论文阅读 | CVPR 2024 | UniRGB-IR:通过适配器调优实现可见光-红外语义任务的统一框架
- 1&&2. 摘要&&引言
- 3.方法
- 3.1 整体架构
- 3.2 多模态特征池
- 3.3 补充特征注入器
- 3.4 适配器调优范式
- 4 实验
- 4.1 RGB-IR 目标检测
- 4.2 RGB-IR 语义分割
- 4.3 RGB-IR 显著目标检测
- 4.4 消融研究
- 4.5 可视化分析
- 5 结论

题目:UniRGB-IR: A Unified Framework for Visible-Infrared
Semantic Tasks via Adapter Tuning
期刊:Computer Vision and Pattern Recognition(CVPR)
论文:paper
代码:code
年份:2024
1&&2. 摘要&&引言
由于可见光(RGB)和红外(IR)图像在低光照和恶劣天气等挑战性条件下能提供更高的准确性和鲁棒性,对它们的语义分析已受到广泛关注。
然而,由于缺乏在大规模红外图像数据集上预训练的基础模型,现有方法倾向于设计特定于任务的框架,并直接在它们的RGB-IR语义相关数据集上使用预训练的基础模型进行微调,这导致了可扩展性差和泛化能力有限的问题。
为了克服这些限制,我们提出了UniRGB-IR,这是一个用于RGB-IR语义任务的可扩展且高效的框架,它引入了一种新颖的适配器机制,能够有效地将丰富的多模态特征融入预训练的基于RGB的基础模型中。
我们的框架包含三个关键组件:一个视觉变换器(ViT)基础模型、一个多模态特征池(MFP)模块和一个补充特征注入器(SFI)模块。MFP和SFI模块相互协作作为一个适配器,有效地利用上下文多尺度特征来补充ViT特征。在训练过程中,我们冻结整个基础模型以继承先验知识,仅优化MFP和SFI模块。
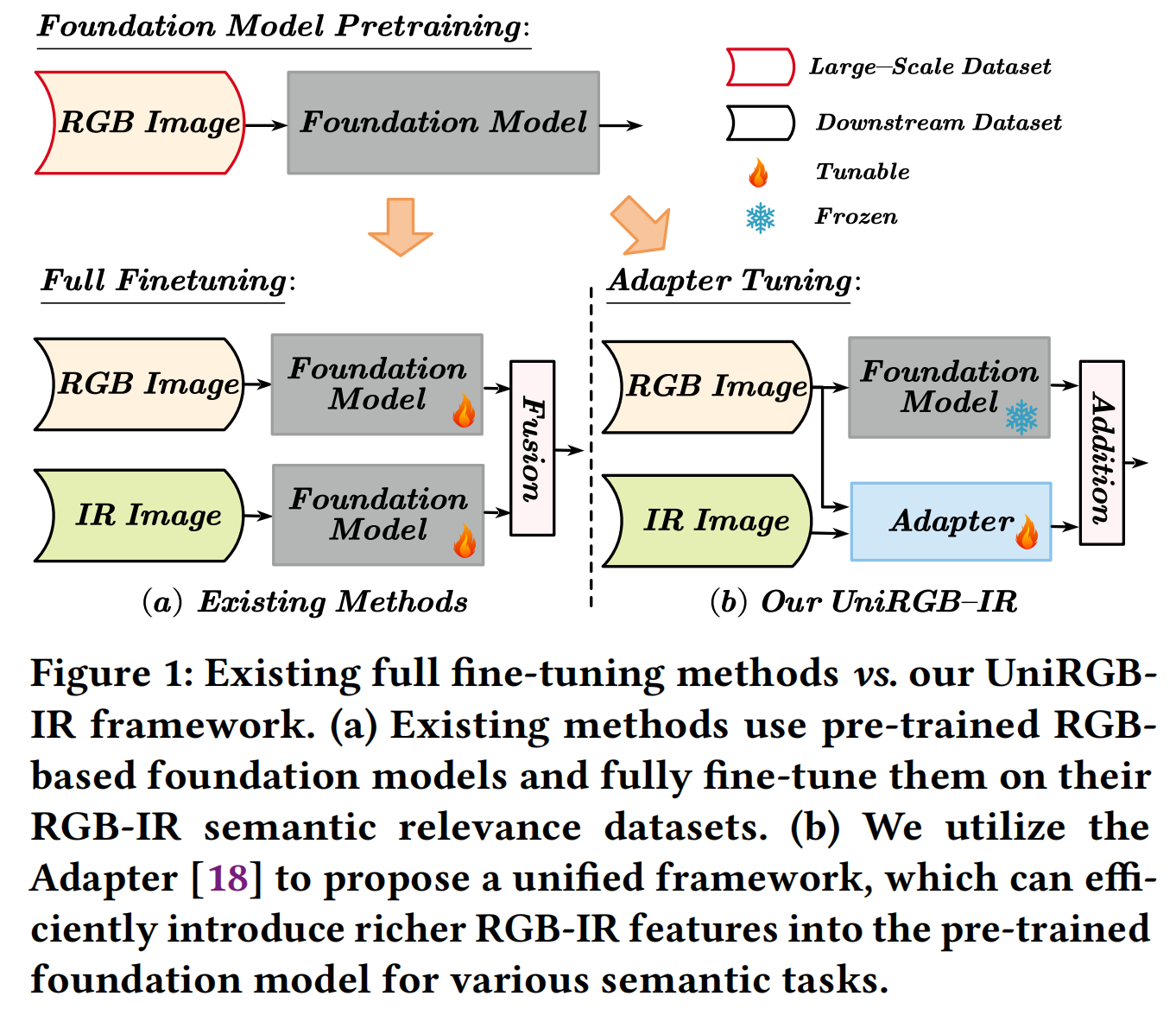
图1:现有全微调方法 vs. 我们的UniRGB-IR框架。(a) 现有方法使用预训练的基于RGB的基础模型,并在其RGB-IR语义相关数据集上对其进行全微调。(b) 我们利用适配器[18]提出一个统一框架,能够高效地将更丰富的RGB-IR特征引入预训练的基础模型,用于各种语义任务。
总体而言,我们的贡献总结如下:
- 我们探索了一个名为UniRGB-IR的可扩展且高效的框架,用于RGB-IR语义任务。据我们所知,这是首次尝试为各种RGB-IR下游任务构建统一框架。
- 我们设计了一个多模态特征池(MFP)模块和一个补充特征注入器(SFI)模块。前者从两种模态图像中提取上下文多尺度特征,后者将所需特征动态注入预训练模型。这两个模块可以通过适配器调优范式进行高效微调,以用更丰富的RGB-IR特征补充预训练的基础模型,用于特定的语义任务。
- 我们将视觉变换器基础模型纳入UniRGB-IR框架,以评估我们方法在RGB-IR语义任务上的有效性,包括RGB-IR目标检测、RGB-IR语义分割和RGB-IR显著目标检测。广泛的实验结果表明,我们的方法可以在这些下游任务上高效地实现卓越的性能。
3.方法
3.1 整体架构
UniRGB-IR 的整体框架如图 2 所示,它包含三个部分:视觉变换器 (Vision Transformer, ViT) 模型、多模态特征池 (Multi-modal Feature Pool, MFP) 模块和补充特征注入器 (Supplementary Feature Injector, SFI) 模块。
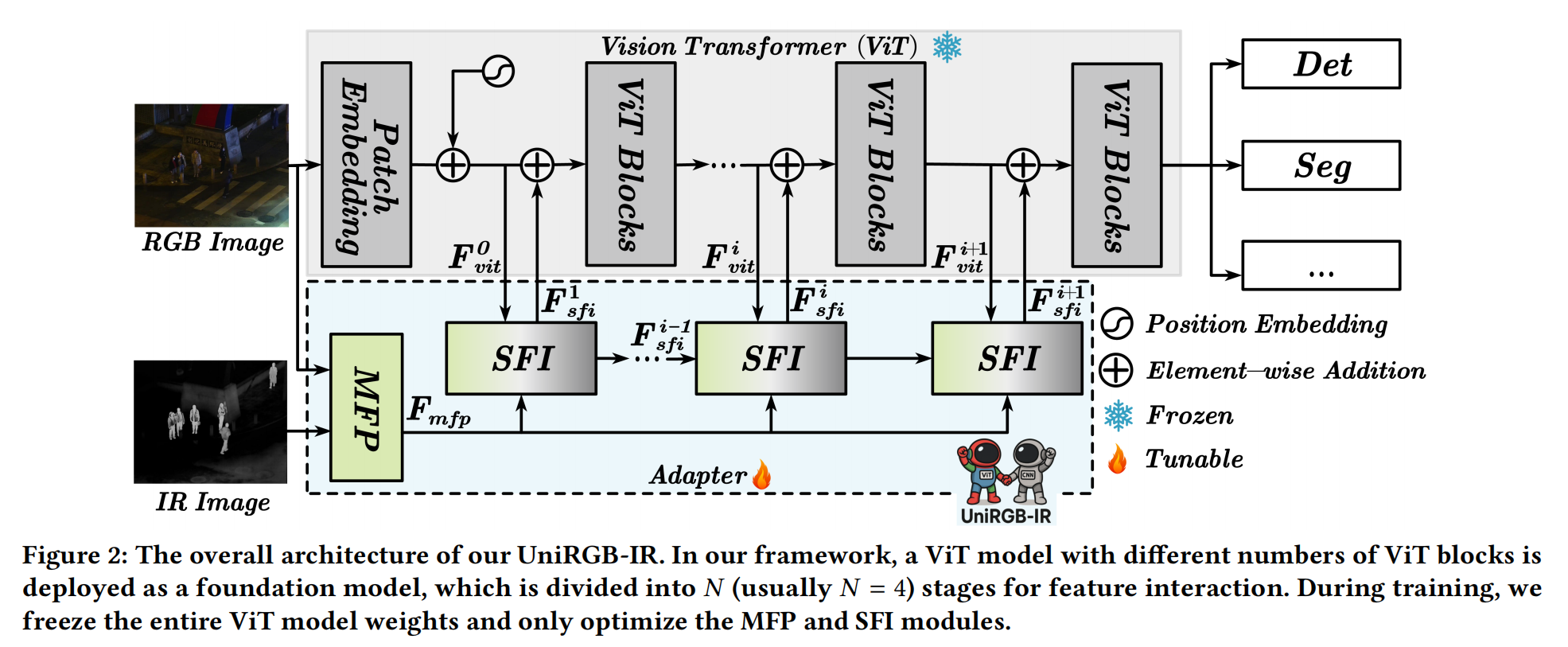
在我们的框架中,ViT 模型被用作预训练的基础模型,并在训练过程中冻结。具体来说,对于 ViT 模型,RGB 图像直接输入到块嵌入 (patch embedding) 过程中以获得 D 维特征标记 (token),其分辨率通常是原始图像的 1/16。
为了补充各种 RGB-IR 语义任务所需的更丰富特征,我们将 RGB 和 IR 图像输入到 MFP 模块中,以从两种模态中提取上下文多尺度特征(例如,原始图像分辨率的 1/8、1/16 和 1/32)。之后,这些更丰富的特征通过 SFI 模块动态注入到 ViT 模型的特征中,这可以自适应地将所需的 RGB-IR 特征引入 ViT 模型。为了将提取的特征完全集成到 ViT 模型中,我们在每个 ViT 阶段 (stage) 开始时添加一个 SFI 模块。因此,经过 N 个阶段的特征注入后,来自 ViT 模型的最终特征可以用于各种 RGB-IR 语义任务。
3.2 多模态特征池
为了补充 RGB-IR 语义任务的丰富特征表示,我们引入了多模态特征池 (MFP) 模块,包括多感知 (multiple perception) 和特征金字塔 (feature pyramid)。前者可以使用不同的卷积核提取具有长距离建模能力的上下文特征。与增加模型宽度或深度的现有工作[17,64]不同,我们在通道维度上高效地实现了多感受野感知。至于特征金字塔,它可以获得多尺度特征以增强小目标特征。因此,这两个操作串联连接以构建 MFP 模块,如图 3 所示。
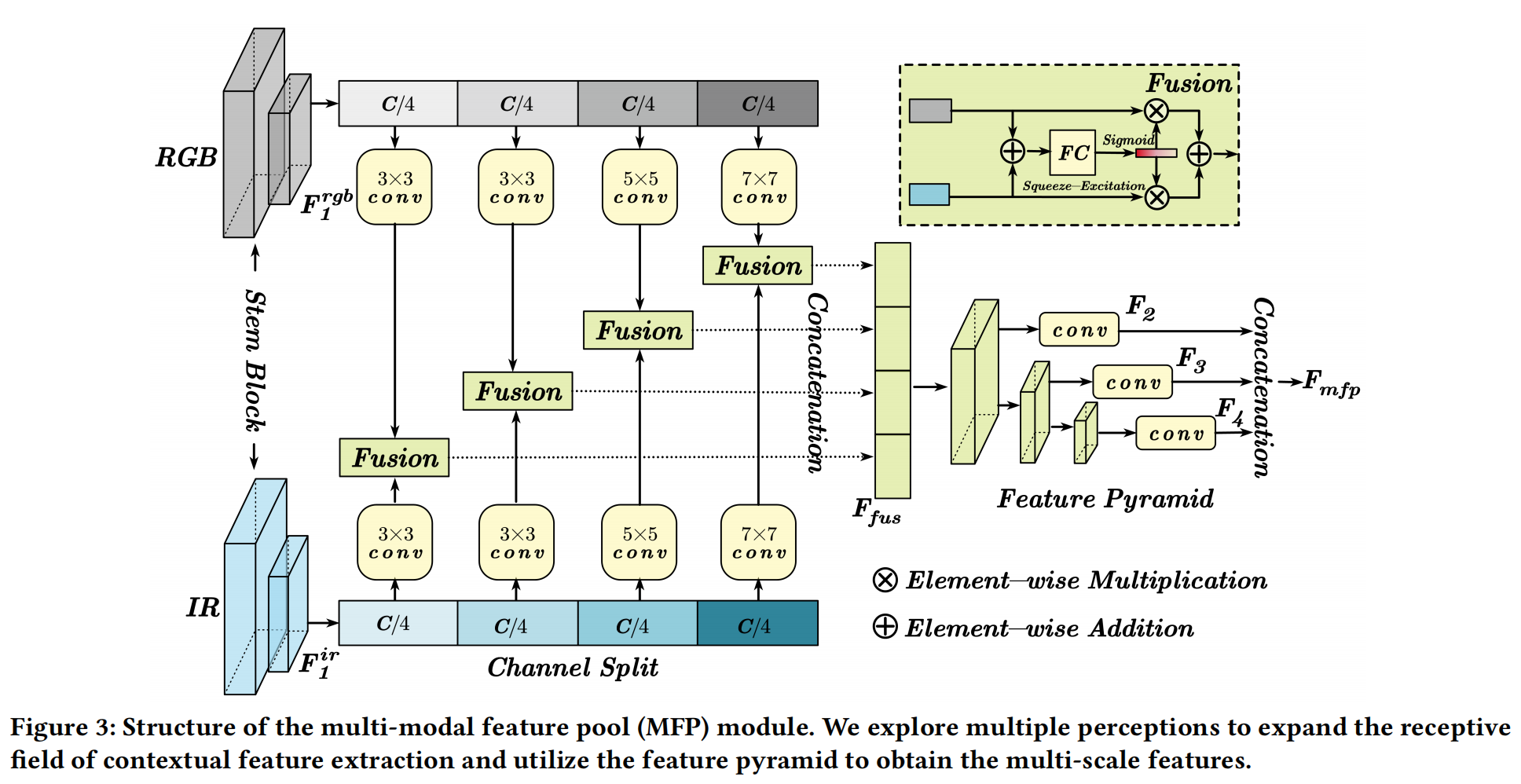
具体来说,对于输入的 RGB(H×W×3) 和 IR(H×W) 图像,我们首先使用从 ResNet[16] 借鉴的 stem 块来提取两种模态的特征 F1rgbF_{1}^{rgb}F1rgb 和 F1ir∈RH/4×W/4×CF_{1}^{ir} \in R^{H/4 \times W/4 \times C}F1ir∈RH/4×W/4×C。然后,利用通道分割 (channel splitting) 将这两个特征分成四个相等的部分。为了提取多感受野感知,每个部分都经过不同核大小(3×3, 3×3, 5×5 和 7×7)的卷积操作。然后,我们使用 SE 注意力[19](如图 3 所示)融合来自两种模态的每个处理后的特征。因此,我们连接每个融合部分以获得 RGB-IR 上下文特征 FfusF_{fus}Ffus,其公式表示为:
Ffus=Γk=14(Fus(Wkrgb∗fkrgb,Wkir∗fkir)),(1)F_{fus}=\Gamma_{k=1}^4\left(\operatorname{Fus}\left(W_k^{rgb}* f_k^{rgb}, W_k^{ir}* f_k^{ir}\right)\right),\qquad(1)Ffus=Γk=14(Fus(Wkrgb∗fkrgb,Wkir∗fkir)),(1)
其中 Ffus∈RH/4×W/4×CF_{fus} \in R^{H/4 \times W/4 \times C}Ffus∈RH/4×W/4×C, fkrgbf_k^{rgb}fkrgb 和 fkirf_k^{ir}fkir 分别是 F1rgbF_{1}^{rgb}F1rgb 和 F1irF_{1}^{ir}F1ir 特征的第 k 部分,WkW_kWk 是第 k 个核大小的卷积,Γ\GammaΓ 是连接操作,Fus(⋅,⋅)\operatorname{Fus}(\cdot,\cdot)Fus(⋅,⋅) 表示图 3 所示的融合模块。
对于特征金字塔,应用了一组三个步长 (stride)=2 的 3×3 卷积来下采样特征图的大小。然后,每个尺度的特征被输入到一个 1×1 卷积中,将特征图投影到 D 维。因此,我们可以获得一组多尺度特征 {F2,F3,F4}\{F_2, F_3, F_4\}{F2,F3,F4},其分辨率分别为原始图像的 1/8、1/16 和 1/32。最后,我们将这些特征展平 (flatten) 并连接 (concatenate) 成特征标记 Fmfp∈R(HW82+HW162+HW322)×DF_{mfp} \in R^{\left(\frac{HW}{8^{2}} + \frac{HW}{16^{2}} + \frac{HW}{32^{2}}\right) \times D}Fmfp∈R(82HW+162HW+322HW)×D,它将用作 ViT 基础模型的补充特征。
3.3 补充特征注入器
为了在不改变 ViT 结构的情况下自适应地引入上下文多尺度特征,我们提出了一个补充特征注入器 (SFI) 模块,如图 4 所示。
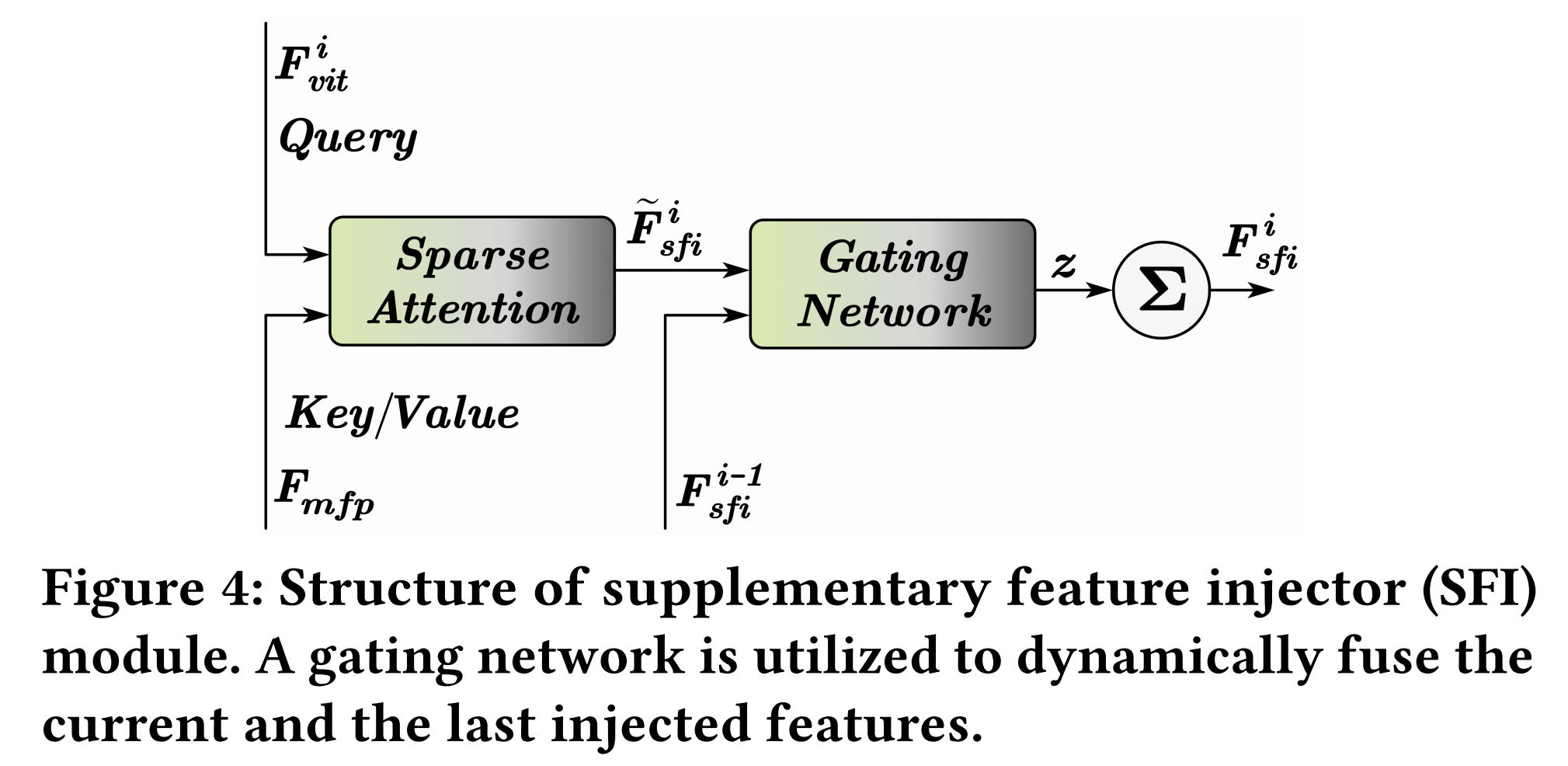
由于上下文多尺度特征 FmfpF_{mfp}Fmfp 和 ViT 特征 FvitiF_{vit}^{i}Fviti 的序列长度不同,为了解决这个问题,我们采用稀疏注意力(例如 Pale Attention[62] 和 Deformable Attention[89])来动态地从每个尺度采样补充特征。具体来说,我们利用 ViT 特征 Fviti∈RHW162×DF_{vit}^{i} \in R^{\frac{HW}{16^{2}} \times D}Fviti∈R162HW×D 作为查询 (query),利用上下文多尺度特征 Fmfp∈R(HW82+HW162+HW322)×DF_{mfp} \in R^{\left(\frac{HW}{8^{2}} + \frac{HW}{16^{2}} + \frac{HW}{32^{2}}\right) \times D}Fmfp∈R(82HW+162HW+322HW)×D 作为键 (key) 和值 (value),其可以表示为:
F~sfii=Attention(LN(Fviti),LN(Fmfp)),\tilde{F}_{sfi}^{i} = \operatorname{Attention}\left(LN\left(F_{vit}^{i}\right), LN\left(F_{mfp}\right)\right),F~sfii=Attention(LN(Fviti),LN(Fmfp)),
其中 Attention(⋅)\operatorname{Attention}(\cdot)Attention(⋅) 是稀疏注意力,LN(⋅)LN(\cdot)LN(⋅) 是 LayerNorm[1],旨在减少训练期间的模态差异。
此外,我们采用渐进式注入 (progressive injection) 来引入上下文多尺度特征,这可以平衡基础模型特征和注入的特征 F~sfii\tilde{F}_{sfi}^{i}F~sfii。因此,我们探索了一个门控网络 (gating network) 来预测融合权重 zzz,以门控 (gate) Fsfii−1F_{sfi}^{i-1}Fsfii−1 和 F~sfii\tilde{F}_{sfi}^{i}F~sfii 进行动态融合。具体来说,我们将两个特征 Fsfii−1F_{sfi}^{i-1}Fsfii−1 和 F~sfii\tilde{F}_{sfi}^{i}F~sfii 连接起来,并将其输入线性层以预测权重 zzz。然后,zzz 和 1−z1-z1−z 分别用于融合 Fsfii−1F_{sfi}^{i-1}Fsfii−1 和 F~sfii\tilde{F}_{sfi}^{i}F~sfii 特征。SFI 模块的最终输出特征 FsfiiF_{sfi}^{i}Fsfii 可以表示为:
Fsfii={F~sfii,i=1(1−z)∗F~sfii+z∗Fsfii−1,i=2…NF_{sfi}^i=\begin{cases}\tilde{F}_{sfi}^i,& i=1\\ (1-z)*\tilde{F}_{sfi}^i + z* F_{sfi}^{i-1},& i=2\ldots N\end{cases}Fsfii={F~sfii,(1−z)∗F~sfii+z∗Fsfii−1,i=1i=2…N
3.4 适配器调优范式
为了完全继承在大规模数据集上预训练的 ViT 的先验知识,我们探索了适配器调优范式 (Adapter Tuning Paradigm) 而非全微调 (Full Fine-tuning) 方式。
对于不同语义任务的数据集 D={(xj,gtj)}j=1MD=\{(x_j, gt_j)\}_{j=1}^{M}D={(xj,gtj)}j=1M,全微调过程计算预测值和真实值 (ground truth) 之间的损失,其可以表示为:
L(D,θ)=∑j=1Mloss(Fθ(xj),gtj),(4)\mathcal{L}(D,\theta)=\sum_{j=1}^{M}\operatorname{loss}\left(F_{\theta}\left(x_{j}\right), gt_{j}\right), \qquad(4)L(D,θ)=j=1∑Mloss(Fθ(xj),gtj),(4)
其中 loss\operatorname{loss}loss 表示损失函数,FθF_{\theta}Fθ 表示由 θ\thetaθ 参数化的整个网络。之后,θ\thetaθ 通过以下公式进行优化:
θ←argminθL(D,θ).(5)\theta \leftarrow \underset{\theta}{\arg\min} \, \mathcal{L}(D,\theta). \qquad(5)θ←θargminL(D,θ).(5)
然而,在我们的适配器调优范式中,参数 θ\thetaθ 由两部分组成:一部分是原始 ViT 模型中的参数 θV\theta_VθV,另一部分是我们 UniRGB-IR 中的参数 θA\theta_AθA(即 MFP 和 SFI 模块的参数)。在训练期间,我们冻结参数 θV\theta_VθV,仅优化参数 θA\theta_AθA。因此,我们的损失函数和优化可以表示为:
L(D,θV,θA)=∑j=1Mloss(FθV,θA(xj),gtj),(6)\mathcal{L}\left(D,\theta_{V},\theta_{A}\right)=\sum_{j=1}^{M}\operatorname{loss}\left(F_{\theta_{V},\theta_{A}}\left(x_{j}\right), gt_{j}\right), \qquad(6)L(D,θV,θA)=j=1∑Mloss(FθV,θA(xj),gtj),(6)
θA←argminθAL(D,θV,θA).(7)\theta_{A} \leftarrow \underset{\theta_{A}}{\arg\min} \, \mathcal{L}\left(D,\theta_{V},\theta_{A}\right). \qquad(7)θA←θAargminL(D,θV,θA).(7)
4 实验
为了评估我们提出的 UniRGB-IR 的有效性,我们利用在 COCO[34] 数据集上预训练的 ViT-Base 模型作为基础模型,并将该框架应用于执行 RGB-IR 语义任务。我们仅优化 MFP 和 SFI 模块。我们评估并比较了我们的方法与各种竞争模型,包括基于 CNN 和基于 Transformer 的模型。此外,我们的评估涵盖了多种任务,包括在 FLIR[73]、LLVIP[23] 和 KAIST[22] 数据集上的 RGB-IR 目标检测,在 PST900[47] 和 MFNet[15](见补充材料)数据集上的 RGB-IR 语义分割,以及在 VT821[57]、VT1000[54] 和 VT5000[52] 数据集上的 RGB-IR 显著目标检测。此外,还对设计的模块进行了消融实验和定性实验,以验证 UniRGB-IR 框架可以作为一个统一框架,有效地将 RGB-IR 特征引入基础模型以实现卓越的性能。
4.1 RGB-IR 目标检测
- 数据集 (Datasets):
- FLIR[73]: 这是一个配对的可见光和红外目标检测数据集,包含白天和夜间场景。它包含 4,129 个对齐的 RGB-IR 图像对用于训练,1,013 个用于测试。
- LLVIP[23]: 该数据集包含 15,488 个对齐的 RGB-IR 图像对,其中 12,025 张图像用于训练,3,463 张图像用于测试。
- KAIST[22]: 这是一个对齐的多光谱行人检测数据集,其中 8,963 个图像对用于训练,2,252 个图像对用于测试。
- 评估指标 (Metrics):
- 对于 FLIR 和 LLVIP 数据集,我们采用 平均精度均值 (mean Average Precision, mAP) 来评估检测性能。
- 对于 KAIST 数据集,我们使用在每张图像误报数 (False Positives Per Image, FPPI) 范围 [10⁻², 10⁰] 上的 对数平均漏检率 (log-average miss rate, MR⁻²) 来评估行人检测性能。
- 实验设置 (Settings):
- 所有实验均在 NVIDIA GeForce RTX 3090 GPU 上进行。
- 我们在 MMDetection 库上实现了我们的框架,并使用 Cascade R-CNN[3] 作为基本框架来执行 RGB-IR 目标检测。
- 检测器使用初始学习率为 2×10⁻⁴ 训练 48 个周期 (epoch)。
- 批量大小 (batch size) 设置为 16,使用 AdamW[41] 优化器,权重衰减 (weight decay) 为 0.1。
- 也使用了水平翻转进行数据增强。
- 结果 (Results):
- FLIR 和 LLVIP 数据集上的结果: 如表 1 所示,我们将我们的方法与五种常见的单模态方法和四种有竞争力的多模态方法进行了比较。可以看出,大多数多模态检测器甚至比单模态检测器(例如 IR 模态的 Cascade R-CNN)还要差。这是因为在有限光照条件下,RGB 特征会干扰红外特征,对用于目标检测任务的融合特征产生了负面影响。然而,我们的 UniRGB-IR 通过 SFI 模块有效地解决了这个问题,使检测器能够实现更好的分类和定位过程。我们的方法在 FLIR 和 LLVIP 数据集上均取得了最佳性能(mAP 分别为 44.1% 和 63.2%)。
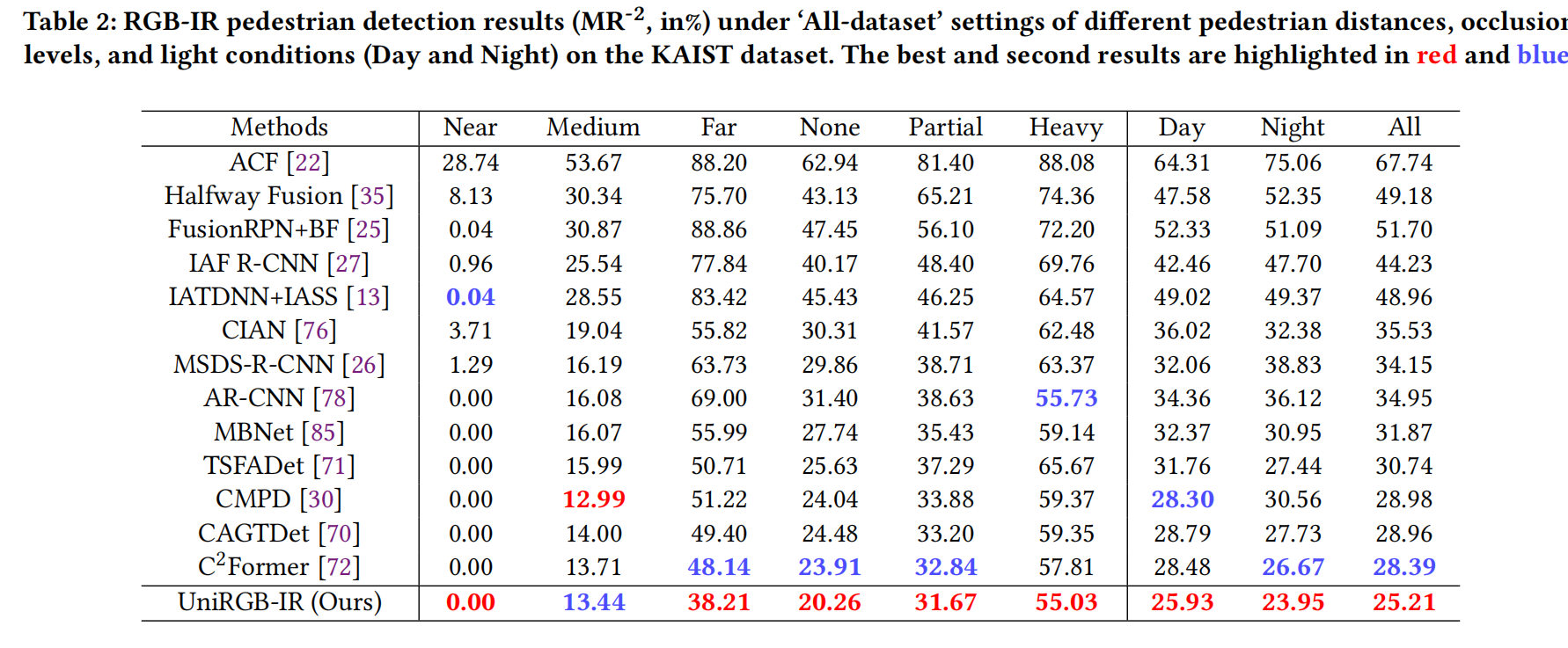
- KAIST 数据集上的结果: 表 2 展示了在 KAIST 数据集“All-dataset”设置[22]下,不同方法在不同行人距离、遮挡程度和光照条件(白天和夜晚)下的结果。我们的模型在“All”、“Day”和“Night”条件以及其他五个子集(“Near”、“Far”、“None”、“Partial”和“Heavy”)中的四个上取得了最佳性能,仅在“Medium”子集上排名第二。此外,我们的检测器在“All”条件下超越了之前的最佳竞争对手 C2Former 3.18%(MR⁻² 从 28.39% 降至 25.21%),这表明 UniRGB-IR 对复杂场景具有鲁棒性。
表 1:在 FLIR 和 LLVIP 数据集上的 RGB-IR 目标检测结果 (mAP, %)。最佳结果标红,次佳结果标蓝。“-”表示作者未提供相应结果。
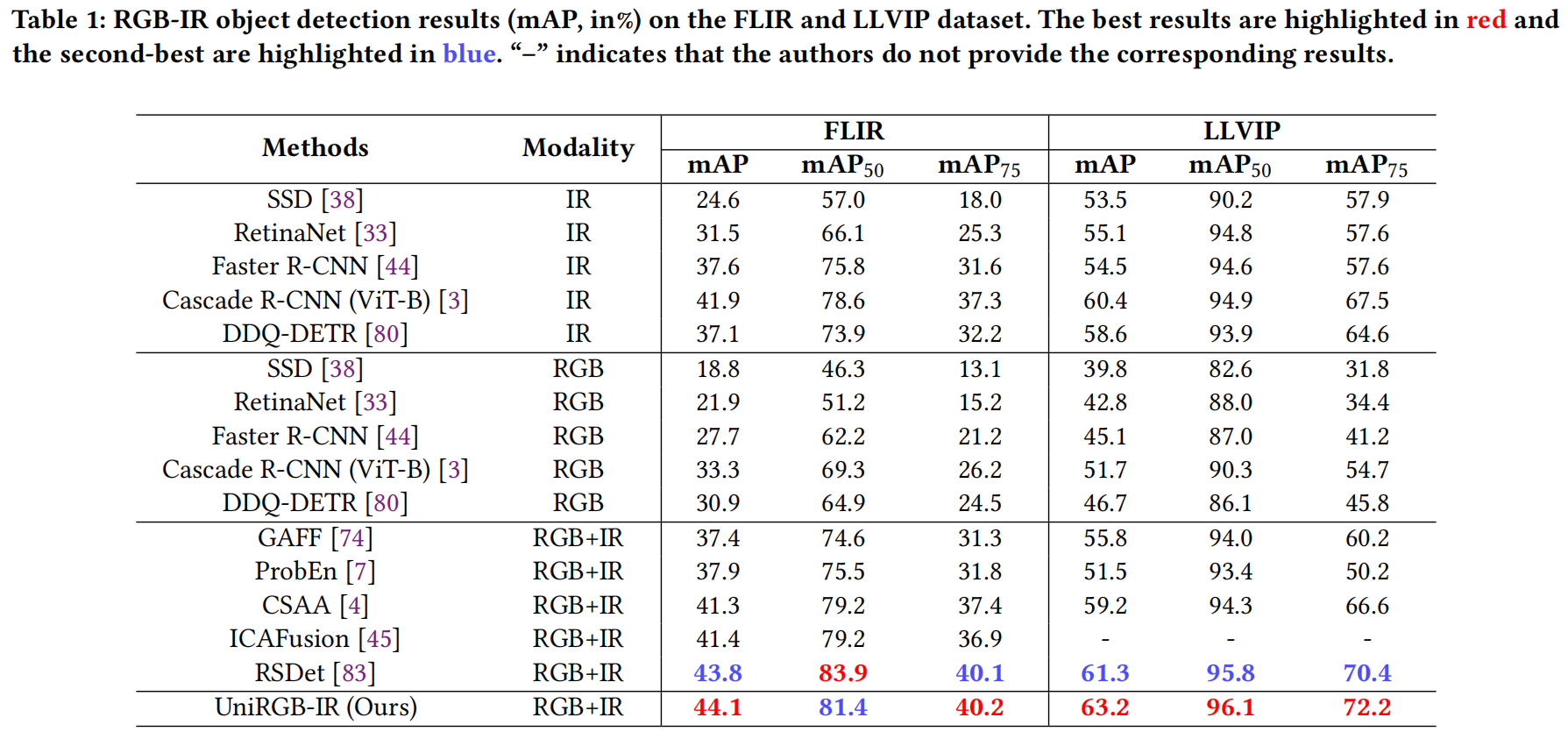
表 2:KAIST 数据集上不同距离、遮挡和光照条件下的 RGB-IR 行人检测结果 (MR⁻², %)。最佳结果标红,次佳结果标蓝。
4.2 RGB-IR 语义分割
- 数据集 (Datasets):
- PST900[47]: 该数据集包含 597 个图像对用于训练,288 个用于测试,包含五个类别(背景、灭火器、背包、手钻和幸存者)。数据集按照 2:1:1 的比例分为训练集、验证集和测试集。
- MFNet[15]: (见补充材料)。
- 评估指标 (Metrics):
- 使用两个指标评估性能:平均准确率 (mean accuracy, mAcc) 和 平均交并比 (mean Intersection over Union, mIoU)。两者都是通过平均所有类别的交集与并集的比率来计算的。
- 实验设置 (Settings):
- 与 RGB-IR 目标检测任务类似,我们将我们的方法集成到 SETR[84] 基础框架中,并在 MMSegmentation 库上实现。
- 微调过程总共进行 10K 次迭代,初始学习率为 0.01。
- 我们使用 SGD 优化器,并将批量大小设置为 16。
- 结果 (Results):
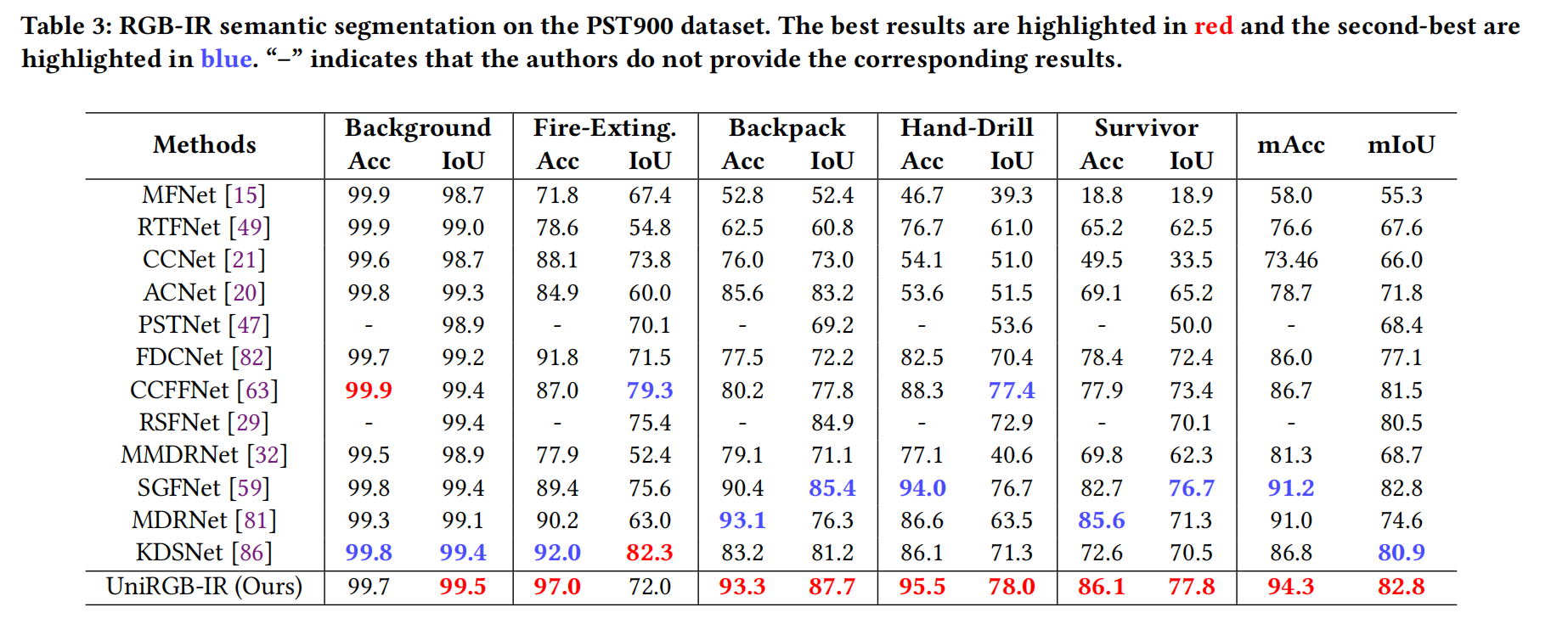
- 表 3 展示了不同 RGB-IR 分割方法在 PST900 数据集上的定量结果。结果表明,我们的模型在 mAcc 和 mIoU 方面均显著优于其他方法(分别为 94.3% 和 82.8%)。此外,我们的模型在背包 (Backpack)、手钻 (Hand-Drill) 和幸存者 (Survivor) 类别上表现出色,IoU 分别超过第二名方法 2.3%、0.6% 和 1.1%,这有力地证明了我们 UniRGB-IR 的有效性。
表 3:PST900 数据集上的 RGB-IR 语义分割结果。最佳结果标红,次佳结果标蓝。“-”表示作者未提供相应结果。
4.3 RGB-IR 显著目标检测
- 数据集 (Datasets):
- VT821[57]: 包含 821 张配准的 RGB 和 IR 图像。
- VT1000[54]: 包含 1000 张配准的 RGB-IR 图像,场景简单且图像对齐。
- VT5000[52]: 这是一个近期的大规模 RGB-IR 数据集,包含全天候各种有限光照条件下的场景。按照 [52] 中的惯例,我们使用 VT5000 数据集中的 2500 个图像对作为训练数据集,其余图像对以及来自 VT821 和 VT1000 数据集的图像对用作测试数据集。
- 评估指标 (Metrics):
- 使用四个指标评估性能:F-measure (adpF↑), E-Measure (adpE↑), S-Measure (S↑) 和 平均绝对误差 (Mean Absolute Error, MAE↓)。↑ 表示越高越好,↓ 表示越低越好。
- 实验设置 (Settings):
- 与 RGB-IR 语义分割任务相同,我们将我们的方法集成到 SETR 基础框架中,并在 MMSegmentation 库上实现。
- 微调过程总共进行 10K 次迭代,初始学习率为 0.01。
- 我们使用 SGD 优化器,并将批量大小设置为 64。
- 为方便起见,所有输入图像在测试时都调整为 224×224。
- 结果 (Results):
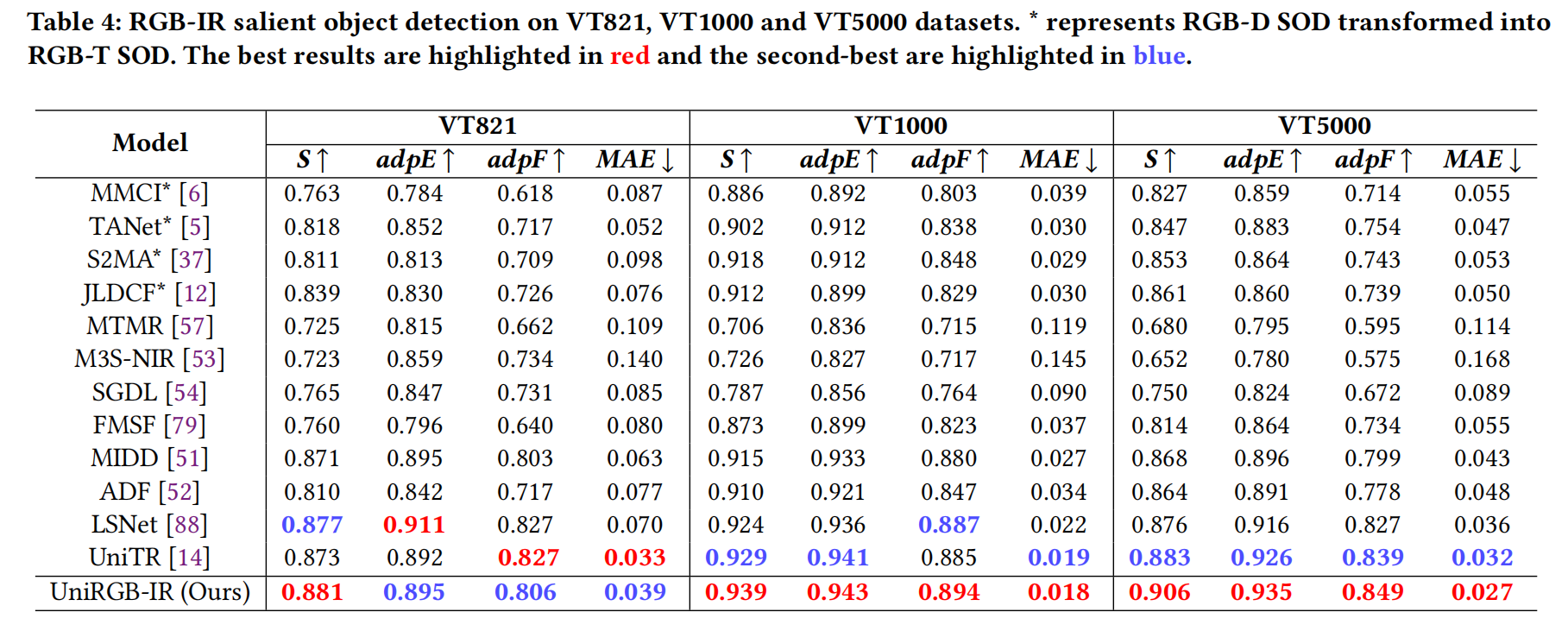
- 表 4 报告了定量比较结果。可以看出,我们的 UniRGB-IR 在 VT1000 和 VT5000 数据集上的所有评估指标均优于 SOTA 方法。具体来说,我们的 UniRGB-IR 在 VT5000 上的 S、adpE、adpF 和 MAE 指标分别达到 0.906、0.935、0.849 和 0.027,所有这些都高于之前的竞争对手 UniTR[14]。这些显著的结果清楚地表明,UniRGB-IR 预测的显著图非常接近相应的真实标注 (ground-truth)。
表 4:在 VT821、VT1000 和 VT5000 数据集上的 RGB-IR 显著目标检测结果。 表示 RGB-D SOD 转换为 RGB-T SOD。最佳结果标红,次佳结果标蓝。
4.4 消融研究
我们进行了一系列消融实验来验证我们框架中关键组件的有效性。
- 组件消融 (Ablation for components): 为了研究 SFI 和 MFP 模块的贡献,我们逐步将每个模块添加到基线模型中(仅使用堆叠的 RGB 和 IR 图像输入 Cascade R-CNN 或 SETR 进行全微调)。如表 5 所示,仅添加 MFP 模块(通过逐元素加法融合)分别带来了 1.6% mAP 和 1.3% mIoU 的提升。最后,用 SFI 模块替换逐元素加法操作进一步将 mAP 和 mIoU 指标分别提高了 2.9% 和 4.0%,在两个数据集上都取得了最佳性能。
- SFI 模块在不同阶段的添加 (SFI module at different stages): 我们在 ViT 预训练模型的不同阶段开始处添加 SFI 模块。从表 6 可以看出,在第一阶段添加 SFI 模块后,检测器在 FLIR 数据集上达到 41.7% mAP。在第二阶段和第三阶段添加 SFI 模块后,性能分别进一步提高了约 2% 和 3% mAP。然而,继续将其添加到最终阶段会降低检测性能,同时增加计算开销。因此,我们从 ViT 模型的第一阶段到第三阶段添加 SFI 模块。
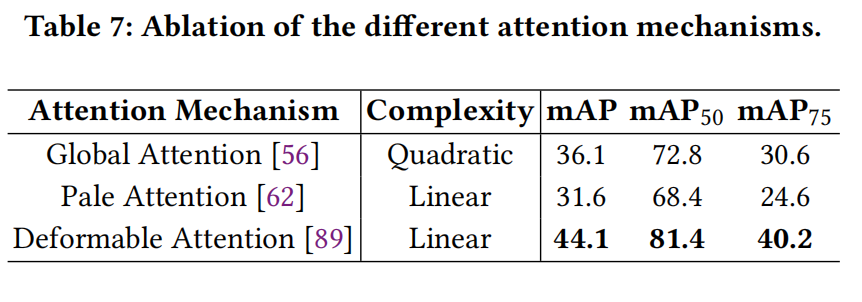
- SFI 模块中的不同注意力机制 (Attention type in SFI module): 由于我们 SFI 模块中的注意力机制是可替换的,我们在 UniRGB-IR 中采用了三种流行的注意力机制来讨论它们对模型性能的影响。如表 7 所示,通过利用可变形注意力 (deformable attention),检测器在线性复杂度下实现了最佳性能(44.1% mAP)。因此,可变形注意力更适合我们的框架,并被用作默认配置。
表 5:在 FLIR 和 PST900 数据集上关键组件的消融研究。最佳结果以粗体标出。
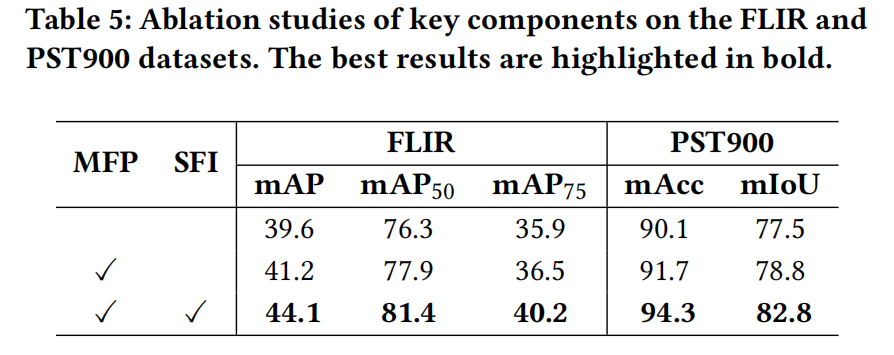
表 6:在不同阶段添加 SFI 模块的消融。

表 7:不同注意力机制的消融。
4.5 可视化分析
-
中间结果 (Intermediate results): 为了说明 SFI 模块的有效性,我们在 FLIR 数据集上可视化了中间结果。从图 5 中的 FmfpF_{mfp}Fmfp 和 FsfiF_{sfi}Fsfi 可以看出,通过 SFI 模块,FsfiF_{sfi}Fsfi 中的前景物体变得显著。此外,我们还分别可视化了 Fmfp−FvitF_{mfp}-F_{vit}Fmfp−Fvit 和 Fsfi−FvitF_{sfi}-F_{vit}Fsfi−Fvit 的 t-SNE 图。在使用 SFI 模块后,注入的特征 FsfiF_{sfi}Fsfi 的分布比 ViT 特征 FvitF_{vit}Fvit 的分布更集中,这表明所需的更丰富的 RGB-IR 特征可以通过 SFI 模块很好地补充到 ViT 模型中。
-
训练效率 (Training efficiency): 我们进一步绘制了 UniRGB-IR 在不同训练范式下每个 epoch 的 mAP 曲线,以证明 UniRGB-IR 的效率,如图 6 所示。在训练过程中,两个模型的所有超参数都相同。从图 6 可以看出,适配器调优范式的收敛速度超过了全微调策略。此外,通过利用适配器调优范式,我们的 UniRGB-IR 以更少的可训练参数(约占全微调模型的 10%)实现了卓越的性能。上述结果验证了我们方法的效率。
5 结论
在本文中,我们提出了一个用于 RGB-IR 语义任务的高效且可扩展的框架(名为 UniRGB-IR)。该框架包含一个多模态特征池(MFP)模块和一个补充特征注入器(SFI)模块。前者从两种模态图像中提取上下文多尺度特征,后者自适应地将这些特征注入到变换器模型中。这两个模块可以通过适配器调优范式进行高效优化,以用更丰富的 RGB-IR 特征补充预训练的基础模型,用于特定的语义任务。为了评估我们方法的有效性,我们将 ViT-Base 模型纳入 UniRGB-IR 框架,并在各种 RGB-IR 语义任务上进行了评估。广泛的实验结果表明,我们的 UniRGB-IR 可以有效地作为一个统一框架,用于 RGB-IR 下游任务,以实现卓越的性能。我们相信我们的方法可以应用于更多的多模态现实世界应用。








:拷贝构造函数与赋值运算符重载深度解析》)

![[ 数据结构 ] 时间和空间复杂度](http://pic.xiahunao.cn/[ 数据结构 ] 时间和空间复杂度)




)



--54-65关)