文章目录
- JavaEE进阶文件操作与IO流核心指南
- 前言:为什么需要文件操作?
- 一、`java.io.File` 类的基本用法
- 1.1 文件路径
- 1.2 常用方法示例
- 获取文件信息
- 创建和删除文件
- 目录操作
- 文件重命名和移动
- 二、IO流的基本概念
- 2.1 核心困境:字节流 vs. 字符流
- 字节流 (`InputStream`/`OutputStream`)
- 字符流 (`Reader`/`Writer`)
- 2.2 资源管理
- 三、文件读写示例
- 3.1 读取文件
- 使用字节流
- 使用字符流
- 使用Scanner
- 3.2 写入文件
- 使用字节流
- 使用PrintWriter
- 四、实战练习
- 文件扫描器
- 文件复制工具
- 内容搜索器
- 本文核心要点总结 (Key Takeaways)
- 本文核心要点总结 (Key Takeaways)
JavaEE进阶文件操作与IO流核心指南
前言:为什么需要文件操作?
刚开始学Java的时候,我发现一个问题:程序里的数据都存在内存中,内存虽然快,但程序一关闭,所有数据就消失了。
这就像你写了很重要的笔记,但没保存,电脑一关就全没了,这显然不行。
所以我们需要把数据保存到硬盘上。操作系统提供了**文件(File)和目录(Directory)**来帮我们组织和管理这些数据。
在Java中,java.io.File 类用来管理文件本身,而IO流则用来读写文件内容。这篇文章主要记录我对这两个核心概念的学习过程。
一、java.io.File 类的基本用法
java.io.File 这个类主要用来管理文件的属性信息,比如文件名、路径、大小等。它不负责读写文件内容,只是文件的"信息卡片"。
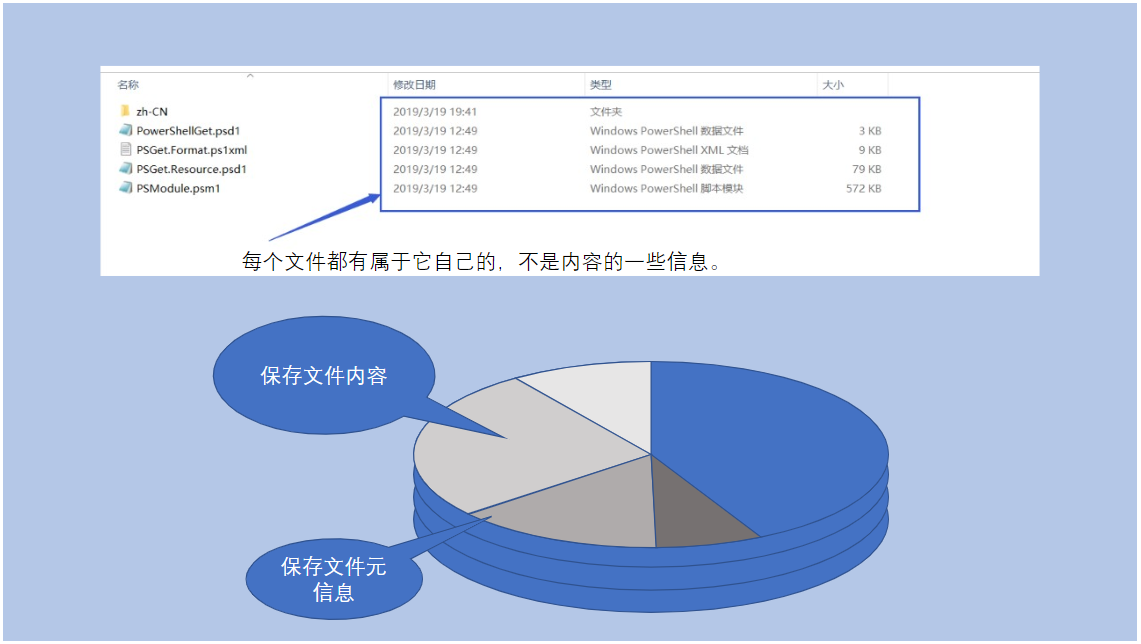
另外要注意,创建 File 对象不代表文件真的存在。你可以先创建对象,后面再决定是否创建实际文件。
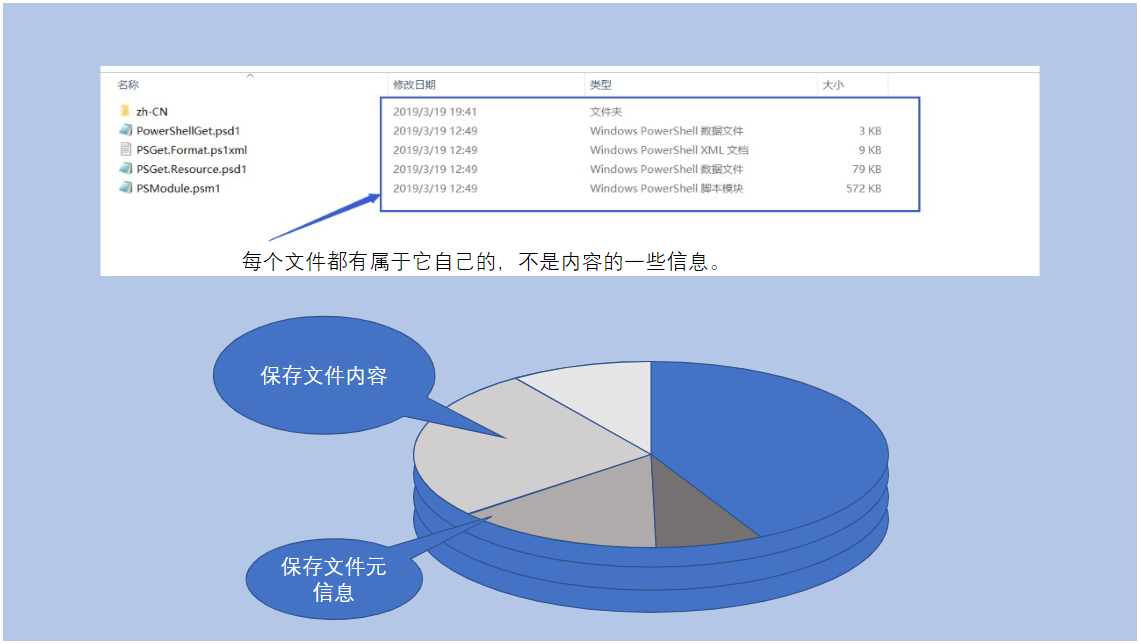
这里我的理解是,File对象更像是一个"文件引用"或"文件指针",它指向文件系统中的某个位置,但不保证那个位置真的有文件存在。这种设计让我们可以先规划好要操作的文件,然后再执行实际的创建操作。
1.1 文件路径

文件路径有两种表示方式:
- 绝对路径:从根目录开始的完整路径,如
D:\JAVA_Learn\test.txt - 相对路径:从当前目录开始的路径,如
./test.txt
使用相对路径时要注意,"当前目录"的位置可能不同:
- 在IDE中运行时,通常是项目根目录
- 在命令行运行JAR文件时,是你执行命令的目录
建议在使用相对路径前,先确认当前工作目录的位置。
1.2 常用方法示例
获取文件信息
import java.io.File;
import java.io.IOException;public class FileInfoExample {public static void main(String[] args) throws IOException {File file = new File("D:/JAVA_Learn/Java_EE_Beginner/MyCodes/File/test.txt");System.out.println("父目录: " + file.getParent());System.out.println("文件名: " + file.getName());System.out.println("文件路径: " + file.getPath());System.out.println("绝对路径: " + file.getAbsolutePath());System.out.println("规范路径: " + file.getCanonicalPath());}
}
创建和删除文件
import java.io.File;
import java.io.IOException;public class FileCreateDeleteExample {public static void main(String[] args) throws IOException {File file = new File("temp-file.txt");System.out.println("文件是否存在: " + file.exists());System.out.println("文件创建成功: " + file.createNewFile());System.out.println("文件是否存在: " + file.exists());System.out.println("文件删除成功: " + file.delete());System.out.println("文件是否存在: " + file.exists());}
}
注意:createNewFile() 在文件已存在时会返回false,不会覆盖原文件。
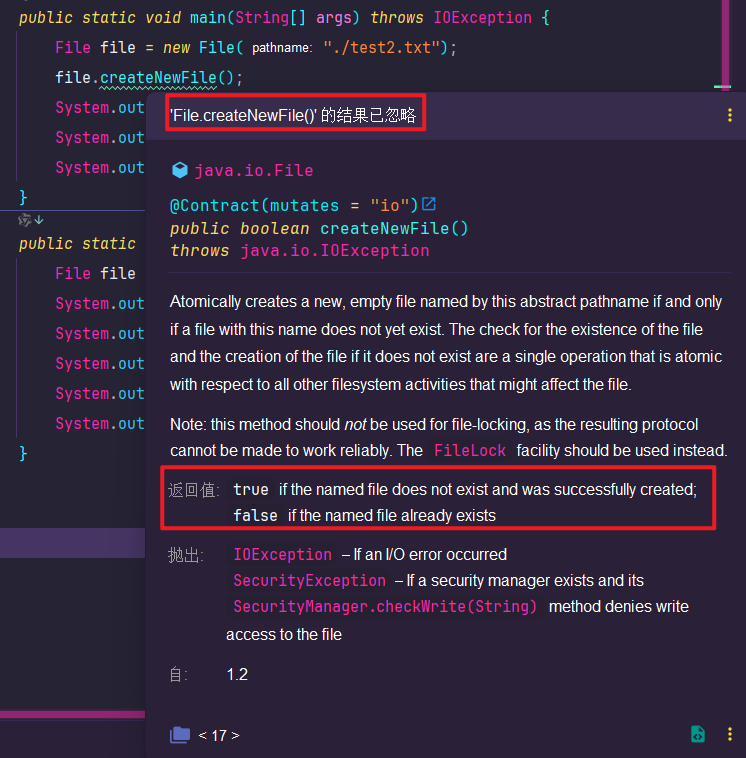
这个方法的设计很合理,避免了意外覆盖重要文件的风险。在实际项目中,我们通常会在调用这个方法前先检查文件是否存在,或者准备好处理文件已存在的情况
目录操作
import java.io.File;
import java.util.Arrays;public class DirectoryExample {public static void main(String[] args) {File dir = new File("some-parent/some-child");if (!dir.exists()) {System.out.println("创建目录成功: " + dir.mkdirs());}File rootDir = new File("./");File[] files = rootDir.listFiles();if (files != null) {System.out.println("当前目录内容: " + Arrays.toString(files));}}
}
mkdirs()和mkdir()的区别很重要:mkdir()只能创建单级目录,如果父目录不存在就会失败;而mkdirs()会创建所有必需的父目录,所以在实际项目中更常用mkdirs()。
文件重命名和移动
renameTo() 方法可以重命名或移动文件:
import java.io.File;
import java.io.IOException;public class FileRenameMoveExample {public static void main(String[] args) throws IOException {File sourceFile = new File("source.txt");sourceFile.createNewFile();// 重命名File destFileRename = new File("renamed.txt");System.out.println("重命名成功: " + sourceFile.renameTo(destFileRename));// 移动文件File destDir = new File("MyCodes/File/");destDir.mkdirs();File destFileMove = new File(destDir, "moved.txt");System.out.println("移动成功: " + destFileRename.renameTo(destFileMove));}
}
在同一磁盘分区内移动文件很快,因为只是修改文件系统的路径记录,不需要复制数据。
这个特性在实际应用中很有用。比如整理文件目录时,我们可以放心地使用
renameTo()来移动文件,不用担心性能问题。但如果要跨磁盘移动,那就需要真正的复制和删除操作了。
二、IO流的基本概念
IO流用来读写文件内容。可以把IO流理解为程序和文件之间的数据通道。
2.1 核心困境:字节流 vs. 字符流
这是Java IO中最重要的一个概念,理解了它,就抓住了IO学习的关键。
字节流 (InputStream/OutputStream)
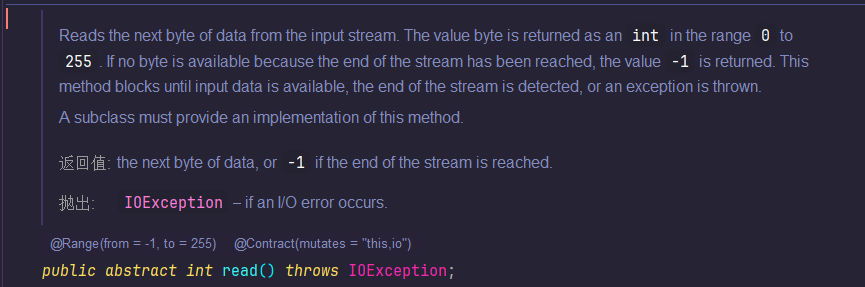
这是
InputStream抽象类中read()方法的源码,它定义了Java I/O操作的核心读取规范:每次读取一个字节,返回0-255之间的整数值,当到达文件末尾时返回-1。所有具体的输入流实现都遵循这个规范。
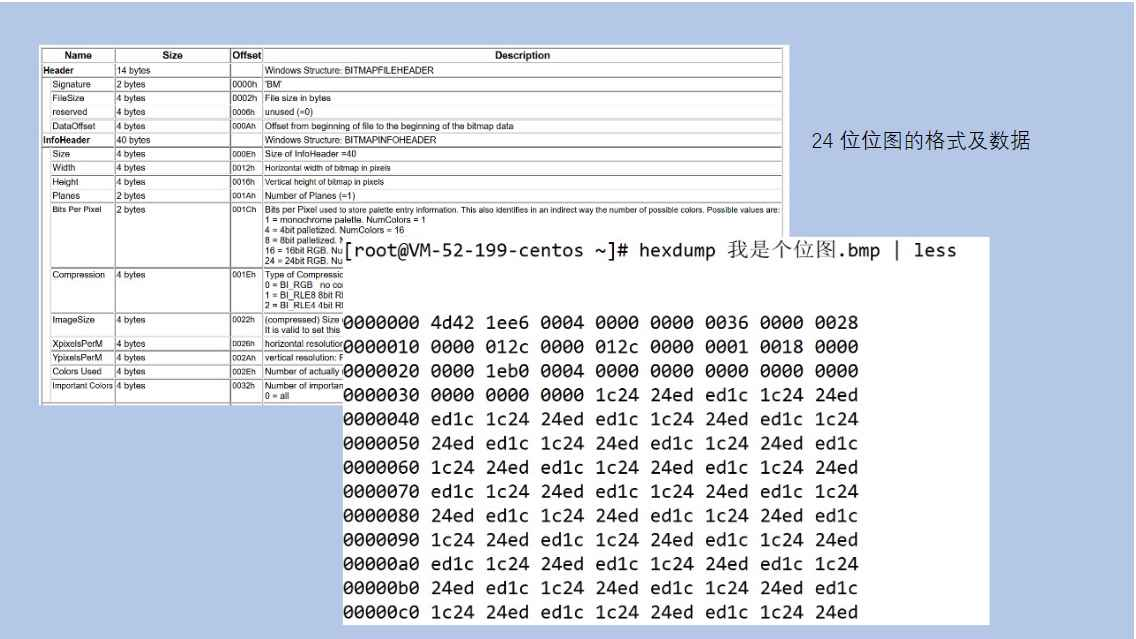
我们可以把字节流想象成一个勤勤恳恳的"字节搬运工"。
- 优点:它非常通用,是处理一切数据的"万金油"。无论是图片、视频、音频还是文本文件,在它眼里都是一堆二进制字节,它都能原封不动地进行搬运。
- 缺点:正因为它只认识字节,当它处理文本文件时,就会暴露一个核心痛点——它不理解字符编码。
我们知道,一个英文字母可能只占1个字节,而一个汉字在UTF-8编码下通常占3个字节。如果让字节流去读一个包含"你好"的文本文件,它只会机械地一次读一个字节,而不知道哪3个字节合在一起才是一个完整的"你"字。这个"翻译"的脏活累活,字节流就甩给了我们程序员自己来做,非常麻烦且容易出错。
字符流 (Reader/Writer)
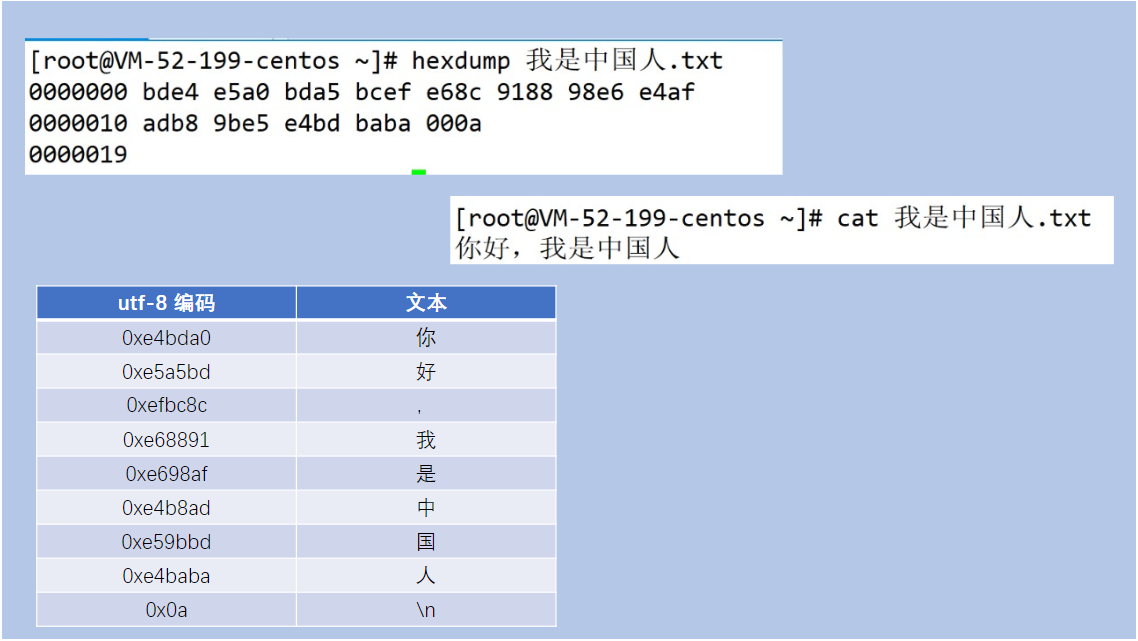
为了解决这个问题,Java提供了字符流,我们可以把它想象成一位"智能翻译官"。
- 优点:它是专门为处理文本数据而生的"专家"。在创建字符流时,我们可以指定正确的字符集(如UTF-8)。之后,当我们从文件读取数据时,字符流会在底层自动帮我们读取字节,并根据指定的编码规则进行"解码",最后直接返回给我们一个个有意义的"字符"。
- 核心作用:字符流自动完成了字节到字符的解码过程,让我们从繁琐的编码处理中解脱出来。
结论:处理纯二进制文件(如图片、音频)时,必须使用字节流。但凡是处理文本文件,都应该优先使用字符流。
2.2 资源管理
使用IO流时必须记得关闭资源,否则会造成资源泄露。
传统写法:
InputStream is = null;
try {is = new FileInputStream("test.txt");// 读写操作
} finally {if (is != null) {is.close();}
}
推荐写法(Java 7+):
try (InputStream is = new FileInputStream("test.txt")) {// 读写操作
}
// 自动关闭资源
try-with-resources 语法更简洁安全,所有IO流类都支持。
try-with-resources应该是Java 7重要的的改进之一。如果在之前的版本写IO代码,经常要在finally块里处理多个资源的关闭,还要处理null检查和异常,代码很容易出错。现在有了这个语法,不仅代码简洁了,而且更安全,再也不用担心忘记关闭资源了。
三、文件读写示例
3.1 读取文件
使用字节流
import java.io.FileInputStream;
import java.io.InputStream;
import java.io.IOException;public class ReadByteExample {public static void main(String[] args) throws IOException {try (InputStream is = new FileInputStream("MyCodes/File/test.txt")) {byte[] buffer = new byte[1024];int bytesRead;while ((bytesRead = is.read(buffer)) != -1) {String data = new String(buffer, 0, bytesRead);System.out.print(data);}}}
}
这里有个潜在的问题:如果文件很大,一次性读取整个文件可能会占用太多内存。更好的做法是逐块处理,比如每次读取1KB或4KB的数据,处理完再读取下一块。
使用字符流
import java.io.FileReader;
import java.io.Reader;
import java.io.IOException;public class ReadCharExample {public static void main(String[] args) throws IOException {try (Reader reader = new FileReader("MyCodes/File/test.txt")) {char[] buffer = new char[1024];int charsRead;while ((charsRead = reader.read(buffer)) != -1) {String data = new String(buffer, 0, charsRead);System.out.print(data);}}}
}
FileReader有个限制:它总是使用系统的默认编码。如果文件编码与系统编码不一致,就可能出现乱码。更安全的做法是使用InputStreamReader并明确指定编码:try (Reader reader = new InputStreamReader(new FileInputStream("file.txt"), StandardCharsets.UTF_8)) {// ... }
使用Scanner
import java.io.FileInputStream;
import java.io.InputStream;
import java.io.IOException;
import java.util.Scanner;public class ReadWithScannerExample {public static void main(String[] args) throws IOException {try (InputStream is = new FileInputStream("MyCodes/File/test.txt")) {try (Scanner scanner = new Scanner(is, "UTF-8")) {while (scanner.hasNextLine()) {String line = scanner.nextLine();System.out.println(line);}}}}
}
Scanner虽然方便,但处理大文件时可能会有性能问题,因为它会做很多额外的解析工作。如果只是简单地按行读取,使用
BufferedReader可能更高效。
3.2 写入文件
使用字节流
import java.io.FileOutputStream;
import java.io.OutputStream;
import java.io.IOException;
import java.nio.charset.StandardCharsets;public class WriteByteExample {public static void main(String[] args) throws IOException {try (OutputStream os = new FileOutputStream("MyCodes/File/output.txt", true)) {String text = "你好,世界\n";byte[] buffer = text.getBytes(StandardCharsets.UTF_8);os.write(buffer);os.flush();}}
}
FileOutputStream的第二个参数true表示追加模式,这点很重要。默认情况下是覆盖模式,如果不小心用了覆盖模式,可能会意外删除文件中原有的内容。
使用PrintWriter
import java.io.FileOutputStream;
import java.io.OutputStream;
import java.io.OutputStreamWriter;
import java.io.PrintWriter;
import java.io.IOException;
import java.nio.charset.StandardCharsets;public class WriteWithPrintWriterExample {public static void main(String[] args) throws IOException {try (OutputStream os = new FileOutputStream("MyCodes/File/output.txt", true);OutputStreamWriter osWriter = new OutputStreamWriter(os, StandardCharsets.UTF_8);PrintWriter writer = new PrintWriter(osWriter)) {writer.println("这是用 PrintWriter 写入的第一行。");writer.print("这是第二行,没有换行。");writer.printf("可以用格式化输出,比如数字:%d\n", 123);writer.flush();}}
}
PrintWriter的自动刷新功能很有用。创建PrintWriter时可以传入第二个参数
true,这样每次调用println()、printf()或format()方法时都会自动刷新缓冲区:PrintWriter writer = new PrintWriter(osWriter, true); // 启用自动刷新
四、实战练习
文件扫描器
扫描目录,查找包含特定关键字的文件:
import java.io.File;
import java.util.ArrayList;
import java.util.List;
import java.util.Scanner;public class FileScanner {public static void main(String[] args) {Scanner scanner = new Scanner(System.in);System.out.print("请输入要扫描的根目录: ");String rootPath = scanner.nextLine();File rootDir = new File(rootPath);if (!rootDir.isDirectory()) {System.out.println("错误:输入的路径不是有效目录。");return;}System.out.print("请输入文件名关键字: ");String keyword = scanner.nextLine();List<File> results = new ArrayList<>();scanDirectory(rootDir, keyword, results);System.out.println("\n扫描完成!找到 " + results.size() + " 个匹配文件:");for (File file : results) {System.out.println(file.getAbsolutePath());}}private static void scanDirectory(File dir, String keyword, List<File> resultList) {File[] files = dir.listFiles();if (files == null) {return;}for (File file : files) {if (file.isDirectory()) {scanDirectory(file, keyword, resultList);} else {if (file.getName().contains(keyword)) {resultList.add(file);}}}}
}
这个程序使用了深度优先搜索(DFS)来遍历目录树。对于大型文件系统,递归可能会导致栈溢出。在实际应用中,可以考虑使用迭代方式(用栈来实现DFS)或者使用Java 7引入的
Files.walk()方法。
文件复制工具
import java.io.*;
import java.util.Scanner;public class FileCopier {public static void main(String[] args) throws IOException {Scanner scanner = new Scanner(System.in);System.out.print("请输入源文件路径: ");String sourcePath = scanner.nextLine();File sourceFile = new File(sourcePath);if (!sourceFile.isFile()) {System.out.println("错误:源文件不存在或不是普通文件。");return;}System.out.print("请输入目标文件路径: ");String destPath = scanner.nextLine();File destFile = new File(destPath);if (destFile.exists() && destFile.isDirectory()) {System.out.println("错误:目标路径是已存在的目录。");return;}if (destFile.exists()) {System.out.print("目标文件已存在,是否覆盖? (y/n): ");String choice = scanner.nextLine();if (!choice.equalsIgnoreCase("y")) {System.out.println("操作取消。");return;}}try (InputStream is = new FileInputStream(sourceFile);OutputStream os = new FileOutputStream(destFile)) {byte[] buffer = new byte[4096];int bytesRead;while ((bytesRead = is.read(buffer)) != -1) {os.write(buffer, 0, bytesRead);}os.flush();}System.out.println("文件复制成功!");}
}
4KB的缓冲区大小是一个经验值,在实际应用中可以根据具体情况调整。对于机械硬盘,较大的缓冲区(如8KB或16KB)可能性能更好;对于SSD,由于随机访问性能很好,缓冲区大小的影响可能不那么明显。
内容搜索器
import java.io.*;
import java.util.ArrayList;
import java.util.List;
import java.util.Scanner;public class ContentSearcher {public static void main(String[] args) throws IOException {Scanner scanner = new Scanner(System.in);System.out.print("请输入要扫描的根目录: ");String rootPath = scanner.nextLine();File rootDir = new File(rootPath);if (!rootDir.isDirectory()) {System.out.println("错误:无效的目录。");return;}System.out.print("请输入要搜索的内容关键字: ");String keyword = scanner.nextLine();List<File> results = new ArrayList<>();searchInDirectory(rootDir, keyword, results);System.out.println("\n搜索完成!找到 " + results.size() + " 个包含关键字的文件:");for (File file : results) {System.out.println(file.getAbsolutePath());}}private static void searchInDirectory(File dir, String keyword, List<File> resultList) throws IOException {File[] files = dir.listFiles();if (files == null) return;for (File file : files) {if (file.isDirectory()) {searchInDirectory(file, keyword, resultList);} else {if (isContentContains(file, keyword)) {resultList.add(file);}}}}private static boolean isContentContains(File file, String keyword) throws IOException {try (Scanner scanner = new Scanner(file, "UTF-8")) {while (scanner.hasNextLine()) {if (scanner.nextLine().contains(keyword)) {return true;}}} catch (Exception e) {// 忽略读取错误}return false;}
}
这个程序有个限制:它会把整个文件读入内存来搜索关键字。对于大文件(如几百MB或几GB的文件),这可能会导致内存问题。更好的做法是逐块读取文件,或者使用内存映射文件(MappedByteBuffer)技术。
本文核心要点总结 (Key Takeaways)
通过这次文件操作和IO流的学习,我梳理出了几个关键点:
-
File类 vs IO流的分工:File类管理文件属性和路径信息,IO流负责读写文件内容,两者分工明确。 -
字节流与字符流的选择原则:处理图片、视频等二进制数据用字节流;处理文本数据永远优先选择字符流,因为它自动处理字符编码问题。
-
资源管理的最佳实践:始终使用
try-with-resources语法处理IO流,能有效防止资源泄露。 -
缓冲区的重要性:无论读写,使用缓冲区(如
byte[]或char[])都能显著提升性能,减少磁盘IO次数。 -
便捷工具的善用:
Scanner、PrintWriter等包装类能大大简化IO操作,让代码更简洁易读。
通过这些实战项目,我对Java文件操作有了更深的理解。文件操作虽然看起来简单,但在实际项目中处理好编码、异常、资源管理这些细节,才能写出稳定可靠的代码。
好的做法是逐块读取文件,或者使用内存映射文件(MappedByteBuffer)技术。
本文核心要点总结 (Key Takeaways)
通过这次文件操作和IO流的学习,我梳理出了几个关键点:
-
File类 vs IO流的分工:File类管理文件属性和路径信息,IO流负责读写文件内容,两者分工明确。 -
字节流与字符流的选择原则:处理图片、视频等二进制数据用字节流;处理文本数据永远优先选择字符流,因为它自动处理字符编码问题。
-
资源管理的最佳实践:始终使用
try-with-resources语法处理IO流,能有效防止资源泄露。 -
缓冲区的重要性:无论读写,使用缓冲区(如
byte[]或char[])都能显著提升性能,减少磁盘IO次数。 -
便捷工具的善用:
Scanner、PrintWriter等包装类能大大简化IO操作,让代码更简洁易读。
通过这些实战项目,我对Java文件操作有了更深的理解。文件操作虽然看起来简单,但在实际项目中处理好编码、异常、资源管理这些细节,才能写出稳定可靠的代码。







)



:Vue3 表格动态增加删除行解决方案)





(持续更新))

