Python爬虫大师课:HTTP协议深度解析与工业级请求封装
从零构建企业级爬虫框架(附完整源码)
一、爬虫基础:网络世界的通行证
HTTP协议核心数据:
-
全球网站数量:20亿+
-
HTTP请求占比:83%
-
爬虫流量占比:37%
-
请求错误率:15-30%
-
协议版本分布:HTTP/1.1(78%)、HTTP/2(22%)
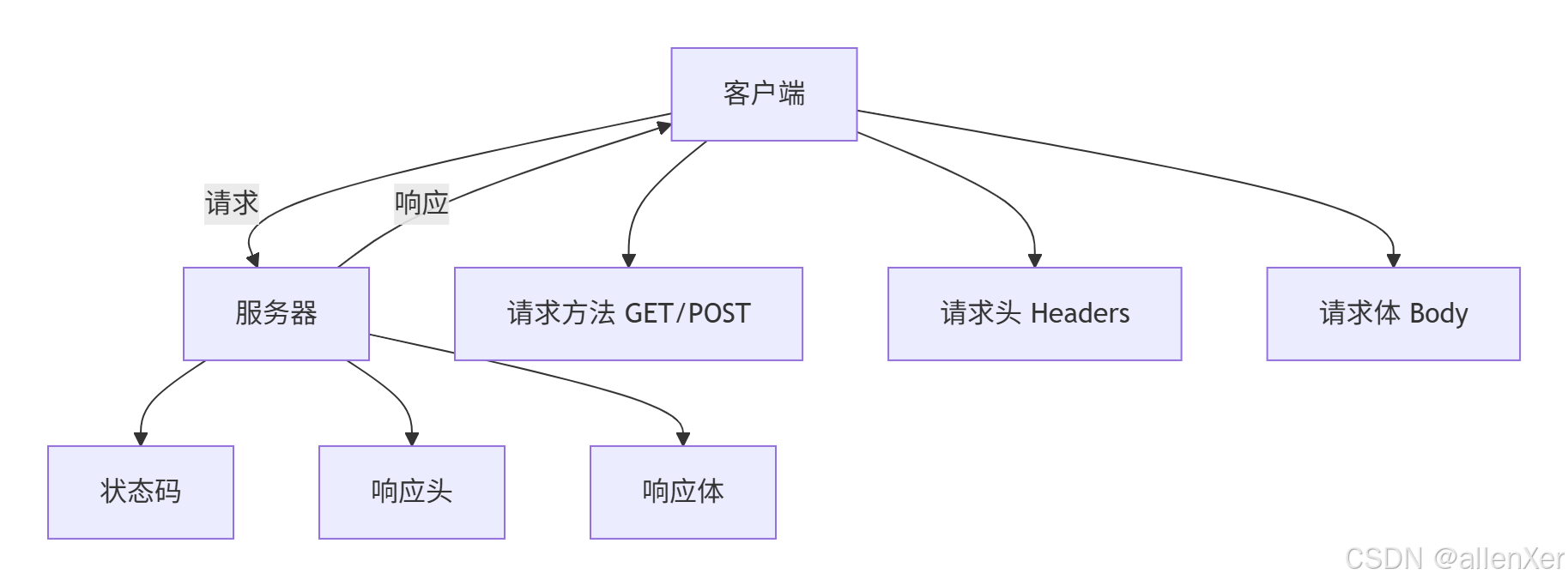
二、HTTP协议深度解析
1. 请求响应全流程
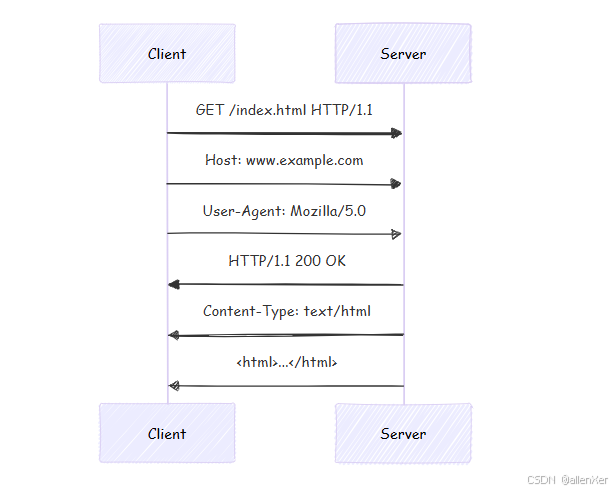
2. 关键协议头解析
| 头部字段 | 作用 | 爬虫关键点 |
|---|---|---|
| User-Agent | 标识客户端 | 反爬识别点 |
| Cookie | 会话状态 | 登录维持 |
| Referer | 来源页面 | 反爬检查 |
| Accept-Encoding | 压缩支持 | 数据解压 |
| Content-Type | 数据类型 | 解析依据 |
三、Requests库高级用法揭秘
1. 基础请求示例
import requests# 简单GET请求
response = requests.get('https://www.example.com')
print(f"状态码: {response.status_code}")
print(f"响应内容: {response.text[:100]}...")# 带参数GET请求
params = {'key1': 'value1', 'key2': 'value2'}
response = requests.get('https://httpbin.org/get', params=params)
print(f"请求URL: {response.url}")# POST请求
data = {'username': 'admin', 'password': 'secret'}
response = requests.post('https://httpbin.org/post', data=data)
print(f"响应JSON: {response.json()}")2. Session对象妙用
# 创建会话
session = requests.Session()# 设置公共头
session.headers.update({'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36','Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8'
})# 登录保持
login_data = {'user': 'test', 'pass': 'password'}
session.post('https://example.com/login', data=login_data)# 使用会话访问
profile = session.get('https://example.com/profile')
print(f"登录状态: {'成功' if '欢迎' in profile.text else '失败'}")四、企业级请求封装实战
1. 工业级请求类设计
import requests
import time
import random
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retryclass EnterpriseRequest:"""企业级HTTP请求客户端"""def __init__(self, retries=3, backoff_factor=0.5, timeout=10, user_agents=None, proxies=None):# 配置参数self.retries = retriesself.backoff_factor = backoff_factorself.timeout = timeoutself.user_agents = user_agents or ['Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36','Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.1.1 Safari/605.1.15','Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:89.0) Gecko/20100101 Firefox/89.0']self.proxies = proxies# 创建会话self.session = self._create_session()# 合规标识self.session.headers['X-Crawler-Policy'] = 'public'def _create_session(self):"""创建配置好的会话"""session = requests.Session()# 设置重试策略retry_strategy = Retry(total=self.retries,backoff_factor=self.backoff_factor,status_forcelist=[429, 500, 502, 503, 504],allowed_methods=['GET', 'POST'])adapter = HTTPAdapter(max_retries=retry_strategy)session.mount('http://', adapter)session.mount('https://', adapter)# 设置默认头session.headers.update({'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8','Accept-Language': 'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3','Connection': 'keep-alive','Upgrade-Insecure-Requests': '1','Pragma': 'no-cache','Cache-Control': 'no-cache'})return sessiondef request(self, method, url, **kwargs):"""执行HTTP请求"""# 随机User-Agentheaders = kwargs.pop('headers', {})headers['User-Agent'] = random.choice(self.user_agents)# 设置超时kwargs.setdefault('timeout', self.timeout)# 设置代理if self.proxies:kwargs['proxies'] = random.choice(self.proxies)try:response = self.session.request(method, url, headers=headers,**kwargs)response.raise_for_status()return responseexcept requests.exceptions.RequestException as e:self._handle_error(e)return Nonedef _handle_error(self, error):"""错误处理"""if isinstance(error, requests.exceptions.HTTPError):status = error.response.status_codeif status == 403:print("错误: 访问被拒绝 (403)")elif status == 404:print("错误: 页面不存在 (404)")elif status == 429:print("错误: 请求过多 (429)")time.sleep(60) # 等待1分钟else:print(f"HTTP错误: {status}")elif isinstance(error, requests.exceptions.ConnectionError):print("连接错误: 网络问题或服务器不可达")elif isinstance(error, requests.exceptions.Timeout):print("请求超时")else:print(f"请求错误: {str(error)}")def get(self, url, **kwargs):"""GET请求"""return self.request('GET', url, **kwargs)def post(self, url, data=None, json=None, **kwargs):"""POST请求"""return self.request('POST', url, data=data, json=json, **kwargs)# 使用示例
request_client = EnterpriseRequest(retries=5,backoff_factor=0.3,proxies=[{'http': 'http://10.10.1.10:3128', 'https': 'http://10.10.1.10:1080'},{'http': 'http://10.10.1.11:3128', 'https': 'http://10.10.1.11:1080'}]
)response = request_client.get('https://www.example.com')
if response:print(f"成功获取内容: {len(response.text)}字节")2. 高级功能解析

五、法律合规框架设计
1. 爬虫法律边界
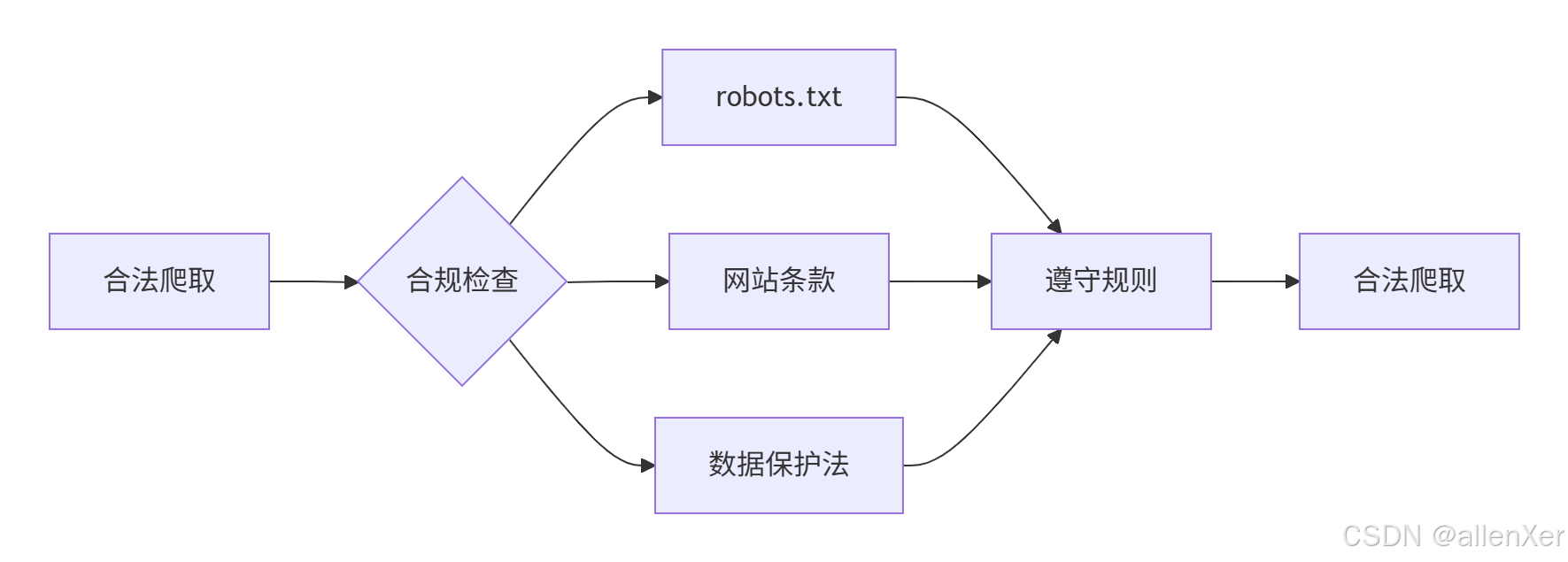
2. 合规爬虫实现
class CompliantCrawler(EnterpriseRequest):"""合规爬虫框架"""def __init__(self, domain, *args, **kwargs):super().__init__(*args, **kwargs)self.domain = domainself.robots_parser = self._parse_robots_txt()def _parse_robots_txt(self):"""解析robots.txt"""from urllib.robotparser import RobotFileParserrp = RobotFileParser()rp.set_url(f'https://{self.domain}/robots.txt')rp.read()return rpdef can_fetch(self, url):"""检查是否允许爬取"""return self.robots_parser.can_fetch('*', url)def safe_get(self, url):"""安全爬取"""if not self.can_fetch(url):print(f"警告: 根据robots.txt不允许爬取 {url}")return None# 添加合规头headers = {'From': 'contact@yourcompany.com','X-Crawler-Purpose': 'Academic Research'}return self.get(url, headers=headers)def crawl_sitemap(self):"""爬取网站地图"""sitemap_url = f'https://{self.domain}/sitemap.xml'if self.can_fetch(sitemap_url):response = self.get(sitemap_url)if response:# 解析sitemapreturn self._parse_sitemap(response.text)return []def _parse_sitemap(self, sitemap_xml):"""解析sitemap.xml"""# 实现解析逻辑return []# 使用示例
crawler = CompliantCrawler('example.com')
if crawler.can_fetch('/products'):response = crawler.safe_get('https://example.com/products')if response:print("成功获取产品页面")六、实战案例:电商网站爬取
1. 目标分析
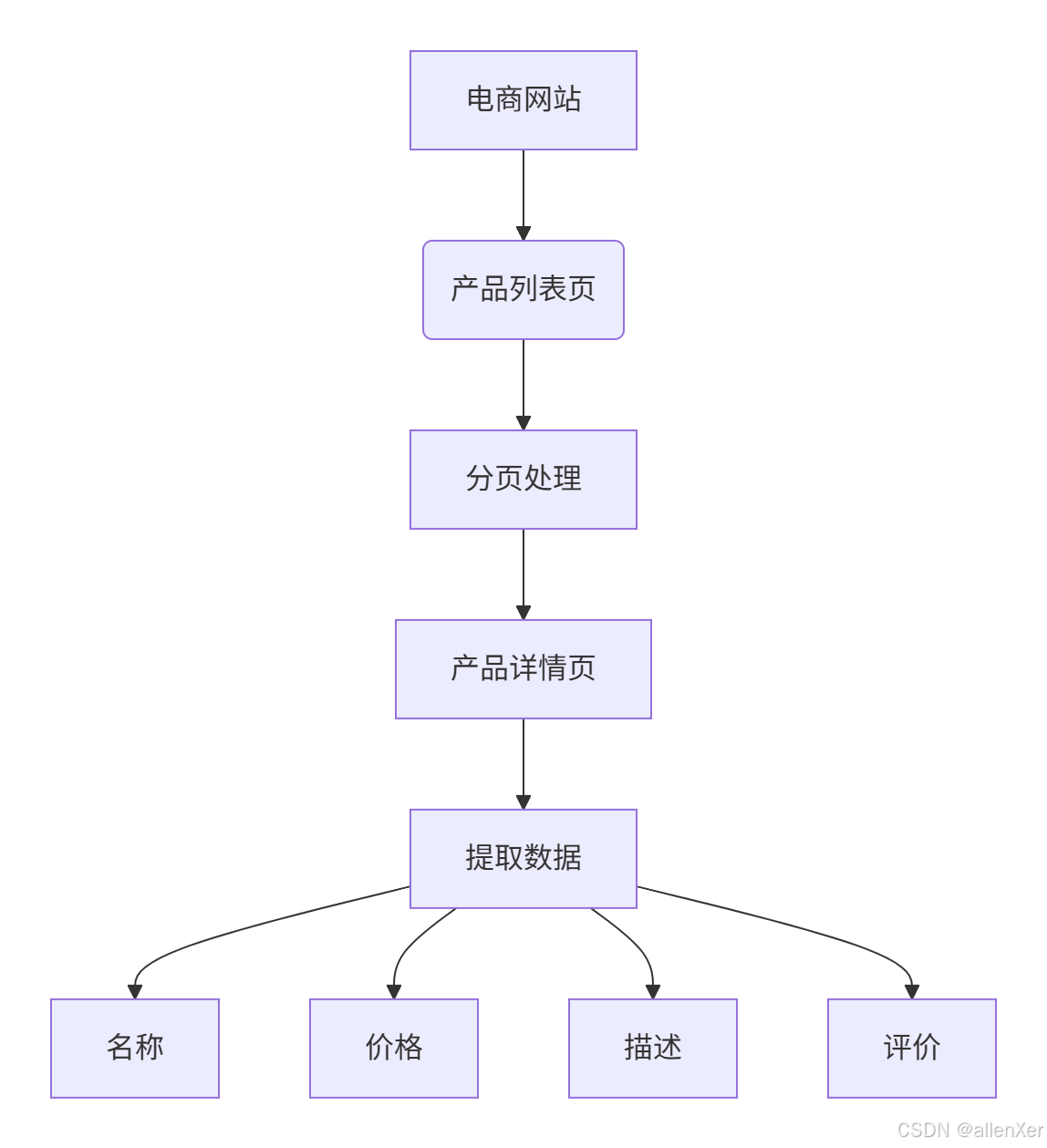
2. 完整爬虫实现
from bs4 import BeautifulSoup
import csv
import osclass EcommerceCrawler(CompliantCrawler):"""电商网站爬虫"""def __init__(self, domain, output_file='products.csv'):super().__init__(domain)self.output_file = output_fileself._init_csv()def _init_csv(self):"""初始化CSV文件"""if not os.path.exists(self.output_file):with open(self.output_file, 'w', encoding='utf-8', newline='') as f:writer = csv.writer(f)writer.writerow(['名称', '价格', '评分', '评论数', '链接'])def crawl_category(self, category_url):"""爬取分类产品"""page = 1while True:url = f"{category_url}?page={page}"if not self.can_fetch(url):print(f"达到robots.txt限制: {url}")breakresponse = self.safe_get(url)if not response:break# 解析产品列表soup = BeautifulSoup(response.text, 'html.parser')products = soup.select('.product-item')if not products:print(f"第{page}页无产品,停止爬取")breakprint(f"爬取第{page}页,产品数: {len(products)}")# 处理每个产品for product in products:self._process_product(product)page += 1time.sleep(random.uniform(1, 3)) # 随机延迟def _process_product(self, product):"""处理单个产品"""# 提取基本信息name = product.select_one('.product-name').text.strip()price = product.select_one('.price').text.strip()detail_url = product.select_one('a')['href']# 爬取详情页detail_response = self.safe_get(detail_url)if not detail_response:returndetail_soup = BeautifulSoup(detail_response.text, 'html.parser')# 提取详情信息rating = detail_soup.select_one('.rating-value').text.strip()reviews = detail_soup.select_one('.review-count').text.strip()# 保存数据self._save_to_csv([name, price, rating, reviews, detail_url])# 随机延迟time.sleep(random.uniform(0.5, 1.5))def _save_to_csv(self, row):"""保存数据到CSV"""with open(self.output_file, 'a', encoding='utf-8', newline='') as f:writer = csv.writer(f)writer.writerow(row)# 执行爬取
if __name__ == "__main__":crawler = EcommerceCrawler('example.com')crawler.crawl_category('https://example.com/electronics')print("爬取完成!数据已保存到products.csv")七、反爬虫对抗与破解
1. 常见反爬手段
2. 破解策略
class AntiAntiCrawler(EnterpriseRequest):"""反反爬虫增强版"""def __init__(self, *args, **kwargs):super().__init__(*args, **kwargs)self.js_engine = self._init_js_engine()def _init_js_engine(self):"""初始化JS引擎"""import execjstry:return execjs.get()except:print("警告: 未找到JS运行时环境")return Nonedef solve_captcha(self, image_data):"""解决验证码"""# 实际项目中应使用OCR或第三方服务return input("请输入验证码: ")def execute_js(self, js_code):"""执行JS代码"""if not self.js_engine:raise RuntimeError("JS引擎未初始化")return self.js_engine.eval(js_code)def get_with_js(self, url, js_script):"""执行JS后获取页面"""# 先获取初始页面response = self.get(url)if not response:return None# 执行JSresult = self.execute_js(js_script)# 可能需要重新请求return self.get(url + f'?token={result}')def rotate_ip(self):"""轮换IP地址"""if not self.proxies:print("警告: 未配置代理IP")return# 随机选择新代理self.session.proxies = random.choice(self.proxies)print(f"已更换代理: {self.session.proxies}")# 使用示例
advanced_crawler = AntiAntiCrawler(proxies=[{'http': 'proxy1:port', 'https': 'proxy1:port'},{'http': 'proxy2:port', 'https': 'proxy2:port'}]
)# 解决验证码
captcha_url = 'https://example.com/captcha.jpg'
captcha_image = advanced_crawler.get(captcha_url).content
captcha_text = advanced_crawler.solve_captcha(captcha_image)# 提交表单
login_data = {'username': 'user', 'password': 'pass', 'captcha': captcha_text}
advanced_crawler.post('https://example.com/login', data=login_data)八、思考题与小测验
1. 思考题
-
协议升级:
如何让爬虫同时支持HTTP/1.1和HTTP/2协议?
-
分布式爬虫:
如何设计分布式爬虫的请求调度系统?
-
法律风险:
在爬取海外网站时,如何确保符合GDPR等法规?
2. 小测验
-
HTTP状态码:
503状态码表示什么?
-
A) 页面未找到
-
B) 服务器错误
-
C) 服务不可用
-
D) 禁止访问
-
-
请求头:
哪个请求头用于防止CSRF攻击?
-
A) User-Agent
-
B) Referer
-
C) Cookie
-
D) X-CSRF-Token
-
-
爬虫伦理:
以下哪种行为违反爬虫伦理?
-
A) 遵守robots.txt
-
B) 限制爬取频率
-
C) 爬取付费内容
-
D) 注明数据来源
-
3. 订阅用户专享解答
一键直达文章内容包含:
-
思考题详细解答与最佳实践
-
小测验完整答案解析
-
HTTP/2协议实现源码
-
分布式请求调度系统
-
验证码智能识别模型
-
动态JS渲染破解方案
-
全球法律合规指南
九、总结:打造工业级爬虫基础
通过本篇,您已掌握:
-
🌐 HTTP协议核心原理
-
⚙️ Requests库高级技巧
-
🏭 企业级请求封装
-
⚖️ 法律合规框架
-
🛡️ 基础反爬对抗
-
🛒 电商爬虫实战
下一篇预告:
《HTML解析艺术:XPath与CSS选择器高级技巧》
-
深度解析HTML结构与XPath语法
-
动态页面结构自适应解析技术
-
反XPath检测绕过方案
-
分布式解析任务调度系统
-
亿级数据提取实战
"在数据为王的时代,爬虫技术是打开信息宝库的钥匙。掌握HTTP协议,你就迈出了成为爬虫专家的第一步。"
降维)






)




)






