文章目录
- 摘要
-
- **稀疏化与专家系统**
- **注意力机制优化**
- **归一化与稳定性设计**
- 模型架构对比详析
-
- DeepSeek-V3 vs Llama 4 Maverick
- Qwen3 vs SmolLM3
- Kimi 2的突破
- 1 DeepSeek V3/R1
-
- 1.1 多头潜在注意力(MLA)
- 1.2 混合专家系统(MoE)
- 1.3 DeepSeek 总结
- 2 OLMo 2
-
- 2.1 归一化层位置
- 2.2 QK-Norm
- 2.3 OLMo 2 总结
- 3 Gemma 3
- 3.1 滑动窗口注意力
- 3.2 Gemma 3的归一化层位置
- 3.3 Gemma 3总结
- 3.4 彩蛋:Gemma 3n
- 4 Mistral Small 3.1
- 5 Llama 4
-
- 6 Qwen3
- 6.1 Qwen3(密集版)
- 6.2 Qwen3(MoE版)
- 7 SmolLM3
-
- 7.1 无位置嵌入(NoPE)
- 8 Kimi 2
- 总结与展望
摘要
本文系统性梳理了2025年主流开源LLM的架构创新,涵盖从DeepSeek-V3到Kimi K2的代表性设计。这些模型在保持高效推理的同时,通过差异化技术路径实现了性能突破,核心趋势可归纳为以下三类:
稀疏化与专家系统
- 混合专家系统(MoE):DeepSeek-V3(671B)、Llama 4 Maverick(400B)、Qwen3(235B)均采用MoE架构,通过激活部分专家(如DeepSeek的9专家/2048隐藏层,Llama 4的2专家/8192隐藏层)平衡计算效率与模型容量。
- 动态路由:MoE通过路由模块选择激活专家,DeepSeek-V3在每层使用9专家,而Qwen3 235B-A22B则采用8专家设计,放弃共享专家(与DeepSeek-V3不同)。
注意力机制优化
- 多头潜在注意力(MLA):DeepSeek-V3首创MLA替代传统MHA,通过低秩投影减少KV缓存(37B激活参数 vs MHA的671B总参数),提升推理效率。
- 滑动窗口注意力(Sliding Window):Gemma 3(27B)采用局部注意力窗口(1024上下文),Mistral Small 3.1(24B)则回归传统GQA,推测因FlashAttention等优化库更适配全局注意力。
- 无位置嵌入(NoPE):SmolLM3(3B)尝试移除显式位置编码,依赖因果掩码隐式学习顺序,实验显示其长度泛化能力更优(序列延长时性能衰减更慢)。
归一化与稳定性设计
- RMSNorm变体:
- OLMo 2采用后归一化(Post-Norm),将RMSNorm置于注意力与前馈模块后,结合QK-Norm(查询键归一化)稳定训练。
- Gemma 3创新性采用前归一化(Pre-Norm)与后归一化混合设计,兼顾梯度稳定性与计算效率。
- 训练优化:Kimi 2(1T参数)首次在万亿规模模型中采用Muon优化器替代AdamW,实现更平滑的损失衰减(尽管梯度L2范数分析显示其平滑性未显著超越OLMo 2)。
模型架构对比详析
DeepSeek-V3 vs Llama 4 Maverick
| 维度 | DeepSeek-V3 | Llama 4 Maverick |
|---|---|---|
| 总参数 | 671B | 400B |
| 激活参数 | 37B(9专家,2048隐藏层) | 17B(2专家,8192隐藏层) |
| MoE层分布 | 除前3层外全采用MoE | 交替使用MoE与密集模块 |
| 注意力机制 | MLA(多头潜在注意力) | GQA(分组查询注意力) |
Qwen3 vs SmolLM3
| 维度 | Qwen3 235B-A22B | SmolLM3 3B |
|---|---|---|
| 架构类型 | MoE(8专家,无共享专家) | 密集(每4层省略RoPE) |
| 位置编码 | RoPE(旋转位置编码) | NoPE(无显式位置嵌入) |
| 性能亮点 | 32B-A3B/235B-A22B双版本 | 3B规模下胜过更大模型(图20) |
Kimi 2的突破
- 规模与创新:1T参数,采用DeepSeek-V3架构扩展(更多MoE专家、MLA头数调整),训练损失曲线衰减显著(图24)。
- 开源策略:继Kimi 1.5(未公开权重)后,Kimi 2成为首个万亿级开源模型,性能比肩专有模型(Gemini、Claude、ChatGPT)。
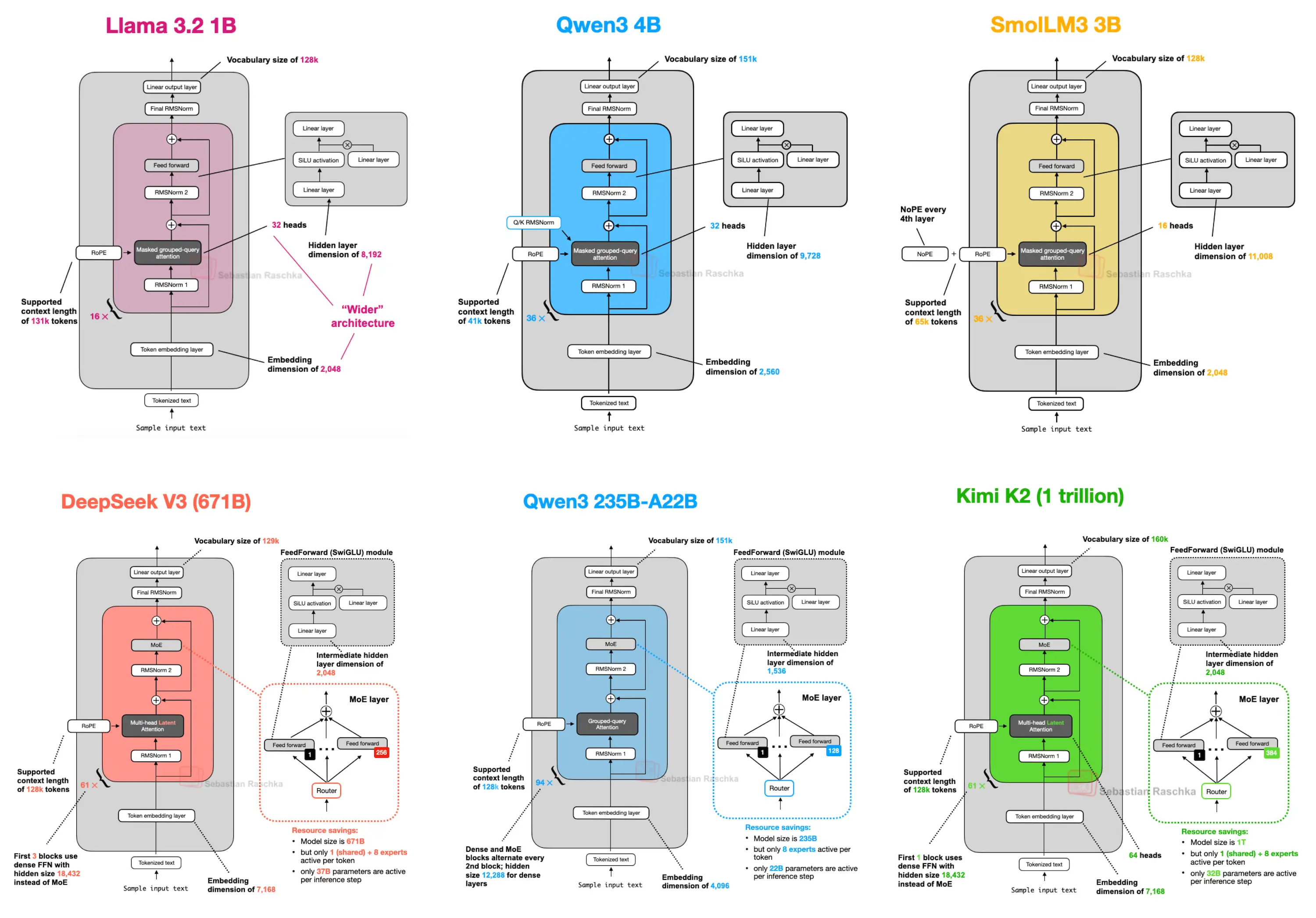
1 DeepSeek V3/R1
你可能已经多次听说过,2025年1月发布的DeepSeek R1引起了巨大反响。该模型是基于2024年12月推出的DeepSeek V3架构构建的推理型模型。
虽然本文聚焦2025年发布的架构,但我认为将DeepSeek V3纳入讨论是合理的,因为它在2025年伴随DeepSeek R1的发布才获得广泛关注和应用。
如果你对DeepSeek R1的训练细节感兴趣,可以参考我今年早些时候发布的文章。
本节将重点分析DeepSeek V3引入的两项关键架构技术,它们提升了计算效率并使其区别于其他LLM:
- 多头潜在注意力(MLA)
- 混合专家系统(MoE)
1.1 多头潜在注意力(MLA)
在讨论多头潜在注意力(MLA)之前,先简要回顾相关背景以说明其动机。我们从分组查询注意力(GQA)说起,它近年来已成为替代多头注意力(MHA)的高效方案,在计算和参数效率上更具优势。
以下是GQA的简要总结:与MHA中每个注意力头独立拥有键(Key)和值(Value)投影不同,GQA通过让多个头共享同一组键和值投影来减少内存占用。
例如,假设有2个键值组和4个注意力头(如图2所示),头1和头2可能共享一组键和值,头3和头4则共享另一组。这减少了键值计算的总次数,从而降低内存消耗并提升效率(消融实验表明,此举对模型性能影响可忽略)。
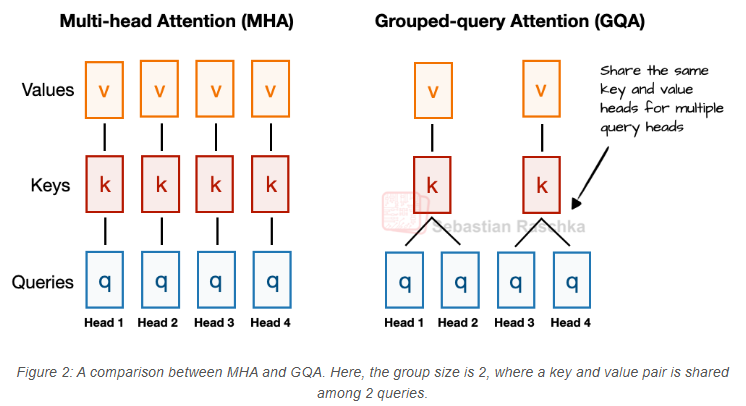
因此,GQA的核心思想是通过让多个查询头共享同一组键值头,来减少键值头的数量。这(1)降低了模型的参数数量,(2)减少了推理时键值张量对内存带宽的占用——因为需要从KV缓存中存储和检索的键值数量更少。
(如果你对GQA的代码实现感兴趣,可以参考我的《GPT-2到Llama 3转换指南》(无KV缓存版本)以及《KV缓存变种指南》。)
虽然GQA主要是对MHA的一种计算效率优化,但消融实验(如原始GQA论文和Llama 2论文中的实验)表明,其在LLM建模性能上与标准MHA相当。
而多头潜在注意力(MLA)则提供了另一种节省内存的策略,且与KV缓存特别适配。与GQA共享键值头不同,MLA在将键值张量存入KV缓存前,会先将其压缩到低维空间。
如图3所示,在推理时,这些压缩后的张量会被投影回原始尺寸后再使用。这一操作增加了一次矩阵乘法,但减少了内存占用。
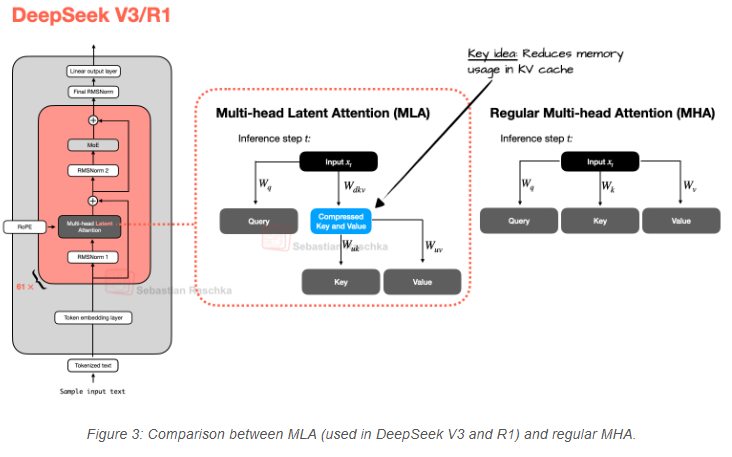
(附带说明,查询(queries)也会被压缩,但仅在训练期间,推理时不会。)
顺便一提,MLA并非DeepSeek V3的新特性,因为其前身DeepSeek-V2也使用了(甚至引入了)它。
此外,V2论文中包含了一些有趣的消融实验,可能解释了为何DeepSeek团队选择MLA而非GQA(见图4)。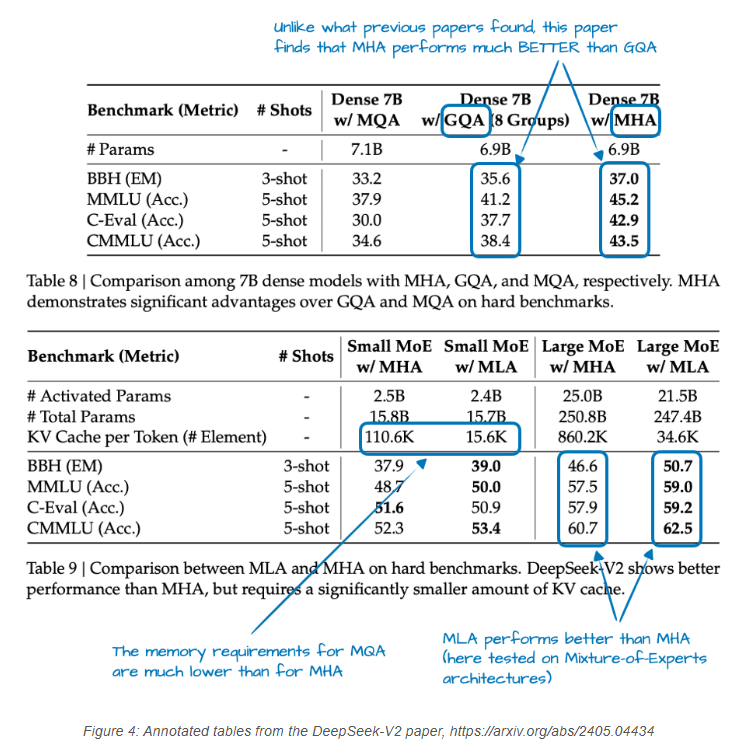
如上图4所示,GQA的性能似乎比MHA更差,而MLA的建模性能优于MHA,这可能就是DeepSeek团队选择MLA而非GQA的原因。(若能比较MLA与GQA在“每标记KV缓存”节省量上的差异,也会很有趣!)
总结本节内容,在进入下一个架构组件前:MLA是一项巧妙的技术,既减少了KV缓存的内存占用,又在建模性能上略微超越了MHA。
1.2 混合专家系统(MoE)
DeepSeek中另一个值得强调的主要架构组件是其使用的混合专家系统(MoE)层。虽然DeepSeek并非MoE的发明者,但该技术今年重新兴起,且我们后续将讨论的许多架构也采用了它。
你可能已经熟悉MoE,但快速回顾一下可能会有帮助。
MoE的核心思想是:将Transformer块中的每个前馈(FeedForward)模块替换为多个专家层,其中每个专家层本身也是一个前馈模块。这意味着我们用多个前馈模块替代了单个前馈模块,如图5所示。
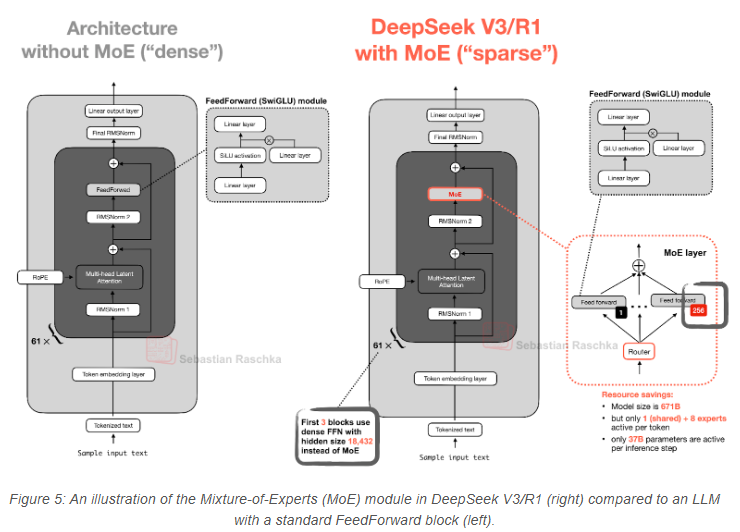
Transformer块内部的前馈模块(如上图中的深灰色块)通常包含模型总参数的很大一部分。(注意:Transformer块(因此前馈模块)在大型语言模型中会多次重复;以DeepSeek-V3为例,重复了61次。)
因此,用多个前馈模块替代单个前馈模块(如MoE设置中所做的)会大幅增加模型的总参数数量。但关键技巧在于:我们不会对每个标记都使用(“激活”)所有专家。相反,路由模块会为每个标记仅选择一小部分专家。(为节省篇幅,路由模块的
——Time、Vector3、位置位移、角度、旋转、缩放、看向)

,KL散度)










Gemini Agent 使用指南)
)

 远程登录VirtualBox中的Ubuntu24.04,显示图形化(GUI)界面)


)