在日常测试工作中,我们经常会遇到分页查询接口,例如:
GET /product/search?keyword=&pageNum=1&pageSize=10
乍看之下,这样的分页接口似乎并无性能问题,响应时间也很快。但在一次性能压测中,我们复现了一个典型的深分页性能瓶颈,并深入分析了其成因与优化思路,本文记录该过程与结论。
📌 压测背景
接口路径:/product/search
功能描述:根据关键字模糊查询商品列表,支持分页(pageNum, pageSize)。
✅ 数据规模
为了模拟真实生产场景,我们使用以下 SQL 批量造数,构造了 100万+商品数据(pms_product 表):
SET @max_id := (SELECT IFNULL(MAX(id), 0) FROM pms_product);
SET @row := 0;INSERT INTO pms_product (id, brand_id, product_category_id, name, sub_title, price,publish_status, verify_status, sort, description, delete_status,new_status, recommand_status, sale, stock, low_stock, unit, weight,preview_status, service_ids, keywords, note, product_sn
)
SELECT @max_id + seq AS id,FLOOR(1 + RAND() * 10),FLOOR(1 + RAND() * 10),CONCAT('商品-', @max_id + seq),'',ROUND(RAND() * 1000, 2),1, 1, @max_id + seq, '', 0, 1, 1, 100, 100, 10, '', 1.5, 1,'1,2,3', '', '', CONCAT('SN', LPAD(@max_id + seq, 6, '0'))
FROM (SELECT @row := @row + 1 AS seqFROM (SELECT 0 UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9) t1,(SELECT 0 UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9) t2,(SELECT 0 UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9) t3,(SELECT 0 UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9) t4,(SELECT 0 UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9) t5,(SELECT @row := 0) rLIMIT 100000
) temp;数据字段包含多个维度如:商品分类、品牌、价格、上下架状态、是否删除等。
🔍 性能压测结果对比
我们使用 JMeter 对分页接口进行了压测,以下是对比结果:
正常分页压测结果:

深分页压测结果:

🚩 分页页码:pageNum=1(正常分页)
| 样本数 | 平均响应时间 | 最大响应时间 | 吞吐量 (TPS) | 平均返回字节数 |
|---|---|---|---|---|
| 10 | 2263ms | 2419ms | 3.2/sec | 9317 字节 |
🚩 分页页码:pageNum=100000(深分页)
| 样本数 | 平均响应时间 | 最大响应时间 | 吞吐量 (TPS) | 平均返回字节数 |
|---|---|---|---|---|
| 10 | 3245ms | 3653ms | 2.4/sec | 4224 字节 |
🧠 为什么深分页会变慢?
❗ 1. Offset 越大,代价越高
分页底层使用 LIMIT offset, size,如:
1)深分页执行的sql:
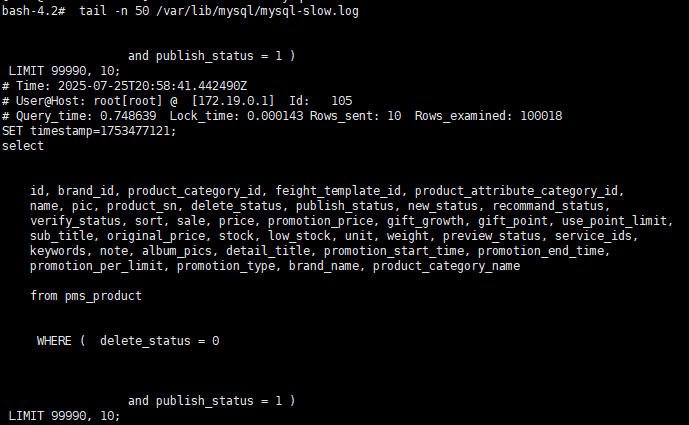
SELECT * FROM pms_product
WHERE delete_status = 0 AND publish_status = 1
ORDER BY id
LIMIT 99990, 10;
该查询需要:
- 遍历前 100000 行(offset),丢弃
- 返回最后 10 行
即使加了索引,MySQL 也必须扫描 offset + limit 条数据后再丢弃前面。
2)正常分页执行的sql:
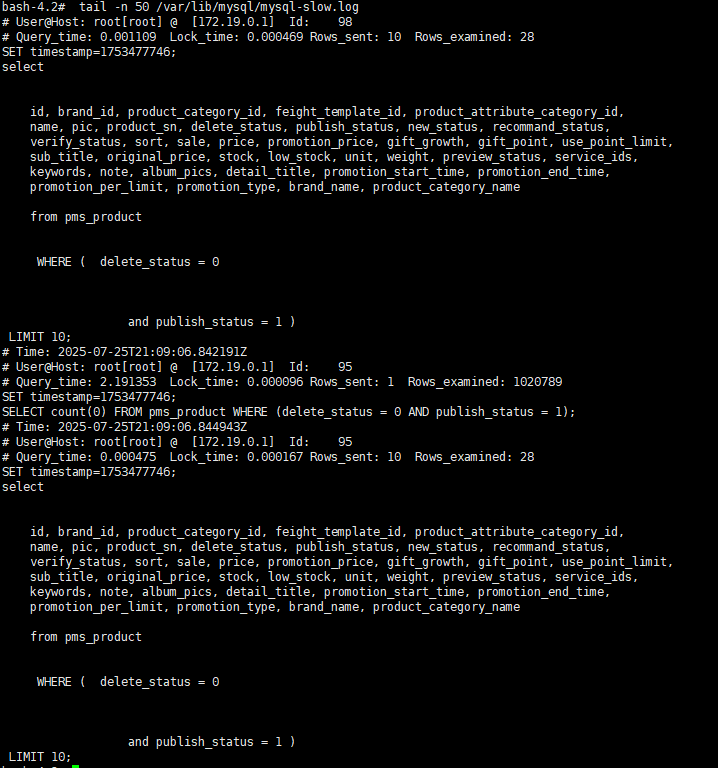
SELECT count(0) FROM pms_product WHERE delete_status = 0 AND publish_status = 1;
SELECT ... FROM pms_product WHERE delete_status = 0 AND publish_status = 1 LIMIT 10;
✅ 结论:
- LIMIT 10 是在数据前面截取的,性能还行,Rows_examined扫描了28行;
- count(0) 已扫描 100w 行(较慢);
❗ 2. explain 显示没有使用覆盖索引
我们对深分页 SQL 执行了 EXPLAIN 分析:
EXPLAIN SELECT * FROM pms_product
WHERE delete_status = 0 AND publish_status = 1
ORDER BY id LIMIT 99990, 10;

❗ 问题分析:
| 字段 | 说明 |
|---|---|
| type=index | 说明是走了索引,但是全索引扫描(index scan),相当于扫描整张表的索引部分。 |
| key=PRIMARY | 表示使用的是主键索引(id)。 |
| rows=100010 | MySQL 预估会扫描大约 10 万行来定位 LIMIT 起始位置。 |
| Extra=Using where | 表示 WHERE 条件在过滤过程中才判断,并没有用到复合索引来提前过滤。 |
⚠️ 这意味着:
- LIMIT 100000, 10 会导致 MySQL 扫描超过 10 万条记录,性能非常差。
- WHERE 条件没有使用到合适的索引(possible_keys 为 NULL)。
✅ 性能优化建议
1. 避免深分页 —— 改用“基于游标”方式
例如前端传入上一次返回结果的 last_id,实现类似“加载更多”:
SELECT * FROM pms_product
WHERE delete_status = 0 AND publish_status = 1 AND id > 上一次最大 id
ORDER BY id
LIMIT 10;
优点:
- 避免 offset,性能线性增长
- 可以用覆盖索引,避免回表
- 建立合理的联合索引
如分页条件为:
WHERE delete_status = 0 AND publish_status = 1 ORDER BY id
建议加:
CREATE INDEX idx_status_id
ON pms_product(delete_status, publish_status, id);
这样可以走索引,减少扫描行数。
3. 考虑分页缓存
如果某些页经常访问,可以考虑将分页结果缓存到 Redis,提升响应速度。
📝 总结
深分页是一种常见但代价昂贵的分页方式,特别在数据量大、页码大的时候:
- offset 会严重拖慢查询
- 即使不使用 count(),深分页依然很慢
- 优化建议包括:改游标分页、加索引、用缓存等








(含删除)(脚本))










