一、小文件合并优化
Hive中的小文件分为Map端的小文件和Reduce端的小文件。
(1)、Map端的小文件优化是通过CombineHiveInputFormat操作。相关的参数是:
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
(2)、Reduce端的小文件合并
Map端的小文件合并是为了将小文件合并成一个切片,然后使用一个MR任务来执行这个切片。而Reduce端的小文件合并是为了将多个小文件合并成为一个大文件。
其原理是根据计算任务输出的文件的平均大小进行判断,若符合条件,就会单独的启动一个额外的任务进行合并。
相关的参数:
--------------开启合并map only任务输出的小文件-----------
set hive.merge.mapfiles=true;
--------------开启合并map reduce任务输出的小文件-----------
set hive.merge.mapredfiles=true;
------触发小文件合并的阈值,若某个计算任务输出的文件平均大小低于该阈值,就会触发合并-----
set hive.merge.smallfiles.avgsize=16000000;
------合并后的文件大小------------
set hive.merge.size.per.task=256000000;
二、CBO优化
CBO全称就是Cost based Optimizer,即基于计算成本的优化。在Hive中,计算成本受到数据的行数、CPU个数、本地IO、HDFS IO、网络IO等方面的影响,Hive会计算同一个SQL语句各个执行计划的计算成本,然后选择出计算成本最低的执行计划来执行。目前CBO在Hive的MR引擎下主要用于join的优化。例如多表join时的join顺序。
相关参数为:
--------是否启用cbo优化--------
set hive.cbo.enable=true;
三、谓词下推优化
谓词下推是指尽量的将过滤操作前移,以减少后续计算步骤中的数据量。
相关的参数是:
---------是否开启谓词下推优化--------------
set hive.optimize.ppd=true;
其实,在CBO优化中也会完成一部分的谓词下推操作,因为经过谓词下推以后的执行计划的计算成本往往会更低一些。
四、矢量化计算优化
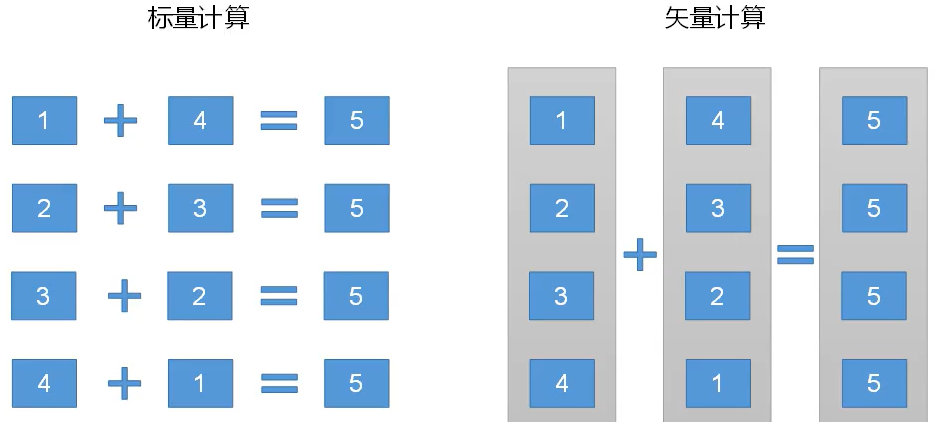
Hive的矢量化计算依赖于CPU的矢量计算操作。他可以使原有的标量计算转化为矢量化计算,提高查询和计算的效率。
在标量计算中,每一条加法计算就会产生一条指令,但是如果这一批计算都是加法计算,就可以先对这批数据矢量化,然后对矢量化后的数据用一次加法指令就可以了,这样就可以提高计算的效率。实现方式如图:
相关的参数设置为:
set hive.vectorized.execution.enable=true;
五、Fetch抓取优化
Fetch抓取优化的出现是因为有些情况下的查询其实不用走MapReduce,只需要简单的读取一下文件,将其中的结果读取出来就可以了。例如select * from emp;
默认情况下是开启这个参数的。相关参数是:
set hive.fetch.task.conversion=more;默认值就是more。none表示不开启,还有一个参数是minimal,但是用的很少,要是开启就直接用more就行了。
六、本地模式优化
当Hive的数据输入量较小的时候,触发任务执行的时间可能都比实际任务执行的时间长,这时就可以设置本地模式,在本地执行任务就可以了。对于小数据集来说,执行时间可以被明显的缩短。
七、并行执行优化
并行执行就是说一条SQL语句其实是分为了多个Stage来执行的,多个Stage之间可能有依赖关系,也可能会没有依赖关系,对于没有依赖关系的Stage,我们可以让他们并行的执行,这就是并行执行的优化目的。因为在默认情况下,不论Stage之间有没有依赖关系,他都只会一个个的执行Stage。
相关参数设置:
---启用并行执行优化
set hive.exec.parallel=true;
---同一个SQL语句的最大执行并行度,默认为8
set hive.exec.parallel.thread.number=8;
八、严格模式
Hive会严格的禁止一些危险的操作,这些危险的操作有:
(1)、分区表不使用分区字段过滤。不使用分区字段就代表着要操作的数据范围是整个表,这对于分区表的操作是十分危险的,因为整张表的数据量非常的巨大,对整张表的操作可能会占用巨大的资源。
(2)、使用order by没有使用limit过滤。order by也是一样,他会是对全表的数据进行排序,这也是十分危险的情况,一般在学习阶段因为数据量少不会注意这个要加上limit,但是在实际的生产环境下,数据量就是十分庞大,必须要加上limit才能够被允许执行。
(3)、笛卡尔积。也是十分消耗资源的一种操作。例如A表有1万条数据,B表有100条数据,进行笛卡尔积之后就会有100万条数据,造成了数据严重膨胀,所以一般情况下也要严格禁止这种操作的执行。


)
—Dubbo Consumer接收服务调用响应)


知识补充——场景切换、退出游戏、鼠标隐藏锁定、随机数、委托)

)

)

)






