- 🍨 本文为🔗365天深度学习训练营中的学习记录博客
- 🍖 原作者:K同学啊
一、Transformer和Seq2Seq
在之前的博客中我们学习了Seq2Seq(深度学习系列 | Seq2Seq端到端翻译模型),知晓了Attention为RNN带来的优点。那么有没有一种神经网络结构直接基于attention构造,并且不再依赖RNN、LSTM或者CNN网络结构了呢?答案便是:Transformer。Seq2Seq和Transformer都是用于处理序列数据的深度学习模型,但它们是两种不同的架构。
- Seq2Seq:
- 定义: Seq2Seq是一种用于序列到序列任务的模型架构,最初用于机器翻译。这意味着它可以处理输入序列,并生成相应的输出序列。
- 结构: Seq2Seq模型通常由两个主要部分组成:编码器和解码器。编码器负责将输入序列编码为固定大小的向量,而解码器则使用此向量生成输出序列。
- 问题: 传统的Seq2Seq模型在处理长序列时可能会遇到梯度消失/爆炸等问题,而Transformer模型的提出正是为了解决这些问题。
- Transformer:
- 定义: Transformer是一种更现代的深度学习模型,专为处理序列数据而设计,最初用于自然语言处理任务。它不依赖于RNN或CNN等传统结构,而是引入了注意力机制。
- 结构: Transformer模型主要由编码器和解码器组成,它们由自注意力层和全连接前馈网络组成。它使用注意力机制来捕捉输入序列中不同位置之间的依赖关系,同时通过多头注意力来提高模型的表达能力。
- 优势: Transformer的设计使其能够更好地处理长距离依赖关系,同时具有更好的并行性。
在某种程度上,可以将Transformer看作是Seq2Seq的一种演变,Transformer可以执行Seq2Seq任务,并且相对于传统的Seq2Seq模型具有更好的性能和可扩展性.
关于Transformer的历史这里不赘述了, 本文重点从技术层面解析Transformer
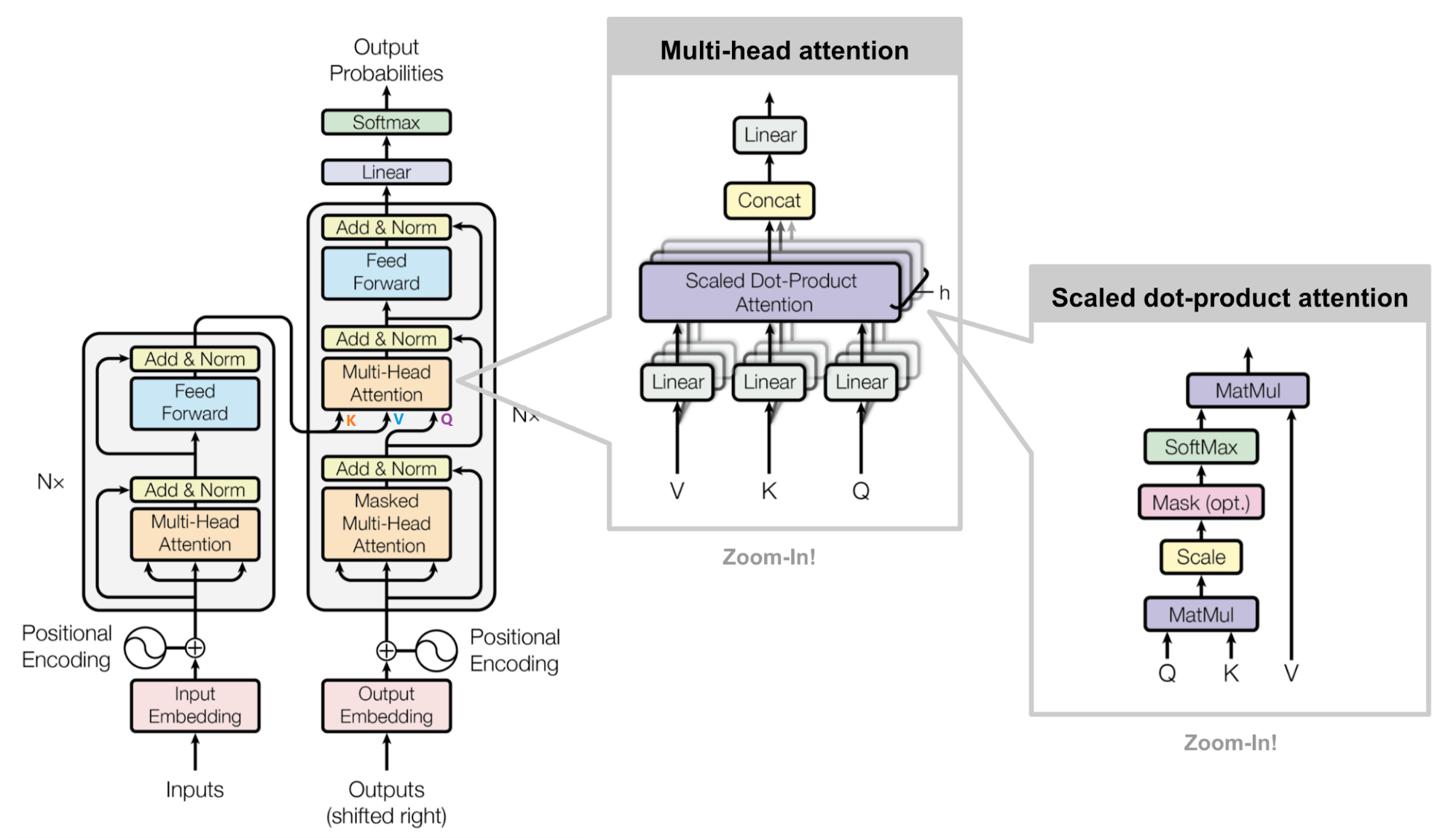
二、Transformer的宏观结构
我们先把模型看作一个黑盒子。在机器翻译应用中,它会接受一种语言的句子,然后输出另一种语言的翻译。

打开“The Transformer”,我们可以看到一个编码组件、一个解码组件以及它们之间的连接。
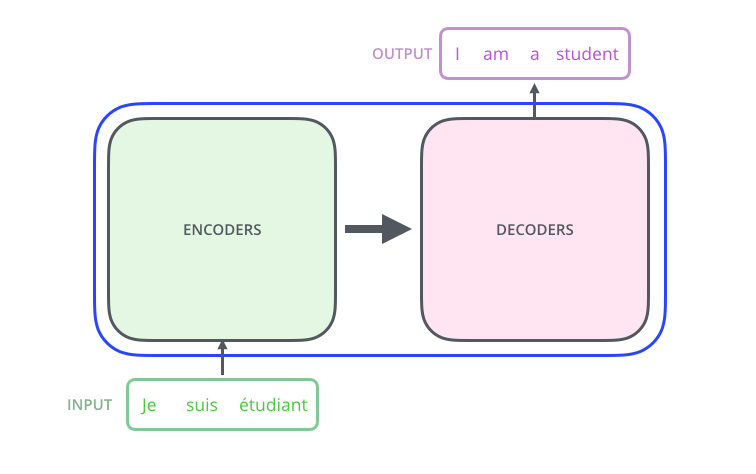
编码组件是一堆编码器(论文中将6个编码器堆叠在一起——“6”这个数字并没有什么神奇之处,当然可以尝试其他排列方式)。解码组件是一堆相同数量的解码器。
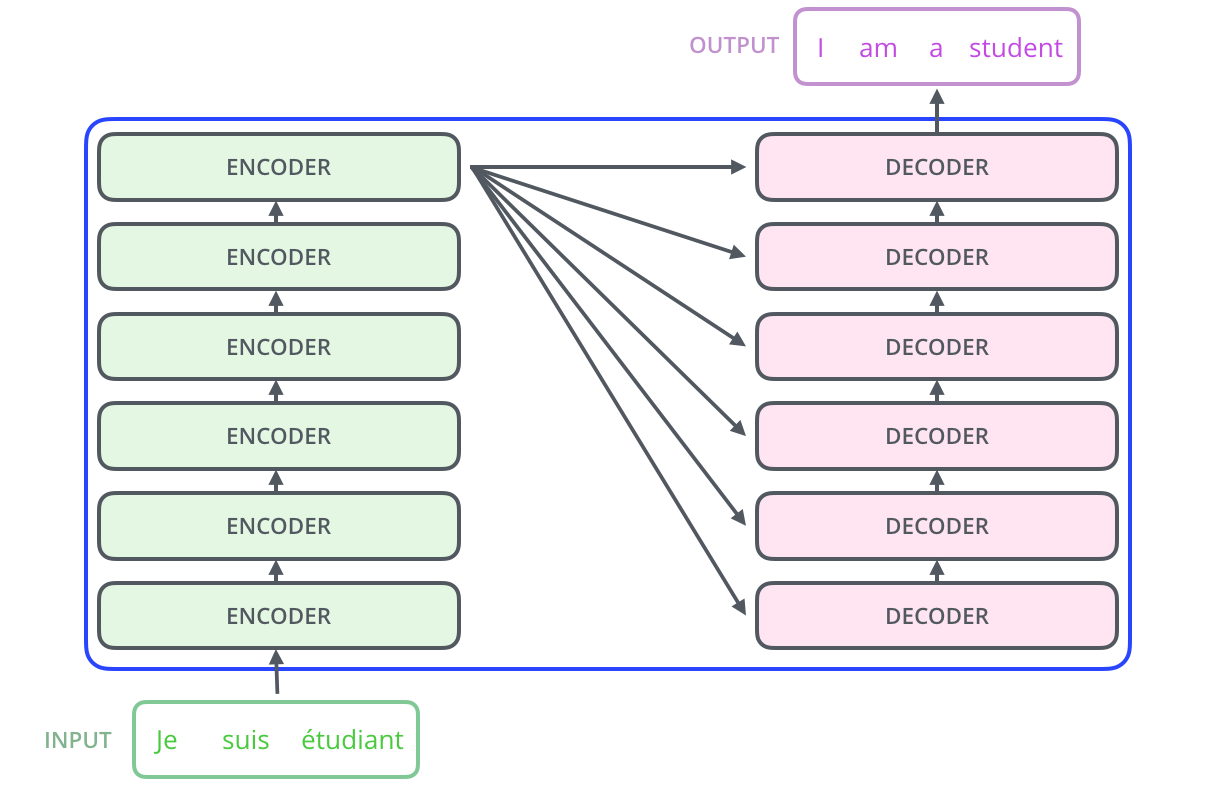
所有编码器的结构完全相同(但它们不共享权重)。每个编码器又分为两个子层 ,主要由自注意力层(Self-Attention Layer)和全连接前馈网络(Feed Forward Neural Network, FFNN)与组成,如下图所示:
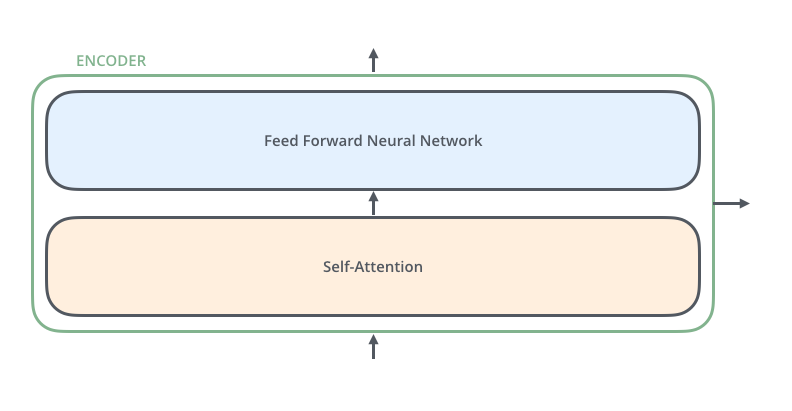
其中,解码器在编码器的自注意力层和全连接前馈网络中间插入了一个Encoder-Decoder Attention层,这个层帮助解码器聚焦于输入序列最相关的部分。
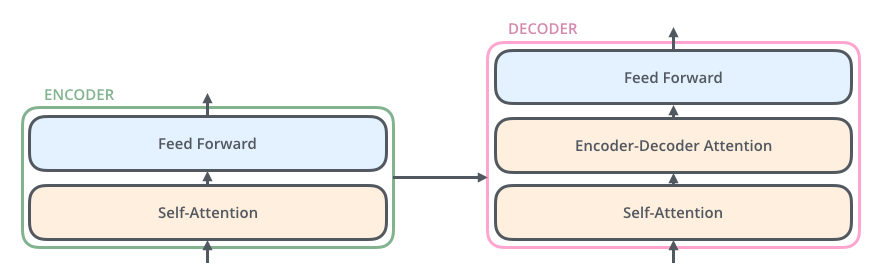
最后总结一下,我们基本了解了Transformer由编码部分和解码部分组成,而编码部分和解码部分又由多个网络结构相同的编码层和解码层组成。每个编码层由自注意力层和全连接前馈网络组成,每个解码层由自注意力层、全连接前馈网络和encoder-decoder attention组成。
三、代码复现
1、导入包
import math
import torch
import torch.nn as nn#设置GPU训练
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
devicedevice(type='mps')2、shape变化类
将张量的指定维度进行交换,并可选择让转置后的张量在内存中保持 “连续” 状态(contiguous)。它本质是对 PyTorch 原生的 transpose 和 contiguous 方法的封装,方便在神经网络的层结构中复用
- transpose作用: 交换张量的两个维度,(batch_size, seq_len, hidden_dim) 经过transpose(1,2)后会将其转换为(batch_size, hidden_dim, seq_len)
- contiguous作用: 通过复制数据确保张量在内存中是“连续存储的”,后续view,reshape操作需要
class Transpose(nn.Module):def __init__(self, *dims, contiguous=False):super(Transpose, self).__init__()self.dims = dims #要交换的维度(如 (1, 2) 表示交换第1和第2维)self.contiguous = contiguous # 是否在转置后强制内存连续def forward(self, x):if self.contiguous:return x.transpose(*self.dims).contiguous()else:return x.transpose(*self.dims)3、Scaled dot-product Attention
Self-Attention机制的一个具体实现 , QKV实现点积, 两个向量若他们的点积越大, 可以表示向量间靠的更接近, 在语义空间中 也可表示两个词更相似, 更有关系
- torch.softmax(..., dim=-1)
- dim=-1表示在张量的最后一个维度上应用 Softmax 函数(这里最后一个维度是 “被关注的位置” 维度,即context_length)
代码实现功能:
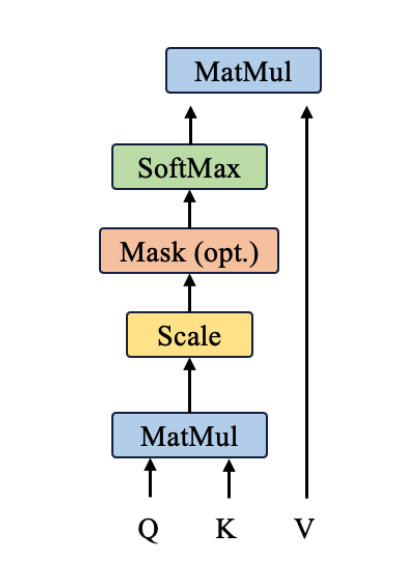
import torch.nn.functional as Fclass scaledDotProductAttention(nn.Module):def __init__(self, d_k):super(scaledDotProductAttention, self).__init__()self.d_k = d_k #表示缩放因子'''计算注意力机制的核心步骤1、先计算Q和K的点积,得到相似分数,k需要转置2、scale: 缩放分数, 防止梯度消失3、应用掩码,decode用,将掩码设置成一个极小的值4、对分数进行softmax, 得到注意力权重概率5、根据注意力权重和v进行加权求和'''def forward(self, q, k, v, mask=None):scores = torch.matmul(q, k) # scores形状: [batch_size, num_heads, d_k, seq_len]scores = scores/ self.d_k ** 0.5 # scale#掩码应用if mask is not None:scores.masked_fill(mask, -1e9)attn = F.softmax(scores, dim=-1)#和v进行加权求和context = torch.matmul(attn, v)return context4、多头注意力机制
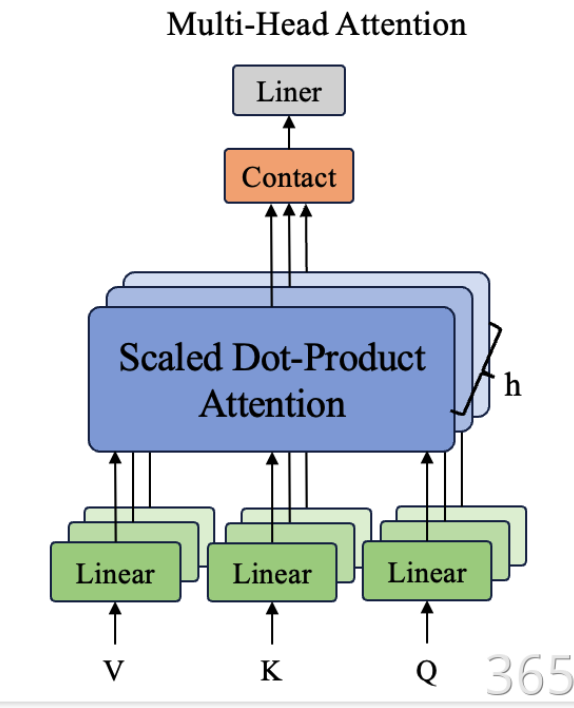
多头注意力,可以直接理解为我们有多个脑袋去注意不同的事情,从全局角度来看,更为全面。那么怎么做到呢?
通过将Q/K/V投影到不同的子空间(subspace),使模型能够并行学习多种语义特征。具体实现分为四个步骤:

class MultiHeadAttention(nn.Module):def __init__(self, d_model, n_heads):'''多头注意力机制的初始化函数d_model:输入的特征维度n_heads:注意力头的数量d_k:每个头的缩放因子 键/查询向量的维度 d_model // n_headsd_v:每个头中值向量维度'''super(MultiHeadAttention, self).__init__()#确保d_model可以被n_heads整除assert d_model % n_heads ==0, f"d_model:{d_model}不能被 n_heads:{n_heads}整除"self.d_k = d_model//n_headsself.d_v = d_model//n_headsself.n_heads = n_heads#定义Q、K、V的线性层, 本质上都是 nn.Linear(d_model, d_model, bias= False)self.W_Q = nn.Linear(d_model, self.d_k * n_heads, bias= False)self.W_K = nn.Linear(d_model, self.d_k * n_heads, bias= False)self.W_V = nn.Linear(d_model, self.d_v * n_heads, bias= False)#用于将多头输出的拼接结果投影回输入特征维度的线性层self.W_O = nn.Linear(n_heads* self.d_v, d_model, bias= False)'''前向传播函数:计算多头注意力'''def forward(self, Q, K, V, mask=None):batch_size = Q.size(0) #获取批量的大小#1、将输入向量进行头拆分,并进行维度变换q_s= self.W_Q(Q).view(batch_size, -1, self.n_heads, self.d_k).transpose(1, 2)k_s= self.W_K(K).view(batch_size, -1, self.n_heads, self.d_k).permute(0, 2, 3, 1)v_s= self.W_V(V).view(batch_size, -1, self.n_heads, self.d_v).transpose(1, 2)#2、计算缩放点积注意力context = scaledDotProductAttention(self.d_k)(q_s, k_s, v_s)#3、将多头的输出拼接起来,拼接后的形状 [batch_size, q_len, n_heads* d_v]context = context.transpose(1, 2).contiguous().view(batch_size, -1, self.n_heads * self.d_v)#4、通过线性层映射回输入特征维度out_put = self.W_O(context) #output形状:[batch_size, q_len, d_model]return out_put5、前馈传播
class Feedforward(nn.Module):def __init__(self, d_model, d_ff, dropout= 0.1):super(Feedforward, self).__init__()#两层线性变换self.linear1 = nn.Linear(d_model, d_ff)self.dropout = nn.Dropout(dropout)self.linear2 = nn.Linear(d_ff, d_model)def forward(self, x):x = F.relu(self.linear1(x))x = self.dropout(x)x = self.linear2(x)return x6、位置编码
class PositionalEncoding(nn.Module):def __init__(self, d_model, dropout, max_len = 5000):super(PositionalEncoding, self).__init__()self.dropout = nn.Dropout(p= dropout)#初始化shape为(max_len, d_model)的PEpe = torch.zeros(max_len, d_model)#初始化一个tensorposition = torch.arange(0, max_len).unsqueeze(1)#这里是sin和cos括号里的内容div_term = torch.exp(torch.arange(0 ,d_model, 2)* -math.log(10000)/d_model)pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)pe = pe.unsqueeze(0) #在最外层加一个batch_sizeself.register_buffer("pe", pe)def forward(self, x):x= x + self.pe[: , :x.size(1)].requires_grad_(False)return self.dropout(x)7、编码层
class EncoderLayer(nn.Module):def __init__(self, d_model, n_heads, d_ff, dropout=0.1):super(EncoderLayer, self).__init__()#编码器层包含自注意力机制和前馈神经网络self.self_attn = MultiHeadAttention(d_model, n_heads)self.feedforward = Feedforward(d_model, d_ff, dropout)self.norm1 = nn.LayerNorm(d_model)self.norm2 = nn.LayerNorm(d_model)self.dropout = nn.Dropout(dropout)def forward(self, x, mask):#自注意力机制,初始值Q、K、V一致attn_output = self.self_attn(x, x, x, mask)x= x+self.dropout(attn_output)x= self.norm1(x)#前馈神经网络ff_output= self.feedforward(x)x = x+ self.dropout(ff_output)x = self.norm2(x)return x8、解码层
class DecoderLayer(nn.Module):def __init__(self, d_model, n_heads, d_ff, dropout=0.1):super(DecoderLayer, self).__init__()#解码器层包含自注意力机制、编码器-解码器注意力机制和前馈神经网络self.self_attn = MultiHeadAttention(d_model, n_heads)self.enc_attn = MultiHeadAttention(d_model, n_heads)self.feedforward = Feedforward(d_model, d_ff, dropout)self.norm1 = nn.LayerNorm(d_model)self.norm2 = nn.LayerNorm(d_model)self.norm3 = nn.LayerNorm(d_model)self.dropout = nn.Dropout(dropout)def forward(self, x, enc_output, self_mask, context_mask):#自注意力机制attn_output = self.self_attn(x, x, x, self_mask)x = x + self.dropout(attn_output)x = self.norm1(x)#编码器-解码器注意力机制attn_output = self.enc_attn(x, enc_output, enc_output, context_mask)x = x +self.dropout(attn_output)x = self.norm2(x)#前馈神经网络ff_output = self.feedforward(x)x = x + self.dropout(ff_output)x = self.norm3(x)return x9、Transformer模型构建
class Transformer(nn.Module):def __init__(self, vocab_size, d_model, n_heads, n_encoder_layers, n_decoder_layers, d_ff, dropout):super(Transformer, self).__init__()#Transformer 包含词嵌入,位置编码,编码器和解码器self.embedding = nn.Embedding(vocab_size, d_model)self.positional_encoding = PositionalEncoding(d_model, dropout)self.encoder_layers = nn.ModuleList([EncoderLayer(d_model, n_heads, d_ff, dropout) for _ in range(n_encoder_layers)])self.decoder_layers = nn.ModuleList([DecoderLayer(d_model, n_heads, d_ff, dropout) for _ in range(n_decoder_layers)])self.fc_out = nn.Linear(d_model, vocab_size)self.dropout = nn.Dropout(dropout)def forward(self, src, trg, src_mask, trg_mask):src = self.embedding(src)src = self.positional_encoding(src)trg = self.embedding(trg)trg = self.positional_encoding(trg)#编码器for layer in self.encoder_layers:src = layer(src, src_mask)#解码器for layer in self.decoder_layers:trg = layer(trg, src, trg_mask, src_mask)#输出层output = self.fc_out(trg)return output10、输出模型结构
#使用示例
vocab_size = 10000 #假设词汇表大小为10000
d_model = 512
n_heads = 8
n_encoder_layers = 6
n_dncoder_layers = 6
d_ff = 2048
dropout=0.1transformer_model = Transformer(vocab_size, d_model, n_heads, n_encoder_layers, n_dncoder_layers, d_ff, dropout)#定义输入
src = torch.randint(0, vocab_size, (32, 10))#源语言句子
trg = torch.randint(0, vocab_size, (32, 20))#目标语言句子
src_mask = (src!=0).unsqueeze(1).unsqueeze(2)
trg_mask = (trg!=0).unsqueeze(1).unsqueeze(2)print("实际|输入数据维度:", src.shape)
print("实际|输出数据维度:", trg.shape)output = transformer_model(src, trg, src_mask, trg_mask)print("实际|输出数据维度:", output.shape)
实际|输入数据维度: torch.Size([32, 10])
实际|输出数据维度: torch.Size([32, 20])
实际|输出数据维度: torch.Size([32, 20, 10000])参考文章
https://jalammar.github.io/illustrated-transformer/








)

)




-- 配置与部署)



