一、聚类算法
概念
属于无监督学习算法,即有特征无标签,根据样本之间的相似性,将样本划分到不同的类别中。
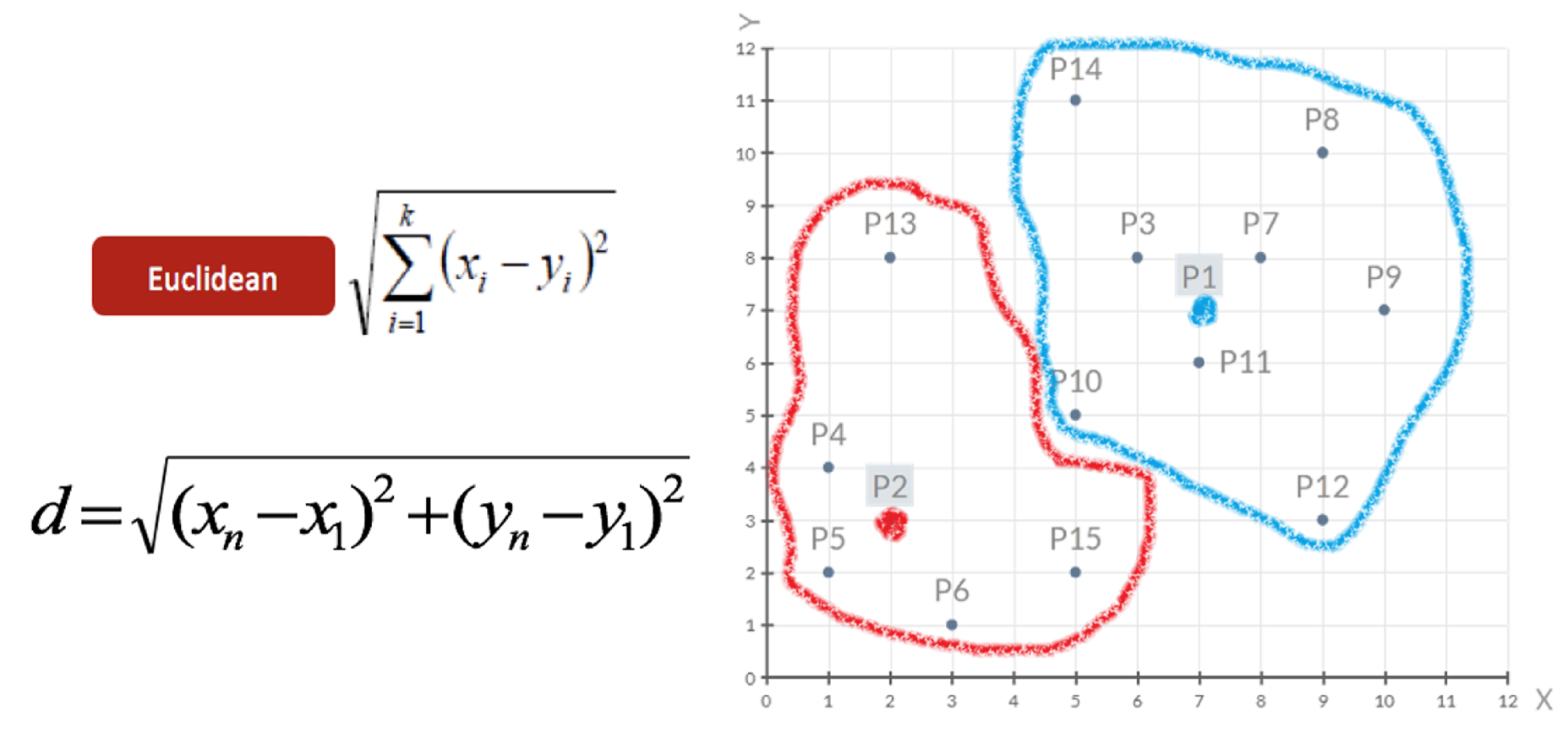
所谓相似性可以理解为欧氏距离、曼哈顿距离、切比雪夫距离... 。
分类
按颗粒度分为:粗聚类、细聚类。
按实现方法分为: K-means聚类、层次聚类、 DBSCAN聚类、谱聚类
二、K-Means聚类
K-Means 是机器学习中最经典、最常用的聚类算法之一
目标是在没有先验知识的情况下,自动发现数据集中的内在结构和模式
适用场景:一般大厂,项目初期在没有 先备知识的情况下的大厂
实现流程 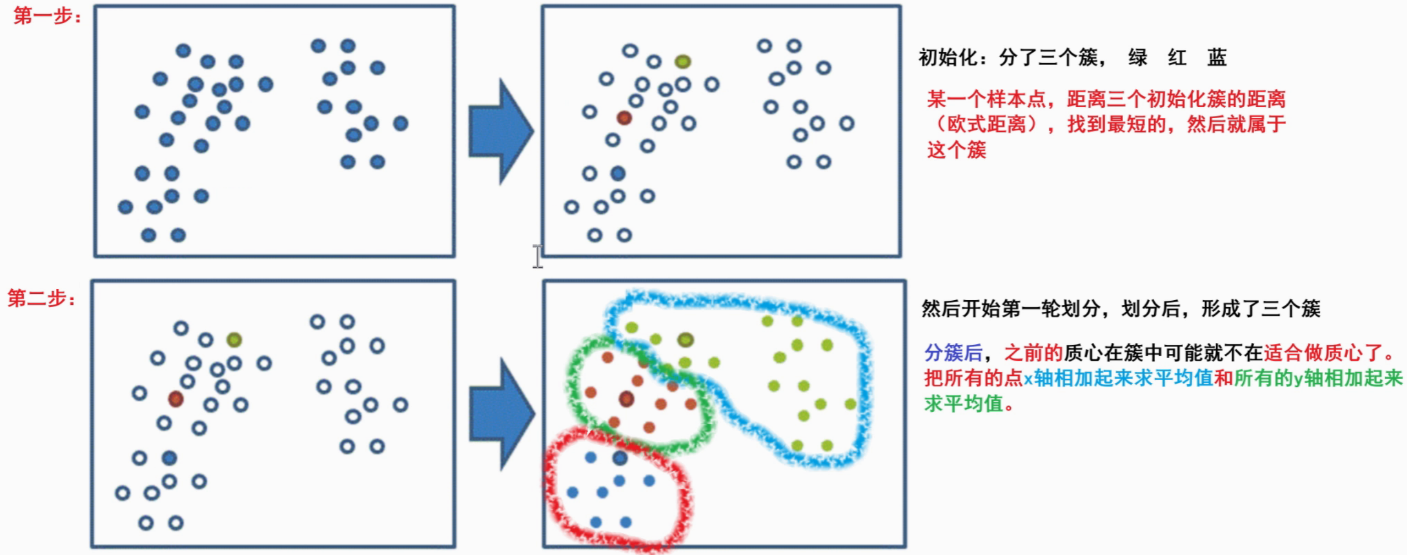

- 事先确定常数K ,常数K意味着最终的聚类类别数
- 随机选择 K 个样本点作为初始聚类中心
- 计算每个样本到 K 个中心的距离,选择最近的聚类中心点作为标记类别
- 根据每个类别中的样本点,重新计算出新的聚类中心点(平均值),如果计算得出的新中心点与原中心点一样则停止聚类,否则重新进行第 3 步过程,直到聚类中心不再变化
实现API
sklearn.cluster.KMeans
# 1.导入工具包
import os
os.environ['OMP_NUM_THREADS']='4'
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs #数据生成器
from sklearn.metrics import calinski_harabasz_score # 评估指标,值越大聚类效果越好
# 2 创建数据集 1000个样本,每个样本2个特征,4个质心蔟,数据标准差[0.4, 0.2, 0.2, 0.2],随机种子22
x, y = make_blobs(n_samples=1000,n_features=2,centers=[[-1,-1], [0,0], [1,1], [2,2]],cluster_std = [0.4, 0.2, 0.2, 0.2],random_state=22)
# x[:, 0]:横坐标(第一个特征)
# x[:, 1]:纵坐标(第二个特征)
print(x) #坐标
print(y) #标签
# 参1:横坐标,参2:纵坐标
plt.scatter(x[:, 0], x[:, 1])
plt.show()
# 3 使用k-means进行聚类, 并使用CH方法评估
es = KMeans(n_clusters=4, random_state=22)
y_pre=es.fit_predict(x)
plt.scatter(x[:, 0], x[:, 1], c=y_pre)
plt.show()
# 4 模型评估
print(calinski_harabasz_score(x, y_pre))三、聚类算法的评估指标
1. SSE + 肘部法
SSE
- 概述:所有的簇 的所有样本到该簇质心的 误差的平方和
- 特点:随着K值增加,SSE值逐渐减少
- 目标: SSE越小,簇内样本越聚集,内聚程度越高

肘部法—K值确定
- 对于n个点的数据集,迭代计算 k from 1 to n,每次聚类完成后计算 SSE
- SSE 是会逐渐变小的,因为每个点都是它所在的簇中心本身。
- SSE 变化过程中会出现一个拐点,下降率突然变缓时即认为是最佳 n_clusters 值。
- 在决定什么时候停止训练时,肘形判据同样有效,数据通常有更多的噪音,在增加分类无法带来更多回报时,我们停止增加类别。
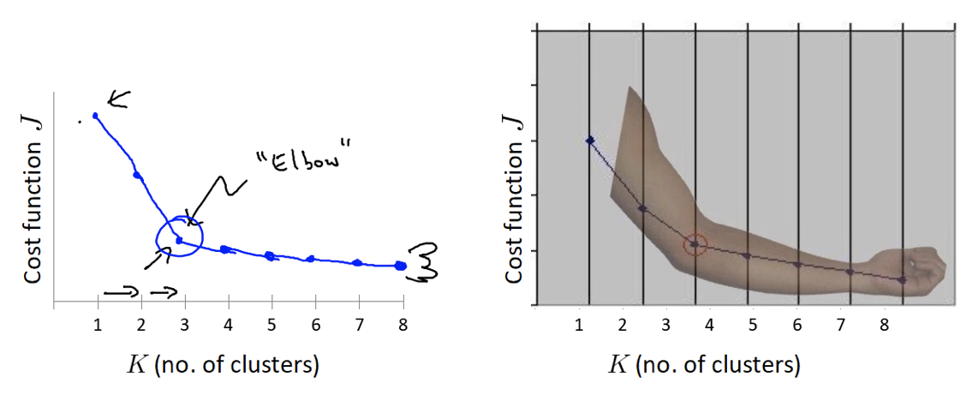
K值增大,SSE值会随之减小,下降梯度突然变换的时候,那个K的值,就是我们要寻找得最佳值
API实现
#导包
import os
os.environ['OMP_NUM_THREADS']='4'
#导包
from sklearn.cluster import KMeans #聚类API 采用指定 质心 分簇
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs # 默认会按照高斯分布(正态分布)生成数据集 ,只需要 指定 均值 ,标准差#1、定义函数 演示:SSE+肘部法
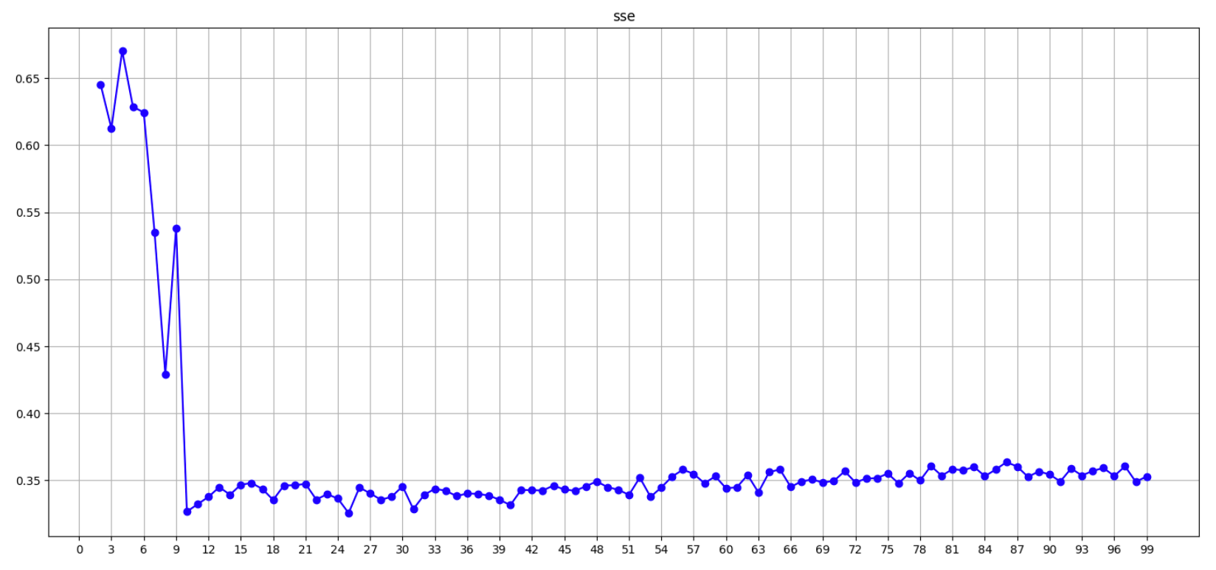
def dm01_sse():#0、定义SSE列表 ,目的:每个K值的SSE值sse_list = []#1、获取数据#参1:样本数量 参2:特征数量 参3:4个簇的质点 参4:std标准差 参5:固定随机种子x,y=make_blobs(n_samples=1000,n_features=2,centers=[[-1,-1],[0,0],[1,1],[2,2]],cluster_std=[0.4,0.2,0.2,0.2],random_state=23)#2、for训练 训练 获取每个K值,对应的SSE值for k in range(1,100):#2.1创建模型#参1:簇的数量#参2:最大迭代次数#参3:固定随机种子es=KMeans(n_clusters=k,max_iter=100,random_state=23)#2.2 训练模型es.fit(x)#2.3获取每个簇的sse值sse_value=es.inertia_#2.4将每个K值对应的SSE值,添加到sse_listsse_list.append(sse_value)#3.绘制SSE曲线 -》数据可视化# print(sse_list)#3.1创建画布plt.figure(figsize=(20,10))#3.2设置标题plt.title("sse value")#3.3设置x轴plt.xticks(range(0,100,3))#参1:K值 参2:该K值所对应的SSE值# o 圆点样式# r 红色# - 连接数据点的样式 实线# color='r' marker='o' linestyle='-'plt.plot(range(1,100),sse_list,'or-')plt.xlabel("k")plt.ylabel("sse")plt.grid()plt.show()if __name__ == '__main__':dm01_sse()聚类效果评估 – 代码效果展示SSE误差平方和,x轴为k值,y轴为SSE值
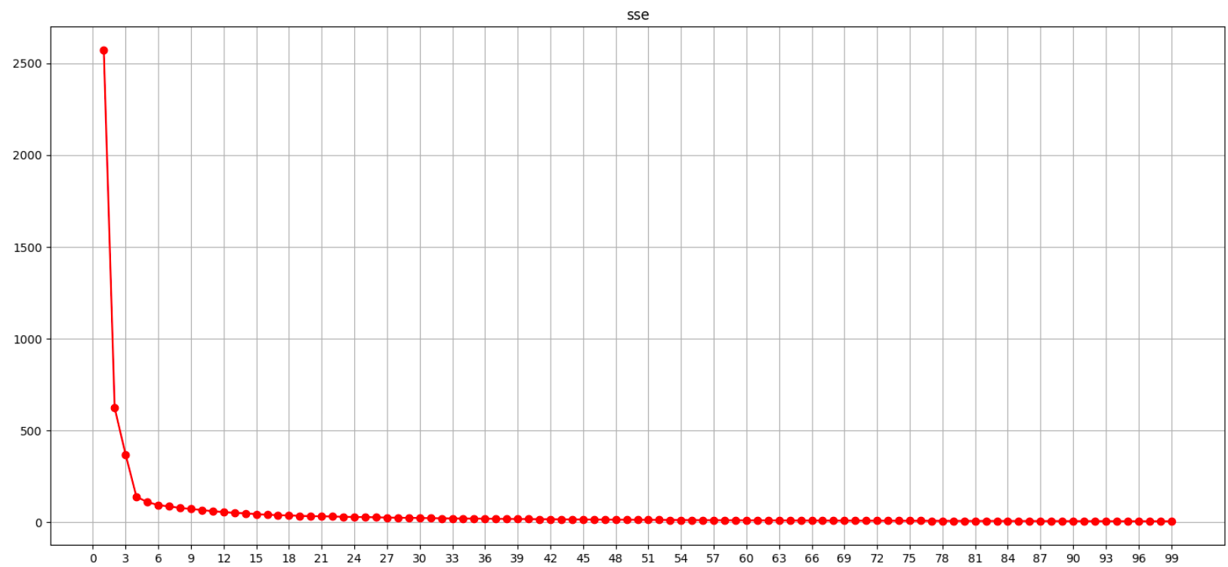
通过图像可观察到 n_clusters=4 sse开始下降趋缓, 最佳值4
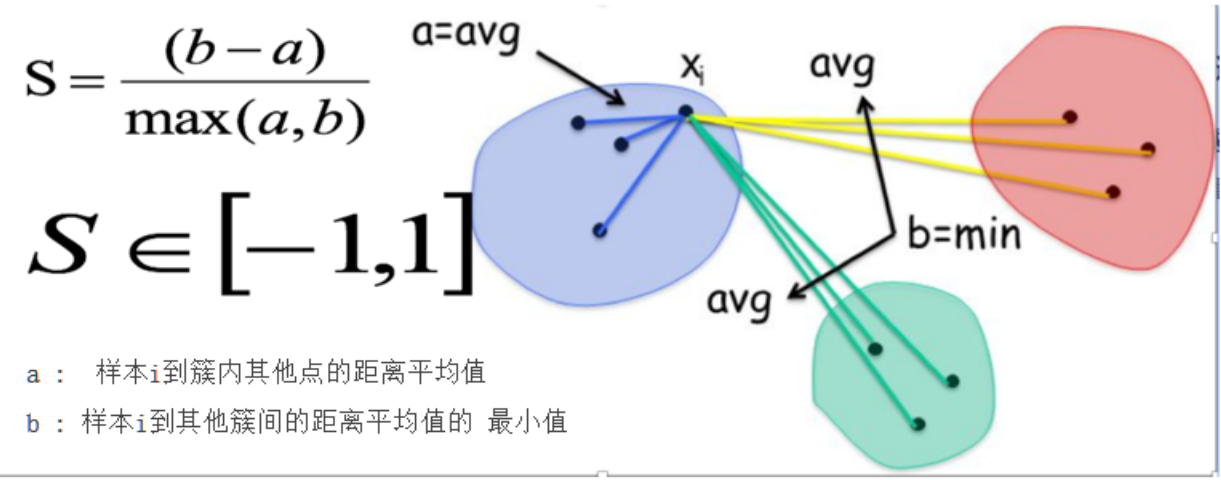
2. SC轮廓系数法—高内聚低耦合
轮廓系数法考虑簇内的内聚程度(Cohesion),簇外的分离程度(Separation)
- 对计算每一个样本 i 到同簇内其他样本的平均距离 ai,该值越小,说明簇内的相似程度越大
- 计算每一个样本 i 到最近簇 j 内的所有样本的平均距离 bij,该值越大,说明该样本越不属于其他簇 j
- 根据下面公式计算该样本的轮廓系数:S = b −a/max(a, b)
- 计算所有样本的平均轮廓系数
- 轮廓系数的范围为:[-1, 1],SC值越大聚类效果越好
API实现
#导包
import os
os.environ['OMP_NUM_THREADS']='4'
#导包
from sklearn.cluster import KMeans #聚类API 采用指定 质心 分簇
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs # 默认会按照高斯分布(正态分布)生成数据集 ,只需要 指定 均值 ,标准差
from sklearn.metrics import silhouette_score,calinski_harabasz_score #silhouette_score :sc calinski_harabasz_score:chdef dm02_sc轮廓系数法():#0、定义sc列表 ,目的:每个K值的SSE值sc_list = []#1、获取数据#参1:样本数量 参2:特征数量 参3:4个簇的质点 参4:std标准差 参5:固定随机种子x,y=make_blobs(n_samples=1000,n_features=2,centers=[[-1,-1],[0,0],[1,1],[2,2]],cluster_std=[0.4,0.2,0.2,0.2],random_state=23)#3、遍历for循环 获取每个K值 ,计算对应SC值 ,并添加到sc_list列表中for k in range(2,100): #考虑簇外 至少2簇es=KMeans(n_clusters=k,max_iter=100,random_state=23)es.fit(x)y_pre=es.predict(x)sc_value=silhouette_score(x,y_pre)sc_list.append(sc_value)#绘制sc曲线-》数据可视化plt.figure(figsize=(20,10))plt.title("sc value")plt.xticks(range(0,100,3))plt.xlabel("k")plt.ylabel("sc")plt.grid()# 注意 sc 值从2开始plt.plot(range(2,100),sc_list,'or-')plt.show()
if __name__ == '__main__':dm02_sc轮廓系数法()代码效果展示 – SC系数
通过图像可观察到 n_clusters=4 取到最大值; 最佳值4
3.CH轮廓系数法—高内聚低耦合加质心
CH 系数考虑簇内的内聚程度、簇外的离散程度、质心的个数。
CH系数越大越好
- 类别内部数据的距离平方和越小越好,
- 类别之间的距离平方和越大越好,
- 聚类的种类数越少越好
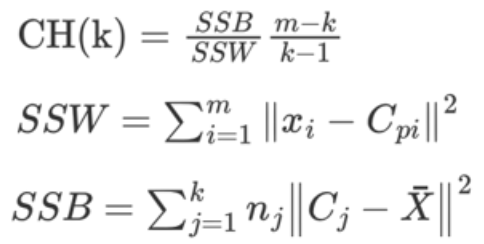

SSW 的含义:相当于SSE,簇内距离
SSB 的含义:簇间距离


API实现
#导包
import os
os.environ['OMP_NUM_THREADS']='4'
#导包
from sklearn.cluster import KMeans #聚类API 采用指定 质心 分簇
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs # 默认会按照高斯分布(正态分布)生成数据集 ,只需要 指定 均值 ,标准差
from sklearn.metrics import silhouette_score,calinski_harabasz_score #silhouette_score :sc calinski_harabasz_score:chdef dm03_CH系数():#0、定义sc列表 ,目的:每个K值的SSE值ch_list = []#1、获取数据#参1:样本数量 参2:特征数量 参3:4个簇的质点 参4:std标准差 参5:固定随机种子x,y=make_blobs(n_samples=1000,n_features=2,centers=[[-1,-1],[0,0],[1,1],[2,2]],cluster_std=[0.4,0.2,0.2,0.2],random_state=23)#3、遍历for循环 获取每个K值 ,计算对应SC值 ,并添加到sc_list列表中for k in range(2,100): #考虑簇外 至少2簇es=KMeans(n_clusters=k,max_iter=100,random_state=23)es.fit(x)y_pre=es.predict(x)sc_value=calinski_harabasz_score(x,y_pre)ch_list.append(sc_value)#绘制sc曲线-》数据可视化plt.figure(figsize=(20,10))plt.title("ch value")plt.xticks(range(0,100,3))plt.xlabel("k")plt.ylabel("ch")plt.grid()# 注意 sc 值从2开始plt.plot(range(2,100),ch_list,'or-')plt.show()
if __name__ == '__main__':dm03_CH系数()代码效果展示 – CH系数
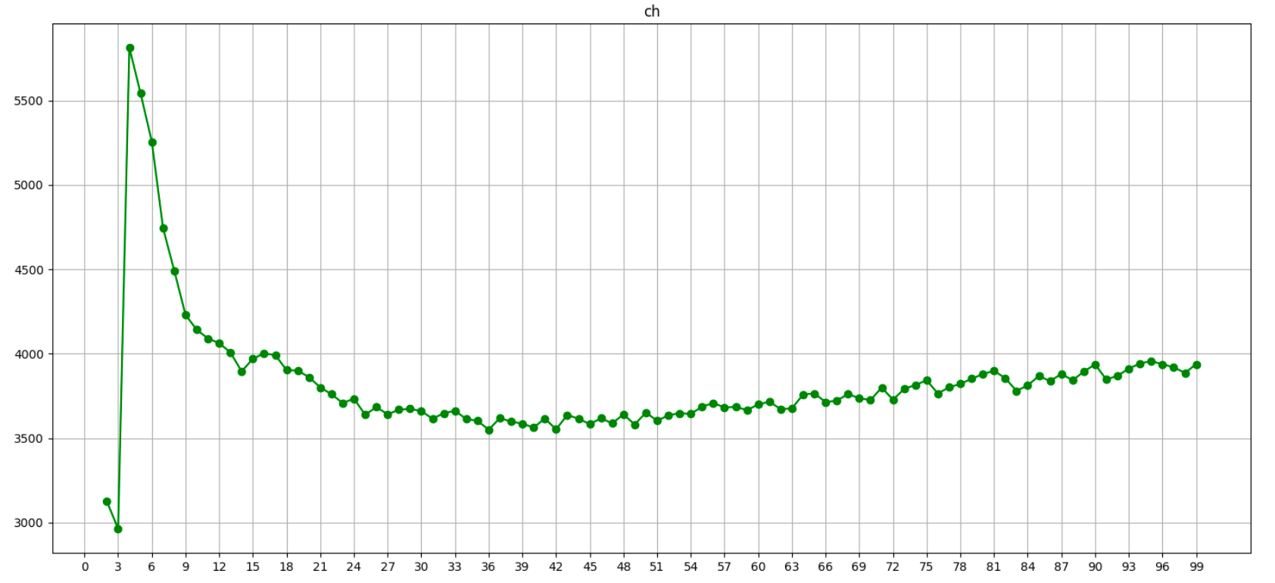
通过图像可观察到 n_clusters=4 取到最大值; 最佳值4


区别分析)

![[Upscayl图像增强] docs | 前端 | Electron工具(web->app)](http://pic.xiahunao.cn/[Upscayl图像增强] docs | 前端 | Electron工具(web->app))






核心语法课件(Node.js/React 环境))







)