vue+flask农产品推荐与价格预测系统、双推荐+机器学习价格预测+知识图谱
文章结尾部分有CSDN官方提供的学长 联系方式名片
文章结尾部分有CSDN官方提供的学长 联系方式名片
关注B站,有好处!
编号: D010
技术架构: vue+flask+mysql+neo4j
核心技术:
- 基于用户和基于物品双推荐算法
- 回归价格预测算法
- echarts 可视化
- 知识图谱
- 爬虫更新数据
背景
随着数据科学技术的发展和农业信息化的深入推进,农产品价格预测系统成为了农业生产和经营管理中的重要工具。本系统基于Vue + Django的前后端分离架构,结合MySQL和Neo4j数据库,采用scikit-learn多项式回归算法进行价格预测,并利用协同过滤算法推荐农产品,旨在为用户提供准确的农产品价格预测和信息服务。系统不仅包括用户和管理员的常规管理功能,还引入了知识图谱和数据可视化技术,以增强系统的信息处理能力和用户体验。
1 系统介绍
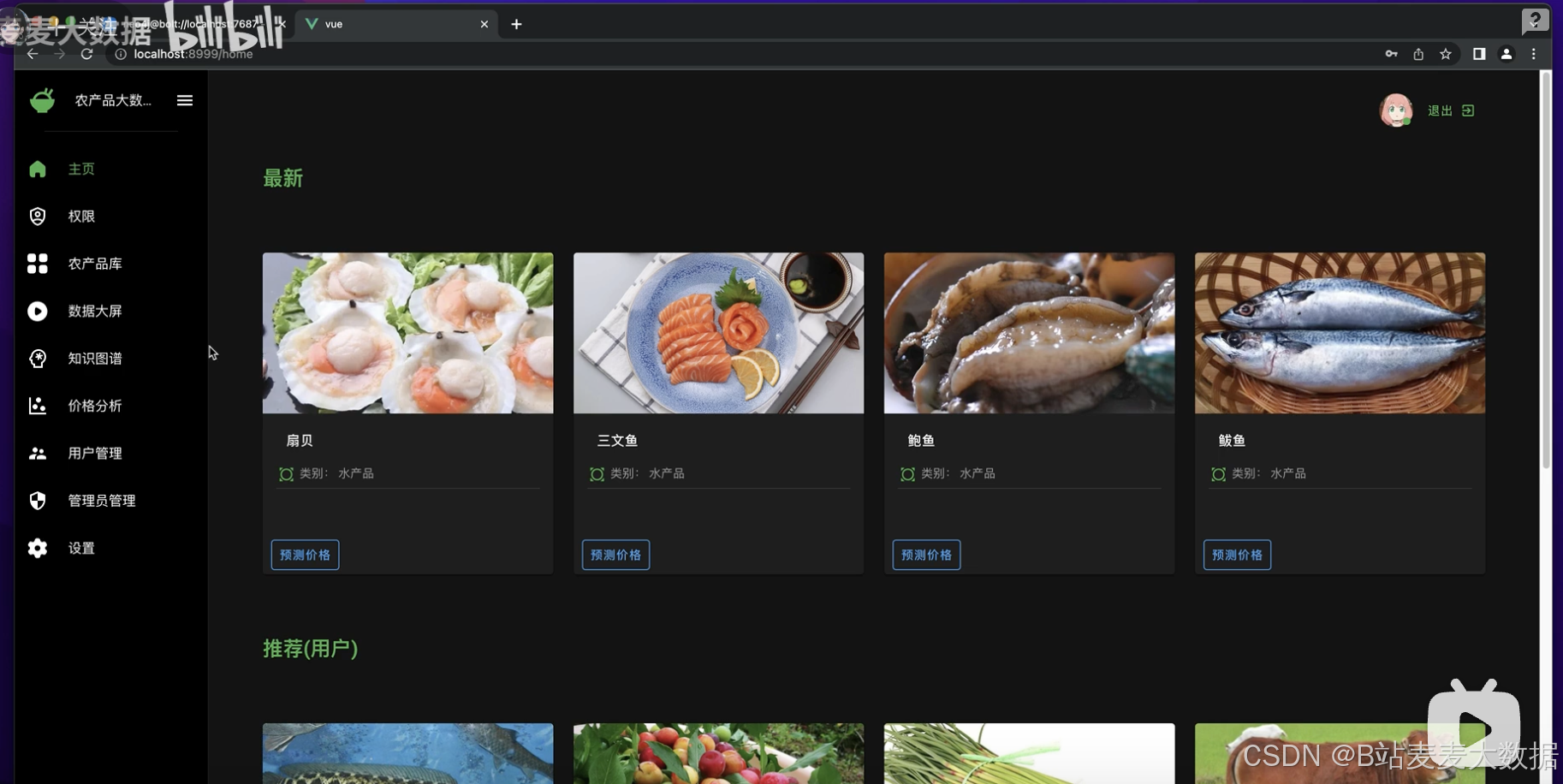
农产品价格预测系统是一个集数据采集、处理、分析、预测于一体的综合信息服务平台。系统主要针对农业领域的企业和个人,提供60多种蔬菜、水果、水产和粮食等农产品的当前最新价格和历史价格数据,以及基于历史数据的价格预测服务。系统采用Vue + Django构建前后端分离架构,前端使用Vuetify框架提高开发效率和用户交互质量,后端以Django框架处理业务逻辑,数据存储则选用MySQL和Neo4j数据库,以适应不同的数据存储需求。
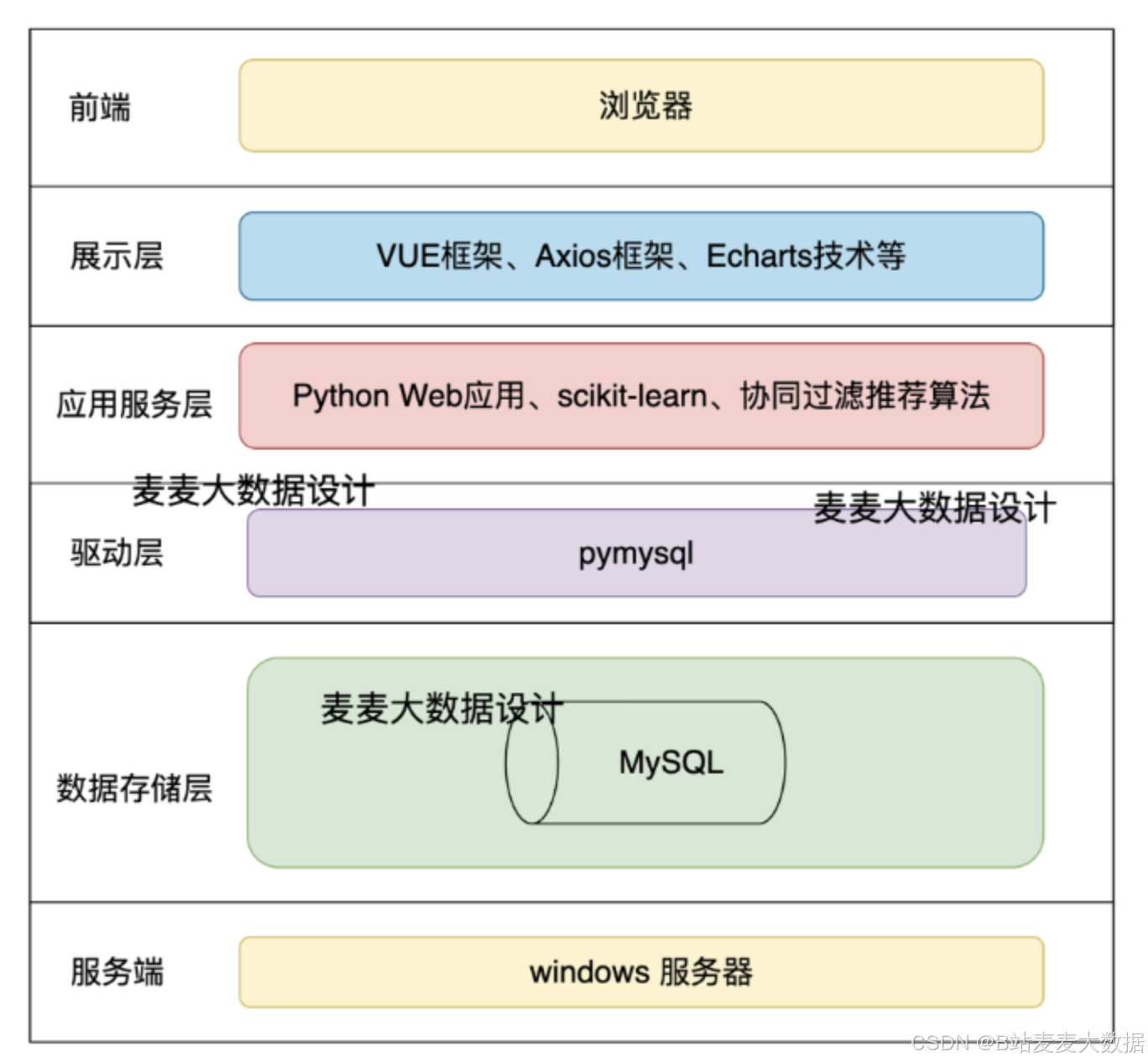
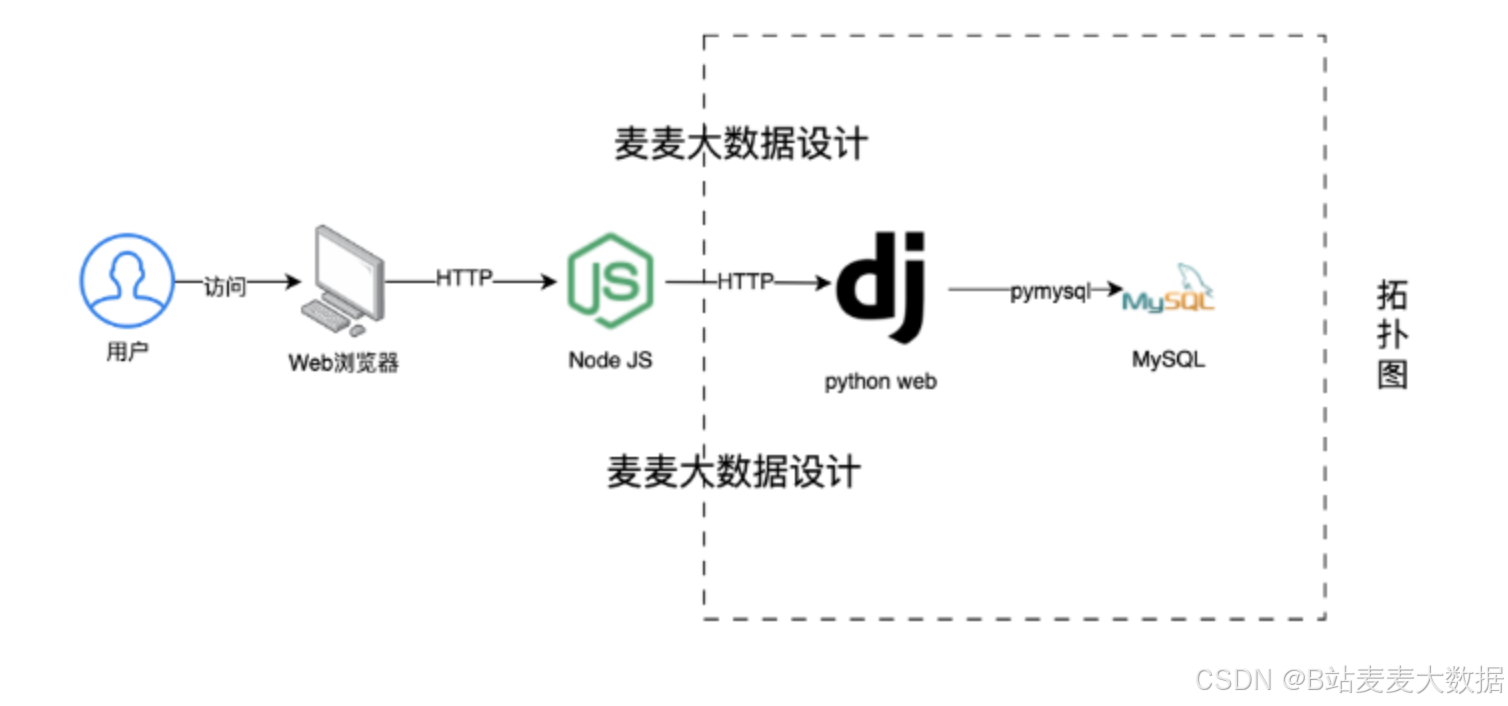
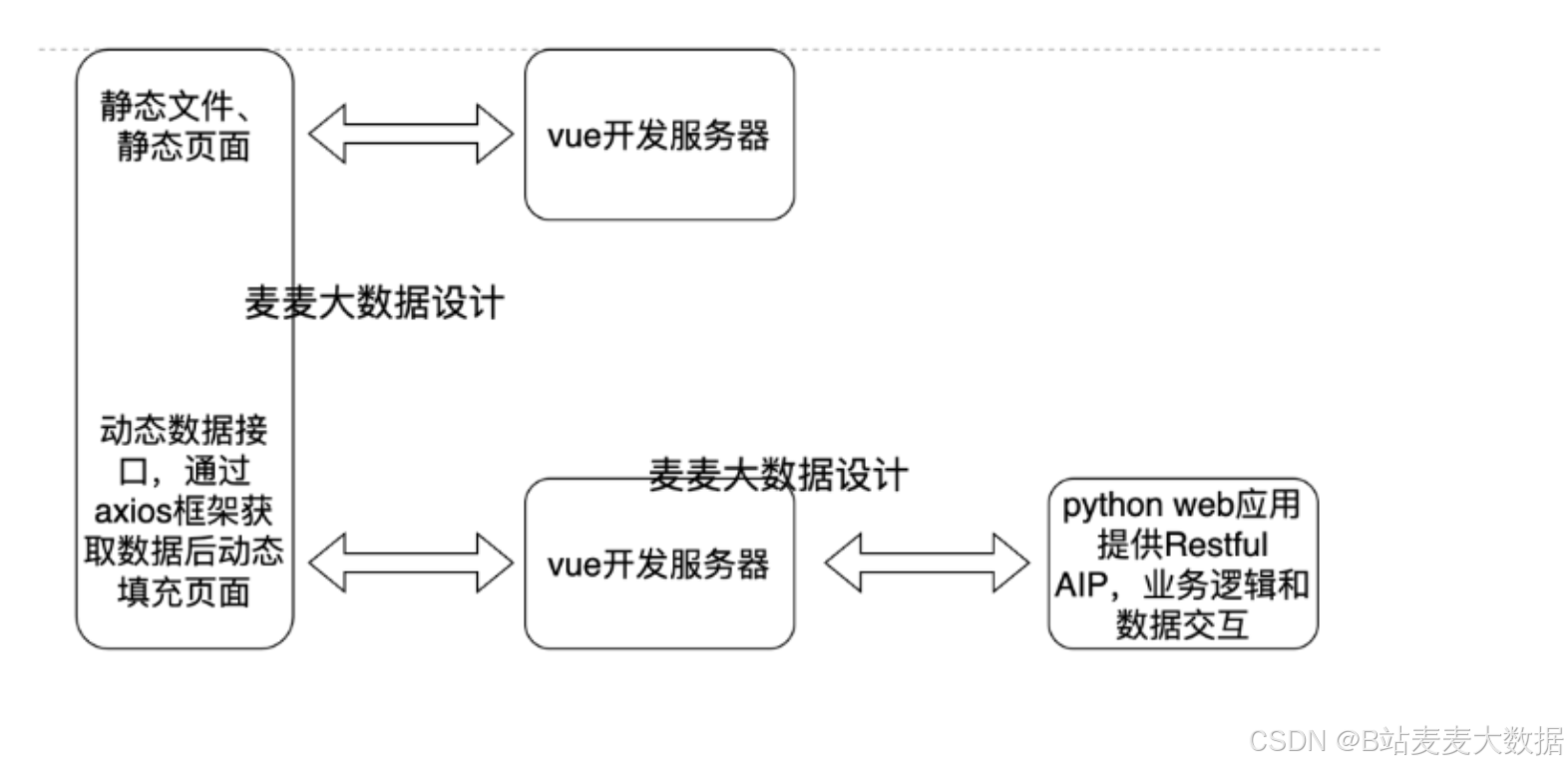
2 系统架构
前端技术:系统前端采用Vue.js框架和Vuetify组件库,构建了一个响应式、用户友好的界面。利用Vue的高效数据绑定和组件系统,配合Vuetify提供的丰富UI组件,为用户提供了流畅的操作体验。
后端技术:Django作为后端框架,不仅提供了强大的模型系统和自动的管理工具,还通过Django REST framework支持构建RESTful API,实现与前端的高效数据交互。
数据存储:系统采用MySQL和Neo4j双数据库设计。MySQL负责存储用户数据、农产品价格数据等结构化信息,而Neo4j用于构建农业领域的知识图谱,支持复杂的关系数据查询。
架构
技术报告

运行说明

3 核心功能
数据采集与处理:系统能够自动采集60多种农产品的最新和历史价格信息,通过数据清洗和处理,保证数据质量和时效性。
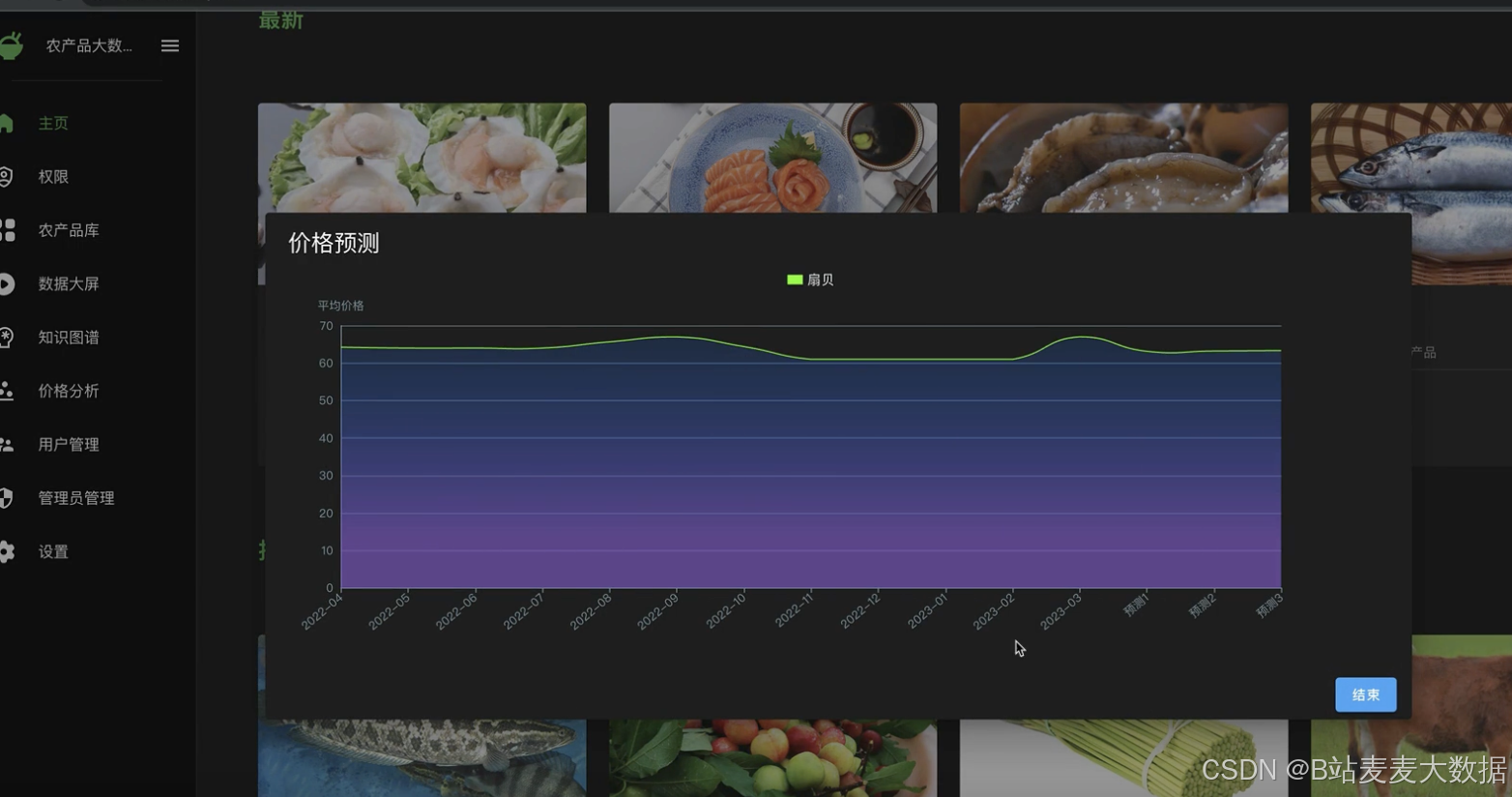
价格预测:采用scikit-learn的多项式回归算法,根据农产品的历史价格数据进行价格预测,帮助用户预测未来价格变动趋势。
import numpy as np
import matplotlib.pyplot as plt
import pymysqlcnn = pymysql.connect(host=host, user=user, password=password, port=port, database=database,charset='utf8')###########1.数据生成部分##########
def f(x1, x2):y = 0.5 * np.sin(x1) + 0.5 * np.cos(x2) + 3 + 0.1 * x1return ydef load_data():x1_train = np.linspace(0, 50, 500)x2_train = np.linspace(-10, 10, 500)data_train = np.array([[x1, x2, f(x1, x2) + (np.random.random(1) - 0.5)] for x1, x2 in zip(x1_train, x2_train)],dtype=object)x1_test = np.linspace(0, 50, 100) + 0.5 * np.random.random(100)x2_test = np.linspace(-10, 10, 100) + 0.02 * np.random.random(100)data_test = np.array([[x1, x2, f(x1, x2)] for x1, x2 in zip(x1_test, x2_test)])return data_train, data_testdef load_data_my():name = '肉蟹'sql = "select time1, avg(price) from tb_crop_price" \" where name='%s' group by time1 limit 12" % (name)with cnn.cursor() as cursor:cursor.execute(sql)print(sql)names = []y = []for line in cursor.fetchall():# print(line)y.append(line[1])names.append(line[0])y = np.array(y)x1_train = np.linspace(1, 12, 12)data_train = np.array([[x1, y] for x1, in zip(x1_train)], dtype=object)x1_test = np.linspace(1, 12, 12)data_test = np.array([[x1, y] for x1, in zip(x1_test)], dtype=object)return data_train, data_testtrain, test = load_data_my()# x_train, y_train = train[:, :2], train[:, 2] # 数据前两列是x1,x2 第三列是y,这里的y有随机噪声
# x_test, y_test = test[:, :2], test[:, 2] # 同上,不过这里的y没有噪声
x_train, y_train = train[:, :1], train[:, 1] # 数据前两列是x1,x2 第三列是y,这里的y有随机噪声
x_test, y_test = test[:, :1], test[:, 1] # 同上,不过这里的y没有噪声###########2.回归部分##########
def try_different_method(model):model.fit(x_train, y_train)score = model.score(x_test, y_test)result = model.predict(x_test)plt.figure()plt.plot(np.arange(len(result)), y_test, 'go-', label='true value')plt.plot(np.arange(len(result)), result, 'ro-', label='predict value')plt.title('score: %f' % score)plt.legend()plt.show()###########3.具体方法选择##########
####3.1决策树回归####
from sklearn import treemodel_DecisionTreeRegressor = tree.DecisionTreeRegressor()
####3.2线性回归####
from sklearn import linear_modelmodel_LinearRegression = linear_model.LinearRegression()
####3.3SVM回归####
from sklearn import svmmodel_SVR = svm.SVR()
####3.4KNN回归####
from sklearn import neighborsmodel_KNeighborsRegressor = neighbors.KNeighborsRegressor()
####3.5随机森林回归####
from sklearn import ensemblemodel_RandomForestRegressor = ensemble.RandomForestRegressor(n_estimators=20) # 这里使用20个决策树
####3.6Adaboost回归####
from sklearn import ensemblemodel_AdaBoostRegressor = ensemble.AdaBoostRegressor(n_estimators=50) # 这里使用50个决策树
####3.7GBRT回归####
from sklearn import ensemblemodel_GradientBoostingRegressor = ensemble.GradientBoostingRegressor(n_estimators=100) # 这里使用100个决策树
####3.8Bagging回归####
from sklearn.ensemble import BaggingRegressormodel_BaggingRegressor = BaggingRegressor()
####3.9ExtraTree极端随机树回归####
from sklearn.tree import ExtraTreeRegressormodel_ExtraTreeRegressor = ExtraTreeRegressor()
###########4.具体方法调用部分##########
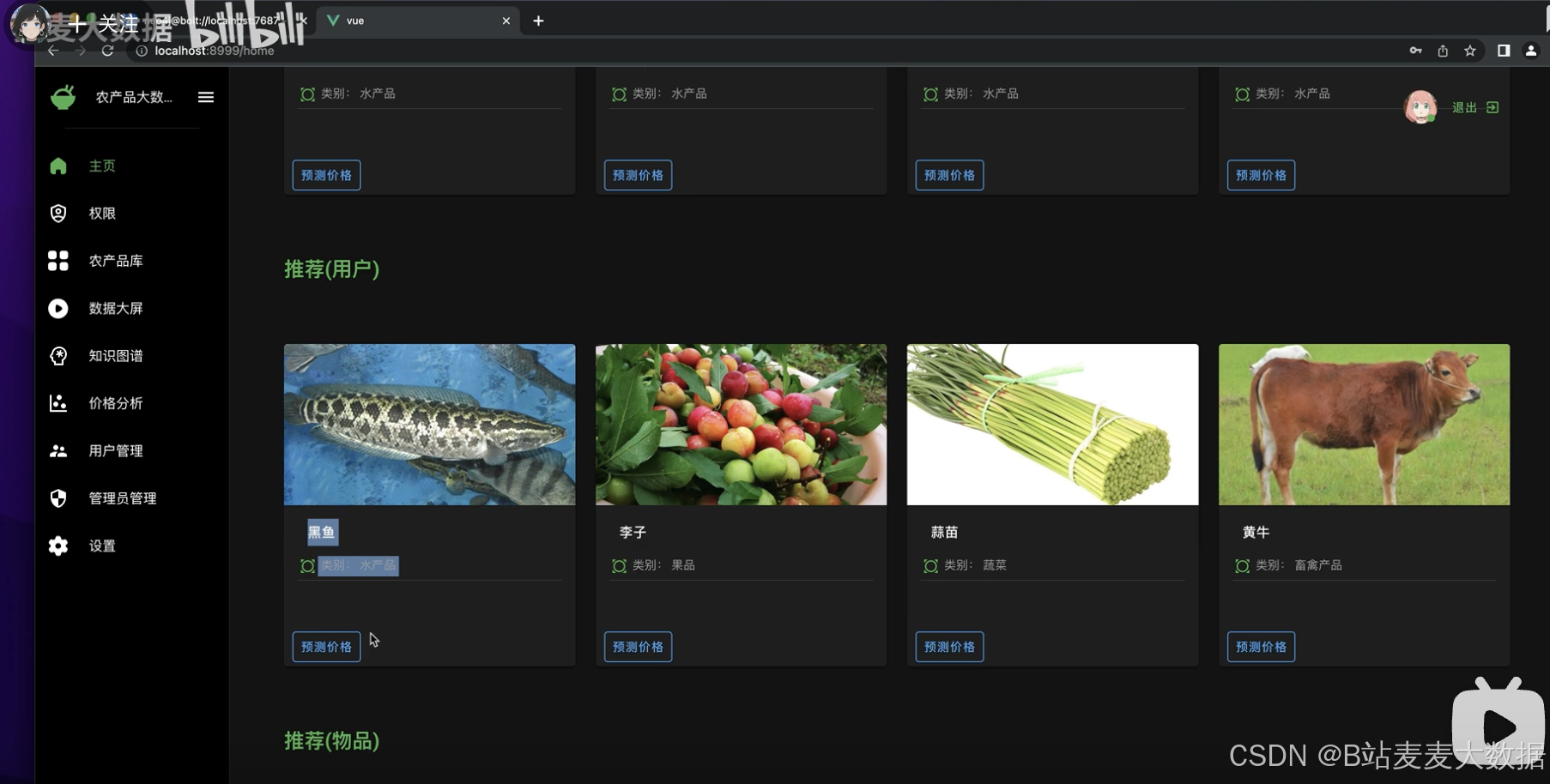
try_different_method(model_ExtraTreeRegressor)推荐算法:系统集成了两种协同过滤推荐算法,根据用户的浏览和购买行为,推荐潜在感兴趣的农产品。
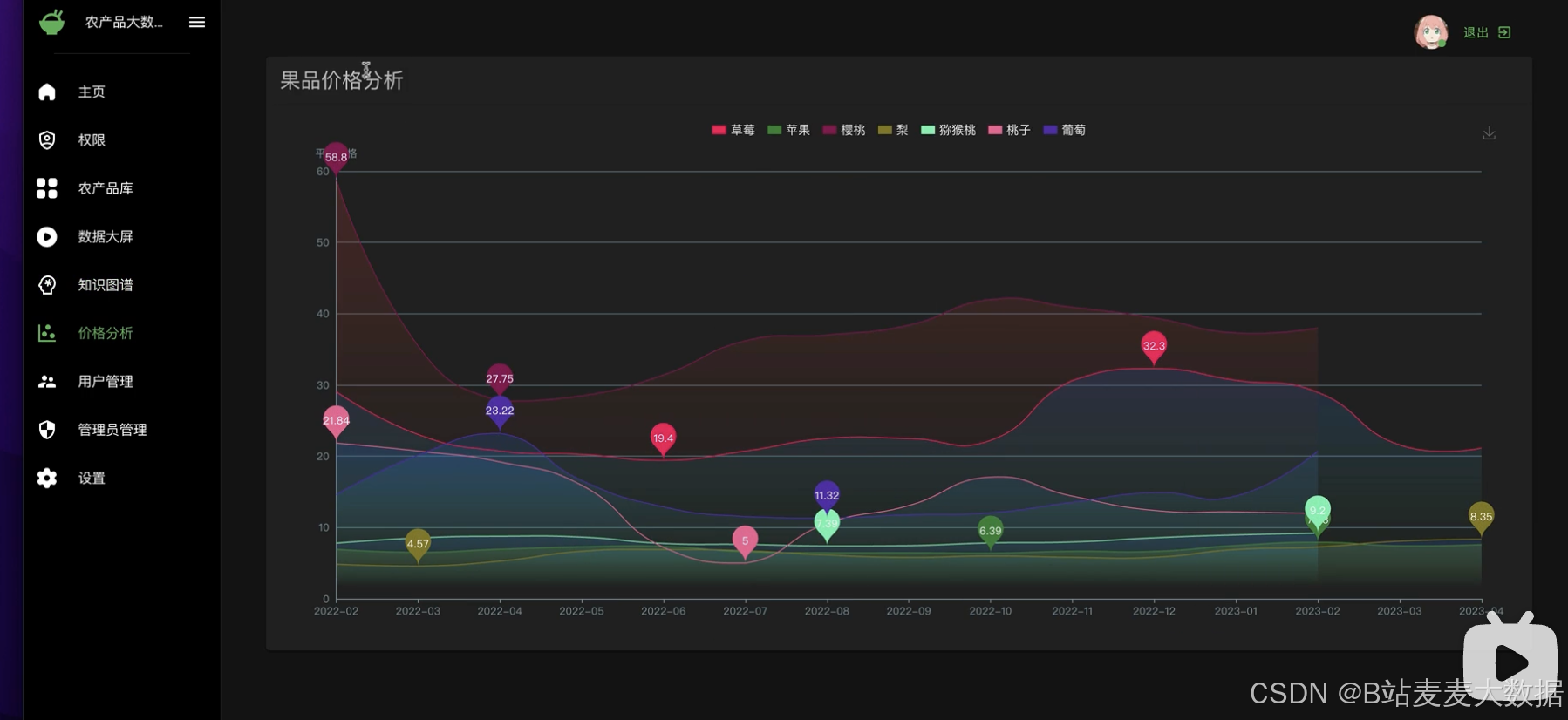
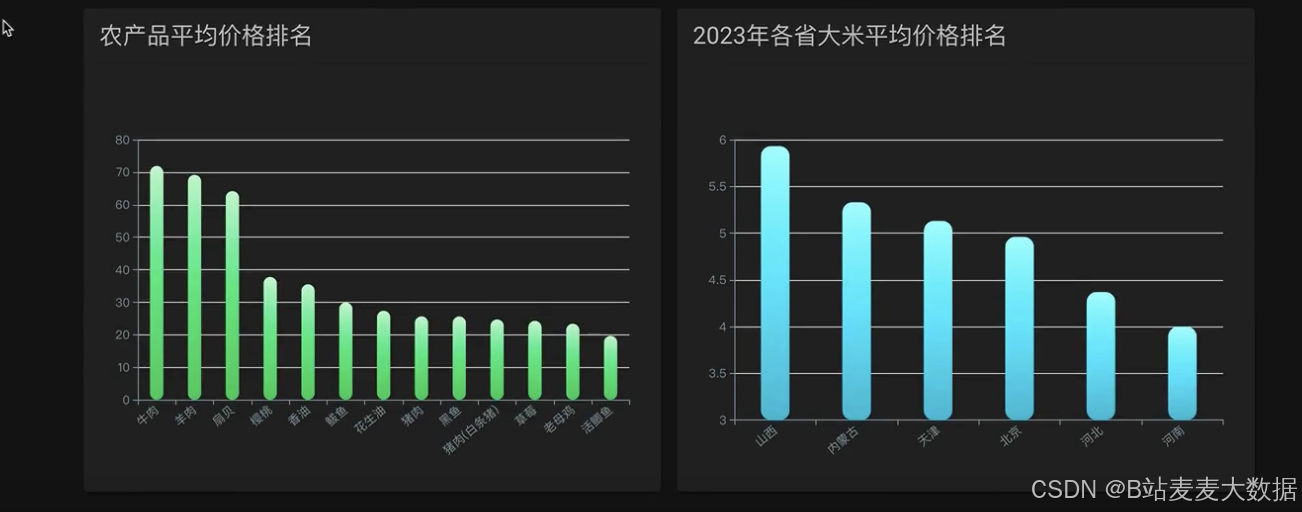
数据可视化:使用ECharts进行数据可视化,包括大屏展示、果品价格分析等功能,直观展现农产品价格趋势和分析结果。
可视化大屏:针对果品价格分析和其他农产品的数据可视化需求,系统设计了可视化大屏功能,通过图表和图形直观展示数据分析结果,增强用户体验。
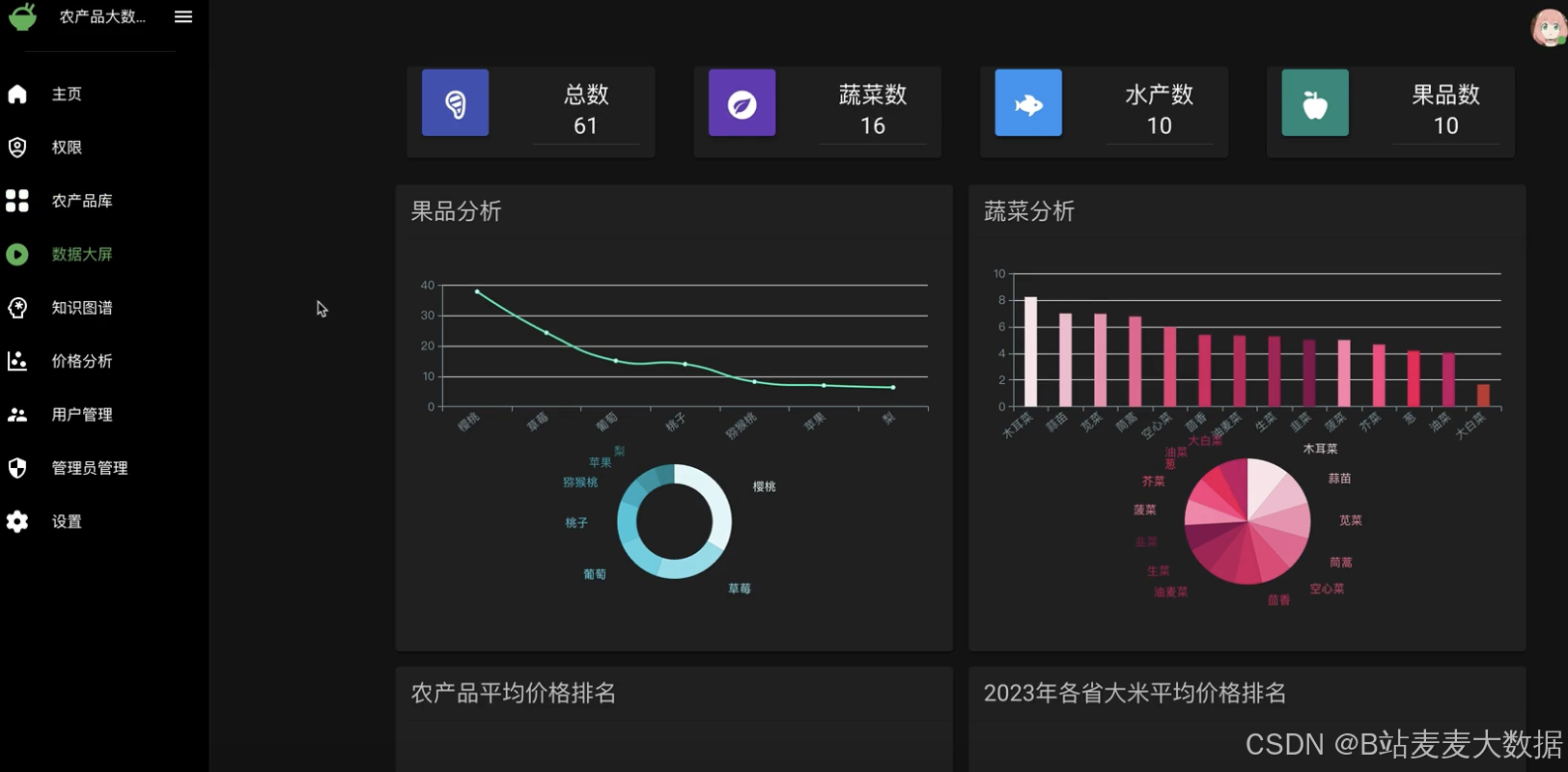
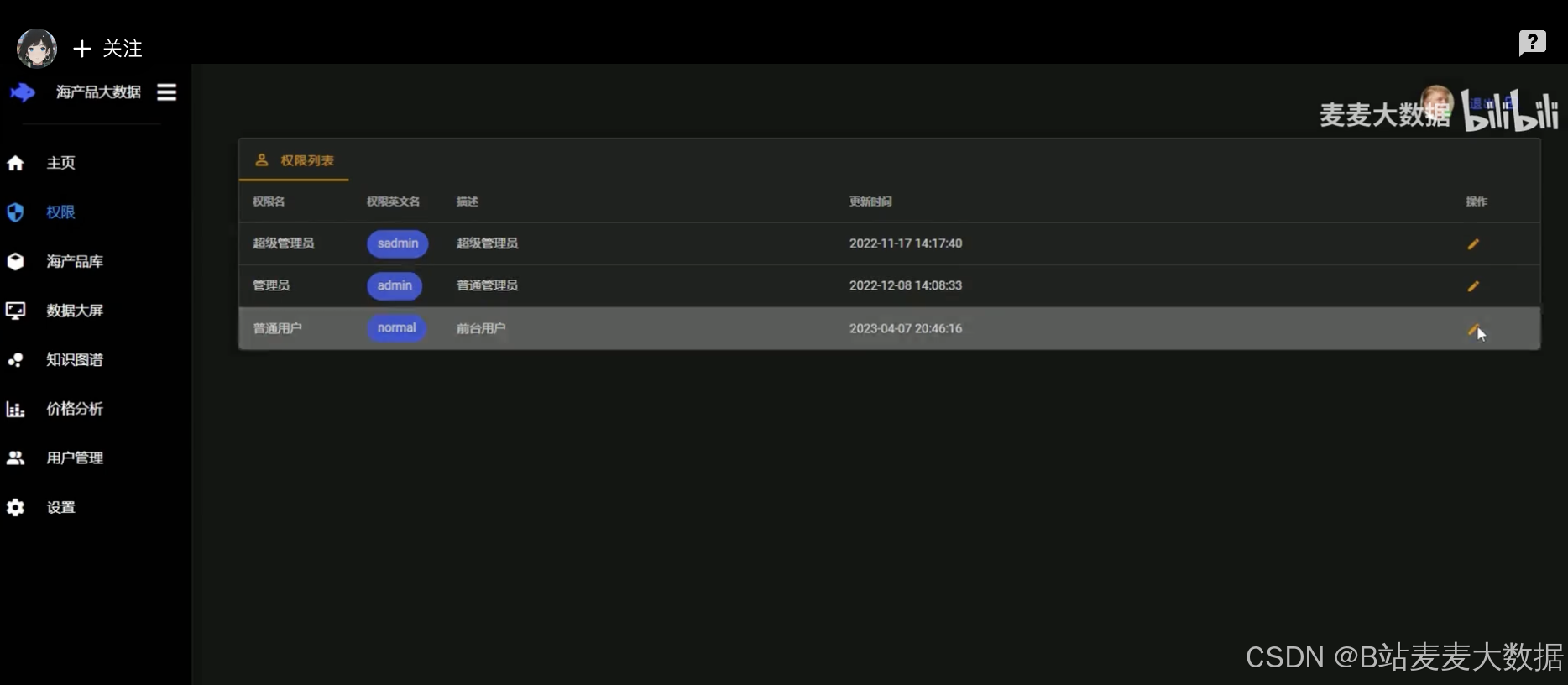
用户和管理员管理:完整的用户管理功能,包括注册、登录、信息修改、短信验证码修改密码等,管理员则具有权限管理功能。

知识图谱:创建农业领域的知识图谱,为用户提供丰富的农业知识和信息。知识图谱的引入,不仅丰富了系统的数据维度,还提高了数据分析和推荐的准确性。
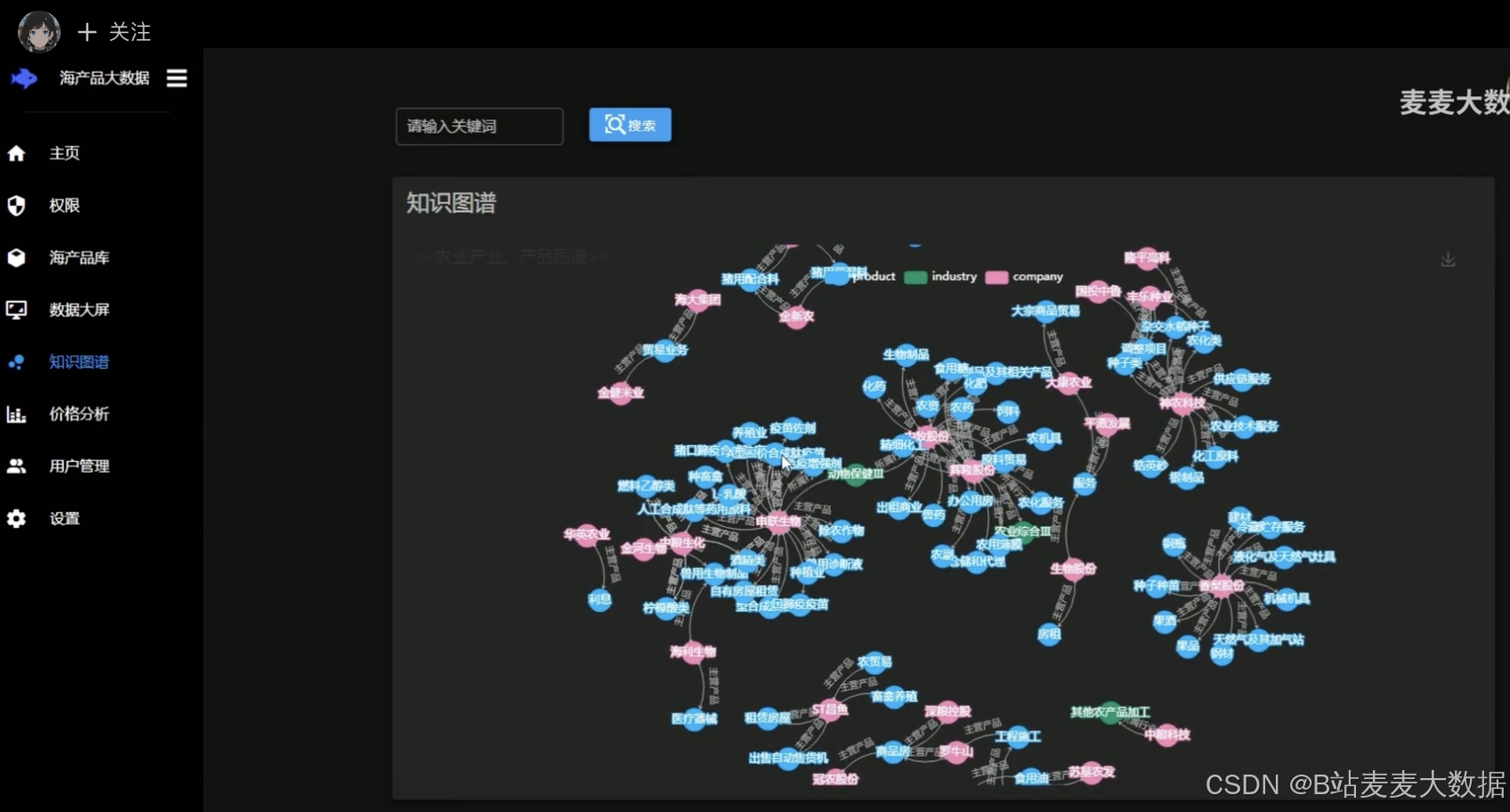
管理员可以使用权限和用户管理功能
登录、注册和个人设置
4 实现难点与解决方案
数据采集的准确性和时效性:系统通过定时任务自动采集数据,并结合人工审核机制,确保数据的准确性和更新及时。
价格预测的准确度:选择适合的多项式回归模型并进行细致的参数调优,通过历史数据训练确保预测结果的可靠性。
知识图谱的构建和应用:采用专业的农业知识进行知识图谱的构建,并通过Neo4j数据库高效管理和查询复杂的关系数据。
5 数据获取与处理
爬取数据
系统的数据采集核心依赖于对中国农产品交易信息网(pfsc.agri.cn)的实时监控与数据抓取。通过编写高效的数据爬虫程序,使用Python的requests库直接向目标网站的API发送请求,获取农产品的最新及历史价格数据。返回的数据格式为JSON,便于进一步的处理和分析。我们的数据处理流程包括数据清洗、去重、格式化,最终将整理好的数据存储到MySQL数据库中,以供后续的数据分析和价格预测使用。
此外,系统设计了一套灵活的数据更新机制,确保无需修改代码即可定期自动更新数据,并且实时展示到用户界面。这一机制不仅大大降低了系统维护的工作量,也保证了用户总能获取到最新的市场价格信息。
需要注意的是,系统中农产品的图片是我们自己去网上找之后放在系统中的,如果新增农产品,图片是需要自己去找到的。
结论
农产品价格预测系统的建立为农业生产和市场分析提供了有力的技术支持。未来,我们计划引入更多的数据源和先进的预测模型,进一步提高价格预测的准确度。同时,将探索利用机器学习和人工智能技术,优化推荐算法,提升用户个性化服务的质量。此外,系统将继续丰富知识图谱内容,拓展可视化分析功能,以满足用户更为多样化的信息需求。
(下篇))
 :哈希表(Hash Table)中的一个关键性能指标)
原理)




Digit Recognizer 手写数字识别)










:拷贝构造函数与赋值运算符重载深度解析》)
