摘要:利用强化学习(RL)对语言模型(LMs)进行后训练,无需监督微调即可增强其复杂推理能力,DeepSeek-R1-Zero便证明了这一点。然而,要有效利用强化学习训练语言模型,需要进行大规模并行化以扩大推理规模,但这会带来不容忽视的技术挑战(如延迟、内存和可靠性问题),同时还会导致财务成本不断攀升。我们提出了群体采样策略优化算法(Swarm sAmpling Policy Optimization,SAPO),这是一种完全去中心化且异步的强化学习后训练算法。SAPO专为异构计算节点组成的去中心化网络而设计,在该网络中,每个节点管理自己的策略模型,同时与网络中的其他节点“共享”采样轨迹(rollouts);该算法无需对延迟、模型同质性或硬件做出明确假设,且如果需要,节点可以独立运行。因此,该算法避免了强化学习后训练规模化过程中常见的瓶颈问题,同时还开辟了(甚至鼓励探索)新的可能性。通过采样网络中“共享”的轨迹,该算法能够促进“顿悟时刻”的传播,从而引导学习过程。在本文中,我们展示了在可控实验中,SAPO实现了高达94%的累积奖励增益。此外,我们还分享了在一次开源演示中的测试见解,此次测试在一个由Gensyn社区成员贡献的数千个节点组成的网络上进行,社区成员在各种硬件和模型上运行了该算法。Huggingface链接:Paper page,论文链接:2509.08721
研究背景和目的
研究背景:
随着人工智能技术的快速发展,语言模型(LMs)在自然语言处理任务中展现出强大的能力。然而,如何进一步提升语言模型的复杂推理能力,使其能够更好地处理需要深度思考和逻辑推断的任务,成为当前AI研究的重要方向。传统的监督微调方法虽然有效,但往往依赖于大量标注数据,且在处理新颖或复杂任务时表现受限。强化学习(RL)作为一种通过试错来优化模型的方法,为语言模型的后训练提供了新的途径。通过引入奖励机制,RL允许模型在探索和利用过程中不断优化其行为,从而提升复杂推理能力。
然而,将RL应用于语言模型后训练面临诸多挑战。首先,传统的分布式RL方法需要大规模的GPU集群,并且需要保持策略权重的同步,这导致了高昂的财务成本和通信瓶颈。其次,随着模型规模的增大,训练过程中的延迟、内存和可靠性问题变得尤为突出。为了解决这些问题,研究人员开始探索更加高效和可扩展的RL后训练算法。
研究目的:
本研究旨在提出一种全新的、完全去中心化和异步的RL后训练算法——Swarm Sampling Policy Optimization(SAPO),以解决传统分布式RL方法在语言模型后训练中的瓶颈问题。具体目标包括:
- 提高训练效率:通过去中心化和异步的训练方式,减少通信开销和同步等待时间,从而提高整体训练效率。
- 增强模型推理能力:利用集体经验共享机制,使模型能够从其他节点的经验中学习,从而提升复杂推理能力。
- 降低训练成本:避免对大规模GPU集群的依赖,降低硬件和运营成本,使RL后训练更加经济可行。
- 提升模型泛化能力:通过多样化的经验共享,增强模型对不同任务和环境的适应能力,提高泛化性能。
研究方法
1. 去中心化网络构建:
SAPO算法构建在一个去中心化的网络中,该网络由多个异构的计算节点组成,每个节点都管理自己的策略模型。节点之间通过共享解码后的策略输出(即rollouts)来进行经验交流,而不需要保持模型架构、学习算法或硬件的一致性。这种设计使得SAPO算法能够灵活地应用于各种异构环境,包括边缘设备和消费者级硬件。
2. 集体经验共享机制:
在SAPO算法中,每个节点在生成自己的rollouts后,会将其与网络中的其他节点共享。接收节点可以根据需要选择性地采样这些共享的rollouts,并将其与自己的本地rollouts结合,构建训练集。这种集体经验共享机制使得节点能够从其他节点的探索中受益,从而加速学习过程。
3. 策略更新算法:
节点使用本地奖励模型计算训练集上的奖励,并采用策略梯度算法(如PPO或GRPO)来更新自己的策略。这种设计允许每个节点根据自己的需求和资源情况独立地进行策略更新,而不需要与其他节点保持同步。
4. 实验设置:
为了验证SAPO算法的有效性,研究团队使用了八个Qwen2.5模型(每个模型有0.5B参数)构建了一个去中心化网络,并在ReasoningGYM数据集上进行了实验。ReasoningGYM数据集包含代数、逻辑和图推理等多个领域的任务,能够提供多样化的训练和评估任务。实验过程中,节点通过Docker容器进行部署和管理,使用PyTorch的分布式包实现多GPU并行计算。
研究结果
1. 累计奖励提升:
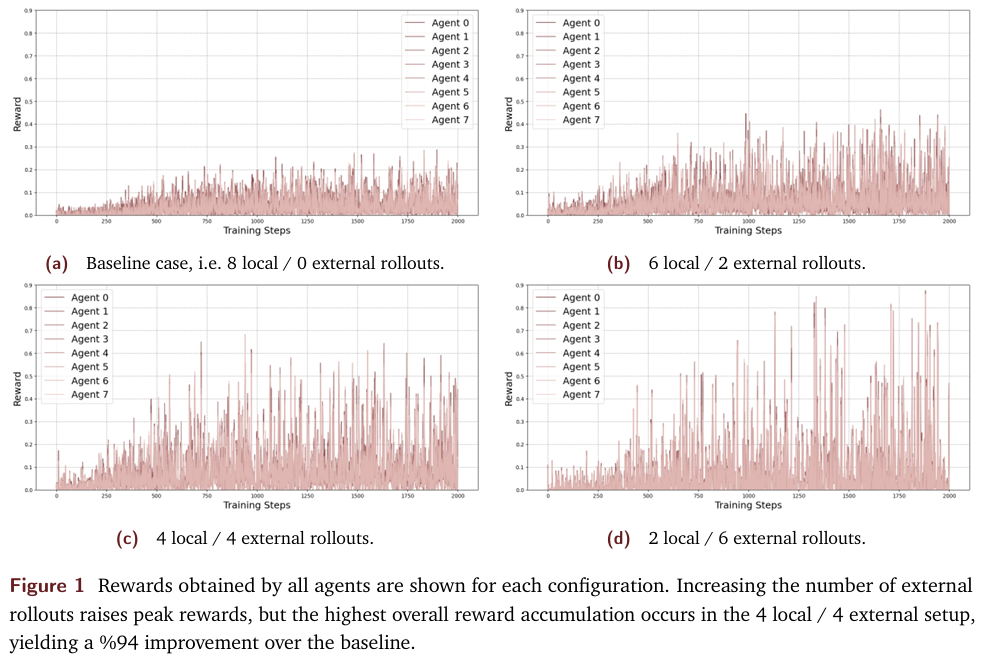
实验结果表明,SAPO算法显著提升了模型的累计奖励。在4本地/4外部rollouts的配置下,SAPO算法相比无共享的基线方法实现了高达94%的累计奖励提升。这一结果证明了集体经验共享机制在提升模型性能方面的有效性。
2. 不同配置下的性能比较:
研究团队还比较了不同配置下的模型性能。实验结果显示,随着外部rollouts数量的增加,模型的峰值奖励逐渐提高。然而,过度依赖外部rollouts会导致学习过程中的震荡和遗忘行为,从而影响整体性能。在4本地/4外部的配置下,模型实现了最佳的整体性能。
3. 大规模开放源码演示中的验证:
为了进一步验证SAPO算法在真实异构环境中的有效性,研究团队组织了一个大规模开放源码演示活动,吸引了数千名Gensyn社区成员参与。演示结果显示,对于中等容量的模型(如0.5B参数的Qwen2.5模型),参与集体训练的模型性能显著优于孤立训练的模型。而对于更高容量的模型(如0.6B参数的Qwen3模型),参与集体训练带来的性能提升则相对有限。这表明SAPO算法的优势在中等容量模型中更为突出。
研究局限
尽管SAPO算法在提升语言模型复杂推理能力方面展现出了显著优势,但本研究仍存在一些局限性:
1. 外部rollouts采样策略的局限性:
在当前研究中,节点采用简单的均匀随机采样策略来选择外部rollouts。这种策略可能导致无用的或低质量的rollouts被过度表示,从而影响训练效果。未来需要探索更加智能的采样策略,以过滤掉无用的rollouts并保留有价值的经验。
2. 对高容量模型的适应性有限:
实验结果显示,SAPO算法对高容量模型(如0.6B参数以上的模型)的性能提升相对有限。这可能是因为高容量模型本身已经具备了较强的推理能力,难以通过简单的经验共享机制实现显著的性能提升。未来需要探索更加适合高容量模型的集体训练方法。
3. 稳定性和鲁棒性有待提升:
在某些配置下(如2本地/6外部),模型表现出较强的学习震荡和遗忘行为。这表明SAPO算法在稳定性和鲁棒性方面仍有待提升。未来需要探索更加稳定的训练策略和鲁棒性增强技术,以提高算法的整体性能。
未来研究方向
针对SAPO算法的局限性和潜在改进空间,未来研究可以从以下几个方面展开:
1. 探索更加智能的外部rollouts采样策略:
未来可以探索基于模型置信度、奖励预测或注意力机制的智能采样策略,以过滤掉无用的rollouts并保留有价值的经验。这将有助于提高训练效率并减少无效计算。
2. 研究高容量模型的集体训练方法:
针对高容量模型,未来可以研究更加复杂的集体训练方法,如分层训练、模型蒸馏或知识融合等。这些方法可能有助于充分利用高容量模型的潜力,并通过集体训练实现性能的进一步提升。
3. 增强算法的稳定性和鲁棒性:
为了提高SAPO算法的稳定性和鲁棒性,未来可以研究基于奖励引导的经验共享机制、RLHF(从人类反馈中强化学习)或生成式验证器等混合方法。这些方法可能有助于减少学习过程中的震荡和遗忘行为,并提高算法的整体性能。
4. 探索多模态应用:
尽管本研究主要关注语言模型,但SAPO算法本身是模态无关的。未来可以探索SAPO算法在多模态学习中的应用,如文本到图像生成、视频理解或跨模态检索等。这将有助于拓展SAPO算法的应用范围,并推动多模态学习领域的发展。
5. 研究非常规策略的集成:
未来还可以探索将非常规策略(如人类)集成到SAPO算法中的可能性。通过设计适当的激励机制,可以鼓励非传统策略(如人类用户)参与到集体训练中,并提供有价值的经验。这将有助于丰富训练数据的多样性,并提高模型的泛化能力。





)
控制相机旋转,限制角度)
归并排序)

:项目探索)
)

)


重点与易错点全面总结)



