文章目录
目录
1. Serial GC(串行收集器)
2. Parallel GC(并行收集器)
3. CMS(Concurrent Mark-Sweep,并发标记 - 清除)
4. G1(Garbage-First,垃圾优先)
5. ZGC(Z Garbage Collector)
6. Shenandoah( shen-uh-doh-uh )
特性对比表:
总结:
前言
在 JVM 中,垃圾收集器(GC)的设计目标差异显著,主要体现在吞吐量、延迟、内存支持规模、线程模型等核心特性上。以下是 JVM 中常见 GC 收集器的详细特性对比:
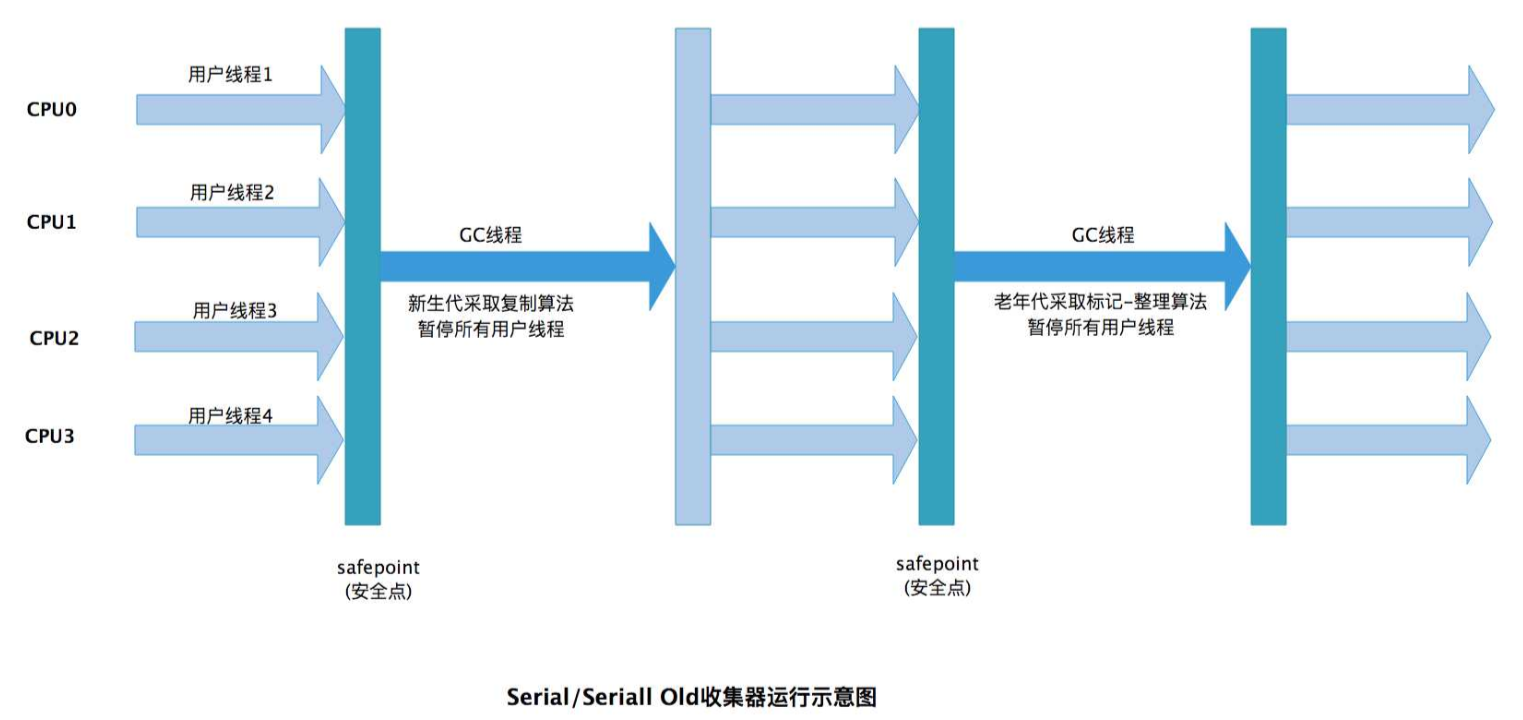
1. Serial GC(串行收集器)
核心目标:单线程环境下的简单高效,专注于低内存占用和实现简洁性。
分代策略:严格分代(新生代 + 老年代):
-
新生代:采用复制算法(将内存分为 Eden 区和两个 Survivor 区,存活对象复制到 Survivor)。
-
老年代:采用标记 - 整理算法(标记存活对象后,将其压缩到内存一端,避免碎片)。
线程模型:单线程执行 GC:GC 过程中只有一个线程工作,且会暂停所有应用线程(STW,Stop-The-World)。
STW 情况:STW 时间较长(随堆大小增加而增加),因为单线程处理所有回收工作。
内存管理:堆内存规模较小(通常 < 1GB),不适合大内存场景。
优点
-
实现简单,代码量少,内存占用极低(几乎无额外 GC 线程开销)。
-
无多线程同步成本,在单 CPU 环境下效率较高。
缺点
-
STW 时间长,无法利用多核 CPU 优势。
-
不适合大型应用或高并发场景。
适用场景
-
嵌入式设备、小型命令行工具(如简单脚本)。
-
单 CPU 环境或内存受限的场景(如物联网设备)。
所有 JDK 版本均支持,JDK 9 后默认不启用,需通过-XX:+UseSerialGC开启。
2. Parallel GC(并行收集器)
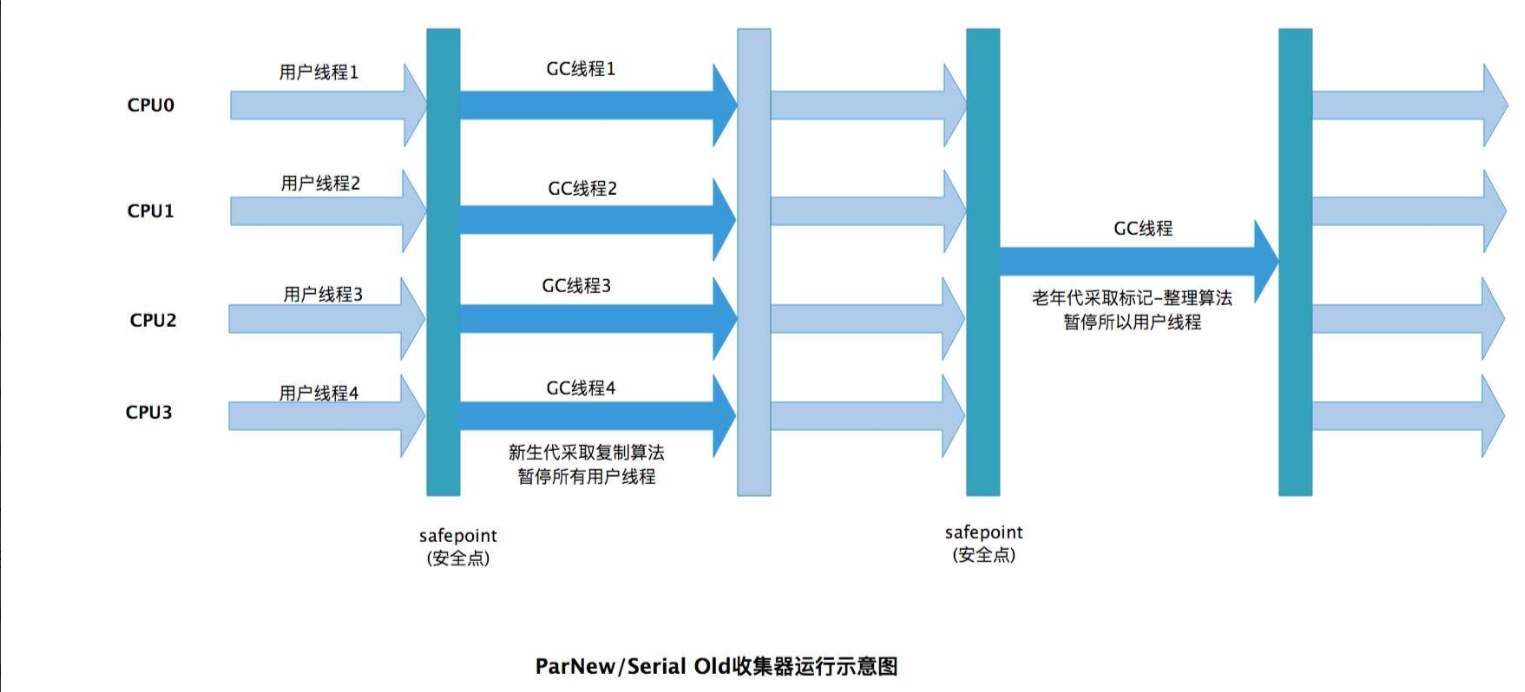
核心目标:最大化吞吐量(单位时间内应用程序运行时间占比),适合计算密集型场景。
分代策略:严格分代(新生代 + 老年代):
-
新生代:并行复制算法(多线程同时复制存活对象)。
-
老年代:并行标记 - 整理算法(多线程同时标记和压缩)。
线程模型:多线程并行执行 GC:GC 线程数默认与 CPU 核心数相关(可通过-XX:ParallelGCThreads配置),GC 时仍会 STW,但效率高于 Serial GC。
STW 情况:STW 时间比 Serial GC 短(多线程并行加速),但仍随堆大小增加而显著增长。
内存管理:支持中等堆内存(通常 1GB~10GB),堆过大会导致 STW 时间过长。
优点
-
吞吐量高(GC 耗时占比低),充分利用多核 CPU。
-
适合对吞吐量敏感、可接受一定 STW 延迟的场景。
缺点
-
无法控制 STW 时间(随堆增大而变长),不适合延迟敏感型应用。
适用场景
-
科学计算、大数据分析(如 Hadoop 离线任务)。
-
后台批处理任务(对响应时间要求低,注重计算效率)。
JDK 支持
-
JDK 1.4.2 引入,JDK 5~8 默认 GC(Server 模式),需通过
-XX:+UseParallelGC或-XX:+UseParallelOldGC开启。
3. CMS(Concurrent Mark-Sweep,并发标记 - 清除)
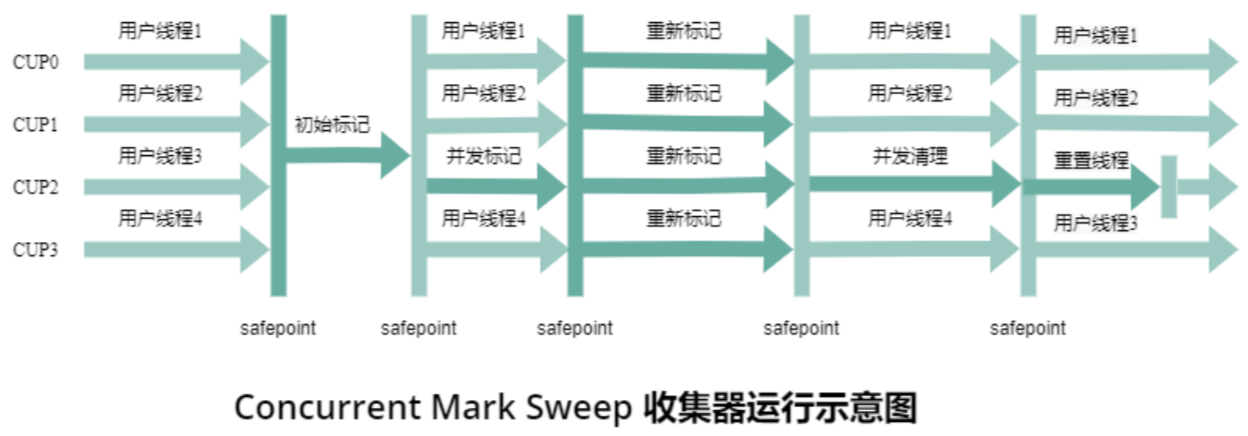
核心目标:最小化STW 延迟,适合对响应时间敏感的应用(如 Web 服务)。
分代策略:严格分代(新生代 + 老年代):
-
新生代:采用Parallel Scavenge(并行复制,与 Parallel GC 一致)。
-
老年代:采用并发标记 - 清除算法(不压缩内存,避免整理耗时)。
并发与并行结合:
-
初始标记、重新标记:STW(单线程 / 多线程快速执行)。
-
并发标记、并发清除:与应用线程同时运行(多线程 GC)。
工作流程:
-
初始标记:STW,标记 GC Roots 直接引用的对象(耗时极短)。
-
并发标记:与应用线程并行,遍历标记所有可达对象(耗时最长,无 STW)。
-
重新标记:STW,修正并发标记期间因应用线程修改引用导致的标记偏差(耗时短)。
-
并发清除:与应用线程并行,清除未标记的垃圾对象(无 STW)。
STW 时间极短(仅初始标记和重新标记阶段,通常 < 10ms),但并发阶段会占用 CPU 资源。
内存管理
-
老年代不压缩,会产生内存碎片(长期运行可能导致大对象无法分配内存,触发 Full GC)。
-
堆内存不宜过大(通常 < 32GB,否则并发标记阶段耗时过长)。
优点:
-
低延迟,适合 Web 服务、实时响应系统。
-
STW 时间短,对用户体验影响小。
缺点:
-
并发阶段占用 CPU 资源,降低应用吞吐量(约 10%~20%)。
-
内存碎片严重,需定期通过
-XX:+UseCMSCompactAtFullCollection强制压缩。 -
对大内存支持差,且实现复杂(易出现内存泄漏风险)。
适用场景
-
互联网 Web 应用(如电商网站、API 服务)。
-
对响应时间敏感(如延迟要求 < 100ms)的在线服务。
-
JDK 5 引入,JDK 9 标记为废弃,JDK 14 正式移除,需通过
-XX:+UseConcMarkSweepGC开启(仅老年代使用 CMS)。
4. G1(Garbage-First,垃圾优先)
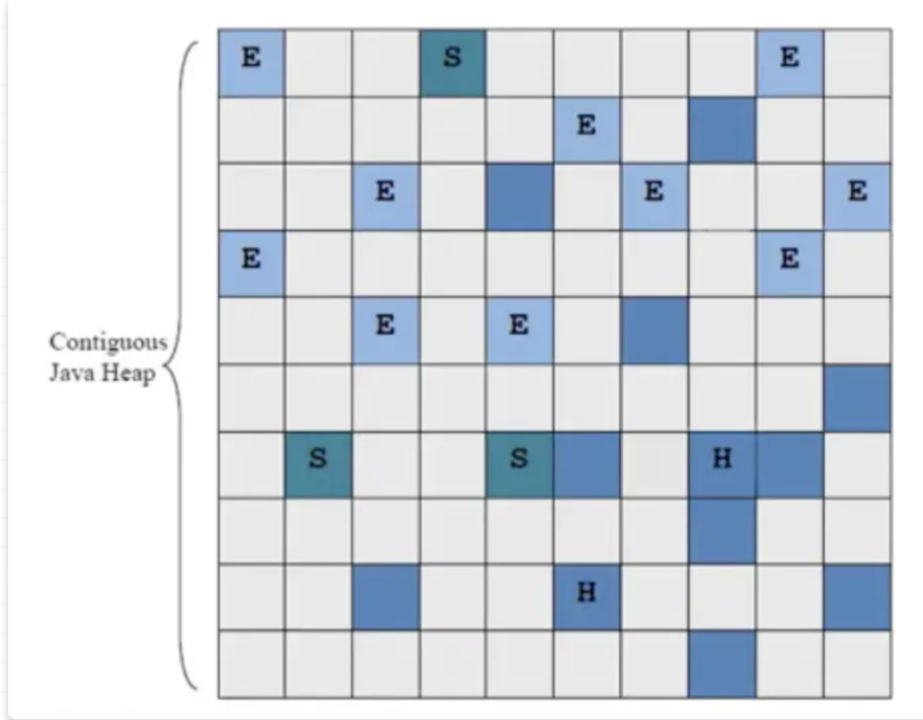
核心目标:平衡吞吐量与延迟,支持可预测的 STW 时间,适合中大型堆内存场景。
区域化分代(逻辑分代,物理不分隔):
-
堆内存划分为 2048 个大小相等的独立区域(Region,1MB~32MB,可配置)。
-
每个 Region 动态扮演 Eden、Survivor 或老年代角色(根据对象存活时间)。
回收算法:
-
新生代:复制算法(多线程并行复制存活对象到新 Region)。
-
老年代:混合回收(优先回收垃圾占比高的 Region,结合标记 - 复制避免碎片)。
并行 + 并发结合:
-
年轻代回收:多线程并行 STW(类似 Parallel GC)。
-
混合回收(含老年代):初始标记(STW)→ 并发标记(与应用线程并行)→ 最终标记(STW)→ 筛选回收(多线程并行 STW,选择垃圾多的 Region 回收)。
STW 情况:通过-XX:MaxGCPauseMillis(默认 200ms)设置目标 STW 时间,G1 会动态调整回收 Region 数量以满足目标,实际 STW 时间通常可控制在 100ms 内。
内存管理
-
支持中等至大型堆内存(1GB~ 数百 GB),Region 机制使回收更灵活。
-
通过复制算法减少内存碎片(回收时将存活对象复制到新 Region)。
优点:
-
兼顾吞吐量和延迟,适用场景广泛。
-
可预测 STW 时间,适合企业级应用。
-
内存碎片少,支持动态调整新生代 / 老年代比例。
缺点:
-
小堆内存场景下效率不如 Serial/Parallel GC(Region 管理有额外开销)。
-
并发标记阶段仍会占用部分 CPU 资源。
适用场景
-
企业级服务(如 ERP 系统、电商中台)。
-
堆内存 10GB~100GB 的中大型应用(需平衡吞吐量和延迟)。
JDK 支持
-
JDK 7 引入,JDK 9 起成为默认 GC,需通过
-XX:+UseG1GC开启(默认启用)。 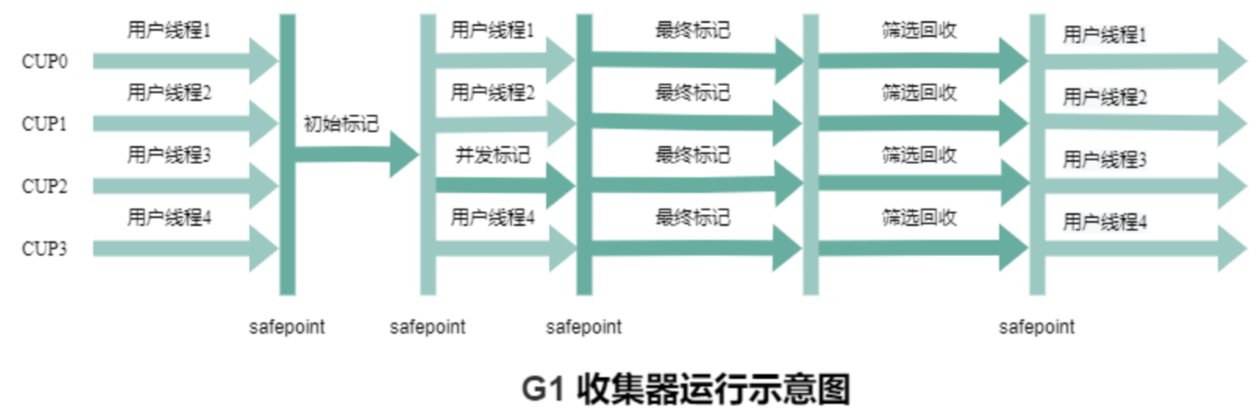
5. ZGC(Z Garbage Collector)
核心目标:超低延迟(<10ms)+ 超大堆内存支持(TB 级),适合内存密集型、低延迟要求的大型系统。
不分代(所有对象统一管理),但可通过-XX:ZGenerational启用分代模式(JDK 21+)。
回收算法:基于区域化内存(Region 大小动态调整:小 Region 2MB,中 Region 32MB,大 Region 大对象独占),采用三色标记法 + 读屏障:
-
标记阶段:并发遍历对象引用(无 STW)。
-
重定位阶段:并发移动存活对象(通过读屏障保证对象访问正确性)。
全并发 + 并行:几乎所有阶段(标记、重定位)与应用线程并发执行,仅初始标记和最终标记有极短 STW(通常 < 1ms)。
STW 情况:STW 时间极短(<10ms,且与堆大小无关),主要来自初始标记和最终标记(各约 1ms)。
内存管理
-
支持超大堆内存(从 MB 级到 TB 级,如 16TB 堆内存仍能保持低延迟)。
-
无内存碎片(重定位阶段自动压缩对象)。
优点
-
延迟极低,适合对响应时间敏感的大型系统。
-
堆内存支持规模大,无需担心内存碎片。
-
吞吐量损失小(并发阶段 CPU 占用低)。
缺点
-
小堆内存场景下,额外开销(如读屏障)可能高于 G1。
-
分代模式(JDK 21+)仍在优化中,成熟度略低于 G1。
适用场景
-
大型分布式系统(如分布式数据库、缓存服务)。
-
内存密集型应用(如大数据实时分析、AI 训练平台)。
JDK 支持
-
JDK 11 作为实验特性引入,JDK 15 成为正式特性,需通过
-XX:+UseZGC开启。
6. Shenandoah( shen-uh-doh-uh )
核心目标:低延迟(<10ms)+ 并发整理,与堆大小无关的 STW 时间,适合金融、交易等强实时场景。
不分代(JDK 17 + 支持分代模式),堆内存划分为 Region(类似 G1)。
回收算法:
并发标记 - 并发整理:通过 “转发指针”(每个对象额外存储一个指向新地址的指针)和 “写屏障” 实现并发移动对象,无需 STW 整理。
线程模型:全并发:标记、整理阶段均与应用线程并发执行,仅初始标记和最终标记有极短 STW(<1ms)。
STW 情况:STW 时间仅与存活对象数量相关(与堆大小无关),通常 < 10ms,适合超大堆。
内存管理
-
支持 TB 级堆内存,无内存碎片(并发整理阶段自动压缩)。
-
对大对象友好(单独 Region 存储,避免频繁移动)。
优点
-
延迟稳定(不受堆大小影响),适合金融交易等强实时场景。
-
并发整理无碎片,内存利用率高。
缺点
-
实现复杂,依赖 JVM 源码修改(早期仅 Red Hat OpenJDK 支持)。
-
额外内存开销(转发指针占对象大小的 12.5%)。
适用场景
-
金融交易系统(如高频交易、支付网关)。
-
超大内存服务(如 PB 级数据处理节点)。
JDK 支持
-
JDK 12 作为实验特性引入,JDK 17 成为正式特性,需通过
-XX:+UseShenandoahGC开启。
特性对比表:
| 收集器 | 核心目标 | 分代策略 | 回收算法 | 线程模型 | STW 时间 | 堆内存支持 | 适用场景 |
|---|---|---|---|---|---|---|---|
| Serial GC | 低内存占用 | 严格分代 | 复制(新)+ 标记 - 整理(老) | 单线程 STW | 长(随堆增大) | <1GB | 嵌入式、小型工具 |
| Parallel GC | 高吞吐量 | 严格分代 | 并行复制 + 并行标记 - 整理 | 多线程并行 STW | 中(比 Serial 短) | 1GB~10GB | 科学计算、批处理任务 |
| CMS | 低延迟 | 严格分代 | 并发标记 - 清除(老) | 并发 + 并行(部分 STW) | 短(<10ms) | <32GB | 传统 Web 服务(已淘汰) |
| G1 | 平衡吞吐与延迟 | 区域化分代 | 复制 + 混合回收 | 并行 + 并发 | 可预测(<100ms) | 1GB~ 数百 GB | 企业级服务、中大型应用 |
| ZGC | 超低延迟 + 大内存 | 可选分代 | 并发标记 + 重定位 | 全并发 + 并行 | 极短(<10ms) | MB~TB 级 | 大型分布式系统、内存密集型 |
| Shenandoah | 低延迟 + 并发整理 | 可选分代 | 并发标记 + 并发整理 | 全并发 | 极短(<10ms) | MB~TB 级 | 金融交易、强实时超大内存应用 |
总结:
选择 JVM GC 收集器的核心依据是业务场景:
- 小型应用 / 嵌入式:优先 Serial GC;
- 吞吐量优先(批处理):Parallel GC;
- 中大型应用(平衡吞吐与延迟):G1(默认选择);
- 超低延迟 + 大内存:ZGC 或 Shenandoah(根据 JDK 版本和生态选择)。
实际使用中需结合堆大小、CPU 核心数、延迟要求进行压测调优,而非盲目选择 “高端” 收集器。


 2022安装教程与下载地址)

)
 的必会知识点汇总)




![[数据结构] ArrayList(顺序表)与LinkedList(链表)](http://pic.xiahunao.cn/[数据结构] ArrayList(顺序表)与LinkedList(链表))

 --- 子查询篇)






)