PyTorch深度学习框架详解与实战
1. PyTorch简介与环境配置
1.1 安装与导入
# 基础导入
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_regression, make_classification
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler# 检查PyTorch版本和CUDA可用性
print(f"PyTorch版本: {torch.__version__}")
print(f"CUDA是否可用: {torch.cuda.is_available()}")
print(f"CUDA版本: {torch.version.cuda}")
print(f"可用GPU数量: {torch.cuda.device_count()}")# 设置设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")

1.2 设置随机种子(保证可重复性)
def set_seed(seed=42):torch.manual_seed(seed)torch.cuda.manual_seed(seed)torch.cuda.manual_seed_all(seed)np.random.seed(seed)torch.backends.cudnn.deterministic = Truetorch.backends.cudnn.benchmark = Falseset_seed(42)
2. PyTorch核心API详解
2.1 张量(Tensor)操作
# 创建张量的多种方式
# 1. 从列表创建
tensor_from_list = torch.tensor([[1, 2, 3], [4, 5, 6]], dtype=torch.float32)
print(f"从列表创建: \n{tensor_from_list}")# 2. 创建特定形状的张量
zeros_tensor = torch.zeros(3, 4, device=device)
ones_tensor = torch.ones(2, 3, device=device)
rand_tensor = torch.rand(2, 3, device=device) # 均匀分布 [0, 1)
randn_tensor = torch.randn(2, 3, device=device) # 标准正态分布# 3. 创建序列
arange_tensor = torch.arange(0, 10, 2, device=device)
linspace_tensor = torch.linspace(0, 1, 5, device=device)print(f"\n零张量: \n{zeros_tensor}")
print(f"\n随机张量: \n{rand_tensor}")
print(f"\n序列张量: {arange_tensor}")

2.2 张量操作与自动求导
# 创建需要梯度的张量
x = torch.tensor([[1.0, 2.0], [3.0, 4.0]], requires_grad=True, device=device)
y = torch.tensor([[2.0, 1.0], [1.0, 2.0]], requires_grad=True, device=device)# 前向传播
z = x * y + x ** 2
out = z.mean()print(f"x: \n{x}")
print(f"z: \n{z}")
print(f"输出: {out}")# 反向传播
out.backward()print(f"\nx的梯度: \n{x.grad}")
print(f"y的梯度: \n{y.grad}")

2.3 常用张量操作
# 形状操作
tensor = torch.randn(2, 3, 4, device=device)
print(f"原始形状: {tensor.shape}")# reshape/view
reshaped = tensor.reshape(6, 4) # 或使用 tensor.view(6, 4)
print(f"重塑后: {reshaped.shape}")# 转置
transposed = tensor.transpose(0, 1)
print(f"转置后: {transposed.shape}")# squeeze和unsqueeze
squeezed = torch.randn(1, 3, 1, 4, device=device).squeeze()
print(f"压缩后: {squeezed.shape}")unsqueezed = squeezed.unsqueeze(0)
print(f"扩展后: {unsqueezed.shape}")# 拼接和分割
a = torch.randn(2, 3, device=device)
b = torch.randn(2, 3, device=device)
concatenated = torch.cat([a, b], dim=0)
print(f"\n拼接后: {concatenated.shape}")chunks = torch.chunk(concatenated, 2, dim=0)
print(f"分割后块数: {len(chunks)}")

3. 神经网络模块 (nn.Module)
3.1 常用层详解
# 全连接层
linear = nn.Linear(10, 5, bias=True).to(device)
print(f"全连接层权重形状: {linear.weight.shape}")
print(f"全连接层偏置形状: {linear.bias.shape}")# 卷积层
conv2d = nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3, stride=1, padding=1).to(device)
print(f"\n卷积层权重形状: {conv2d.weight.shape}")# 批归一化
bn = nn.BatchNorm1d(num_features=10).to(device)
print(f"\n批归一化参数:")
print(f" - running_mean形状: {bn.running_mean.shape}")
print(f" - running_var形状: {bn.running_var.shape}")# Dropout
dropout = nn.Dropout(p=0.5)# 激活函数
relu = nn.ReLU()
sigmoid = nn.Sigmoid()
tanh = nn.Tanh()
leaky_relu = nn.LeakyReLU(negative_slope=0.01)

3.2 损失函数详解
# 回归损失
mse_loss = nn.MSELoss()
l1_loss = nn.L1Loss()
smooth_l1_loss = nn.SmoothL1Loss()# 分类损失
ce_loss = nn.CrossEntropyLoss() # 包含了softmax
bce_loss = nn.BCELoss() # 二分类,需要先sigmoid
bce_with_logits = nn.BCEWithLogitsLoss() # 包含了sigmoid# 示例
pred = torch.randn(4, 3, device=device)
target = torch.tensor([0, 1, 2, 0], device=device)
loss = ce_loss(pred, target)
print(f"交叉熵损失: {loss.item()}")
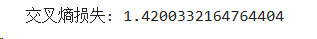
3.3 优化器详解
# 创建模拟参数
params = [torch.randn(10, 5, requires_grad=True, device=device)]# 不同优化器
sgd = optim.SGD(params, lr=0.01, momentum=0.9, weight_decay=1e-4)
adam = optim.Adam(params, lr=0.001, betas=(0.9, 0.999), eps=1e-8)
adamw = optim.AdamW(params, lr=0.001, weight_decay=0.01)
rmsprop = optim.RMSprop(params, lr=0.001, alpha=0.99)# 学习率调度器
scheduler_step = optim.lr_scheduler.StepLR(adam, step_size=10, gamma=0.1)
scheduler_cosine = optim.lr_scheduler.CosineAnnealingLR(adam, T_max=100)
scheduler_reduce = optim.lr_scheduler.ReduceLROnPlateau(adam, mode='min', patience=5, factor=0.5)
4. 回归任务完整案例
4.1 生成回归数据集
# 生成回归数据
X, y = make_regression(n_samples=1000, n_features=10, n_informative=8, noise=10, random_state=42)# 数据预处理
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42
)# 转换为PyTorch张量
X_train_tensor = torch.FloatTensor(X_train).to(device)
y_train_tensor = torch.FloatTensor(y_train).reshape(-1, 1).to(device)
X_test_tensor = torch.FloatTensor(X_test).to(device)
y_test_tensor = torch.FloatTensor(y_test).reshape(-1, 1).to(device)print(f"训练集大小: {X_train_tensor.shape}")
print(f"测试集大小: {X_test_tensor.shape}")
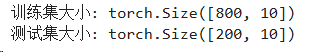
4.2 定义回归模型
class RegressionNet(nn.Module):def __init__(self, input_dim, hidden_dims, output_dim=1, dropout_rate=0.2):super(RegressionNet, self).__init__()# 构建层列表layers = []prev_dim = input_dim# 隐藏层for hidden_dim in hidden_dims:layers.append(nn.Linear(prev_dim, hidden_dim))layers.append(nn.BatchNorm1d(hidden_dim))layers.append(nn.ReLU())layers.append(nn.Dropout(dropout_rate))prev_dim = hidden_dim# 输出层layers.append(nn.Linear(prev_dim, output_dim))# 将所有层组合成Sequentialself.model = nn.Sequential(*layers)# 初始化权重self._initialize_weights()def _initialize_weights(self):for m in self.modules():if isinstance(m, nn.Linear):nn.init.xavier_uniform_(m.weight)if m.bias is not None:nn.init.zeros_(m.bias)elif isinstance(m, nn.BatchNorm1d):nn.init.ones_(m.weight)nn.init.zeros_(m.bias)def forward(self, x):return self.model(x)# 创建模型实例
reg_model = RegressionNet(input_dim=10,hidden_dims=[64, 32, 16],output_dim=1,dropout_rate=0.2
).to(device)print(reg_model)
print(f"\n总参数量: {sum(p.numel() for p in reg_model.parameters())}")

4.3 创建数据加载器
# 创建数据集
train_dataset = TensorDataset(X_train_tensor, y_train_tensor)
test_dataset = TensorDataset(X_test_tensor, y_test_tensor)# 创建数据加载器
batch_size = 32
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=0)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, num_workers=0)print(f"批次数量: {len(train_loader)}")

4.4 训练回归模型
# 设置训练参数
criterion = nn.MSELoss()
optimizer = optim.Adam(reg_model.parameters(), lr=0.001, weight_decay=1e-5)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', patience=10, factor=0.5)# 训练函数
def train_epoch(model, loader, criterion, optimizer, device):model.train()total_loss = 0for batch_idx, (data, target) in enumerate(loader):data, target = data.to(device), target.to(device)# 前向传播optimizer.zero_grad()output = model(data)loss = criterion(output, target)# 反向传播loss.backward()optimizer.step()total_loss += loss.item()return total_loss / len(loader)# 评估函数
def evaluate(model, loader, criterion, device):model.eval()total_loss = 0predictions = []actuals = []with torch.no_grad():for data, target in loader:data, target = data.to(device), target.to(device)output = model(data)loss = criterion(output, target)total_loss += loss.item()predictions.extend(output.cpu().numpy())actuals.extend(target.cpu().numpy())return total_loss / len(loader), np.array(predictions), np.array(actuals)# 训练循环
epochs = 100
train_losses = []
test_losses = []for epoch in range(epochs):train_loss = train_epoch(reg_model, train_loader, criterion, optimizer, device)test_loss, predictions, actuals = evaluate(reg_model, test_loader, criterion, device)train_losses.append(train_loss)test_losses.append(test_loss)# 学习率调度scheduler.step(test_loss)if (epoch + 1) % 10 == 0:print(f'Epoch [{epoch+1}/{epochs}], 'f'Train Loss: {train_loss:.4f}, 'f'Test Loss: {test_loss:.4f}, 'f'LR: {optimizer.param_groups[0]["lr"]:.6f}')

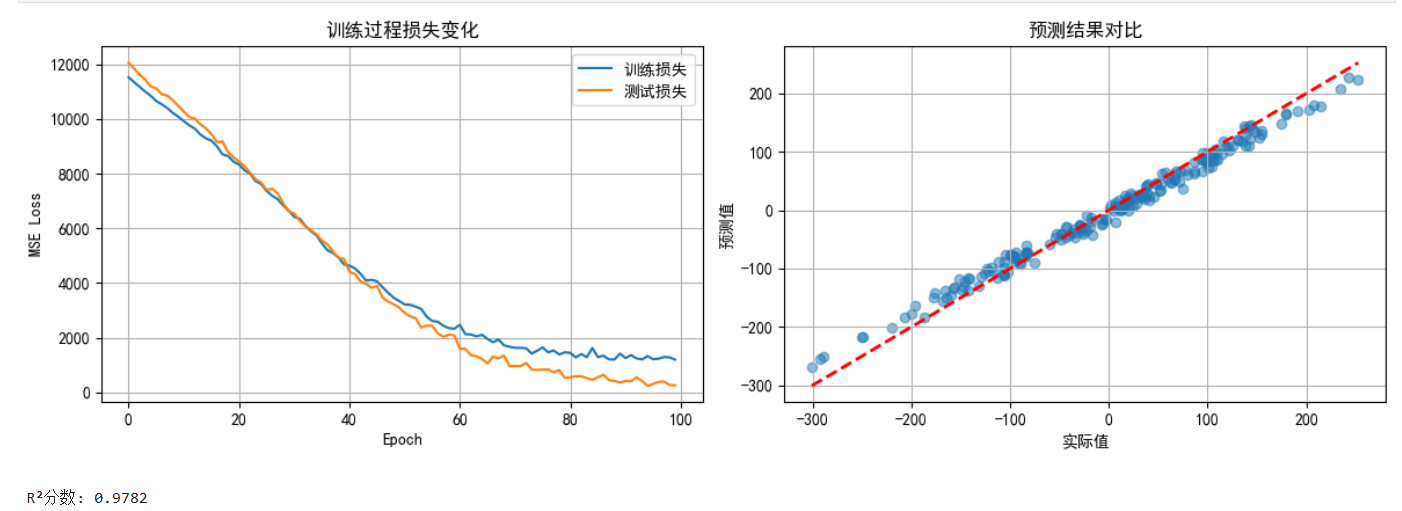
4.5 可视化回归结果
# 绘制损失曲线
plt.figure(figsize=(12, 4))plt.subplot(1, 2, 1)
plt.plot(train_losses, label='训练损失')
plt.plot(test_losses, label='测试损失')
plt.xlabel('Epoch')
plt.ylabel('MSE Loss')
plt.title('训练过程损失变化')
plt.legend()
plt.grid(True)# 预测vs实际值散点图
plt.subplot(1, 2, 2)
_, final_predictions, final_actuals = evaluate(reg_model, test_loader, criterion, device)
plt.scatter(final_actuals, final_predictions, alpha=0.5)
plt.plot([final_actuals.min(), final_actuals.max()], [final_actuals.min(), final_actuals.max()], 'r--', lw=2)
plt.xlabel('实际值')
plt.ylabel('预测值')
plt.title('预测结果对比')
plt.grid(True)plt.tight_layout()
plt.show()# 计算R²分数
from sklearn.metrics import r2_score
r2 = r2_score(final_actuals, final_predictions)
print(f"\nR²分数: {r2:.4f}")
5. 分类任务完整案例
5.1 生成分类数据集
# 生成多分类数据
X, y = make_classification(n_samples=2000, n_features=20, n_informative=15,n_redundant=5, n_classes=4, n_clusters_per_class=2,flip_y=0.1, random_state=42)# 数据预处理
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, stratify=y, random_state=42
)# 转换为PyTorch张量
X_train_tensor = torch.FloatTensor(X_train).to(device)
y_train_tensor = torch.LongTensor(y_train).to(device)
X_test_tensor = torch.FloatTensor(X_test).to(device)
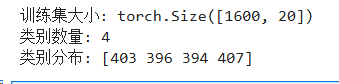
y_test_tensor = torch.LongTensor(y_test).to(device)print(f"训练集大小: {X_train_tensor.shape}")
print(f"类别数量: {len(np.unique(y))}")
print(f"类别分布: {np.bincount(y_train)}")
5.2 定义分类模型
class ClassificationNet(nn.Module):def __init__(self, input_dim, hidden_dims, num_classes, dropout_rate=0.3):super(ClassificationNet, self).__init__()layers = []prev_dim = input_dim# 隐藏层for i, hidden_dim in enumerate(hidden_dims):layers.append(nn.Linear(prev_dim, hidden_dim))layers.append(nn.BatchNorm1d(hidden_dim))layers.append(nn.ReLU())# 在前几层使用更高的dropoutif i < len(hidden_dims) - 1:layers.append(nn.Dropout(dropout_rate))else:layers.append(nn.Dropout(dropout_rate * 0.5))prev_dim = hidden_dim# 输出层layers.append(nn.Linear(prev_dim, num_classes))self.model = nn.Sequential(*layers)self._initialize_weights()def _initialize_weights(self):for m in self.modules():if isinstance(m, nn.Linear):# 使用He初始化(适合ReLU)nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')if m.bias is not None:nn.init.constant_(m.bias, 0)elif isinstance(m, nn.BatchNorm1d):nn.init.constant_(m.weight, 1)nn.init.constant_(m.bias, 0)def forward(self, x):return self.model(x)# 创建模型
clf_model = ClassificationNet(input_dim=20,hidden_dims=[128, 64, 32],num_classes=4,dropout_rate=0.3
).to(device)print(clf_model)
print(f"\n总参数量: {sum(p.numel() for p in clf_model.parameters())}")

5.3 创建数据加载器(带数据增强)
class AddGaussianNoise:"""训练时添加高斯噪声的数据增强"""def __init__(self, mean=0., std=0.1):self.mean = meanself.std = stddef __call__(self, tensor):return tensor + torch.randn(tensor.size(), device=tensor.device) * self.std + self.mean# 创建数据集
train_dataset = TensorDataset(X_train_tensor, y_train_tensor)
test_dataset = TensorDataset(X_test_tensor, y_test_tensor)# 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=0)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, num_workers=0)
5.4 训练分类模型(带早停)
# 设置训练参数
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(clf_model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=50)# 早停类
class EarlyStopping:def __init__(self, patience=15, verbose=False, delta=0):self.patience = patienceself.verbose = verboseself.counter = 0self.best_score = Noneself.early_stop = Falseself.val_loss_min = np.Infself.delta = deltaself.best_model = Nonedef __call__(self, val_loss, model):score = -val_lossif self.best_score is None:self.best_score = scoreself.save_checkpoint(val_loss, model)elif score < self.best_score + self.delta:self.counter += 1if self.verbose:print(f'EarlyStopping counter: {self.counter} out of {self.patience}')if self.counter >= self.patience:self.early_stop = Trueelse:self.best_score = scoreself.save_checkpoint(val_loss, model)self.counter = 0def save_checkpoint(self, val_loss, model):if self.verbose:print(f'Validation loss decreased ({self.val_loss_min:.6f} --> {val_loss:.6f}). Saving model ...')self.best_model = model.state_dict().copy()self.val_loss_min = val_loss# 训练函数(带混合精度训练)
from torch.cuda.amp import autocast, GradScalerscaler = GradScaler()def train_epoch_amp(model, loader, criterion, optimizer, device):model.train()total_loss = 0correct = 0total = 0for batch_idx, (data, target) in enumerate(loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()# 混合精度训练with autocast():output = model(data)loss = criterion(output, target)# 反向传播scaler.scale(loss).backward()scaler.step(optimizer)scaler.update()total_loss += loss.item()_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()accuracy = 100. * correct / totalreturn total_loss / len(loader), accuracy# 评估函数
def evaluate_classification(model, loader, criterion, device):model.eval()total_loss = 0correct = 0total = 0all_predictions = []all_targets = []all_probs = []with torch.no_grad():for data, target in loader:data, target = data.to(device), target.to(device)output = model(data)loss = criterion(output, target)total_loss += loss.item()_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()# 保存预测结果用于后续分析all_predictions.extend(predicted.cpu().numpy())all_targets.extend(target.cpu().numpy())all_probs.extend(F.softmax(output, dim=1).cpu().numpy())accuracy = 100. * correct / totalreturn total_loss / len(loader), accuracy, all_predictions, all_targets, all_probs# 训练循环
epochs = 100
train_losses = []
train_accs = []
test_losses = []
test_accs = []early_stopping = EarlyStopping(patience=15, verbose=True)for epoch in range(epochs):train_loss, train_acc = train_epoch_amp(clf_model, train_loader, criterion, optimizer, device)test_loss, test_acc, _, _, _ = evaluate_classification(clf_model, test_loader, criterion, device)train_losses.append(train_loss)train_accs.append(train_acc)test_losses.append(test_loss)test_accs.append(test_acc)scheduler.step()if (epoch + 1) % 10 == 0:print(f'Epoch [{epoch+1}/{epochs}], 'f'Train Loss: {train_loss:.4f}, Train Acc: {train_acc:.2f}%, 'f'Test Loss: {test_loss:.4f}, Test Acc: {test_acc:.2f}%')# 早停检查early_stopping(test_loss, clf_model)if early_stopping.early_stop:print("Early stopping")# 加载最佳模型clf_model.load_state_dict(early_stopping.best_model)break
5.5 分类结果可视化与评估
from sklearn.metrics import confusion_matrix, classification_report
import seaborn as sns# 获取最终预测结果
_, _, predictions, actuals, probs = evaluate_classification(clf_model, test_loader, criterion, device
)# 绘制训练历史
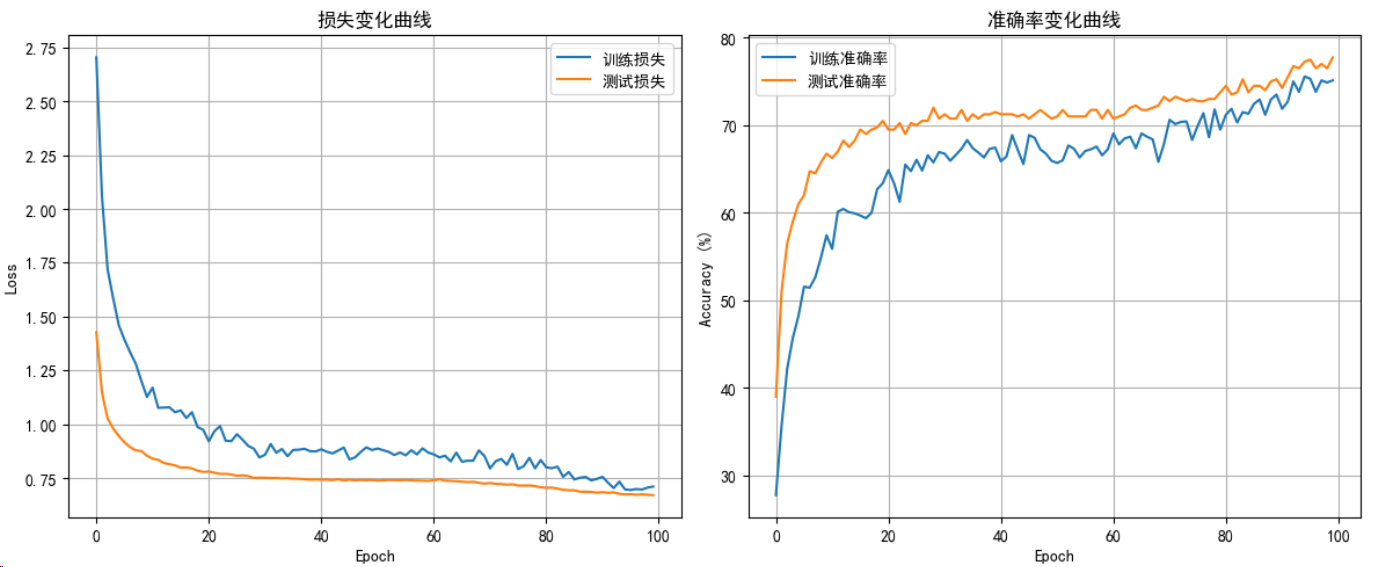
fig, axes = plt.subplots(2, 2, figsize=(12, 10))# 损失曲线
axes[0, 0].plot(train_losses, label='训练损失')
axes[0, 0].plot(test_losses, label='测试损失')
axes[0, 0].set_xlabel('Epoch')
axes[0, 0].set_ylabel('Loss')
axes[0, 0].set_title('损失变化曲线')
axes[0, 0].legend()
axes[0, 0].grid(True)# 准确率曲线
axes[0, 1].plot(train_accs, label='训练准确率')
axes[0, 1].plot(test_accs, label='测试准确率')
axes[0, 1].set_xlabel('Epoch')
axes[0, 1].set_ylabel('Accuracy (%)')
axes[0, 1].set_title('准确率变化曲线')
axes[0, 1].legend()
axes[0, 1].grid(True)# 混淆矩阵
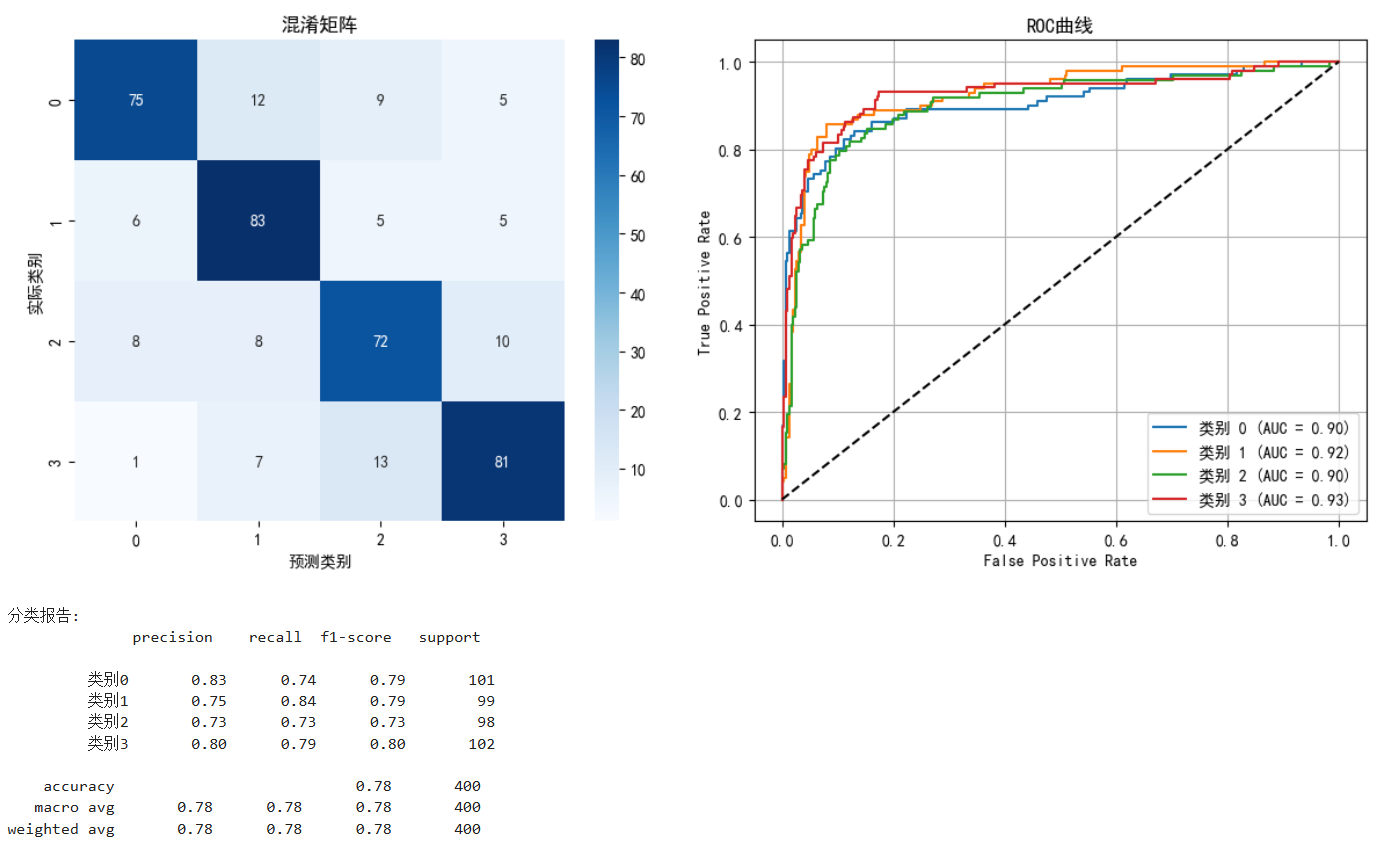
cm = confusion_matrix(actuals, predictions)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', ax=axes[1, 0])
axes[1, 0].set_xlabel('预测类别')
axes[1, 0].set_ylabel('实际类别')
axes[1, 0].set_title('混淆矩阵')# ROC曲线(多分类)
from sklearn.metrics import roc_curve, auc
from sklearn.preprocessing import label_binarize# 将标签二值化
y_test_bin = label_binarize(actuals, classes=[0, 1, 2, 3])
probs_array = np.array(probs)# 计算每个类别的ROC曲线
for i in range(4):fpr, tpr, _ = roc_curve(y_test_bin[:, i], probs_array[:, i])roc_auc = auc(fpr, tpr)axes[1, 1].plot(fpr, tpr, label=f'类别 {i} (AUC = {roc_auc:.2f})')axes[1, 1].plot([0, 1], [0, 1], 'k--')
axes[1, 1].set_xlabel('False Positive Rate')
axes[1, 1].set_ylabel('True Positive Rate')
axes[1, 1].set_title('ROC曲线')
axes[1, 1].legend()
axes[1, 1].grid(True)plt.tight_layout()
plt.show()# 打印分类报告
print("\n分类报告:")
print(classification_report(actuals, predictions, target_names=[f'类别{i}' for i in range(4)]))
6. 高级技巧与最佳实践
6.1 模型保存与加载
# 保存完整模型
torch.save(clf_model, 'complete_model.pth')# 保存模型参数
torch.save(clf_model.state_dict(), 'model_weights.pth')# 保存检查点(包含优化器状态等)
checkpoint = {'epoch': epoch,'model_state_dict': clf_model.state_dict(),'optimizer_state_dict': optimizer.state_dict(),'loss': test_loss,'accuracy': test_acc
}
torch.save(checkpoint, 'checkpoint.pth')# 加载模型
# 方式1:加载完整模型
loaded_model = torch.load('complete_model.pth', map_location=device)# 方式2:加载模型参数
new_model = ClassificationNet(input_dim=20, hidden_dims=[128, 64, 32], num_classes=4).to(device)
new_model.load_state_dict(torch.load('model_weights.pth', map_location=device))# 方式3:加载检查点
checkpoint = torch.load('checkpoint.pth', map_location=device)
new_model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
epoch = checkpoint['epoch']
loss = checkpoint['loss']
6.2 模型并行与数据并行
# 数据并行(多GPU)
if torch.cuda.device_count() > 1:print(f"使用 {torch.cuda.device_count()} 个GPU!")model = nn.DataParallel(clf_model)# 分布式数据并行(更高效)
# import torch.distributed as dist
# from torch.nn.parallel import DistributedDataParallel as DDP
#
# dist.init_process_group("nccl")
# model = DDP(model)
6.3 梯度累积(处理大批量)
accumulation_steps = 4
optimizer.zero_grad()for i, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)output = clf_model(data)loss = criterion(output, target)loss = loss / accumulation_steps # 标准化损失loss.backward()if (i + 1) % accumulation_steps == 0:optimizer.step()optimizer.zero_grad()
6.4 梯度裁剪
# 防止梯度爆炸
max_norm = 1.0for epoch in range(1): # 示例for data, target in train_loader:data, target = data.to(device), target.to(device)optimizer.zero_grad()output = clf_model(data)loss = criterion(output, target)loss.backward()# 梯度裁剪torch.nn.utils.clip_grad_norm_(clf_model.parameters(), max_norm)optimizer.step()break # 只演示一个批次
6.5 自定义数据集类
class CustomDataset(torch.utils.data.Dataset):def __init__(self, X, y, transform=None):self.X = torch.FloatTensor(X)self.y = torch.LongTensor(y)self.transform = transformdef __len__(self):return len(self.X)def __getitem__(self, idx):sample_X = self.X[idx]sample_y = self.y[idx]if self.transform:sample_X = self.transform(sample_X)return sample_X, sample_y# 使用自定义数据集
custom_dataset = CustomDataset(X_train, y_train, transform=AddGaussianNoise(0, 0.1))
custom_loader = DataLoader(custom_dataset, batch_size=32, shuffle=True)
7. 性能优化技巧
7.1 使用TensorBoard监控训练
from torch.utils.tensorboard import SummaryWriter# 创建TensorBoard写入器
writer = SummaryWriter('runs/experiment_1')# 在训练循环中记录
for epoch in range(10): # 简化示例train_loss = np.random.random() # 模拟损失test_loss = np.random.random()writer.add_scalar('Loss/train', train_loss, epoch)writer.add_scalar('Loss/test', test_loss, epoch)# 记录模型权重直方图for name, param in clf_model.named_parameters():writer.add_histogram(name, param, epoch)writer.close()# 运行命令查看:tensorboard --logdir=runs
7.2 内存优化
# 1. 使用半精度训练
model_fp16 = clf_model.half() # 转换为float16# 2. 梯度检查点(节省内存)
# from torch.utils.checkpoint import checkpoint
# 在forward中使用checkpoint包装计算密集型层# 3. 清理不需要的张量
del X_train_tensor, y_train_tensor
torch.cuda.empty_cache()# 4. 使用inplace操作
x = torch.randn(100, 100, device=device)
x.relu_() # inplace ReLU# 5. 关闭不需要的梯度计算
with torch.no_grad():# 推理代码pass
7.3 CUDA优化技巧
# 1. 异步数据传输
data_cpu = torch.randn(1000, 1000)
data_gpu = data_cpu.to(device, non_blocking=True)# 2. 固定内存
# 在DataLoader中使用pin_memory=True
loader = DataLoader(dataset, batch_size=32, pin_memory=True)# 3. CUDA流
stream = torch.cuda.Stream()
with torch.cuda.stream(stream):# 异步操作pass# 4. 预先分配内存
torch.cuda.empty_cache()
torch.cuda.set_per_process_memory_fraction(0.8) # 使用80%的GPU内存# 5. 基准测试模式
torch.backends.cudnn.benchmark = True # 适用于输入大小固定的情况
8. 总结
本教程详细介绍了PyTorch框架的核心概念和实际应用:
- 基础概念:张量操作、自动求导、GPU加速
- 神经网络模块:层、损失函数、优化器
- 完整案例:回归和分类任务的端到端实现
- 高级技巧:模型保存、并行计算、性能优化
- 最佳实践:数据增强、早停、梯度裁剪等
关键要点:
- 始终注意数据和模型的设备位置(CPU/GPU)
- 使用DataLoader进行批处理和数据加载优化
- 合理使用正则化技术(Dropout、BatchNorm、权重衰减)
- 监控训练过程,使用早停避免过拟合
- 根据任务选择合适的损失函数和评估指标
- 利用GPU加速和混合精度训练提升性能











)





上安装SVN Server和库权限设置问题)

