py爬虫的话,selenium和reqeusts谁更强,selenium是不是能完全取代requests?
答案基本是可以的,selenium适合动态网页抓取,因为它可以控制浏览器去点击、加载网页,requests则比较适合静态网页采集,它非常轻量化速度快,没有浏览器开销,占用资源少。当然如果不考虑资源占用和速度,selenium是可以替代requests的。
但selenium需要配合一些解锁功能才能发挥作用,因为现在大网站反爬机制非常严格,已经从传统的IP识别升级到行为分析和动态对抗,像是浏览器指纹、验证码(CAPTCHA)、动态加密、异步加载等,一般简单的爬虫技术基本不可能抓取到稳定的电商数据。
所以开发者们需要进行技术伪装、动态IP设置和自动化工具等方法,去测试和调整不同平台的规则,但又必须要保证在法律允许的范围之内进行数据采集。
什么是法律允许的范围呢?首先只能抓取互联网上公开的非隐私数据,不要去破解后台加密数据,也不可以获取用户隐私数据。其次只能在网站合理的承受范围发送http请求,不能对目标网站造成破坏。否则,可能会面临法律风险。
这次我准备结合Python selenium + bright data的组合来采集某跨境电商网站上的智能手机商品数据,并结合AI搭建一个电商商品分析系统,用于监测竞品数据。
当然这个仅供参考学习使用。
1、bright data数据采集技术解读
bright data提供包含网页抓取API、网页解锁器API、网页抓取浏览器、SERP API等在内的自动化产品。这些产品能解决什么问题呢?像你在爬虫过程中遇到的人机验证、验证码、动态页面、浏览器指纹验证等问题,这些都有针对性的解决技术。
https://get.brightdata.com/webscra
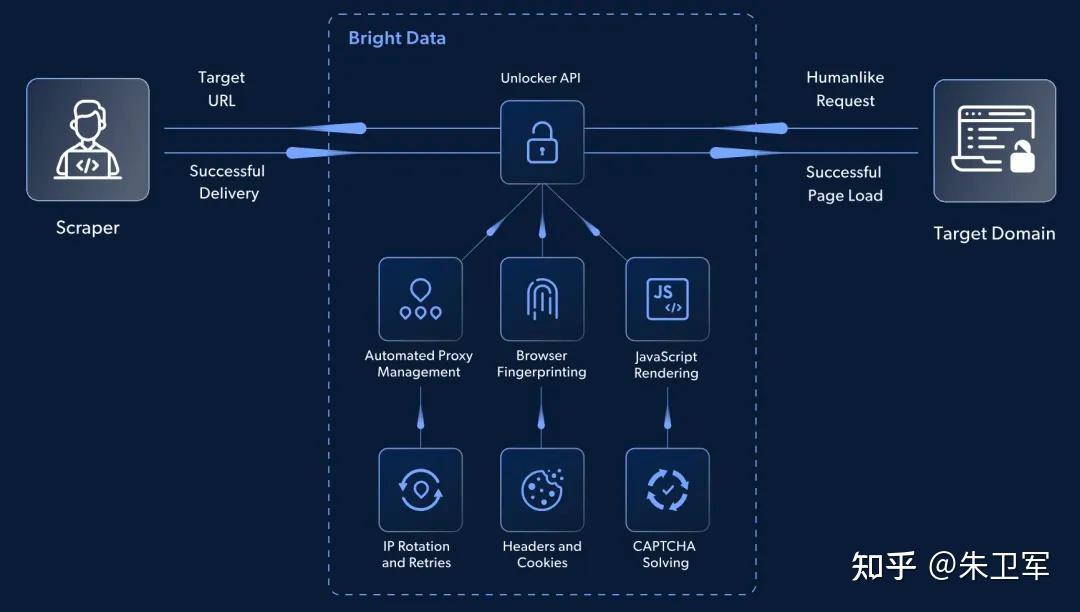
就拿这次我用的Scraping Browser来举例,Scraping Browser是数据采集浏览器的意思,它是bright data提供的云浏览器,是有图形界面的有头浏览器,托管在亮数据平台上。它的工作原理和普通自动化浏览器一样,能通过Selenium、Playwright等自动化API来操作采集数据,适合交互频繁的动态网页,执行各种点击、加载等操作。
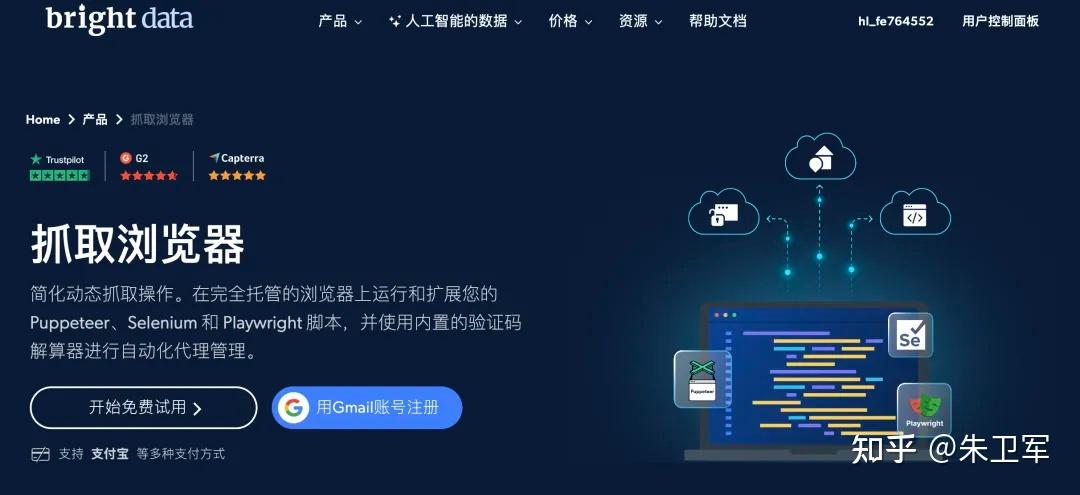
但是Scraping Browser封装了代理和网站解锁能力,能进行各种高级爬虫操作,比如:CAPTCHA 识别、浏览器指纹、自动重试、请求头选择、处理 cookies、JavaScript 渲染等,对于反爬机制复杂的网站非常适用。
2、使用Scraping Browser采集商品数据
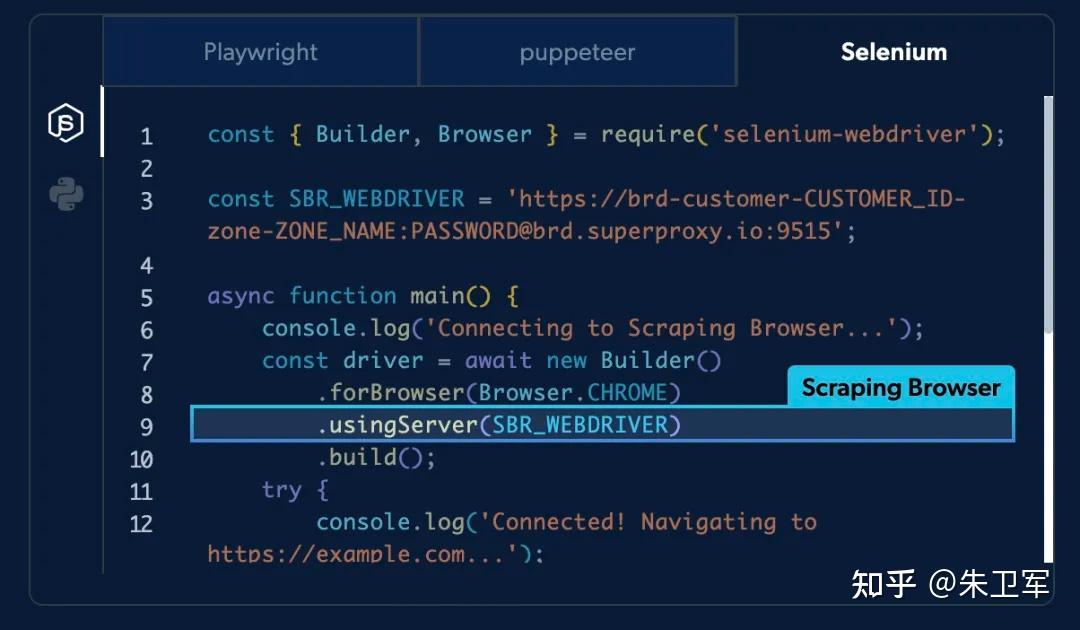
首先这次测试的采集目标是某跨境电商网站的智能手机商品数据,基于Scraping Browser服务,使用Python Selenium库来请求和解析数据,Selenium是主流的浏览器自动化工具,也支持其API接口,操作起来比较方便。
第一步:创建通道
打开bright data,然后打开后台控制面板界面,找到“浏览器API“,创建新的通道。
https://get.brightdata.com/webscra
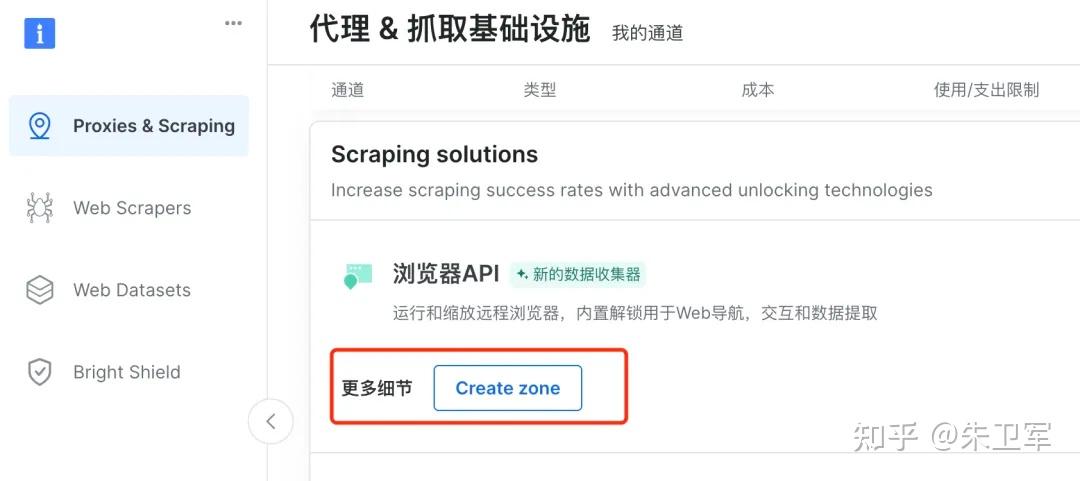
第二步:设置“浏览器API“相关参数
给新通道起一个任务名称,比如ecommerce_task
接着勾选CAPTCHA 解决器,它能帮你自动识别和解锁各种验证码,非常省心。
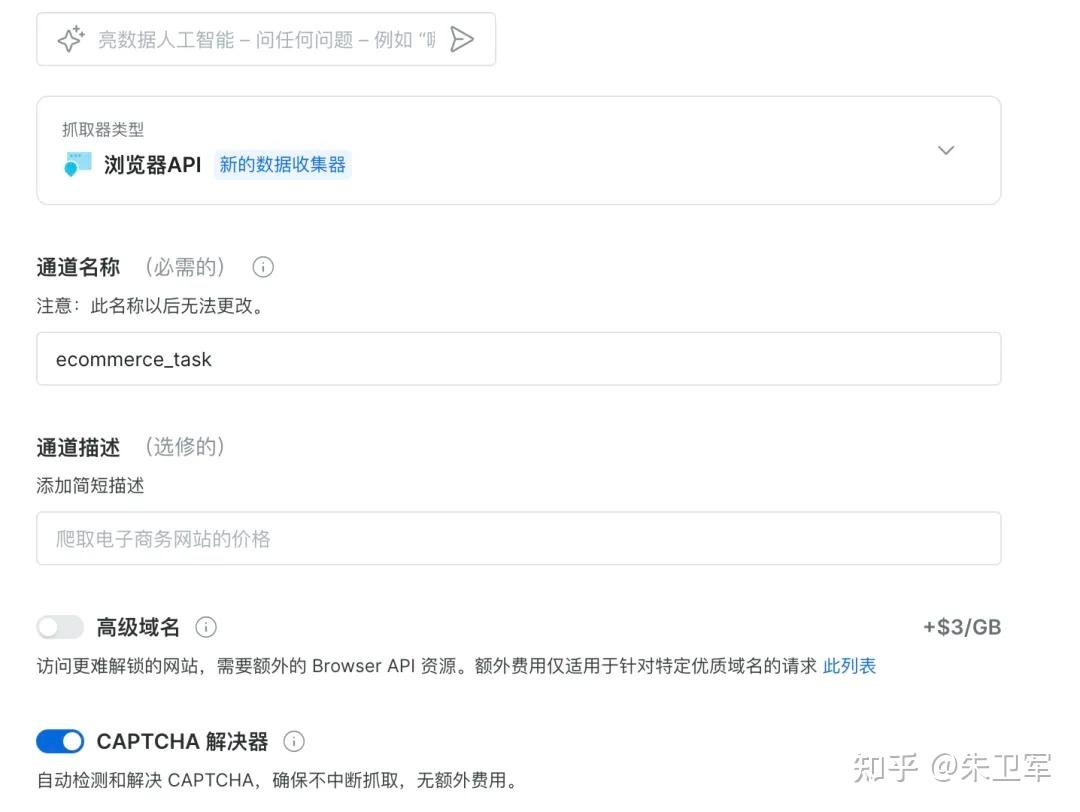
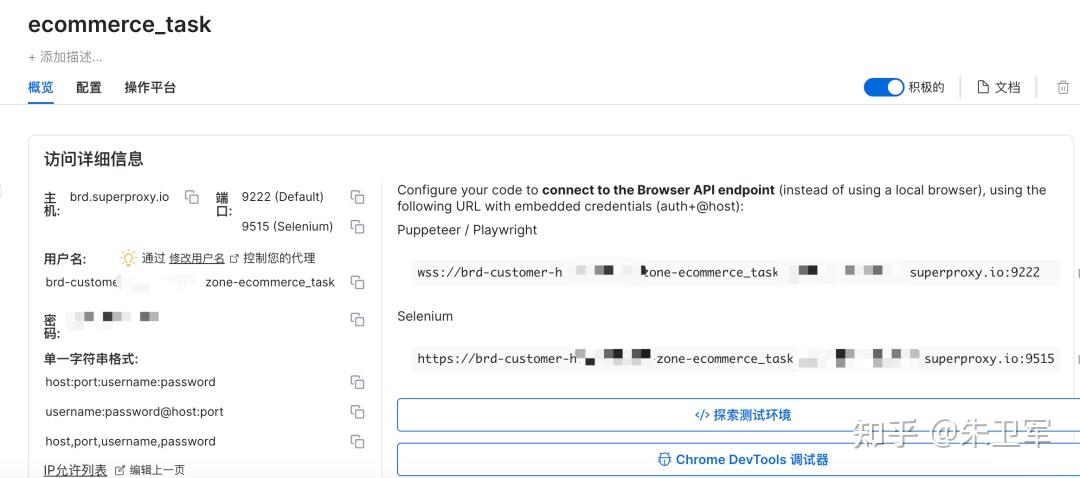
最后点击添加,即创建了一个新通道ecommerce_task。
新通道会有用户名、密码,以及Selenium对应的端口,要记住和保密。
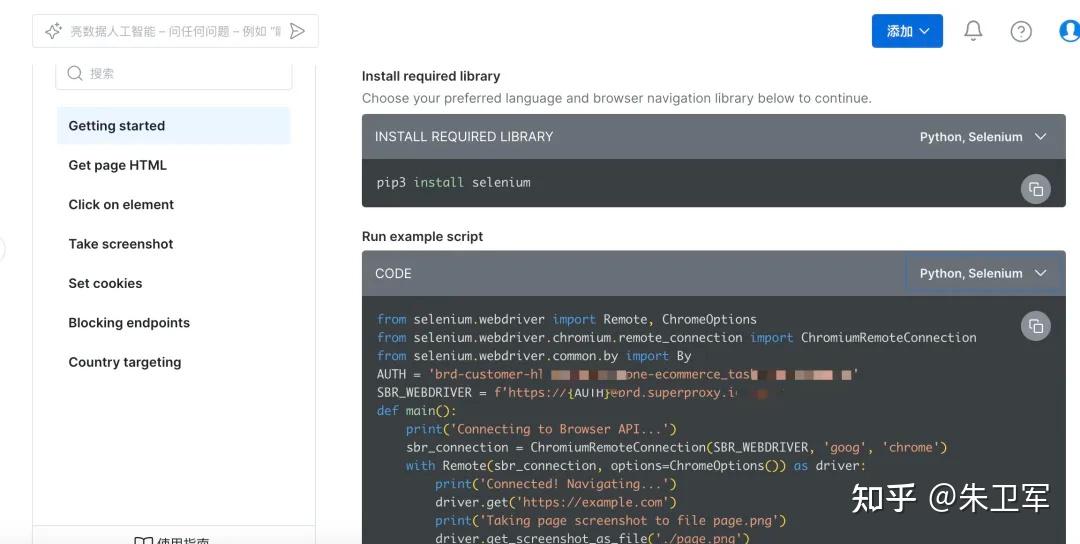
在操作平台里,你能找示例代码,比如这次用到的Selenium,我们就直接改改示例请求代码用于抓取商品数据。
第三步:编写脚本,采集数据
这次直接抓取某跨境电商网站搜索页的智能手机商品,搜索关键词为:smart phone,采集的字段有:商品名称(name)、商品价格(price)、商品来源地(location),因为是示例爬虫,所以只选重要的的几个字段。
https://get.brightdata.com/webscra
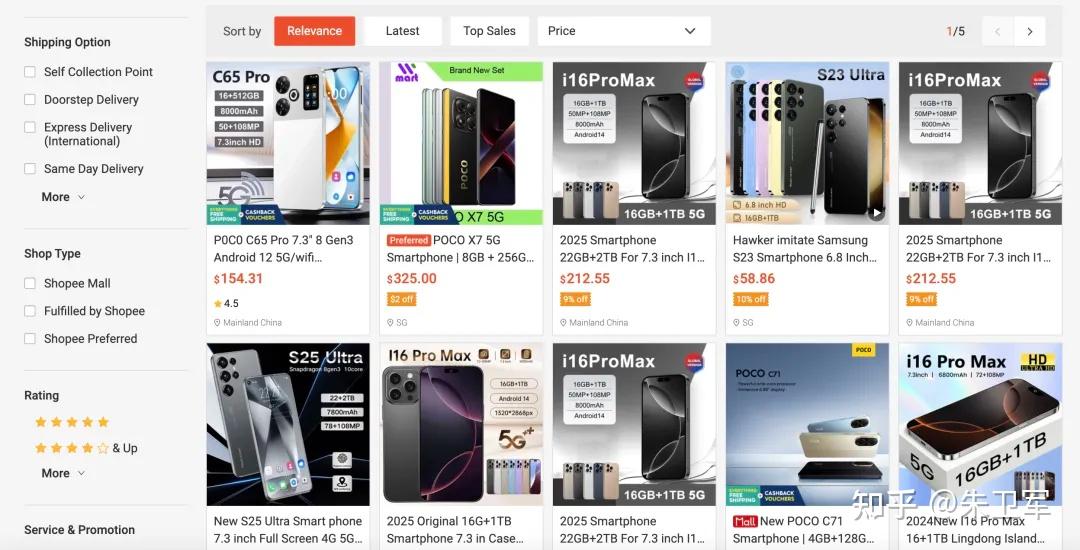
采集好数据后,保存到本地CSV文件中,用于后续分析。
示例代码如下:
# 本案例仅用于技术研究,遵守《网络安全法》第27条与目标网站robots.txt协议,采样频率控制在5次/分钟以下,单日采集量不超过1000条from selenium.webdriver import Remote, ChromeOptions
from selenium.webdriver.chromium.remote_connection import ChromiumRemoteConnection
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
import csv# ==== 请替换为你的 Bright Data 授权信息 ====
AUTH = '你的账号接口地址'
SBR_WEBDRIVER = f'https://{AUTH}@brd.superproxy.io:9515'def main():print('正在连接Scraping Browser...')# 建立远程连接sbr_connection = ChromiumRemoteConnection(SBR_WEBDRIVER, 'goog', 'chrome')opts = ChromeOptions()# 可选:开启无头模式# opts.add_argument('--headless')with Remote(sbr_connection, options=opts) as driver:print('已连接! 导航到Shopee...')# 1)打开 Shopee 手机搜索页url = 'https://shopee.sg/search?keyword=smart%20phone'driver.get(url)# 2)等待商品列表渲染完成:等待每个“商品卡片”出现wait = WebDriverWait(driver, 80)item_selector = 'li[data-sqe="item"]'wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, item_selector)))# 3)滚动以加载更多(如果需要懒加载,可根据实际情况调整)driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")time.sleep(2)# 4)再一次抓取商品卡片items = driver.find_elements(By.CSS_SELECTOR, item_selector)print(f'定位到 {len(items)} 个商品卡片,开始抓取…')# 5)准备存储结果results = []for itm in items:try:# 商品名称name = itm.find_element(By.CSS_SELECTOR, 'div.line-clamp-2').text.strip()# 价格(带币种符号)price = itm.find_element(By.CSS_SELECTOR, 'span.font-medium.text-base\\/5').text.strip()# 商品来源地location = itm.find_element(By.CSS_SELECTOR, 'span.ml-\[3px\]').text.strip()except Exception as e:# 若某个字段缺失则跳过print(f'⚠️ 解析失败:{e}')continueresults.append({'name': name,'price': price,'location': location})# 6)输出到 CSVout_file = 'shopee_mobile_phones.csv'keys = ['name', 'price', 'location']with open(out_file, 'w', newline='', encoding='utf-8-sig') as f:writer = csv.DictWriter(f, fieldnames=keys)writer.writeheader()for row in results:writer.writerow(row)print(f'完成:共抓取 {len(results)} 条,已保存至 {out_file}')if __name__ == '__main__':main()
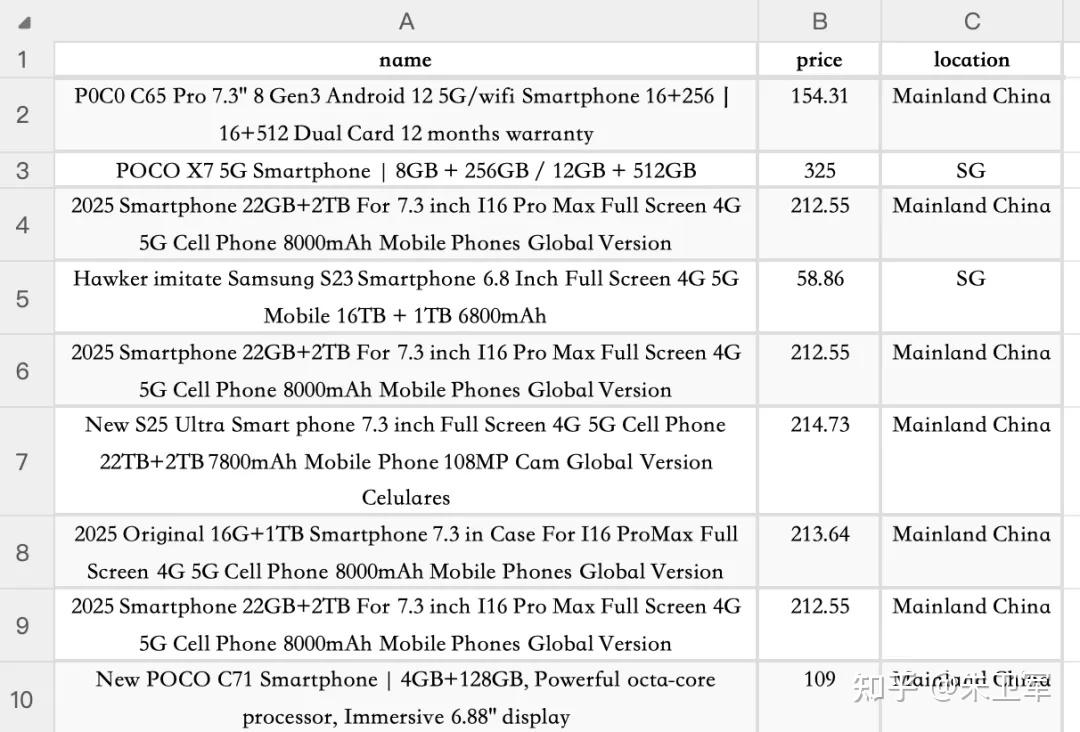
最终采集数据保存到CSV文件中,部分数据如下:
注:name代表商品名称,price是售价(新加坡元)、location是来源地。
❞
该跨境电商网站是对爬虫监测比较严的平台,会要求各种验证,Scraping Browser都能轻松解锁,而且搜索结果页异步加载,部分操作(如翻页)需模拟用户点击,也能一并解决。






))
、GitHub Desktop(版本控制工具)、VSCode(代码编辑器))

 sync.Pool)

 选择器详解:为什么它是“父选择器”?如何实现真正的容器查询?)

后训练方法)





)