1. 基础语法
1.1. 注释
和java一样
我是单行注释
/*
我是多行注释
我是多行注释
*/
/**
* 我是文档注释
* 我是文档注释
*/1.2. 语句
语句可以不以分号结尾
一条语句独占一行
println("Hello World!")多条语句在一行
println("Hello World!"); println("Hello Scala!")1.3. 打印输出
println("123","123")同时输出多个字符串1.4. 常量
val 常量名:常量类型 = 初始值
val max_num:Int = 1001.5. 变量
var 变量名:变量类型 = 初始值
var minNum:Int = 1Int可以省略,Scala会根据变量值自动匹配类型官方推荐使用val
更安全
代码可读性更高
资源回收更快,方法执行完,val 所定义的常量就会被回收
1.6. 字符串
双引号、三引号、插值表达式
val|var 变量名 = "字符串"
val|var 变量名 = """
字符串1
字符串2
"""
val|var 变量名 = s"${变量|表达式}字符串"
val a = s"值为:${value}"1.6.1. 惰性赋值
当有一些变量保存的数据较大时,且这些数据又不需要马上加载到 JVM 内存中,就可以使用惰性赋值来提高效率
lazy val 变量名 = 表达式
lazy val sql = """
12345
12345
12345
"""
首次被使用该常量才会被加载到内存中。
println(sql)1.7. 标识符
命名规则
- 支持大小写英文字母,数字,下划线_,美元符$;
- 不能数字开头;
- 不能使用关键字;
- 遵循见名知意。
- 支持"撇撇"。
val `worker.heartbeat.interval` = 3命名规范
- 变量和方法:小驼峰,从第二个单词开始,每个单词的首字母大写。例如:maxSize、selectUserById。
- 类和特征(Trait):大驼峰,每个单词的首字母都大写。例如:UserController、WordCount。
- 包:全部小写,一般是公司或组织的域名反写,多级包之间用 . 隔开。例如:com.yjxxt.scala。
1.8. 数据类型
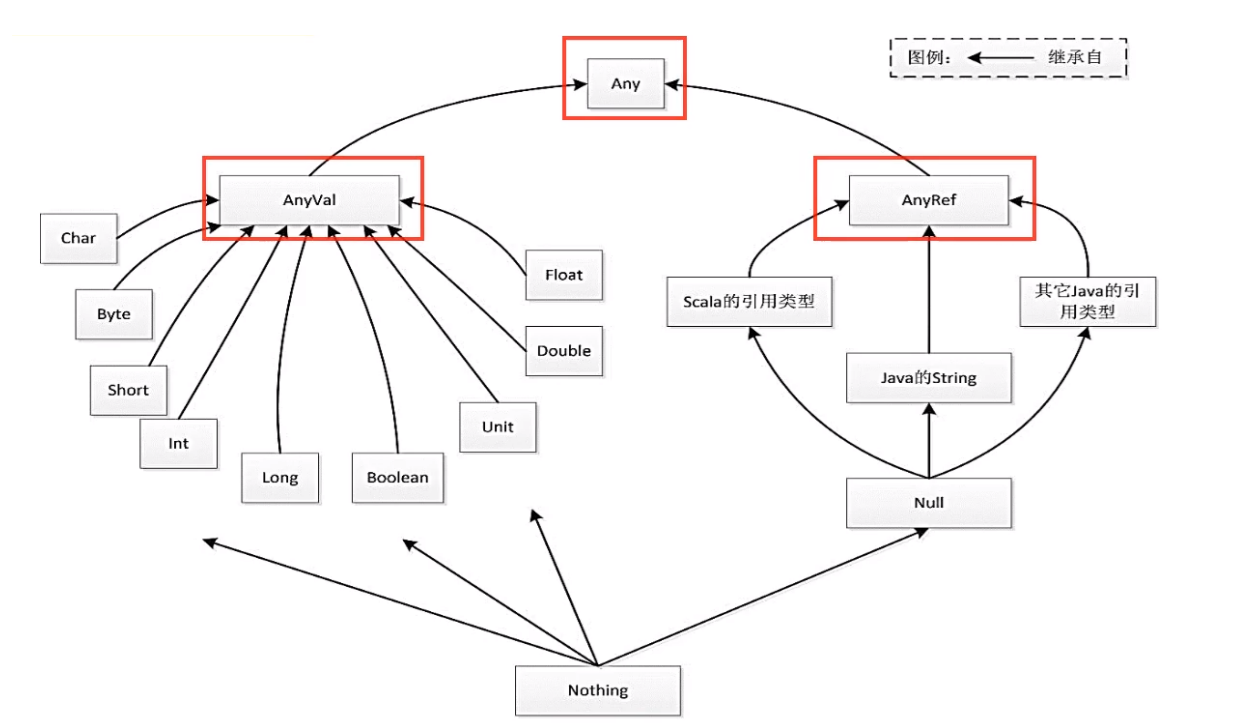
整型是Int不是Integer,Unit相当于java中的void。基本数据类型长度和java一致。
1.9. 类型转换
1.9.1. 自动类型转换(小转大)
val a:Int = 10
val b:Double = a+1.01.9.2. 强制类型转换(大转小".to类型")
使用".to类型"
val a:Double = 10.2
val b:Int = a.toInt1.9.3. String类型转换(toString)
val a:String = "10"
val b:Int = a.toString1.10. 键盘录入
- 导包: import scala.io.StdIn
- 调用方法:通过 StdIn.readXxx() 接收用户键盘录入的数据
import scala.io.StdIn
val userName = StdIn.readLine()
println(userName)1.11. 运算符
和java一样
- 算术运算符
- 赋值运算符
- 关系运算符
- 逻辑运算符
1.12. 语句块
用{}括起来的
val result = {println("这是一个语句块")1+1
}1.13. 流程控制
和java一样
- 顺序结构
- 选择结构
- 循环结构
三元表达式
val a = 10
val b:Boolean = if (a>10) true else false1.14. 循环
格式
for (i <- 表达式|数组|集合) {语句块(也叫循环体)
}守卫
在for语句中添加if语句
for(i 1 to 10 if(i%2==0)) println(i)输出2、4、6、8、10
to代表【1,10】、Until代表区间【1,10) yield生成器
将循环中的参数值返回到一个集合中
val result = for (i <- 1 to 10 if i % 2 == 0) yield ibreak和continue
break
先导包
import scala.util.control.Breaks._当 i == 5 时结束循环
breakable {
for (i <- 1 to 10) {
if (i == 5) break() else println(i)
}
}continue
先导包
import scala.util.control.Breaks._当 i == 5 时跳过当次循环,继续下一次
for (i <- 1 to 10) {
breakable {
if (i == 5) break() else println(i)
}
}区别在于结束的代码范围。
1.15. 方法
在 Scala 中,方法传参默认是 val 类型,即不可变,这意味着你在方法体内部不能改变传入的参数。这和 Scala 的设计理念有关,Scala 遵循函数式编程理念,强调方法不应该有副作用。
1.15.1. 语法格式
def 方法名(参数名:参数类型, 参数名:参数类型, ...): [返回值类型] = {语句块(方法体)
}
def addNum(a:Int, b:Int): Int = {
a + b
}方法中最后一行产生的值就是返回值,可以省略return1.15.2. 惰性方法
注意:lazy 只支持 val,不支持 var。
使用场景:
数据库连接,真正使用时才建立连接
提升程序的启动时间,将某些模块推迟执行
确保对象中的某些属性能优先初始化,对其他属性进行惰性化处理
定义方法
def addNum(a:Int, b:Int): Int = {
a + b
}惰性加载
lazy val result = addNum(2, 3)首次使用该值时,方法才会执行
println(result)默认参数
def addNum(a:Int=1,b:Int=2):Int= a+b
val a = addNum
printLn(a) 返回3带名参数
def addNum(a:Int=1,b:Int=2):Int= a+b
val a = addNum(b=5)
println(a) 返回6变长参数
def add(a:Int*):Int={a.sum}
val a = add(1,2,3,4,5)
println(a)返回15方法调用
后缀调用法
Math.abs(-1)对象.方法(参数)中缀调用法
Math max (1, 2)对象 方法 参数花括号调用法
对象.方法{语句块}
Math.abs{-1}
Math.abs {
println("求绝对值")
-1
}无括号调用法
方法是无参的
定义一个无参数的方法
def hello(): Unit = {
println("Hello World!")
}调用方法
hello1.16. 函数
在Scala函数式编程中,函数是一等公民,主要体现在:
- 函数可以存储在变量中
- 函数可以作为参数
- 函数可以作为返回值
函数式编程指的是方法的参数列表可以接收函数对象,函数式编程中的函数指的不是程序中的函数(方法),而是数学中的函数即映射关系,例如正弦函数 y=sin(x),x 和 y 的关系。
1.16.1. 定义函数
语法格式
因为函数是对象,所以函数有类型:(函数参数类型1, 函数参数类型2,...) => 函数返回值类型
val 函数名: (函数参数类型1, 函数参数类型2,...) => 函数返回值类型 = (参数名:参数类型, 参数名:参数类型, ...) => {
函数体
}注意:
- 函数的本质就是引用类型,相当于 Java 中 new 出来的实例,所以函数是在堆内存中开辟空间;
- 函数的定义不需要使用 def 关键字,但定义的函数一定要有输入和返回值,没有返回值相当于返回的是 Unit;
- 函数不建议写 return 关键字,会报错,Scala 会使用函数体的最后一行代码作为返回值;
- 因为函数是对象,所以函数有类型,但函数类型可以省略,Scala 编译期可以自动推断类型。
val addNum:(a:Int,b:Int)=>(Int) = (a:Int,b:Int)=> a+b
省略函数返回值
val addNum:(a:Int,b:Int)=>{a+b}
val result = addNum(10,20)1.16.2. 方法和函数的区别
- 方法是隶属于类或者对象的,在运行时,它会被加载到 JVM 的方法区中
- 函数是一个对象,继承自 FunctionN,函数作为对可以调用一些方法比如有 apply,curried,toString,tupled 这些方法,方法没有。
1.16.3. 方法转换成函数
val|var 变量名=方法名_
def addNum(a:Int,b:Int):Int={a+b
}
var c = addNum_
println(c(1,2))2. 面向对象
2.1. 概念
面向对象的思想是各语言共通的。
2.2. 成员属性
2.2.1. 初始化成员属性
使用 _ 初始化成员变量时,变量必须声明数据类型var address: String = _ nullvar phone: Int = _ 02.3. 成员方法
def eat(): Unit = {println("吃饭")
}
调用方法和java一致2.4. 访问权限
Scala 中的权限修饰符只有:private、private[this]、protected、默认这四种。
2.5. 构造器
主构造器
辅助构造器
2.5.1. 主构造器
class 类名(val|var 参数名:类型 = 默认值, val|var 参数名:类型 = 默认值, ...) {语句块(构造代码块)
}
- 主构造器的参数列表直接定义在类名后面,可以通过主构造器直接定义成员属性
- 构造器参数列表可以指定默认值
- 创建实例时,可以指定参数属性进行初始化
- 整个 class 中除了属性定义和方法定义的代码都是构造代码
class Student(var name:String="张三",var age:Int=18) {print("调用主构造器")}
def main(args: Array[String]): Unit = {val zhangsan = new Student();println(zhangsan.name,zhangsan.age)val lisi = new Student("李四",19)println((lisi.name, lisi.age))val wangwu = new Student(name = "wangwu")println(wangwu.name,wangwu.age)
}
2.5.2. 辅助构造器
def this(参数名:类型,参数名:类型){第一行需要调用主构造器或其他构造器辅助构造器代码
}
class Teacher {var name:String = _var age:Int = _println("主构造器")def this(name:String,age:Int){this()println("辅助构造器")this.name=namethis.age=age}val zhangsan1 = new Teacher("zhangsan", 18)println(zhangsan1.name,zhangsan1.age)2.6. 单列对象
相当于java中的静态类,比如说main方法就是在单列对象object文件中的。
单例对象除了没有构造器外,可以拥有类的所有特性。
object 单列对象名{}- 在 object 中定义的成员属性类似于 Java 的静态属性,在内存中都只有一个
- 在单例对象中,可以直接使用 单列对象名. 的形式调用成员
- 在单例对象中定义的成员方法类似于 Java 中的静态方法。
object objectDemo{var str = "这是scala的静态属性"def func()=println("这是scala的静态方法")def main(args: Array[String]): Unit = {println(objectDemo.str)}
}2.7. 伴生对象
2.7.1. 定义半生对象
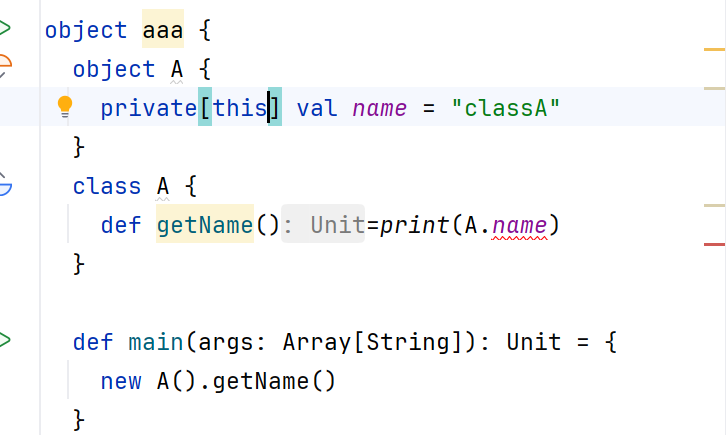
在同一个scala文件中,class和object名字一样时,object称为伴生对象,class称为伴生类。他们可以互相访问彼此的private私有属性。
object aaa {object A {private val name = "classA"}class A {def getName()=print(A.name)}def main(args: Array[String]): Unit = {new A().getName()}2.7.2. private[this]权限
该权限下伴生对象和类的属性不可相互访问
2.7.3. apply方法
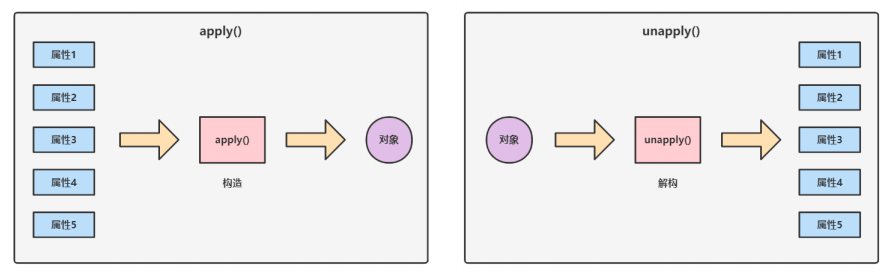
通过伴生对象的apply方法可以在创建对象的时候省去new关键字
object 伴生对象名{def apply(参数名:Int,参数名:String...) = new 类(参数1,参数2...)
}
val 对象名 = 伴生对象名(参数1,参数2...)2.8. 继承
基本和java一样
object|class 子 extends 父{}2.8.1. 方法重写
override def 父类方法()={} 需要通过override关键字重写2.8.2. 类型判断、转换
判断对象是否为指定类型
val trueOrFalse:Boolean = 对象.isInstanceOf[类]将对象转换为指定类型
val 变量 = 对象.asInstanceOf[类型]2.9. 抽象类
抽象属性:没有初始化值的变量就是抽象属性
抽象方法:没有方法体的方法就是抽象方法
abstract class 抽象类名{val |var 抽象属性名:类型def 方法名(参数:类型,参数:类型):返回值类型
}2.10. 匿名类
当对象方法仅调用一次的时候
作为方法的参数进行传递时
new 类名{重写父类中所有的抽象内容
}
object Hello {abstract class Hi {def sayHi(str:String) = println(str)}def main(args: Array[String]): Unit = {new Hi{
override def sayHi(str: String): Unit =println(str)}.sayHi("你好呀")}2.11. 特质
相当于java中的接口
特质可以提高代码的扩展性和可维护性
类与特质之间是继承关系,只不过类与类之间只支持单继承,但是类与特质之间可以多继承
特质中可以有具体的属性、抽象属性、具体的方法以及抽象方法
瘦接口:只有抽象内容
胖接口:有抽象内容和具体内容
trait 特质名称{具体属性抽象属性具体方法 抽象方法
}继承特质
class|trait|object A extends 特质B with 特质C
trait aobject b extends aclass c extends atrait d extends a2.12. 对象混入
对对象的功能进行临时增强或者扩展,通过特定的关键字,却可以让该类的对象具有指定特质中的成员。
val|var 对象名 = new 类 with 特质val user = new User with Logger {override def log(msg: String): Unit = println(msg)
}
trait Logger {定义抽象方法def log(msg: String): Unit定义具体方法def info(msg: String): Unit = log(s"INFO: ${msg}")}类和 Logger 特质之间无任何关系class User {}2.13. 包
package com.yjxxt.packagespackage com.yjxxt
package packagespackage com.yjxxt {package packages {这里写类,特质等}
}3. 高阶函数

函数可以存储在变量中;函数可以作为参数;函数可以作为返回值。
分类
- 回调函数(Callback Function)
- 偏应用函数(Partial Applied Function)
- 柯里化函数(Currying Function)
- 闭包函数(Closure Function)
- 函数作为参数
- 函数作为返回值
- 匿名函数(Anonymous Function)
- 递归函数(Recursive Function)
3.1. 基本使用
函数是引用数据类型,相当于new实例,在堆中开辟空间
函数的定义不需要使用 def 关键字,但定义的函数一定要有输入和返回值,没有返回值相当于返回的是 Unit;
函数不建议写 return 关键字,Scala 会使用函数体的最后一行代码作为返回值;
因为函数是对象,所以函数有类型,但函数类型可以省略,Scala 编译期可以自动推断类型;
调用函数其实是调用函数里面的 apply 方法来执行逻辑。
def main(args: Array[String]): Unit = {函数最完整写法val func1:(Int,Int)=>Int = (a:Int,b:Int)=>{a+b}参数部分不写返回值参数类型如果能够推断出来,那么可以省略val func2:(Int,Double)=>Double = (a,b)=>{a+b}如果函数体只有一行代码,可以省略花括号 {}val func3:(Int,Double)=>Double = (a,b)=>a+b函数类型可以省略,Scala 编译期可以自动推断类型因为省略了函数类型,所以参数类型就无法推断了,这时参数必须声明类型val func4=(a:Int,b:Int)=>a+b使用 Function1 特质声明带一个参数的方法时,需要两个参数第一个是入参的数据类型,第二个是返回值的数据类型val func5:Int=>Int = new Function[Int,Int]{使用 Function1 特质,必须重写 apply 接口
override def apply(x: Int): Int = x+1}使用 Function2 特质声明带一个参数的方法时,需要三个参数前两个是入参的数据类型,第三个是返回值的数据类型val func6=new Function2[Int,Double,(Double,Int)] {
override def apply(v1: Int, v2: Double): (Double, Int) = (v1,v2)}使用 Function2 特质,必须重写 apply 接口val func7 = new ((Int,Double)=>(Double,Int)){
override def apply(v1: Int, v2: Double): (Double, Int) = v1+v2}使用 Function2 特质,必须重写 apply 接口}3.2. 至简原则
优雅
方法和函数不建议写 return 关键字,Scala 会使用函数体的最后一行代码作为返回值;
方法的返回值类型如果能够推断出来,那么可以省略,如果有 return 则不能省略返回值类型,必须指定;
因为函数是对象,所以函数有类型,但函数类型可以省略,Scala 编译期可以自动推断类型;
如果方法明确声明了返回值为 Unit,那么即使方法体中有 return 关键字也不起作用;
如果方法的返回值类型为 Unit,可以省略等号 = ;
如果函数的参数类型能够推断出来,那么可以省略;
如果方法体或函数体只有一行代码,可以省略花括号 {} ;
如果方法无参,但是定义时声明了 () ,调用时小括号 () 可省可不省;
如果方法无参,但是定义时没有声明 () ,调用时必须省略小括号 () ;
如果不关心名称,只关心逻辑处理,那么函数名可以省略。也就是所谓的匿名函数;
如果匿名函数只有一个参数,小括号 () 和参数类型都可以省略,没有参数或参数超过一个的情况下不能省略 () ;
如果参数只出现一次,且方法体或函数体没有嵌套使用参数,则参数可以用下划线 _ 来替代。
def main(args: Array[String]): Unit = {方法和函数不建议写 return 关键字,Scala 会使用函数体的最后一行代码作为返回值;def method1(x:Int,y:Double):Double={x+y}val func1:(Int,Double)=>Double = (a:Int,b:Double)=>{a+b}println(method1(1,2.2),func1(2,2.2))方法的返回值类型如果能够推断出来,那么可以省略,如果有 return 则不能省略返回值类型,必须指定;def method2(a:Int,b:Double){a+b}推断的出def method3(a:Int,b:Double):Double={return a+b}因为函数是对象,所以函数有类型,但函数类型可以省略,Scala 编译期可以自动推断类型;val func2=(a:Int,b:Double)=>{a+b}如果方法明确声明了返回值为 Unit,那么即使方法体中有 return 关键字也不起作用;def method4(a:Int,b:Double):Unit={return a+b}println(method4(1,2.1)) 无返回如果方法的返回值类型为 Unit,可以省略等号 = ;def method5(a:Int,b:Double){a+b}println(method5(2,2.2)) 无返回值可以不写,不写的话,即便方法体有内容也不会返回如果函数的参数类型能够推断出来,那么可以省略;val func3:(Int,Double)=>Double=(a,b)=>a+bprintln(func3(1,1.2))如果方法体或函数体只有一行代码,可以省略花括号 {} ;val func4=(a:Int,b:Double)=>a+bdef method6(a:Int,b:Double):Double=a+bprintln(func4(1,1.1),method6(2,2.2))如果方法无参,但是定义时声明了 () ,调用时小括号 () 可省可不省;def method7()=println("无参有括号")method7()method7如果方法无参,但是定义时没有声明 () ,调用时必须省略小括号 () ;def method8 {println("无参无括号")}method8如果不关心名称,只关心逻辑处理,那么函数名可以省略。也就是所谓的匿名函数;val list =( 1 to 10).toListval list1 = list.map((a) => {
a + 2})如果匿名函数只有一个参数,小括号 () 和参数类型都可以省略,没有参数或参数超过一个的情况下不能省略 () ;val list2 = list.map(a => a + 2)如果参数只出现一次,且方法体或函数体没有嵌套使用参数,则参数可以用下划线 _ 来替代。val list3 = list.map(_ + 2)val i1 = list.reduce((x, y) => x + y)val i = list.reduce(_ + _)}3.3. 函数作为参数
val str= a =>"*"*a
val list = (1 to 10).toList
极简写法相当于list.map(x=>str(x))
val strings:List[String] = list.map(str)
println(strings)3.4. 函数作为返回值
def func1():(Int,Double)=>Double={
def func2(x:Int,y:Double):Double={x+y
}
func2}println(func1()(2,3.0))func1()(2, 3.0) :调用func1();返回func2拼接上(2,3.0) 就得到f(2, 3.0)。}4. 集合

Scala 同时支持不可变集合和可变集合,因为不可变集合可以安全的并发访问,所以它也是默认使用的集合类库。在Scala 中,对于几乎所有的集合类,都提供了可变和不可变两个版本,具体如下:
不可变集合:集合内的元素、长度一旦初始化完成就不可再进行更改,任何对集合的改变都将生成一个新的集合。不可变集合都在 scala.collection.immutable 这个包下,使用时无需手动导包。
可变集合:指的是这个集合本身可以动态改变,且可变集合提供了改变集合内元素的方法。可变集合都在scala.collection.mutable 这个包下,使用时需要手动导包。
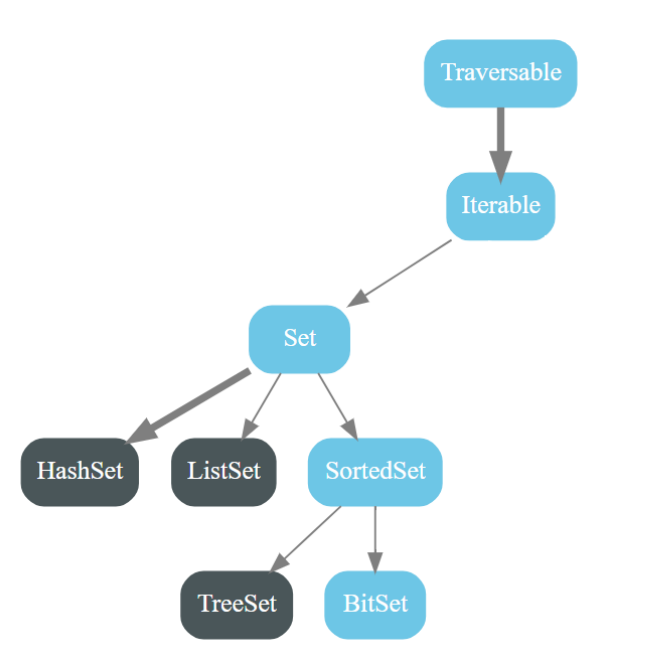
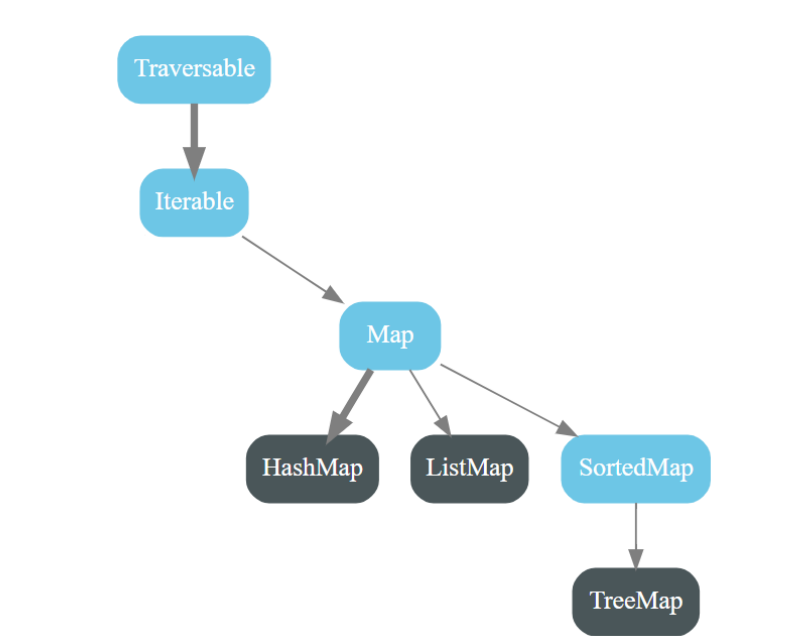
4.1. 结构树
蓝色为特质(接口),黑色为实现类
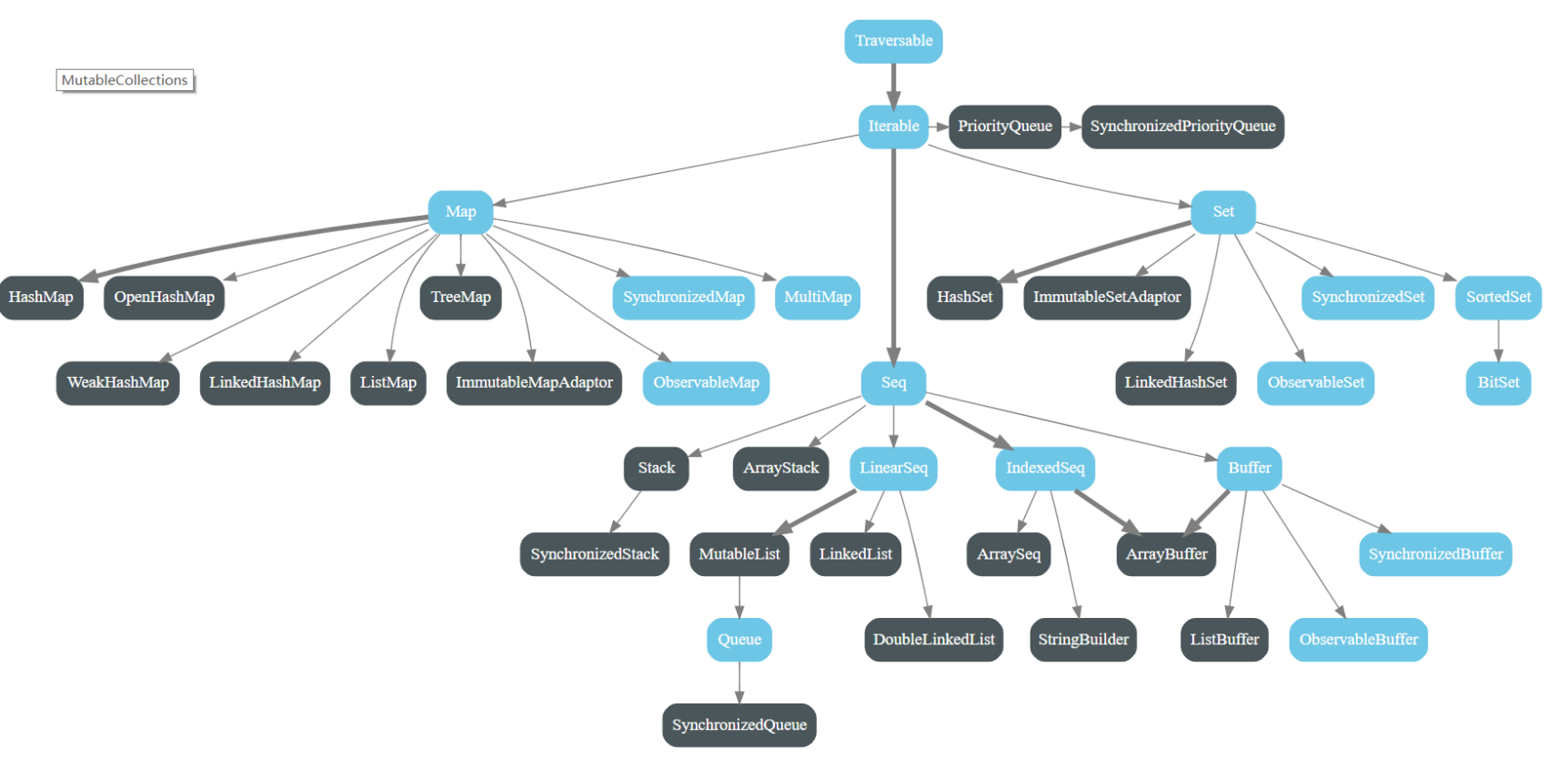
4.2. Traversable
4.2.1. 语法格式
创建空的Traversaleval t1 = Traversable.empty[Int]val t2 = Traversable[Int]()val t3 = Nil创建带元素的Traversable对象val t4 = List(1,2,3).toTraversable List为默认实现类val t5=Array(1,2,3).toTraversableval t6 = Set(1,2,3).toTraversable通过Traversable伴生对象apply方式实现val t7 = Traversable(1,2,3)4.2.2. 转置集合transpose
val t8 = Traversable(Traversable(1,2,3),Traversable(4,5,6),Traversable(7,8,9))val result1 =t8.transposeprintln(result1)List(List(1, 4, 7), List(2, 5, 8), List(3, 6, 9))4.2.3. 拼接集合 Traversable.concat(x,x,x)
已知有三个 Traversable 集合,分别存储 (11, 22, 33), (44, 55), (66, 77, 88, 99) 元素通过 concat 方法拼接上述三个集合将拼接后的结果打印到控制台val t9 = List(11,22,33).toTraversableval t10 = List(44,55).toTraversableval t11 = Traversable(66,77,88,99)val result2 = Traversable.concat(t9,t10,t11)println(result2)List(11, 22, 33, 44, 55, 66, 77, 88, 99)拼接成一个集合4.2.4. 计算阶乘scan(1)(_*_)
val t12 = Traversable(1,2,3,4,5)val result3 = t12.scan(1)(_*_)scan(1)代表起始值为1完整scan(1)((x:Int,y:Int)=>x*y)println(result3)List(1, 1, 2, 6, 24, 120)1*1 1*2 2*3 6*4 24*5从左往右val result4 = t12.scanLeft(1)(_*_)从右往左val result5 = t12.scanRight(1)(_*_)4.2.5. 获取元素
head :获取集合的第一个元素,如果元素不存在,则抛出 NoSuchElementException 异常
last :获取集合的最后一个元素,如果元素不存在,则抛出 NoSuchElementException 异常
headOption :获取集合的第一个元素,返回值类型是 Option
lastOption :获取集合的最后一个元素,返回值类型是 Option
find :查找集合中第一个满足指定条件的元素
slice :根据起始值,截取集合中的一部分元素(左闭右开)
需求:
定义一个 Traversable 集合,包含 1, 2, 3, 4, 5, 6
分别通过 head、last、headOption、lastOption 获取集合中的首尾元素
通过 find 方法获取集合中第一个偶数
通过 slice 方法获取 3, 4, 5 并将它们放到一个新的 Traversable 集合
val t13 = Traversable(1,2,3,4,5,6)println(t13.head,t13.last,t13.headOption.getOrElse(0),t13.lastOption.getOrElse(0))getOrElse(0)如果不存在就返回0(1,6,Some(1),Some(6))val result6= t13.find(_ % 2 == 0)(x)=>{x%2==0}println(result6)Some(2)val result7=t13.slice(2,5)println(result7)List(3, 4, 5)4.2.6. 判断元素是否符合条件forall、exists
def forall(p: (A) => Boolean): Boolean
如果集合中所有元素都满足指定的条件则返回 true,否则返回 false
def exists(p: (A) => Boolean): Boolean
只要集合中任意一个元素满足指定的条件就返回 true,否则返回 false
需求:
定义一个 Traversable 集合,包含 1, 2, 3, 4, 5, 6
通过 forall 方法判断集合中的元素是否都是偶数
通过 exists 方法判断集合中的元素是否有偶数
val t14 = Traversable(1,2,3,4,5,6)val result8 = t14.forall(_%2==0)val result9 = t14.exists(_%2==0)println(result8,result9)(false,true)4.2.7. 聚合操作
count :统计集合中满足条件的元素个数
sum :获取集合中所有的元素和
product :获取集合中所有的元素乘积
max :获取集合中所有元素的最大值
min :获取集合中所有元素的最小值
需求:
定义一个 Traversable 集合,包含 1, 2, 3, 4, 5, 6
通过 count 方法统计集合中所有奇数的个数
通过 sum 方法获取集合中所有元素的和
通过 product 方法获取集合中所有元素的乘积
通过 max 方法获取集合中所有元素的最大值
通过 min 方法获取集合中所有元素的最小值
val t15 = Traversable(1,2,3,4,5,6)val result10 = t15.count(_%2==1)val result11 = t15.sumval result12 = t15.productval result13 = t15.maxval result14 = t15.minprintln(result10,result11,result12,result13,result14)(3,21,720,6,1)4.2.8. 类型转换 toXxx()
toXxx() 方法(toList, toSet, toArray, toSeq 等)。
需求:
定义一个 Traversable 集合,包含 1, 2, 3, 4, 5, 6
将集合分别转成数组、列表、集这三种形式,并打印结果
val t16 = Traversable(1,2,3,4,5,6)val resultArray = t16.toArrayval resultList = t16.toListval resultSet = t16.toSetprintln(resultArray,resultList,resultSet)([I@57855c9a,List(1, 2, 3, 4, 5, 6),Set(5, 1, 6, 2, 3, 4))4.2.9. 填充元素fil、iterate、range
fill :快速生成指定数量的元素,并放入集合中
iterate :根据指定的条件,生成指定数量的元素,并放入集合中
range :生成某个区间内指定间隔的元素,并放入集合中,左闭右开
需求:
通过 fill 方法,生成一个 Traversable 集合,该集合包含 5 个元素,都是"abc"
通过 fill 方法,生成一个 Traversable 集合,该集合包含 3 个随机数
通过 fill 方法,生成一个 Traversable 集合,该集合包含 5 个元素,都是 List("abc", "abc") 集合
通过 iterate 方法,生成一个 Traversable 集合,该集合包含 5 个元素,分别为:1, 10, 100, 1000, 10000
通过 range 方法,获取从数字 1 开始到数字 21 结束,间隔为 5 的所有数据
println(Traversable.fill(5)("abc"))List(abc, abc, abc, abc, abc)println(Traversable.fill(3)(Random.nextInt(100)))一百以内的随机整数List(62, 71, 37)println(Traversable.fill(5,2)("abc"))5 表示生成的集合中有 5 个集合元素,2 表示每个集合元素的长度为 2List(List(abc, abc), List(abc, abc), List(abc, abc), List(abc, abc), List(abc, abc))println(Traversable.iterate(1,5)(x=>x*10))List(1, 10, 100, 1000, 10000)println(Traversable.range(1,21,5))左闭右开List(1, 6, 11, 16)4.3. Iterable
4.3.1. 遍历
Traversable 提供了两种遍历数据的方式:
通过 iterator() 方法实现,迭代访问元素。这种方式属于主动迭代,可以通过 hasNext() 检查是否还有元素,且可以主动的调用 next() 方法获取元素。即:我们可以自主控制迭代过程。
通过 foreach() 方法实现,遍历访问元素。这种方式属于被动迭代,只需要提供一个函数,并不能控制遍历的过程。即:迭代过程是由集合本身控制的。
需求:
定义一个 Traversable 集合,包含 1, 2, 3, 4, 5
通过 iterator() 方法遍历上述列表
通过 foreach() 方法遍历上述列表
val t17 = Traversable(1,2,3,4,5,6)val iterator: Iterator[Int] = t17.toIteratorwhile(iterator.hasNext){print(iterator.next())}123456println()val result15 = t17.foreach(print)foreach(x=>println(x))123456println()4.3.2. 分组遍历grouped(n)
def grouped(size: Int): Iterator[Ierable[A]]
需求:
定义一个 Iterable 集合,存储 1~13 之间的所有整数
通过 grouped() 方法,对 Iterator 集合按照 5 个元素为一组的形式进行分组,遍历并打印结果
val t18= (1 to 13).toIterable
val result16 = t18.grouped(5)每组5个result16.foreach(print(_))Vector(1, 2, 3, 4, 5)Vector(6, 7, 8, 9, 10)Vector(11, 12, 13)println()4.3.3. 按索引生成元组zipWithIndex
需求:
定义一个 Iterable 集合,存储 "A", "B", "C", "D", "E"
通过 zipWithIndex() 方法按照 字符串 -> 索引 生成新的集合
将上一步结果通过 map() 方法再按照 索引 -> 字符串 生成新的集合
val t19 = ('A' to 'E').toIterableval result17 = t19.zipWithIndexprintln(result17)Vector((A,0), (B,1), (C,2), (D,3), (E,4))val result18 = result17.map(x=>x._1->x._2)println(result18)Vector((A,0), (B,1), (C,2), (D,3), (E,4))4.3.4. 判断集合是否相同x.sameElements(y)
需求:
定义 Iterable 集合 iter1,包含 "A", "B", "C"
通过 sameElements() 方法,判断集合 iter1 和 Iterable("A", "B", "C") 是否相同
通过 sameElements() 方法,判断集合 iter1 和 Iterable("A", "C", "B") 是否相同
定义 Iterable 集合 iter2,包含 "A", "B", "C", "D"
通过 sameElements() 方法,判断集合 iter1 和 iter2 是否相同
思考:HashSet(1, 5, 2, 3, 4) 和 TreeSet(2, 1, 4, 3, 5) 是否相同?
val t20 = Iterable("A" ,"B", "C")通过 sameElements() 方法,判断集合 iter1 和 Iterable("A", "B", "C") 是否相同println(t20.sameElements(Iterable("A", "B", "C"))) true
通过 sameElements() 方法,判断集合 iter1 和 Iterable("A", "B", "C") 是否相同println(t20.sameElements(Iterable("A", "C", "B"))) false
定义 Iterable 集合 iter2,包含 "A", "B", "C", "D"val iter2 = Iterable("A", "B", "C", "D")
通过 sameElements() 方法,判断集合 iter1 和 iter2 是否相同println(t20.sameElements(iter2)) false
思考:HashSet(1, 5, 2, 3, 4) 和 TreeSet(2, 1, 4, 3, 5) 是否相同?println(mutable.HashSet(1, 5, 2, 3, 4).sameElements(mutable.TreeSet(2, 1, 4, 3, 5)))truefalsefalsetrue4.3.5. Seq
4.3.6. Set
HashSet:HashSet 是基于 HashMap 实现的,对 HashMap 做了一层简单的封装,而且只使用了HashMap 的 Key 来实现各种特性。元素特点唯一、无序。
ListSet:元素特点唯一、有序(元素添加的顺序)。
TreeSet:元素特点唯一、排序(按自然顺序排序)。
需求:
创建 HashSet 集合,存储元素 1, 4, 3, 2, 5, 5,然后打印集合
创建 ListSet 集合,存储 1, 4, 3, 2, 5, 5,然后打印集合
创建 SortedSet 集合,存储元素 1, 4, 3, 2, 5, 5,然后打印集合
val hashSet1 = HashSet(1,4,3,2,5,5)val listSet1 = ListSet(1,4,3,2,5,5)val sortSet1 = SortedSet(1,4,3,2,5,5)println(hashSet1,listSet1,sortSet1)(Set(5, 1, 2, 3, 4),ListSet(1, 4, 3, 2, 5),TreeSet(1, 2, 3, 4, 5))4.3.7. Map
HashMap:元素特点 Key 唯一、无序。
ListMap:元素特点 Key 唯一、有序(元素添加(存储)的顺序)。
TreeMap:元素特点 Key 唯一、排序(按自然顺序排序)。
需求:
创建 HashMap 集合,存储元素 ("A", 1), ("B", 2), ("C", 3), ("C", 3),然后打印集合
创建 ListMap 集合,存储 ("A", 1), ("C", 3), ("B", 2), ("C", 3),然后打印集合
创建 TreeMap 集合,存储元素 ("A", 1), ("C", 3), ("B", 2), ("C", 3),然后打印集合
val hashMap1 = HashMap(("A"-> 1), ("B"-> 2), ("C"-> 3), ("C"->3))
val listMap1 = ListMap(("A", 1), ("C", 3), ("B", 2), ("C", 3))
val treeMap1 = TreeMap(("A", 1), ("C", 3), ("B", 2), ("C", 3))
println(hashMap1,listMap1,treeMap1)(Map(A -> 1, B -> 2, C -> 3),ListMap(A -> 1, B -> 2, C -> 3),Map(A -> 1, B -> 2, C -> 3))4.4. 数组Array
分为可变数组和不可变数组
4.4.1. 不可变数组
数组的长度不允许改变,数组的内容可以改变。
val|var 数组名 = new Array[元素类型](数组长度)new的数组()写的是长度val|var 数组名 = Array(元素1, 元素2, 元素3, ...)`非new的数组()写的是元素需求:
定义一个长度为 10 的整型数组,设置第 1 个元素为 5,设置第 2 个元素为 10,并打印这两个元素
定义一个包含 Java,Scala,Python 三个元素的数组,并打印数组长度
val arr1 = new Array[Int](10)arr1(0)=5arr1(1)=10arr1.foreach(print)println()510000000004.4.2. 可变数组
数组的长度和内容都是可变的,可以往数组中添加、删除元素。
val|var 变量名 = ArrayBuffer[元素类型]()val|var 变量名 = ArrayBuffer(元素1, 元素2, 元素3, ...)需求:
定义一个长度为 0 的整型变长数组
定义一个包含 Hadoop、Hive、Spark 三个元素的变长数组
val arr2 = ArrayBuffer[Int](0)println(arr2)val arr3 = ArrayBuffer[String]("Hadoop","Hive","Spark")arr3.foreach(println)ArrayBuffer(0)HadoopHiveSpark4.4.3. 增删改
针对可变数组
+= :添加单个元素
-= :删除单个元素
++= :追加多个元素到变长数组中
--= :移除变长数组中的多个元素
数组名(索引) = 新值 或者 数组名.update(索引, 新值) :修改元素
val arr4 = ArrayBuffer("Hadoop","Hive","Spark")arr4+="Scala"println(arr4)arr4-="Hadoop"println(arr4)arr4++=Array("Linux","zookeeper")println(arr4)arr4--=Array("Scala","Linux")println(arr4)arr4 ++= ArrayBuffer("Phoenix", "Sqoop")println(arr4)arr4.update(1,"123")println(arr4)arr4(2)="234"ArrayBuffer(Hadoop, Hive, Spark, Scala)ArrayBuffer(Hive, Spark, Scala)ArrayBuffer(Hive, Spark, Scala, Linux, zookeeper)ArrayBuffer(Hive, Spark, zookeeper)ArrayBuffer(Hive, Spark, zookeeper, Phoenix, Sqoop)ArrayBuffer(Hive, 123, zookeeper, Phoenix, Sqoop)4.4.4. 遍历数组
val arr5 = Array(1, "2", 3.14, true, null)
遍历元素
for(i<-arr5){println(i)}遍历索引for(i<-arr5.indices){println(i)}to 或 untilfor(i <- 0 to arr5.size){println(i)}arr5.foreach(println)4.4.5. 常用方法
sum() :求和。
max() :求最大。
min() :求最小。
sorted() :排序(正序),返回一个新的数组。倒序可以先排序再反转。
reverse() :反转,返回一个新的数组。
var arr6=Array(4,1,3,2,5)println(arr6.sum)println(arr6.max)println(arr6.min)arr6.sorted.foreach(print)printlnarr6.sorted.reverse.foreach(print)println155112345543214.5. 元组Tuple
元组的长度和元素都是不可变的。
val|var 元组名 = (元素1, 元素2, 元素3, ...)
val|var 元组名 = 元素1 -> 元素2注意:格式二只适用于元组中只有两个元素的情况
需求:
定义一个元组,包含学生的姓名和年龄
分别使用小括号以及箭头的方式来定义元组
val tuple1 = ("a",1,"123",true,false)println(tuple1)val tuple2 = "一个人"->12println(tuple2)(a,1,123,true,false)(一个人,12)4.5.1. 访问元素tuple3._1
元组名._nval tuple3 = ("a",1,"123",true,false)println(tuple3._1,tuple3._5)(a,false)4.6. 列表List
有序,可重复。
4.6.1. 不可变列表
列表的元素、长度都是不可变的。
val|var 列表名 = List(元素1, 元素2, 元素3, ...)
val|var 列表名 = Nil
val|var 列表名 = 元素1 :: 元素2 :: 元素n :: Nil需求:
创建一个不可变列表,存放元素
使用 Nil 创建一个不可变的空列表
使用 :: 方法创建列表,包含 -2、-1 两个元素
val list1 = List(1,2,3,4,5)val list2 = Nilval list3 = -1 :: -1 :: 2 :: Nilprintln(list3)List(-1, -1, 2)4.6.2. 可变列表
可变列表指的是列表的元素、长度都是可变的。
val|var 列表名 = ListBuffer[数据类型]()
val|var 列表名 = ListBuffer(元素1, 元素2, 元素3, ...需求:
创建空的整型可变列表
创建一个可变列表,初始化时包含 1, "2", 3.14, true, null 元素
val list4 = ListBuffer[Any]()val list5 = ListBuffer(1, "2", 3.14, true, null)4.6.3. 常用方法
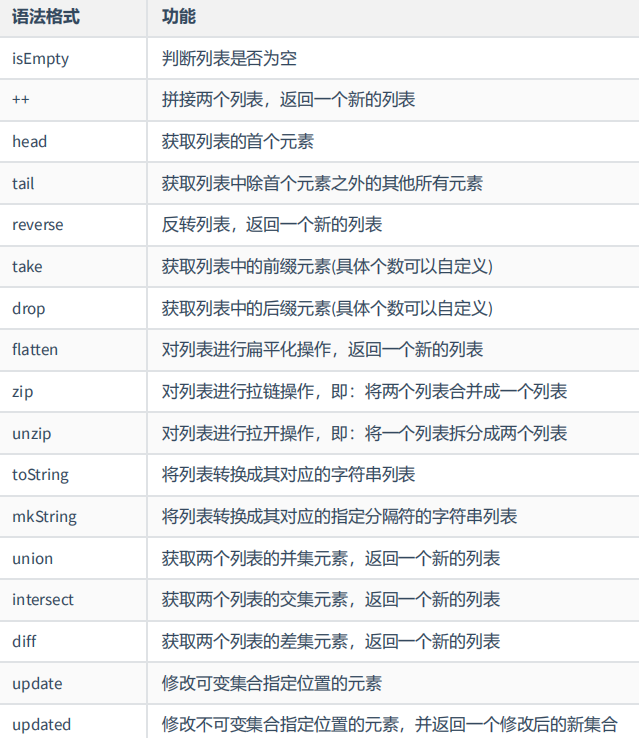
列表名(索引) 根据索引(索引从0开始),获取列表中的指定元素
列表名(索引) = 值 修改元素值
+= 添加单个元素
++= 追加多个元素到可变列表中
-= 删除单个元素
--= 移除可变列表中的多个元素
toList 将可变列表(ListBuffer)转换为不可变列表(List)
toArray 将可变列表(ListBuffer)转换为不可变数组(Array)
toBuffer 将可变列表(ListBuffer)转换为可变数组(BufferArray)
val list6 = ListBuffer[Int]()
list6+=123
list6.toList+=1 显然这样会报错,因为不可变列表不可添加和修改元素
println(list6)
需求:
定义一个列表 list1,包含以下元素: 1, "2", 3.14, true, null
使用 isEmpty 方法判断列表是否为空,并打印结果
再定义一个列表 list2,包含以下元素: "a", "b", "c"
使用 ++ 将两个列表拼接起来,并打印结果
使用 head 方法,获取列表的首个元素,并打印结果
使用 tail 方法,获取列表中除首个元素之外的其他所有元素,并打印结果
使用 reverse 方法,将列表元素反转,并打印结果
使用 take 方法,获取列表中的前缀元素,并打印结果
使用 drop 方法,获取列表中的后缀元素,并打印结果
使用 update 方法,修改指定位置元素,并返回一个修改后的新集合
val list7 = List(1, "2", 3.14, true, null)println(list7.isEmpty)val list8 = List("a", "b", "c")println(list7 ++ list8)println(list7.head)println(list7.tail)println(list7.reverse)println(list7.take(3))前3个数println(list7.drop(4))除了前4个数println(list7.updated(0, "abc"))
falseList(1, 2, 3.14, true, null, a, b, c)1List(2, 3.14, true, null)List(null, true, 3.14, 2, 1)List(1, 2, 3.14)List(null)List(abc, 2, 3.14, true, null)4.6.4. 扁平化flatten
嵌套列表中的每个元素单独放到一个新的列表中。
需求:
定义一个列表,该列表有三个元素,分别为: List("Hello", "World") 、 List("Hello", "Scala") 、
List("Hello", "Spark")
使用 flatten 将这个列表转换为 List("Hello", "World", "Hello", "Scala", "Hello", "Spark")
val list9 = List(List("Hello", "World") ,List("Hello", "Scala"), List("Hello", "Spark"))println(list9.flatten)List(Hello, World, Hello, Scala, Hello, Spark)4.6.5. 拉链与拉开zip/unzip
将两个列表合并成一个列表,列表的元素为元组。无法组成拉链的单个元素会被丢弃
将一个列表拆分成两个列表,两个列表被元组包含
需求:
定义列表 names,保存三个学生的姓名,分别为:张三、李四、王五
定义列表 ages,保存学生的年龄,分别为:18、19、20
使用 zip 将列表 names 和 ages 合并成一个列表 list
使用 unzip 将列表 list 拆分成包含两个列表的元组 tuple
val names = List("张三","李四","王五")val ages = List(18,19,20)val list= names.zip(ages)println(list)println(list.unzip)List((张三,18), (李四,19), (王五,20))(List(张三, 李四, 王五),List(18, 19, 20))4.6.6. 转换字符串toString/mkString
toString :返回 List 中的所有元素的字符串
mkString :可以将元素以指定的分隔符拼接起来并返回,默认没有分隔符
需求:
定义一个列表,包含元素:1, 2, 3, 4
使用 toString 方法输出该列表元素
使用 mkString 方法指定分隔符为冒号,并输出该列表元素
var list10 = (1 to 4).toListprintln(list10.toString())println(list10.mkString(":"))List(1, 2, 3, 4)1:2:3:44.6.7. 并集union/交集intersect/差集diff
union并集(合并)操作,且不去重
intersect :表示对两个列表取交集(相同)
diff :表示对两个列表取差集(不同)
需求:
定义列表 list1,包含以下元素:1, 2, 3, 4
定义列表 list2,包含以下元素:3, 4, 5, 6
使用 union 获取 list1 和 list2 的并集
在上一步的基础上,使用 distinct 去除重复的元素
使用 intersect 获取 list1 和 list2 的交集
使用 diff 获取列表 list1 和 list2 的差集
var list11 = List(1,2,3,4)var list12 = List(3,4,6,5)println(list11.union(list12))println(list11.union(list12).distinct)println(list11.intersect(list12))println(list11.diff(list12))List(1, 2, 3, 4, 3, 4, 6, 5)List(1, 2, 3, 4, 6, 5)List(3, 4)List(1, 2)4.7. 集Set
唯一,自动去重。
4.7.1. 不可变集
元素和长度都不可变
val|var 集名 = Set[类型]()
val|var 集名 = Set(元素1, 元素2, 元素3, ...)
需求:
定义一个空的整型不可变集
定义一个不可变集,保存以下元素:1, 1, 2, 3, 4, 5
var set1 = Set(1,1,2,3,4,5)println(set1)4.7.2. 可变集
元素和长度都可变
val|var 集名 = mutable.Set[类型]()
val|var 集名 = mutable.Set(元素1, 元素2, 元素3, ...)
需求:
定义一个可变集,包含以下元素:1, 2, 3, 4
添加元素 5 到可变集中
添加元素 6, 7, 8 到可变集中
从可变集中移除元素 3
从可变集中移除元素 3, 5, 7
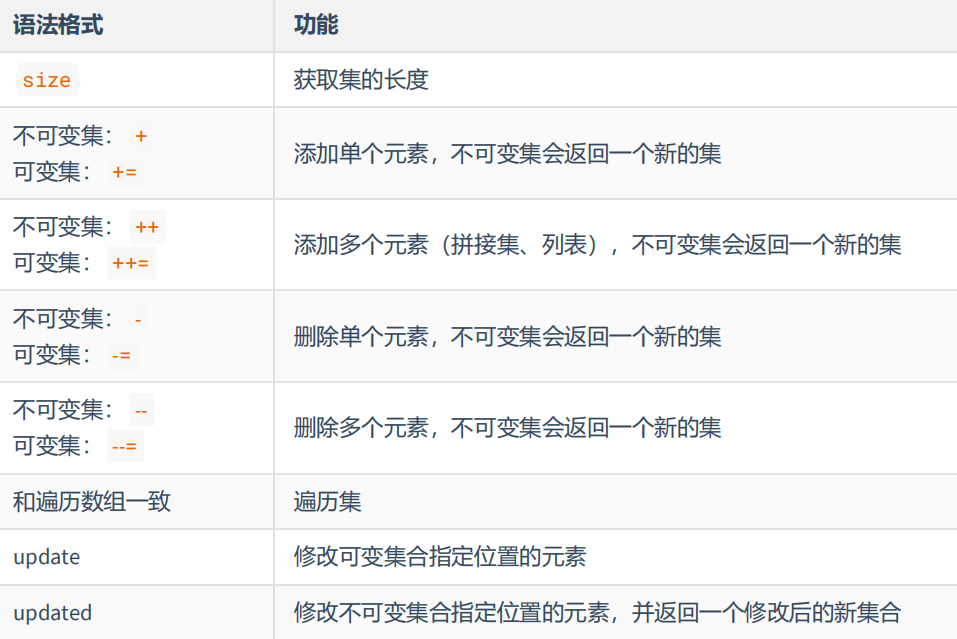
var set2 = mutable.Set(1, 2, 3, 4)set2+=5println(set2)set2++=List(6,7,8)println(set2)set2-=3println(set2)set2--=Array(3,4,5)println(set2)Set(5, 1, 2, 3, 4)Set(5, 1, 2, 3, 4)Set(5, 1, 6, 2, 7, 3, 8, 4)Set(5, 1, 6, 2, 7, 8, 4)Set(1, 6, 2, 7, 8)set2.update(2,false)删除set2.update(10,true)添加println(set2)Set(1, 2, 6, 7, 8)Set(1, 6, 10, 7, 8)4.7.3. 语法格式功能
不可变集返回新的集
4.8. 映射 Map
如果添加相同键元素,则后者的值会覆盖前者的值。
4.8.1. 不可变Map
Map 的元素、长度都是不可变的。
val|var map = Map(键1 -> 值1, 键2 -> 值2, 键3 -> 值3, ...)val|var 集名 = Map((键1, 值1), (键2, 值2), (键3, 值3), ...)需求:
定义一个 Map,包含以下元素: "张三" -> 18 , "李四" -> 19 , "王五" -> 20
获取键为张三的值
var map1 = Map("张三"-> 18,"李四"->19,"王五"->20)var map2 = Map(("张三",18),("李四",19),("王五",20))println(map1("张三"))println(map2("李四"))println(map1.getOrElse("zs","不存在"))1819不存在4.8.2. 可变Map
需求:
定义一个 Map,包含以下元素: "张三" -> 18 , "李四" -> 19 , "王五" -> 20
获取键为张三的值
修改张三的年龄为 28
var map3 = mutable.Map("张三" -> 18, "李四" -> 19, "王五" -> 20)println(map3("张三"))map3.update("张三", 29)4.8.3. 遍历map
for(elem <- map3)println(elem)for((k,v) <-map3)println(k,v)map3.foreach(println)4.8.4. 常见操作
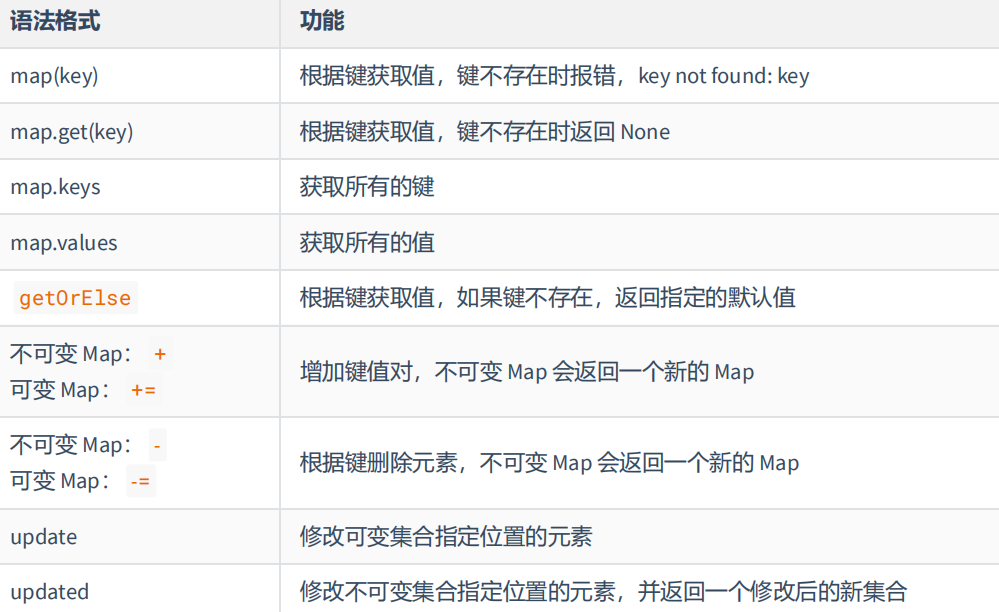
需求:
定义一个可变 Map,包含以下元素: "张三" -> 18 , "李四" -> 19 , "王五" -> 20
获取张三的年龄
获取所有学生姓名
获取所有学生年龄
获取所有学生姓名和年龄
获取赵六的年龄,如果赵六不存在则返回 -1
新增一个学生: "赵六" -> 21
将李四从 Map 中移除
var map4 = mutable.Map("张三" -> 18 ,"李四" -> 19 , "王五" -> 20)println(map4.get("张三"))println(map4.keys)println(map4.values)for((k,v)<-map4)println(k,v)println(map4.getOrElse("赵六", -1))println(map4 += "赵六" -> 21)println(map4 -= "李四")Some(18)Set(王五, 张三, 李四)HashMap(20, 18, 19)(王五,20)(张三,18)(李四,19)-1Map(赵六 -> 21, 王五 -> 20, 张三 -> 18, 李四 -> 19)Map(赵六 -> 21, 王五 -> 20, 张三 -> 18)4.9. range
val range01: Range.Inclusive = 1 to 5for (i <- range01) println(i) 1 2 3 4 5val range03: Range = 1 to 5 by 2val range03: Range = Range(1, 5, 2)for (i <- range03) println(i) 1 3 54.10. 函数式编程
4.10.1. 遍历foreach
def foreach(f:(A) => Unit): Unit简写形式
def foreach(函数)4.10.2. 去重distinct
val list = List(1, 2, 2, 3, 4, 5, 6)
println(list.distinct) List(1, 2, 3, 4, 5, 6)4.10.3. 映射map
def map[B](f: (A) => B): TraversableOnce[B]简写形式def map(函数对象)val result2 = list.map(x => x * 2)println(result2)4.10.4. 扁平化flatmap
扁平化映射可以理解为先 map,然后再 flatten,它也是将来使用最多的操作,也是必须要掌握的。
def flatMap[B](f: (A) => GenTraversableOnce[B]): TraversableOnce[B]
简写形式
def flatMap(f: (A) => 待转换的集合的处理代码)
val list = List("hello world", "a new line", "the end")val result3 = list.flatMap(s => s.split("\\s+"))println(s"result3 = ${result3}")根据空格拆分再合并4.10.5. 过滤filter
def filter(f: (A) => Boolean): TraversableOnce[A]val result1 = list.filter(x => x % 2 == 0)4.10.6. 排序sorted、sortBy、sortWith
sorted :按默认规则(升序)排序集合
sortBy :按指定属性排序集合
sortWith :按自定义规则排序集合
val sortby1 = List("01 zookeeper", "02 hadoop", "03 hive", "04 spark")val resSort = sortby1.sortBy(x=>x.split("\\s+")(1))val sortWith1 = List("01 zookeeper", "02 hadoop", "03 hive", "04 spark")val resSort1 = sortWith1.sortWith((x, y) => x > y)println(resSort1)根据字典序排序从左至右List(04 spark, 03 hive, 02 hadoop, 01 zookeeper)4.10.7. 分组groupBy
val groupList1 = List("张三" -> "男", "李四" -> "女", "王五" -> "男")val resGroupBy1 = groupList1.groupBy(x=>x._2)println(resGroupBy1)返回Map集合Map(男 -> List((张三,男), (王五,男)), 女 -> List((李四,女)))4.10.8. 聚合reduce
def reduce[A1 >: A](op: (A1, A1) => A1): A1简写形式def reduce(op:(A1, A1) => A1)val listRedu = (1 to 10).toList使用 reduce 计算所有元素的和val resRedu = listRedu.reduce((x, y) => x + y)println(resRedu)55println(listRedu.reduceLeft(_ - _))-53println(listRedu.reduceRight(_ + _))554.10.9. 折叠
def fold[A1 >: A](z: A1)(op: (A1, A1) => A1): A1
简写形式
def fold(初始值)(op:(A1, A1) => A1)
val listFold = (1 to 10).toListval resFold = listFold.fold(10)((x, y) => x + y)10为起始值println(resFold)65println(list.foldLeft(10)(_ - _))println(list.foldRight(10)(_ - _))5. 模式匹配
5.1. 语法格式
类似switch只是省去了break
变量 match {case "常量1" => 表达式1case "常量2" => 表达式2case "常量n" => 表达式ncase _ => 表达式n+1
}- 先执行第一个 case,看变量值和该 case 对应的常量值是否一致;
- 如果一致,则执行该 case 对应的表达式;
- 如果不一致,则执行下一个 case,看变量值和该 case 对应的常量值是否一致;
- 以此类推,如果所有的 case 都不匹配,则执行 case _ 对应的表达式。
需求:
提示用户输入一个单词并接收
判断该单词是否能够匹配以下单词,如果能匹配,返回一句话
hadoop:大数据分布式存储和计算框架
zookeeper:大数据分布式协调服务框架
spark:大数据分布式内存计算框架
其他:未匹配
val str = StdIn.readLine().toLowerCase()
val result1 = str match{case "ABCD" => "这是A"case "B" => "这是B"case _ =>"没有匹配到"
}
println(result1)5.2. 匹配类型
对象名 match {
case 变量名1:类型1 => 表达式1
case 变量名2:类型2 => 表达式2
case 变量名n:类型n => 表达式n
case _ => 表达式n+1
}
val a:Any = "Hadoop"
val result2 = a match{case x:Int =>"这是整数"case x:String =>"这是字符串"case _ =>"匹配失败"
}val result2 = a match {case _: String => "String 类型的数据"case _: Int => "Int 类型的数据"case _: Double => "Double 类型的数据"case _ => "未匹配"}
println(result2)5.3. 守卫
变量 match {case 变量名 if条件 => 表达式...case _ -> 表达式
}5.4. 匹配样例类
对象名 match {case 样例类型1(属性1, 属性2, 属性n) => 表达式1case 样例类型2(属性1, 属性2, 属性n) => 表达式2case 样例类型n(属性1, 属性2, 属性n) => 表达式ncase _ => 表达式n+1
}case 样例类后的小括号中的字段个数,要和具体的样例类的字段个数保持一致。
通过 match 进行模式匹配的时候,要匹配的对象必须声明为 Any 类型。
创建两个样例类 User(姓名, 年龄) 和 Order(编号)
分别定义两个样例类的对象,并指定为 Any 类型
使用模式匹配这两个对象,并分别打印它们的成员
case class User(name:Any,age:Any);
case class Order(id:Int);
val a1:Any = User("张三",19)
val b:Any = Order(1)a1 match{case User(a,b)=>println(a,b)case Order(a)=>println(a)case _ =>println("未匹配")
}
(张三,19)5.5. 匹配数组
需求:
定义以下数组:
Array(5) :只包含 5 一个元素的数组
Array(x, y) :只包含两个元素的数组
Array(5, x, y) :以 5 开头的数组,长度为 3
Array(x, y, 5) :以 5 结尾的数组,长度为 3
Array(5, ...) :以 5 开头的数组,数量不固定
val arr1 = Array(5)
val arr2 = Array(1,2)
val arr3 = Array(5,6,7)
val arr4 = Array(3,4,5)
val arr5 = Array(5,6,7,8,9)
arr5 match{case Array(x)=>println(x)case Array(x,y)=>println(x,y)case Array(5,x,y)=>println(5,x,y)case Array(x,y,5)=>println(x,y,5)case Array(5,_*) =>println("以5开头的很长的数组")case _ => println("未匹配")
}5.6. 匹配列表
需求:
定义以下列表:
List(5) :只包含 5 一个元素的列表
List(x, y) :只包含两个元素的列表
List(5, x, y) :以 5 开头的列表,长度为 3
List(x, y, 5) :以 5 结尾的列表,长度为 3
List(5, ...) :以 5 开头的列表,数量不固定
和上面一样
5.7. 匹配集
和列表数组一样的
5.8. 匹配映射
由于 Map 中的元素就是一个一个的二元组,所以在遍历时,可以使用元组匹配。
定义val map1 = Map("A" -> 1, "B" -> 2, "C" -> 3)
使用匹配模式,匹配上述 Map
val map1 = Map("A" -> 1, "B" -> 2, "C" -> 3)
for((k,v)<-map1){println(k,v)
}
(A,1)
(B,2)
(C,3)
for(("A",x)<-map1){println("A",x)
}
(A,1)
for((k,v)<-map1 if v%2==0){println(k,v)
}
(B,2)5.9. 变量声明的匹配
生成包含 0-10 数字的数组,使用模式匹配分别获取第二个、第三个、第四个元素
生成包含 0-10 数字的列表,使用模式匹配分别获取第一个、第二个元素
val arr6 = (0 to 10).toArray
val list1 = (0 to 10).toList
val Array(_,x,y,z,_*) = arr6
//将值取到x,y,z当中
val List(a2,b1,c,_*) = list1
//将值取到a,b当中
println(x,y,z,a2,b1)
(1,2,3,0,1)5.10. 匹配Option
5.11. 偏函数
val pf2: PartialFunction[Int, String] = {//参数值和函数返回值case 1 => "One"case 2 => "Two"case 3 => "Three"
}
println(pf2.isDefinedAt(1), pf2.isDefinedAt(4))
//(true,false)5.12. 结合函数使用
5.12.1. collect
在 Scala 中,我们还可以通过 collect() 方法实现偏函数结合集合来使用,从集合中筛选指定的数据。
def collect[B](pf: PartialFunction[A, B]): Traversable[B]
需求:
已知一个 List 列表,存储元素为:1, 2, 3, 4, 5, 6, 7, 8, 9, 10
通过 collect 函数筛选出集合中所有的偶数
val list10 = (1 to 10).toList
val pf:PartialFunction[Int,Int]={case x if x%2 == 0=>x
}
val result10 = list10.collect(pf);
println(result10)
List(2, 4, 6, 8, 10)
//合并版
val result11 = list10.collect{case x if x%2==0=>x
}
println(result11)5.12.2. map
需求:
定义一个列表,包含 1-10 的数字
请将 1-3 的数字都转换为 [1-3]
请将 4-8 的数字都转换为 [4-8]
将其他的数字转换为 (8-*]
var list12 = (1 to 10).toList
val result12 = list12.map{case x if x >=1 && x<=3 =>"[1-3]"case x if x >=4 && x<=8 =>"[4-5]"case _ =>"(8-*]"
}
println(result12)
val list = List("张三" -> 18, "李四" -> 19, ("tuple1", "tuple2", "tuple3"),
(1 to 5).toList, 5, "Scala")
list.foreach{case (k,v)=>println(k,v)case (x,y,z) =>println(x,y,z)case x:List[Int] =>println(x)case x:Int=>println(x)case x:String =>println(x)
}
// (张三,18)
// (李四,19)
// (tuple1,tuple2,tuple3)
// List(1, 2, 3, 4, 5)
// 5
// Scala5.12.3. foreach
需求:定义列表 List(("张三", 18), ("李四", 19), 5, "Scala", (1 to 5).toList) ,根据不同的元素类型
做出不同的处理。
val list20 = List("张三" -> 18, "李四" -> 19, ("tuple1", "tuple2", "tuple3"),(1 to 5).toList, 5, "Scala")list20.foreach{case (k,v) =>println(k,v)case (x,y,z) =>println(x,y,z)case x:List[Int] =>println(x)case x:Int =>println(x)case x:String =>println(x)case _ =>println("匹配失败")}




)
--SPI主机设计思路与代码解析)




(健康生活是coder抒写优质代码的前提条件——《黄帝内经》伴读学习纪要))
作业提交)






