【GPT入门】第43课 使用LlamaFactory微调Llama3
- 1.环境准备
- 2. 下载基座模型
- 3.LLaMA-Factory部署与启动
- 4. 重新训练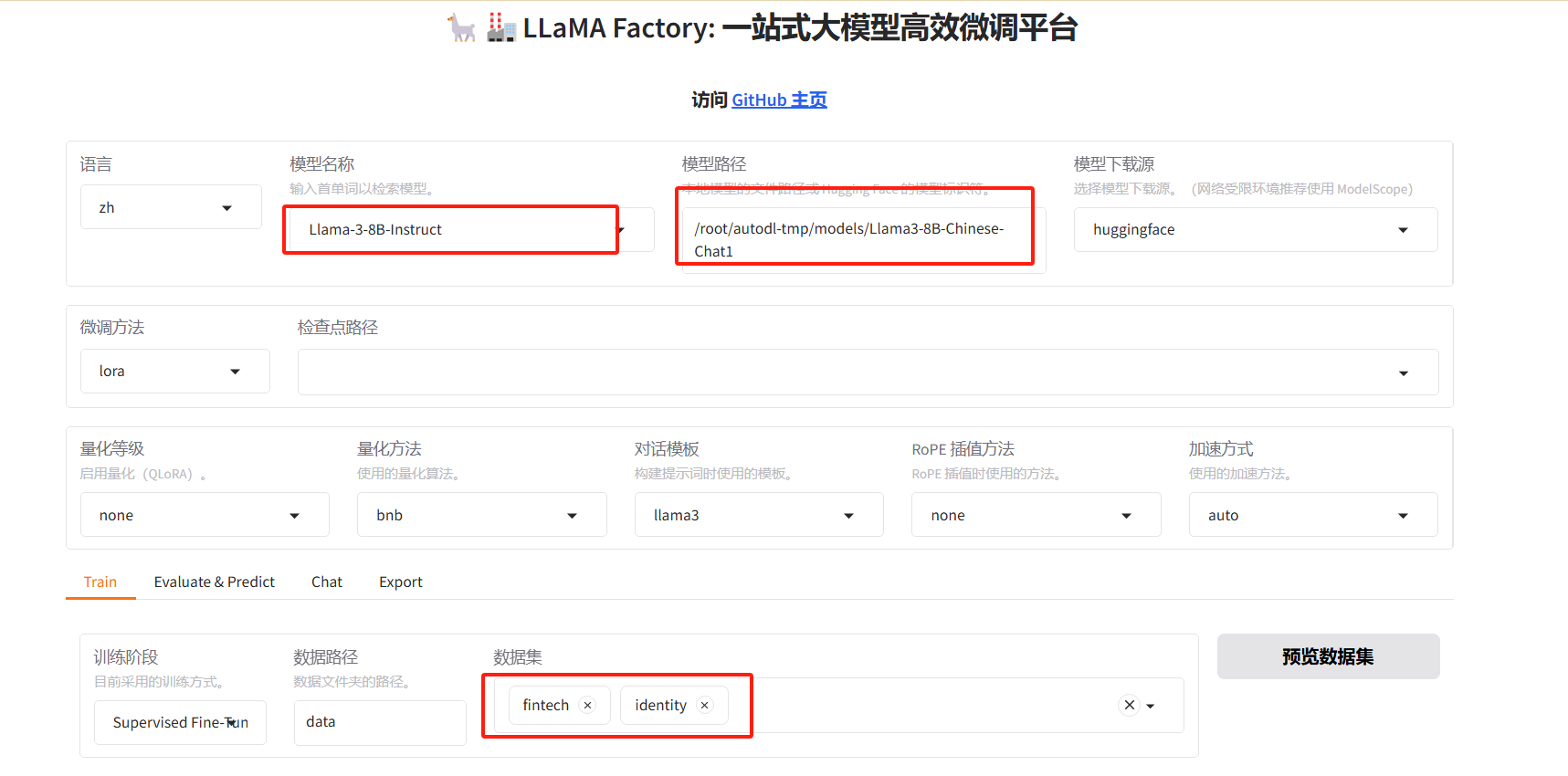
1.环境准备
采购autodl服务器,24G,GPU,型号3090,每小时大概2元。
2. 下载基座模型
下载基座模型:
source /etc/network_turbo
pip install -U huggingface_hub
export HF_ENDPOINT=https://hf-mirror.comsource /etc/network_turbohuggingface-cli download --resume-download shenzhi-wang/Llama3-8B-Chinese-Chat --local-dir /root/autodl-tmp/models/Llama3-8B-Chinese-Chat说明:
配置hf国内镜像
export HF_ENDPOINT=https://hf-mirror.com
autodl的学术加速
source /etc/network_turbo
3.LLaMA-Factory部署与启动
- 官网介绍
https://github.com/hiyouga/LLaMA-Factory
在数据盘下载LLaMA-Facotry
cd /root/autodl-tmp
- 下载
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e .
- 启动ui
llamafactory-cli webui
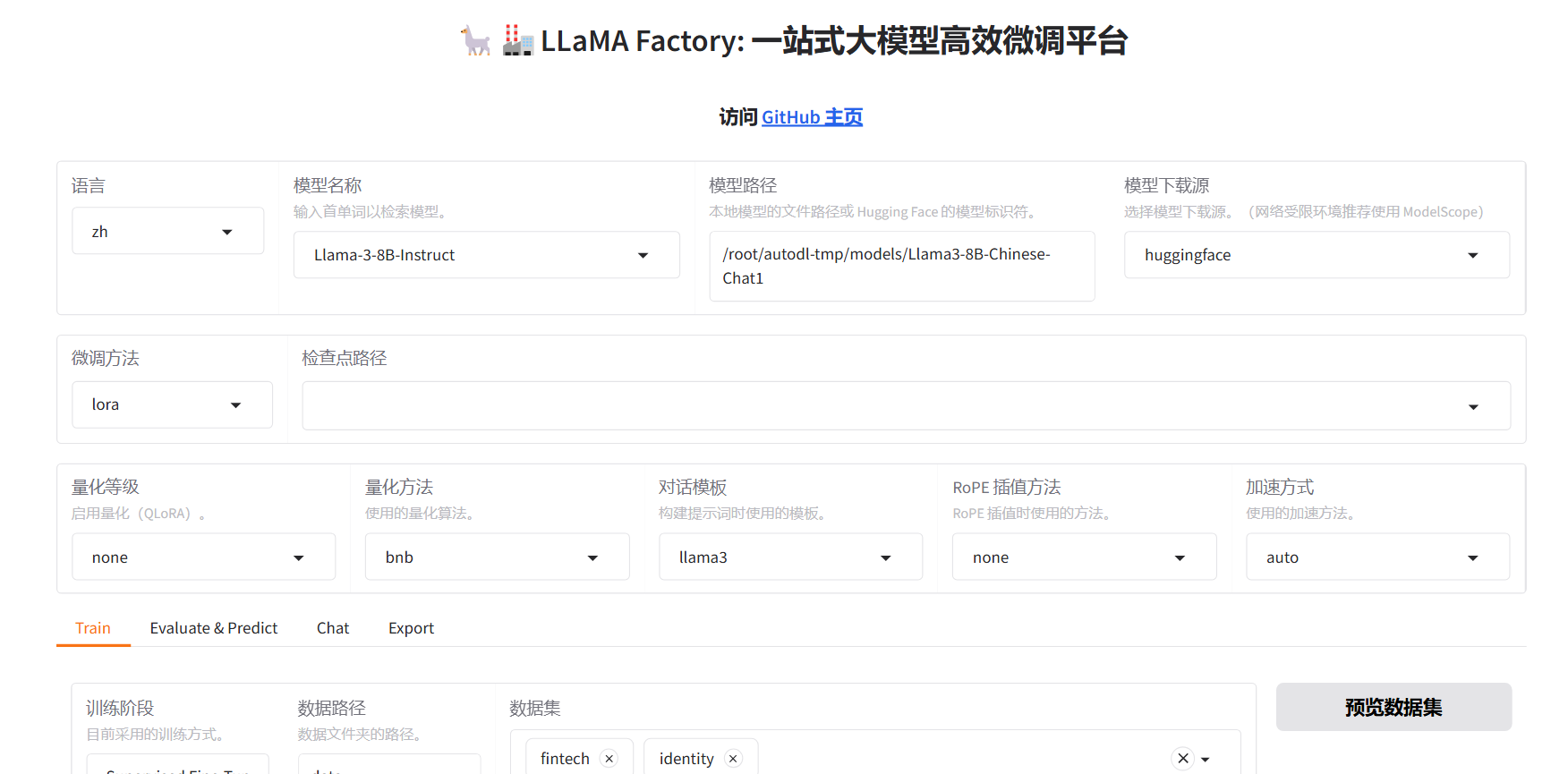
配置好模型相关参数
可以生成命令,点击开始,就开始训练
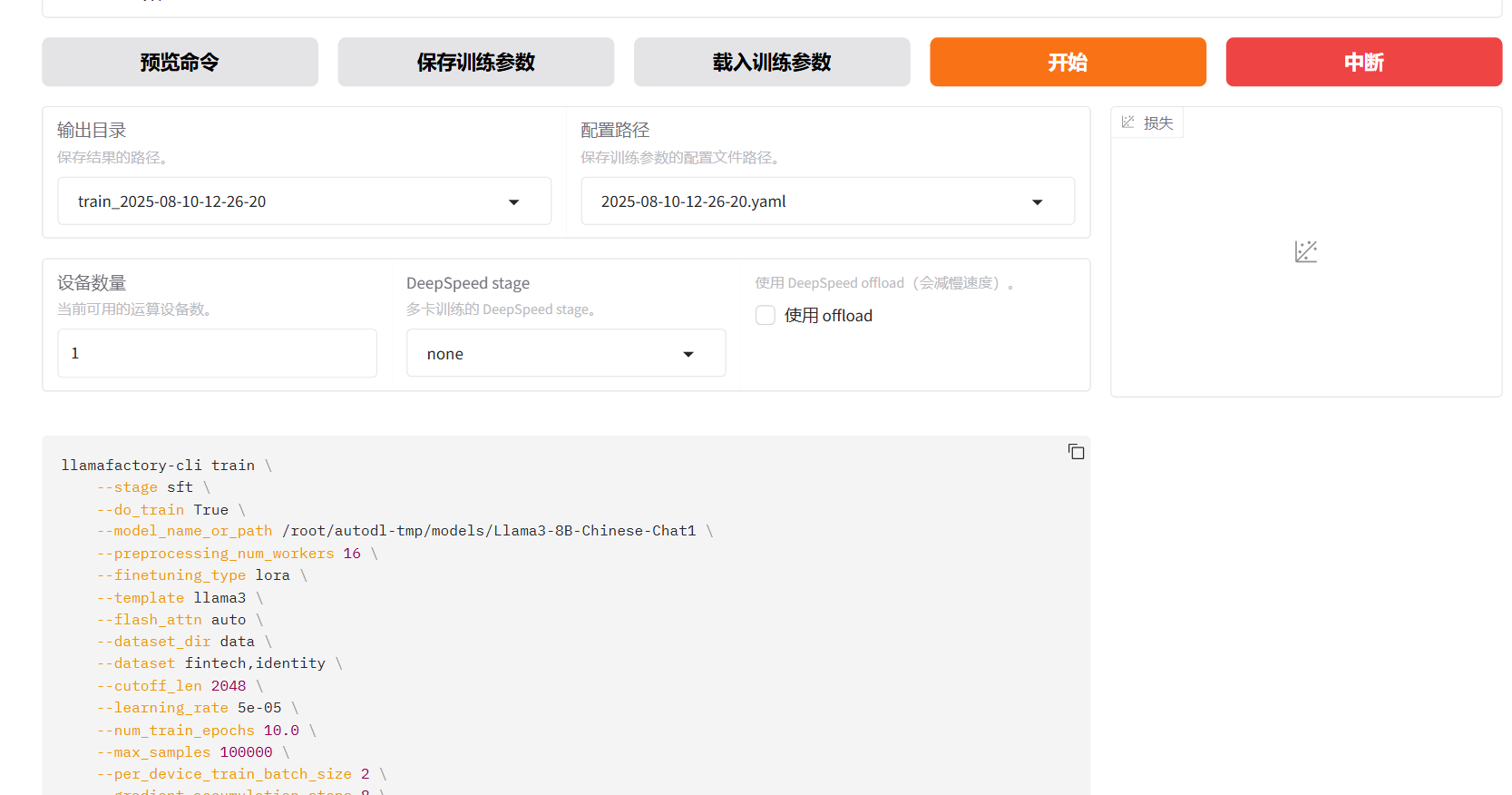
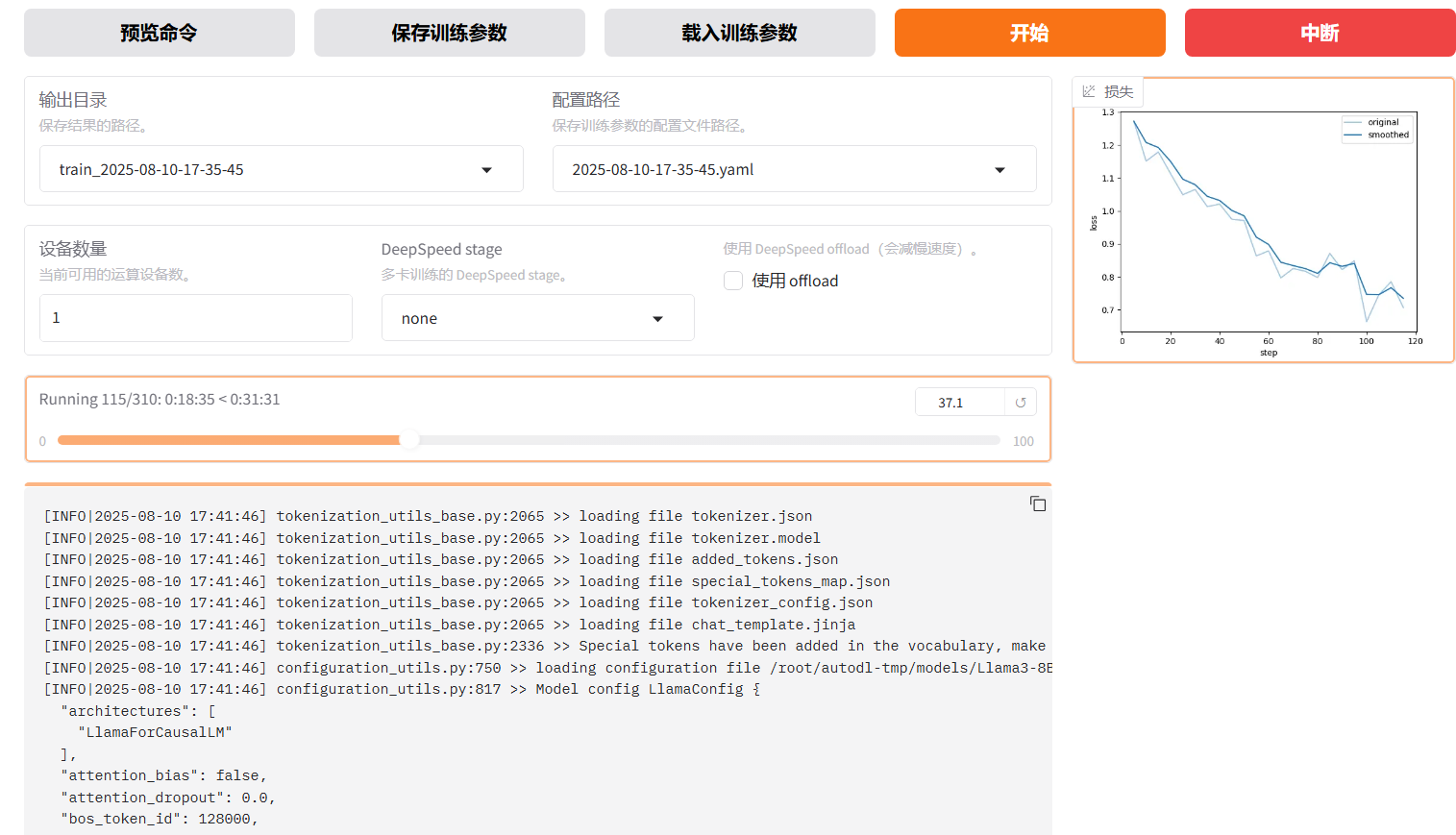
训练损失:
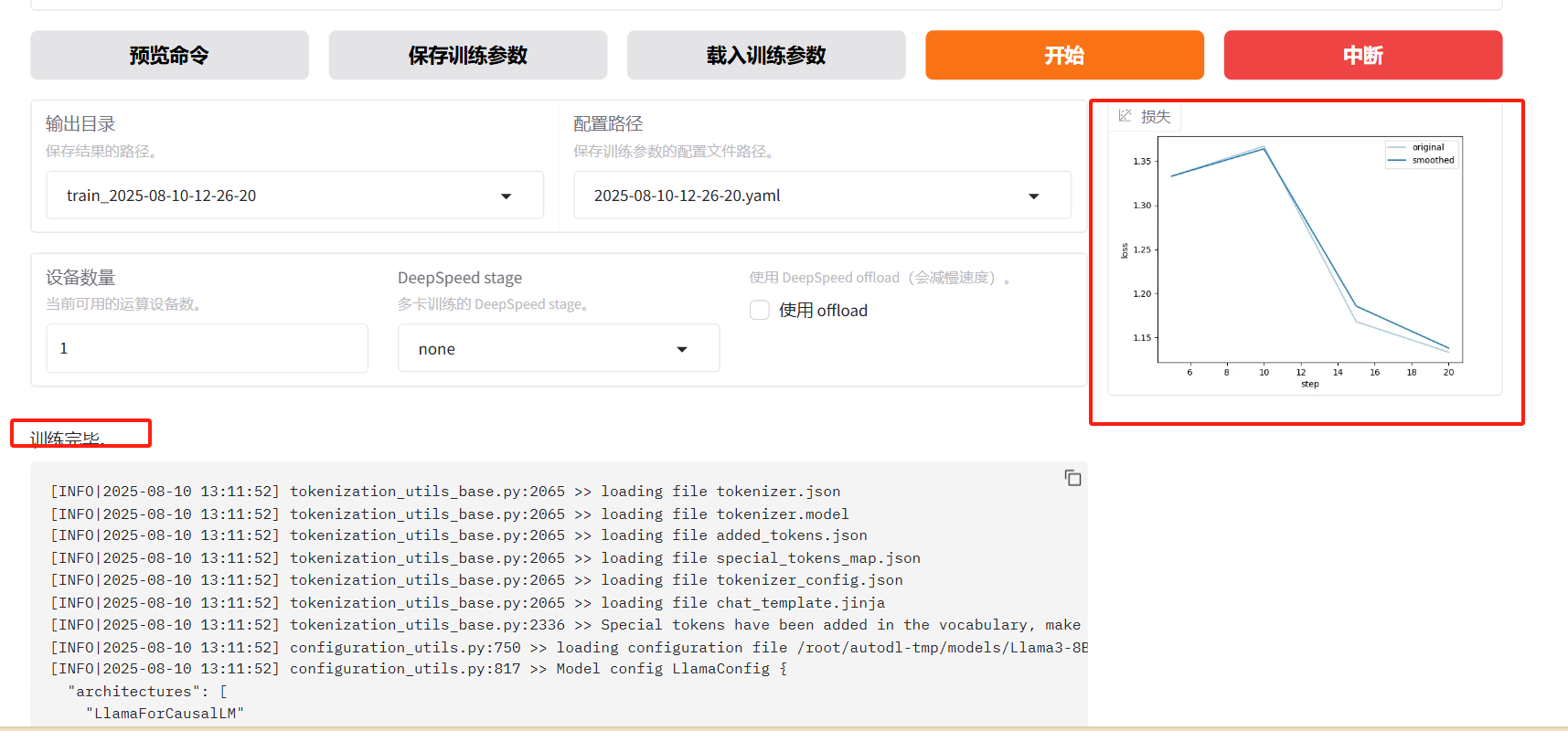
训练结果:
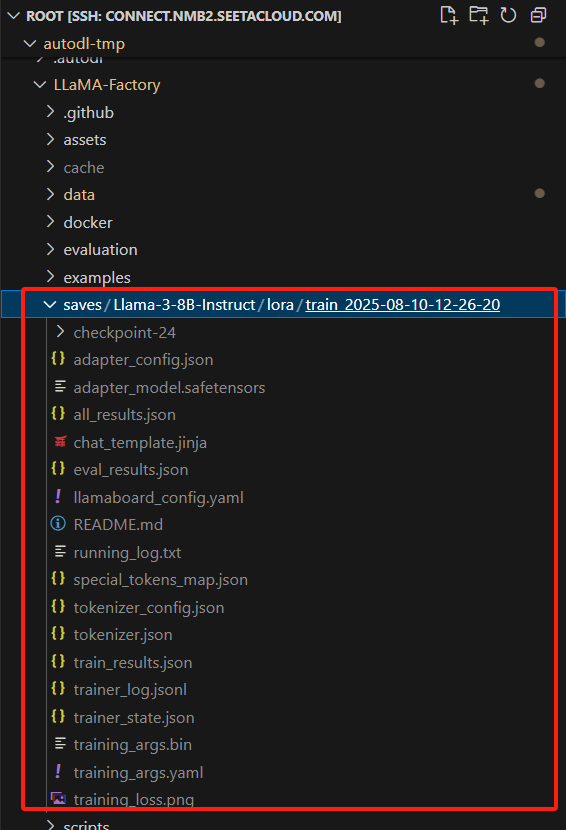
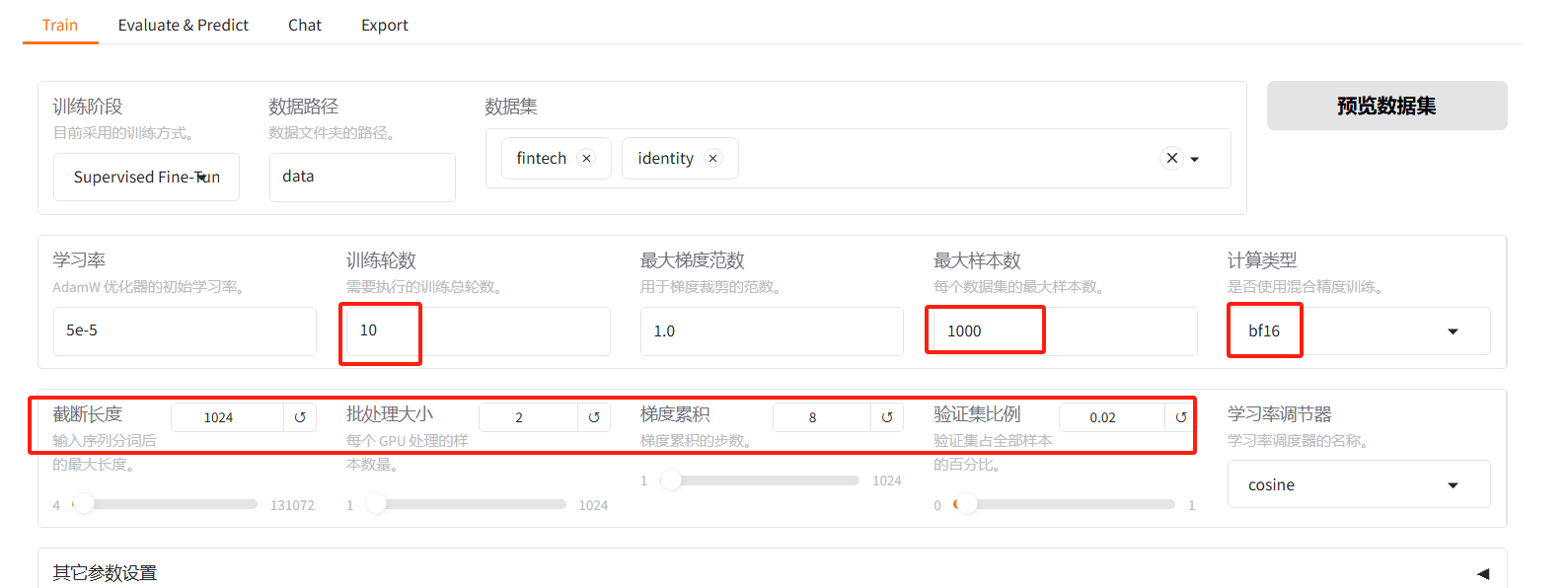
4. 重新训练
配置修改
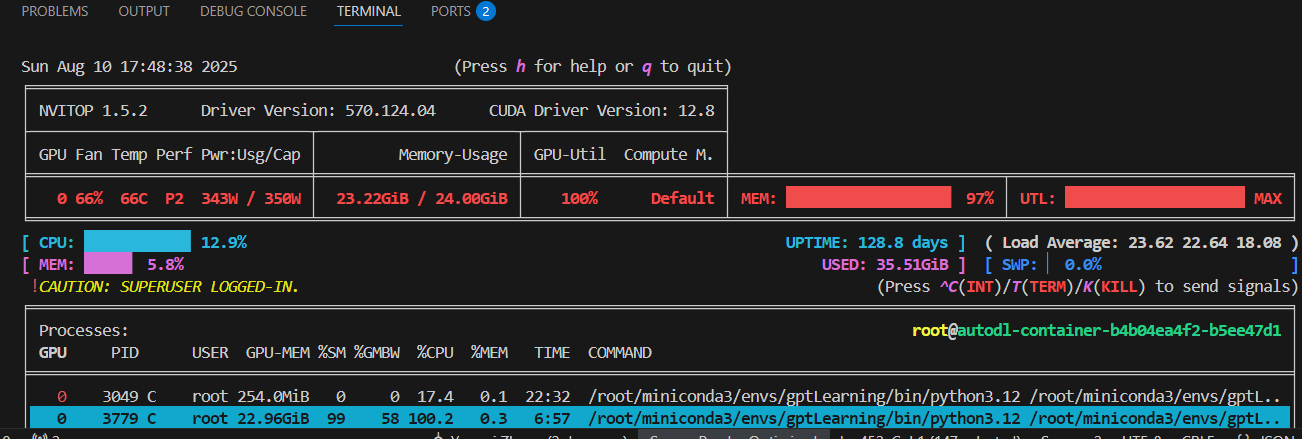
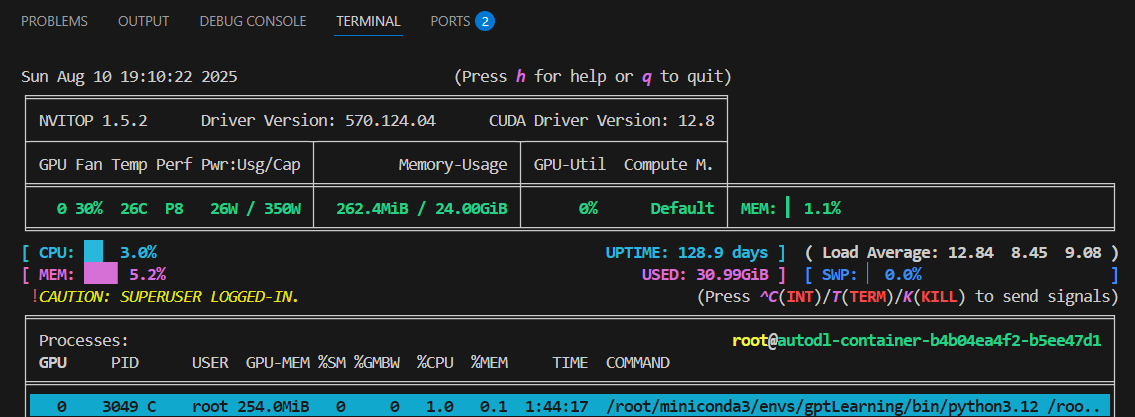
- 查看内存使用 nvitop
训练过程,内存,GPU都使用完。
- 记录训练过程
- 训练结果
null,"rope_theta": 500000.0,"tie_word_embeddings": false,"torch_dtype": "bfloat16","transformers_version": "4.55.0","use_cache": true,"vocab_size": 128256
}[INFO|2025-08-10 17:41:53] logging.py:143 >> KV cache is disabled during training.
[INFO|2025-08-10 17:41:53] modeling_utils.py:1305 >> loading weights file /root/autodl-tmp/models/Llama3-8B-Chinese-Chat1/model.safetensors.index.json
[INFO|2025-08-10 17:41:53] modeling_utils.py:2411 >> Instantiating LlamaForCausalLM model under default dtype torch.bfloat16.
[INFO|2025-08-10 17:41:53] configuration_utils.py:1098 >> Generate config GenerationConfig {"bos_token_id": 128000,"eos_token_id": 128009,"use_cache": false
}[INFO|2025-08-10 17:41:55] modeling_utils.py:5606 >> All model checkpoint weights were used when initializing LlamaForCausalLM.[INFO|2025-08-10 17:41:55] modeling_utils.py:5614 >> All the weights of LlamaForCausalLM were initialized from the model checkpoint at /root/autodl-tmp/models/Llama3-8B-Chinese-Chat1.
If your task is similar to the task the model of the checkpoint was trained on, you can already use LlamaForCausalLM for predictions without further training.
[INFO|2025-08-10 17:41:55] configuration_utils.py:1051 >> loading configuration file /root/autodl-tmp/models/Llama3-8B-Chinese-Chat1/generation_config.json
[INFO|2025-08-10 17:41:55] configuration_utils.py:1098 >> Generate config GenerationConfig {"bos_token_id": 128000,"eos_token_id": 128009,"pad_token_id": 128009
}[INFO|2025-08-10 17:41:55] logging.py:143 >> Gradient checkpointing enabled.
[INFO|2025-08-10 17:41:55] logging.py:143 >> Using torch SDPA for faster training and inference.
[INFO|2025-08-10 17:41:55] logging.py:143 >> Upcasting trainable params to float32.
[INFO|2025-08-10 17:41:55] logging.py:143 >> Fine-tuning method: LoRA
[INFO|2025-08-10 17:41:55] logging.py:143 >> Found linear modules: k_proj,gate_proj,o_proj,down_proj,v_proj,up_proj,q_proj
[INFO|2025-08-10 17:41:55] logging.py:143 >> trainable params: 20,971,520 || all params: 8,051,232,768 || trainable%: 0.2605
[INFO|2025-08-10 17:41:56] trainer.py:757 >> Using auto half precision backend
[INFO|2025-08-10 17:41:56] trainer.py:2433 >> ***** Running training *****
[INFO|2025-08-10 17:41:56] trainer.py:2434 >> Num examples = 481
[INFO|2025-08-10 17:41:56] trainer.py:2435 >> Num Epochs = 10
[INFO|2025-08-10 17:41:56] trainer.py:2436 >> Instantaneous batch size per device = 2
[INFO|2025-08-10 17:41:56] trainer.py:2439 >> Total train batch size (w. parallel, distributed & accumulation) = 16
[INFO|2025-08-10 17:41:56] trainer.py:2440 >> Gradient Accumulation steps = 8
[INFO|2025-08-10 17:41:56] trainer.py:2441 >> Total optimization steps = 310
[INFO|2025-08-10 17:41:56] trainer.py:2442 >> Number of trainable parameters = 20,971,520
[INFO|2025-08-10 17:42:46] logging.py:143 >> {'loss': 1.2718, 'learning_rate': 4.9979e-05, 'epoch': 0.17, 'throughput': 973.44}
[INFO|2025-08-10 17:43:33] logging.py:143 >> {'loss': 1.1509, 'learning_rate': 4.9896e-05, 'epoch': 0.33, 'throughput': 977.09}
[INFO|2025-08-10 17:44:25] logging.py:143 >> {'loss': 1.1788, 'learning_rate': 4.9749e-05, 'epoch': 0.50, 'throughput': 973.40}
[INFO|2025-08-10 17:45:15] logging.py:143 >> {'loss': 1.1129, 'learning_rate': 4.9538e-05, 'epoch': 0.66, 'throughput': 972.88}
[INFO|2025-08-10 17:46:07] logging.py:143 >> {'loss': 1.0490, 'learning_rate': 4.9264e-05, 'epoch': 0.83, 'throughput': 973.34}
[INFO|2025-08-10 17:46:52] logging.py:143 >> {'loss': 1.0651, 'learning_rate': 4.8928e-05, 'epoch': 1.00, 'throughput': 970.40}
[INFO|2025-08-10 17:47:32] logging.py:143 >> {'loss': 1.0130, 'learning_rate': 4.8531e-05, 'epoch': 1.13, 'throughput': 968.83}
[INFO|2025-08-10 17:48:25] logging.py:143 >> {'loss': 1.0207, 'learning_rate': 4.8073e-05, 'epoch': 1.30, 'throughput': 968.68}
[INFO|2025-08-10 17:49:20] logging.py:143 >> {'loss': 0.9748, 'learning_rate': 4.7556e-05, 'epoch': 1.46, 'throughput': 968.56}
[INFO|2025-08-10 17:50:18] logging.py:143 >> {'loss': 0.9706, 'learning_rate': 4.6980e-05, 'epoch': 1.63, 'throughput': 969.27}
[INFO|2025-08-10 17:51:10] logging.py:143 >> {'loss': 0.8635, 'learning_rate': 4.6349e-05, 'epoch': 1.80, 'throughput': 968.72}
[INFO|2025-08-10 17:51:52] logging.py:143 >> {'loss': 0.8789, 'learning_rate': 4.5663e-05, 'epoch': 1.96, 'throughput': 967.37}
[INFO|2025-08-10 17:52:26] logging.py:143 >> {'loss': 0.7969, 'learning_rate': 4.4923e-05, 'epoch': 2.10, 'throughput': 966.36}
[INFO|2025-08-10 17:53:13] logging.py:143 >> {'loss': 0.8251, 'learning_rate': 4.4133e-05, 'epoch': 2.27, 'throughput': 965.43}
[INFO|2025-08-10 17:54:01] logging.py:143 >> {'loss': 0.8170, 'learning_rate': 4.3293e-05, 'epoch': 2.43, 'throughput': 965.72}
[INFO|2025-08-10 17:54:52] logging.py:143 >> {'loss': 0.7979, 'learning_rate': 4.2407e-05, 'epoch': 2.60, 'throughput': 965.57}
[INFO|2025-08-10 17:55:41] logging.py:143 >> {'loss': 0.8711, 'learning_rate': 4.1476e-05, 'epoch': 2.76, 'throughput': 966.39}
[INFO|2025-08-10 17:56:35] logging.py:143 >> {'loss': 0.8219, 'learning_rate': 4.0502e-05, 'epoch': 2.93, 'throughput': 966.59}
[INFO|2025-08-10 17:57:19] logging.py:143 >> {'loss': 0.8487, 'learning_rate': 3.9489e-05, 'epoch': 3.07, 'throughput': 967.22}
[INFO|2025-08-10 17:58:06] logging.py:143 >> {'loss': 0.6639, 'learning_rate': 3.8438e-05, 'epoch': 3.23, 'throughput': 967.08}
[INFO|2025-08-10 17:58:06] trainer.py:4408 >>
***** Running Evaluation *****
[INFO|2025-08-10 17:58:06] trainer.py:4410 >> Num examples = 10
[INFO|2025-08-10 17:58:06] trainer.py:4413 >> Batch size = 2
[INFO|2025-08-10 17:58:08] trainer.py:4074 >> Saving model checkpoint to saves/Llama-3-8B-Instruct/lora/train_2025-08-10-17-35-45/checkpoint-100
[INFO|2025-08-10 17:58:08] configuration_utils.py:750 >> loading configuration file /root/autodl-tmp/models/Llama3-8B-Chinese-Chat1/config.json
[INFO|2025-08-10 17:58:08] configuration_utils.py:817 >> Model config LlamaConfig {"architectures": ["LlamaForCausalLM"],"attention_bias": false,"attention_dropout": 0.0,"bos_token_id": 128000,"eos_token_id": 128009,"head_dim": 128,"hidden_act": "silu","hidden_size": 4096,"initializer_range": 0.02,"intermediate_size": 14336,"max_position_embeddings": 8192,"mlp_bias": false,"model_type": "llama","num_attention_heads": 32,"num_hidden_layers": 32,"num_key_value_heads": 8,"pretraining_tp": 1,"rms_norm_eps": 1e-05,"rope_scaling": null,"rope_theta": 500000.0,"tie_word_embeddings": false,"torch_dtype": "bfloat16","transformers_version": "4.55.0","use_cache": true,"vocab_size": 128256
}[INFO|2025-08-10 17:58:08] tokenization_utils_base.py:2393 >> chat template saved in saves/Llama-3-8B-Instruct/lora/train_2025-08-10-17-35-45/checkpoint-100/chat_template.jinja
[INFO|2025-08-10 17:58:08] tokenization_utils_base.py:2562 >> tokenizer config file saved in saves/Llama-3-8B-Instruct/lora/train_2025-08-10-17-35-45/checkpoint-100/tokenizer_config.json
[INFO|2025-08-10 17:58:08] tokenization_utils_base.py:2571 >> Special tokens file saved in saves/Llama-3-8B-Instruct/lora/train_2025-08-10-17-35-45/checkpoint-100/special_tokens_map.json
[INFO|2025-08-10 17:58:57] logging.py:143 >> {'loss': 0.7453, 'learning_rate': 3.7353e-05, 'epoch': 3.40, 'throughput': 964.85}
[INFO|2025-08-10 17:59:43] logging.py:143 >> {'loss': 0.7854, 'learning_rate': 3.6237e-05, 'epoch': 3.56, 'throughput': 964.81}
[INFO|2025-08-10 18:00:31] logging.py:143 >> {'loss': 0.7068, 'learning_rate': 3.5091e-05, 'epoch': 3.73, 'throughput': 964.43}
[INFO|2025-08-10 18:01:27] logging.py:143 >> {'loss': 0.7155, 'learning_rate': 3.3920e-05, 'epoch': 3.90, 'throughput': 964.82}
[INFO|2025-08-10 18:02:05] logging.py:143 >> {'loss': 0.6858, 'learning_rate': 3.2725e-05, 'epoch': 4.03, 'throughput': 964.73}
[INFO|2025-08-10 18:02:52] logging.py:143 >> {'loss': 0.6058, 'learning_rate': 3.1511e-05, 'epoch': 4.20, 'throughput': 964.82}
[INFO|2025-08-10 18:03:41] logging.py:143 >> {'loss': 0.6702, 'learning_rate': 3.0280e-05, 'epoch': 4.37, 'throughput': 964.40}
[INFO|2025-08-10 18:04:29] logging.py:143 >> {'loss': 0.6454, 'learning_rate': 2.9036e-05, 'epoch': 4.53, 'throughput': 964.05}
[INFO|2025-08-10 18:05:23] logging.py:143 >> {'loss': 0.6122, 'learning_rate': 2.7781e-05, 'epoch': 4.70, 'throughput': 964.45}
[INFO|2025-08-10 18:06:15] logging.py:143 >> {'loss': 0.6598, 'learning_rate': 2.6519e-05, 'epoch': 4.86, 'throughput': 964.33}
[INFO|2025-08-10 18:06:55] logging.py:143 >> {'loss': 0.5058, 'learning_rate': 2.5253e-05, 'epoch': 5.00, 'throughput': 964.34}
[INFO|2025-08-10 18:07:57] logging.py:143 >> {'loss': 0.6128, 'learning_rate': 2.3987e-05, 'epoch': 5.17, 'throughput': 964.73}
[INFO|2025-08-10 18:08:49] logging.py:143 >> {'loss': 0.5506, 'learning_rate': 2.2723e-05, 'epoch': 5.33, 'throughput': 965.04}
[INFO|2025-08-10 18:09:33] logging.py:143 >> {'loss': 0.4599, 'learning_rate': 2.1465e-05, 'epoch': 5.50, 'throughput': 964.54}
[INFO|2025-08-10 18:10:21] logging.py:143 >> {'loss': 0.5927, 'learning_rate': 2.0216e-05, 'epoch': 5.66, 'throughput': 964.48}
[INFO|2025-08-10 18:11:14] logging.py:143 >> {'loss': 0.5014, 'learning_rate': 1.8979e-05, 'epoch': 5.83, 'throughput': 964.93}
[INFO|2025-08-10 18:11:58] logging.py:143 >> {'loss': 0.5629, 'learning_rate': 1.7758e-05, 'epoch': 6.00, 'throughput': 965.11}
[INFO|2025-08-10 18:12:35] logging.py:143 >> {'loss': 0.3429, 'learning_rate': 1.6555e-05, 'epoch': 6.13, 'throughput': 964.97}
[INFO|2025-08-10 18:13:27] logging.py:143 >> {'loss': 0.5253, 'learning_rate': 1.5374e-05, 'epoch': 6.30, 'throughput': 965.11}
[INFO|2025-08-10 18:14:15] logging.py:143 >> {'loss': 0.4926, 'learning_rate': 1.4218e-05, 'epoch': 6.46, 'throughput': 965.22}
[INFO|2025-08-10 18:14:15] trainer.py:4408 >>
***** Running Evaluation *****
[INFO|2025-08-10 18:14:15] trainer.py:4410 >> Num examples = 10
[INFO|2025-08-10 18:14:15] trainer.py:4413 >> Batch size = 2
[INFO|2025-08-10 18:14:18] trainer.py:4074 >> Saving model checkpoint to saves/Llama-3-8B-Instruct/lora/train_2025-08-10-17-35-45/checkpoint-200
[INFO|2025-08-10 18:14:18] configuration_utils.py:750 >> loading configuration file /root/autodl-tmp/models/Llama3-8B-Chinese-Chat1/config.json
[INFO|2025-08-10 18:14:18] configuration_utils.py:817 >> Model config LlamaConfig {"architectures": ["LlamaForCausalLM"],"attention_bias": false,"attention_dropout": 0.0,"bos_token_id": 128000,"eos_token_id": 128009,"head_dim": 128,"hidden_act": "silu","hidden_size": 4096,"initializer_range": 0.02,"intermediate_size": 14336,"max_position_embeddings": 8192,"mlp_bias": false,"model_type": "llama","num_attention_heads": 32,"num_hidden_layers": 32,"num_key_value_heads": 8,"pretraining_tp": 1,"rms_norm_eps": 1e-05,"rope_scaling": null,"rope_theta": 500000.0,"tie_word_embeddings": false,"torch_dtype": "bfloat16","transformers_version": "4.55.0","use_cache": true,"vocab_size": 128256
}[INFO|2025-08-10 18:14:18] tokenization_utils_base.py:2393 >> chat template saved in saves/Llama-3-8B-Instruct/lora/train_2025-08-10-17-35-45/checkpoint-200/chat_template.jinja
[INFO|2025-08-10 18:14:18] tokenization_utils_base.py:2562 >> tokenizer config file saved in saves/Llama-3-8B-Instruct/lora/train_2025-08-10-17-35-45/checkpoint-200/tokenizer_config.json
[INFO|2025-08-10 18:14:18] tokenization_utils_base.py:2571 >> Special tokens file saved in saves/Llama-3-8B-Instruct/lora/train_2025-08-10-17-35-45/checkpoint-200/special_tokens_map.json
[INFO|2025-08-10 18:15:09] logging.py:143 >> {'loss': 0.4487, 'learning_rate': 1.3090e-05, 'epoch': 6.63, 'throughput': 963.77}
[INFO|2025-08-10 18:16:01] logging.py:143 >> {'loss': 0.5197, 'learning_rate': 1.1992e-05, 'epoch': 6.80, 'throughput': 964.14}
[INFO|2025-08-10 18:16:48] logging.py:143 >> {'loss': 0.4752, 'learning_rate': 1.0927e-05, 'epoch': 6.96, 'throughput': 964.07}
[INFO|2025-08-10 18:17:29] logging.py:143 >> {'loss': 0.4830, 'learning_rate': 9.8985e-06, 'epoch': 7.10, 'throughput': 964.03}
[INFO|2025-08-10 18:18:11] logging.py:143 >> {'loss': 0.4122, 'learning_rate': 8.9088e-06, 'epoch': 7.27, 'throughput': 963.90}
[INFO|2025-08-10 18:19:01] logging.py:143 >> {'loss': 0.3856, 'learning_rate': 7.9603e-06, 'epoch': 7.43, 'throughput': 963.90}
[INFO|2025-08-10 18:19:49] logging.py:143 >> {'loss': 0.4221, 'learning_rate': 7.0557e-06, 'epoch': 7.60, 'throughput': 963.93}
[INFO|2025-08-10 18:20:43] logging.py:143 >> {'loss': 0.4601, 'learning_rate': 6.1970e-06, 'epoch': 7.76, 'throughput': 963.97}
[INFO|2025-08-10 18:21:38] logging.py:143 >> {'loss': 0.4670, 'learning_rate': 5.3867e-06, 'epoch': 7.93, 'throughput': 964.27}
[INFO|2025-08-10 18:22:17] logging.py:143 >> {'loss': 0.3538, 'learning_rate': 4.6267e-06, 'epoch': 8.07, 'throughput': 964.06}
[INFO|2025-08-10 18:23:05] logging.py:143 >> {'loss': 0.3823, 'learning_rate': 3.9190e-06, 'epoch': 8.23, 'throughput': 963.94}
[INFO|2025-08-10 18:23:58] logging.py:143 >> {'loss': 0.3467, 'learning_rate': 3.2654e-06, 'epoch': 8.40, 'throughput': 963.98}
[INFO|2025-08-10 18:24:45] logging.py:143 >> {'loss': 0.4004, 'learning_rate': 2.6676e-06, 'epoch': 8.56, 'throughput': 963.92}
[INFO|2025-08-10 18:25:33] logging.py:143 >> {'loss': 0.4647, 'learning_rate': 2.1271e-06, 'epoch': 8.73, 'throughput': 963.86}
[INFO|2025-08-10 18:26:28] logging.py:143 >> {'loss': 0.3902, 'learning_rate': 1.6454e-06, 'epoch': 8.90, 'throughput': 964.21}
[INFO|2025-08-10 18:27:05] logging.py:143 >> {'loss': 0.4114, 'learning_rate': 1.2236e-06, 'epoch': 9.03, 'throughput': 963.96}
[INFO|2025-08-10 18:28:06] logging.py:143 >> {'loss': 0.4310, 'learning_rate': 8.6282e-07, 'epoch': 9.20, 'throughput': 964.55}
[INFO|2025-08-10 18:28:53] logging.py:143 >> {'loss': 0.4251, 'learning_rate': 5.6401e-07, 'epoch': 9.37, 'throughput': 964.58}
[INFO|2025-08-10 18:29:35] logging.py:143 >> {'loss': 0.3407, 'learning_rate': 3.2793e-07, 'epoch': 9.53, 'throughput': 964.39}
[INFO|2025-08-10 18:30:26] logging.py:143 >> {'loss': 0.4325, 'learning_rate': 1.5518e-07, 'epoch': 9.70, 'throughput': 964.48}
[INFO|2025-08-10 18:30:26] trainer.py:4408 >>
***** Running Evaluation *****
[INFO|2025-08-10 18:30:26] trainer.py:4410 >> Num examples = 10
[INFO|2025-08-10 18:30:26] trainer.py:4413 >> Batch size = 2
[INFO|2025-08-10 18:30:28] trainer.py:4074 >> Saving model checkpoint to saves/Llama-3-8B-Instruct/lora/train_2025-08-10-17-35-45/checkpoint-300
[INFO|2025-08-10 18:30:28] configuration_utils.py:750 >> loading configuration file /root/autodl-tmp/models/Llama3-8B-Chinese-Chat1/config.json
[INFO|2025-08-10 18:30:28] configuration_utils.py:817 >> Model config LlamaConfig {"architectures": ["LlamaForCausalLM"],"attention_bias": false,"attention_dropout": 0.0,"bos_token_id": 128000,"eos_token_id": 128009,"head_dim": 128,"hidden_act": "silu","hidden_size": 4096,"initializer_range": 0.02,"intermediate_size": 14336,"max_position_embeddings": 8192,"mlp_bias": false,"model_type": "llama","num_attention_heads": 32,"num_hidden_layers": 32,"num_key_value_heads": 8,"pretraining_tp": 1,"rms_norm_eps": 1e-05,"rope_scaling": null,"rope_theta": 500000.0,"tie_word_embeddings": false,"torch_dtype": "bfloat16","transformers_version": "4.55.0","use_cache": true,"vocab_size": 128256
}[INFO|2025-08-10 18:30:28] tokenization_utils_base.py:2393 >> chat template saved in saves/Llama-3-8B-Instruct/lora/train_2025-08-10-17-35-45/checkpoint-300/chat_template.jinja
[INFO|2025-08-10 18:30:28] tokenization_utils_base.py:2562 >> tokenizer config file saved in saves/Llama-3-8B-Instruct/lora/train_2025-08-10-17-35-45/checkpoint-300/tokenizer_config.json
[INFO|2025-08-10 18:30:28] tokenization_utils_base.py:2571 >> Special tokens file saved in saves/Llama-3-8B-Instruct/lora/train_2025-08-10-17-35-45/checkpoint-300/special_tokens_map.json
[INFO|2025-08-10 18:31:15] logging.py:143 >> {'loss': 0.3490, 'learning_rate': 4.6201e-08, 'epoch': 9.86, 'throughput': 963.47}
[INFO|2025-08-10 18:32:01] logging.py:143 >> {'loss': 0.3733, 'learning_rate': 1.2838e-09, 'epoch': 10.00, 'throughput': 963.59}
[INFO|2025-08-10 18:32:01] trainer.py:4074 >> Saving model checkpoint to saves/Llama-3-8B-Instruct/lora/train_2025-08-10-17-35-45/checkpoint-310
[INFO|2025-08-10 18:32:01] configuration_utils.py:750 >> loading configuration file /root/autodl-tmp/models/Llama3-8B-Chinese-Chat1/config.json
[INFO|2025-08-10 18:32:01] configuration_utils.py:817 >> Model config LlamaConfig {"architectures": ["LlamaForCausalLM"],"attention_bias": false,"attention_dropout": 0.0,"bos_token_id": 128000,"eos_token_id": 128009,"head_dim": 128,"hidden_act": "silu","hidden_size": 4096,"initializer_range": 0.02,"intermediate_size": 14336,"max_position_embeddings": 8192,"mlp_bias": false,"model_type": "llama","num_attention_heads": 32,"num_hidden_layers": 32,"num_key_value_heads": 8,"pretraining_tp": 1,"rms_norm_eps": 1e-05,"rope_scaling": null,"rope_theta": 500000.0,"tie_word_embeddings": false,"torch_dtype": "bfloat16","transformers_version": "4.55.0","use_cache": true,"vocab_size": 128256
}[INFO|2025-08-10 18:32:01] tokenization_utils_base.py:2393 >> chat template saved in saves/Llama-3-8B-Instruct/lora/train_2025-08-10-17-35-45/checkpoint-310/chat_template.jinja
[INFO|2025-08-10 18:32:01] tokenization_utils_base.py:2562 >> tokenizer config file saved in saves/Llama-3-8B-Instruct/lora/train_2025-08-10-17-35-45/checkpoint-310/tokenizer_config.json
[INFO|2025-08-10 18:32:01] tokenization_utils_base.py:2571 >> Special tokens file saved in saves/Llama-3-8B-Instruct/lora/train_2025-08-10-17-35-45/checkpoint-310/special_tokens_map.json
[INFO|2025-08-10 18:32:01] trainer.py:2718 >> Training completed. Do not forget to share your model on huggingface.co/models =)[INFO|2025-08-10 18:32:01] trainer.py:4074 >> Saving model checkpoint to saves/Llama-3-8B-Instruct/lora/train_2025-08-10-17-35-45
[INFO|2025-08-10 18:32:01] configuration_utils.py:750 >> loading configuration file /root/autodl-tmp/models/Llama3-8B-Chinese-Chat1/config.json
[INFO|2025-08-10 18:32:01] configuration_utils.py:817 >> Model config LlamaConfig {"architectures": ["LlamaForCausalLM"],"attention_bias": false,"attention_dropout": 0.0,"bos_token_id": 128000,"eos_token_id": 128009,"head_dim": 128,"hidden_act": "silu","hidden_size": 4096,"initializer_range": 0.02,"intermediate_size": 14336,"max_position_embeddings": 8192,"mlp_bias": false,"model_type": "llama","num_attention_heads": 32,"num_hidden_layers": 32,"num_key_value_heads": 8,"pretraining_tp": 1,"rms_norm_eps": 1e-05,"rope_scaling": null,"rope_theta": 500000.0,"tie_word_embeddings": false,"torch_dtype": "bfloat16","transformers_version": "4.55.0","use_cache": true,"vocab_size": 128256
}[INFO|2025-08-10 18:32:01] tokenization_utils_base.py:2393 >> chat template saved in saves/Llama-3-8B-Instruct/lora/train_2025-08-10-17-35-45/chat_template.jinja
[INFO|2025-08-10 18:32:01] tokenization_utils_base.py:2562 >> tokenizer config file saved in saves/Llama-3-8B-Instruct/lora/train_2025-08-10-17-35-45/tokenizer_config.json
[INFO|2025-08-10 18:32:01] tokenization_utils_base.py:2571 >> Special tokens file saved in saves/Llama-3-8B-Instruct/lora/train_2025-08-10-17-35-45/special_tokens_map.json
[WARNING|2025-08-10 18:32:02] logging.py:148 >> No metric eval_accuracy to plot.
[INFO|2025-08-10 18:32:02] trainer.py:4408 >>
***** Running Evaluation *****
[INFO|2025-08-10 18:32:02] trainer.py:4410 >> Num examples = 10
[INFO|2025-08-10 18:32:02] trainer.py:4413 >> Batch size = 2
[INFO|2025-08-10 18:32:04] modelcard.py:456 >> Dropping the following result as it does not have all the necessary fields:
{'task': {'name': 'Causal Language Modeling', 'type': 'text-generation'}}
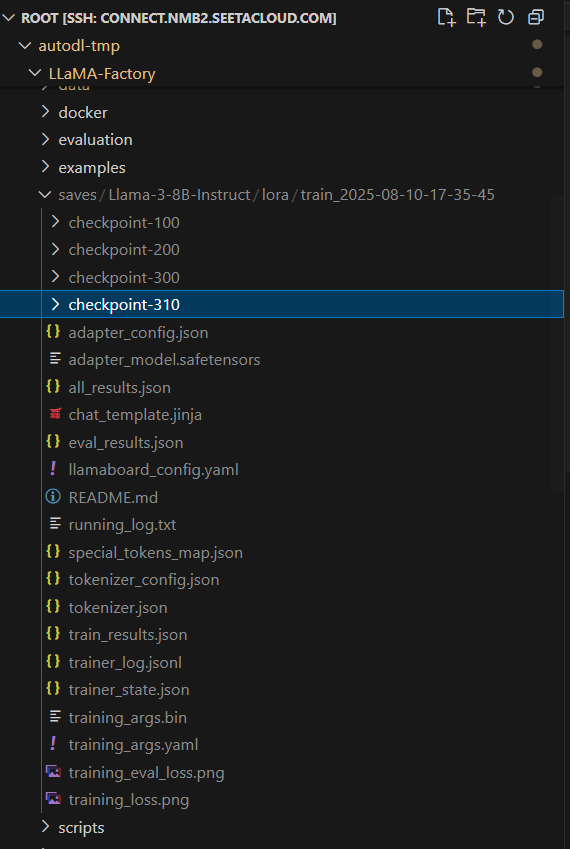
- 训练完成
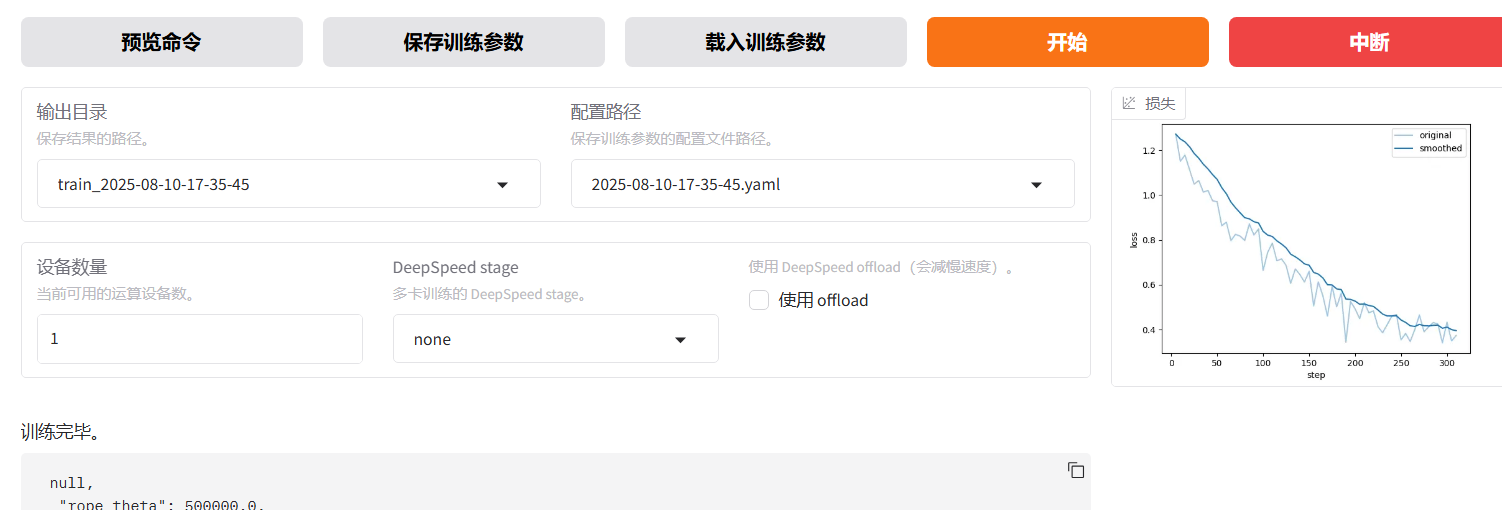
- 训练结果
- 训练后,内存自动被释放



路由策略)



)
)







![[论文阅读] 人工智能 + 软件工程 | LLM协作新突破:用多智能体强化学习实现高效协同——解析MAGRPO算法](http://pic.xiahunao.cn/[论文阅读] 人工智能 + 软件工程 | LLM协作新突破:用多智能体强化学习实现高效协同——解析MAGRPO算法)


