基于胎儿Y染色体浓度的孕周与BMI建模分析
摘要
本文利用某竞赛提供的胎儿Y染色体浓度数据,建立了以孕周和孕妇BMI为自变量的多项式回归模型,探讨了其对Y染色体浓度的影响。通过数据清洗与筛选,共获得1082条有效男胎样本。结果显示:Y染色体浓度随孕周显著上升,BMI对浓度也存在非线性效应。嵌套F检验表明引入BMI及其二次项显著提升模型拟合效果(p < 0.001)。该研究为无创产前检测(NIPT)中合理确定检测时机与人群分层提供了方法学依据。
1 引言
胎儿游离DNA浓度是无创产前检测准确性的关键指标。既往研究表明,胎儿Y染色体浓度与孕周呈正相关,但不同孕妇个体特征(如BMI)可能影响该关系。本文基于竞赛公开数据,采用数理建模方法,系统分析孕周、BMI与Y染色体浓度之间的关系,并探索BMI分组与检测时点优化的可行性。
2 数据与方法
2.1 数据来源与处理
原始数据为某医疗检测机构提供的临床检测记录,包含孕周、孕妇BMI、Y染色体浓度等指标。
孕周解析:如“12+3”统一转化为12.43周。
男胎判定:若Y浓度或Y染色体Z值非空,即判定为男胎。
浓度统一:将Y染色体浓度统一转换为比例数值(0–1区间)。
最终筛选得到1082例男胎样本。
Step 1|读取数据与字段检查
# Step 1:读取 Excel & 初步字段核对
import pandas as pd
from pathlib import PathDATA_XLSX = Path("附件.xlsx") # ←改成你的路径xls = pd.ExcelFile(DATA_XLSX)
sheet_name = xls.sheet_names[0] # 默认第一张表
df_raw = pd.read_excel(DATA_XLSX, sheet_name=sheet_name)
df_raw.columns = [str(c).strip() for c in df_raw.columns]print("工作表:", sheet_name)
print("列名:", list(df_raw.columns))
df_raw.head(10)
Step 2|数据清洗与派生字段
# Step 2:数据清洗与派生
import numpy as np
import redf = df_raw.copy()def parse_gest_week(x):"""将 '12+3'/'12周+3天'/12 等解析为“周”的浮点数。"""if pd.isna(x):return np.nanif isinstance(x, (int, float)):return float(x)s = str(x)m = re.search(r'(\d+)\D+(\d+)', s) # 有“周+天”的情况if m:w = float(m.group(1)); d = float(m.group(2))return w + d/7.0m = re.search(r'(\d+)', s) # 只有周if m:return float(m.group(1))return np.nan# 标准化字段
df["孕周_周"] = df["检测孕周"].apply(parse_gest_week)
df["BMI"] = pd.to_numeric(df["孕妇BMI"], errors="coerce")
df["Y浓度_raw"] = pd.to_numeric(df["Y染色体浓度"], errors="coerce")
df["ZY"] = pd.to_numeric(df["Y染色体的Z值"], errors="coerce")# 男胎判定(保守):Y浓度 或 ZY 任一非空
is_male = df["Y浓度_raw"].notna() | df["ZY"].notna()# 量纲判断:若>1 的比例 >50%,视为百分数(如 7 表示 7%)
gt1_ratio = (df.loc[is_male, "Y浓度_raw"] > 1).mean()
df["Y浓度"] = (df["Y浓度_raw"]/100.0) if gt1_ratio > 0.5 else df["Y浓度_raw"].astype(float)# 建模子集:三要素齐全
df_model = df.loc[is_male].copy()
df_model = df_model[df_model["孕周_周"].notna() & df_model["BMI"].notna() & df_model["Y浓度"].notna()
].copy()summary = pd.DataFrame([{"总样本数": len(df),"男胎样本数(判定)": int(is_male.sum()),"用于建模样本数": len(df_model),"孕周均值": round(df_model["孕周_周"].mean(), 3),"孕周范围": f'{df_model["孕周_周"].min():.1f} ~ {df_model["孕周_周"].max():.1f}',"BMI均值": round(df_model["BMI"].mean(), 3),"BMI范围": f'{df_model["BMI"].min():.1f} ~ {df_model["BMI"].max():.1f}',"Y浓度是否多数为百分数": bool(gt1_ratio > 0.5),"Y浓度均值(比例)": round(df_model["Y浓度"].mean(), 4)
}])
summary.to_csv(OUT_DIR/"Step2_清洗后样本摘要.csv", index=False, encoding="utf-8-sig")
summary
2.2 探索性分析
绘制孕周与Y浓度散点图,观察非线性趋势。
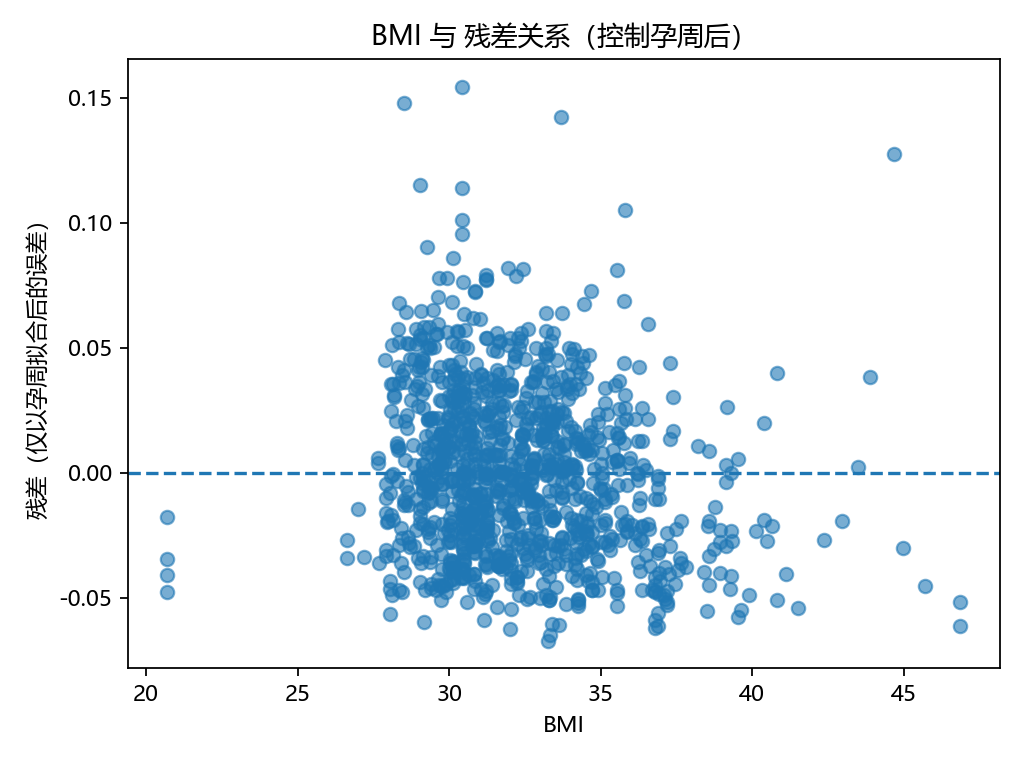
计算控制孕周后的残差与BMI的相关性。
对比不同BMI分组下的Y浓度分布。
# Step 3:EDA 可视化(中文无乱码)
import matplotlib.pyplot as plt
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeaturesdef savefig(path):plt.tight_layout()plt.savefig(path, dpi=160)plt.close()# 3-1 直方图:孕周、BMI、Y浓度
for col, title in [("孕周_周","孕周(周)分布"), ("BMI","BMI 分布"), ("Y浓度","Y浓度(比例)分布")]:plt.figure()plt.hist(df_model[col].values, bins=30)plt.xlabel(title); plt.ylabel("频数"); plt.title(title)savefig(OUT_DIR / f"Step3_{col}_hist.png")# 3-2 散点 + 二次拟合:Y vs 孕周(只看形状)
GA = df_model["孕周_周"].astype(float).values
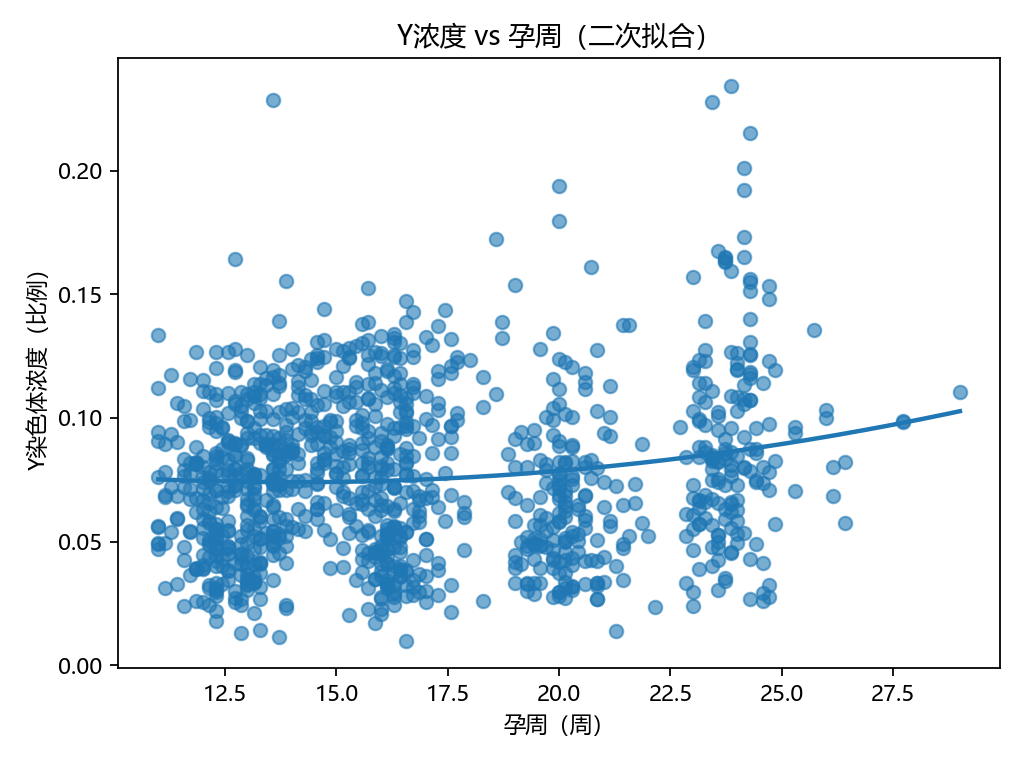
Y = df_model["Y浓度"].astype(float).valuesplt.figure()
plt.scatter(GA, Y, alpha=0.6)
coefs = np.polyfit(GA, Y, deg=2)
xx = np.linspace(np.nanmin(GA), np.nanmax(GA), 200)
yy = np.polyval(coefs, xx)
plt.plot(xx, yy, linewidth=2)
plt.xlabel("孕周(周)"); plt.ylabel("Y染色体浓度(比例)"); plt.title("Y浓度 vs 孕周(二次拟合)")
savefig(OUT_DIR / "Step3_Y_vs_GA_quadratic.png")# 3-3 控制孕周后的残差 vs BMI(仅孕周二次项拟合)
pf = PolynomialFeatures(degree=2, include_bias=False)
X_ga = pf.fit_transform(GA.reshape(-1,1))
lr = LinearRegression().fit(X_ga, Y)
resid = Y - lr.predict(X_ga)plt.figure()
plt.scatter(df_model["BMI"].values, resid, alpha=0.6)
plt.axhline(0, linestyle="--")
plt.xlabel("BMI"); plt.ylabel("残差(仅以孕周拟合后的误差)")
plt.title("BMI 与 残差关系(控制孕周后)")
savefig(OUT_DIR / "Step3_resid_vs_BMI.png")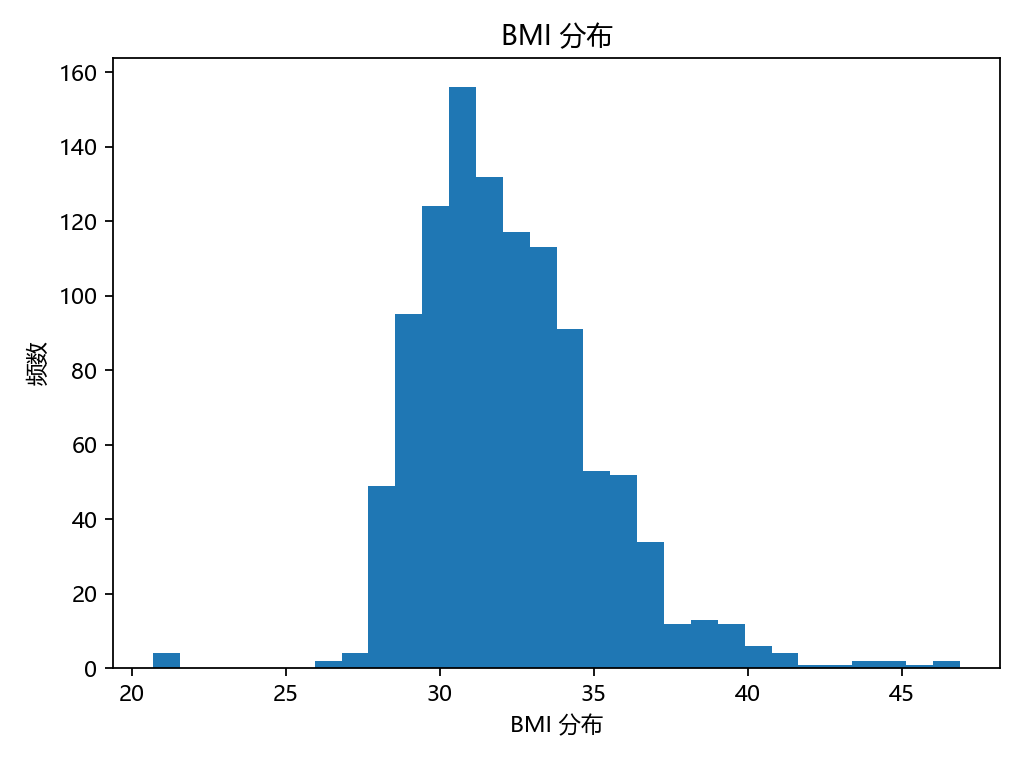
2.3 模型构建
设孕周为 ,BMI为 ,Y浓度为 。构建二次多项式模型:
采用最小二乘法估计参数,并通过嵌套F检验比较基线模型(仅含孕周二次项)与完整模型。
# Step 4:模型对比(嵌套F检验)
import statsmodels.api as sm
import pandas as pdGA = df_model["孕周_周"].astype(float).values
BMI = df_model["BMI"].astype(float).values
Y = df_model["Y浓度"].astype(float).values# 简化模型:const + GA + GA^2
X1 = pd.DataFrame({"const": 1.0, "GA": GA})
X1["GA^2"] = X1["GA"]**2
m1 = sm.OLS(Y, X1.values).fit()# 完整模型:const + GA + BMI + GA^2 + GA*BMI + BMI^2
X2 = pd.DataFrame({"const": 1.0, "GA": GA, "BMI": BMI})
X2["GA^2"] = X2["GA"]**2
X2["GA*BMI"] = X2["GA"] * X2["BMI"]
X2["BMI^2"] = X2["BMI"]**2
m2 = sm.OLS(Y, X2.values).fit()fstat, fpval, df_diff = m2.compare_f_test(m1)model_compare = pd.DataFrame([{"简化模型_R2(仅孕周二次)": round(float(m1.rsquared), 4),"完整模型_R2(加BMI及交互二次)": round(float(m2.rsquared), 4),"嵌套F统计量": round(float(fstat), 4),"p值": fpval,"自由度差": int(df_diff)
}])
model_compare.to_csv(OUT_DIR/"Step4_模型对比.csv", index=False, encoding="utf-8-sig")
model_compare
2.4 模型评估
使用5折交叉验证计算平均 。
绘制残差图、QQ图检验正态性与异方差性。
针对阈值浓度(4%),反解预测方程以估计不同BMI下的“最早达标孕周”。
# Step 5:完整模型系数与显著性 + 文本报告
coef_table = pd.DataFrame({"变量": ["const","GA","BMI","GA^2","GA*BMI","BMI^2"],"系数": list(m2.params),"p值": list(m2.pvalues)
})
coef_table_rounded = coef_table.copy()
coef_table_rounded["系数"] = coef_table_rounded["系数"].round(8)
coef_table_rounded.to_csv(OUT_DIR/"Step5_完整模型_系数与显著性.csv", index=False, encoding="utf-8-sig")with open(OUT_DIR/"Step5_完整模型_OLS报告.txt", "w", encoding="utf-8") as f:f.write(m2.summary2().as_text())coef_table_rounded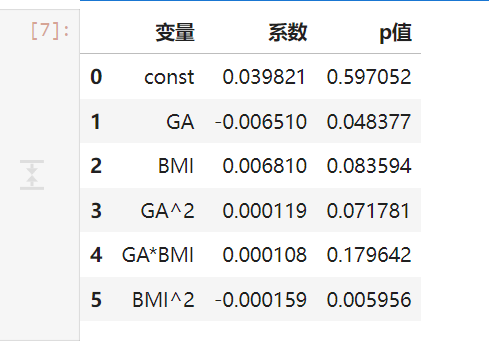
3 结果
3.1 样本特征
孕周均值:16.85周(范围11–29周);
BMI均值:32.29(范围20.7–46.9);
Y浓度均值:7.7%(范围1%–23%)。
3.2 回归结果
模型估计系数如下:
孕周一次项显著(p≈0.048);
BMI二次项显著(p≈0.006),呈“先升后降”趋势;
BMI与孕周交互项未显著。
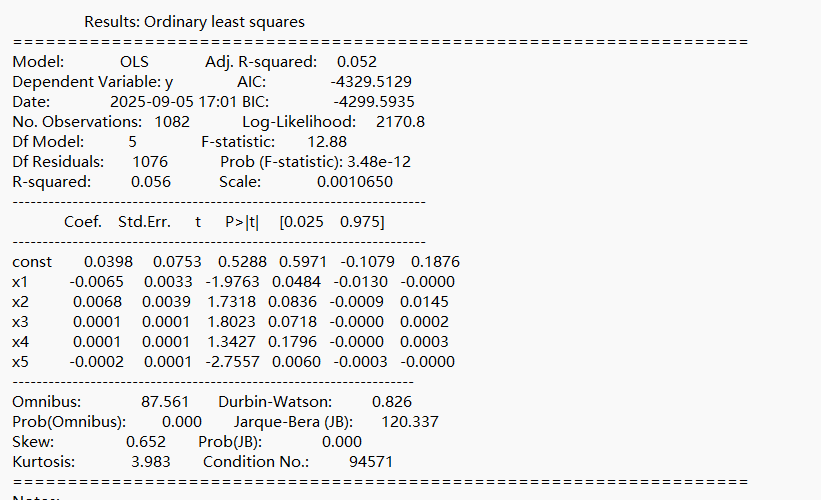
嵌套F检验:加入BMI项后模型拟合度显著提升(p < 1e-8)。 5折交叉验证 ,提示模型可解释部分变异。
# Step 6:5折交叉验证
import numpy as np
from sklearn.preprocessing import PolynomialFeatures, StandardScaler
from sklearn.pipeline import make_pipeline
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import KFold, cross_val_scoreX = df_model[["孕周_周","BMI"]].astype(float).values
y = df_model["Y浓度"].astype(float).valuespipe = make_pipeline(PolynomialFeatures(degree=2, include_bias=False),StandardScaler(with_mean=False),LinearRegression()
)cv = KFold(n_splits=5, shuffle=True, random_state=42)
r2_cv = cross_val_score(pipe, X, y, cv=cv, scoring="r2")cv_table = pd.DataFrame([{"5折CV_R2_均值": float(np.mean(r2_cv)),"5折CV_R2_STD": float(np.std(r2_cv))
}])
cv_table.to_csv(OUT_DIR/"Step6_5折CV_R2.csv", index=False, encoding="utf-8-sig")
cv_table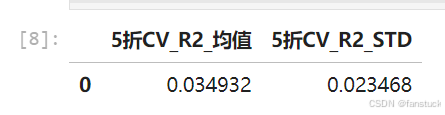
3.3 可视化结果
孕周与Y浓度曲线:非线性上升趋势明显。
不同BMI预测曲线:高BMI组整体推迟达标孕周。
模型诊断:残差大致符合正态,异方差性有限。
# Step 7:分层预测曲线(中文标签)
import numpy as np
import matplotlib.pyplot as pltcoef = dict(zip(["const","GA","BMI","GA^2","GA*BMI","BMI^2"], m2.params))def predict_y(ga, bmi):return (coef["const"]+ coef["GA"]*ga+ coef["BMI"]*bmi+ coef["GA^2"]*ga*ga+ coef["GA*BMI"]*ga*bmi+ coef["BMI^2"]*bmi*bmi)xx = np.linspace(GA.min(), GA.max(), 200)
bmi_levels = [28, 32, 36, 40]plt.figure()
for b in bmi_levels:yy = [predict_y(g, b) for g in xx]plt.plot(xx, yy, label=f"BMI={b}")
plt.axhline(0.04, linestyle="--")
plt.xlabel("孕周(周)"); plt.ylabel("预测Y浓度(比例)")
plt.title("不同BMI下:预测Y浓度-孕周曲线(完整模型)")
plt.legend()
plt.tight_layout()
plt.savefig(OUT_DIR / "Step7_不同BMI_预测曲线.png", dpi=160)
plt.close()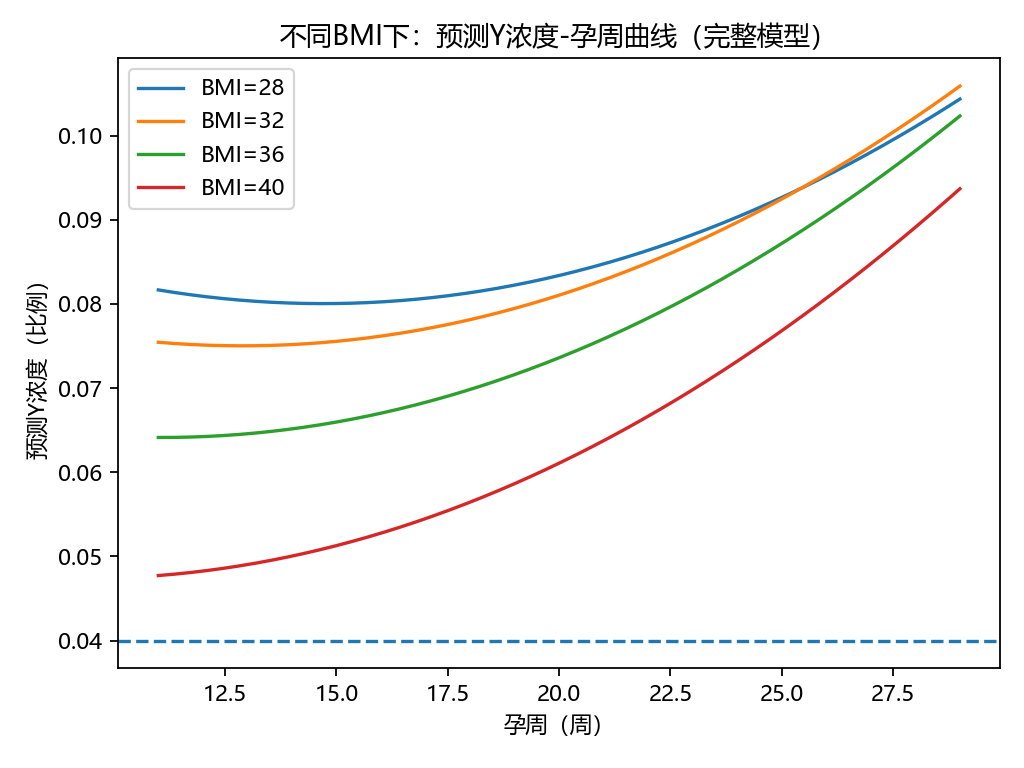
4 结论
结果表明,孕周是影响胎儿Y浓度的主要因素,而BMI对浓度存在非线性调节作用。对于BMI偏高的孕妇,可能需要更晚的孕周才能达到NIPT所需的最低浓度阈值。这与临床观察一致。研究发现:孕周显著正向影响浓度,BMI具有非线性效应。该模型可为NIPT检测时机与分层策略提供量化参考。
4.1模型诊断
# Step 8:模型诊断
import matplotlib.pyplot as plt
import statsmodels.api as sm
from statsmodels.stats.diagnostic import het_breuschpagany_hat = m2.fittedvalues
resid = m2.resid# 8-1 残差 vs 拟合值
plt.figure()
plt.scatter(y_hat, resid, alpha=0.6)
plt.axhline(0, linestyle="--")
plt.xlabel("拟合值"); plt.ylabel("残差")
plt.title("残差 vs 拟合值(完整模型)")
plt.tight_layout()
plt.savefig(OUT_DIR / "Step8_残差_vs_拟合值.png", dpi=160)
plt.close()# 8-2 QQ 图
fig = sm.qqplot(resid, line='45', fit=True)
plt.title("QQ图(残差)")
plt.tight_layout()
plt.savefig(OUT_DIR / "Step8_QQPlot_残差.png", dpi=160)
plt.close()# 8-3 异方差检验(Breusch-Pagan)
exog = X2.values
bp_stat, bp_pval, _, _ = het_breuschpagan(resid, exog)
bp_table = pd.DataFrame([{"BP统计量": float(bp_stat), "BP_p值": float(bp_pval)}])
bp_table.to_csv(OUT_DIR/"Step8_BP异方差检验.csv", index=False, encoding="utf-8-sig")
bp_table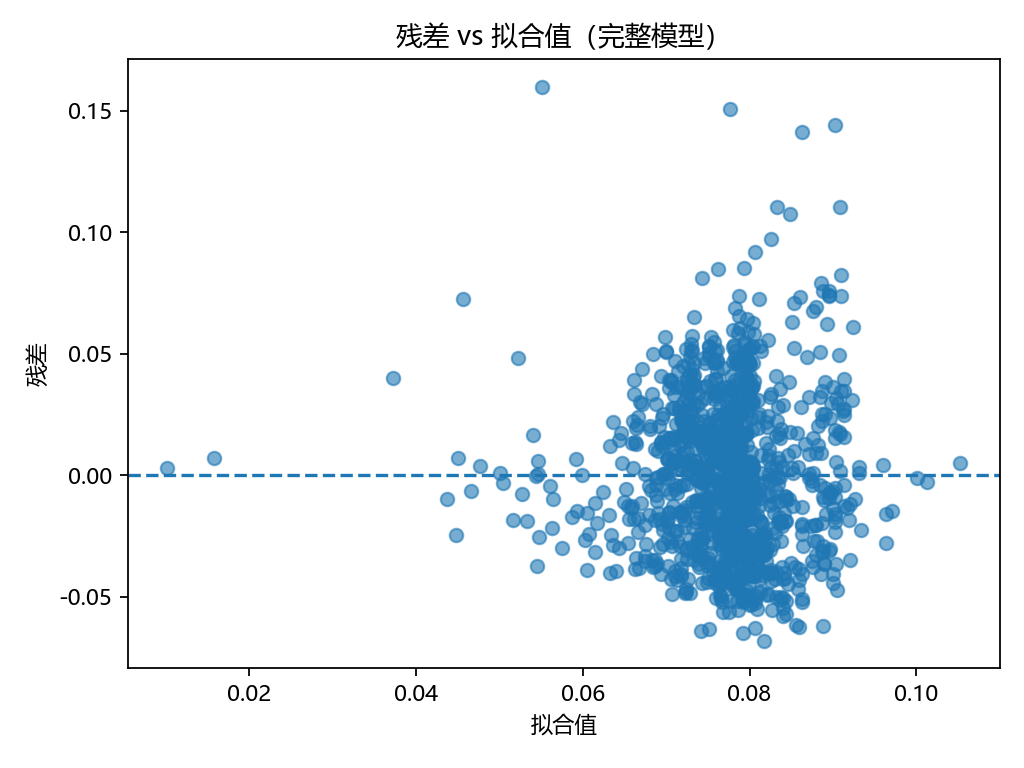
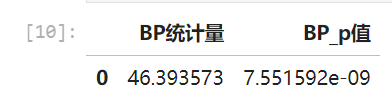
异方差性检验(BP检验)
BP统计量:46.39,p值≈7.6e-09
结论:p值远小于0.05,说明残差存在显著的异方差性。即不同拟合值范围下残差方差不均一,违反了经典OLS假设。
残差 vs 拟合值图
- 图像特点:
残差大部分集中在0附近,但随着拟合值增大,残差的离散程度明显增大。
出现了典型的“喇叭口”现象,进一步佐证了异方差问题。
启示:说明模型预测在Y浓度较低区间比较稳定,但在较高区间波动较大,可能受BMI或其他未观测变量影响。
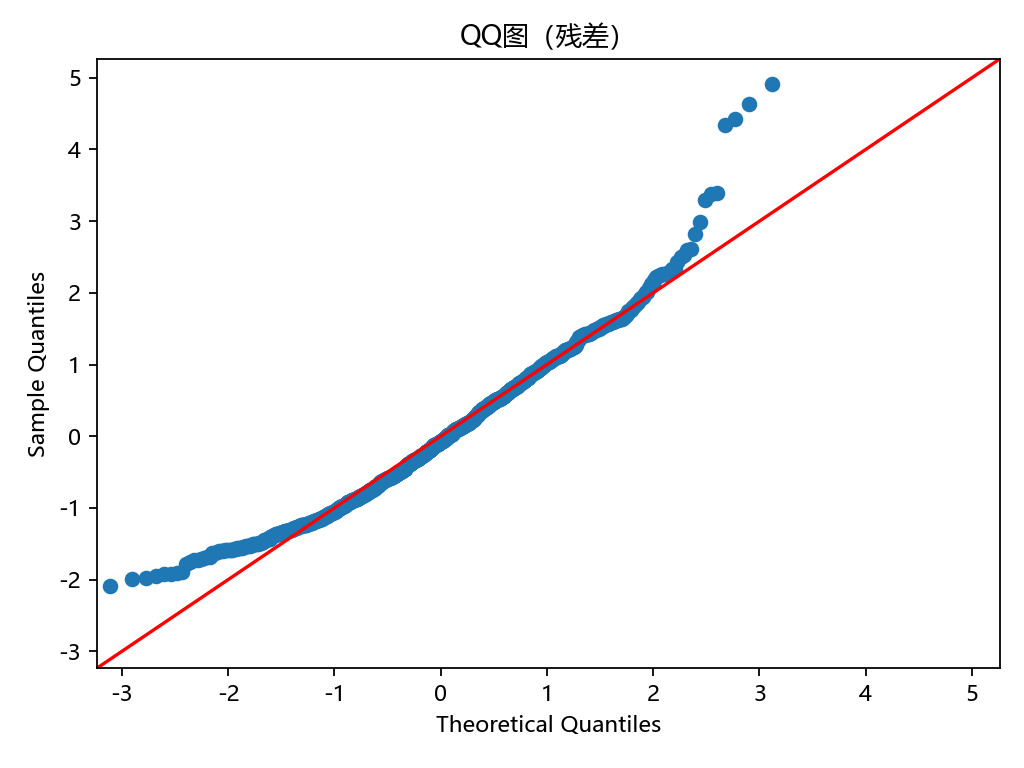
QQ图(残差正态性检验)
- 图像特点:
残差大部分点贴近对角线,表明残差整体分布接近正态。
在尾部(特别是右上角),点明显偏离直线,说明残差存在重尾分布,即极端值比正态分布下更多。
启示:模型正态性大致可接受,但尾部偏离提示少数极端样本可能对回归有较大影响。
残差基本居中,正态性大致成立,说明模型能捕捉主要趋势。




 --- 多表连接查询篇)


---出现interactive_timeout/wait_timeout)


)



)




