目录
一、图数据库介绍
二、安装Neo4j
2.1 安装java环境
2.2 安装 Neo4j(社区版)
2.3 修改配置
2.4 验证测试
2.5 卸载
2.6 基本用法
2.7 windows连接服务器可视化
三、neo4j和mysql对比
3.1 场景对比
3.2 Mysql和neo4j的映射对比
3.3 mysql数据转换到neo4j存储
四、实操mysql到neo4j转化
4.1 场景描述
4.2 neo4j数据建模设计
4.3 python代码实现数据导入
4.4 常见错误及解决方法
4.5 代码不使用apoc插件
五、参考资料
一、图数据库介绍
图形数据库(例如 Neo4j)是用于表示和处理以图形形式存储的数据的数据库。图形数据由节点 、 边( 或关系) 和属性组成。节点表示实体,关系连接实体,属性提供有关节点和关系的附加元数据。
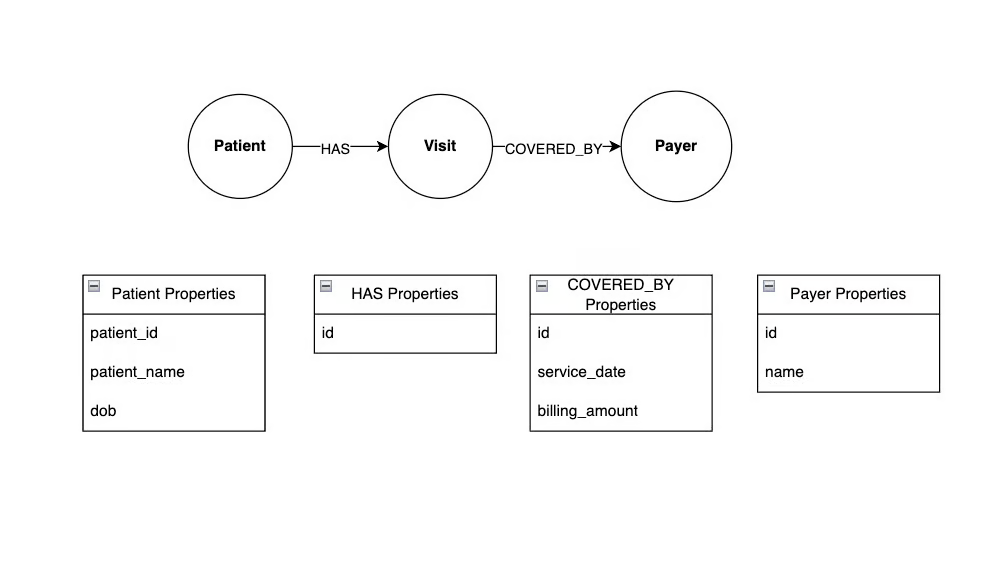
该图包含三个节点 - Patient 、 Visit 和 Payer 。 Patient 和 Visit 通过 HAS 关系连接,表示某位住院患者进行了一次就诊。同样, Visit 和 Payer 通过 COVERED_BY 关系连接,表示某位保险支付方承担了某次住院费用。
注意,这些关系是用箭头表示方向的。例如, HAS 关系的方向表示患者可以就诊,但就诊不能有患者。
节点和关系都可以具有属性。在本例中, Patient 节点具有 ID、姓名和出生日期属性,而 COVERED_BY 关系具有服务日期和账单金额属性。像这样将数据存储在图中有几个优点:
简单性 :在图形数据库中对实体之间的真实关系进行建模是很自然的,从而减少了需要多个连接操作来回答查询的复杂模式的需要。
关系 :图形数据库擅长处理复杂的关系。遍历关系非常高效,可以轻松查询和分析关联数据。
灵活性 :图形数据库无模式,可以轻松适应不断变化的数据结构。这种灵活性有利于不断发展的数据模型。
性能 :在图形数据库中检索连接数据的速度比在关系数据库中更快,特别是对于涉及具有多种关系的复杂查询的场景。
模式匹配 :图形数据库支持强大的模式匹配查询,使得表达和查找数据中的特定结构变得更加容易。
当您的数据具有许多复杂的关系时,与关系数据库相比,图数据库的简单性和灵活性使其更易于设计和查询。正如您稍后将看到的,在图数据库查询中指定关系非常简洁,并且不需要复杂的连接操作。如果您感兴趣,Neo4j 在其文档中通过一个实际的示例数据库很好地说明了这一点。
由于这种简洁的数据表示,LLM 生成图数据库查询时出错的可能性更小。这是因为您只需告知 LLM 图数据库中的节点、关系和属性。相比之下,关系数据库的 LLM 必须遍历并保留整个数据库中的表模式和外键关系,这导致 SQL 生成过程中更容易出错。
二、安装Neo4j
需求,在ubuntu服务器安装neo4j,windows上安装可视化
2.1 安装java环境
Neo4j 依赖 Java 运行环境,需先安装 OpenJDK:
sudo apt update
sudo apt install openjdk-11-jdk
java -version # 验证安装

2.2 安装 Neo4j(社区版)
# 下载并添加 Neo4j 官方 GPG 密钥
wget -O - https://debian.neo4j.com/neotechnology.gpg.key | sudo apt-key add -# 添加 Neo4j 5.x 的仓库源
echo 'deb https://debian.neo4j.com stable 5' | sudo tee /etc/apt/sources.list.d/neo4j.list# 安装 Neo4j
sudo apt updatesudo apt install neo4j
# 或者安装特定版本
sudo apt install neo4j=1:5.26.11
# 启动服务
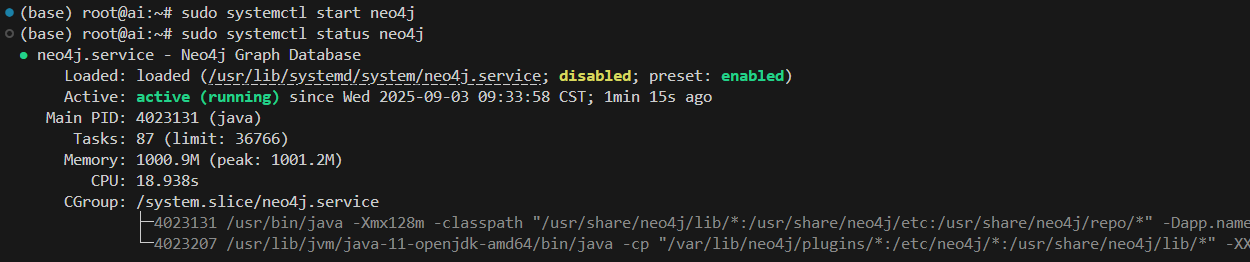
sudo systemctl start neo4j# 查看运行状态
sudo systemctl status neo4j
sudo systemctl enable neo4j # 设置开机自启
2.3 修改配置
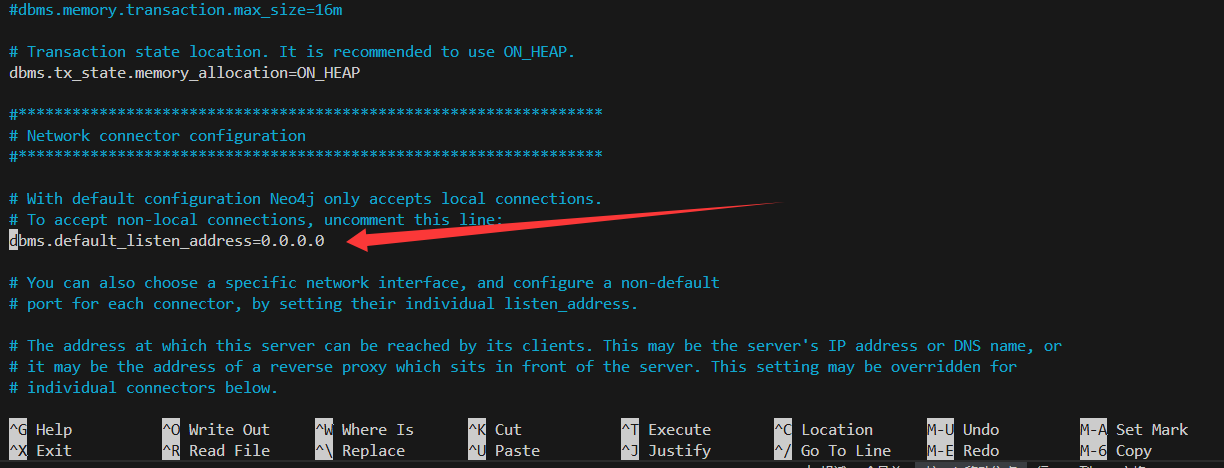
默认配置下,Neo4j 只允许本地连接。要允许从 Windows 机器访问,需修改其配置文件。
找到并修改以下行,确保 Neo4j 监听所有网络接口:
sudo nano /etc/neo4j/neo4j.conf
# 取消注释或修改为以下内容
dbms.default_listen_address=0.0.0.0# 分配内存
dbms.memory.heap.initial_size=1G
dbms.memory.heap.max_size=2G
重启服务,配置信息才会生效
sudo systemctl restart neo4j # 重启服务
sudo systemctl enable neo4j # 设置开机自动启动
sudo systemctl status neo4j # 检查服务状态
2.4 验证测试
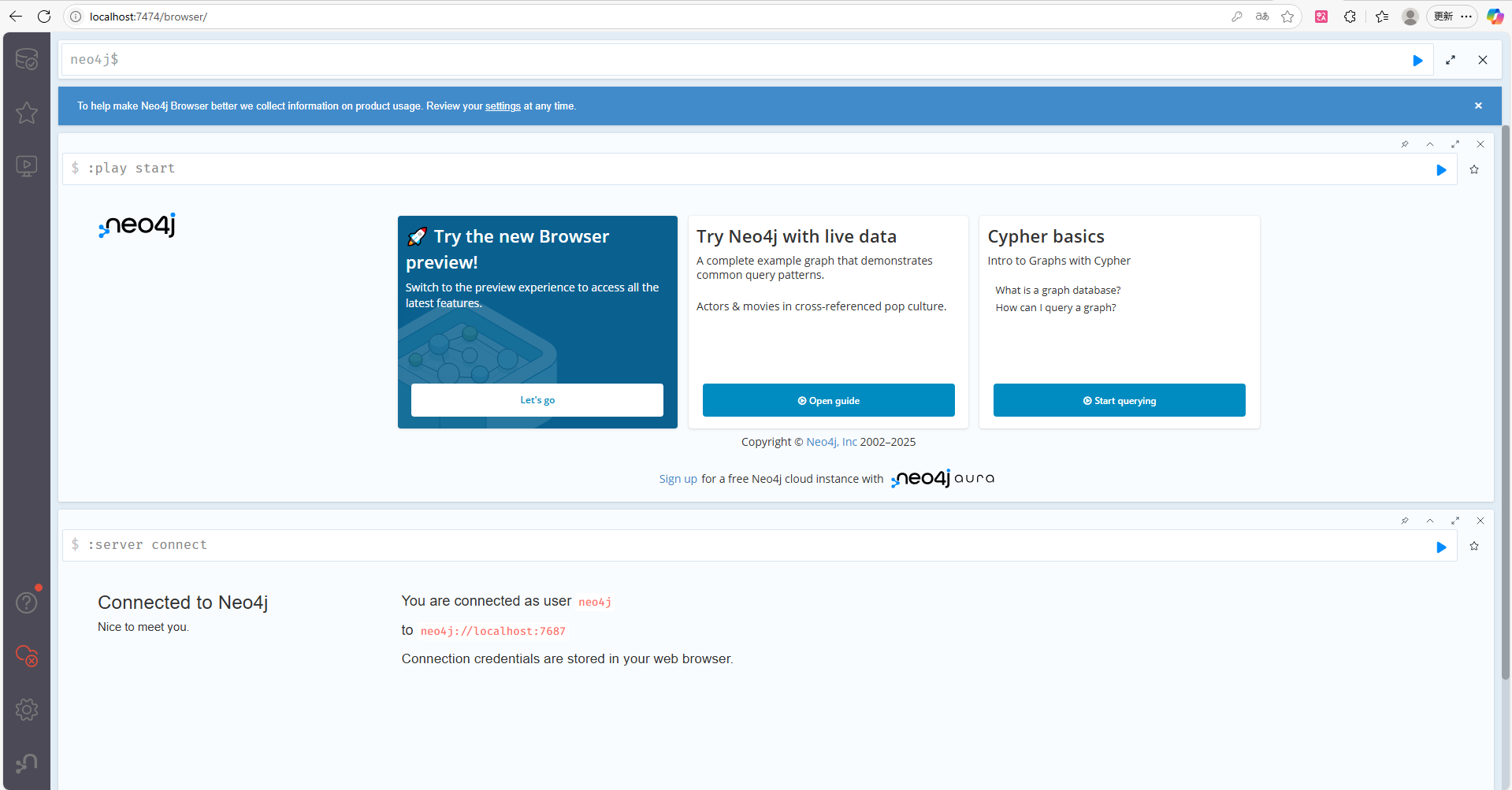
- 打开 http://localhost:7474
- 使用默认用户名
neo4j和初始密码neo4j登录 - 按提示设置新密码
2.5 卸载
# 停止 Neo4j 服务
sudo systemctl stop neo4j# 卸载 neo4j 软件包(保留配置文件可选)
sudo apt remove neo4j# 如果你想彻底删除所有配置文件和数据,可以使用 purge
sudo apt purge neo4j
2.6 基本用法
使用浏览器来进行增删改查
CREATE (n:Person {name: 'Alice', age: 30})
CREATE (a:Person {name: 'Bob', age: 25}), (b:Person {name: 'Charlie', age: 35})
# 创建关系
MATCH (a:Person {name: 'Alice'}), (b:Person {name: 'Bob'}) CREATE (a)-[:KNOWS {since: '2024-09-03'}]->(b)
# 查询
MATCH (n) RETURN n
MATCH (p:Person {name: 'Alice'}) RETURN p
# 查找年龄大于 25 且名字以 'A' 开头的人
MATCH (p:Person)
WHERE p.age > 25 AND p.name STARTS WITH 'A'RETURN p
查询节点和关系的个数
-- 检查是否还有任何节点存在,期望结果为 0
MATCH (n) RETURN count(n);-- 检查是否还有任何关系存在,期望结果为 0
MATCH ()-[r]->() RETURN count(r);
删除所有节点信息:
-- 这将匹配并删除所有节点及其所有关系
MATCH (n) DETACH DELETE n;
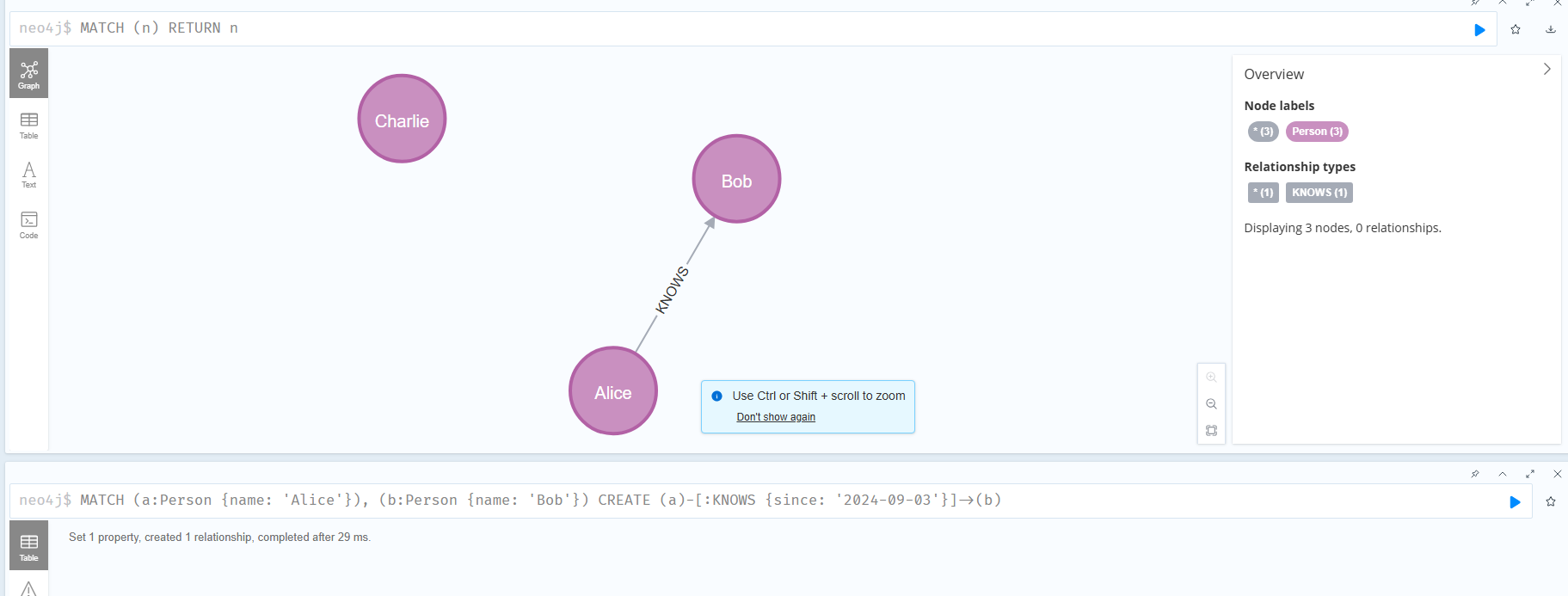
2.7 windows连接服务器可视化
访问官网,下载windows的软件
Thanks for Downloading Neo4j Desktop - Graph Database & Analytics
然后选择连接,用户名是 neoj4 ,密码如果没有在浏览器改过,就是neoj4,修改过就是修改后的密码。
连接的协议是 neo4j:// 地址是 服务器公网IP:7687 用户名:neoj4 密码初始是 neoj4
三、neo4j和mysql对比
3.1 场景对比
| 对比维度 | Neo4j (图数据库) | MySQL (关系型数据库) |
|---|---|---|
| 数据模型 | 图结构:节点(实体)、关系(连接)、属性(键值对) | 表结构:表、行、列,通过外键关联 |
| 查询语言 | Cypher:声明式语言,直观描述图形模式(如 | SQL:声明式语言,用于操作和查询表数据(如 |
| 核心优势 | 处理深度关联数据:多跳查询(如朋友的朋友)、路径查找、复杂关系分析性能极高,近乎实时 | 处理结构化数据:事务处理(OLTP)、复杂报表(OLAP)、多表连接查询,技术成熟稳定 |
| 典型应用场景 | 社交网络、推荐系统、欺诈检测、知识图谱、权限管理、供应链分析 | 电商平台、ERP系统、财务系统、内容管理系统(CMS) |
| 模式灵活性 | 动态模式(Schema-less):节点和关系的属性可以随时增减,无需预先定义严格结构 | 固定模式(Schema-full):表结构需预先设计定义(DDL),修改成本较高 |
| 扩展性 | 支持原生图存储和优化,擅长垂直扩展;企业版支持因果集群实现高可用和水平读扩展 | 支持主从复制、分片(Sharding)等方式进行水平和垂直扩展,方案成熟 |
| 事务支持 | 完全支持 ACID 事务 | 完全支持 ACID 事务 |
3.2 Mysql和neo4j的映射对比
| MySQL (关系型数据库) | Neo4j (图数据库) | 说明 |
|---|---|---|
| 表 (Table) | 节点标签 (Label) | 在 MySQL 中,一个表定义了一类实体的结构。在 Neo4j 中,一类实体用节点标签表示,如 |
| 一行记录 (Row) | 一个节点 (Node) | MySQL 表中的一行具体数据,对应 Neo4j 中的一个具体节点。 |
| 列 (Column) | 节点属性 (Property) | MySQL 中描述实体属性的列,对应 Neo4j 中节点的属性键值对。 |
| 外键关联 (Foreign Key) | 关系 (Relationship) | MySQL 中通过外键建立的表间关联,在 Neo4j 中转化为节点之间有方向、有类型的关系边。 |
| 关联表 (Junction Table) | 关系属性 (Property) | 在处理多对多关系时,MySQL 可能需要关联表,而 Neo4j 的关系本身可以直接拥有属性。 |
| JOIN 查询 | 关系遍历 | MySQL 中通过 JOIN 操作关联多表,Neo4j 通过直接遍历节点间的关系进行查询,效率更高。 |
3.3 mysql数据转换到neo4j存储
🔄 从 MySQL 转换到 Neo4j 的关键步骤
将 MySQL 数据库迁移到 Neo4j 通常包含以下几个核心阶段
- 1 数据建模(核心):
- •识别 MySQL 中的每个表:这些表通常会成为 Neo4j 中的节点标签(Label)。例如,
Users表对应:User节点。 - •识别 MySQL 表中的列:这些列通常会成为 Neo4j 中节点的属性。例如,
Users表中的name,email列。 - •识别 MySQL 中的外键关系或关联表:这些是转换的关键。它们会成为 Neo4j 中连接节点的关系(Relationship)。你需要为每种关系定义一个类型(Type)和方向(Direction)。例如,
FRIENDS_WITH、PLACED_ORDER、BELONGS_TO。
- •识别 MySQL 中的每个表:这些表通常会成为 Neo4j 中的节点标签(Label)。例如,
- 2 数据迁移:
- •编写 ETL (Extract, Transform, Load) 脚本或使用数据迁移工具。
- •提取 (Extract):从 MySQL 中读取数据。
- •转换 (Transform):将 MySQL 的数据结构转换为 Neo4j 的图数据结构(按照上一步的模型)。
- •加载 (Load):将转换后的数据导入 Neo4j。这可以通过 Neo4j 的
neo4j-admin批量导入工具实现,或者使用官方驱动(如neo4j-python-driver)通过 Cypher 语句写入
- 3 应用层调整:
- •将应用程序中原先的 SQL 查询语句重写为 Cypher 查询语句。
- •调整代码中与数据库交互的部分,使其适应 Neo4j 的查询方式和返回结果。
比如:假设有一个简单的 MySQL 数据库,包含 Users表和 Orders表
CREATE TABLE Users (UserID INT PRIMARY KEY,UserName VARCHAR(50)
);
CREATE TABLE Orders (OrderID INT PRIMARY KEY,UserID INT,ProductName VARCHAR(50),FOREIGN KEY (UserID) REFERENCES Users(UserID)
);转换为 Neo4j 的 Cypher 语句:
// 创建 User 节点
CREATE (u:User {UserID: 123, UserName: 'Alice'});// 创建 Order 节点
CREATE (o:Order {OrderID: 456, ProductName: 'Laptop'});// 创建用户和订单之间的关系 (假设用户ID123下了订单ID456)
MATCH (u:User {UserID: 123}), (o:Order {OrderID: 456})
CREATE (u)-[:PLACED_ORDER]->(o);四、实操mysql到neo4j转化
4.1 场景描述
mysql数据库中有两张表,用于记录用户和大模型交互系统的数据。
一张是chat_feedback.csv,用户反馈的表格
详细记录了哪个组织的哪个用户对哪个会话的哪轮回答进行点赞还是点踩(也可能没有点赞点踩),还有相关原因。
org_id user_id conversation_id task_id query answer is_like reasons comment created_at updated_at
还有一个表格是conversations.csv,用户会话表格
详细记录了 哪个组织的哪个用户的会话信息情况,下面是相关字段
org_id user_id conversation_id conversation_len conversation_name created_at updated_at
现在我们的目的是把上述两张表信息存储到neo4j中,然后进行高效的查询下述问题:
1) 查询某个组织(例如org_id为'XYZ')收到的所有负面反馈(is_like为0)及其原因
2) 查找用户'user123'提交的所有反馈所在的会话及其会话名称
3)分析某个会话(conversation_id为'conv456')中反馈的分布情况(点赞、点踩数量)
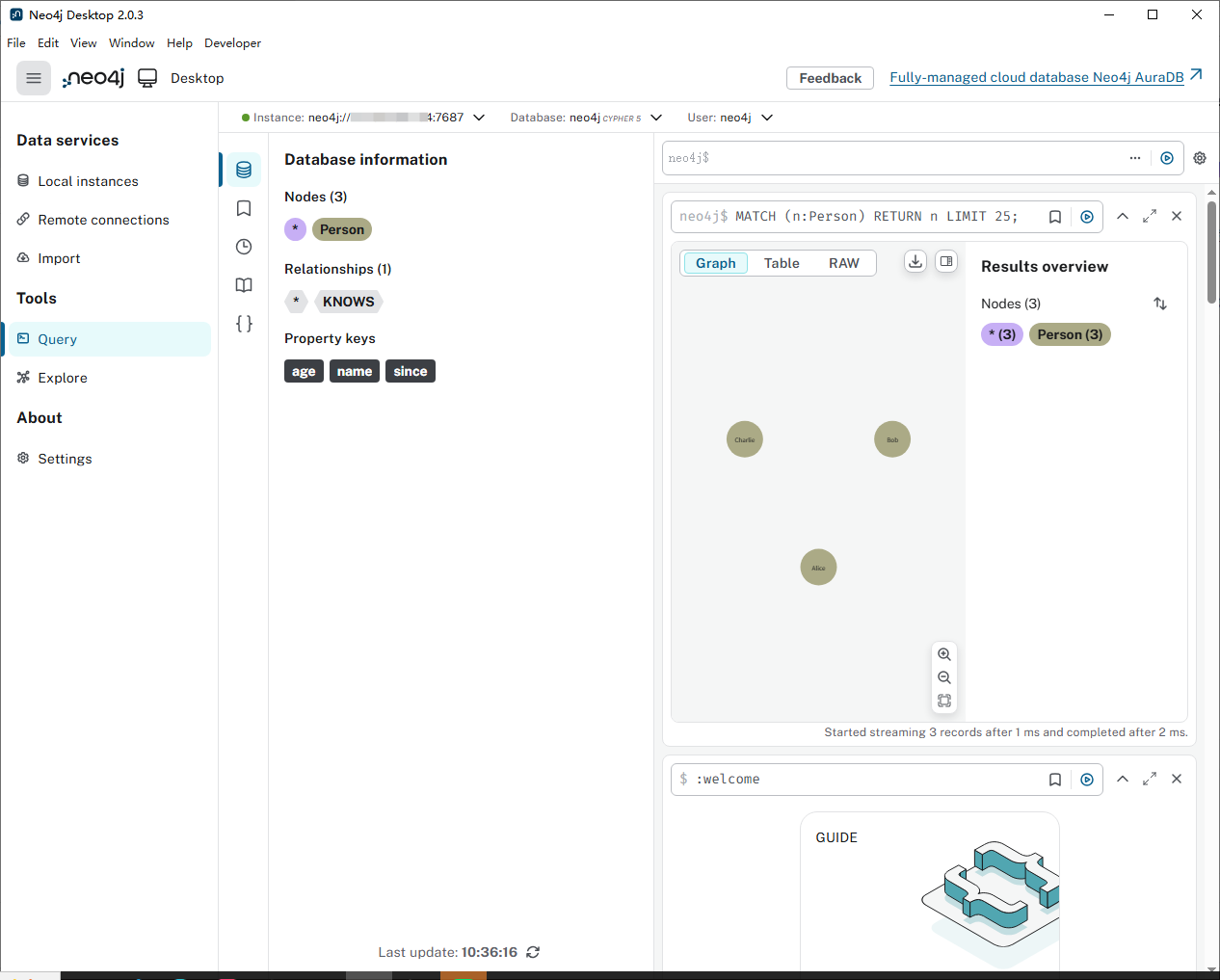
4.2 neo4j数据建模设计
| 节点名称 | 属性 | 标签 |
|---|---|---|
| 组织 |
|
|
| 用户 |
|
|
| 会话 |
|
|
| 反馈 |
|
|
| 关系名称 | 方向 | 属性(示例) | 描述 |
|---|---|---|---|
|
| 用户 → 组织 | - | 用户属于某个组织 |
|
| 会话 → 用户 | | 会话由某个用户在特定时间创建 |
|
| 会话 → 反馈 | - | 会话包含多条反馈 |
|
| 反馈 → 用户 | | 反馈由某个用户在特定时间提交 |
|
| 反馈 → 组织 | - | 反馈针对某个组织(可选,根据查询需求) |
4.3 python代码实现数据导入
import pandas as pd
from neo4j import GraphDatabase# Neo4j 连接配置
NEO4J_URI = "bolt://localhost:7687"
NEO4J_USER = "neo4j"
NEO4J_PASSWORD = "your_password" # 请替换为你的密码# 初始化驱动
driver = GraphDatabase.driver(NEO4J_URI, auth=(NEO4J_USER, NEO4J_PASSWORD))def import_to_neo4j(conversations_csv_path, chat_feedback_csv_path):"""将CSV数据导入Neo4j:param conversations_csv_path: 会话CSV文件路径:param chat_feedback_csv_path: 反馈CSV文件路径"""# 读取CSV文件df_conversations = pd.read_csv(conversations_csv_path)df_feedback = pd.read_csv(chat_feedback_csv_path)with driver.session() as session:# 1. 清空现有数据库(谨慎使用!根据需求决定是否保留)# session.run("MATCH (n) DETACH DELETE n")# 2. 创建索引以提高查询和导入性能session.run("CREATE INDEX IF NOT EXISTS FOR (o:Organization) ON (o.org_id)")session.run("CREATE INDEX IF NOT EXISTS FOR (u:User) ON (u.user_id)")session.run("CREATE INDEX IF NOT EXISTS FOR (c:Conversation) ON (c.conversation_id)")session.run("CREATE INDEX IF NOT EXISTS FOR (f:Feedback) ON (f.created_at)")# 3. 批量处理组织、用户和会话节点及其关系# 使用apoc.periodic.iterate进行批量处理,提高大规模数据导入效率create_nodes_relationships_query = """CALL apoc.periodic.iterate('UNWIND $batch AS row RETURN row','MERGE (org:Organization {org_id: row.org_id})MERGE (user:User {user_id: row.user_id})MERGE (conv:Conversation {conversation_id: row.conversation_id})ON CREATE SET conv.conversation_name = row.conversation_name,conv.conversation_len = row.conversation_len,conv.created_at = row.created_at,conv.updated_at = row.updated_atMERGE (user)-[:BELONGS_TO]->(org)// 创建CREATED_BY关系并设置created_at属性MERGE (conv)-[:CREATED_BY {created_at: row.created_at}]->(user)',{batchSize: 10000, parallel: false, params: {batch: $batch}})"""conversations_batch = df_conversations.to_dict('records')session.run(create_nodes_relationships_query, batch=conversations_batch)# 4. 批量处理反馈节点及其关系create_feedback_relationships_query = """CALL apoc.periodic.iterate('UNWIND $batch AS row RETURN row','MATCH (conv:Conversation {conversation_id: row.conversation_id})MATCH (user:User {user_id: row.user_id})MATCH (org:Organization {org_id: row.org_id})CREATE (feedback:Feedback {is_like: row.is_like,reasons: row.reasons,comment: row.comment,query: row.query,answer: row.answer,created_at: row.created_at,updated_at: row.updated_at})CREATE (conv)-[:HAS_FEEDBACK]->(feedback)// 创建SUBMITTED_BY关系并设置created_at属性CREATE (feedback)-[:SUBMITTED_BY {created_at: row.created_at}]->(user)CREATE (feedback)-[:ABOUT_ORGANIZATION]->(org)',{batchSize: 10000, parallel: false, params: {batch: $batch}})"""feedback_batch = df_feedback.to_dict('records')session.run(create_feedback_relationships_query, batch=feedback_batch)print("数据导入完成!")if __name__ == "__main__":try:import_to_neo4j("conversations.csv", "chat_feedback.csv")except Exception as e:print(f"导入过程中发生错误: {e}")finally:driver.close()4.4 常见错误及解决方法
{code: Neo.ClientError.Procedure.ProcedureNotFound} {message: There is no procedure with the name `apoc.periodic.iterate` registered for this database instance. Please ensure you've spelled the procedure name correctly and that the procedure is properly deployed.}
报错说明neo4j服务器端没有安装匹配版本的apoc插件,或者没有启用这个插件。
查找一下插件目录位置
sudo systemctl status neo4j
确认插件目录/var/lib/neo4j/plugins/,再查找目录下有没有apoc插件
cd /var/lib/neo4j/plugins/
ls

说明没有安装插件
确认neo4j版本号
CALL dbms.components() YIELD name, versions
RETURN name, versions;
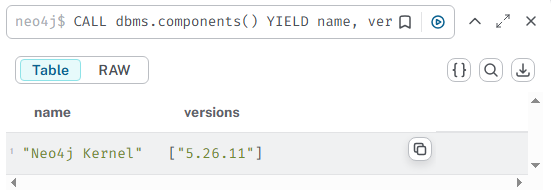
根据查询得到的 Neo4j 版本号,去 GitHub Release 页面下载对应版本的 APOC 插件。
确保你下载的 APOC 版本与你的 Neo4j 版本完全一致(例如 Neo4j 4.4.45对应 APOC 4.4.45)。
然后直接将 Jar 文件放入 plugins目录,不要新建子文件夹,也不要解压 Jar 包
sudo cp /path/to/your/downloaded/apoc-*.jar /var/lib/neo4j/plugins/
sudo cp /root/apoc-5.26.11-core.jar /var/lib/neo4j/plugins/
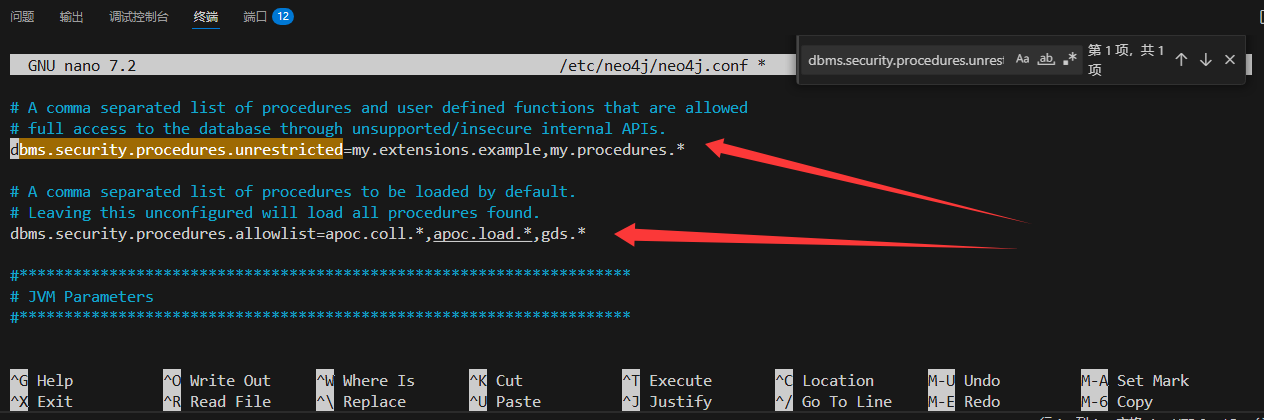
修改配置文件
sudo nano /etc/neo4j/neo4j.conf
#找到如下配置打开
dbms.security.procedures.unrestricted=apoc.*
dbms.security.procedures.allowlist=apoc.*# 重启生效
sudo systemctl restart neo4j
# 验证
RETURN apoc.version();
4.5 代码不使用apoc插件
如果插件apoc安装还是失败,那就修改代码,不用apoc插件,这个插件比较快。面对大文件或者多种格式的文件都可以。
import pandas as pd
from neo4j import GraphDatabase
import chardet # 用于自动检测文件编码# Neo4j 连接配置
NEO4J_URI = "neo4j://yourIP:7687"
NEO4J_USER = "neo4j"
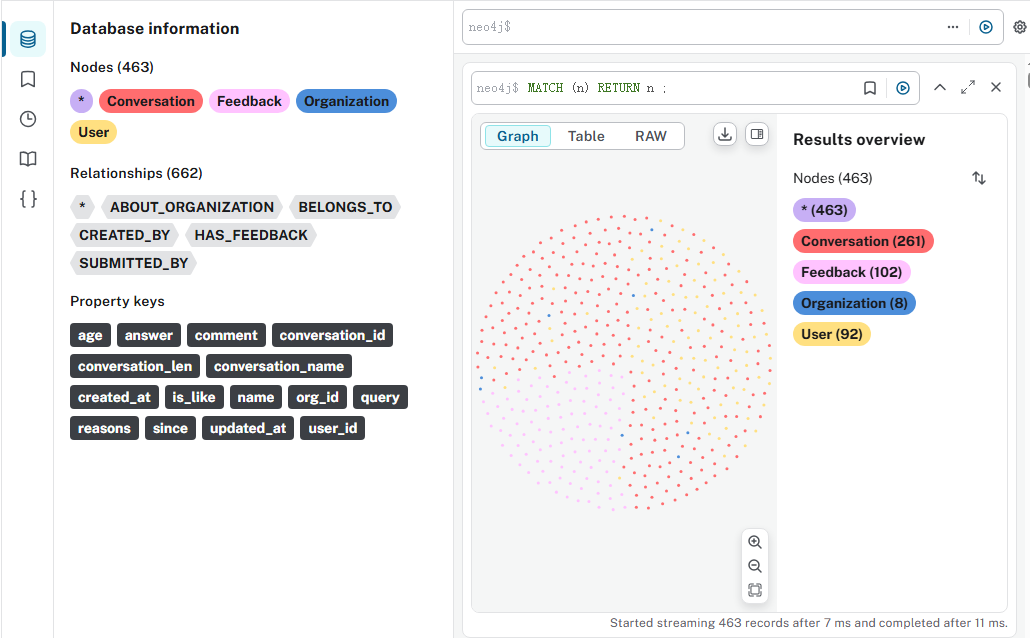
NEO4J_PASSWORD = "password" # 请替换为你的密码def detect_encoding(file_path):"""自动检测文件的编码格式:param file_path: 文件路径:return: 检测到的编码字符串,如 'utf-8', 'gbk' 等"""with open(file_path, 'rb') as f:raw_data = f.read(10000) # 读取文件前10000字节来检测编码,通常足够result = chardet.detect(raw_data)encoding = result['encoding']confidence = result['confidence']print(f"文件 '{file_path}' 检测到编码: {encoding} (置信度: {confidence:.2f})")return encoding if confidence > 0.7 else 'utf-8' # 如果置信度太低,则默认使用utf-8尝试def read_csv_with_encoding(file_path, fallback_encodings=['utf-8', 'gbk', 'gb18030', 'iso-8859-1']):"""尝试使用检测到的或备选的编码读取CSV文件:param file_path: 文件路径:param fallback_encodings: 备选编码列表:return: DataFrame对象"""# 首先尝试自动检测编码try:detected_encoding = detect_encoding(file_path)if detected_encoding:df = pd.read_csv(file_path, encoding=detected_encoding)print(f"使用检测到的编码 '{detected_encoding}' 成功读取文件 '{file_path}'")return dfexcept Exception as e:print(f"使用检测到的编码 '{detected_encoding}' 读取文件 '{file_path}' 失败: {e}")print("开始尝试备选编码...")# 如果自动检测失败,则逐个尝试备选编码for enc in fallback_encodings:try:df = pd.read_csv(file_path, encoding=enc)print(f"使用备选编码 '{enc}' 成功读取文件 '{file_path}'")return dfexcept UnicodeDecodeError as e:print(f"备选编码 '{enc}' 失败: {e}")continueexcept Exception as e:print(f"使用备选编码 '{enc}' 读取文件时发生其他错误: {e}")continue# 所有编码尝试都失败raise ValueError(f"无法读取文件 '{file_path}',所有尝试的编码均失败。")def import_to_neo4j(conversations_csv_path, chat_feedback_csv_path):"""将CSV数据导入Neo4j:param conversations_csv_path: 会话CSV文件路径:param chat_feedback_csv_path: 反馈CSV文件路径"""# 读取CSV文件,处理编码问题try:df_conversations = read_csv_with_encoding(conversations_csv_path)df_feedback = read_csv_with_encoding(chat_feedback_csv_path)# 确保日期列是字符串类型,避免后续处理问题for df in [df_conversations, df_feedback]:if 'created_at' in df.columns:df['created_at'] = df['created_at'].astype(str)if 'updated_at' in df.columns:df['updated_at'] = df['updated_at'].astype(str)except Exception as e:print(f"读取CSV文件时发生错误: {e}")return# 初始化Neo4j驱动driver = GraphDatabase.driver(NEO4J_URI, auth=(NEO4J_USER, NEO4J_PASSWORD))try:with driver.session() as session:# 1. 清空现有数据库(谨慎使用!根据需求决定是否保留)session.run("MATCH (n) DETACH DELETE n")# 2. 创建索引以提高查询和导入性能[3](@ref)session.run("CREATE INDEX IF NOT EXISTS FOR (o:Organization) ON (o.org_id)")session.run("CREATE INDEX IF NOT EXISTS FOR (u:User) ON (u.user_id)")session.run("CREATE INDEX IF NOT EXISTS FOR (c:Conversation) ON (c.conversation_id)")session.run("CREATE INDEX IF NOT EXISTS FOR (f:Feedback) ON (f.created_at)")# 3. 批量处理组织、用户和会话节点及其关系(使用UNWIND代替APOC)[1,3](@ref)print("开始导入会话数据...")conversations_batch = df_conversations.to_dict('records')batch_size = 10000 # 每批处理的数据量[3](@ref)for i in range(0, len(conversations_batch), batch_size):batch = conversations_batch[i:i+batch_size]create_nodes_relationships_query = """UNWIND $batch AS rowMERGE (org:Organization {org_id: row.org_id})MERGE (user:User {user_id: row.user_id})MERGE (conv:Conversation {conversation_id: row.conversation_id})ON CREATE SET conv.conversation_name = row.conversation_name,conv.conversation_len = row.conversation_len,conv.created_at = row.created_at,conv.updated_at = row.updated_atMERGE (user)-[:BELONGS_TO]->(org)MERGE (conv)-[:CREATED_BY {created_at: row.created_at}]->(user)"""session.run(create_nodes_relationships_query, batch=batch)print(f"已处理 {min(i+batch_size, len(conversations_batch))}/{len(conversations_batch)} 条会话记录")print("会话数据导入完成!")# 4. 批量处理反馈节点及其关系(使用UNWIND代替APOC)print("开始导入反馈数据...")feedback_batch = df_feedback.to_dict('records')for i in range(0, len(feedback_batch), batch_size):batch = feedback_batch[i:i+batch_size]create_feedback_relationships_query = """UNWIND $batch AS rowMATCH (conv:Conversation {conversation_id: row.conversation_id})MATCH (user:User {user_id: row.user_id})MATCH (org:Organization {org_id: row.org_id})CREATE (feedback:Feedback {is_like: row.is_like,reasons: row.reasons,comment: row.comment,query: row.query,answer: row.answer,created_at: row.created_at,updated_at: row.updated_at})CREATE (conv)-[:HAS_FEEDBACK]->(feedback)CREATE (feedback)-[:SUBMITTED_BY {created_at: row.created_at}]->(user)CREATE (feedback)-[:ABOUT_ORGANIZATION]->(org)"""session.run(create_feedback_relationships_query, batch=batch)print(f"已处理 {min(i+batch_size, len(feedback_batch))}/{len(feedback_batch)} 条反馈记录")print("反馈数据导入完成!")print("所有数据导入完成!")except Exception as e:print(f"导入Neo4j过程中发生错误: {e}")finally:driver.close()if __name__ == "__main__":try:import_to_neo4j(r"C:\Users\GDZD-BG-202115\Desktop\knowlege\medgraph-ai\data\conversations.csv",r"C:\Users\GDZD-BG-202115\Desktop\knowlege\medgraph-ai\data\chat_feedback.csv")except Exception as e:print(f"导入过程中发生错误: {e}")导入数据成功后,就是增删改查了。
五、参考资料
asanmateu/medgraph-ai:基于 Neo4j 知识图谱的医疗保健 RAG 代理 - 使用 LangChain、FastAPI 和 Streamlit 查询医疗数据 --- asanmateu/medgraph-ai: Healthcare RAG agent with Neo4j knowledge graphs - Query medical data using LangChain, FastAPI & Streamlit
Cypher 与 SQL 的比较 - 入门 --- Comparing Cypher with SQL - Getting Started
企业知识库AI助手的知识图谱构建架构:从数据到图谱-CSDN博客
Neo4j简介及安装_neo4j安装-CSDN博客
Neo4j简介及安装_neo4j安装-CSDN博客
从关系型到图数据库:MySQL到Neo4j的平滑迁移策略_mysql数据导入neo4j-CSDN博客
使用 LangChain 构建 LLM RAG 聊天机器人 – Real Python --- Build an LLM RAG Chatbot With LangChain – Real Python

---出现interactive_timeout/wait_timeout)


)



)










