目录
一、NeRAF
1、概述
2、方法
3、训练过程
4、实验
二、ImVid
1、概述
2、Imvid数据集
3、STG++方法
一、NeRAF
1、概述
NeRF类方法仅支持视觉合成功能,缺乏声学建模能力。对于以往的声学建模(如NAR/INRAS)会忽略三维场景几何对声波传播的本质影响。
NeRAF可以在现有图像和音频数据中学习辐射场和声学场信息,并且能够在未知区域合成视听信息,无需依赖同位置的视听传感器进行训练。
2、方法
NeRAF模型包含三个部分NeRF神经辐射场,网格采样器,神经声学场(NAcF)。
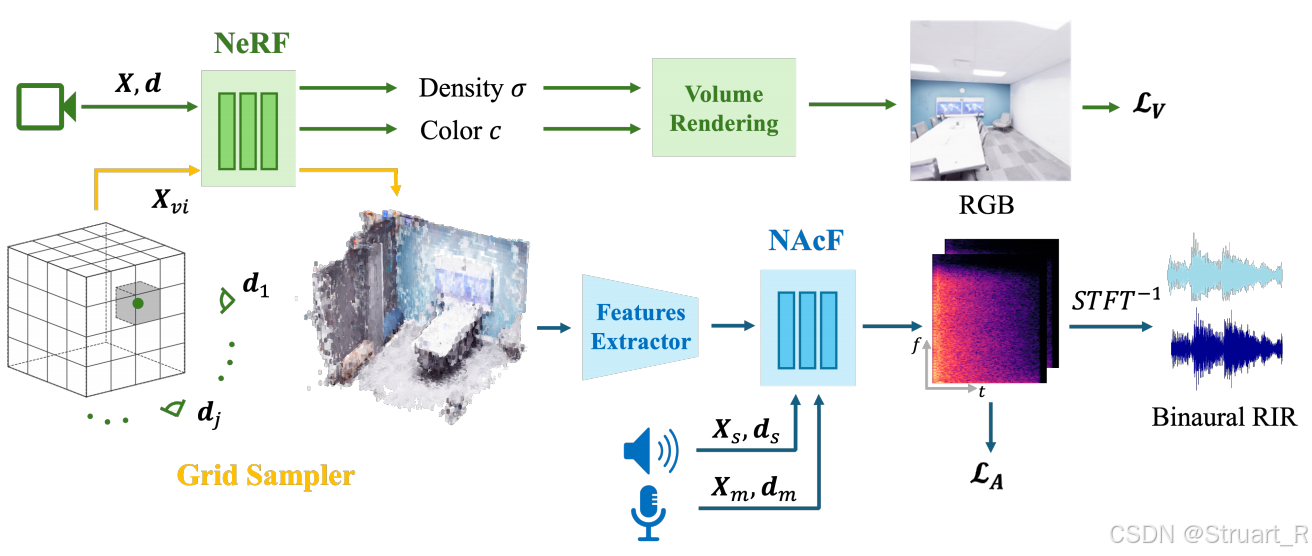
神经辐射场首先依赖于Nerfacto进行搭建,该框架整合了哈希编码,场景收缩,相机位姿优化等技术,并且NeRAF模型也不对NeRF进行改进。NeRF通过给定xyz坐标和位姿->输出密度和颜色信息。
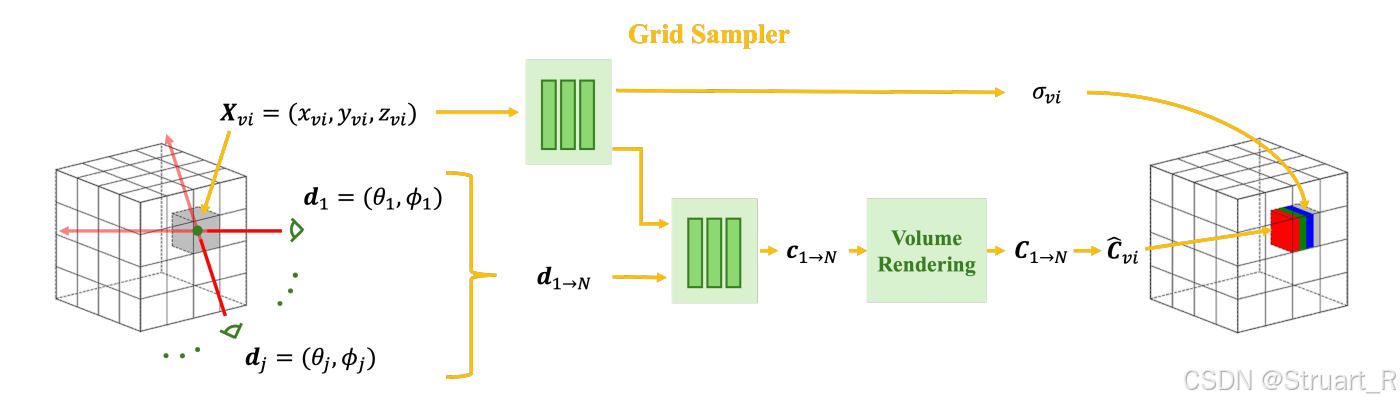
网格采样器,目的是将NeRF模型切换到一个可以提取特征的网格特征结构。对整个3D场景构建一个128x128x128的体素网格空间,并对每一个体素中心点查询NeRF,不透明度为
,并且对每一个坐标投射18个视角,并对每一个视角渲染一个颜色信息,计算均值
,这样就成功的将NeRF模型转换成了一个显式的体素网格结构,输出7通道体素
。
神经声学场部分:
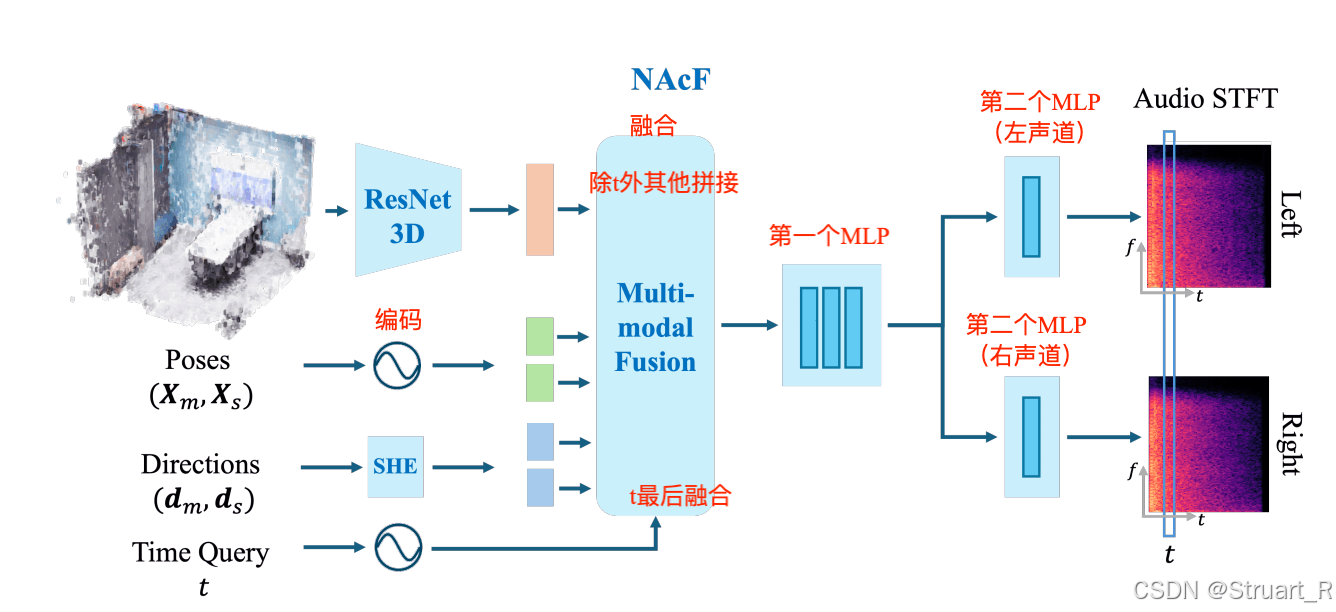
RIR:房间脉冲响应,描述声波从声源到麦克风的传播特性,比如正常一个声音从声源传到听者,他需要经过早期反射和晚期混响两个阶段,早期反射反应声源周围的表面到声源的距离信息,晚期混响则是多次散射形成的能量衰减,受场景规模,材质等影响。
神经声学场(NAcF)旨在学习场景中的声学特性的连续神经表征,也就是计算任意位置上的RIR合成,最后输出到双耳声道。输入任意位置的麦克风坐标以及方向角
,以及声源位置的坐标
和声源方向角
,时间查询t。上述这些信息均用作编码。
NAcF函数表示:,这个RIR实际上就是STFT的时频表示,可以理解为利用上述五个信息,得到一个某一个位置的房间脉冲响应,这个响应用STFT来表示。
ResNet3D作为三维场景特征提取器,输入一个体素网格,输出1024或2048维的特征向量,他的目的是学习体素网格中的几何特征和材质特征。
Multi-modal Fusion包含两个MLP,第一个用来输入所有融合向量,输出一个512维的声学latent vector,用于学习声波在场景中的传播物理规律,第二个MLP分为左右两个声道独立MLP,最终输出STFT频域系数。
MLP Block1:5层全连接,LeakyReLU作激活函数
MLP Block2:学习非对称HRTF,证明空间定位能力,两耳存在一定的声压差,Tanh作为激活函数。
还原RIR波形,通过Griffin-Lim算法来实现还原(参考NAcF)
3、训练过程
损失函数
NeRF损失包括重建MSE误差和互补损失(相机位姿修正损失和多分辨率哈希损失),不修改原损失。
声学损失计算光谱对数损失L_SL和光谱收敛损失L_SC

训练策略
先训练NeRF,并且分批更新体素网格。
之后联合训练NAcF和NeRF。
数据集
SoundSpaces:仿真数据由Habitat Sim构建,包含6个室内场景信息,声学数据提供双耳RIR并且每隔0.5m网格进行空间采样,视觉数据则初始128x128 的RGB-D数据,NeRAF重新渲染了512x512的。
RAF:RAF之前的SoundSpaces和MeshRIR都是合成数据或者稀疏采样,RAF是首个真实世界密集采样视听数据集,每平方米372个样本,只有两个真实房间:空房间和带家具房间。视觉采集来自于VR-NeRF相机环,22个相机多视角共11418张图像,带有深度图。声学采集利用全向麦克风,共86K条,每个4秒钟,48kHz采样,RIR数据。
RWAVS:来自于AV-NeRF论文,首个真实世界视听同步数据集,包括办公室,公寓,房屋,户外(户外那个视频带一段空房间),并且故意保留了一些设备噪声,环境噪声,脚步声这种,覆盖日常全场景声学特性。数据量232分钟,样本数12319个(8:2训练和验证分开)。数据模态构成为相机位姿+视频帧+双耳音频+单声道源音频。
4、实验
性能指标
对于重建仍然用LPIPS,PSNR,SSIM
声学指标上用有T60,C50,EDT,都是计算预测值与真实值之间的误差百分比。STFT error计算频域相似度。你可以理解为前三个是重建环境对音质的影响,最后一个是能重建音色,音调一致。
T60:混响时间,在一个封闭空间内,当声源突然停止发声后,声能衰减60分贝(dB)所需的时间。T60越长,空间回声感越强,听起来越“空旷”;T60越短,声音消失得越快,听起来越“干”或“死寂”。T60的物理属性,受空间大小和界面材质影响,空间越大声音传播路径越长,衰减到同样水平所需时间也就更长。界面材质来说,硬质光滑表面(如混凝土墙、玻璃窗):吸声能力差,大部分声能被反射,导致T60较长。∙软质多孔表面(如地毯、窗帘、沙发、吸音棉):吸声能力强,将声能转化为热能,导致T60较短。
C50:语音清晰度指数,计算声波到达后 前50毫秒 的声能与 50毫秒后 的残余声能的对数比。正值表示语音清晰(早期能量>混响能量),负值表示浑浊(如会议室回音干扰)。家具房间的C50值普遍高于空房间(图7对比),证明物体对混响的抑制作用。
EDT:声源停止后,前10毫秒内 声能衰减曲线的斜率(通常外推至衰减60dB所需时间)。EDT短(如0.5秒)→ 空间感“紧致”;EDT长(如2秒)→ 空间感“开阔”(如教堂)
STFT Error:短时傅里叶变换误差是评估 生成脉冲响应(RIR)与真实RIR在频域相似度 的核心指标,为什么用STFT error,是因为STFT的频带划分(Bark/Mel尺度)匹配人耳非线性感知,单纯计算RIR的相位信息对听觉影响较小,频谱幅度误差更关键。一般没有障碍的地方STFT error较低,边缘,遮挡的地方误差容易升高。
实验分析
对比过去的声光场方法中声音的指标。
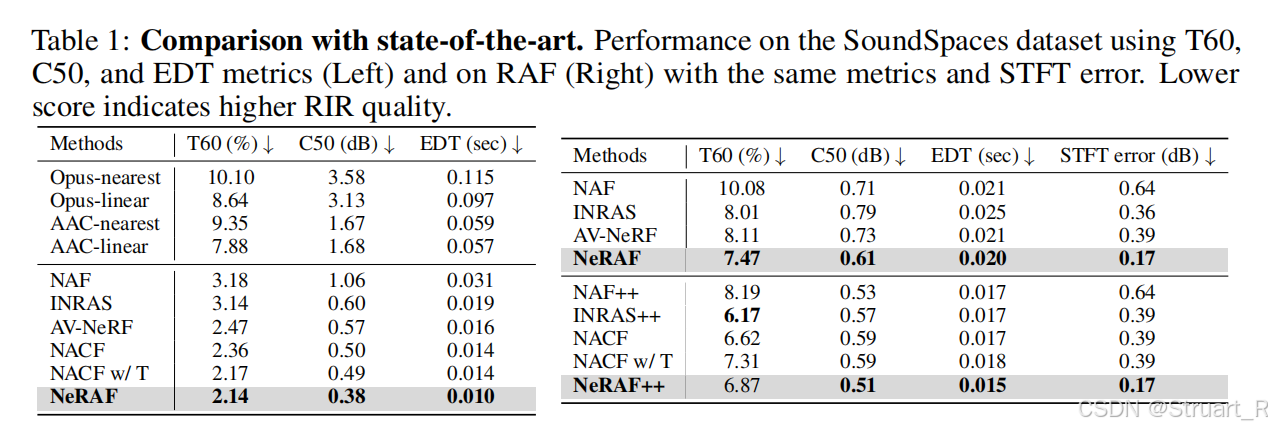
对比NeRF基础模型的重建指标。
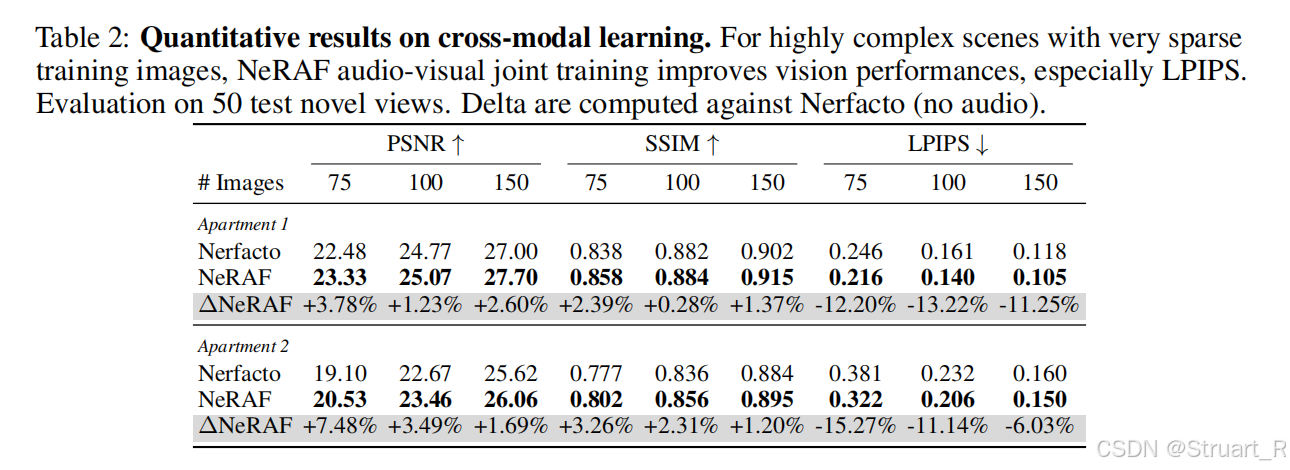
难道audio中也有vision信息?这两者可以互补

二、ImVid
1、概述
动机:一方面受现有数据集稀少影响,当前数据集视角受限,固定相机阵列只能支持静态拍摄,无法覆盖360度背景,当前数据集缺乏同步的音频,比如Diva-360,Replay数据集。当前数据集缺乏动态场景支持,多是单目,低分辨率,时长短的。另一方面工业上Vision Pro的推动,也需要更加全视角覆盖的,兼顾视听多模态的数据集。
ImVid中主要贡献:
(1)首次设计了移动式多模态采集系统
(2)高质量的动态场景视听数据集ImViD
(3)动态光场重建STG++,无需训练的声场重建(不用神经网络)

2、Imvid数据集
移动式多模态采集系统
采集系统:46台GoPro相机安装在可移动小车的半球形支架上,高度模拟人眼视角(1.7m)同时相机和麦克风集成,同步采集5K@60FPS视频+48kHz音频。遥控小车可在场景中缓慢移动(速度受限于地形安全),覆盖最小6m³空间(2分钟内采集1000+图像)。GoPro相机可以实现误差2ms内的同步,并且有降噪功能。
数据集
价值意义:
对比传统方案,缺乏动态场景和移动视角,另外手持设备局限。该数据集是首个支持移动中的多模态采集的数据集。
数据采集:
静态场景高密度采集。小车固定位置,多相机同步拍摄高分辨率静态照片(5568×4176),覆盖360°背景(如实验室设备、窗外景物),为动态重建提供环境先验。
动态场景双模式采集。固定点拍摄模式,不移动小车,捕捉细微动态细节。移动拍摄模式,缓慢移动(每秒0.1立方米),扩展交互空间。
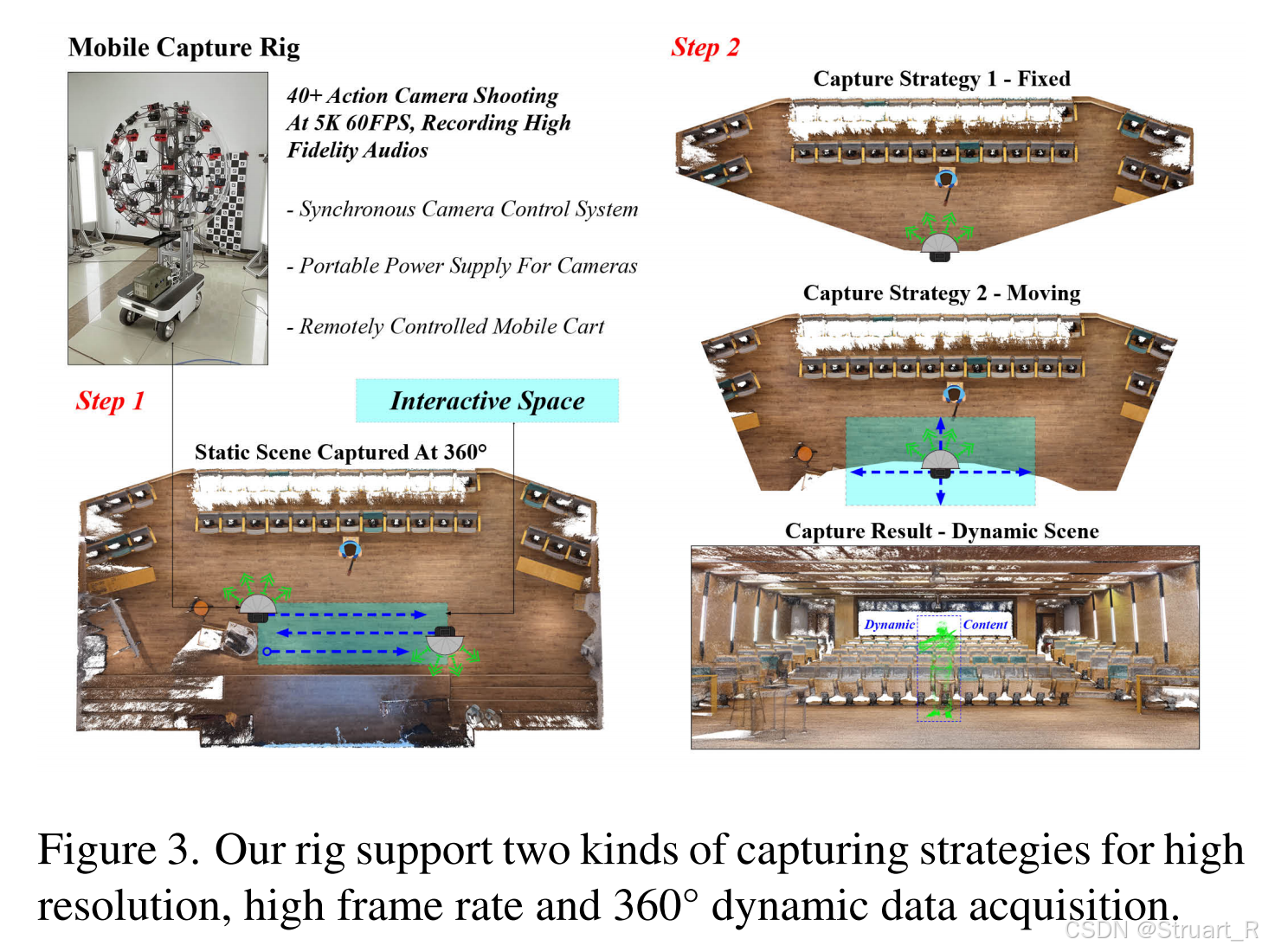
数据处理:
静态问题上基于GoPro内参利用COLMAP进行稀疏重建,另外基于硬件同步声音时间码对齐。
动态数据上,对视频切段,分别进行COLMAP重建,并用PnP拼接,但是没有给出具体做法,近期的方法其实也可以预测了。
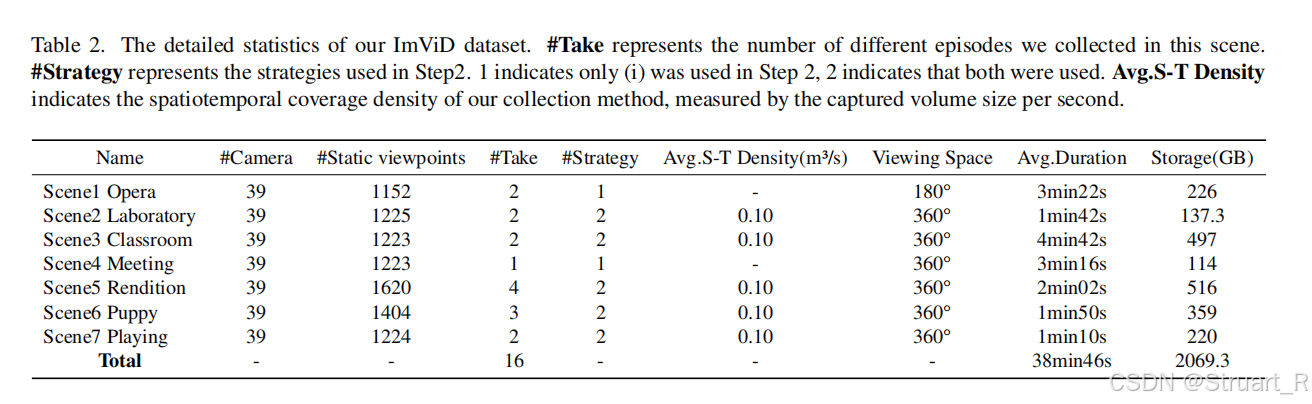
数据集:包含7种场景,39个摄像机,共38分46秒,包含人体动作,物体交互,反射表面,光影变化等问题。
3、STG++方法
首先这个方法对比的是4DGS的方法,不做声光场重建,光场重建依赖从4DGS学来的,声场重建只依赖声源位姿和麦克风位姿,不考虑场景材质信息。
STG++在STG模型基础上,优化了多相机颜色不一致导致视图切换时闪烁和分段训练时跨段连续性差的问题,引入了颜色校正模块和时变密度控制两个策略。
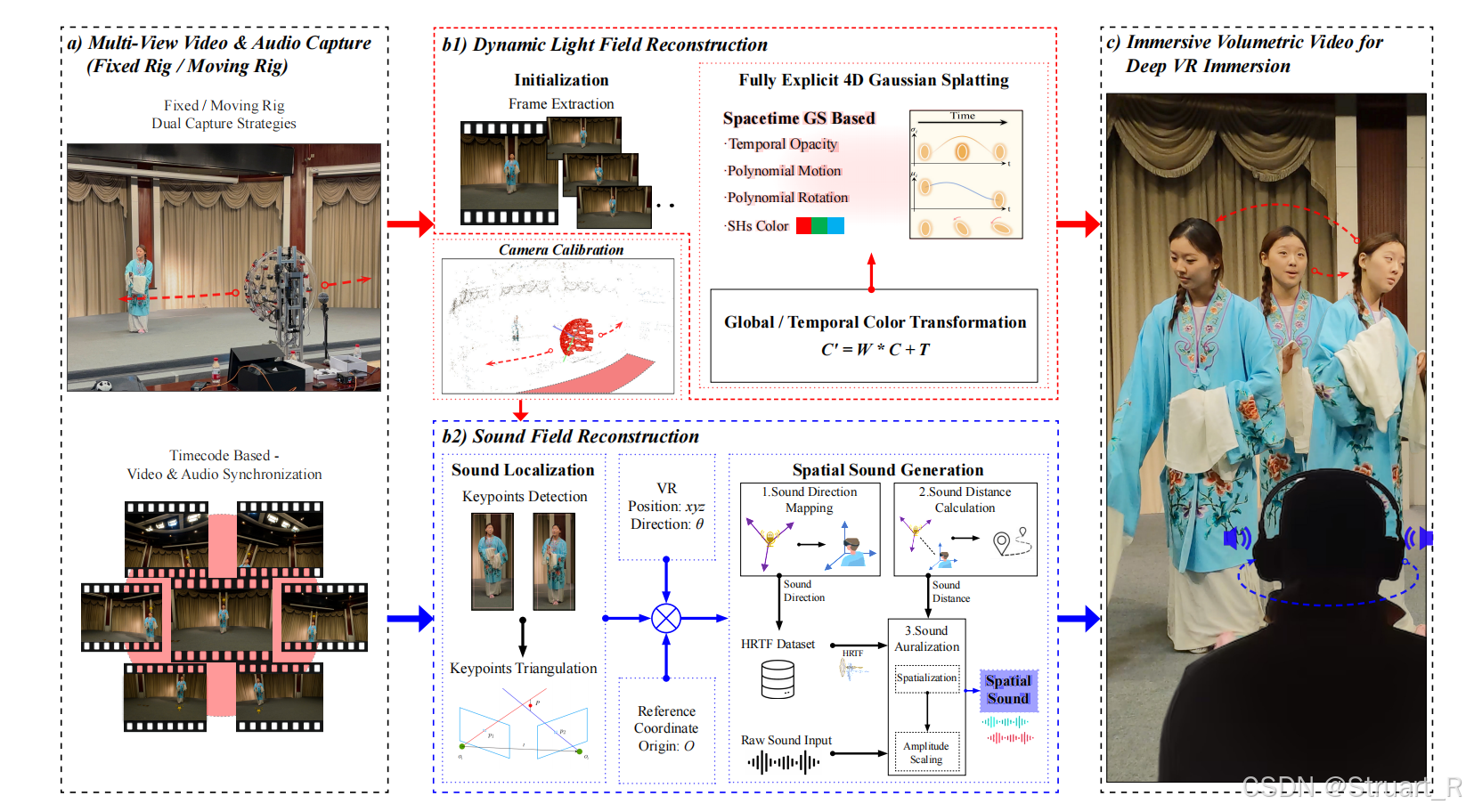
声学重建上,数据机遇39个摄像头携带的多麦克风音频,生成6-DoF的空间音频,对预测位置的声音则完全通过几何计算,加声学优化区分双耳来实现。首先规定:

声源方向计算相对方位角,表示声源相对于听者正前方的偏角(逆时针为正):
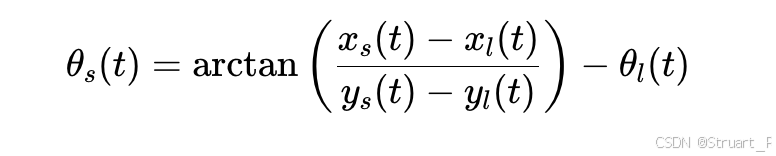
声源距离映射:计算能量衰减系数,进而计算声音能量下降(模拟声音随着距离的平方反比衰减)
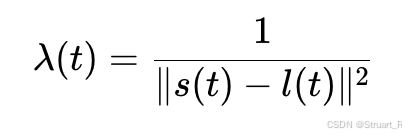
双耳音频合成:根据SADIE II数据集中的传递函数,利用STFT计算左右耳的频域谱
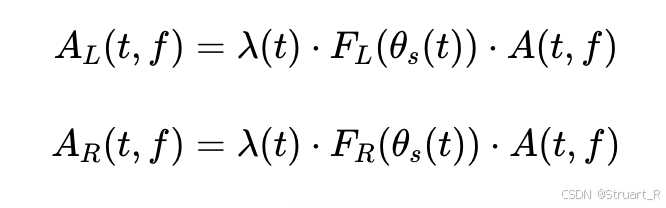
参考论文:
[2405.18213] NeRAF: 3D Scene Infused Neural Radiance and Acoustic Fields
[2503.14359] ImViD: Immersive Volumetric Videos for Enhanced VR Engagement







)








-以太坊共识机制)
计算机网络)

![ZYNQ [Petalinux的运行]](http://pic.xiahunao.cn/ZYNQ [Petalinux的运行])