.plot(fpr, tpr, color='tomato', lw=2, label='AUC = %0.2f' % roc_auc)
plt.plot([0, 1], [0, 1], color='k', lw=1, linestyle='--')
plt.xlim([0.0, 1.0]) ; plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate') ; plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic (ROC) Curve')
plt.legend(loc="lower right")# 绘制PR曲线
plt.subplot(1, 2, 2)
plt.plot(recall, precision, color='skyblue', lw=2)
plt.xlim([0.0, 1.0]) ; plt.ylim([0.0, 1.05])
plt.xlabel('Recall') ; plt.ylabel('Precision')
plt.title('Precision-Recall (PR) Curve')# 显示图像
plt.tight_layout()
plt.show()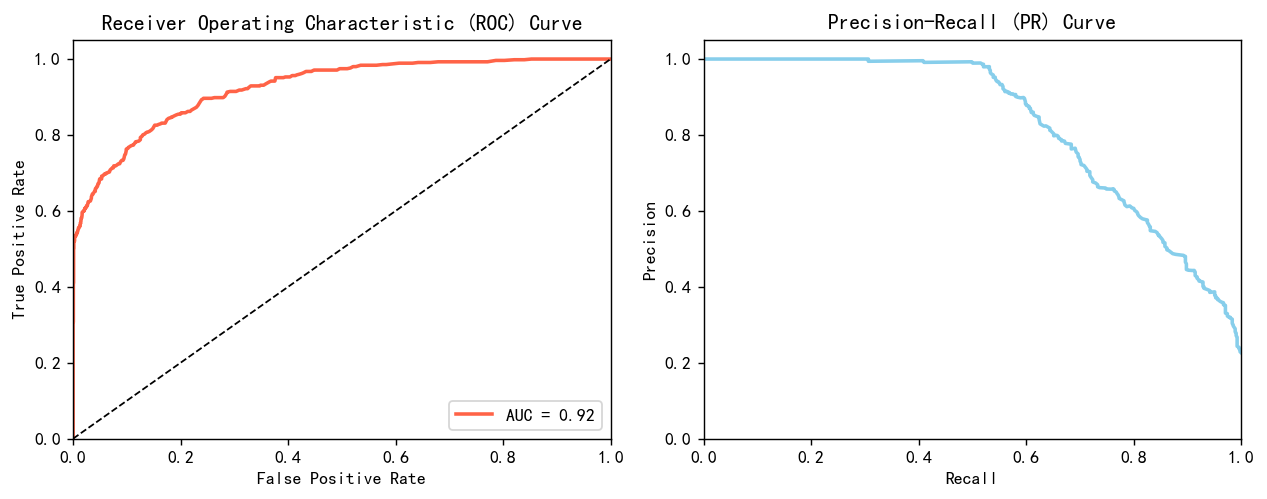
很漂亮的曲线,效果很好,不过也可能是上采样和下采样导致的有些样本重复。
画KS图:
import scikitplot as skplt
skplt.metrics.plot_ks_statistic(y_test,model.predict_proba(X_test))
plt.show()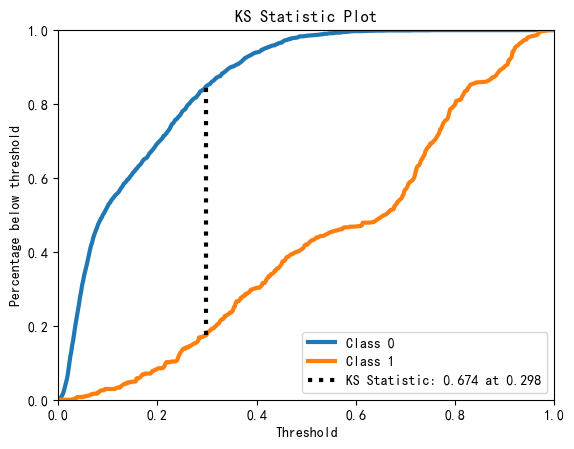
模型的AUC0.92, KS0.674,说明模型效果很好,对好坏客户有很强的区分能力
进一步的去观察他每个预测的概率区间里面有多少个样本,多少个好样本,坏样本,坏样本的比例有多少,它的提升度有多少,累积的这个坏样本的百分比有多少。
自定义函数
def calculate_pred_proba_bin(true_labels,predictions, bins=10):# 创建分箱区间bin_edges = np.linspace(0, 1, bins + 1)# 分箱bin_labels = [f"{bin_edges[i]:.2f}-{bin_edges[i+1]:.2f}" for i in range(len(bin_edges)-1)]bin_indices = np.digitize(predictions, bin_edges, right=False) - 1# 创建数据框df = pd.DataFrame({ 'bin': [bin_labels[i] for i in bin_indices], 'label': true_labels })# 统计各个分箱的总数、类别为0和1的样本数result = df.groupby('bin')['label'].agg(total='count',count_0=lambda x: (x == 0).sum(),count_1=lambda x: (x == 1).sum()).reset_index()# 计算坏样本率和坏样本在所有坏样本中的比例total_bad_samples = result['count_1'].sum()result['bad_rate'] = result['count_1'] / result['total']result['bad_percent'] = result['count_1'] / total_bad_samples#result=result.sort_values('bin',ascending=False)result['lift']=result['bad_rate']/(total_bad_samples/result['total'].sum())result['cumulative_bad_percent'] = result['bad_percent'][::-1].cumsum()[::-1]return result.style.bar(color='skyblue').format(subset=['bad_rate','bad_percent','lift','cumulative_bad_percent'], precision=4)def scorecardpy_display_bin(bins_info):df_list = []for col, bin_data in bins_info.items():df = pd.DataFrame(bin_data)df_list.append(df)result_df = pd.concat(df_list, ignore_index=True)# 增加 lift 列total_bad = result_df['bad'].sum() ; total_count = result_df['count'].sum()overall_bad_rate = total_bad / total_countresult_df['lift'] = result_df['badprob'] / overall_bad_rateresult_df=result_df.sort_values(['total_iv','variable'],ascending=False).set_index(['variable','total_iv','bin'])[['count_distr','count','good','bad','badprob','lift','bin_iv','woe']]return result_df.style.format(subset=['count','good','bad'], precision=0).format(subset=['count_distr', 'bad','lift','badprob','woe','bin_iv'], precision=4).bar(subset=['badprob','bin_iv','lift'], color=['#d65f5f', '#5fba7d'])calculate_pred_proba_bin(y_test,y_pred_proba, bins=20)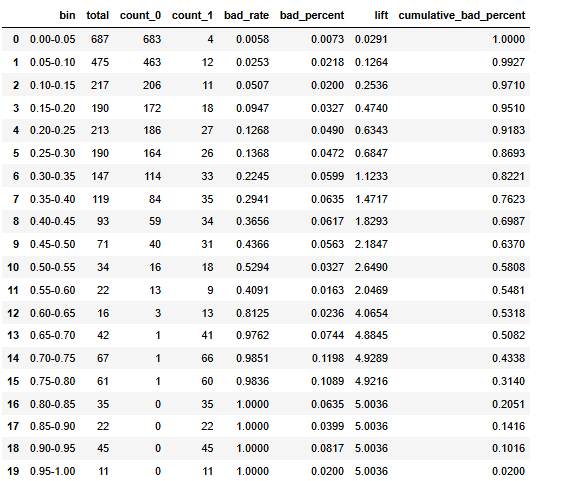
基本上随着模型的概率越来越高,模型预测正确的把握越来越大,其提升度也就是每一箱的这个黑样本的比例也是越来越高的。说明模型其性能没有什么太多的问题。
如果要进行使用的话建议是可以模型预测概率为0.6区间以上的全部拒绝掉,可以过滤到50%的黑样本,0.15到0.5之间的样本再进行一次审查,0.15以下的贷款可以接受.
)



)












))

