我认为知识是一定要系统化的学习,结构化梳理,这样在运用或思考的时候,能够回忆起自己在这一块梳理的知识结构,如果有记录那么能快速回忆并理解,如果没有记录,那么说明对自己来说超纲了,把知识进行分类,写入自己的知识库,那就对知识点有了一个快速的定位和理解。能够梳理清晰自己所学的知识,并定位知识点。这就是我认为系统化知识的意义。
我在学习过程中发现,我自己的思维方式和理解方式,想要学会和理解一个知识点,使用它是最快的方式,将这个知识点实战一次,就基本知道了这东西的作用。
- 使用层面
1)起步入门:粗读是什么?有什么用?解决了什么问题? 怎么用?(来一个快速实战,上手做一做)
2)运用核心功能:也是基础功能、核心知识点,学习运用功能以及掌握核心知识为主。
3)最佳实践:核心知识要实践,知识运用有无数种方式,最佳实践能避免错误的运用知识。理论是在原理层面指导实践。如果有最佳实践的总结,那便是最好的理论。比如:【关系型数据库设计理论】就是指导如何设计出高质量的关系型数据库。
4)小总结:技术优缺点,适用场景。
学到这里,我可以说我会用 CRUD 了。
当然仅仅会用是不够的,要想用的好、用的灵活,必须要知道它的内部结构和工作原理,比如MySQL ,如果仅仅停留在使用层面,那可能只会CRUD, 如果深入学习了MySQL 内部是B+树索引,二级索引等,那么在创建表时会酌情新增索引,毕竟每新增一个索引就要创建一棵新的B+树,另外在查询表的时候知道如何利用索引高效查询,如果了解MySQL内部有redo log ,DoubleWrtie pool , 就不那么担心 SQL 语句执行过程中断电的问题。知道了 buffer pool ,就明白 InnoDB 是由缓存的,缓存优先存储最常用的数据,这可能为编写SQL 带来一些便利,不过学习到最后明白了 MySQL 调优有限,不如 redis 或者业务优化来的更快更高效。
这便是深入学习和仅仅停留在使用层面的不同之处,我们想要用好一个技术,自然是要学习技术内部原理,明白技术内部是如何工作的,这就是我最喜欢的两个学习思维,学习技术内部层次结构和工作流程,这两个方面弄明白了,思维就通畅了。
以今天学到的 MySQL 为例,看看内部层次结构和工作流程。直接上图了
这是通用关系型数据库的内部结构图
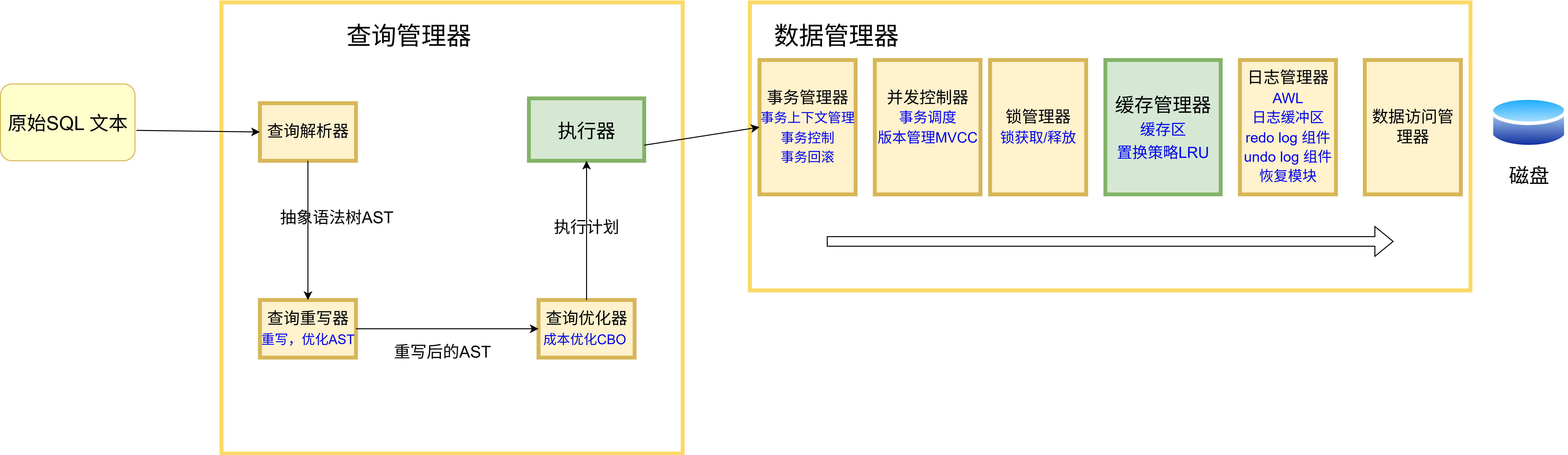
这是MySQL 内部结构图
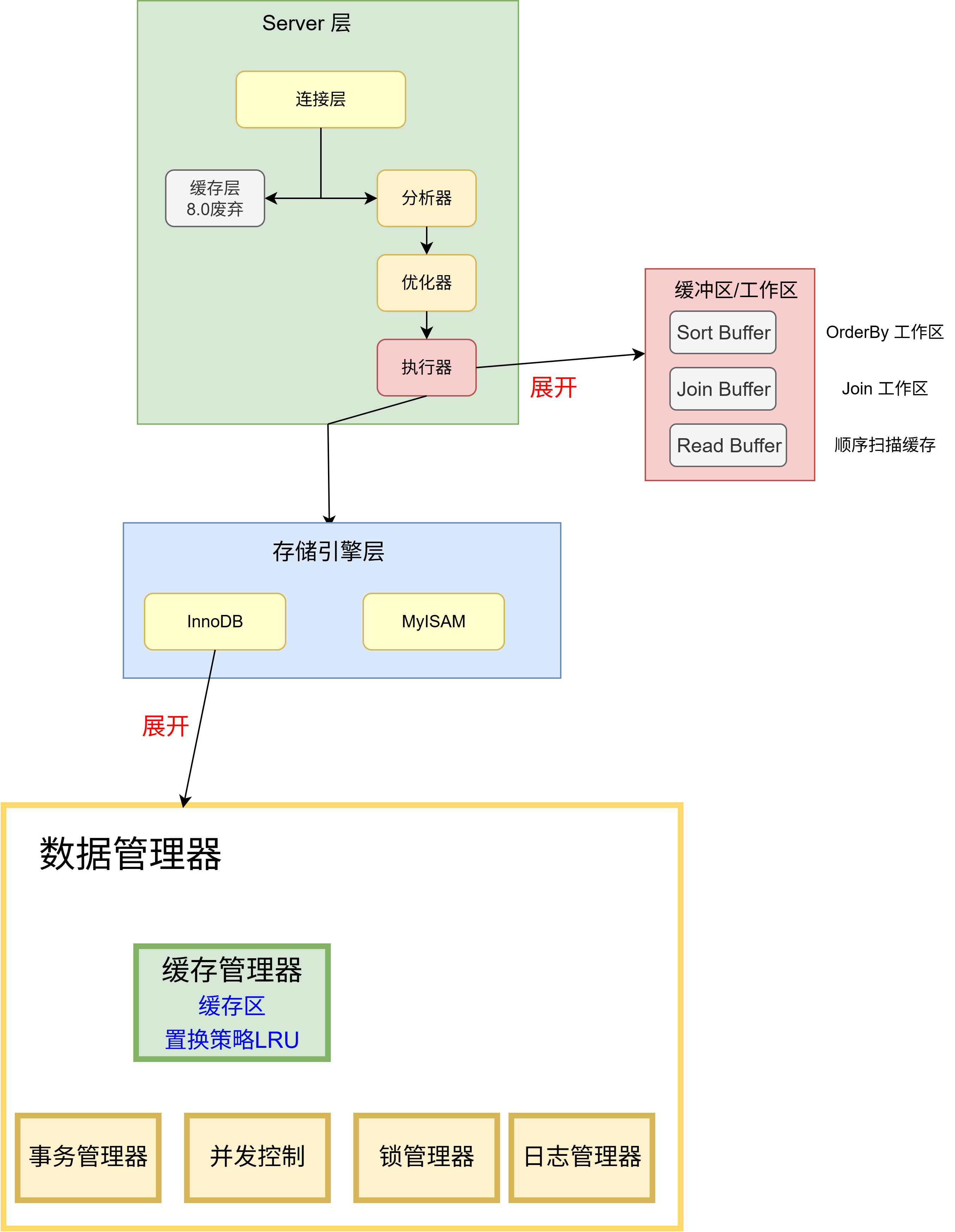
这是 InnoDB 内部存储结构图

画出了这三张图,我基本上了解 MySQL 内部结构的全貌,当然以上的图并没有画出 MySQL 的所有结构,所有的部分,随着我对 MySQL 知识面的扩展,我会继续追加,这些图有助于我定位正在学习知识点属于 MySQL 结构的哪一个部分。比如 Doublewrite buffer, 将它定位到结构中,看三分钟文档我就理解了。
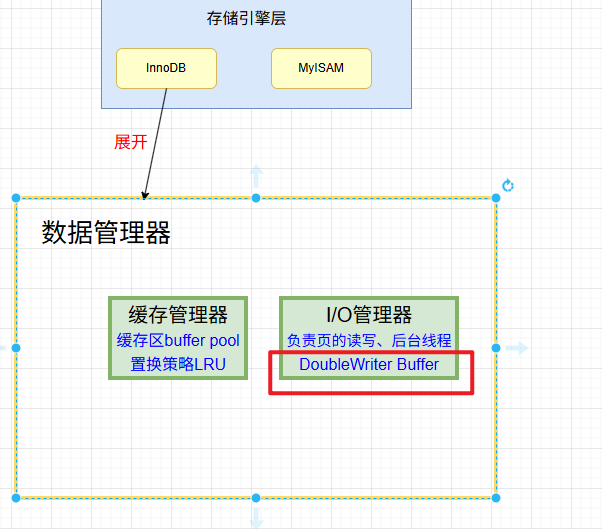
我另一个热爱的学习方式是工作流程,看看这玩意是咋工作的,就能把内部结构串起来,理解MySQL 各个结构的作用。当然它的工作流程不止一种,不同情况会有不同的工作流程,可能很多很复杂。不过我们先掌握正常运转的工作流程,意外情况掌握几个经典的~
再拿 MySQL 举例,我们来看看工作原理:
左边红色的块是 Java 程序,集成了 MYSQL 驱动并且引用线程池,避免频繁创建和销毁连接带来的损耗。
中间是发送网络请求,java 应用发送的 SQL 语句的请求在 MySQL 中是由一个个的线程去处理的。
那么可以得出, 一个 SQL 请求会产生 两个活跃的线程:一个在 Java 应用侧等待/处理结果,一个在 MySQL 侧执行 SQL。 注意不是占用哈,占用的意思是拿着不放,活跃的线程是可以调度,切换,阻塞。
右边是MySQL 数据库,同样用一个连接池接收 SQL 请求,线程读取网络请求后在MySQL内部执行。
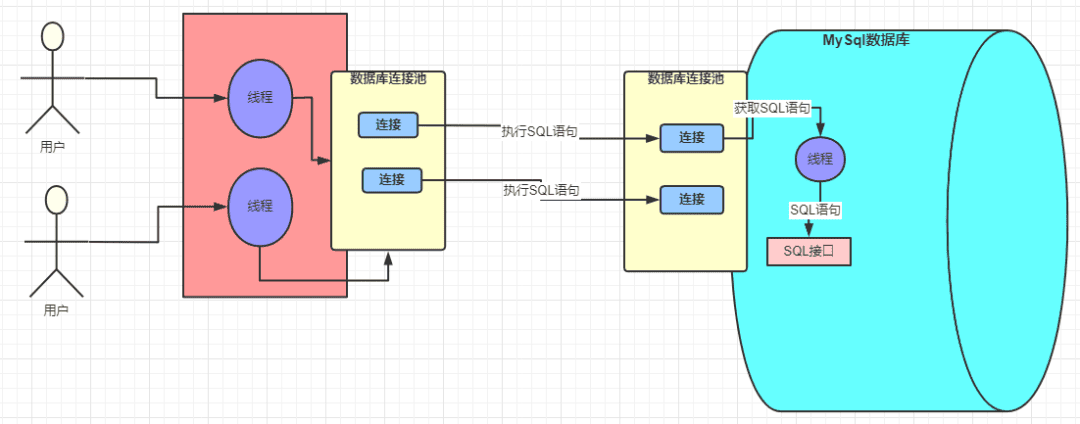
Java 程序通过网络请求将 SQL 语句字符串发送给 MySQL 服务后,我们看看MySQL 服务内部怎么处理。
1. MYSQL 处理请求流程
- SQL 接口:MySQL 中处理请求的线程在获取到请求以后获取 SQL 语句去交给 SQL 接口去处理。
- SQL 解析器:他会将 SQL 接口传递过来的 SQL 语句进行解析,翻译成 MySQL 自己能认识的语言
- SQL 优化器:MySQL 会帮我去使用他自己认为的最好的方式去优化这条 SQL 语句,并生成一条条的执行计划
- 存储引擎:查询优化器会调用存储引擎的接口,去执行 SQL,也就是说真正执行 SQL 的动作是在存储引擎中完成的。
- 执行器:前面那些组件的操作最终必须通过执行器去调用存储引擎接口才能被执行
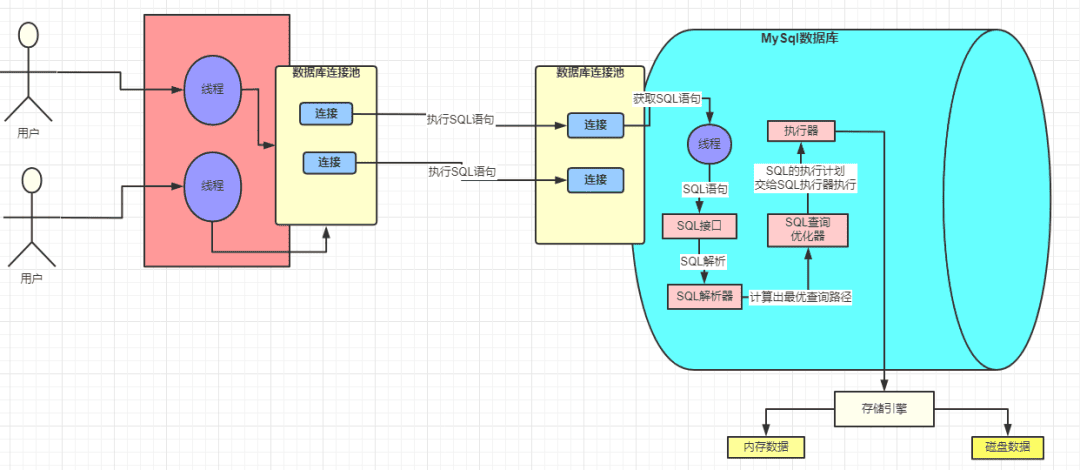
接下来看看存储引擎做了什么!
2. 存储引擎执行 SQL 流程
1)Buffer Pool (缓冲池)是 InnoDB 存储引擎中非常重要的内存结构, InnoDB 级别的缓存。缓冲池中的数据和数据库(磁盘)中的数据不一致时候,我们就认为缓存中的数据是脏数据,
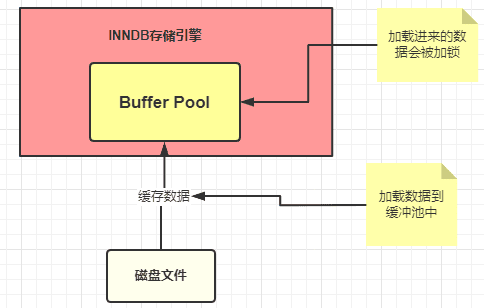
2)undo 日志文件:记录数据被修改前的样子,事务回滚时发挥作用。我们程序是正常运作,这里仅仅记录。
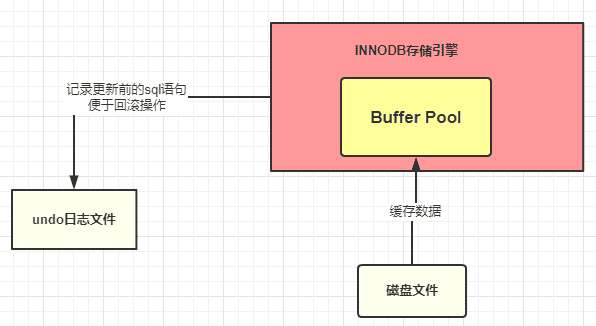
3)redo 日志文件:记录数据被修改后的样子,redo 日志文件是 InnoDB 特有的,他是存储引擎级别的,不是 MySQL 级别的,缓存池更新后记录到缓存日志中,缓存日志默认是立刻写入磁盘。缓存池数据是延迟。
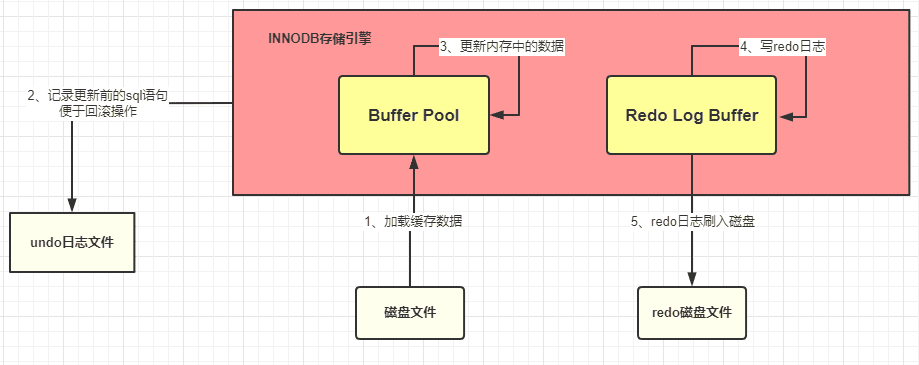
InnoDB 目前整体执行流程:
- 准备更新一条 SQL 语句
- MySQL(innodb)会先去缓冲池(BufferPool)中去查找这条数据,没找到就会去磁盘中查找,如果查找到就会将这条数据加载到缓冲池(BufferPool)中
- 在加载到 Buffer Pool 的同时,会将这条数据的原始记录保存到 undo 日志文件中
- innodb 会在 Buffer Pool 中执行更新操作
- 更新后的数据会记录在 redo log buffer 中
- MySQL 提交事务的时候,会将 redo log buffer 中的数据写入到 redo 日志文件中 刷磁盘可以通过 innodb_flush_log_at_trx_commit 参数来设置
- 值为 0 表示不刷入磁盘
- 值为 1 表示立即刷入磁盘
- 值为 2 表示先刷到 os cache
- myslq 重启的时候会将 redo 日志恢复到缓冲池中
4) binlog : 记录整个操作过程,bin log 通过追加的方式记录,当文件大小大于给定值后,后续的日志会记录到新的文件上,bin log 适用于主从复制和数据恢复。
bin log 刷盘有三种模式
- STATMENT :基于 SQL 语句的复制(statement-based replication, SBR),每一条会修改数据的 SQL 语句会记录到 bin log 中
- ROW:基于行的复制(row-based replication, RBR),不记录每条SQL语句的上下文信息,仅需记录哪条数据被修改了
- MIXED:基于 STATMENT 和 ROW 两种模式的混合复制( mixed-based replication, MBR ),一般的复制使用 STATEMENT 模式保存 bin log ,对于 STATEMENT 模式无法复制的操作使用 ROW 模式保存 bin log
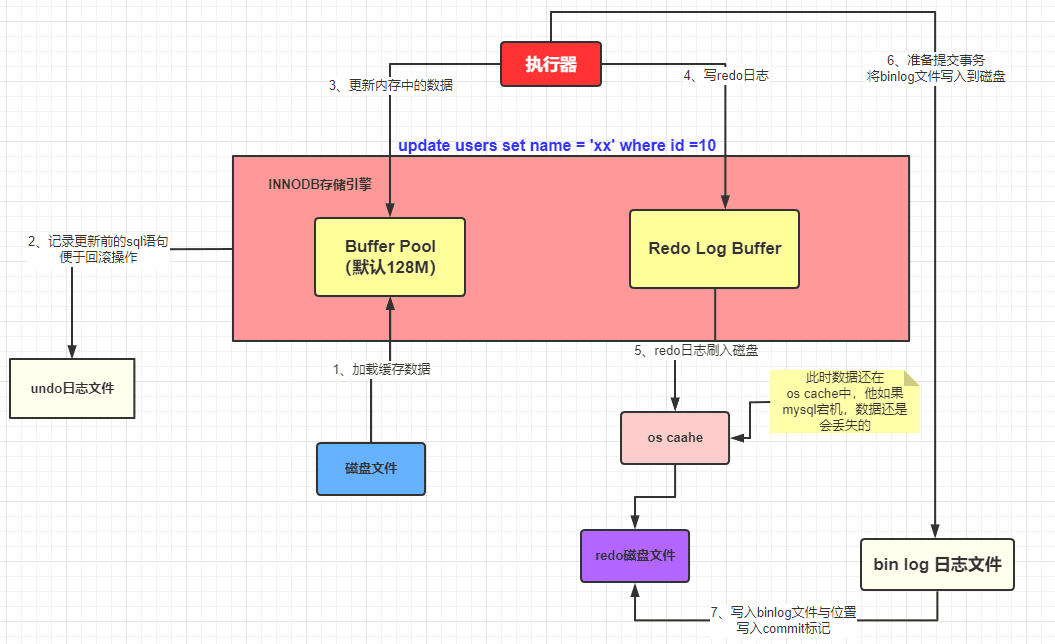
5) MySQL 会有一个后台线程,它会在某个时机从 Buffer Pool 中挑选出脏数据刷到 MySQL 数据库中

如果在数据被写入到bin log文件的时候,刚写完,数据库宕机了,数据会丢失吗?
首先可以确定的是,只要redo log最后没有 commit 标记,说明本次的事务一定是失败的。但是数据是没有丢失了,因为已经被记录到redo log的磁盘文件中了。在 MySQL 重启的时候,就会将 redo log 中的数据恢复(加载)到Buffer Pool中。
最后返回到查询执行器,经过封装后发回给调用的客户端。
从这两个角度学习新技术,基本上就能掌握技术,但是并不能掌握高级使用场景,比如知道了MySQL 以上内容,当碰到主从复制,读写分离、分库分表的场景还是手足无措。这些都属于MySQL的优化,一门技术核心功能掌握了,肯定要想还能怎么优化,优化到上限是什么?优化的代价又是什么?
当使用分库分表,比如将数据库做了一个水平分库,把一个库分成多个库,这样的数据存在多个数据库中,在高并发场景下,对多个数据库读写肯定比对一个库读写要快不少,做了一个性能优化,这是一种 MySQL 的高阶使用。
分库的代价是什么呢?
此时思维要切换到管理多个数据库带来了什么麻烦?
我们都知道 SQL 语句是在数据库中执行的,也就是说 SQL 中的 Order By 排序仅仅是对于单个数据库排序,而我的数据库有多个,这并不算是对我系统的全部数据排序。
另外还有 count(*) , START TRANSACTION 都会出现这种情况。这是第一个代价,管理数据库变得更复杂。
第二个代价,要把思维切换到存储数据层面,你能想到什么?
ID 要保持唯一性,多个数据库就有可能发生 ID 重复,那么 ID 失去了唯一性还能叫 ID 吗?根据一个ID 查出两个人这合理吗?我不希望有人跟我的身份证同号呀,可想而知这个问题会带来多少麻烦。
问题的解决办法不加以探索了,我要学习一些更核心的知识,毕竟我还是太菜了。

![NSSCTF每日一题_Web_[SWPUCTF 2022 新生赛]奇妙的MD5](http://pic.xiahunao.cn/NSSCTF每日一题_Web_[SWPUCTF 2022 新生赛]奇妙的MD5)










![[论文阅读] 人工智能 + 软件工程 | 别让AI写的代码带“漏洞”!无触发投毒攻击的防御困境与启示](http://pic.xiahunao.cn/[论文阅读] 人工智能 + 软件工程 | 别让AI写的代码带“漏洞”!无触发投毒攻击的防御困境与启示)

- H2 Database Console 未授权访问)

更新中......)


