KORGym:评估大语言模型推理能力的动态游戏平台
现有评估基准多受领域限制或 pretraining 数据影响,难以精准测LLMs内在推理能力。KORGym平台应运而生,含50余款游戏,多维度评估,本文将深入解析其设计、框架、实验及发现。
📄 论文标题:KORGym: A Dynamic Game Platform for LLM Reasoning Evaluation
🌐 来源:arXiv:2505.14552v2 [cs.CL] + 链接:https://arxiv.org/abs/2505.14552
近年来,大型语言模型(LLMs)在推理任务上取得显著进展,但现有评估基准存在诸多局限。为此,研究者提出了KORGym这一动态评估平台,旨在更全面、精准地评估LLMs的内在推理能力。
研究背景与动机
当前,推理模型在文本理解、逻辑推理等任务中表现出色,但多数评估基准具有领域特异性,如AIME、PHYBench,无法捕捉通用推理能力。即便一些旨在评估更广泛推理能力的基准,如SuperGPQA、HLE,也受pretraining数据影响较大,难以衡量模型的内在推理技能。
而游戏因其场景多样,在pretraining语料中罕见,成为评估内在推理能力的理想测试床。但现有基于游戏的评估方法存在不足,如LogicGame仅采用单轮场景,无法评估LLMs的长期规划能力;TextArena和SPINBench虽支持多轮场景,但引入的对手动态会产生额外变异性,干扰纯推理评估等。
基于这些问题,研究者提出了KORGym。
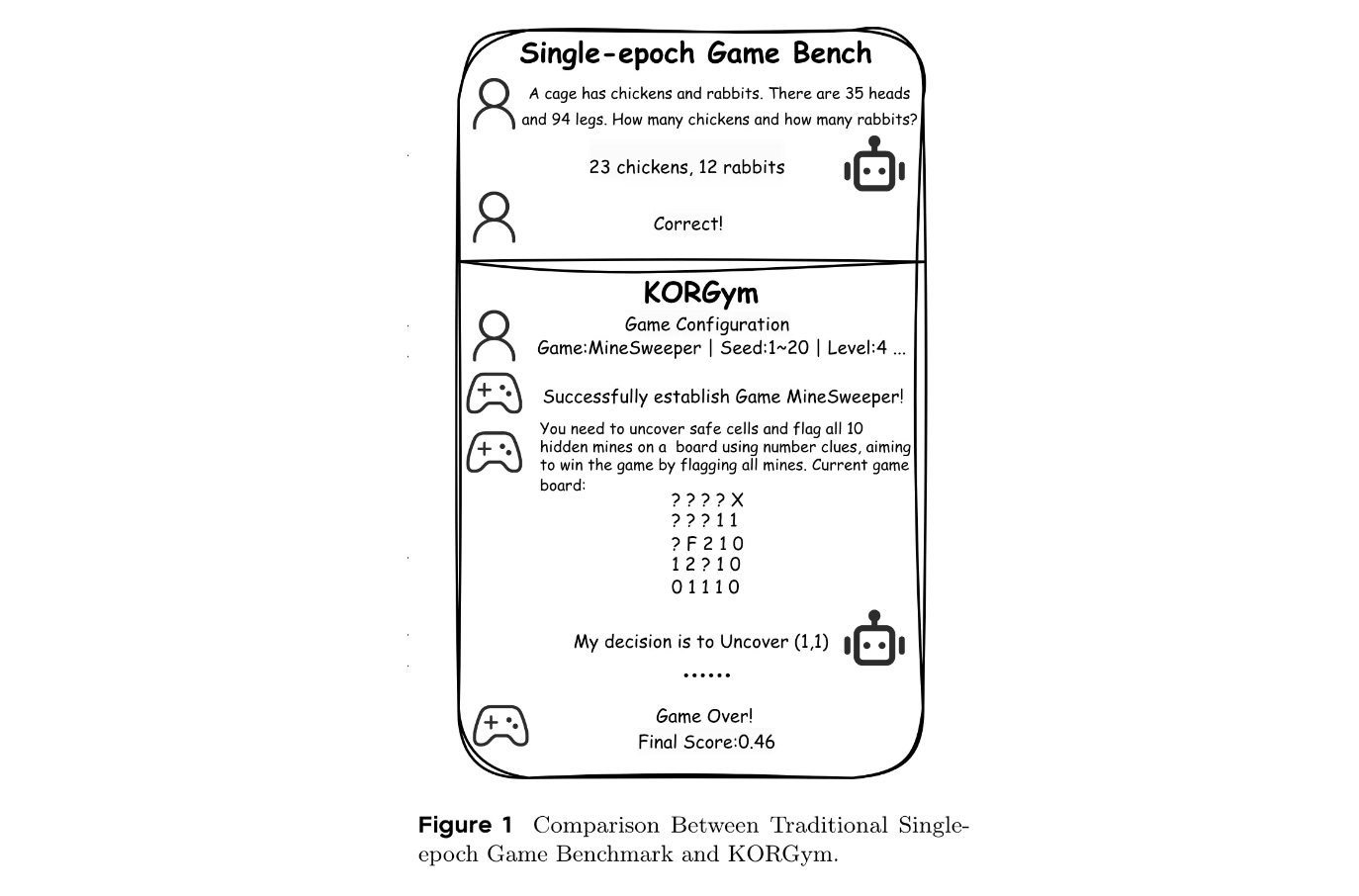
KORGym平台设计
KORGym受KOR-Bench的知识正交推理框架启发,基于Gymnasium构建,包含50余款游戏,涵盖六个推理维度:数学和逻辑推理、控制交互推理、 puzzle推理、空间和几何推理、战略推理以及多模态推理。
平台由四个模块化组件构成:推理模块、游戏交互模块、评估模块和通信模块,支持多轮评估、可配置难度级别和稳定的强化学习支持。
相关工作
- LLMs for Gaming:游戏因对多步推理和战略规划的需求,成为评估LLMs的宝贵测试床。早期研究集中在单一游戏评估,如《我的世界》或社交推理游戏,但这些狭窄的设置限制了通用性。后续虽引入更广泛的基准,但在开放对话、动态合作冲突转换和丰富社会动态等关键维度仍未充分探索。SPINBench通过结合正式规划分析、多智能体合作/竞争和开放式对话,统一了战略规划和社会智能。
- Knowledge Orthogonality Based Evaluation:当前AI推理基准常将记忆与推理混为一谈,难以深入了解潜在认知过程。整合型基准虽推进了对情境问题解决的关注,但仍存在领域特定知识偏差风险。知识正交性概念主张将推理评估与先验知识分离,优先考虑在分布外场景中遵循规则,以隔离核心能力。
方法
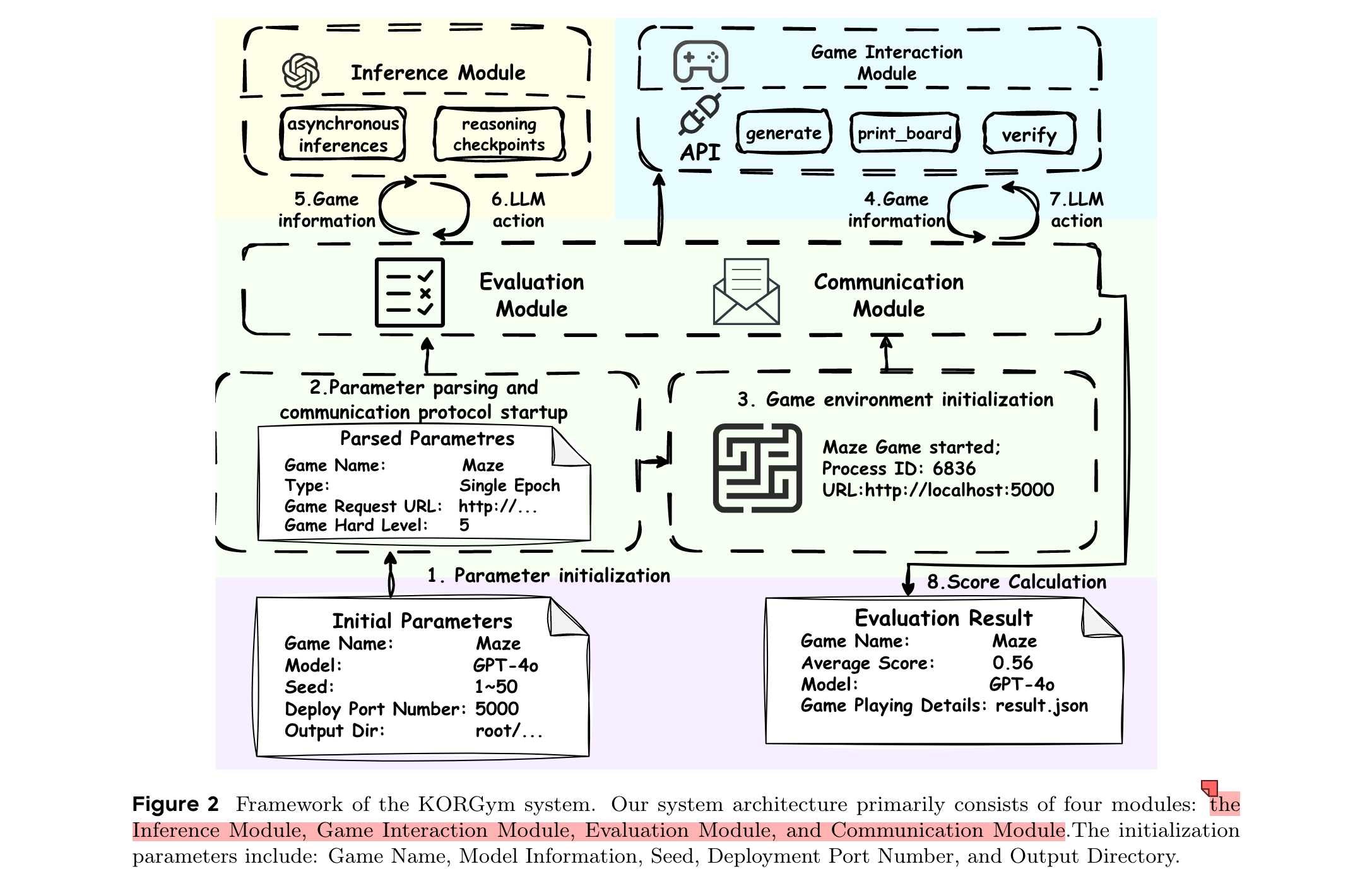
框架
KORGym的系统架构主要包括四个模块:推理模块、游戏交互模块、评估模块和通信模块。初始化参数包括游戏名称、模型信息、种子、部署端口号和输出目录。

任务介绍
KORGym支持50余款新颖游戏,通过六个不同能力维度对LLMs的推理能力进行精确高效评估。这些游戏涵盖传统谜题(如数独)、经典视频游戏改编(如《植物大战僵尸》《扫雷》)、博弈论挑战(如N点、信任进化)和多模态任务(如拼图、圈猫)等。
平台支持通过标准化API进行多轮交互,专为强化学习设计,提供环境状态和奖励信号,用户可通过可扩展参数调整游戏难度和环境多样性,还包括9个多模态游戏,便于在文本和多模态环境中进行综合评估。

评估方法
- 分数计算规则:为解决二元(0/1)评分在反映KORGym中间进度方面的局限性,提出了三种评分方案:二元评分(单目标游戏,成功得1分,失败得0分)、比例评分(选择题游戏,得分等于正确答案数除以选项总数)、累积评分(增量得分游戏,累加所有获得的分数)。
- 能力维度聚合均值:由于原始游戏分数可能超出[0,1]区间,且可能因游戏难度变化或模型异常行为而产生偏差,引入能力维度聚合均值这一更稳健的聚合指标。通过一系列转换和归一化操作,确保每个游戏的模型性能映射到[0,1]范围内,同时保留相对差异,进而得到模型在各推理维度上的表现。
实验
设置
评估了19个大型语言模型(包括11个思维模型和8个指令微调模型)和8个视觉语言模型。评估中,对单轮和多轮游戏采用不同协议:单轮游戏中,通过将“generate”API中的“seed”参数从1变为50,每个模型在50个独立初始化的游戏实例上进行评估;多轮游戏中,每个模型初始化20个游戏环境,每轮允许最多100次交互,并改变“generate”API中的“seed”参数以确保可重复性。所有评估均采用零样本提示设置,保留每个模型的默认采样参数。
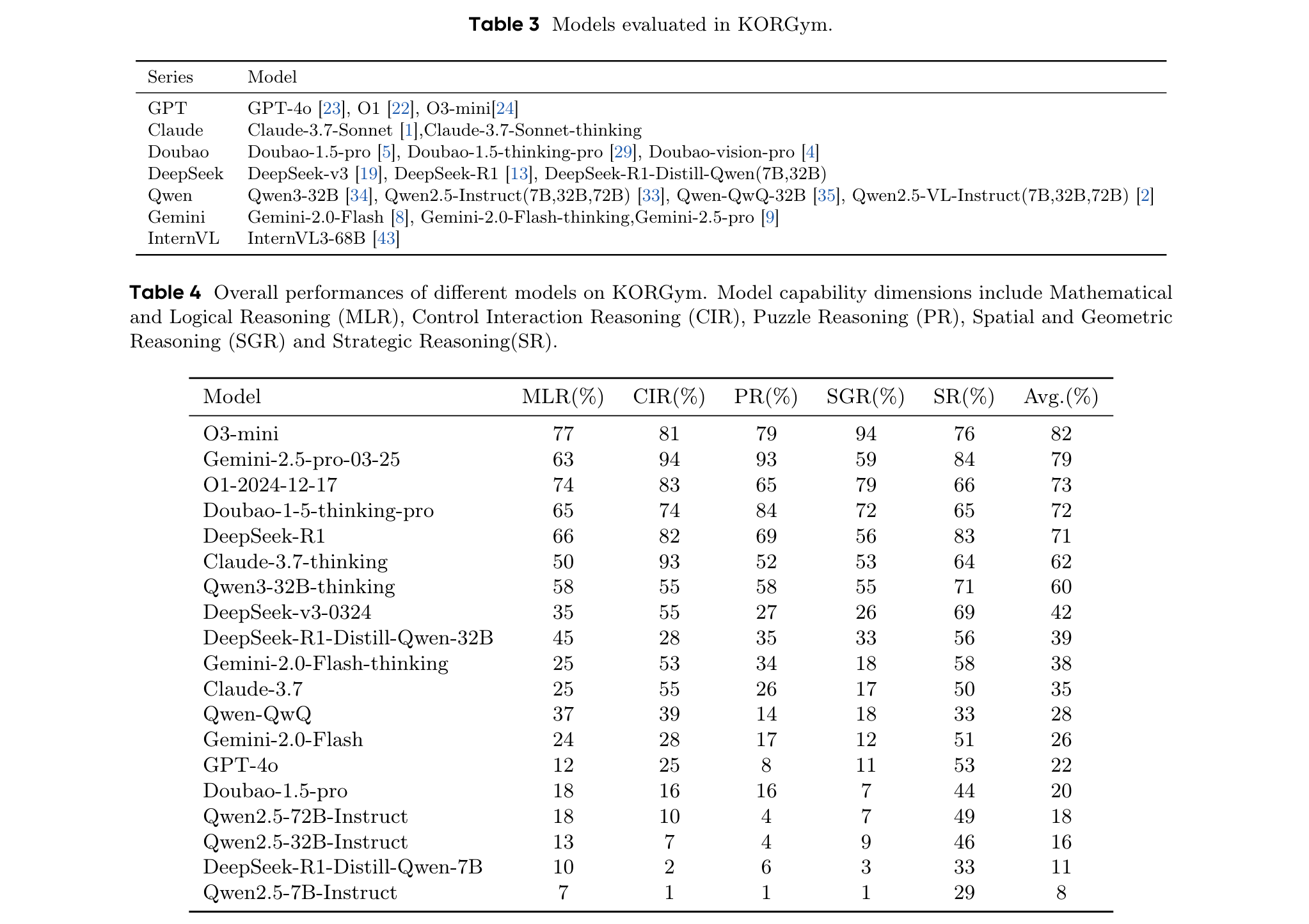
主要结果
- 同一模型系列内的推理能力表现出一致的优势和劣势特征。例如,O1和O3-mini在空间推理方面表现出色,而Gemini系列在数学和puzzle推理方面领先。
- 闭源模型展示出更优的推理性能。O3-mini在KORGym上获得最高综合得分,尤其在空间推理方面;Claude-3.7-thinking和Gemini-2.5-pro在puzzle推理方面表现最佳等。
- 模型规模和架构对推理能力有影响。模型性能随模型大小呈正相关,思维模型优于同等规模的非思维模型。例如,DeepSeek-R1-Distill-Qwen-32B虽规模较小,但性能超过Qwen2.5-72B-Instruct。
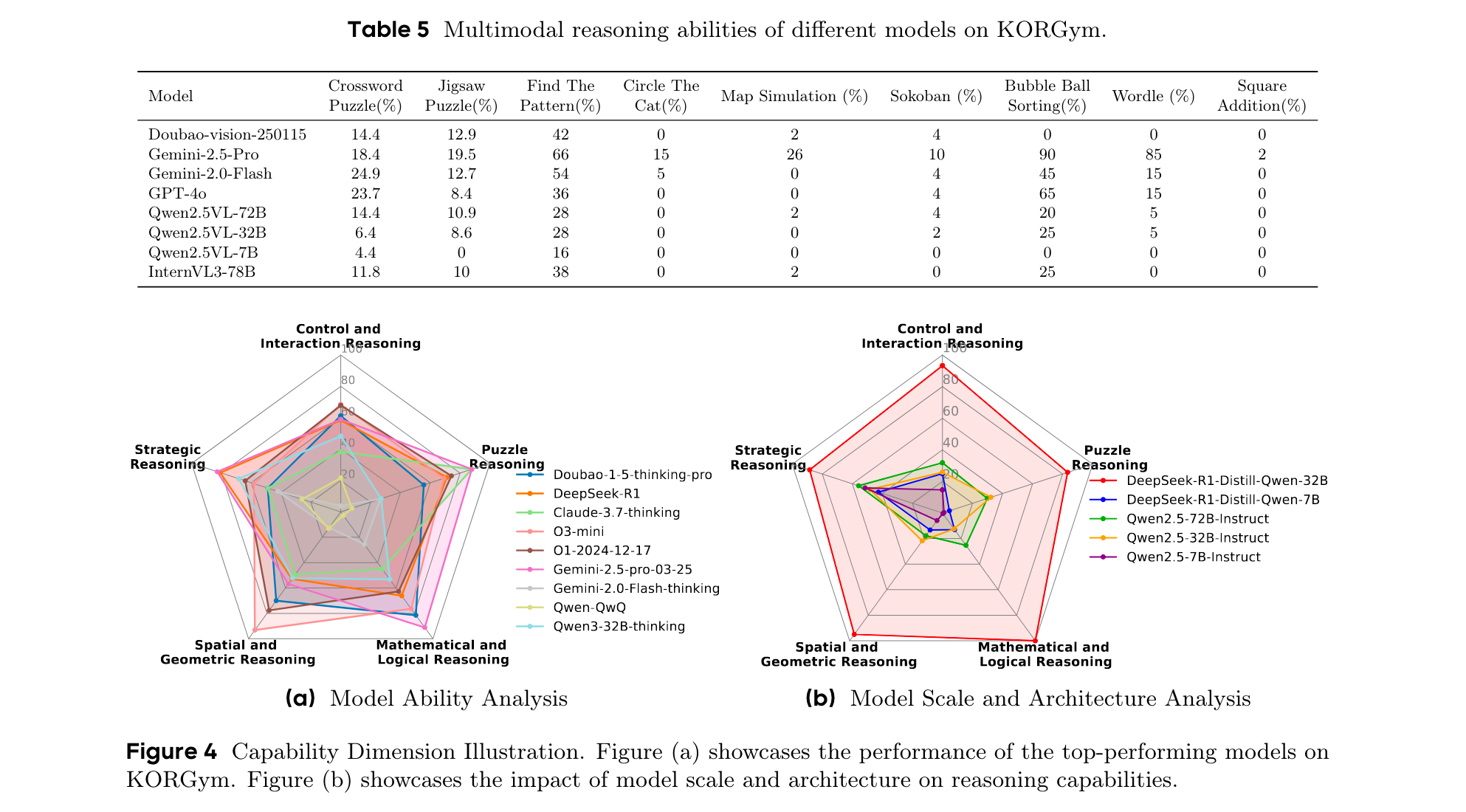
讨论
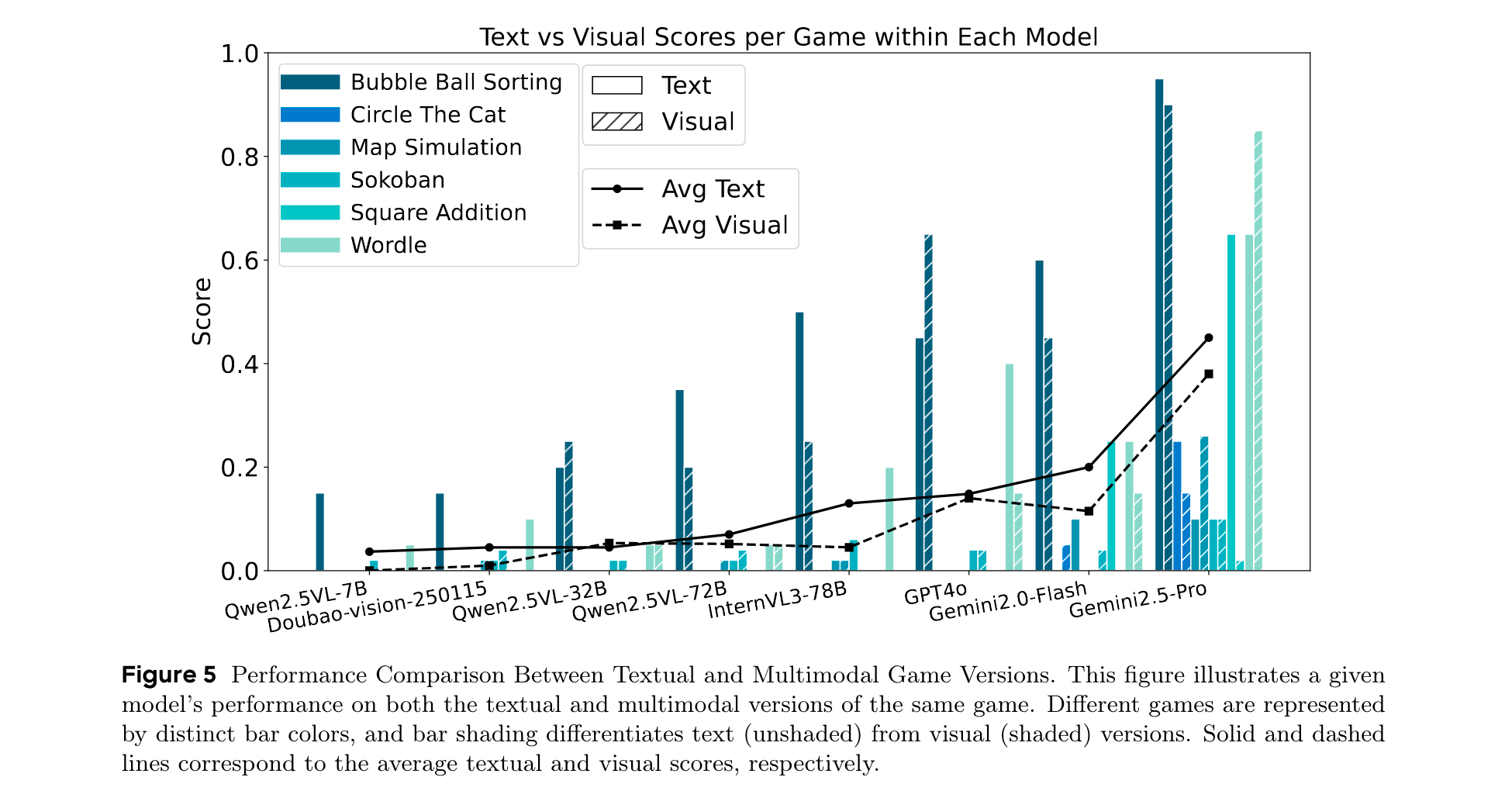
- 模态对推理性能的影响:文本版本游戏的平均得分始终高于视觉版本。开源VLMs在基于文本的推理上比基于视觉的任务表现更好,表明其视觉基础有限或多模态对齐不够完善。一些闭源VLMs在视觉版本上的得分高于文本版本,表明其更强的视觉推理或更优的多模态集成能力。在数学相关游戏中,模型在文本版本上的得分显著更高,凸显了符号表示在数值推理中的优势。
- 不同模型系列是否表现出一致的行为模式:顶级模型在PCA空间中形成紧密集群,表明在所有维度上都具有一致的强推理性能;思维模型和非思维模型表现出不同的行为模式;LLMs在进行分析和问题解决时倾向于采用明确的推理范式,包括代码范式、数学范式、特定算法范式和自然语言推理范式。

- 强化学习对问题解决能力的影响:在多轮强化学习微调中,特定模型结合专门的算法框架,并在综合语料库上训练,在KORGym中,强化学习驱动的增强在各个推理维度上都带来了显著收益。
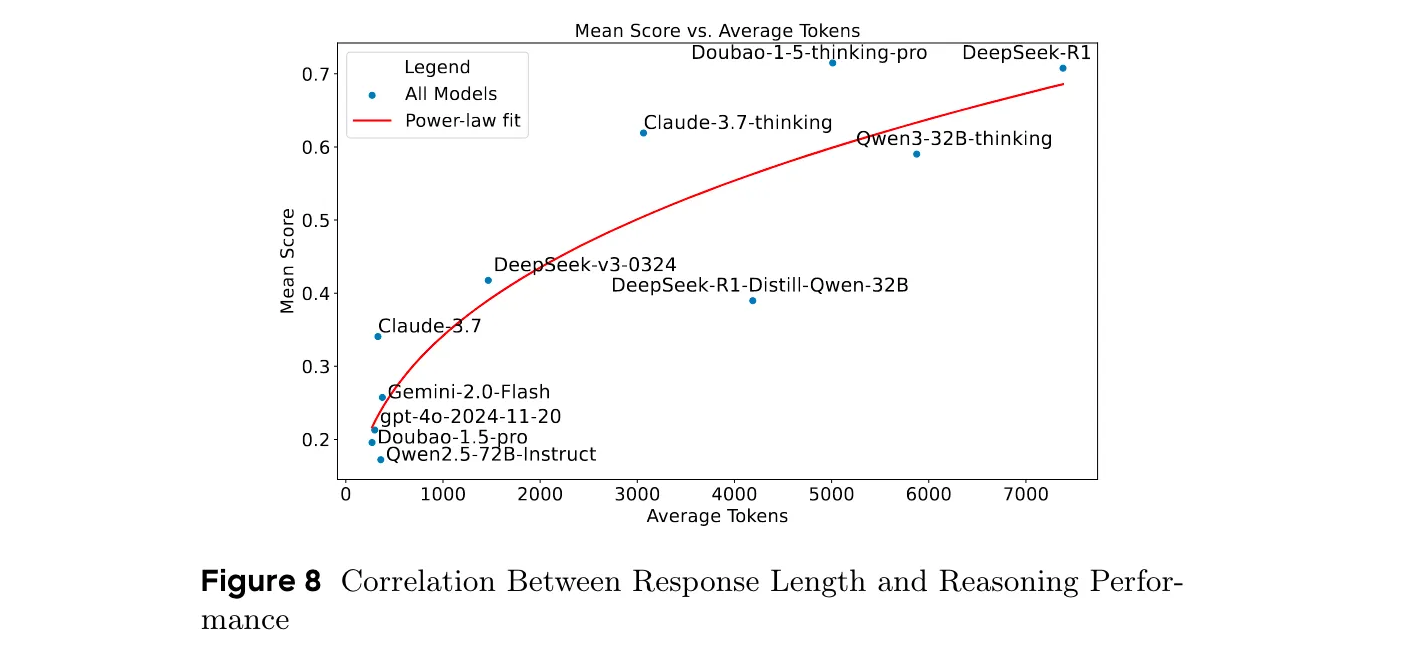
- 响应长度与推理性能的相关性:推理性能与响应长度呈强正相关,推理模型和非推理模型在响应长度分布上有显著差异,响应长度对性能的影响存在边际效益递减现象。
总结
KORGym是一个可扩展的、基于游戏的基准,包含50多个跨越六个推理维度的任务。它支持多模态交互、强化学习和参数化环境,并采用基于维度感知分数聚合的稳健评估方法。通过对19个LLMs和8个VLMs的评估,揭示了模型系列内一致的强弱特征,以及模型规模和架构对推理能力的影响等。
















)

![[Python] -项目实战4- 利用Python进行Excel批量处理](http://pic.xiahunao.cn/[Python] -项目实战4- 利用Python进行Excel批量处理)
