在现代Python开发中,异步编程已经成为提高程序性能的重要手段,特别是在处理网络请求、数据库操作或AI模型调用等耗时操作时。本文将通过实际的LangGraph 示例,深入解析async的真正作用,并揭示一个常见误区:为什么异步顺序执行与同步执行时间相近?

async的核心作用
async的主要价值在于创建异步编程环境,让程序在等待耗时操作时不被阻塞,从而提高执行效率。但是,很多开发者对异步编程存在一个根本性的误解。
常见误区:async ≠ 自动加速
许多人认为只要在函数前加上async,程序就会自动变快。这是错误的!
让我们通过一个LangGraph的实际例子来说明:
from langchain.chat_models import init_chat_model
from langgraph.graph import MessagesState, StateGraphfrom dotenv import load_dotenv
load_dotenv()
# 初始化 LLM 模型
llm = ChatDeepSeek(model="deepseek-chat")# 异步节点定义
async def async_node(state: MessagesState): new_message = await llm.ainvoke(state["messages"]) return {"messages": [new_message]}builder = StateGraph(MessagesState).add_node(async_node).set_entry_point("node")
graph = builder.compile()
完整的性能对比示例
以下是一个可以完整运行的性能测试示例:
import asyncio
import time
from langchain.chat_models import init_chat_model
from langgraph.graph import MessagesState, StateGraphfrom dotenv import load_dotenv
load_dotenv()
# 初始化 LLM 模型
llm = ChatDeepSeek(model="deepseek-chat")# 同步版本的节点
def sync_node(state: MessagesState):"""同步版本:会阻塞等待"""new_message = llm.invoke(state["messages"])return {"messages": [new_message]}# 异步版本的节点
async def async_node(state: MessagesState):"""异步版本:可以并发执行"""new_message = await llm.ainvoke(state["messages"])return {"messages": [new_message]}# 创建同步图
sync_builder = StateGraph(MessagesState).add_node("node", sync_node).set_entry_point("node")
sync_graph = sync_builder.compile()# 创建异步图
async_builder = StateGraph(MessagesState).add_node("node", async_node).set_entry_point("node")
async_graph = async_builder.compile()# 测试消息
messages = [{"role": "user", "content": "你好,请介绍一下自己"},{"role": "user", "content": "请解释一下什么是人工智能"},{"role": "user", "content": "给我讲个笑话吧"},{"role": "user", "content": "请推荐几本好书"},{"role": "user", "content": "今天天气怎么样?"}
]def test_sync_sequential():"""测试同步顺序执行"""print("同步顺序执行测试...")start_time = time.time()results = []for i, msg in enumerate(messages):print(f" 处理消息 {i+1}/{len(messages)}...")result = sync_graph.invoke({"messages": [msg]})results.append(result)end_time = time.time()duration = end_time - start_timeprint(f"同步执行完成,总耗时: {duration:.2f} 秒")return results, durationasync def test_async_sequential():"""测试异步顺序执行"""print("异步顺序执行测试...")start_time = time.time()results = []for i, msg in enumerate(messages):print(f" 处理消息 {i+1}/{len(messages)}...")result = await async_graph.ainvoke({"messages": [msg]})results.append(result)end_time = time.time()duration = end_time - start_timeprint(f"异步顺序执行完成,总耗时: {duration:.2f} 秒")return results, durationasync def test_async_concurrent():"""测试异步并发执行"""print("异步并发执行测试...")start_time = time.time()# 创建所有任务tasks = []for i, msg in enumerate(messages):print(f" 启动任务 {i+1}/{len(messages)}...")task = async_graph.ainvoke({"messages": [msg]})tasks.append(task)# 并发执行所有任务print(" 所有任务并发运行中...")results = await asyncio.gather(*tasks)end_time = time.time()duration = end_time - start_timeprint(f"异步并发执行完成,总耗时: {duration:.2f} 秒")return results, durationasync def main():"""主函数:运行所有测试"""print("=" * 60)print("LangGraph 异步 vs 同步性能测试")print("=" * 60)print(f"测试场景:处理 {len(messages)} 个 LLM 请求")print()# 1. 同步顺序执行sync_results, sync_time = test_sync_sequential()print()# 2. 异步顺序执行async_seq_results, async_seq_time = await test_async_sequential()print()# 3. 异步并发执行async_con_results, async_con_time = await test_async_concurrent()print()# 性能对比分析print("=" * 60)print("性能对比分析")print("=" * 60)print(f"同步顺序执行: {sync_time:.2f} 秒")print(f"异步顺序执行: {async_seq_time:.2f} 秒")print(f"异步并发执行: {async_con_time:.2f} 秒")print()# 计算性能提升if async_con_time > 0:speedup_vs_sync = sync_time / async_con_timespeedup_vs_async_seq = async_seq_time / async_con_timeprint("性能提升:")print(f"异步并发 vs 同步顺序: {speedup_vs_sync:.1f}x 倍速提升")print(f"异步并发 vs 异步顺序: {speedup_vs_async_seq:.1f}x 倍速提升")# 运行测试
if __name__ == "__main__":asyncio.run(main())
三种执行方式的性能对比
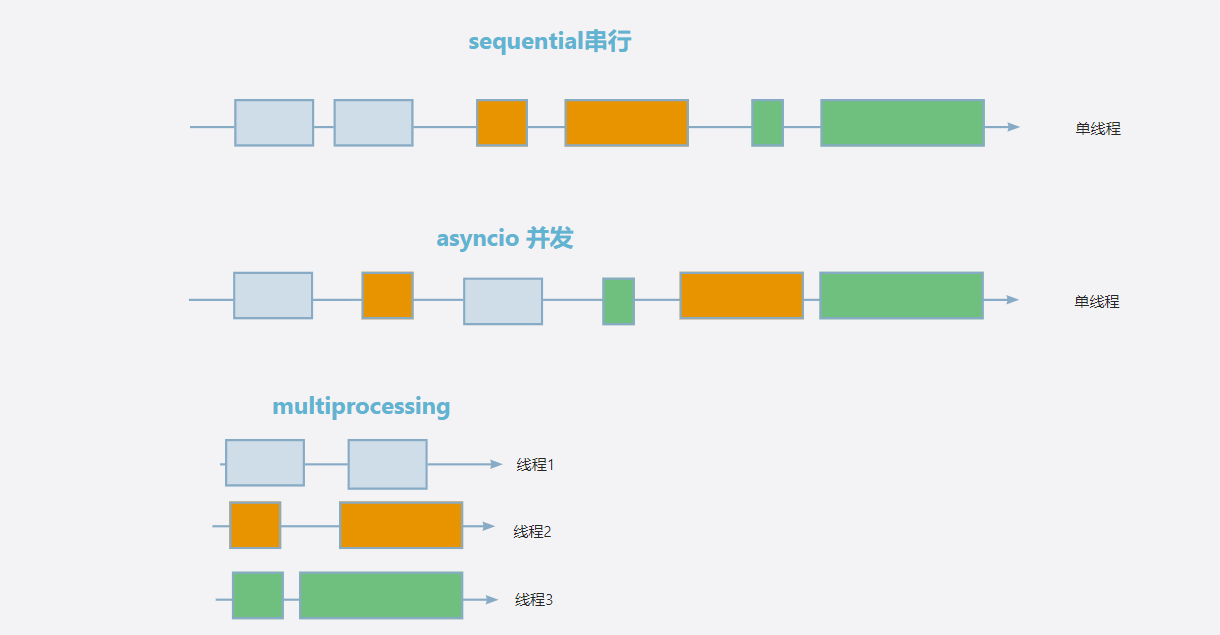
1. 同步顺序执行
def test_sync_sequential():results = []for msg in messages:result = sync_graph.invoke({"messages": [msg]})results.append(result)return results# 执行时间线:
# [请求1---等待---响应1] [请求2---等待---响应2] [请求3---等待---响应3] ...
# 总耗时:约 10-15 秒(5个请求 × 每个2-3秒)
2. 异步顺序执行
async def test_async_sequential():results = []for msg in messages:result = await async_graph.ainvoke({"messages": [msg]}) # 还是逐个等待results.append(result)return results# 执行时间线:
# [请求1---等待---响应1] [请求2---等待---响应2] [请求3---等待---响应3] ...
# 总耗时:约 10-15 秒(与同步执行相近)
3. 异步并发执行
async def test_async_concurrent():# 关键:同时启动所有任务tasks = [async_graph.ainvoke({"messages": [msg]}) for msg in messages]# 并发执行所有任务results = await asyncio.gather(*tasks)return results# 执行时间线:
# [请求1---等待---响应1]
# [请求2---等待---响应2] ← 同时进行
# [请求3---等待---响应3] ← 同时进行
# [请求4---等待---响应4] ← 同时进行
# [请求5---等待---响应5] ← 同时进行
# 总耗时:约 2-3 秒(接近单个请求时间)
为什么异步顺序执行时间相近?
这个现象困惑了很多开发者。让我们深入分析原因:
控制权的概念
在异步编程中,控制权指的是CPU当前正在执行哪段代码的决定权。
同步执行中的控制权
def sync_function():print("开始")result = llm.invoke(messages) # CPU 在这里"卡住"等待print("结束")return result# 执行流程:
# 1. CPU 执行 print("开始")
# 2. CPU 调用 llm.invoke()
# 3. CPU 完全停止,等待网络响应(2-3秒)
# 4. 收到响应后,CPU 继续执行 print("结束")
在步骤3中,CPU被完全占用但什么都不做,这就是"阻塞"。
异步执行中的控制权转移
async def async_function():print("开始")result = await llm.ainvoke(messages) # 让出控制权print("结束")return result# 执行流程:
# 1. CPU 执行 print("开始")
# 2. CPU 调用 llm.ainvoke()
# 3. 遇到 await,CPU 说:"我先去做别的事,响应来了再叫我"
# 4. CPU 可以执行其他任务
# 5. 网络响应到达,CPU 重新获得控制权
# 6. CPU 继续执行 print("结束")
关键洞察:让出控制权 ≠ 时间节省
# 异步但没有性能提升(顺序执行)
for msg in messages:result = await process_message(msg) # 还是一个接一个等待# 异步真正的优势(并发执行)
tasks = [process_message(msg) for msg in messages]
results = await asyncio.gather(*tasks) # 同时处理所有
异步顺序执行时间相近的原因:
- 都是顺序执行:两种方式都是"处理完第一个请求,再处理第二个"
- 等待时间相同:每个LLM调用的网络延迟和处理时间是一样的
- 没有并发优势:异步顺序执行没有利用异步的核心优势——并发
实际运行和测试
将上述代码保存为 async_test.py,运行后会看到类似输出:
============================================================
🧪 LangGraph 异步 vs 同步性能测试
============================================================
📝 测试场景:处理 5 个 LLM 请求🔄 同步顺序执行测试...处理消息 1/5...处理消息 2/5...处理消息 3/5...处理消息 4/5...处理消息 5/5...
✅ 同步执行完成,总耗时: 148.37 秒⏳ 异步顺序执行测试...处理消息 1/5...处理消息 2/5...处理消息 3/5...处理消息 4/5...处理消息 5/5...
✅ 异步顺序执行完成,总耗时: 147.72 秒🚀 异步并发执行测试...启动任务 1/5...启动任务 2/5...启动任务 3/5...启动任务 4/5...启动任务 5/5...🔥 所有任务并发运行中...
✅ 异步执行完成,总耗时: 67.24 秒============================================================
📊 性能对比分析
============================================================
同步顺序执行: 148.37 秒
异步顺序执行: 147.72 秒
异步并发执行: 67.24 秒🎯 性能提升:
异步并发 vs 同步顺序: 2.2x 倍速提升
异步并发 vs 异步顺序: 2.2x 倍速提升💡 关键发现:
• 异步并发执行可以显著减少总耗时
• 当有多个独立的 LLM 调用时,并发执行效果最明显
• 异步顺序执行与同步执行时间相近(都是逐个等待)
• 实际加速比取决于网络延迟和 LLM 响应时间
实际应用指导
何时使用异步?
适合使用异步的场景:
- 多个独立的网络请求(如批量API调用)
- 并发的数据库查询
- 同时处理多个用户请求
- I/O密集型任务
不适合使用异步的场景:
- CPU密集型计算
- 必须顺序执行的依赖任务
- 简单的单次操作
最佳实践
# 错误用法:异步但无性能提升
async def bad_example():result1 = await api_call_1()result2 = await api_call_2() # 依赖result1result3 = await api_call_3() # 依赖result2return [result1, result2, result3]# 改进:部分并发
async def better_example():# 可以并发的部分task1 = api_call_1()task2 = independent_api_call()result1, result2 = await asyncio.gather(task1, task2)# 依赖前面结果的部分result3 = await api_call_3(result1)return [result1, result2, result3]# 最佳:完全并发(当任务独立时)
async def best_example():tasks = [api_call_1(),api_call_2(),api_call_3(),api_call_4(),api_call_5()]results = await asyncio.gather(*tasks)return results
总结
- async的真正价值:不在于让单个任务变快,而在于让多个任务可以同时进行
- 异步顺序执行时间相近:因为还是逐个等待,没有发挥并发优势
- 性能提升的关键:使用
asyncio.gather()或类似机制实现真正的并发 - 实际应用:在设计异步程序时,要识别哪些任务可以并发执行
异步编程是一个强大的工具,但只有正确使用才能发挥其真正的威力。记住:异步的魅力不在于等待得更快,而在于可以同时等待多件事情。
延伸思考:在你的项目中,有哪些场景可以从顺序执行改为并发执行?试着识别那些相互独立的异步操作,这通常是性能优化的黄金机会。


)




)







)



)