定义解释
Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera,Edge等。这个工具的主要功能包括:测试与浏览器的兼容性——测试应用程序看是否能够很好地工作在不同浏览器和操作系统之上。测试系统功能——创建回归测试检验软件功能和用户需求。支持自动录制动作和自动生成.Net、Java、Perl等不同语言的测试脚本。
selenium 运行效果
chrome 浏览器的运行效果
安装好 selenium 模块后,运行下面代码
from selenium import webdriver
driver = webdriver.Chrome()
#向一个url发起请求
driver.get("http://www.python.org")
#打印页面标题
print(driver.title)
#退出模拟器 不退出会残留进程
driver.quit()

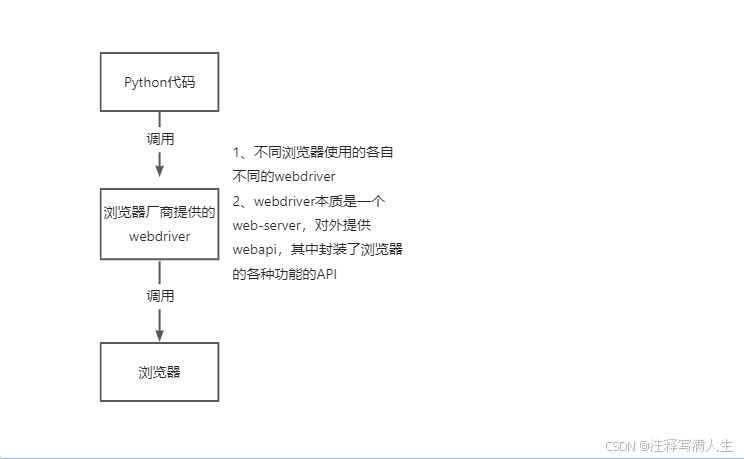
selenium的作用和工作原理
利用浏览器原生的 API,封装成一套更加面向对象的 Selenium web Driver API,直接操作浏览器页面里的元素,甚至操作浏览器本生(截屏、窗口大小、关闭、安装插件、配置证书等)
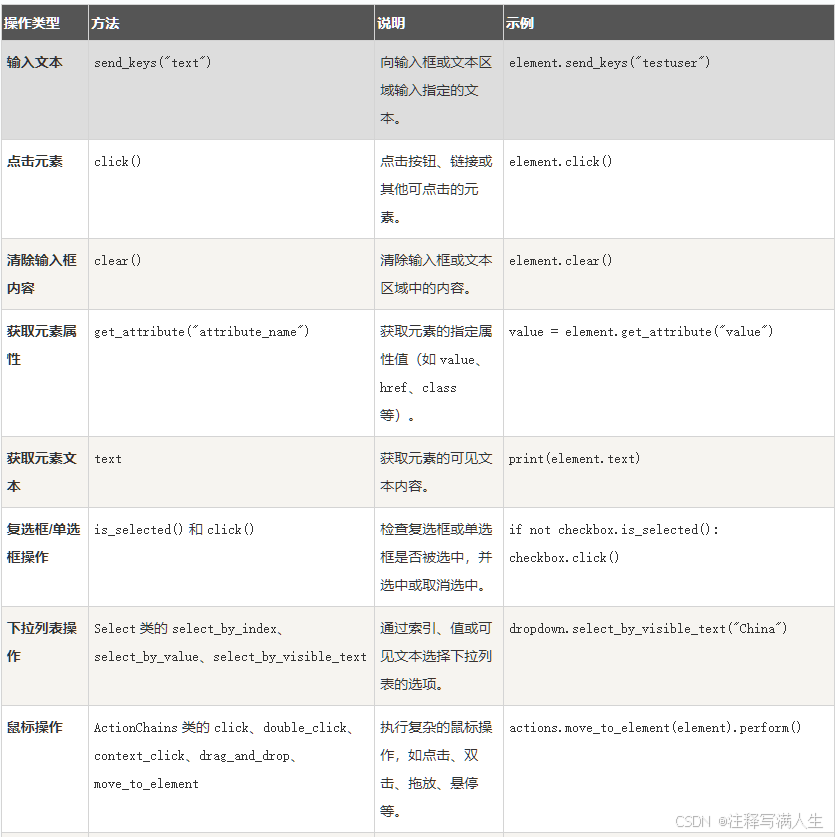
selenium 的简单使用
from selenium import webdriver
from selenium.webdriver.common.by import Bydriver = webdriver.Chrome()
#控制浏览器访问url地址
driver.get("http://www.baidu.com")
#在百度中搜索python
driver.find_element(By.ID, "kw").send_keys("python")
#点击百度搜索
driver.find_element(By.ID, "su").click()
print(driver.current_url)
#退出浏览器
driver.quit()
运行打印出当前 url:https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=python&fenlei=256&rsv_pq=0xe86c7938000744b9&rsv_t=2ebfD821B8kkLpalpk%2B8V8BJXURm5E5QmGKnhK5amkSt2VBud92sYJFn9Xkt&rqlang=en&rsv_enter=0&rsv_dl=tb&rsv_sug3=6&rsv_sug1=1&rsv_sug7=100&rsv_btype=i&inputT=422&rsv_sug4=422
webdriver.Chrome(executable_path=‘./chromedriver’)中executable参数指定的是下载好的chromedriver文件的路径
driver.find_element(By.ID, “kw”).send_keys(“python”)定位id属性值是’kw’的标签,并向其中输入字符串’python’
driver.find_element(By.ID, “su”).click()定位id属性值是su的标签,并点击
click函数作用是:触发标签的js的click事件
selenium 提取数据
driver 对象的常用属性和方法
- driver.page_source 当前标签页浏览器渲染之后的网页源代码
- driver.current_url 当前标签页的url
- driver.close() 关闭当前标签页,如果只有一个标签页则关闭整个浏览器
- driver.quit() 关闭浏览器
- driver.forward() 页面前进
- driver.back() 页面后退
- driver.screen_shot(img_name) 页面截图
driver对象定位标签元素获取标签对象的方法
- find_element(By.TAG_NAME, “tag_name”) 通过元素的标签名定位(如 、 等)
- find_element(By.CSS_SELECTOR, “css_selector”) 通过 CSS 选择器定位元素
- find_element(By.NAME, “name_value”) 通过元素的 name 属性定位
- find_element(By.CLASS_NAME, “class_name”) 通过元素的 class 属性定位
- find_element(By.TAG_NAME, “tag_name”) 通过元素的标签名定位(如 、 等)
- find_element(By.XPATH, “xpath_expression”) 通过 XPath 表达式定位元素
- find_element(By.LINK_TEXT, “link_text”) 通过链接的文本内容定位(适用于 标签)
- find_element(By.PARTIAL_LINK_TEXT, “partial_link_text”) 通过链接的部分文本内容定位
注意:
- find_element和find_elements的区别:
- 多了个s就返回列表,没有s就返回匹配到的第一个标签对象
- find_element匹配不到就抛出异常,find_elements匹配不到就返回空列表
- by_link_text和by_partial_link_tex的区别:全部文本和包含某个文本
- 以上函数的使用方法
- driver.find_element_by_id(‘id_str’)
标签对象提取文本内容和属性值

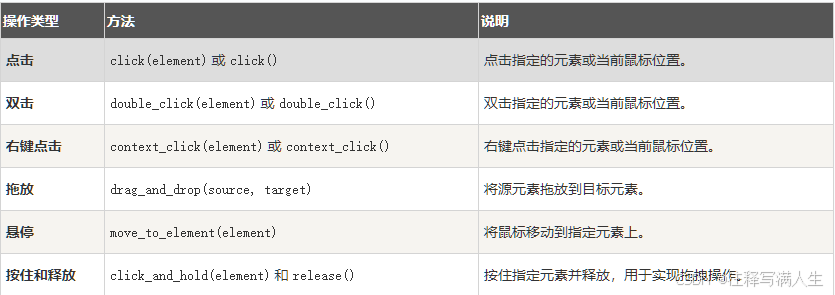
selenium 鼠标和键盘操作
鼠标操作
键盘操作
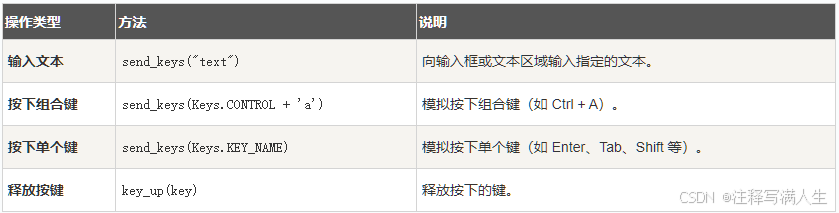 #### 常用键盘键值
#### 常用键盘键值
在这里插入图片描述
selenium 的其他使用方法
selenium 标签页的切换
当 selenium 控制浏览器打开多个标签页时,如何控制浏览器在多个标签页之间进行切换?分两步处理
- 获取所有标签页的窗口权柄
- 利用窗口权柄字切换到权柄指向标签页对象的标识
- 这里的窗口权柄是指:标签页对象的标识
#1、获取当前所有的标签页的权柄构成的列表
current_windows = driver.window_handles
#2、根据标签页权柄列表索引下标进行切换
driver.switch_to.window(current_windows[0])
测试示例
import time
from selenium import webdriver
from selenium.webdriver.common.by import Bydriver = webdriver.Chrome()
driver.get("http://www.baidu.com")time.sleep(1)
driver.find_element(By.ID, "kw").send_keys("python")
time.sleep(1)
driver.find_element(By.ID, "su").click()
time.sleep(1)#通过执行js来新开一个标签页
js = 'window.open("http://www.sougou.com");'
driver.execute_script(js)
time.sleep(1)#获取当前全部窗口
current_windows = driver.window_handles
time.sleep(2)#根据窗口索引进行切换
driver.switch_to.window(current_windows[0])
time.sleep(2)
driver.switch_to.window(current_windows[1])time.sleep(6)
driver.quit()
switch_to 切换 frame 标签
iframe 是嵌入在网页中的另一个网页。Selenium 提供了 <font style="color:rgb(51, 51, 51);background-color:rgb(250, 252, 253);">switch_to.frame()</font> 方法来切换到 iframe。
import time
from selenium import webdriver
from selenium.webdriver.common.by import Bydriver = webdriver.Chrome()
url = 'https://wx.mail.qq.com/?cancel_login=true&from=get_ticket_fail'
driver.get(url)login_frame = driver.find_element(By.ID,'iframe_wx')
driver.switch_to.frame(login_frame)
print(driver.title)
"""操作frame外边的元素需要切换出去"""
windows = driver.window_handles
driver.switch_to.window(windows[0])content = driver.find_element(By.CLASS_NAME,'login_pictures_title').text
print(content)driver.quit()
- 总结:
- 切换到定位的frame标签嵌套的页面中
driver.switch_to.frame(通过find_element_by函数定位的frame、iframe标签对象)
- 利用切换标签页的方式切出frame标签
- 切换到定位的frame标签嵌套的页面中
windows = driver.window_handles
driver.switch_to.window(windows[0])
selnium 对 cookie 的处理
Selenium 提供了get_cookies()、add_cookie()、delete_cookie()等方法来操作浏览器的 Cookies。
获取 cookie
driver.get_cookies()返回列表,其中包含的是完整的cookie信息!不光有name、value,还有domain等cookie其他维度的信息。所以如果想要把获取的cookie信息和requests模块配合使用的话,需要转换为name、value作为键值对的cookie字典
#获取当前标签页的全部cookie信息
print(driver.get_cookies())
#把cookie转化为字典
cookies_dict = {cookie[‘name’]: cookie[‘value’] for cookie in driver.get_cookies()}
添加 cookie
# 添加 Cookie
driver.add_cookie({"name": "test", "value": "123"})# 获取所有 Cookies
cookies = driver.get_cookies()
删除 cookie
#删除一条cookie
driver.delete_cookie("CookieName")# 删除所有的cookie
driver.delete_all_cookies()
执行 js 代码
Selenium 提供了 `execute_script()方法来执行 JavaScript 代码。
import time
from selenium import webdriverdriver = webdriver.Chrome()
driver.get("http://www.python.org")
time.sleep(1)js = 'window.scrollTo(0, document.body.scrollHeight);'
driver.execute_script(js)time.sleep(5)
driver.quit()
页面等待
在 Selenium 中,等待机制是确保页面元素加载完成后再进行操作的关键。
由于网页加载速度受网络、服务器性能等因素影响,直接操作未加载完成的元素会导致脚本失败。
Selenium 提供了多种等待机制来解决这一问题。
- 隐式等待
- 显示等待
- 固定等待
- fluent wait
隐式等待
隐式等待是一种全局性的等待机制,它会在查找元素时等待一定的时间。如果在指定的时间内找到了元素,Selenium 会立即继续执行后续操作;如果超时仍未找到元素,则会抛出 NoSuchElementException异常。
import time
from selenium import webdriverdriver = webdriver.Chrome()
#设置隐式等待时间为10秒
driver.implicitly_wait(10)
driver.get("http://www.baidu.com")
print(driver.title)
driver.quit()
- 优点:
- 简单易用,只需设置一次即可应用于所有元素的查找操作
- 适用于大多数简单的场景
- 缺点:
- 全局性等待,可能会导致不必要的等待时间
- 无法处理某些负责的等待条件,例如等待元素变为可点击状态。
显示等待
显式等待是一种更为灵活的等待机制,它允许你为特定的操作设置等待条件。显式等待通常与WebDriverWait类和expected_conditions模块一起使用。
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.support.wait import WebDriverWaitdriver = webdriver.Chrome()
driver.get("http://www.baidu.com")
#设置显示等待,最多等待10秒,直到元素出现
element = WebDriverWait(driver, 10).until(expected_conditions.presence_of_element_located(By.TAG_NAME,'a'))
driver.quit()
常用的 expected_conditions
expected_conditions 模块提供了多种预定义的等待条件,以下是一些常用的条件:
presence_of_element_located:等待元素出现在 DOM 中。
visibility_of_element_located:等待元素出现在 DOM 中并且可见。
element_to_be_clickable:等待元素可点击。
text_to_be_present_in_element:等待元素的文本包含指定的文本。
优点:
- 灵活性高,可以为不同的操作设置不同的等待条件。
- 可以处理复杂的等待场景。
缺点:
- 代码相对复杂,需要更多的代码量。
- 需要为每个操作单独设置等待条件。
固定等待
固定等待是一种最简单的等待机制,它通过time.sleep()方法让脚本暂停执行指定的时间。无论页面是否加载完成,脚本都会等待指定的时间后再继续执行。
import time
from selenium import webdriverdriver = webdriver.Chrome()
driver.get("http://www.baidu.com")
#固定等待5秒
time.sleep(5)
print(driver.title)
driver.quit()
优点:
- 简单易用,适用于简单的测试场景。
缺点:
- 效率低下,可能会导致不必要的等待时间。
- 无法根据页面加载情况动态调整等待时间。
Fluent Wait
作用:动态设置等待条件,可以自定义轮询频率和忽略特定异常。
方法:WebDriverWait 结合 polling_every 和 ignoring
特点:更灵活,适用于需要动态调整等待时间的场景。
import time
from selenium import webdriver
from selenium.common import TimeoutException
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.support.wait import WebDriverWaitdriver = webdriver.Chrome()
driver.get("http://www.baidu.com")
#设置fluent wait
wait = WebDriverWait(driver, timeout=10,poll_frequency=1,ignored_exceptions=[TimeoutException]).until(expected_conditions.presence_of_element_located(By.ID, "username")
)
driver.quit()
总结
- 隐式等待:适用于简单的场景,全局性等待,但可能会导致不必要的等待时间。
- 显式等待:适用于复杂的场景,灵活性高,但代码相对复杂。
- 固定等待:简单易用,但效率低下,不推荐在复杂的测试场景中使用。
- Fluent Wait::适用于需要动态调整等待时间的场景。
selenium 开启无界面模式
绝大多数服务器是没有界面的,selenium控制谷歌浏览器也是存在无界面模式的。
- 开启无界面模式的方法
- 实例化配置对象
options = webdriver.ChromeOptions()
- 配置对象添加开启无界面模式的命令
options.add_argument("--headless")
- 配置对象添加禁用gpu的命令
options.add_argument("--disable-gpu")
- 实例化带有配置对象的driver对象
driver = webdriver.Chrome(chrome_options=options)
- 实例化配置对象
import time
from selenium import webdriver
options = webdriver.ChromeOptions() #创建一个配置对象
options.add_argument('--headless') #开启无界面模式
options.add_argument('--disable-gpu') # 禁用gpu
# options.set_headles() # 无界面模式的另外一种开启方式
driver = webdriver.Chrome(options) #实例化带有配置的driver对象
driver.get("http://www.baidu.com")
print(driver.title)
driver.quit()
selenium 使用代理 IP
selenium控制浏览器也是可以使用代理ip的!
- 使用代理ip的方法
- 实例化配置对象
options = webdriver.ChromeOptions()
- 配置对象添加使用代理ip的命令
options.add_argument('--proxy-server=http://202.20.16.82:9527')
- 实例化带有配置对象的driver对象
driver = webdriver.Chrome('./chromedriver', chrome_options=options)
- 实例化配置对象
import time
from selenium import webdriver
options = webdriver.ChromeOptions() #创建一个配置对象
options.add_argument('--proxy-server=http://172.16.31.10:3128') #使用待遇ip
driver = webdriver.Chrome(options) #实例化带有配置的driver对象
driver.get("http://www.baidu.com")
print(driver.title)
driver.quit()
selenium 替换 user-agent
selenium控制谷歌浏览器时,User-Agent默认是谷歌浏览器的,但是这个值是可以修改的。
- 替换user-agent的方法
- 实例化配置对象
options = webdriver.ChromeOptions()
- 配置对象添加替换UA的命令
options.add_argument('--user-agent=Mozilla/5.0 HAHA')
- 实例化带有配置对象的driver对象
driver = webdriver.Chrome('./chromedriver', chrome_options=options)
- 实例化配置对象
import time
from selenium import webdriver
options = webdriver.ChromeOptions() #创建一个配置对象
options.add_argument('--user-agent=Mozilla/5.0') #替换User-agent
driver = webdriver.Chrome(options) #实例化带有配置的driver对象
driver.get("http://www.itcast.cn")
print(driver.title)
driver.quit()











行为型:备忘录模式详解)




 的解决方案)


