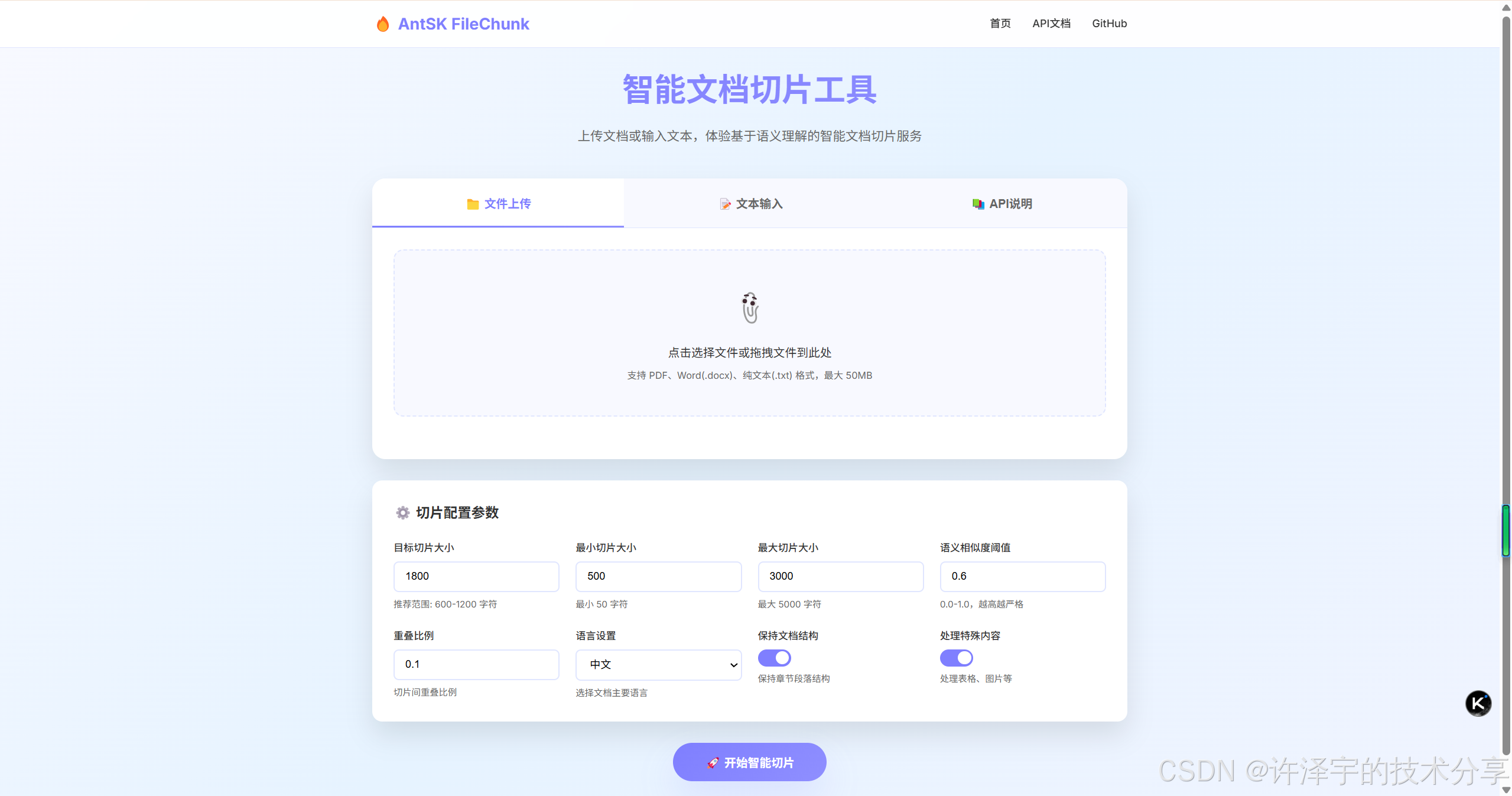
在当今大语言模型(LLM)应用蓬勃发展的时代,我们面临着一个看似简单却至关重要的问题:如何有效地处理长文本?无论是构建知识库、实现RAG(检索增强生成)系统,还是进行文档智能分析,都离不开一个核心环节——文本切片。
传统的文本切片方法大多采用固定长度或基于Token数量的简单切分策略。这些方法虽然实现简单,但却带来了一系列问题:语义割裂、上下文丢失、格式混乱等。想象一下,如果一个重要的概念解释被生硬地切成两半,或者一个表格的数据与其标题被分到不同切片中,这对后续的检索和理解将造成多大的障碍?
今天,我要向大家介绍一个开源项目——AntSK-FileChunk,它通过语义理解的方式,彻底改变了我们处理文本切片的方式。这不仅是一个工具,更是一种思维方式的转变:从机械切分到智能理解。
一、传统文本切片的痛点与挑战
在深入了解AntSK-FileChunk之前,让我们先剖析一下传统文本切片方法存在的主要问题:
1.1 语义割裂:切断了知识的脉络
传统的固定长度切分方法就像一把无情的大刀,不管内容如何,到了指定长度就切一刀。这种方式经常会在句子中间、段落中间,甚至一个完整概念的中间进行切分,导致语义的严重割裂。
举个例子,假设有这样一段文本:
神经网络是一种模拟人脑结构和功能的计算模型。它由大量相互连接的神经元组成,每个神经元接收输入信号,经过处理后产生输出信号。神经网络通过调整神经元之间的连接权重来学习数据中的模式。
如果使用固定长度切分(假设限制为30个字符),可能会变成:
切片1: 神经网络是一种模拟人脑结构和功能
切片2: 的计算模型。它由大量相互连接的
切片3: 神经元组成,每个神经元接收输入
...
显然,这种切分方式破坏了原文的语义完整性,第一个切片甚至没有完成一个完整的定义。
1.2 上下文丢失:孤立的信息碎片
传统切片方法无法保持相关内容的关联性。当我们将文档切分成多个小块后,每个块都成了孤立的信息孤岛,失去了与其他部分的联系。
例如,在一篇论文中,"方法"部分可能引用了"背景"部分的概念,或者"结论"部分需要结合"实验结果"来理解。如果这些相关内容被分到不同的切片中,且没有任何重叠或关联机制,那么每个切片的信息价值都会大打折扣。
1.3 格式处理:结构化内容的噩梦
现实世界的文档往往包含各种复杂的格式元素:表格、图片、公式、代码块等。传统切片方法对这些特殊内容的处理往往力不从心。
想象一下,一个包含10行的表格被切成了两半,或者一个代码示例被分割成多个片段,这不仅会导致信息的不完整,还可能引入错误的理解。
1.4 质量评估:缺乏有效的衡量标准
传统切片方法通常缺乏对切片质量的评估机制。我们很难客观地判断一个切片是否"好"——它是否保持了语义的完整性?是否包含了足够的上下文?是否有效地处理了特殊格式?
没有这些评估标准,我们就无法系统地优化切片策略,只能凭经验进行调整,这显然不是一个可靠的方法。
二、AntSK-FileChunk:语义切片的创新之道
面对传统文本切片的种种挑战,AntSK-FileChunk提出了一套全新的解决方案——基于语义理解的智能文本切片。这不仅是技术上的创新,更是思维方式的转变。
2.1 核心理念:以语义为中心
与传统方法不同,AntSK-FileChunk的核心理念是以语义为中心,而非简单地以字符数或Token数为标准。这意味着:
-
尊重语义边界:切片的边界应该尽可能地与语义边界一致,如段落、句子或完整的概念单元。
-
保持上下文连贯:相关的内容应该尽可能地保持在同一个切片中,或通过重叠机制保持连贯。
-
适应内容特点:切片大小应该根据内容的复杂性和密度动态调整,而非固定不变。
2.2 技术架构:模块化设计
查看AntSK-FileChunk的源码,我们可以看到它采用了清晰的模块化设计,主要包括以下几个核心组件:
SemanticChunker (主控制器)
├── DocumentParser (文档解析器)
├── SemanticAnalyzer (语义分析器)
├── ChunkOptimizer (切片优化器)
└── QualityEvaluator (质量评估器)
这种设计不仅使代码结构清晰,也使得每个组件可以独立优化和扩展。让我们深入了解每个组件的功能:
2.2.1 DocumentParser:智能文档解析
DocumentParser负责将各种格式的文档(PDF、Word、纯文本等)解析为统一的结构化表示。它不仅提取文本内容,还识别文档的结构信息,如标题、段落、表格等。
从源码中可以看到,它针对不同的文档格式采用了不同的处理策略:
def parse_file(self, file_path: Union[str, Path]) -> DocumentContent:file_extension = file_path.suffix.lower()if file_extension == '.pdf':return self._parse_pdf(file_path)elif file_extension in ['.docx', '.doc']:return self._parse_docx(file_path)elif file_extension == '.txt':return self._parse_txt(file_path)
对于PDF文件,它使用PyMuPDF库提取文本、识别表格和图片;对于Word文档,则使用python-docx库进行解析;对于纯文本文件,则进行智能段落分割。
2.2.2 SemanticAnalyzer:深度语义分析
SemanticAnalyzer是整个系统的核心,它负责计算文本的语义向量,并基于这些向量分析文本的语义关系。
它使用预训练的Transformer模型(如SentenceTransformer)将文本转换为高维向量表示:
def compute_embeddings(self, texts: List[str]) -> np.ndarray:processed_texts = [self._preprocess_text(text) for text in texts]embeddings = self.model.encode(processed_texts,show_progress_bar=True,batch_size=32,normalize_embeddings=True # 归一化向量)return embeddings
这些向量捕捉了文本的语义信息,使得系统能够判断不同文本片段之间的语义相似度,从而为切片决策提供依据。
2.2.3 SemanticChunker:智能切片决策
SemanticChunker是整个系统的主控制器,它协调各个组件的工作,并实现核心的切片算法。
从源码中可以看到,它的切片决策不仅考虑了文本长度,更重要的是考虑了语义连贯性:
def _should_start_new_chunk(self, current_indices, current_length, new_para_length, embeddings, new_para_index) -> bool:# 硬性长度限制potential_length = current_length + new_para_lengthif potential_length > self.config.max_chunk_size: # 默认1500字符return True# 语义连贯性检查semantic_coherence = self._calculate_semantic_coherence(current_indices, new_para_index, embeddings)if semantic_coherence < self.config.semantic_threshold: # 默认0.7if current_length >= self.config.target_chunk_size: # 默认800字符return True
这段代码展示了切片决策的两个关键条件:
-
硬性长度限制:确保切片不会过长,超过模型的处理能力。
-
语义连贯性检查:通过计算语义相似度,判断新段落是否与当前切片在语义上连贯。
2.2.4 ChunkOptimizer:切片优化
切片生成后,ChunkOptimizer会对初步切片进行优化,包括合并过小的切片、分割过大的切片、优化切片边界等。
这一步确保了最终的切片不仅在语义上连贯,也在长度上适合后续处理。
2.2.5 QualityEvaluator:质量评估
QualityEvaluator提供了一套多维度的切片质量评估体系,包括:
-
连贯性:切片内部的语义连贯程度
-
完整性:切片是否包含完整的语义单元
-
长度平衡性:切片长度的分布是否均衡
-
语义密度:切片中包含的信息密度
-
边界质量:切片边界是否符合语义边界
这些评估指标不仅可以用来判断切片质量,还可以指导切片策略的优化。
2.3 工作流程:从文档到切片
了解了各个组件的功能后,让我们看看整个系统的工作流程:
-
文档解析:将输入文档解析为结构化的段落列表。
-
预处理:对段落进行清理、过滤和规范化。
-
语义向量计算:为每个段落计算语义向量。
-
智能切片:基于语义相似度和长度限制,将段落组织成切片。
-
切片优化:合并过小切片,分割过大切片,优化切片边界。
-
质量评估:对切片质量进行多维度评估,提供优化建议。
这个流程确保了最终的切片既满足技术要求(如长度限制),又保持了语义的完整性和连贯性。
三、深入理解语义切片算法
语义切片的核心在于如何基于语义相似度进行切片决策。让我们深入了解AntSK-FileChunk的语义切片算法。
3.1 语义向量计算
语义切片的第一步是计算文本的语义向量。AntSK-FileChunk使用预训练的Transformer模型将文本转换为高维向量:
def compute_embeddings(self, texts: List[str]) -> np.ndarray:# 预处理文本processed_texts = [self._preprocess_text(text) for text in texts]# 计算嵌入向量embeddings = self.model.encode(processed_texts,show_progress_bar=True,batch_size=32,normalize_embeddings=True # 归一化向量)return embeddings
这些向量捕捉了文本的语义信息,使得我们可以通过计算向量之间的相似度来判断文本之间的语义关系。
3.2 语义相似度计算
有了语义向量后,我们可以通过余弦相似度计算文本之间的语义相似度:
def _calculate_semantic_coherence(self, current_indices, new_index, embeddings) -> float:# 提取新段落的语义向量new_embedding = embeddings[new_index:new_index+1]# 提取当前切片中所有段落的语义向量current_embeddings = embeddings[current_indices]# 计算新段落与当前切片中所有段落的相似度similarities = cosine_similarity(new_embedding, current_embeddings)[0]# 返回平均相似度作为连贯性得分return np.mean(similarities)
这个函数计算了新段落与当前切片中所有段落的平均相似度,作为语义连贯性的度量。
3.3 切片边界决策
基于语义相似度和长度限制,AntSK-FileChunk实现了智能的切片边界决策:
def _should_start_new_chunk(self, current_indices, current_length, new_para_length, embeddings, new_para_index) -> bool:# 硬性长度限制potential_length = current_length + new_para_lengthif potential_length > self.config.max_chunk_size: # 默认1500字符return True# 语义连贯性检查semantic_coherence = self._calculate_semantic_coherence(current_indices, new_para_index, embeddings)if semantic_coherence < self.config.semantic_threshold: # 默认0.7if current_length >= self.config.target_chunk_size: # 默认800字符return Truereturn False
这个函数决定了是否应该开始一个新的切片,它考虑了两个关键因素:
-
长度限制:如果添加新段落后切片长度超过最大限制,则开始新切片。
-
语义连贯性:如果新段落与当前切片的语义连贯性低于阈值,且当前切片已达到目标长度,则开始新切片。
这种决策机制确保了切片既不会过长,也保持了语义的连贯性。
3.4 重叠处理机制
为了进一步增强切片之间的连续性,AntSK-FileChunk实现了重叠处理机制:
def _calculate_overlap(self, indices: List[int], content: List[str]) -> Tuple[List[int], List[str]]:# 计算重叠段落数量overlap_count = max(1, int(len(indices) * self.config.overlap_ratio))# 取当前切片的最后几个段落作为重叠内容overlap_indices = indices[-overlap_count:]overlap_content = content[-overlap_count:]return overlap_indices, overlap_content
这个函数计算了当前切片与下一个切片之间应该重叠的段落,确保了切片之间的平滑过渡。
四、实际应用案例分析
理论讲解之后,让我们通过几个实际案例来看看AntSK-FileChunk的语义切片效果。
4.1 学术论文处理
学术论文通常包含复杂的结构和专业术语,是传统切片方法的难点。
假设我们有一篇AI领域的学术论文,其中包含了大量的专业术语、公式和引用。使用传统的固定长度切分方法,可能会导致一个公式被切分成两半,或者一个概念的定义与其解释被分到不同的切片中。
而使用AntSK-FileChunk的语义切片,系统会:
-
识别论文的结构(标题、摘要、章节等)
-
理解专业术语之间的语义关联
-
保持公式和引用的完整性
-
确保每个切片都包含足够的上下文
最终,切片结果会更加符合人类的阅读理解习惯,便于后续的检索和分析。
4.2 法律文档处理
法律文档是另一类具有挑战性的文本,它们通常包含复杂的条款、引用和专业术语。
使用AntSK-FileChunk处理法律文档,系统会:
-
识别法律条款的边界
-
保持相关条款之间的关联
-
确保引用和定义的完整性
-
适当处理列表和表格等特殊格式
这样处理后的切片不仅保持了法律文档的严谨性,也便于后续的法律分析和检索。
4.3 技术文档处理
技术文档通常包含代码示例、API说明、表格等特殊内容,这些都是传统切片方法的难点。
使用AntSK-FileChunk处理技术文档,系统会:
-
识别代码块的边界,确保代码示例的完整性
-
保持API说明与其参数说明的关联
-
完整处理表格和列表
-
识别技术术语之间的关联
这样处理后的切片更加适合技术文档的特点,便于开发者查询和理解。
五、性能与优化
语义切片虽然在质量上有明显优势,但也面临着性能挑战。AntSK-FileChunk通过多种优化策略解决了这些问题。
5.1 缓存机制
语义向量的计算是整个过程中最耗时的部分。为了避免重复计算,AntSK-FileChunk实现了缓存机制:
def compute_embeddings(self, texts: List[str]) -> np.ndarray:# 使用缓存避免重复计算cached_embeddings = []texts_to_compute = []indices_map = []for i, text in enumerate(texts):text_hash = hashlib.md5(text.encode()).hexdigest()if text_hash in self.embedding_cache:cached_embeddings.append(self.embedding_cache[text_hash])indices_map.append((i, len(cached_embeddings) - 1, True))else:texts_to_compute.append(text)indices_map.append((i, len(texts_to_compute) - 1, False))# 只计算未缓存的文本if texts_to_compute:new_embeddings = self.model.encode(texts_to_compute, ...)# 更新缓存for i, text in enumerate(texts_to_compute):text_hash = hashlib.md5(text.encode()).hexdigest()self.embedding_cache[text_hash] = new_embeddings[i]# 组合缓存和新计算的向量all_embeddings = np.zeros((len(texts), self.embedding_dim))for orig_idx, cache_or_new_idx, is_cached in indices_map:if is_cached:all_embeddings[orig_idx] = cached_embeddings[cache_or_new_idx]else:all_embeddings[orig_idx] = new_embeddings[cache_or_new_idx]return all_embeddings
这种缓存机制大大减少了重复计算,提高了系统的整体性能。
5.2 批处理优化
对于大型文档,一次性处理所有段落可能会导致内存问题。AntSK-FileChunk采用了批处理策略:
def compute_embeddings(self, texts: List[str]) -> np.ndarray:# 批量处理,避免内存溢出batch_size = 32embeddings = []for i in range(0, len(texts), batch_size):batch_texts = texts[i:i+batch_size]batch_embeddings = self.model.encode(batch_texts, ...)embeddings.append(batch_embeddings)return np.vstack(embeddings)
这种批处理策略不仅解决了内存问题,还提高了计算效率。
5.3 多线程处理
对于大型文档,AntSK-FileChunk还支持多线程处理,进一步提高了处理速度:
def process_large_document(self, document_content):# 将文档分割成多个部分parts = self._split_document(document_content)# 多线程处理各部分with concurrent.futures.ThreadPoolExecutor() as executor:futures = [executor.submit(self._process_part, part) for part in parts]results = [future.result() for future in futures]# 合并结果return self._merge_results(results)
这种多线程处理策略使得系统能够充分利用多核CPU,显著提高了处理大型文档的速度。
六、未来展望与发展方向
AntSK-FileChunk已经在语义切片领域取得了显著成果,但仍有许多值得探索的方向。
6.1 多模态内容处理
目前的AntSK-FileChunk主要处理文本内容,未来可以扩展到多模态内容处理,包括:
-
图像内容理解:识别图片内容,将相关的图片与文本关联起来。
-
表格语义提取:深入理解表格的结构和内容,提取表格的语义信息。
-
代码语义分析:针对代码块进行专门的语义分析,理解代码的功能和结构。
6.2 领域适应性优化
不同领域的文档有不同的特点和要求,未来可以针对特定领域进行优化:
-
医疗文档:处理医疗术语、病历格式等特殊内容。
-
金融报告:处理财务数据、图表等特殊内容。
-
教育资料:优化对教材、习题等内容的处理。
6.3 交互式切片调整
目前的切片过程是全自动的,未来可以引入交互式调整机制:
-
可视化界面:直观展示切片结果,便于用户理解和调整。
-
反馈学习:根据用户反馈调整切片策略,不断优化切片效果。
-
自定义规则:允许用户定义特定的切片规则,满足特殊需求。
6.4 与大语言模型的深度集成
随着大语言模型的发展,可以将AntSK-FileChunk与大语言模型进行更深度的集成:
-
语义理解增强:利用大语言模型的语义理解能力,提高切片的质量。
-
动态切片策略:根据文档内容和查询需求,动态调整切片策略。
-
多级切片:实现多级切片机制,满足不同粒度的查询需求。
七、总结与思考
AntSK-FileChunk通过语义理解的方式,彻底改变了我们处理文本切片的方式。它不仅解决了传统切片方法的痛点,还为文本处理提供了新的可能性。
7.1 核心价值
-
语义完整性:确保每个切片在语义上的完整性和连贯性。
-
上下文保持:通过重叠机制和语义关联,保持切片之间的上下文连续性。
-
格式智能处理:针对表格、图片等特殊内容进行智能处理。
-
质量评估体系:提供多维度的切片质量评估,指导优化。
7.2 应用前景
语义切片技术在多个领域有广阔的应用前景:
-
知识库构建:为企业知识库提供高质量的文档切片。
-
RAG系统:为检索增强生成系统提供更精准的检索单元。
-
文档智能分析:支持对长文档的智能分析和理解。
-
内容推荐:基于语义相似度,实现更精准的内容推荐。
7.3 开发者建议
对于想要使用或贡献AntSK-FileChunk的开发者,我有以下建议:
-
理解核心概念:深入理解语义切片的核心概念和算法。
-
定制化配置:根据具体需求调整切片配置,如语义阈值、切片大小等。
-
性能优化:针对大型文档,考虑使用缓存和多线程处理。
-
扩展功能:根据特定领域需求,扩展特定的处理功能。
结语:从切片到理解
文本切片看似是一个简单的技术问题,但实际上它反映了我们如何看待和处理信息的方式。从机械切分到语义理解,这不仅是技术的进步,更是思维方式的转变。
AntSK-FileChunk让我们看到了一种可能性:通过深入理解内容的语义,我们可以更好地组织和利用信息。这种方式不仅适用于文本切片,也适用于更广泛的信息处理领域。
在信息爆炸的时代,我们需要的不仅是更多的信息,还有更好的信息组织方式。语义切片技术正是朝着这个方向迈出的重要一步。
互动环节
感谢您阅读本文!我很想听听您的想法和经验:
-
您在文本切片中遇到过哪些挑战?传统方法是如何解决的?
-
您认为语义切片技术还有哪些可以改进的地方?
-
您是否有使用AntSK-FileChunk的经验?效果如何?
欢迎在评论区分享您的见解,也欢迎提出任何问题,我会尽力回答。如果您觉得这篇文章对您有帮助,别忘了点赞和收藏,让更多人看到!
关注我,获取更多AI技术深度解析!
更多AIGC文章








` 数据库查询函数)
![[系统架构设计师]通信系统架构设计理论与实践(十七)](http://pic.xiahunao.cn/[系统架构设计师]通信系统架构设计理论与实践(十七))

)


)
)



