文章目录
- 哈希
- 两数之和
- 字母异位词分组
- 最长连续序列
- 双指针
- 移动零
- 盛最多水的容器
- 滑动窗口
- 子串
多刷题
LeetCode 热题100
哈希
两数之和
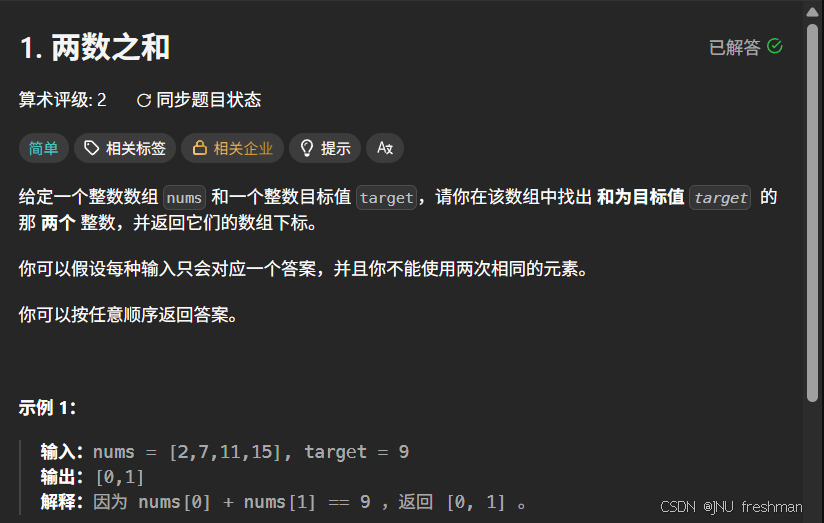
思路分析:暴力做法:每一个数字都与剩余的数字作比较,时间复杂度是O(n2)O(n^2)O(n2)哈希做法:我们可以使用一个哈希表存储已经检查过的数字,每次遍历到新的数字的时候,就在哈希表里面检查,target-num是否在这个哈希表里面;如果不存在,则将当前元素加入哈希表,哈希表存储的是{值:索引}
class Solution {
public:vector<int> twoSum(vector<int>& nums, int target) {int n = nums.size();// 使用哈希表map<int,int> store;for(int i = 0 ; i < n ;i++){int tar = target - nums[i];if (store.find(tar) != store.end()){return {store.find(tar)->second,i};}else{store[nums[i]] = i; }}return {};}
};
字母异位词分组

思路分析:- 首先,如何判断哪些单词是等价的,也就是可以通过重新排列变为一样的?那么我们肯定会说,只要这个
对应字符的个数和种类一样即可,但是我们实际上,并不会真正的去统计比较每一个字符串的字符的具体情况,然后进行一一对比 - 既然都可以进行重新排序,为什么不直接将全部的字符串进行排序,我们将排序之后的字符作为键,原本的字符串作为值,这样就可以实现O(n)O(n)O(n)的时间复杂度进行统计,最后只需将这个值汇总一下即可
- 首先,如何判断哪些单词是等价的,也就是可以通过重新排列变为一样的?那么我们肯定会说,只要这个
class Solution {
public:vector<vector<string>> groupAnagrams(vector<string>& strs) {// 存储{排序后字符串:原本字符串}unordered_map<string,vector<string>> store;for(auto& s:strs ){string tmp = s ;sort(s.begin(),s.end()); // 升序排序store[s].push_back(tmp);}// 整理答案vector<vector<string>> result;for (auto& p:store){result.push_back(p.second);}return result;}
};最长连续序列
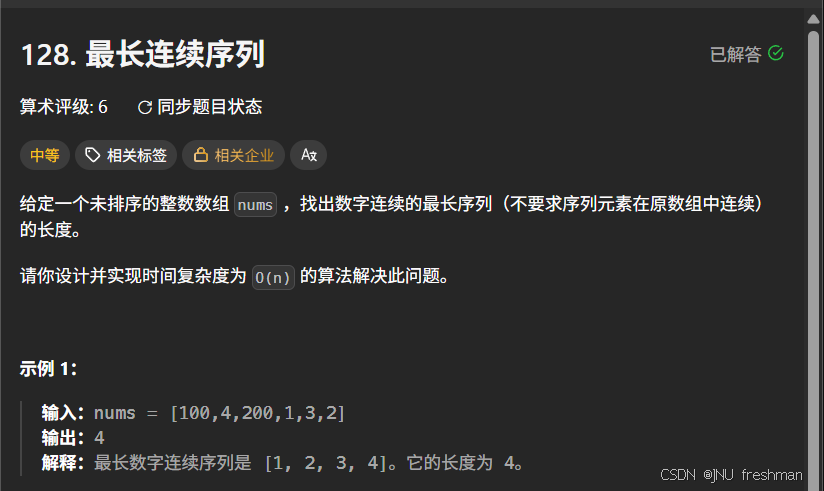
思路分析:暴力做法:直接对全部的整数数组进行一个排序,然后进行遍历一遍即可,但是这个排序的时间复杂度为O(nlogn)O(nlogn)O(nlogn)哈希表:题目要求的是使用O(n)O(n)O(n)的时间复杂度进行计算,所以就不能进行这个排序操作,这里有几点操作技巧- 重复的元素,我们只需遍历一次即可
- 找到以元素
num开始的最大情况,当存在num-1在哈希表的时候,就直接跳过(因为以num-1会比以num开头的序列长1) - 然后我们就可以一直查找,看看是否
num+1在哈希表,然后进行统计更新
class Solution {
public:int longestConsecutive(vector<int>& nums) { int ans = 0;unordered_set<int> store(nums.begin(),nums.end()); // 把nums转成哈希集合for (int x : store){if (store.contains(x-1)){continue;}// 以 x 为序列起点int y = x + 1;while (store.contains(y)){y++;}// 此时的y-1是序列的最后一个数,那么从x开始到y-1,一共y-x个数字ans = max(ans,y-x);}return ans;}
};双指针
双指针有多种类型,常见来说,就有正向双指针和对向双指针
移动零
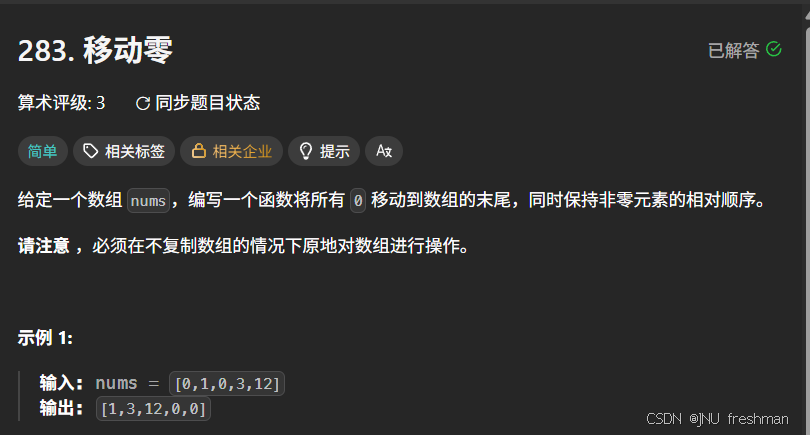
思路分析:
*
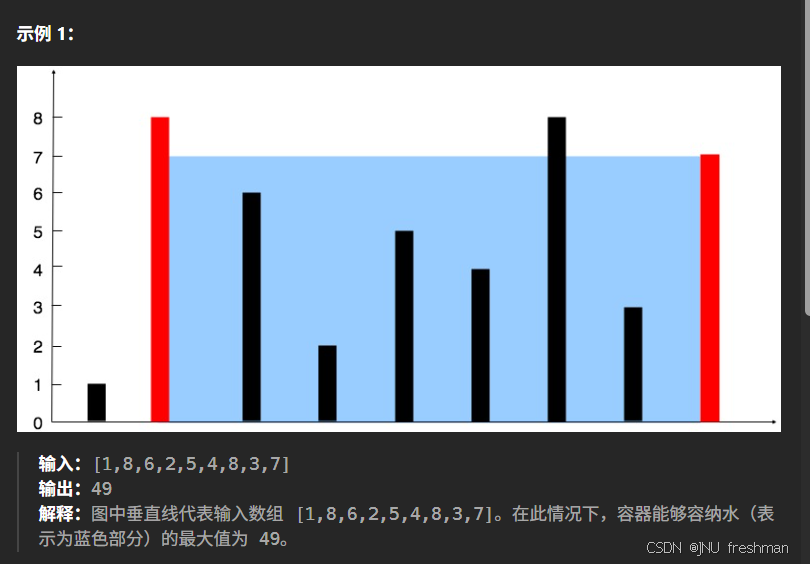
盛最多水的容器