【机器学习】通过tensorflow实现猫狗识别的深度学习进阶之路
简介
猫狗识别作为计算机视觉领域的经典入门任务,不仅能帮助我们掌握深度学习的核心流程,更能直观体会到不同优化策略对模型性能的影响。本文将从 “从零搭建简单 CNN” 出发,逐步引入 “数据增强” 和 **“**迁移学习” 技术,完整记录猫狗识别任务的优化历程。
项目背景
猫狗识别属于二分类图像任务,其核心挑战在于:
- 图像存在姿态、光照、背景等差异,模型需要具备一定的泛化能力;
- 若数据集规模有限,容易出现 “过拟合”(训练准确率高但验证准确率低)。
数据集介绍
数据集采用经典的“cats_and_dogs”的数据集,目录结构如下:
cats_and_dogs/
├── train/ # 训练集(约2000张图像)
│ ├── cats/ # 猫的图像
│ └── dogs/ # 狗的图像
└── validation/ # 验证集(约500张图像)
├── cats/
└── dogs/
阶段一:搭建基础CNN模型
我们先搭建一个简单的卷积神经网络(CNN),熟悉图像分类的完整流程:数据加载、模型构建、编译与训练。
导入库以及制定好数据路径
导入必要的库和自己所下载的数据的文件路径。
import os
import warnings
warnings.filterwarnings("ignore")
import tensorflow as tf
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.preprocessing.image import ImageDataGenerator
base_dir = "D:/工作学习/Tensorflow2版本/第五章:猫狗识别实战/猫狗识别/猫狗识别/data/cats_and_dogs"
train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')
train_cats_dir = os.path.join(train_dir, 'cats')
train_dogs_dir = os.path.join(train_dir, 'dogs')
validation_cats_dir = os.path.join(validation_dir, 'cats')
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
数据预处理
图像数据进行归一化(0-1)区间和批量处理数据。
train_datagen = ImageDataGenerator(rescale=1./255)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(train_dir, # 文件夹路径target_size=(64, 64), # 指定resize成的大小batch_size=20,# 如果one-hot就是categorical,二分类用binary就可以class_mode='binary')
validation_generator = test_datagen.flow_from_directory(validation_dir,target_size=(64, 64),batch_size=20,class_mode='binary')
搭建基础CNN模型
CNN 的核心是 “卷积 + 池化”:卷积层提取图像特征,池化层缩小特征图尺寸、减少计算量,最后通过全连接层输出分类结果。
model = tf.keras.models.Sequential([tf.keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(64,64,3)),tf.keras.layers.MaxPooling2D(2,2),tf.keras.layers.Conv2D(64,(3,3),activation='relu'),tf.keras.layers.MaxPooling2D(2,2),tf.keras.layers.Conv2D(128,(3,3),activation='relu'),tf.keras.layers.MaxPooling2D(2,2),# 为全连接层准备tf.keras.layers.Flatten(),tf.keras.layers.Dense(512,activation='relu'),# 二分类sigmoid就够了tf.keras.layers.Dense(1,activation='sigmoid')
])
# 配置训练器
model.compile(loss='binary_crossentropy', optimizer=Adam(1e-4), metrics=['acc'])
训练网络模型
history = model.fit_generator(train_generator,steps_per_epoch=100,epochs=20,validation_data=validation_generator,validation_steps=50,verbose=2
)
训练结果
效果展示
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs,acc,'bo',label='Training accuracy')
plt.plot(epochs,val_acc,'b',label='Validation accuracy')
plt.title('Training and validation accuracy')
plt.figure()
plt.plot(epochs,loss,'bo',label='Training loss')
plt.plot(epochs,val_loss,'b',label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
运行结果
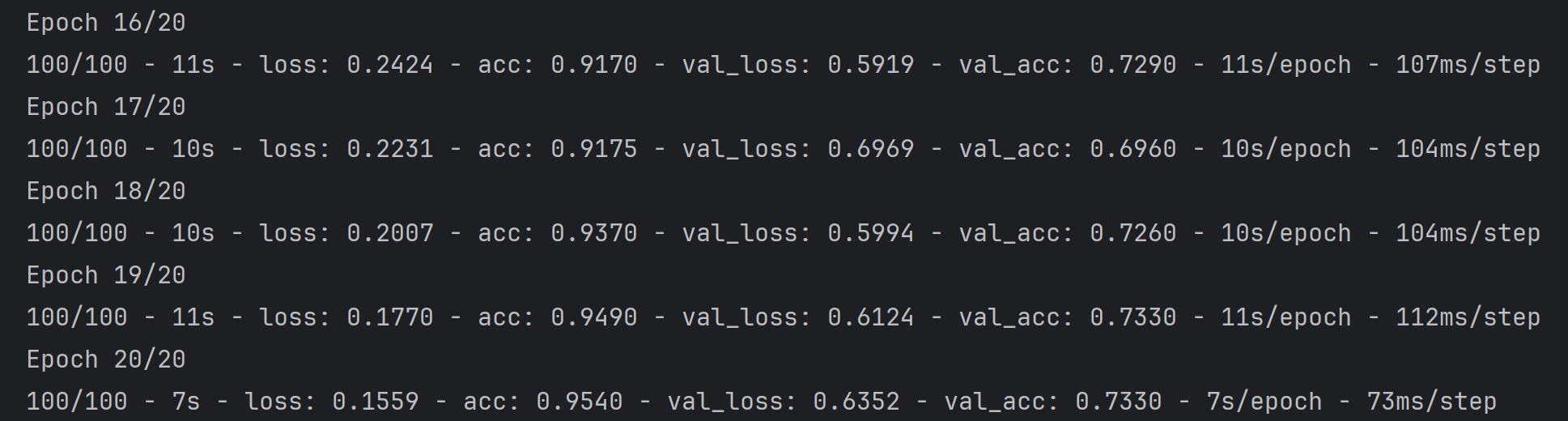
1.准确率曲线(Training and validation accuracy)
训练准确率:呈现出持续上升的趋势,最终接近并超过 0.95,说明模型在训练集上的学习效果很好,能够不断地从训练数据中提取特征并正确分类。
验证准确率:虽然整体也有上升,但上升幅度远小于训练准确率,且数值稳定在 0.7 左右,与训练准确率差距较大。这表明模型在未见过的验证集数据上的泛化能力不足,没有很好地学到能推广到新数据的通用特征。
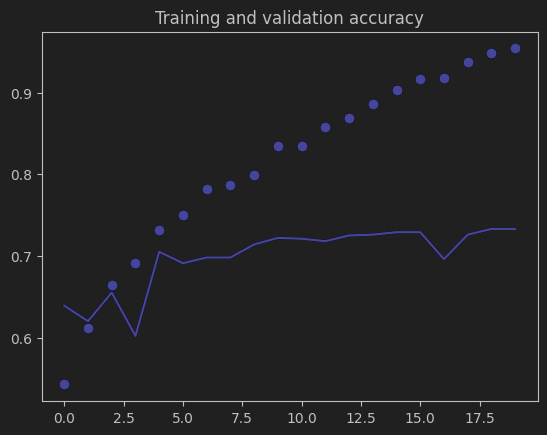
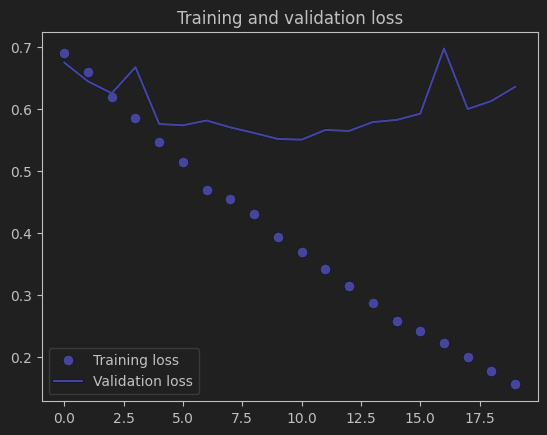
2. 损失曲线(Training and validation loss)
训练损失:随着训练轮次的增加,持续下降,最终接近 0.2,说明模型在训练过程中对训练数据的拟合程度越来越高,预测误差不断减小。
验证损失:虽然初期有下降,但之后趋于平稳甚至有所上升,最终稳定在 0.6 左右,与训练损失差距明显。这进一步验证了模型过拟合的问题,模型在训练集上表现越来越好,但在验证集上的性能提升不明显甚至变差。
阶段二:优化策略——数据增强缓解过拟合
过拟合的本质是 “数据多样性不足”,而数据增强通过对训练图像进行随机变换(旋转、平移、翻转等),人为扩充数据集,让模型学习到更通用的特征。
修改配置器并训练模型
修改train_datagen的配置(验证集不增强,保证评估真实性)。
增加随机旋转0-40度、随机水平平移20%、随机垂直平移20%、随即剪切、随机缩放、随即水平翻转以及空白区域用最近像素填充。
train_datagen = ImageDataGenerator(rescale=1./255,rotation_range=40,width_shift_range=0.2,height_shift_range=0.2,shear_range=0.2,zoom_range=0.2,horizontal_flip=True,fill_mode='nearest'
)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(train_dir,target_size=(64,64),batch_size=20,class_mode='binary'
)
validation_generator = test_datagen.flow_from_directory(validation_dir,target_size=(64,64),batch_size=20,class_mode='binary'
)
history = model.fit_generator(train_generator,steps_per_epoch=100,epochs=100,validation_data=validation_generator,validation_steps=50,verbose=2
)
训练结果
效果展示
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs,acc,'b',label='Training accuracy')
plt.plot(epochs,val_acc,'r',label='Validation accuracy')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs,loss,'b',label='Training loss')
plt.plot(epochs,val_loss,'r',label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
运行结果
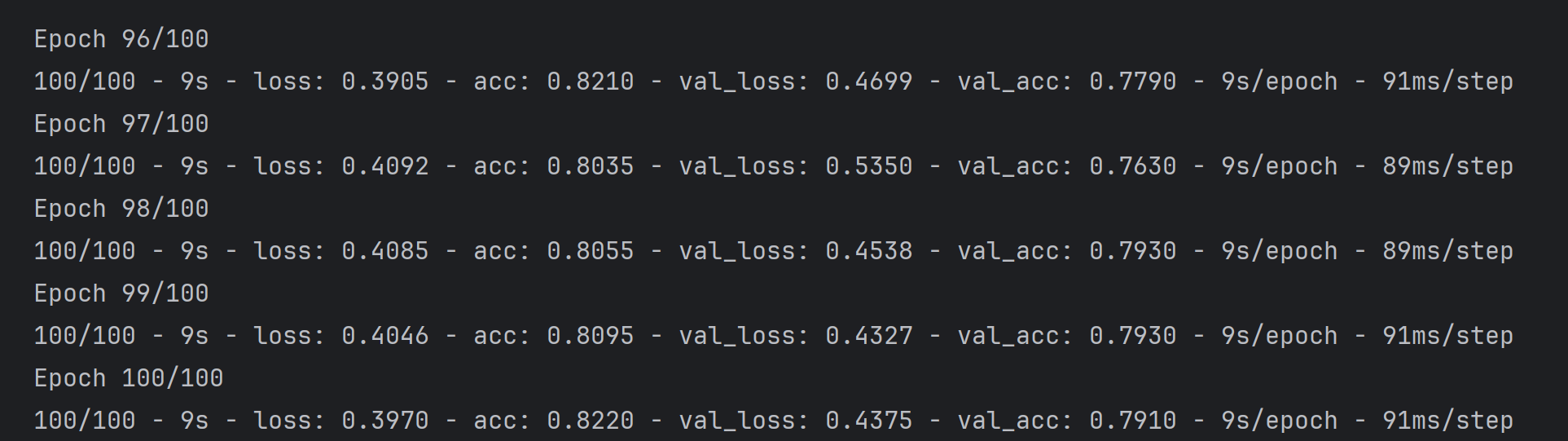
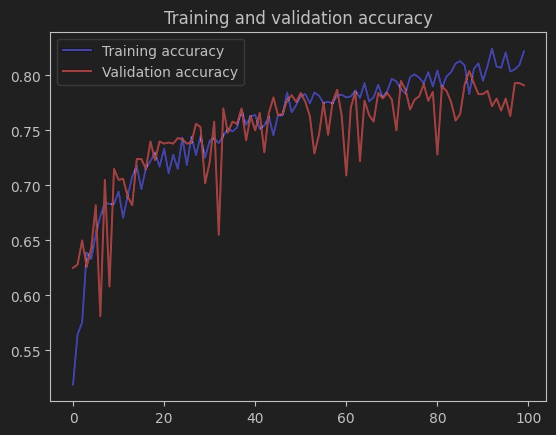
1.准确率曲线(Training and validation accuracy)
训练准确率:整体呈现上升趋势,最终接近 0.85 左右,说明模型在训练集上仍能有效学习特征。
验证准确率:也有明显的上升,并且与训练准确率的差距相比基础 CNN 模型有所缩小,最终稳定在 0.78 左右。这表明数据增强通过增加训练数据的多样性,使模型学到了更具泛化性的特征,在验证集上的表现得到了提升。不过,两者之间仍有一定差距,说明过拟合问题并未完全解决。
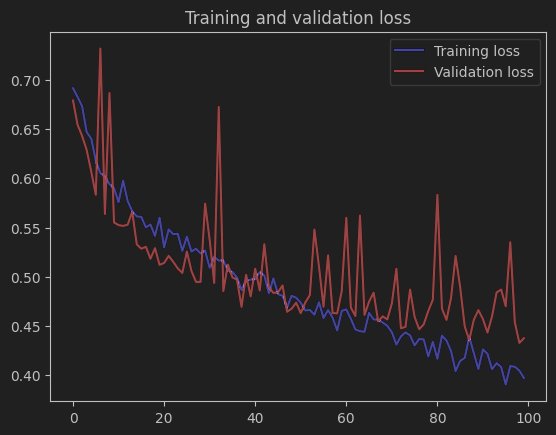
2. 损失曲线(Training and validation loss)
训练损失:随着训练轮次的增加,持续下降,最终接近 0.4,说明模型在训练数据上的拟合程度不断提高,预测误差减小。
验证损失:虽然整体也有下降的趋势,但波动较大,并且与训练损失仍存在一定差距。这进一步说明模型在验证集上的性能虽然有提升,但还不够稳定,仍然存在一定的过拟合风险。
阶段三:迁移学习借力训练模型
基础 CNN 的特征提取能力有限,而迁移学习直接使用在 “ImageNet”(百万级图像数据集)上预训练的模型(如 ResNet、Inception),这些模型已学到通用的图像特征,只需微调即可适配猫狗识别任务。
加载预训练模型ResNet101
选择 ResNet101(101 层残差网络),并移除其顶层分类器(保留特征提取部分)。
from tensorflow.keras.applications.resnet import ResNet101
from tensorflow.keras import layers, Model
pre_trained_model = ResNet101(input_shape=(75,75,3),# 输入大小include_top=False,# 不要最后的全连接层weights='imagenet')
# 冻结预训练模型权重(避免破坏已有特征)
for layer in pre_trained_model.layers:layer.trainable = False
添加自定义分类头
在预训练模型后添加适合二分类的全连接层。
from tensorflow.keras.optimizers import Adam
# 为全连接层准备
x = layers.Flatten()(pre_trained_model.output)
# 加入全连接层,这个需要重头训练
x = layers.Dense(1024, activation='relu')(x)
x = layers.Dropout(0.2)(x)
# 输出层
x = layers.Dense(1, activation='sigmoid')(x)
# 构建模型序列
model = Model(pre_trained_model.input, x)
model.compile(optimizer=Adam(learning_rate=0.001), loss='binary_crossentropy',metrics=['acc'])
添加早停回调并训练模型
当准确率达到目标后自动停止训练,避免无效迭代。
class myCallback(tf.keras.callbacks.Callback):def on_epoch_end(self, epoch, logs={}):if(logs.get('acc')>0.95):print('\nReached 0.95 accuracy so cancelling training')self.model.stop_training =True
callables = myCallback()
history = model.fit_generator(train_generator,validation_data=validation_generator,steps_per_epoch = 100,epochs=100,validation_steps= 50,verbose=2,callbacks=[callables]
)
训练结果
效果展示
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']epochs = range(len(acc))plt.plot(epochs, acc, 'b', label='Training accuracy')
plt.plot(epochs, val_acc, 'r', label='Validation accuracy')
plt.title('Training and validation accuracy')
plt.legend()plt.figure()plt.plot(epochs, loss, 'b', label='Training Loss')
plt.plot(epochs, val_loss, 'r', label='Validation Loss')
plt.title('Training and validation loss')
plt.legend()plt.show()
运行结果
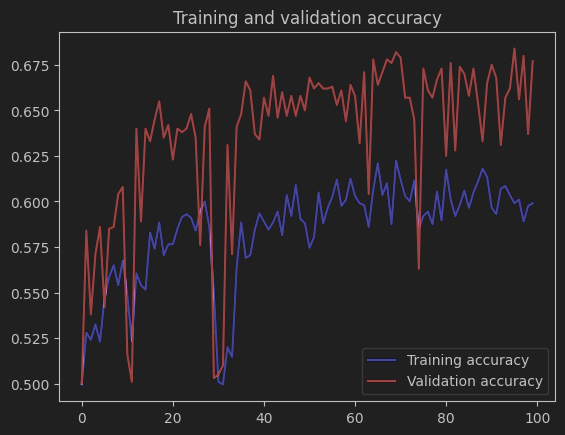
准确率表现
训练准确率约 0.66,验证准确率约 0.68,过拟合问题大幅缓解,但是整体准确率远低于基础 CNN 的训练表现,说明迁移学习后的模型特征提取或分类头设计可能未充分发挥作用。
损失表现
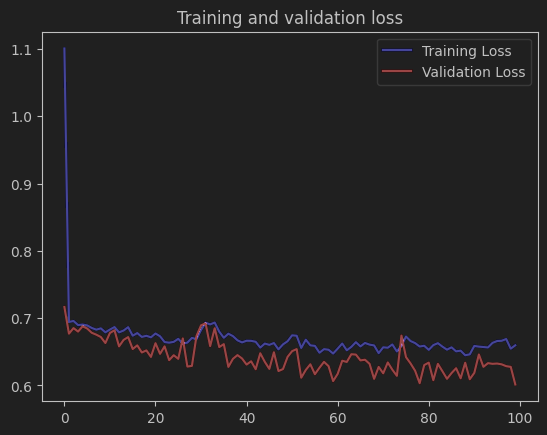
训练损失和验证损失整体都有下降趋势,且差距较小,过拟合缓解;但训练损失仍维持在 0.65 左右(基础 CNN 训练损失最终接近 0.2),验证损失波动极大,说明模型在 “降低误差” 和 “稳定泛化” 上都有不足。
)


)

)



![[论文阅读] 算法 | 抗量子+紧凑!SM3-OTS:基于国产哈希算法的一次签名新方案](http://pic.xiahunao.cn/[论文阅读] 算法 | 抗量子+紧凑!SM3-OTS:基于国产哈希算法的一次签名新方案)

模型,实现高效实时语音识别(附源码))

高级特性深度剖析:详解RabbitMQ与Kafka)



)

