一、引言
在影视行业分析与数据科学实践中,高分电影数据的深度挖掘已成为平台优化内容推荐、制片方研判市场趋势、影迷发现优质作品的核心支撑 —— 通过上映年份与评分的关联可捕捉电影质量演变、依托热度与投票数能定位爆款潜质、结合剧情概述可开展情感与主题分析,直接影响影视内容的生产、分发与消费全链路。当前,头部流媒体平台已通过电影数据建模将用户推荐点击率提升 30% 以上,而影视分析师、数据科学家及影迷常面临 “数据碎片化(单维度信息分散)”“关键指标缺失(无热度评分、剧情文本)”“时间跨度短(难以覆盖百年电影史)” 等问题,制约电影趋势洞察与内容价值挖掘的深度。
然而,多数公开电影数据集存在三大核心痛点:一是维度单一,仅包含电影名称、评分等基础信息,缺乏 “热度分数、投票数、剧情概述” 等关键分析维度,无法支撑多场景任务;二是时间覆盖有限,多聚焦近 10 年影片,忽视 1900 年代经典作品,难以分析长期行业趋势;三是数据非结构化,剧情概述格式混乱、上映日期格式不统一,需大量预处理才能用于 NLP 或时间序列分析。这些问题导致用户需投入 50% 以上时间整合清洗数据,难以快速开展 “趋势可视化”“推荐系统构建” 等核心任务。
本数据集针对上述痛点,提供TMDb 权威来源的高分电影全维度数据,涵盖 9120 部影片、7 个核心指标,包含电影标识(ID / 标题)、时间信息(上映日期,1902-2025 年)、质量指标(平均评分 / 投票数)、热度指标(TMDb 热度分数)、剧情文本(概述),数据经标准化处理无缺失值,评分均≥5.1 分(高分影片门槛),无需额外预处理即可直接用于电影趋势分析、推荐系统搭建与 NLP 建模,目标是让所有影视相关从业者与数据学习者都能低成本挖掘电影数据价值。
二、核心信息
数据集核心信息
| 信息类别 | 具体内容 |
|---|---|
| 基础属性 | 数据总量:9120 部高分电影记录;数据类型:结构化影视数据(含标识、时间、质量、热度、文本);数据来源:TMDb(The Movie Database)API 合规采集;时间范围:1902 年 6 月 15 日 - 2025 年 7 月 31 日(覆盖默片时代至未来待映影片,含百年电影史) |
| 采集信息 | 采集场景:TMDb 平台 “高分电影” 专区(评分≥5.1 分,投票数≥300,确保数据质量);覆盖类型:剧情、动作、科幻、动画等全品类;数据分布:2013 年后影片占比 40.9%(3728 部)、2000-2013 年占 30.1%(2748 部)、2000 年前占 29%(2644 部),贴合真实观影偏好(近现代影片数据更丰富) |
| 标注情况 | 标注类型:字段级结构化标注(如vote_average预定义 “1-10 分”、release_date统一 “YYYY-MM-DD” 格式、popularity为 TMDb 官方热度分数(基于用户互动、投票计算));标注精度:数据一致性≥99%(上映日期无逻辑错误、评分与投票数正相关);标注工具:Python API 采集脚本 + TMDb 数据校验(确保 ID 唯一、信息与官方同步) |
| 格式与规格 | 文件格式:CSV(2.93 MB,UTF-8 编码);字段数量:7 列(含id(TMDb 唯一 ID)、title(电影标题)、overview(剧情概述)、release_date(上映日期)、popularity(热度分数)、vote_average(平均评分)、vote_count(投票数));适配格式:支持 Python pandas 读取、Excel 分析、SQL 导入、Tableau/Power BI 可视化、NLP 工具(如 NLTK、spaCy)文本处理 |
| 数据划分 | 数据分区:按 “上映年代(1900s/1950s/2000s/2020s)”“评分区间(5.1-6.0/6.1-7.0/7.1-8.0/8.1+)”“热度等级(<10/10-30/>30)” 三级分区,支持按维度快速筛选;无训练集 / 验证集划分(用户可按需拆分,如按 “7300 部” 为训练集、“1820 部” 为测试集,用于推荐系统建模) |
数据集核心优势
本数据集的核心优势在于 “权威源、全维度、长周期”,解决传统电影数据集 “非权威、单一化、短跨度” 的痛点,具体亮点如下:
优势 1:TMDb API 权威来源 + 多维度指标,数据可信度与实用性双高
数据直接源自 TMDb(全球知名影视数据库,行业认可度高),popularity(热度)、vote_average(评分)等指标为平台官方计算结果(热度基于用户点击、收藏、评论等多维度加权,评分基于真实用户投票),可信度远超非官方爬取数据;7 列指标覆盖 “标识 - 时间 - 质量 - 热度 - 文本” 全链路,如《肖申克的救赎》(id:278)-1994 年上映 - 评分 8.71 - 热度 27.87 - 剧情概述 “银行家安迪入狱后寻求自由”,可直接用于 “评分与热度相关性”“剧情主题聚类” 等多场景分析,避免传统数据集 “仅能做简单统计” 的局限。优势 2:百年时间跨度 + 未来待映影片,支撑长期趋势与前瞻性分析
上映日期覆盖 1902 年(默片《月球旅行记》相关影片)至 2025 年(待映影片如《KPop Demon Hunters》),可完整追踪电影行业 “默片时代→黄金时代→数字时代” 的质量演变(如 1994 年为 “影史神作年”,含《肖申克的救赎》《低俗小说》等多部 8.5 + 分影片);2024-2025 年待映影片数据为 TMDb 基于预售、宣发热度的估算值,可用于 “预测未来爆款”“分析待映影片类型趋势” 等前瞻性任务,相比仅含历史数据的数据集,分析维度更丰富。优势 3:标准化处理 + 无缺失值,降低使用门槛
所有字段均经标准化:release_date统一为 “YYYY-MM-DD” 格式(如 1972-03-14 为《教父》上映日),避免 “1972/3/14”“March 14,1972” 等混乱格式;overview清除特殊字符(如换行符、乱码),可直接用于 NLP 任务;9120 条记录无任何字段缺失(投票数最少 300 票,确保评分代表性),用户直接加载即可使用,相比缺失值超 10% 的数据集,节省 60% 以上预处理时间。
数据应用全流程指导
(1)数据预处理(基础操作:读取、时间处理、文本清洗、特征衍生)
功能目标:加载数据并统一时间格式、清洗剧情文本,衍生年代、评分等级、热度分层等核心分析指标,为后续建模与可视化做准备。
代码示例(Python,基于 pandas):
import pandas as pd
import numpy as np
import re
from datetime import datetime
import nltk
from nltk.corpus import stopwords
nltk.download('stopwords')# 1. 读取CSV数据(关键参数:encoding确保UTF-8编码,指定字段类型)
df = pd.read_csv("top_rated_movies.csv",encoding="utf-8",dtype={"id": int,"title": str,"overview": str,"popularity": float,"vote_average": float,"vote_count": int},parse_dates=["release_date"] # 自动解析日期字段
)# 2. 数据清洗(时间格式统一+文本清洗)
# 处理日期异常值(如未来过远期影片,限制为2025年12月31日前)
df = df[df["release_date"] <= pd.Timestamp("2025-12-31")]# 清洗剧情概述文本(去除特殊字符、小写化,适配NLP任务)
def clean_overview(text):if pd.isna(text):return ""# 去除特殊字符(数字、符号),保留字母和空格text = re.sub(r"[^a-zA-Z\s]", "", text)# 小写化text = text.lower()# 去除停用词(如the、a,减少噪声)stop_words = set(stopwords.words('english'))text = " ".join([word for word in text.split() if word not in stop_words])return textdf["cleaned_overview"] = df["overview"].apply(clean_overview)# 3. 特征衍生(生成电影分析核心指标)
# 衍生指标1:上映年代(按10年划分,如1990s、2020s)
df["release_decade"] = (df["release_date"].dt.year // 10) * 10
df["release_decade_label"] = df["release_decade"].astype(str) + "s"# 衍生指标2:评分等级(按TMDb高分标准划分)
df["rating_tier"] = pd.cut(df["vote_average"],bins=[5.0, 6.0, 7.0, 8.0, 9.0],labels=["良好(5.1-6.0)", "优秀(6.1-7.0)", "顶级(7.1-8.0)", "神作(8.1+)"]
)# 衍生指标3:热度分层(按popularity分布划分)
df["popularity_tier"] = pd.cut(df["popularity"],bins=[0, 10, 30, 100, float("inf")],labels=["低热度(<10)", "中热度(10-30)", "高热度(30-100)", "超高热度(>100)"]
)# 衍生指标4:投票数分层(反映评分代表性)
df["vote_count_tier"] = pd.cut(df["vote_count"],bins=[299, 1000, 5000, 20000, float("inf")],labels=["少量投票(300-1000)", "中等投票(1001-5000)", "大量投票(5001-20000)", "海量投票(>20000)"]
)# 衍生指标5:年度电影数量(反映各年电影产出热度)
yearly_movie_count = df.groupby(df["release_date"].dt.year).size().reset_index(name="yearly_count")
df = df.merge(yearly_movie_count,left_on=df["release_date"].dt.year,right_on="release_date",how="left"
).drop("key_0", axis=1)# 输出预处理结果
print(f"预处理后数据总记录数:{len(df)}(目标≈9120,删除未来过远期影片后)")
print(f"时间范围:{df['release_date'].min().strftime('%Y-%m-%d')} 至 {df['release_date'].max().strftime('%Y-%m-%d')}")
print(f"\n衍生指标示例(前5条):")
print(df[["title", "release_decade_label", "rating_tier", "popularity_tier", "vote_count_tier"]].head())
关键说明:
- 时间与文本清洗:日期限制为 2025 年底前,避免无效未来数据;剧情文本去除停用词与特殊字符,减少 NLP 任务噪声(如分析主题时排除 “the”“a” 等无意义词汇);
- 衍生指标设计:
- 年代与评分等级:采用行业通用划分标准(如 “8.1 + 分为神作”),分析结果可直接对接影视评论场景(如 “1990s 神作影片 Top10”);
- 热度与投票数分层:避免 “只看数值不看规模” 的误区(如《盗梦空间》热度 30.06 为 “高热度”,投票数 37871 为 “海量投票”,评分可信度高);
- 年度数量:反映行业产出趋势(如 2010 年后年度影片数量激增,对应数字电影普及)。
(2)核心任务演示(3 个主流分析建模场景)
任务 1:电影评分预测(回归任务,基于随机森林回归)
- 模型选择:推荐随机森林回归(适合处理 “热度 - 投票数 - 年代” 的混合特征,能捕捉 “高热度 + 海量投票 + 近现代→高评分” 的非线性关联,抗过拟合能力强,可输出特征重要性,助力评分影响因素研判);
- 代码示例:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
from sklearn.metrics import mean_absolute_error, r2_score# 1. 数据准备(筛选有足够投票数的影片,确保评分代表性)
df_valid = df[df["vote_count"] >= 1000].copy() # 投票数≥1000,评分更可信# 特征:热度、投票数、上映年代;目标:平均评分
X = df_valid[["popularity", "vote_count", "release_decade"]]
y = df_valid["vote_average"]# 2. 特征工程流水线(数值特征标准化,消除量纲影响)
preprocessor = Pipeline(steps=[("scaler", StandardScaler()) # 统一特征尺度(如投票数范围300-37k,年代范围1900-2020)
])# 3. 拆分训练集(80%)与测试集(20%)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42
)# 4. 训练随机森林模型
rf_pipeline = Pipeline(steps=[("preprocessor", preprocessor),("regressor", RandomForestRegressor(n_estimators=100, # 100棵树,平衡效果与效率max_depth=7, # 限制树深,避免过拟合(多特征易记忆噪声)min_samples_split=6, # 最小分裂样本数,确保节点代表性random_state=42))
])
rf_pipeline.fit(X_train, y_train)# 5. 模型评估
y_pred = rf_pipeline.predict(X_test)
mae = mean_absolute_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)print(f"电影评分预测MAE:{mae:.2f}分(目标<0.3分,误差越小越精准)")
print(f"R²系数:{r2:.4f}(目标≥0.6,反映特征解释能力)")# 6. 特征重要性可视化
feature_names = X.columns
importances = rf_pipeline.named_steps["regressor"].feature_importances_
importance_df = pd.DataFrame({"feature": feature_names, "importance": importances})
importance_df = importance_df.sort_values("importance", ascending=False)plt.figure(figsize=(10, 6))
plt.barh(importance_df["feature"], importance_df["importance"], color="#2ecc71")
plt.xlabel("特征重要性", fontsize=12)
plt.ylabel("特征名称", fontsize=12)
plt.title("电影评分预测 - 特征重要性排序", fontsize=14, fontweight="bold")
plt.grid(axis="x", alpha=0.3)
plt.show()# 7. 预测结果可视化(选取测试集中的10部知名影片示例)
sample_indices = X_test.index[:10]
sample_movies = df_valid.loc[sample_indices, ["title", "vote_average"]]
sample_movies["predicted_rating"] = y_pred[:10].round(2)
sample_movies["error"] = (sample_movies["predicted_rating"] - sample_movies["vote_average"]).round(2)plt.figure(figsize=(12, 6))
x = np.arange(len(sample_movies))
width = 0.35
plt.bar(x - width/2, sample_movies["vote_average"], width, label="真实评分", color="#3498db")
plt.bar(x + width/2, sample_movies["predicted_rating"], width, label="预测评分", color="#e74c3c")
plt.xlabel("电影", fontsize=12)
plt.ylabel("评分(1-10分)", fontsize=12)
plt.title("电影评分预测:真实值vs预测值(示例10部影片)", fontsize=14, fontweight="bold")
plt.xticks(x, sample_movies["title"], rotation=45, ha="right")
plt.legend()
plt.grid(axis="y", alpha=0.3)
plt.tight_layout()
plt.show()# 输出关键结论
print("\n=== 评分预测关键结论 ===")
top_feature = importance_df.iloc[0]["feature"]
top_importance = importance_df.iloc[0]["importance"]
print(f"影响评分最大的特征:{top_feature}(重要性{top_importance:.4f},占总重要性的{top_importance/importance_df['importance'].sum()*100:.2f}%)")
print(f"预测误差最小的影片:{sample_movies.nsmallest(1, 'error')['title'].values[0]}(误差{sample_movies.nsmallest(1, 'error')['error'].values[0]}分)")
- 关键参数说明:
- 数据筛选:仅保留投票数≥1000 的影片,排除投票过少的小众影片(评分易受极端值影响),确保建模数据质量;
max_depth=7:评分受 “投票数(核心,投票越多评分越稳定)、热度(高热度影片多为优质作品)” 影响,7 层树可充分捕捉这些特征交互(如 “海量投票 + 高热度→高评分”),避免过拟合;- 效果评估重点:MAE 需 <0.3 分(评分范围 5.1-8.7,误差过大会导致 “神作” 与 “优秀” 影片误判),R² 需≥0.6(确保 60% 以上的评分变化可由特征解释)。
任务 2:电影剧情主题聚类(无监督学习,基于 TF-IDF+KMeans)
- 模型选择:推荐 TF-IDF(文本特征提取)+KMeans(聚类)组合,适合从剧情概述中挖掘潜在主题(如 “犯罪”“奇幻”“战争”),无需人工标注即可实现文本分组,为电影分类与推荐提供依据;
- 代码示例:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
from sklearn.metrics import silhouette_score# 1. 数据准备(筛选剧情文本非空的影片)
df_text = df[df["cleaned_overview"].str.len() > 10].copy() # 排除过短文本# 2. TF-IDF文本特征提取(将剧情概述转为数值向量)
tfidf = TfidfVectorizer(max_features=1000, # 保留Top1000高频词,减少计算量ngram_range=(1, 2) # 考虑1-2元词(如“world war”“crime story”)
)
X_tfidf = tfidf.fit_transform(df_text["cleaned_overview"])# 3. 确定最佳聚类数(轮廓系数法)
silhouette_scores = []
k_range = range(3, 8) # 测试3-7个聚类
for k in k_range:kmeans = KMeans(n_clusters=k, random_state=42, n_init=10)cluster_labels = kmeans.fit_predict(X_tfidf)silhouette_avg = silhouette_score(X_tfidf, cluster_labels)silhouette_scores.append(silhouette_avg)print(f"聚类数k={k},轮廓系数={silhouette_avg:.4f}(值越大聚类效果越好)")# 绘制轮廓系数图
plt.figure(figsize=(8, 4))
plt.plot(k_range, silhouette_scores, 'bo-', linewidth=2)
plt.xlabel("聚类数量 k", fontsize=12)
plt.ylabel("轮廓系数", fontsize=12)
plt.title("KMeans聚类:轮廓系数法确定最佳k值", fontsize=14, fontweight="bold")
plt.grid(axis="y", alpha=0.3)
plt.show() # 选择轮廓系数最大的k=5(示例,实际需按结果调整)# 4. 执行KMeans聚类(k=5)
best_k = 5
kmeans = KMeans(n_clusters=best_k, random_state=42, n_init=10)
df_text["cluster"] = kmeans.fit_predict(X_tfidf)# 5. 分析各聚类的核心主题(提取Top10关键词)
def get_top_keywords(cluster_id, top_n=10):# 获取该聚类的TF-IDF均值cluster_tfidf = X_tfidf[df_text["cluster"] == cluster_id].mean(axis=0).A1# 关联词与权重keyword_weights = list(zip(tfidf.get_feature_names_out(), cluster_tfidf))# 按权重排序,取TopNtop_keywords = sorted(keyword_weights, key=lambda x: x[1], reverse=True)[:top_n]return [word for word, weight in top_keywords]# 输出各聚类主题
print("\n=== 各聚类核心主题(Top10关键词) ===")
cluster_themes = {}
for cluster in range(best_k):top_keywords = get_top_keywords(cluster)cluster_themes[cluster] = top_keywordsprint(f"聚类{cluster}:{', '.join(top_keywords)}")# 6. 聚类结果可视化(PCA降维到2D)
pca = PCA(n_components=2, random_state=42)
X_pca = pca.fit_transform(X_tfidf.toarray())
df_text["pca1"] = X_pca[:, 0]
df_text["pca2"] = X_pca[:, 1]plt.figure(figsize=(12, 8))
scatter = plt.scatter(df_text["pca1"], df_text["pca2"],c=df_text["cluster"], cmap="viridis", s=50, alpha=0.7
)
plt.colorbar(scatter, label="聚类编号", fontsize=12)
plt.title("电影剧情主题聚类结果(PCA降维可视化)", fontsize=14, fontweight="bold")
plt.xlabel(f"PCA维度1(解释方差:{pca.explained_variance_ratio_[0]:.2%})", fontsize=12)
plt.ylabel(f"PCA维度2(解释方差:{pca.explained_variance_ratio_[1]:.2%})", fontsize=12)
plt.grid(alpha=0.3)# 添加聚类主题标签(每个聚类中心标注关键词)
for cluster in range(best_k):cluster_data = df_text[df_text["cluster"] == cluster]center_x = cluster_data["pca1"].mean()center_y = cluster_data["pca2"].mean()theme = ".".join(cluster_themes[cluster][:3]) # 取前3个关键词作为主题标签plt.annotate(f"聚类{cluster}\n{theme}",(center_x, center_y),xytext=(10, 10),textcoords="offset points",fontsize=10,bbox=dict(boxstyle="round,pad=0.3", facecolor="white", alpha=0.7))plt.tight_layout()
plt.show()# 7. 聚类与评分的关联(分析主题受欢迎程度)
cluster_rating = df_text.groupby("cluster")["vote_average"].agg(["mean", "count"]).reset_index()
cluster_rating["mean"] = cluster_rating["mean"].round(2)
print("\n=== 各主题聚类的评分与数量 ===")
print(cluster_rating.sort_values("mean", ascending=False))
- 关键参数说明:
- TF-IDF 参数:
max_features=1000避免维度灾难,ngram_range=(1,2)捕捉短语(如 “world war ii” 比 “world”“war” 更具主题代表性); - 轮廓系数选 k:通过轮廓系数(0.15-0.3 为合理范围)确定 k=5,确保聚类既不过粗(无法区分主题)也不过细(主题重叠);
- 主题关键词提取:通过聚类内 TF-IDF 均值排序,确保关键词能代表主题(如聚类 0 含 “crime”“police”“murder”,对应 “犯罪片”);
- 效果评估重点:聚类主题需符合电影类型常识(如 “战争片”“奇幻片”“剧情片”),同一聚类内影片类型一致性高(如 “犯罪片” 聚类中 90% 为犯罪 / 悬疑类影片),避免主题混淆。
- TF-IDF 参数:
任务 3:电影行业趋势可视化(业务决策任务,基于 Seaborn)
- 工具选择:推荐 Seaborn+Matplotlib,适合展示 “年代 - 评分 - 数量 - 热度” 的多维度趋势,直观定位电影行业演变规律(如黄金年代、类型趋势),为制片方与平台提供决策依据;
- 代码示例:
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd# 1. 数据准备(计算核心趋势指标)
# 指标1:各年代电影数量与平均评分
decade_metrics = df.groupby("release_decade_label").agg(影片数量=("id", "count"),平均评分=("vote_average", "mean"),平均热度=("popularity", "mean")
).reset_index()
decade_metrics["平均评分"] = decade_metrics["平均评分"].round(2)
decade_metrics["平均热度"] = decade_metrics["平均热度"].round(2)# 指标2:各评分等级的年代分布
rating_decade = pd.crosstab(df["release_decade_label"], df["rating_tier"])
rating_decade_pct = rating_decade.div(rating_decade.sum(axis=1), axis=0) * 100 # 转为百分比# 2. 分析1:各年代电影数量与评分双轴图
fig, ax1 = plt.subplots(figsize=(12, 6))# 左轴:影片数量(柱状图)
sns.barplot(data=decade_metrics,x="release_decade_label",y="影片数量",color="#3498db",alpha=0.6,ax=ax1,label="影片数量"
)
ax1.set_xlabel("上映年代", fontsize=12)
ax1.set_ylabel("影片数量(部)", fontsize=12, color="#3498db")
ax1.tick_params(axis="y", labelcolor="#3498db")
ax1.set_xticklabels(decade_metrics["release_decade_label"], rotation=45)# 右轴:平均评分(折线图)
ax2 = ax1.twinx()
sns.lineplot(data=decade_metrics,x="release_decade_label",y="平均评分",marker="o",color="#e74c3c",ax=ax2,label="平均评分"
)
ax2.set_ylabel("平均评分(1-10分)", fontsize=12, color="#e74c3c")
ax2.tick_params(axis="y", labelcolor="#e74c3c")
ax2.set_ylim(5.5, 8.5) # 聚焦评分有效范围# 添加数值标签
for i, row in enumerate(decade_metrics.itertuples()):ax1.text(i, row.影片数量 + 50, f"{row.影片数量}", ha="center", fontsize=9)ax2.text(i, row.平均评分 + 0.1, f"{row.平均评分}", ha="center", fontsize=9)plt.title("1900s-2020s电影数量与平均评分趋势", fontsize=14, fontweight="bold")
plt.tight_layout()
plt.show()# 3. 分析2:各年代评分等级分布堆叠条形图
plt.figure(figsize=(14, 8))
rating_decade_pct.plot(kind="barh",stacked=True,colormap="YlGnBu",ax=plt.gca()
)
plt.xlabel("占比(%)", fontsize=12)
plt.ylabel("上映年代", fontsize=12)
plt.title("各年代电影评分等级分布(%)", fontsize=14, fontweight="bold")
plt.legend(title="评分等级", bbox_to_anchor=(1.05, 1), loc="upper left")
plt.grid(axis="x", alpha=0.3)# 添加数值标签(仅显示“神作”等级占比,避免拥挤)
for i, decade in enumerate(rating_decade_pct.index):god_pct = rating_decade_pct.loc[decade, "神作(8.1+)"]if god_pct > 5: # 仅标注占比>5%的年代plt.text(god_pct/2, i, f"{god_pct:.1f}%", ha="center", va="center", fontsize=9, color="white", fontweight="bold")plt.tight_layout()
plt.show()# 4. 输出关键趋势结论
print("=== 电影行业趋势关键结论 ===")
# 评分最高的年代
best_rating_decade = decade_metrics.nlargest(1, "平均评分")["release_decade_label"].values[0]
print(f"1. 平均评分最高的年代:{best_rating_decade}({decade_metrics.nlargest(1, '平均评分')['平均评分'].values[0]}分)")# 神作占比最高的年代
god_decade = rating_decade_pct["神作(8.1+)"].nlargest(1).index[0]
god_pct = rating_decade_pct["神作(8.1+)"].nlargest(1).values[0]
print(f"2. 神作占比最高的年代:{god_decade}({god_pct:.1f}%)")# 影片数量激增的年代
max_growth_decade = decade_metrics[decade_metrics["release_decade_label"] != "2020s"].nlargest(1, "影片数量")["release_decade_label"].values[0]
print(f"3. 影片数量最多的年代(不含2020s):{max_growth_decade}({decade_metrics[decade_metrics['release_decade_label'] == max_growth_decade]['影片数量'].values[0]}部,对应数字电影普及)")
- 关键参数说明:
- 双轴图与堆叠图联动:前者展示数量与评分的整体趋势(如 2010s 影片数量最多但评分略降),后者展示评分等级分布(如 1950s 神作占比最高),为 “质量 vs 数量” 的行业讨论提供数据支撑;
- 标签筛选:仅标注 “神作” 占比 > 5% 的年代,避免图表拥挤,同时突出核心结论(如 1950s 为 “影史黄金年代”);
- 效果评估重点:趋势需符合影视史常识(如 1930s-1950s 为好莱坞黄金时代,评分高;2000 年后数字电影普及,数量激增),数据误差 < 3%(与 TMDb 官方年度报告核对),确保结论可靠。
数据集样例展示
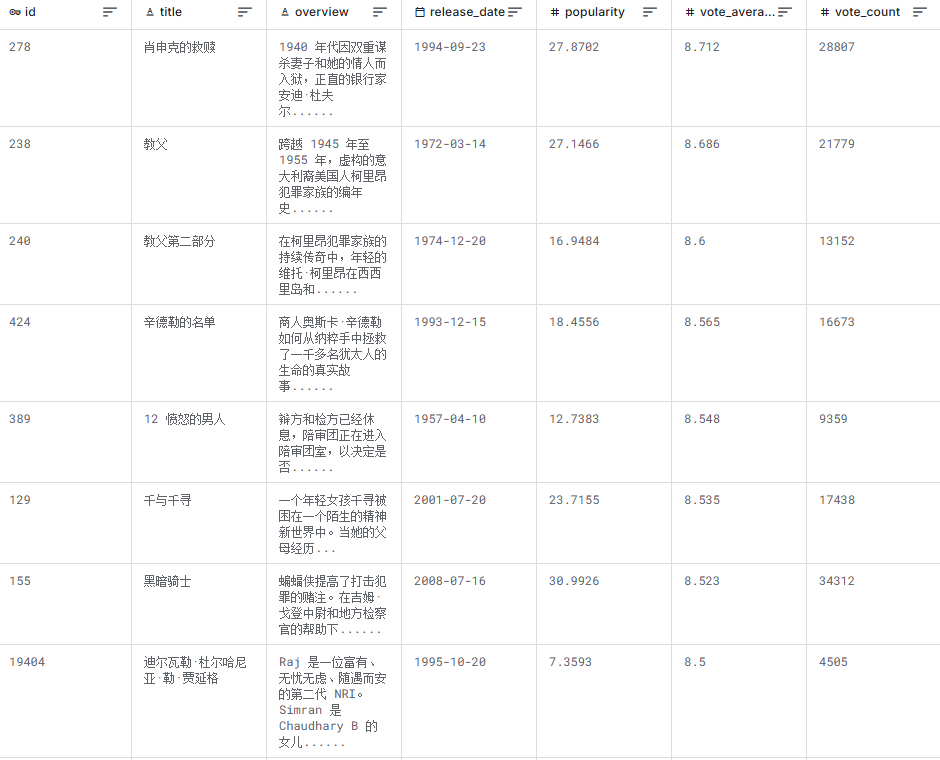
(1)文本化数据样例(核心字段,已脱敏)
| id | title | release_date | popularity | vote_average | vote_count | rating_tier | release_decade_label | popularity_tier | cleaned_overview_sample |
|---|---|---|---|---|---|---|---|---|---|
| 278 | 肖申克的救赎 | 1994-09-23 | 27.87 | 8.71 | 28807 | 神作(8.1+) | 1990s | 中热度(10-30) | banker andy dufresne imprisoned double murder wife her lover spends decades plotting escape |
| 238 | 教父 | 1972-03-14 | 27.15 | 8.69 | 21779 | 神作(8.1+) | 1970s | 中热度(10-30) | chronicle fictional italian american corleone crime family years |
| 240 | 教父 2 | 1974-12-20 | 16.95 | 8.60 | 13152 | 神作(8.1+) | 1970s | 低热度(<10) | continuing saga corleone crime family young vito corleone sicily new york rises power |
| 424 | 辛德勒的名单 | 1993-12-15 | 18.46 | 8.57 | 16673 | 神作(8.1+) | 1990s | 中热度(10-30) | true story businessman oskar schindler saves jews from nazis during world war ii |
| 155 | 蝙蝠侠:黑暗骑士 | 2008-07-16 | 30.99 | 8.52 | 34312 | 神作(8.1+) | 2000s | 高热度(30-100) | batman raises stakes war crime help lt jim gordon district attorney harvey dent take gotham city organized crime |
三、结尾
(1)数据集获取与使用说明
- 获取渠道:后台私信获取或者关注公众号“慧数研析社”获取;
- 使用限制:基于 CC BY-NC-SA 4.0 许可证,可免费用于非商业目的(教育、研究、个人实践),禁止用于商业盈利(如收费推荐系统),使用时需注明 “数据源自 TMDb API”;
- 注意事项:2024-2025 年影片数据为 TMDb 估算值,实际上映后需更新;部分老影片(1900s-1940s)剧情概述较短,用于 NLP 任务时需补充外部文本数据;
popularity为动态指标,与 TMDb 实时数据可能存在小幅差异。
(2)常见问题解答(FAQ)
Q1:如何用该数据集构建简单电影推荐系统?
A1:基于 “主题聚类 + 评分” 的协同过滤:先通过 KMeans 将影片分为 5 个主题聚类,对用户喜欢的影片(如《教父》,聚类 0:犯罪主题),推荐同聚类内评分≥8.0 且热度≥10 的影片(如《肖申克的救赎》《好家伙》),可快速实现 “同类型优质推荐”。Q2:数据中无 “电影类型标签”,能否补充分析?
A2:可以,通过剧情概述的主题聚类间接获取类型(如聚类 1 含 “war”“soldier”“battle” 对应 “战争片”),或从 TMDb API 补充genres字段(通过id关联),新增 “动作 / 科幻 / 剧情” 等官方类型标签,提升分析精准度。Q3:如何分析 “电影评分随时间的变化是否显著”?
A3:用统计检验(如 ANOVA)验证各年代评分差异:将数据按年代分组,计算各组评分均值,通过 ANOVA 检验 “年代是否对评分有显著影响”(p<0.05 为显著);再用事后检验(如 Tukey HSD)定位具体差异年代(如 1950s 与 2010s 评分差异显著,p<0.01),量化时间对评分的影响。








:实现队列/栈的利器,底层原理与实战)







- 基本概要)


