1、线性回归模型
线性回归模型(Liner Regression),是利用线性拟合的方式来探寻数据背后的规律。通过搭建线性回归模型,可以寻找这些散点(也称样本点)背后的趋势线(也称回归曲线)。
借助回归曲线,我们可以进行一些简单的预测分析,或因果关系分析。
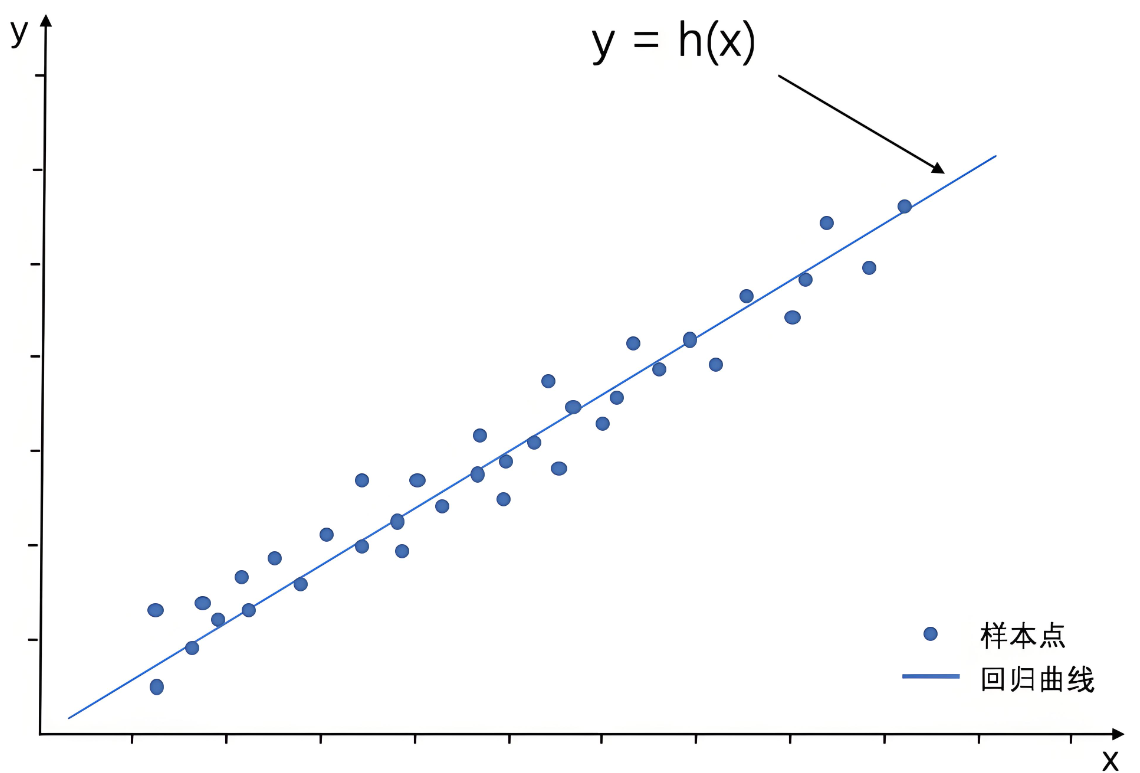
1.1、一元线性回归数学原理
一元线性回归模型也称为简单线性回归模型,其形式可以通过如下方程公式表达:
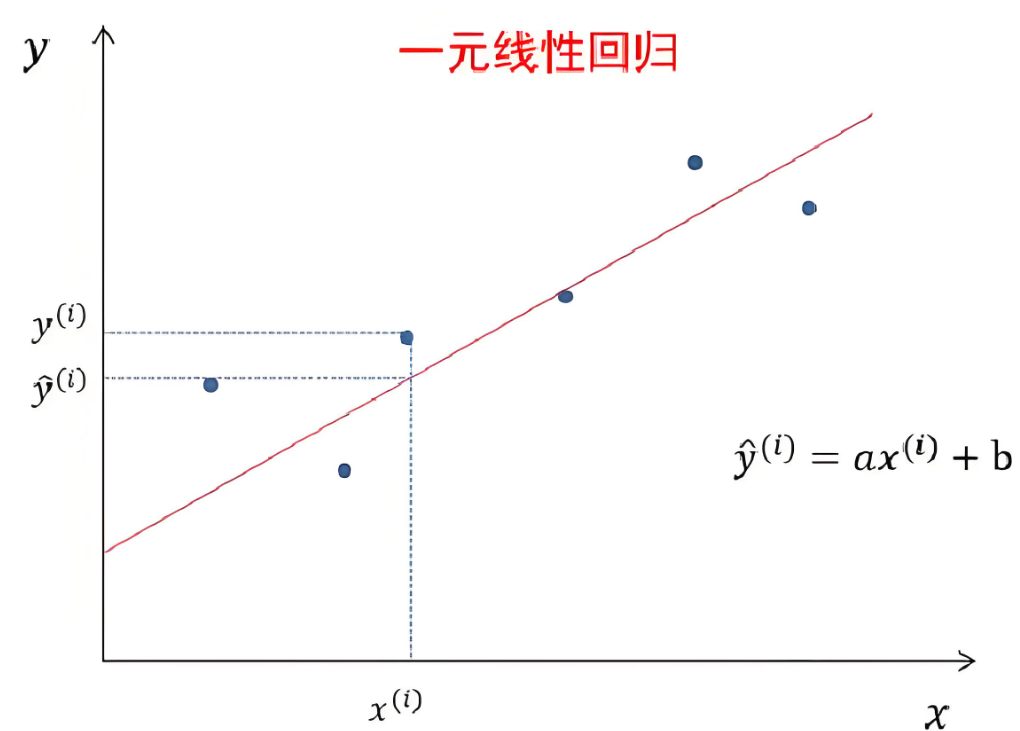
其中:y是目标(因)变量,x是特征(自)变量,a表示回归系数,b表示截距。
一元线性回归的目的,是拟合出一条线,使得预测值()和实际值(
)尽可能的接近,如果大部分点都落在拟合出来的线上,那么该线性回归模型拟合效果较好。
此外,我们可以通过两者差值平方和(,也称为残值平方和)来进行衡量,在机器学习领域,该残差平方和也被称之为回归模型的损失函数。
1.2、一元线性回归的代码实现
在Python中,我们可以通过Scikit-learn工具库,快速构建一元线性回归模型。实现一元线性回归的核心功能代码如下:
from sklearn.linear_model import LinearRegression
from matplotlib import pyplot as plt
import matplotlib# pycharm工具:设置本地显示后端
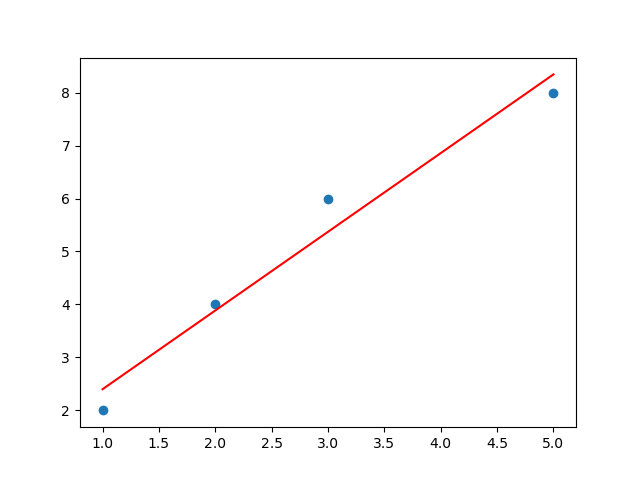
matplotlib.use('TkAgg')if __name__ == '__main__':X = [[1],[2],[3],[5]]Y = [2,4,6,8]# 1. 构建线性回归模型对象lg = LinearRegression()# 2. 使用准备的自变量、因变量数据做训练lg.fit(X, Y)# 3. 使用训练好的模型预测新数据集y_pred = lg.predict([[4]])print(f"预测值:{y_pred[0]:.4f}") # 6.8571# 4. 绘制自变量、因变量组成的散点图plt.scatter(X, Y, label='实际数据')# 5. 绘制训练结果一元线性回归方程plt.plot(X, lg.predict(X), color='red', label='回归线')# 6. 展示执行效果|或使用Jupyter执行效果plt.show()
借助matplotlib工具,将模型进行可视化展示:
1.3、多元线性回归
同理,多元线性回归模型是在一元线性回归模型基础上,增加多个自变量,其形式可以通过如下方程公式表达:
其中:y是目标(因)变量,是特征(自)变量,
表示权重系数,
表示(误差项)截距。
线性回归使用均方误差(MSE)作为损失函数:
1.3.1、经典案例
此处,我们使用波士顿房价数据集(Boston Housing Dataset)一个经典的回归分析数据集,常用于预测房价。
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegressionif __name__ == '__main__':# 1. 数据加载data = pd.read_csv("boston_house_prices.csv", skiprows=1)# 2. 特征和标签分离X = data.loc[:, :"LSTAT"].to_numpy() # 特征y = data.loc[:, "MEDV"].to_numpy() # 目标标签# 3. 数据切分X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)# 4. 手动数据标准化(可用标准库实现)mu = X_train.mean(axis=0)sigma = X_train.std(axis=0) + 1e-9X_train = (X_train - mu) / sigmaX_test = (X_test - mu) / sigma# 5. 模型训练lr = LinearRegression()lr.fit(X=X_train, y=y_train)# 6. 预测与评估y_pred = lr.predict(X=X_test)mse = ((y_pred - y_test) ** 2).mean()print(f"均⽅误差: {mse}")1.3.2、实战案例
案例:基于线性回归模型的客户价值预测
客户价值可以帮助企业预测未来一段时间,客户预计能够为企业带来多少利润。尝试结合已有的客户价值数据表,完成以下功能。
1、结合客户的价值数据,构建回归模型;
| 历史贷款金额 | 贷款次数 | 学历 | 月收入 | 性别 | 是否有房产 | 客户价值 |
| 50000 | 2 | 2 | 20000 | 1 | 1 | 2000 |
| 50000 | 3 | 1 | 15000 | 0 | 0 | 1200 |
| 100000 | 5 | 2 | 32000 | 1 | 0 | 1800 |
| - | - | - | - | - | - | - |
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_reportif __name__ == '__main__':# 1. 加载数据df = pd.read_csv("cust_value_data.csv", skiprows=1)# 2. 查看原始数据信息print("原始数据前10行:")print(df.head(10))print("\n数据信息:")print(df.info())print("缺失值统计:")print(df.isnull().sum())# 3. 找出存在null值的行null_rows = df[df.isnull().any(axis=1)]print("\n存在缺失值的行:")print(null_rows)# 4. 数据预处理# 4.1. 均值填充:将age为null的使用均值填充age_mean = df['age'].mean()df['age'].fillna(age_mean, inplace=True)# 4.2. 缺失值填充:将贷款均值填充history_debit_mean = df['history_debit'].mean()df['history_debit'].fillna(history_debit_mean, inplace=True)# 4.3. 缺失值填充:将月收入均值填充month_income_mean = df['month_income'].mean()df['month_income'].fillna(month_income_mean, inplace=True)# 5. 选择特征和目标变量# 选择特征列和目标列feature_cols = ['history_debit', 'debit_times', 'degree', 'month_income', 'sex', 'house_flag']X = df[feature_cols]y = df['customer_value']# 6. 数据切分(70%训练,30%测试)X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 7. 模型训练model = LinearRegression()model.fit(X_train, y_train)# 8. 预测与评估y_pred = model.predict(X_test)# 5. 模型评估accuracy = accuracy_score(y_test, y_pred)report = classification_report(y_test, y_pred)print("模型准确率:", accuracy)print("分类报告:")print(report)2、逻辑回归模型
逻辑回归(Logistic Regression)是线性回归的一种扩展,主要用来处理分类模型,因其简单有效、可解释性强的特点,目前在多行业中被广泛应用。
逻辑回归的本质,是将线性回归模型(-∞,+∞)通过Sigmoid()函数(也称Logistic函数) 进行了非线性转换,从而得到一个介于(0,1)之间的概率值,从而实现分类的效果。
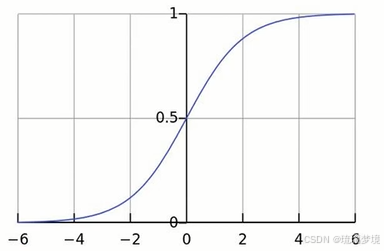
sigmoid函数代码实现:
import numpy as np
import matplotlib.pyplot as pltdef sigmoid(x):"""Sigmoid 激活函数"""return 1 / (1 + np.exp(-x))if __name__ == '__main__':# 可视化 Sigmoid 函数x = np.linspace(-10, 10, 100)plt.plot(x, sigmoid(x))plt.grid()plt.title('Sigmoid Function')plt.xlabel('Input')plt.ylabel('Output')plt.show()2.1、分类与回归的区别
回归模型:用于对连续变量进行预测,如预测收入范围、房价变化、客户价值等,线性回归就是一种典型的回归模型。
分类模型:用于对离散变量进行预测,分类模型预测的变量不是连续的,而是离散的一些类型。例如,使用常见的二分类模型,预测客户是否违约、客户是否会流失、肿瘤是良性还是恶性等。
2.2、经典案例
这是一个经典的二分类数据集,其目标是根据乳腺肿瘤的显微图像特征来诊断肿瘤是恶性(Malignant)还是良性(Benign)。
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_splitif __name__ == '__main__':# 1. 加载数据X, y = load_breast_cancer(return_X_y=True)# 2. 数据切分X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)# 3. 数据标准化mu = X_train.mean(axis=0)sigma = X_train.std(axis=0) + 1e-9X_train = (X_train - mu) / sigmaX_test = (X_test - mu) / sigma# 4. 模型训练lr = LogisticRegression()lr.fit(X=X_train, y=y_train)# 5. 预测与评估y_pred = lr.predict(X=X_test)accuracy = (y_pred == y_test).mean()print(f"准确率: {accuracy:.4f}")# 查看模型参数print(f"权重数量: {lr.coef_.shape}")print(f"偏置项: {lr.intercept_}")2.3、实战案例
案例:信用卡客户流失预警模型
客户流失预警模型可以用于预测客户未来的流失情况。针对流失概率较大的客户,可以采取适当的措施进行挽留,有效降低客户的流失率。根据案例数据集,完成以下功能:
| 用户ID | 账户金额(元) | 用户年龄 | 学历 | 性别 | 最后一次交易时间 | 上月交易佣金(元) | 累计交易佣金(元) | 使用信用卡年限(年 | 是否流失 |
| 10011 | 52000 | 32 | 本科 | 难 | 2025/6/2 | 232.21 | 3500 | 5 | 0 |
1、结合信用卡客户流失数据,构建逻辑回归模型(分类)
2、结合已有的数据判断模型预测准确性,查看每名客户的预估流失概率
import pandas as pd
from datetime import datetime
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_reportif __name__ == '__main__':# 1. 加载数据df = pd.read_csv("credit_data.csv", skiprows=1)# 2. 查看原始数据信息print("原始数据前10行:")print(df.head(10))print("\n数据信息:")print(df.info())print("缺失值统计:")print(df.isnull().sum())# 3. 找出存在null值的行null_rows = df[df.isnull().any(axis=1)]print("\n存在缺失值的行:")print(null_rows)# 4. 数据预处理# 4.1. 删除行:删除amount为null的行df = df.dropna(subset=['amount'])# 4.2. 均值填充:将age为null的使用均值填充age_mean = df['age'].mean()df['age'].fillna(age_mean, inplace=True)# 4.3. 缺失值填充:将degree为null的使用"本科"填充df['degree'].fillna('本科', inplace=True)# 4.4. 删除列:userId列(与训练无关列),axis=1 表示删除列df = df.drop('userId', axis=1)# 4.5.特征工程:性别编码(男=0, 女=1)df['sex'] = df['sex'].map({'男': 0, '女': 1})current_date = datetime.now()# 4.6 最后一次交易时间处理为距现在时间的天数df['last_txn_time'] = pd.to_datetime(df['last_txn_time'])df['days_since_last_txn'] = (current_date - df['last_txn_time']).dt.days# 4.7 对学历进行one-hot编码,并避免多重共线性(删除基准类别"本科")degree_dummies = pd.get_dummies(df['degree'], prefix='degree')if 'degree_本科' in degree_dummies.columns:degree_dummies = degree_dummies.drop('degree_本科', axis=1)# axis=1,指定df,degree_dummiesdf = pd.concat([df, degree_dummies], axis=1)# 5. 选择特征和目标变量# 选择特征列和目标列feature_cols = ['amount', 'age', 'last_month_kickback', 'accu_kickback', 'used_limit', 'days_since_last_txn', 'sex']X = df[feature_cols + degree_dummies.columns.tolist()]y = df['loss_flag']# 6. 数据切分(70%训练,30%测试)X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 7. 模型训练model = LogisticRegression(random_state=42)model.fit(X_train, y_train)# 8. 预测与评估y_pred = model.predict(X_test)# 5. 模型评估accuracy = accuracy_score(y_test, y_pred)report = classification_report(y_test, y_pred)print("模型准确率:", accuracy)print("分类报告:")print(report)


















