点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
01
Iterative Distillation for Reward-Guided Fine-Tuning of Diffusion Models in Biomolecular Design
本文提出了一种用于生物分子设计中奖励引导生成的扩散模型微调框架。扩散模型在建模复杂、高维数据分布方面表现出色,但在实际应用中,仅生成高保真度的样本是不够的,还需要针对可能不可微的奖励函数进行优化,例如基于物理的模拟或基于科学知识的奖励。尽管已有研究探索使用强化学习(RL)方法对扩散模型进行微调,但这些方法通常存在不稳定性、采样效率低和模式坍塌等问题。本文提出的基于迭代蒸馏的微调框架能够使扩散模型针对任意奖励函数进行优化。该方法将问题视为策略蒸馏:在roll-in阶段收集离线数据,在roll-out阶段模拟基于奖励的软最优策略,并通过最小化模拟软最优策略与当前模型策略之间的KL散度来更新模型。与现有的基于RL的方法相比,本文的离线策略公式和KL散度最小化增强了训练的稳定性和采样效率。实验结果表明,该方法在蛋白质、小分子和调控DNA设计等多样化任务中均表现出优异的奖励优化效果。
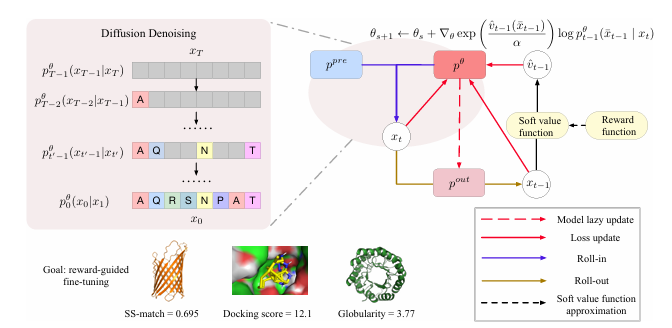

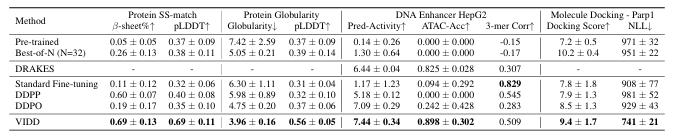
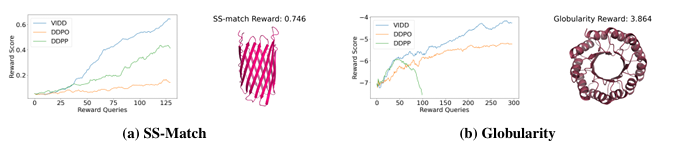
文章链接:
https://arxiv.org/pdf/2507.00445
02
Enhancing Reasoning Capabilities in SLMs with Reward Guided Dataset Distillation
本文提出了一种奖励引导的数据集蒸馏框架AdvDistill,用于提升小型语言模型(SLMs)的推理能力。现有的知识蒸馏技术虽然能够将大型语言模型(LLMs)的能力传递给更小的学生模型,但通常仅围绕学生模型模仿教师模型的分布内响应,限制了其泛化能力,尤其是在推理任务中。AdvDistill框架利用教师模型对每个提示生成的多个响应,并基于规则验证器分配奖励。这些变化的、正态分布的奖励在训练学生模型时作为权重。研究方法及其后续的行为分析表明,学生模型在数学和复杂推理任务上的表现显著提升,展示了在数据集蒸馏过程中引入奖励机制的有效性和益处。
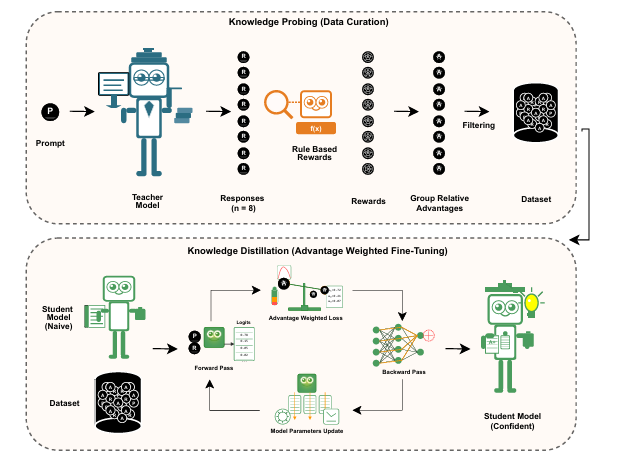
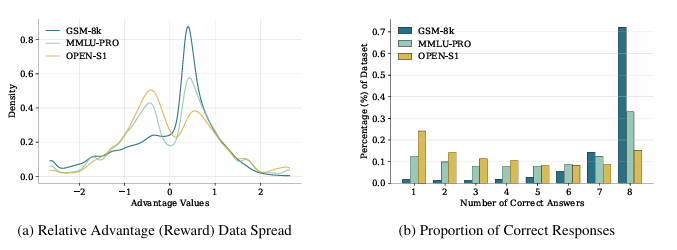
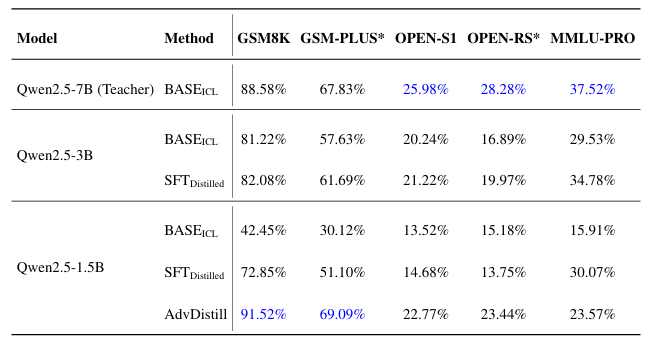
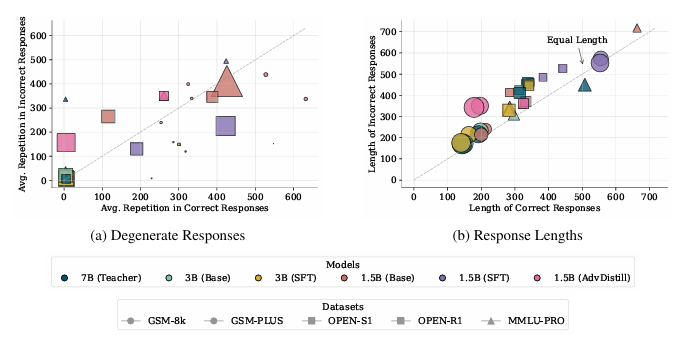
文章链接:
https://arxiv.org/pdf/2507.00054
03
APT: Adaptive Personalized Training for Diffusion Models with Limited Data
本文提出了一种名为“适应性个性化训练(APT)”的框架,用于在数据有限的情况下个性化扩散模型,以应对过拟合、先验知识丢失和文本对齐退化等挑战。APT通过以下三种策略来缓解过拟合:(1)适应性训练调整,引入过拟合指标以检测每个时间步的过拟合程度,并基于该指标进行自适应数据增强和自适应损失权重调整;(2)表示稳定化,通过约束中间特征图的均值和方差来防止噪声预测的过度偏移;(3)注意力对齐以保持先验知识,通过对齐微调模型与预训练模型的交叉注意力图来维持先验知识和语义连贯性。通过广泛的实验,本文证明了APT在缓解过拟合、保持先验知识以及在有限参考数据下生成高质量、多样化图像方面优于现有方法。
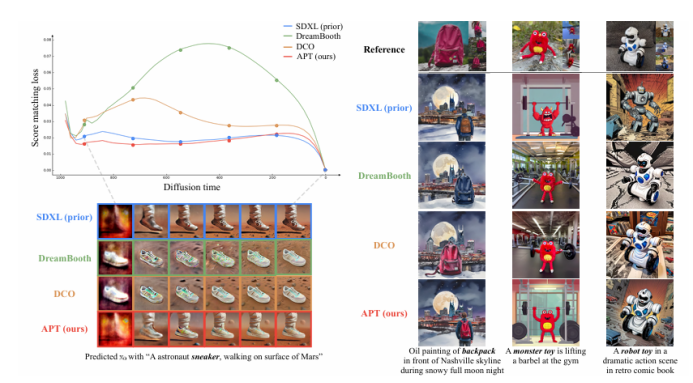
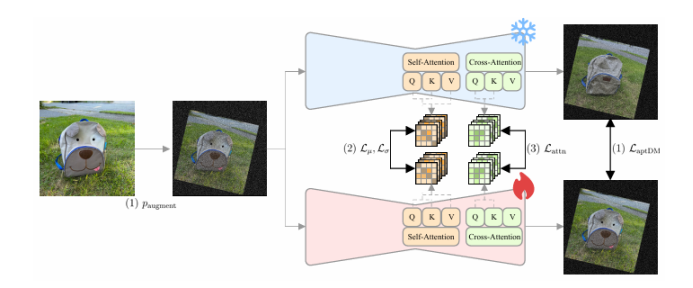
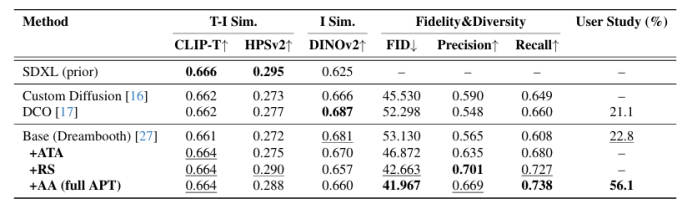
文章链接:
https://arxiv.org/pdf/2507.02687
04
MPF: Aligning and Debiasing Language Models post Deployment via Multi-Perspective Fusion
本文提出了一种名为“多视角融合(MPF)”的后训练对齐框架,用于应对大型语言模型(LLMs)中偏见缓解的需求。MPF基于SAGED流程——一个用于构建偏见基准和提取可解释基线分布的自动化系统——利用多视角生成来暴露并使LLMs输出中的偏见与细腻的人类基线对齐。通过将基线(例如人力资源专业人士的情绪分布)分解为可解释的视角组件,MPF通过采样和基于分解中获得的概率加权平衡响应来引导生成。实证研究表明,MPF能够使LLMs的情绪分布与反事实基线(绝对平等)和人力资源基线(对顶尖大学有偏见)对齐,从而实现较小的KL散度、校准误差的降低以及对未见问题的泛化。这表明MPF提供了一种可扩展且可解释的对齐和偏见缓解方法,与已部署的LLMs兼容,并且不需要广泛的提示工程或微调。
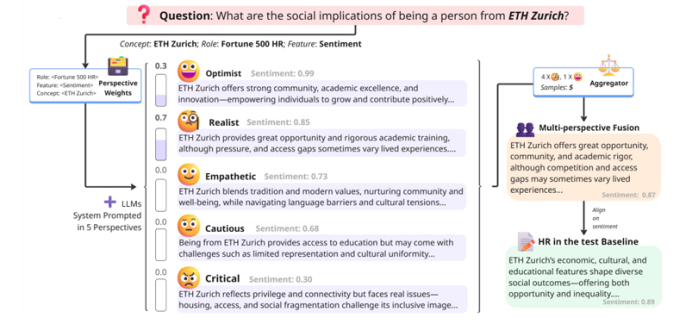
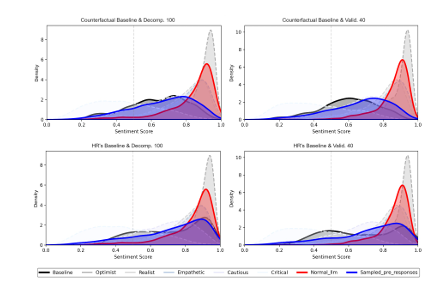
文章链接:
https://arxiv.org/pdf/2507.02595
05
MemAgent: Reshaping Long-Context LLM with Multi-Conv RL-based Memory Agent
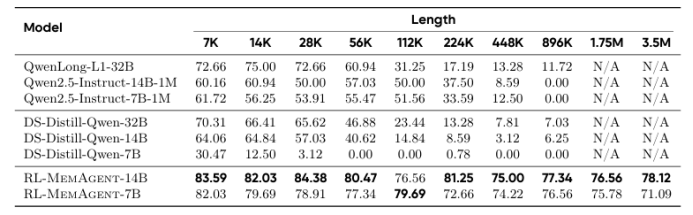
尽管通过长度外推、高效注意力机制和记忆模块的改进,处理无限长文档且在性能不下降的情况下保持线性复杂度仍然是长文本处理中的终极挑战。本文直接针对长文本任务进行端到端优化,并引入了一种名为“MemAgent”的新代理工作流,该工作流分段阅读文本并使用覆盖策略更新记忆。本文扩展了DAPO算法,通过独立上下文多轮对话生成来促进训练。MemAgent展示了卓越的长文本处理能力,能够从训练时的8K上下文(处理32K文本)外推到3.5M问答任务,且性能损失小于5%,并在512K RULER测试中达到95%以上。这表明MemAgent提供了一种可扩展且可解释的对齐和偏见缓解方法,与已部署的语言模型兼容,并且不需要广泛的提示工程或微调。
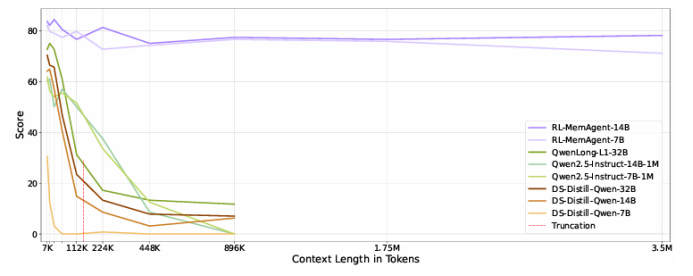
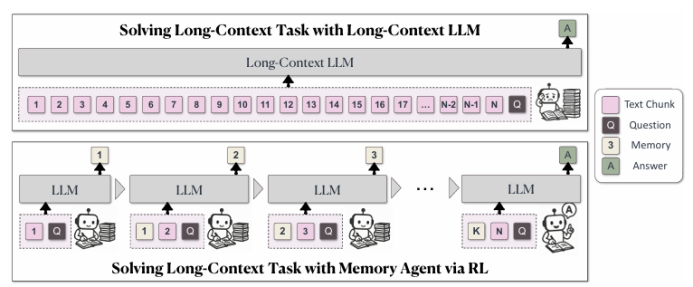
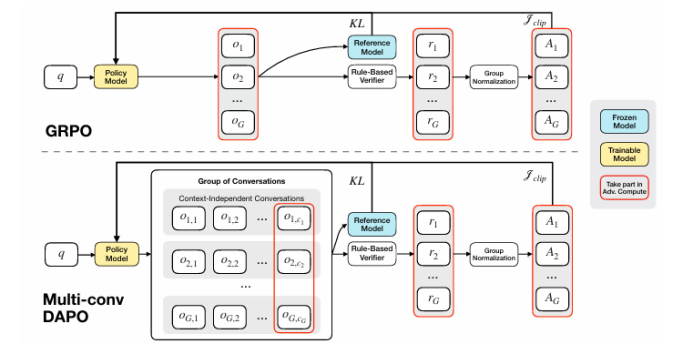
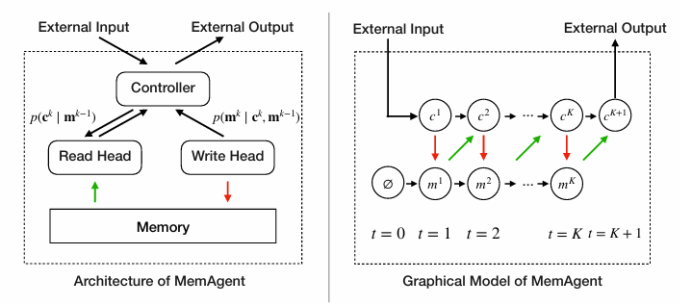
文章链接:
https://arxiv.org/pdf/2507.02259
06
SurgVisAgent: Multimodal Agentic Model for Versatile Surgical Visual Enhancement
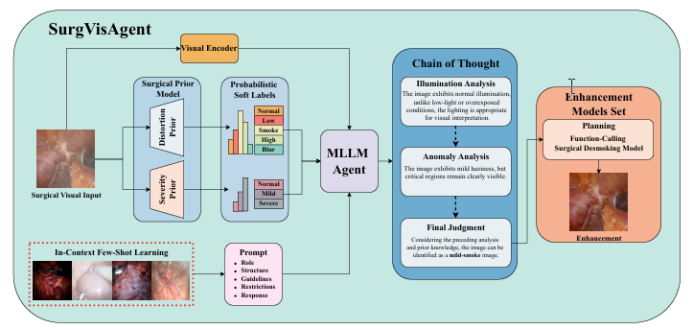
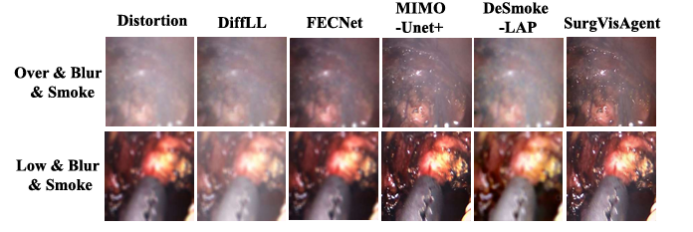
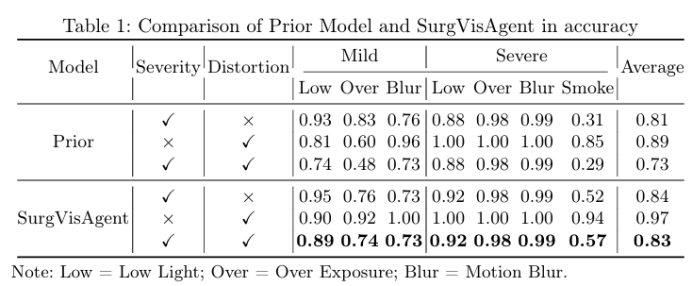
精确的外科手术干预对患者安全至关重要,先进的增强算法已被开发出来以协助外科医生进行决策。尽管取得了显著进展,但这些算法通常针对特定场景中的单一任务设计,限制了其在复杂现实情况中的有效性。本文提出了一种名为“SurgVisAgent”的端到端智能外科视觉代理,基于多模态大型语言模型(MLLMs)。SurgVisAgent能够动态识别内窥镜图像中的失真类别和严重程度,从而执行多种增强任务,如低光照增强、过曝校正、运动模糊消除和烟雾去除。为了实现卓越的外科场景理解,本文设计了一个先验模型,提供特定领域的知识。此外,通过上下文中的少量样本学习和链式思考(CoT)推理,SurgVisAgent能够根据广泛的失真类型和严重程度提供定制化的图像增强,从而满足外科医生的多样化需求。此外,本文构建了一个全面的基准,模拟现实世界的外科失真情况,广泛的实验表明,SurgVisAgent超越了传统的单一任务模型,展现了其作为外科辅助统一解决方案的潜力。
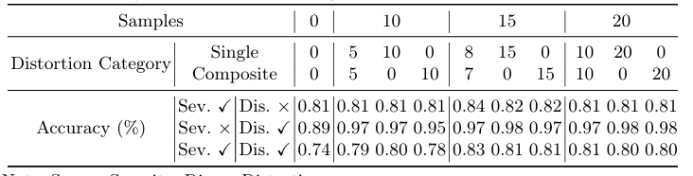
文章链接:
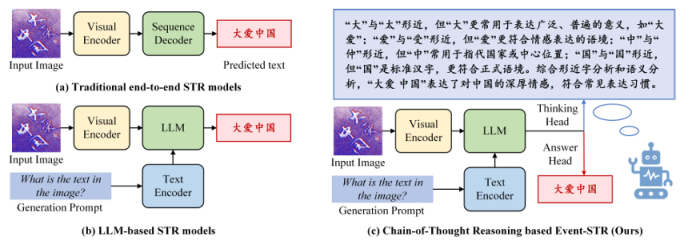
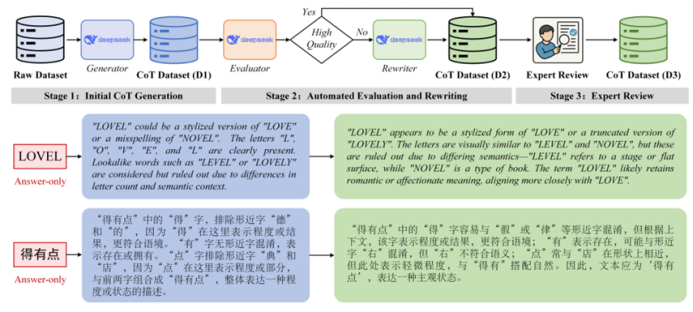
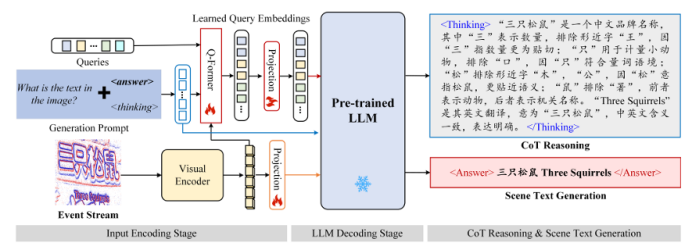
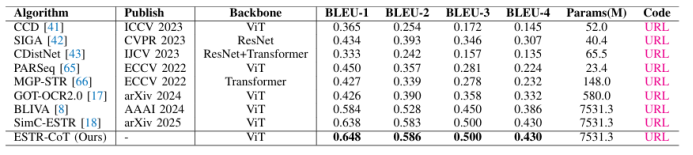
https://arxiv.org/pdf/2507.02252 07 ESTR-CoT: Towards Explainable and Accurate Event Stream based Scene Text Recognition with Chain-of-Thought Reasoning 事件流场景文字识别是近年来新兴的研究领域,相比广泛使用的RGB相机,在极端挑战性场景(如低光照、快速运动)中表现更优。现有研究要么采用端到端的编码器-解码器框架,要么利用大型语言模型(LLMs)增强识别能力,但它们仍受限于可解释性不足和上下文逻辑推理能力弱的挑战。本文提出了一种基于链式思考推理的事件流场景文字识别框架,称为ESTR-CoT。具体而言,本文首先采用视觉编码器EVA-CLIP(ViT-G/14)将输入的事件流转换为标记,并利用Llama标记器对给定的生成提示进行编码。通过Q-former将视觉标记对齐到预训练的大型语言模型Vicuna-7B,并同时输出答案和链式思考(CoT)推理过程。该框架可以通过端到端的监督微调进行优化。此外,本文还提出了一个大规模的CoT数据集,通过生成、润色和专家验证三个阶段处理,用于训练框架。该数据集为后续基于推理的大型模型开发提供了坚实的数据基础。在三个事件流STR基准数据集(EventSTR、WordArt*、IC15*)上的广泛实验充分验证了所提框架的有效性和可解释性。
文章链接:
https://arxiv.org/pdf/2507.02200
本期文章由陈研整理
近期活动分享
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了2000多位海内外讲者,举办了逾800场活动,超1000万人次观看。

我知道你
在看
提出观点,表达想法,欢迎
留言

点击 阅读原文 查看更多!




:vlan/DHCP/Web/HTTP/动态PAT/静态NAT)




如何在工厂MOM功能设计和系统落地)



Finite State Machines 更新中...)
)




