RAG 的主要动机 大模型训练的时候虽然使用了庞大的世界数据,但是并没有涵盖用户关心的所有数据,
其预训练令牌(token)数量虽大但相对这些数据仍有限。另外大模型输入的上下文窗口越来越大,从几千个token到几万个token,这相当于几十几百页内容,但是遇到你有几个G的文献资料你还是不能完全用上下文输入大模型来找到你想要的内容。大模型就像是新型操作系统的核心,将核心与各种各样的大量的外部链接起来,是这个新兴的操作系统发展中的一个非常核心的能力,如下图:
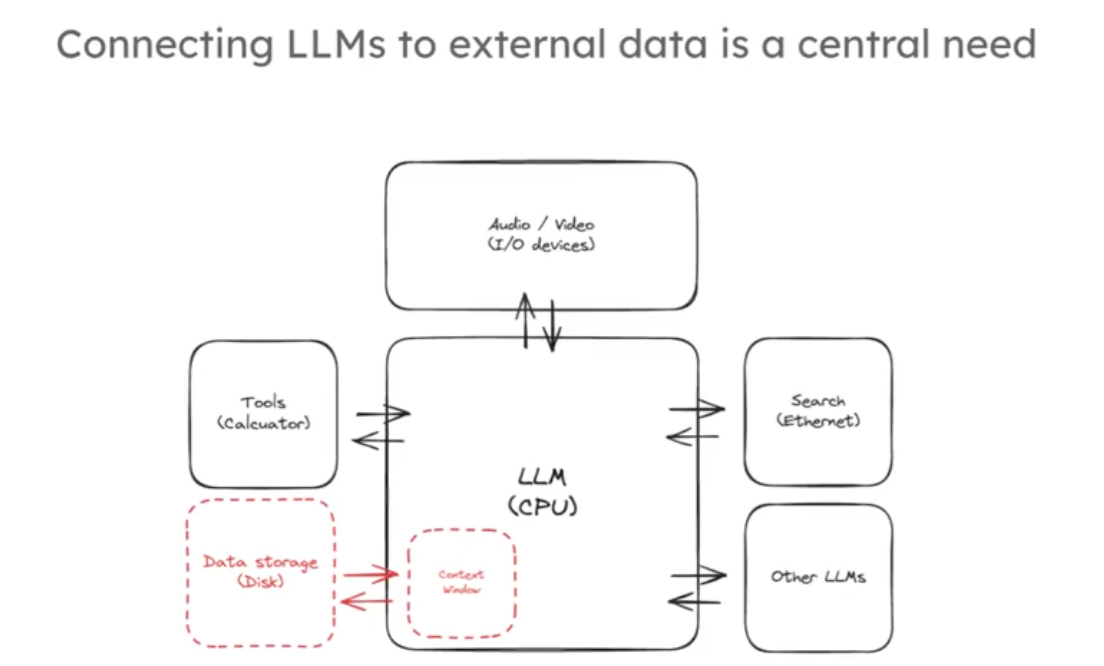
RAG(Retrieval Augmented Generation)是实现这一目标的通用范式,RAG管道组成的三个部分通常包括:索引、检索、生成三个部分。这三个阶段,索引是对外部文档进行处理以便根据查询轻松检索;检索是根据输入查询获取相关文档;生成是将检索到的文档喂给 LLM 以产生基于这些文档的答案,如下图:
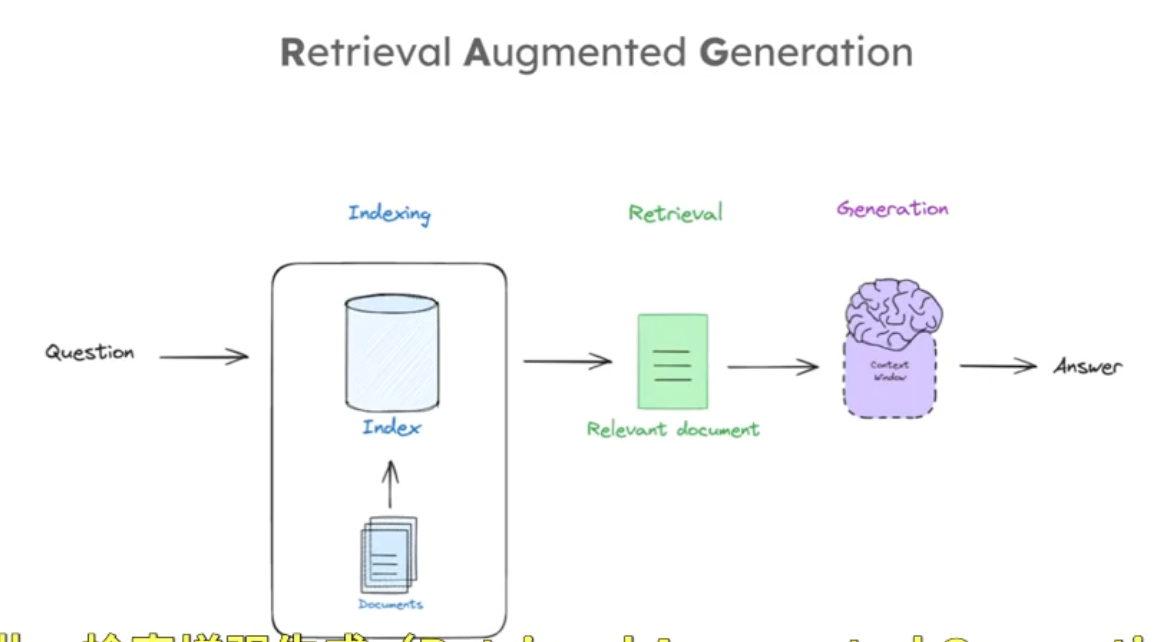
以下是一个RAG过程的简单流程
import bs4
from langchain import hub
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_openai import ChatOpenAI
import os# 先验证环境变量是否加载成功
ali_api_key = os.getenv("DASHSCOPE_API_KEY")
print(ali_api_key)
llm = ChatOpenAI(model="qwen-max-latest",base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",openai_api_key = ali_api_key,temperature = 0,
)#respons = llm.invoke("你是谁,能帮我解决什么问题")
#print(respons.content)
# 确保正确初始化 embedding 模型
embedding_model = DashScopeEmbeddings(model="text-embedding-v4",dashscope_api_key=os.getenv("DASHSCOPE_API_KEY") # 显式传递 API 密钥
)#### INDEXING ##### Load Documents
loader = WebBaseLoader(web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),bs_kwargs=dict(parse_only=bs4.SoupStrainer(class_=("post-content", "post-title", "post-header"))),requests_kwargs={"headers": {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3"}}
)
docs = loader.load()
# Split
from langchain_chroma import Chroma
# 初始化 RecursiveCharacterTextSplitter 实例
# chunk_size=1000 表示每个文本块的最大字符数为 1000
# chunk_overlap=200 表示相邻文本块之间重叠的字符数为 200,这有助于保持上下文的连贯性
text_splitter = RecursiveCharacterTextSplitter(chunk_size=300, chunk_overlap=50)# 调用 text_splitter 的 split_documents 方法,将文档列表 docs 分割成多个较小的文本块
# 分割后的文本块存储在 splits 列表中
splits = text_splitter.split_documents(docs)# 创建空集合
# 初始化 Chroma 向量数据库实例,使用 embedding_model 作为嵌入函数
# 嵌入函数用于将文本转换为向量表示,以便在向量数据库中存储和检索
vectorstore = Chroma(embedding_function=embedding_model)# 手动分批次添加文档(每次最多10个)
# 使用 for 循环和 range 函数,以 10 为步长遍历 splits 列表
for i in range(0, len(splits), 10):# 从 splits 列表中截取当前批次的文档,每次最多 10 个batch = splits[i:i+10]# 调用 vectorstore 的 add_documents 方法,将当前批次的文档添加到向量数据库中vectorstore.add_documents(documents=batch)# 调用 vectorstore 的 as_retriever 方法,将向量数据库转换为检索器
# 检索器可以根据输入的查询向量,从向量数据库中检索出相关的文档
retriever = vectorstore.as_retriever()
# Prompt
prompt = hub.pull("rlm/rag-prompt")
print(prompt)# Post-processing
# 定义一个名为 format_docs 的函数,用于对文档列表进行后处理
# 参数 docs 是一个包含文档对象的列表,每个文档对象应有 page_content 属性
def format_docs(docs):# 使用生成器表达式遍历 docs 列表中的每个文档对象,获取其 page_content 属性# 然后使用 \n\n 作为分隔符将所有文档的内容连接成一个字符串并返回return "\n\n".join(doc.page_content for doc in docs)# Chain
# 构建一个可运行的链式结构 rag_chain,用于执行问答任务
rag_chain = (# 构建一个字典,包含两个键值对# "context" 键对应的值是一个链式操作,先通过 retriever 检索相关文档,# 再将检索到的文档列表传递给 format_docs 函数进行格式化# "question" 键对应的值是 RunnablePassthrough(),表示直接传递输入的问题{"context": retriever | format_docs, "question": RunnablePassthrough()}# 将上述字典作为输入传递给 prompt,生成提示信息| prompt# 将生成的提示信息传递给大语言模型 llm,获取模型的回答| llm# 使用 StrOutputParser() 对大语言模型的输出进行解析,提取纯文本内容| StrOutputParser()
)# Question
# 调用 rag_chain 的 invoke 方法,传入问题 "What is Task Decomposition?"
# 执行整个问答流程,最终返回关于 "任务分解是什么" 的答案
rag_chain.invoke("What is Task Decomposition?")
实际上围绕着索引、检索和生成这三个组件,衍生出很多有趣的方法和技巧,如下图:
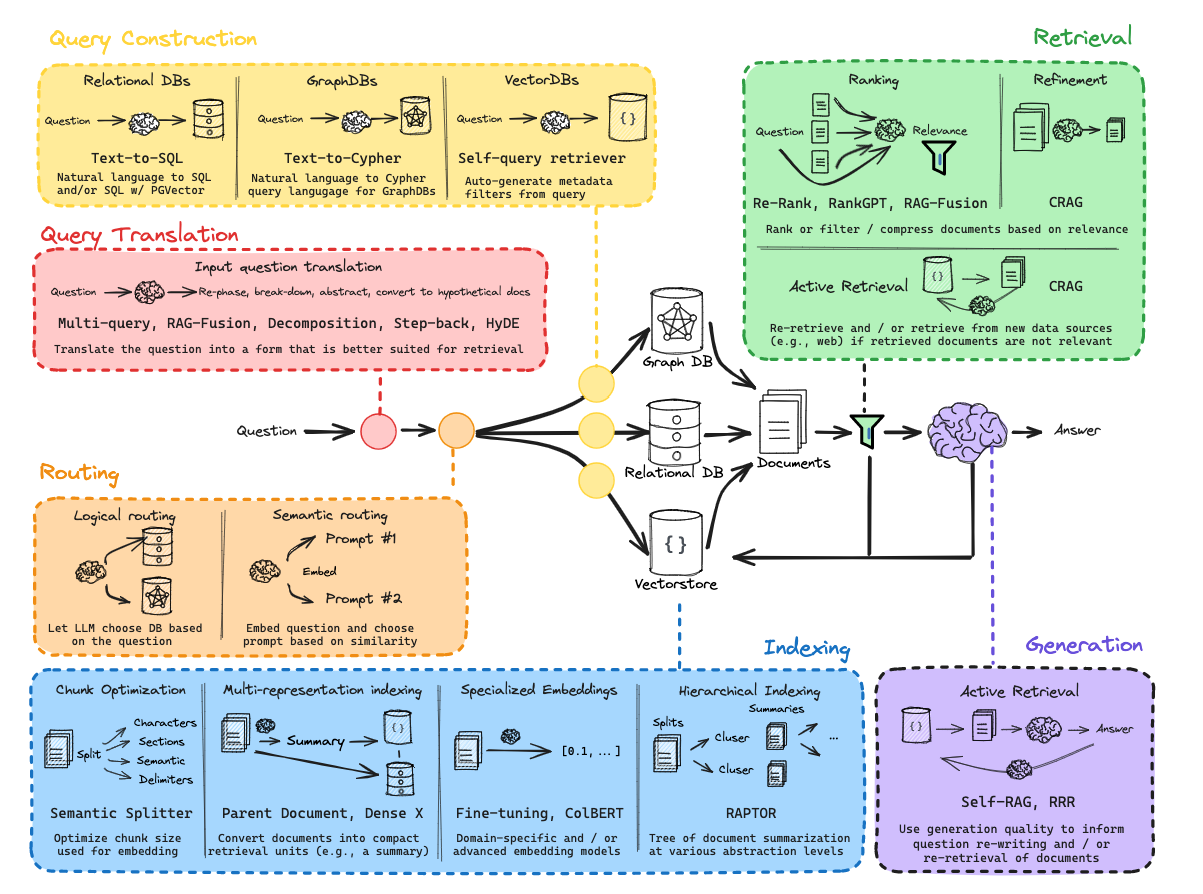
首先我们先从检索器开始,索引是 RAG(检索增强生成)系统堆栈管道的核心环节之一,指将外部文档(如网页、论文、本地文件等)进行处理(如分割、转换为数值向量等),使其转化为可被高效检索的形式,并存储起来的过程。其核心是将非结构化的文本信息转化为结构化、可计算的格式(如向量),为后续检索做准备。
索引的作用
1.适配检索需求:外部文档通常是原始文本,直接用于检索效率极低。索引通过分割文档(因嵌入模型上下文窗口有限)、将文本转换为向量(捕捉语义信息)等操作,使文档能被快速匹配和检索。
2.支撑语义匹配:索引过程中,文档会被嵌入为固定长度的向量(如视频中提到的 1536 维向量),这些向量编码了文本的语义含义,便于通过余弦相似性等数值方法与问题向量进行比较,从而找到相关文档。
3.连接外部知识与检索器:索引将外部文档 “加载” 到向量存储中,并与原始文档关联,为检索器提供可查询的 “知识库”,使检索器能基于输入问题精准定位相关信息。
索引与检索器的关系
索引是检索器的 “前置依赖”,二者是 “准备” 与 “使用” 的关系:
- 索引为检索器提供数据基础:索引处理后的文档(以向量形式存储)是检索器的核心数据源。没有索引,检索器无法高效获取和匹配外部文档。
- 检索器依赖索引实现功能:检索器的核心任务是根据输入问题,从索引后的向量存储中找到最相关的文档片段。它通过将问题也转换为向量,与索引中的文档向量进行数值比较(如余弦相似性),完成 “检索相关文档” 的过程
首先要对文档进行数值表示,建立文档与问题的关系通常使用文档的数值表示,因为对于计算机来说向量(数字)容易比较,相对随意文本更便于处理。
文档压缩为数值表示的方法有哪些:多年来有多种方法将文本文档压缩为可轻松搜索的数值表示,
1,谷歌等公司开发的统计方法,通过查看单词频率构建稀疏向量,向量位置对应大词汇表,值代表单词出现次数,因词汇表庞大而稀疏;
2,还有较新的机器学习嵌入方法,将文档构建为压缩的固定长度表示,有强大的对应搜索方法。
由于嵌入模型有受限的上下文窗口输入,所以通常将大文档分割成小部分来输入限制,每个分割部分通过嵌入模型转化为向量作为文档的数值表示,然后通将向量和原始文档的片段链接一起存储在我们的向量存储中,一般是向量数据库比如chroma,Faiss等数据库,其中向量作为做为索引存储的。
如下图:
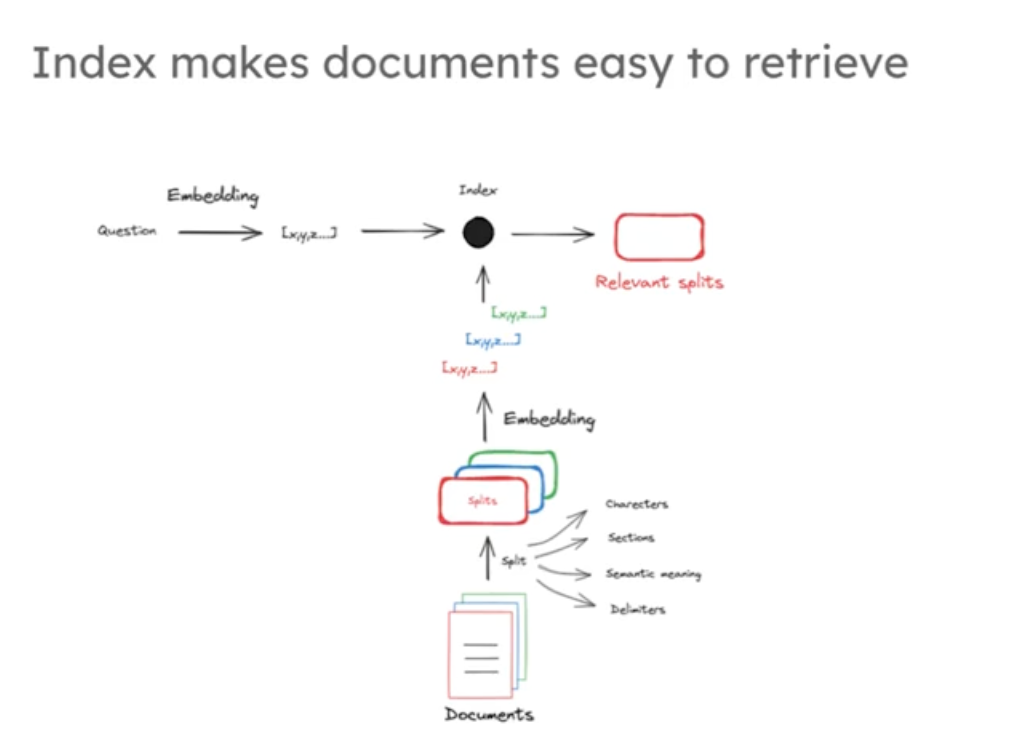
index过程代码
# Documents
question = "What kinds of pets do I like?"
document = "My favorite pet is a cat."
import tiktoken
#返回文本字符串中的 token 数量。
def num_tokens_from_string(string: str, encoding_name: str) -> int:"""Returns the number of tokens in a text string."""encoding = tiktoken.get_encoding(encoding_name)num_tokens = len(encoding.encode(string))return num_tokens
# 调用 num_tokens_from_string 函数,计算变量 question 中的文本使用 "cl100k_base" 编码后的 token 数量
num_tokens_from_string(question, "cl100k_base")from langchain_community.embeddings import DashScopeEmbeddings
# 确保正确初始化 embedding 模型
embd = DashScopeEmbeddings(model="text-embedding-v4",dashscope_api_key=os.getenv("DASHSCOPE_API_KEY") # 显式传递 API 密钥
)
query_result = embd.embed_query(question)
document_result = embd.embed_query(document)#文本转向量
len(query_result)import numpy as npdef cosine_similarity(vec1, vec2):"""计算两个向量之间的余弦相似度。余弦相似度是通过计算两个向量的夹角余弦值来评估它们的方向相似性。取值范围在 -1 到 1 之间,值越接近 1 表示两个向量越相似,值越接近 -1 表示两个向量越不相似,值为 0 表示两个向量正交。参数:vec1 (array-like): 第一个输入向量。vec2 (array-like): 第二个输入向量。返回:float: 两个向量的余弦相似度。"""# 计算两个向量的点积dot_product = np.dot(vec1, vec2)# 计算第一个向量的 L2 范数(欧几里得范数)norm_vec1 = np.linalg.norm(vec1)# 计算第二个向量的 L2 范数(欧几里得范数)norm_vec2 = np.linalg.norm(vec2)# 计算并返回余弦相似度return dot_product / (norm_vec1 * norm_vec2)
# 调用 cosine_similarity 函数计算 query_result 和 document_result 两个向量的余弦相似度
similarity = cosine_similarity(query_result, document_result)
# 打印计算得到的余弦相似度
print("Cosine Similarity:", similarity)#### INDEXING ##### Load blog
import bs4
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader(web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),bs_kwargs=dict(parse_only=bs4.SoupStrainer(class_=("post-content", "post-title", "post-header"))),
)
blog_docs = loader.load()# Split
# 从 langchain 库中导入 RecursiveCharacterTextSplitter 类
# 该类用于将文本递归地按字符分割成较小的块
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(# 每个文本块的最大 token 数量为 300chunk_size=300, # 相邻文本块之间重叠的 token 数量为 50,这有助于保持上下文的连贯性chunk_overlap=50)# Make splits
# 调用 text_splitter 实例的 split_documents 方法
# 对 blog_docs 中的文档进行分割,返回分割后的文本块列表
splits = text_splitter.split_documents(blog_docs)from langchain_community.embeddings import DashScopeEmbeddings
from langchain_chroma import Chroma# 确保正确初始化 embedding 模型
embd = DashScopeEmbeddings(model="text-embedding-v4",dashscope_api_key=os.getenv("DASHSCOPE_API_KEY") # 显式传递 API 密钥
)
# vectorstore = Chroma.from_documents(documents=splits,
# embedding=embd)
# # 调用 vectorstore 的 as_retriever 方法,将向量数据库转换为检索器
# # 检索器可以根据输入的查询向量,从向量数据库中检索出相关的文档
# retriever = vectorstore.as_retriever()
# 创建空的 Chroma 向量库
vectorstore = Chroma(embedding_function=embd)
# 手动分批次添加文档,每次最多 10 个
for i in range(0, len(splits), 10):batch = splits[i:i + 10]vectorstore.add_documents(documents=batch)# 调用 vectorstore 的 as_retriever 方法,将向量数据库转换为检索器
# 检索器可以根据输入的查询向量,从向量数据库中检索出相关的文档
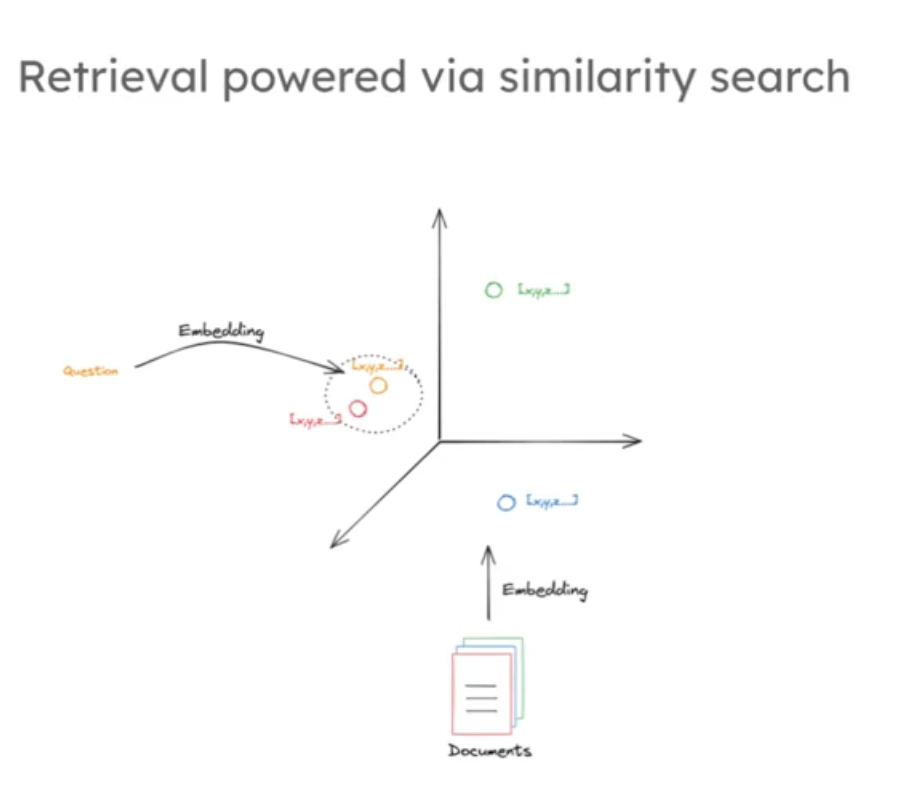
retriever = vectorstore.as_retriever()当给出一个同样经过嵌入处理的问题时,索引会执行相似性搜索,并返回与该问题相似的文档片段。我们可以想象这些向量有三个维度,每个文档片段处理的文档都被映射到三维空间的某个点上,这些点的位置是由不同的文本语义决定的,位于空间中相似位置的文档,其包含的语义也是相似的,这是许多现代向量存储中搜索与检索的基石。同样的将问题嵌入后进行搜索,就和围绕问题开展局部领域搜索一样如下图中黄点是问题,周围的红点是我们的目标文档。
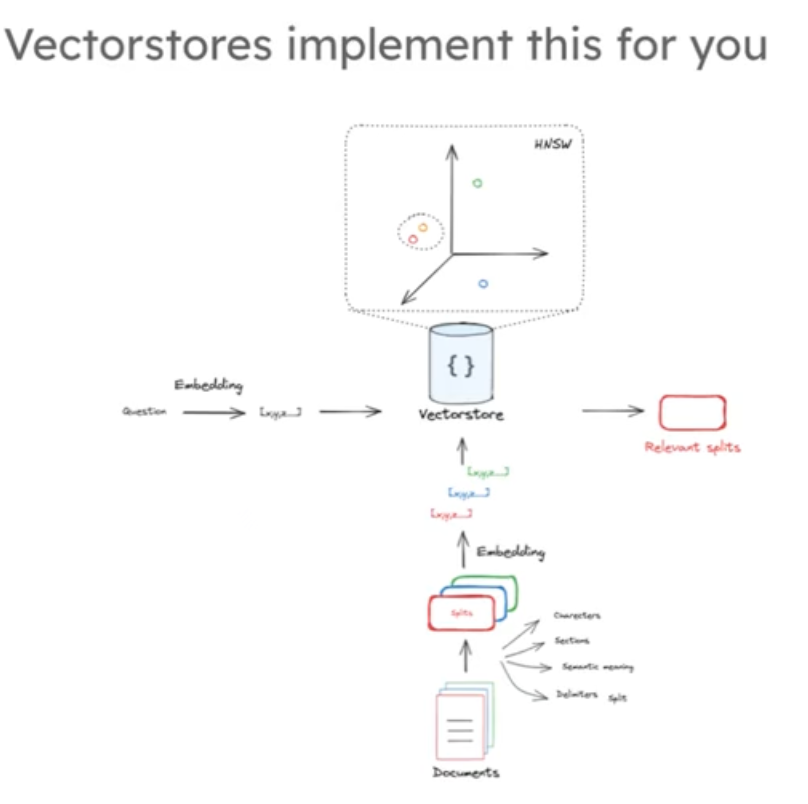
总之,从文档切片到文本嵌入向量化保存到数据库,然后再将问题嵌入向量后进行搜索,获取我们需要的一个或者多个我们需要的文档片段,这是一个完整的流程如下图:
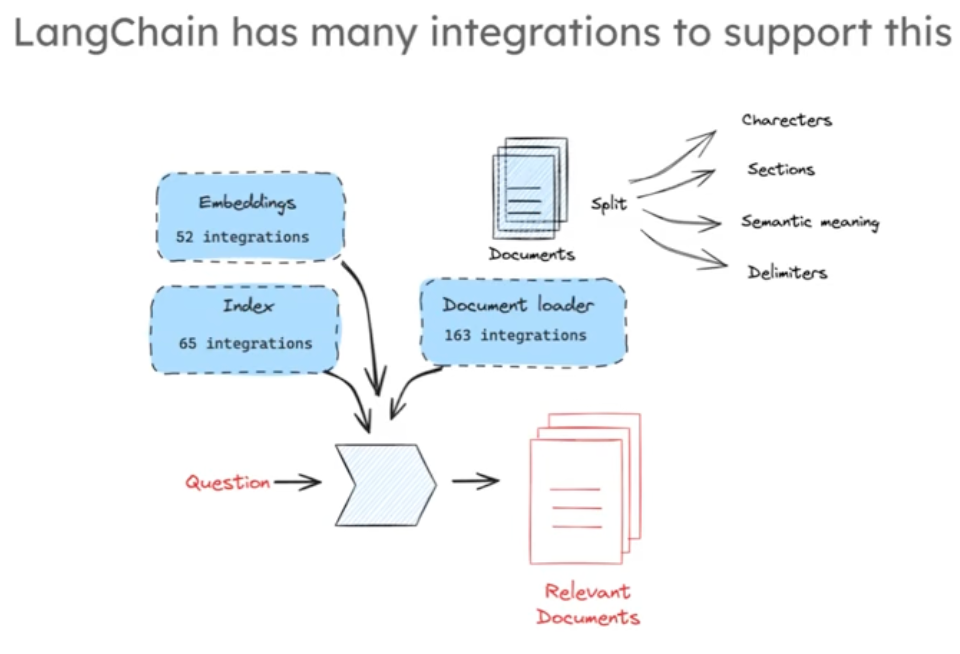
langchain中我们可以找到很多不同的嵌入模型,多样的索引方式,丰富的文档加载器和分割器,我们可以自由组合测试不同的索引和检测方法,来完成这一过程
Retrievel 索引代码
# Index
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
# vectorstore = Chroma.from_documents(documents=splits,
# embedding=embd)
vectorstore = Chroma(embedding_function=embd)
# 手动分批次添加文档,每次最多 10 个
for i in range(0, len(splits), 10):batch = splits[i:i + 10]vectorstore.add_documents(documents=batch)#参数k决定了检索过程中要获取的最近邻的数量
retriever = vectorstore.as_retriever(search_kwargs={"k": 2})
# docs = retriever.get_relevant_documents("What is Task Decomposition?")
docs = retriever.invoke("What is Task Decomposition?")
print(docs)
len(docs)Generation:
接下来我们讨论生成回答的过程
当我们使用KNN,或者k邻近算法从空间索引中寻找到问题相关的文档片段后,我们将这些文档片段整合到大模型的上下文窗口中,从而让大模型生成我们需要的答案,如下图:generation:
from langchain_openai import ChatOpenAI
from langchain.prompts import ChatPromptTemplate# Prompt
template = """Answer the question based only on the following context:
{context}Question: {question}
"""prompt = ChatPromptTemplate.from_template(template)
prompt# Chain
chain = prompt | llm# Run 用于生成回答内容
chain.invoke({"context":docs,"question":"What is Task Decomposition?"})from langchain import hub
prompt_hub_rag = hub.pull("rlm/rag-prompt")
prompt_hub_rag
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
#创建一个基于检索增强生成(RAG)的链式处理流程
# RAG 结合了检索和生成模型的能力,利用外部知识源来回答问题
rag_chain = (# 使用字典来组织输入数据# "context" 键对应的值为 retriever,意味着将输入问题通过检索器获取相关上下文# "question" 键对应的值为 RunnablePassthrough(),表示直接传递输入的问题{"context": retriever, "question": RunnablePassthrough()}# 将组织好的输入数据(包含上下文和问题)传递给提示模板 prompt# prompt 会根据上下文和问题生成适合大语言模型输入的提示文本| prompt
# 将生成好的提示文本传递给大语言模型 llm 进行推理,得到模型的输出| llm
# 使用 StrOutputParser() 对大语言模型的输出进行解析# 该解析器会将模型的输出转换为字符串类型| StrOutputParser()
)rag_chain.invoke("What is Task Decomposition?")


(通过php内置服务器运行php文件))









)
)
操作)
)



