一.sed是啥
sed(流编辑器,Stream Editor)是 Unix/Linux 系统中强大的文本处理工具,常用于对文本进行替换、删除、插入、追加等操作。它逐行处理输入文本,并根据提供的脚本命令修改文本,最后输出结果。
二.基本操作
1.修改操作
(1)对整个文本进行修改
sed "s/-year/years" people.txt 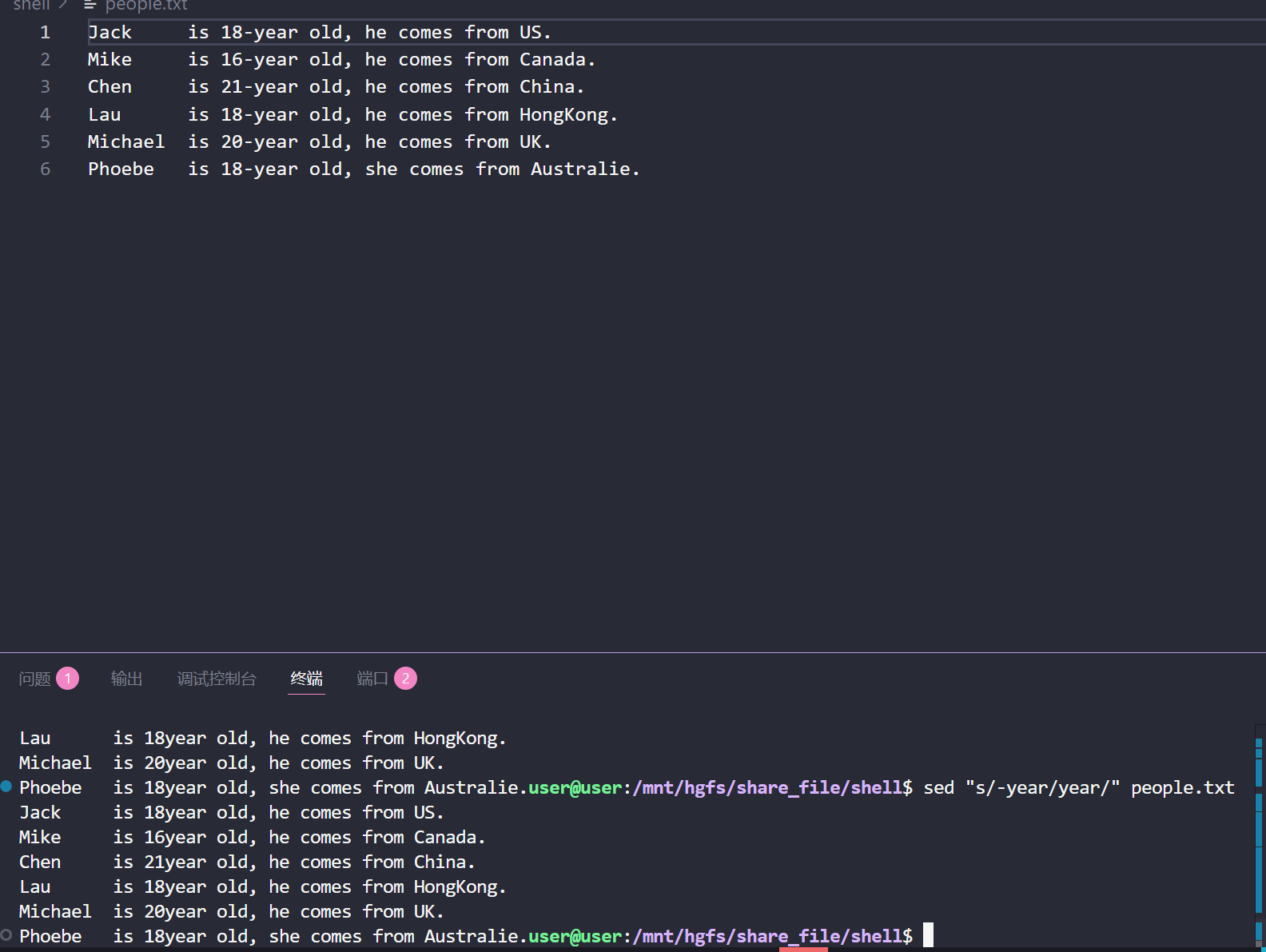
(2)对文本指定行号进行修改
sed "2s/-year/years/" people.txt 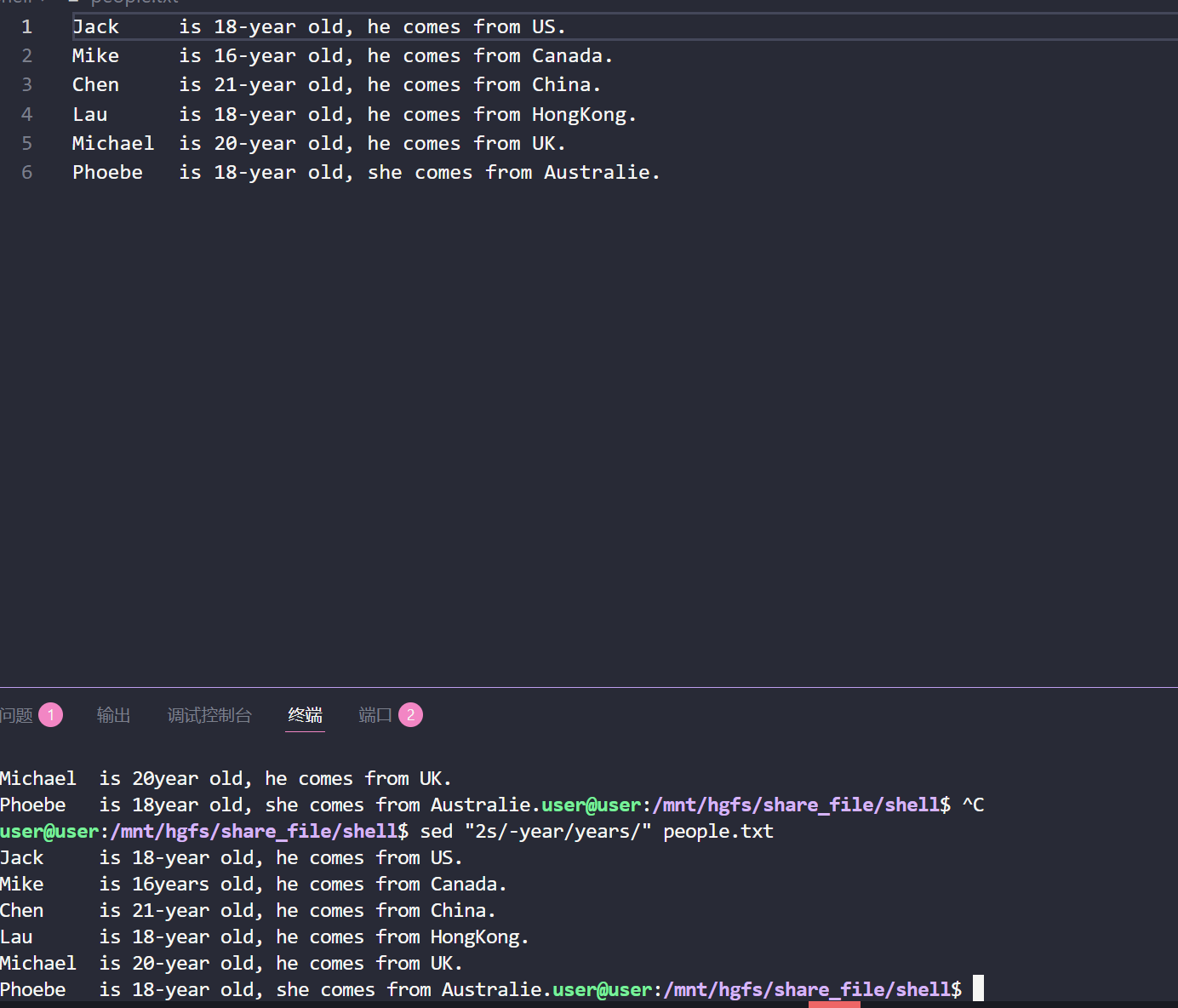
(3)对2到5行进行修改
sed "2,5s/-year/years/" people.txt 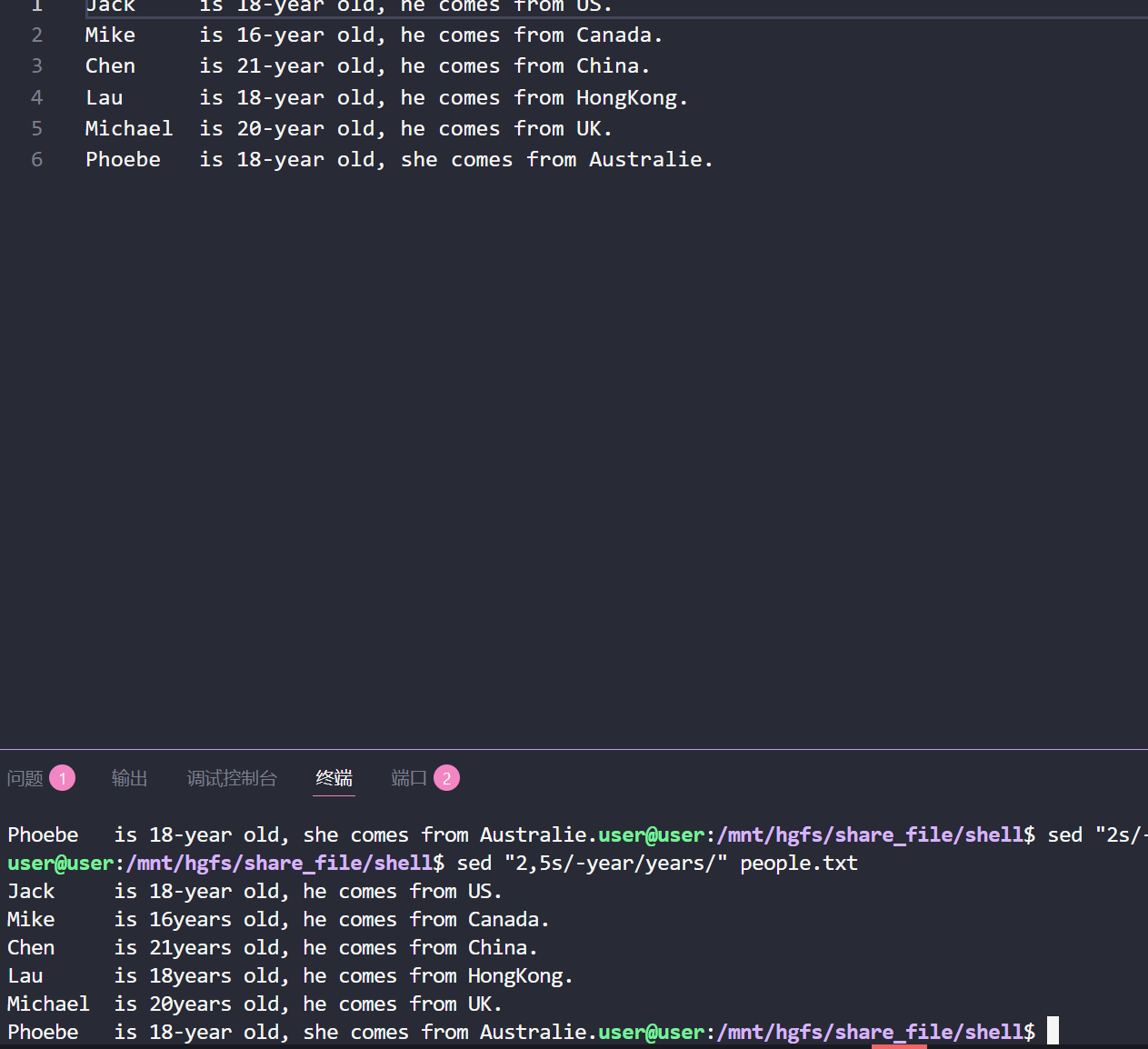
(4)直接对原文进行修改加上-i
sed "2,5s/-year/years/" people.txt -i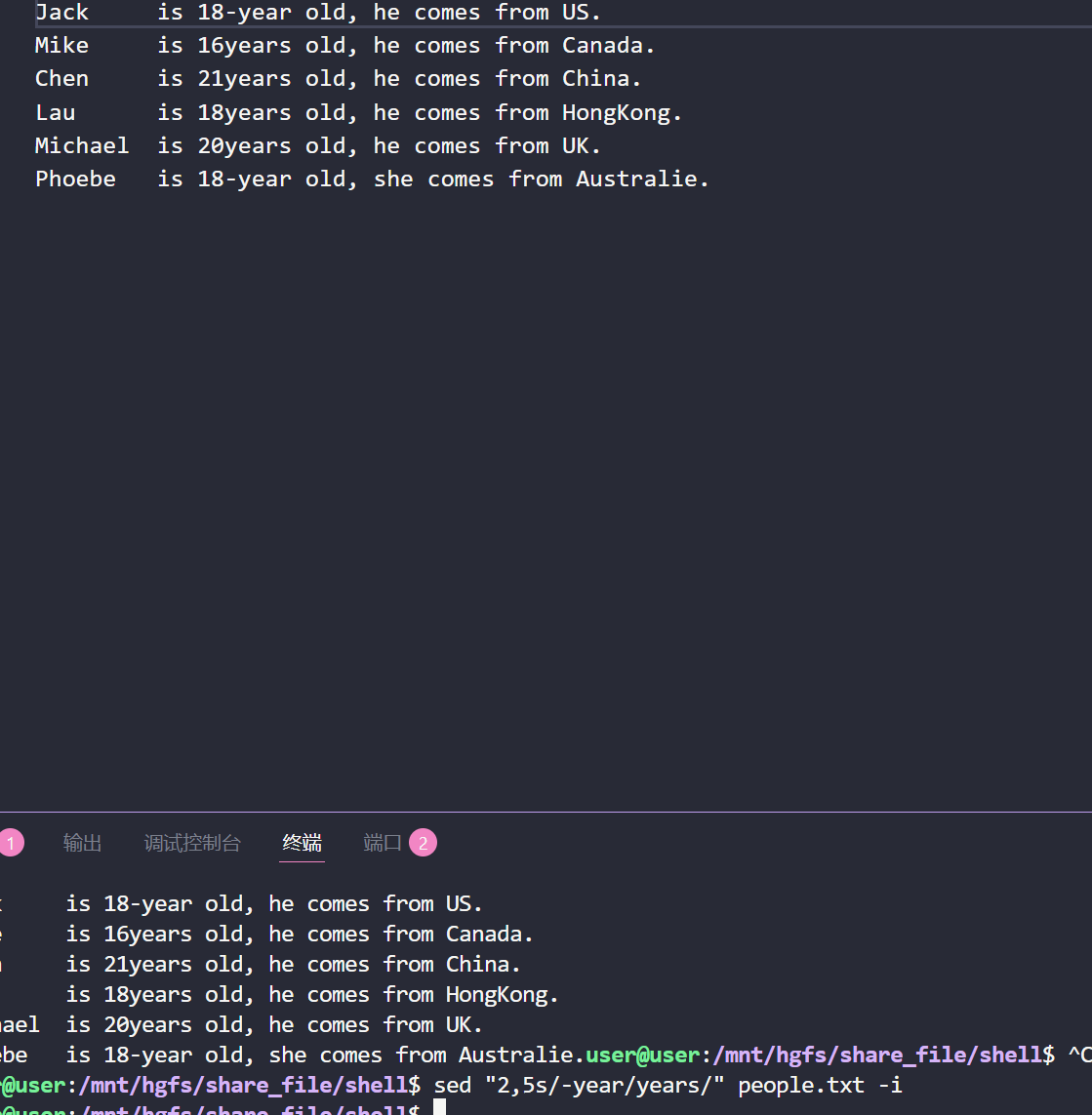
(5)替换每一行中的所有的小写 s 成大写 S:
sed "s/s/S/g" people.txt注意:g 的意思是一行中所有的匹配项,否则缺省只会匹配第一个 s
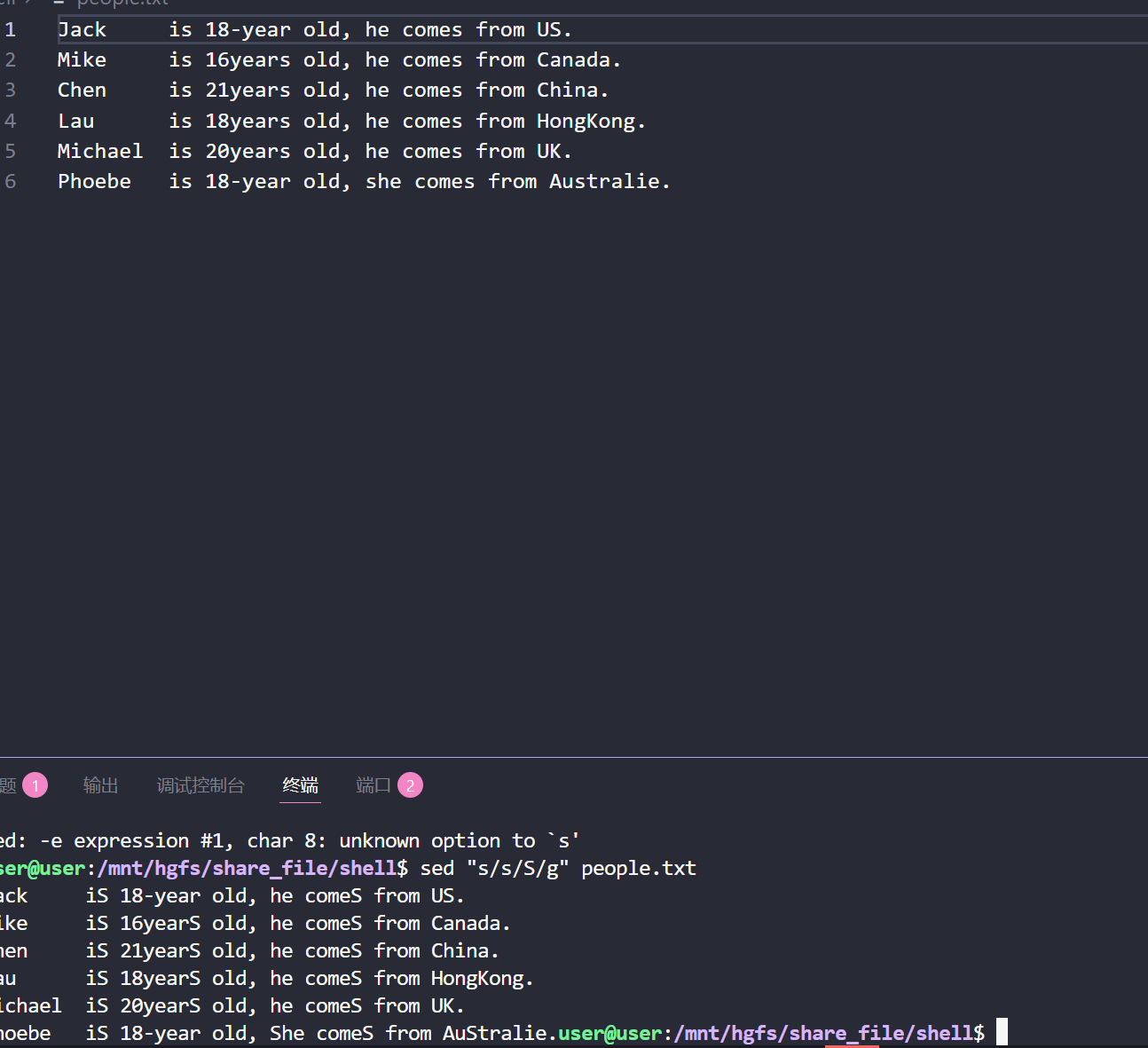
(6)替换每一行中的第 2 个小写 s 成大写 1:
sed "s/s/1/2" people.txt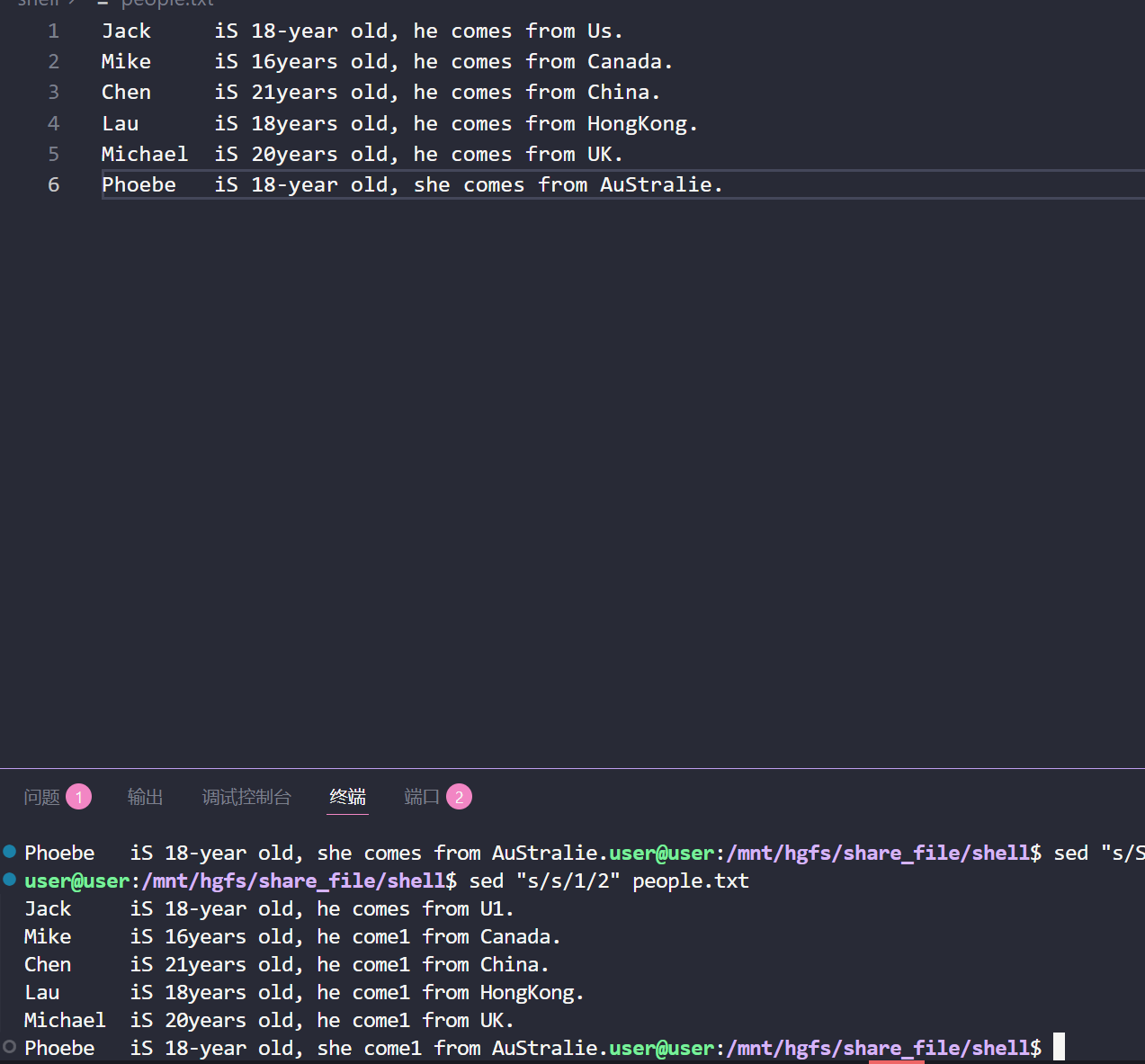
(7)替换每一行中的第 2 个以后的小写 s 成大写 1:
sed "s/s/1/2g" people.txt 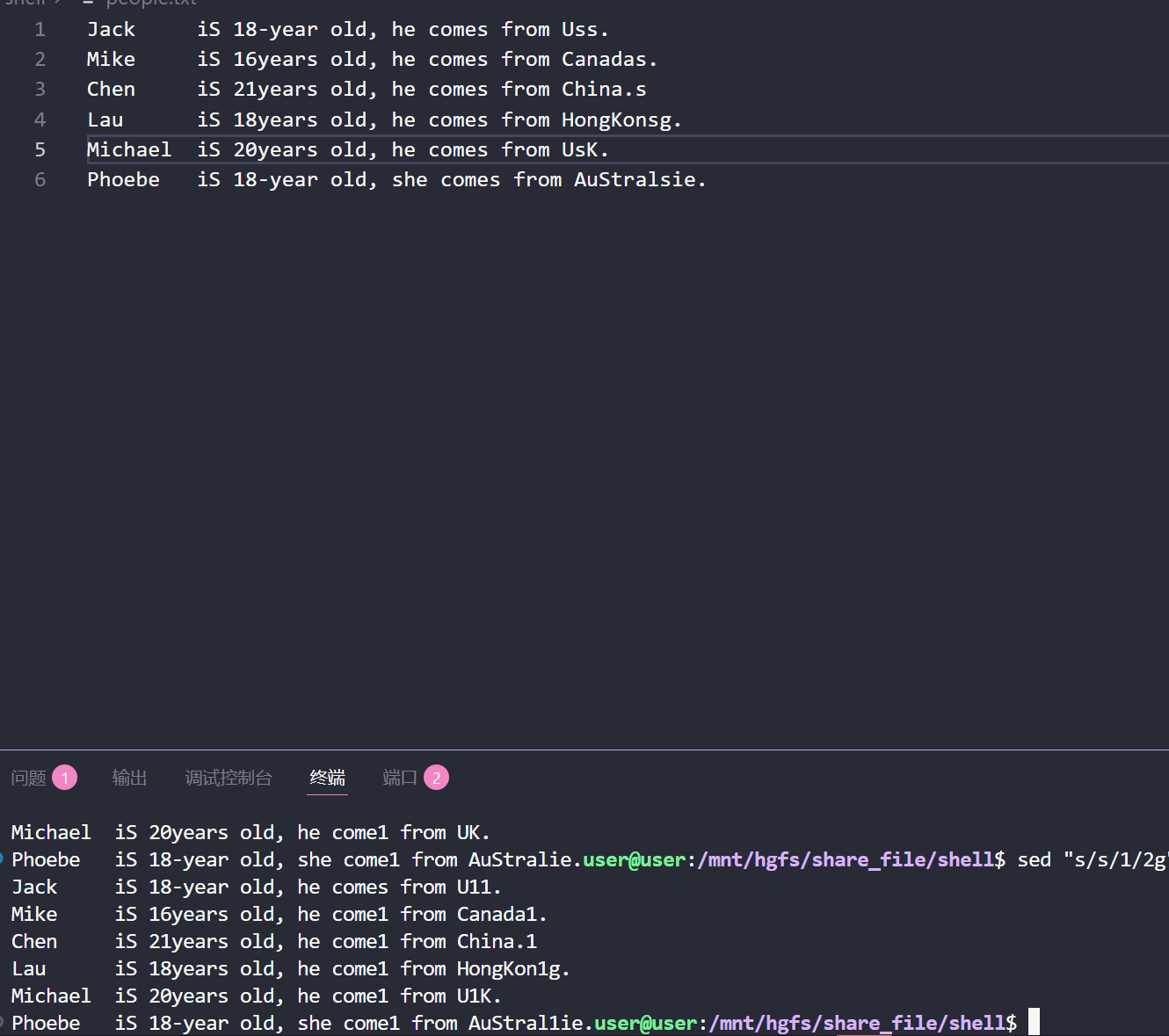
2.多个匹配
(1)将 "-year" 改成 "years",并且将第 3 行以后的最后一个任意字符去掉:
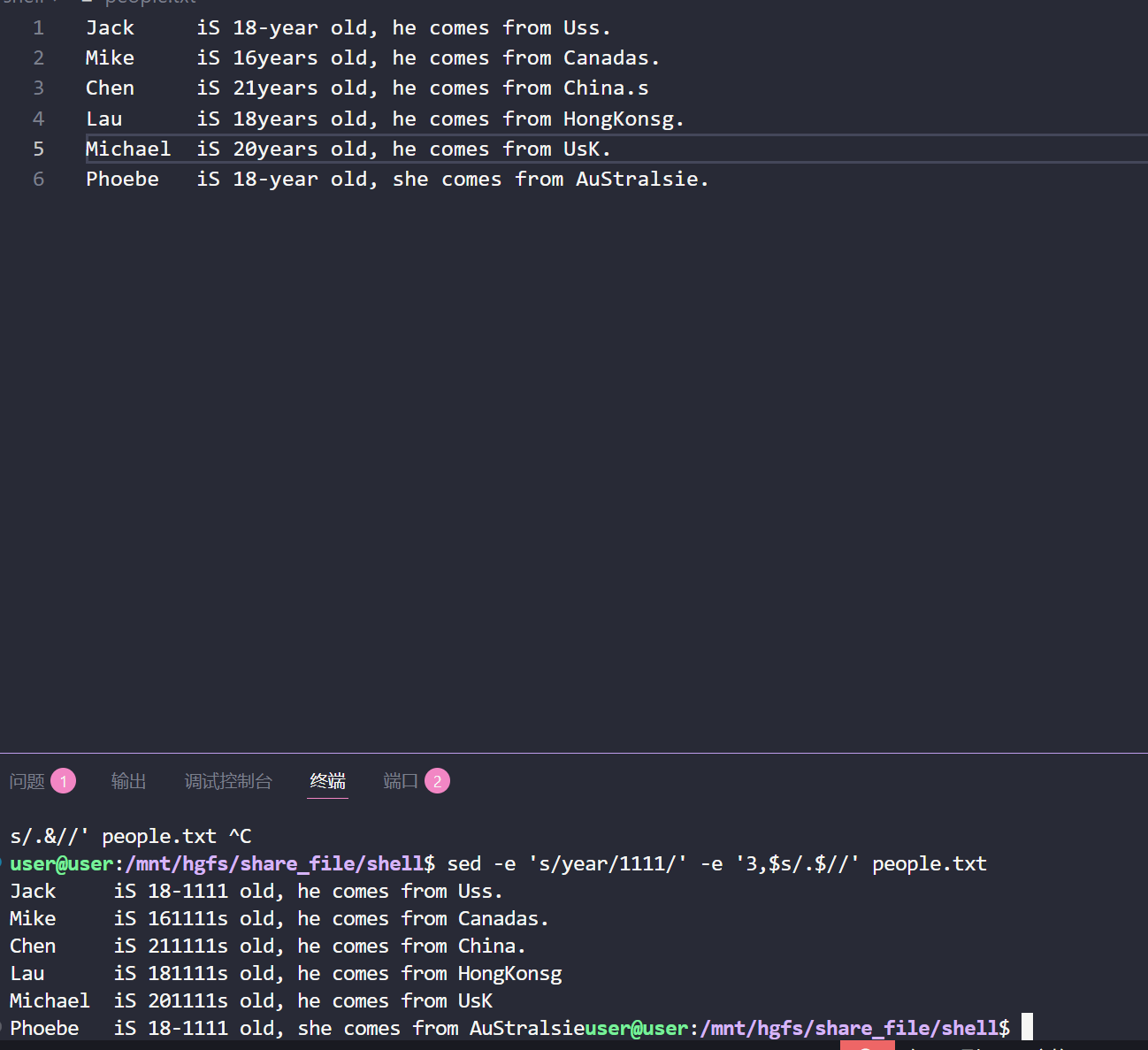
在
sed命令里,3,$s/.$//是一段用于文本处理的规则,下面这就拆分成几个部分,给你详细讲讲每个符号的含义:1. 行范围:
3,$
3代表第 3 行,$在sed里是一个特殊符号,专门用来表示最后一行。- 把它们用
,连起来3,$,整体的意思就是 “从第 3 行开始,一直到文件的最后一行” 。也就是说,下面的替换操作(s/.$//)会作用在这个范围内的每一行文本上。2. 替换语法:
s/原内容/新内容/这是
sed里最常用的替换操作格式,s就是 “substitute(替换)” 的意思,整个结构就是告诉sed:找到 “原内容”,把它换成 “新内容” 。3. 匹配规则:
.$
.是正则表达式里的元字符,代表任意一个单个字符(像字母、数字、标点符号这些,除了换行符一般都能匹配)。$前面讲过,是行尾的意思。把它们放一起.$,就是说要匹配行末尾的那一个任意字符 。打个比方,要是一行文本是abcde.,那这里的.(行末尾的那个点)就会被.$匹配到;要是文本是abcde,那最后一个字符e会被匹配。4. 替换为空:
//
sed替换语法里,/是用来分隔 “原内容” 和 “新内容” 的。这里 “新内容” 的位置是空的(两个/紧挨着),意思就是把前面.$匹配到的内容(行末尾最后一个字符 )替换成空字符串,说白了就是把行末尾最后一个字符删掉 。
注意:
*在单引号里面,元义字符可以直接使用,如果要去掉元义则要在前面加 \;在双引号里面,sed 的命令要使用元义,则需要加 \,而命令的正则表达式要使用元义直接使用就行。
*在
sed命令中,-e选项用于指定多个编辑命令,允许在一次sed执行中组合多个操作。
(2)将 & 代替被匹配的变量:
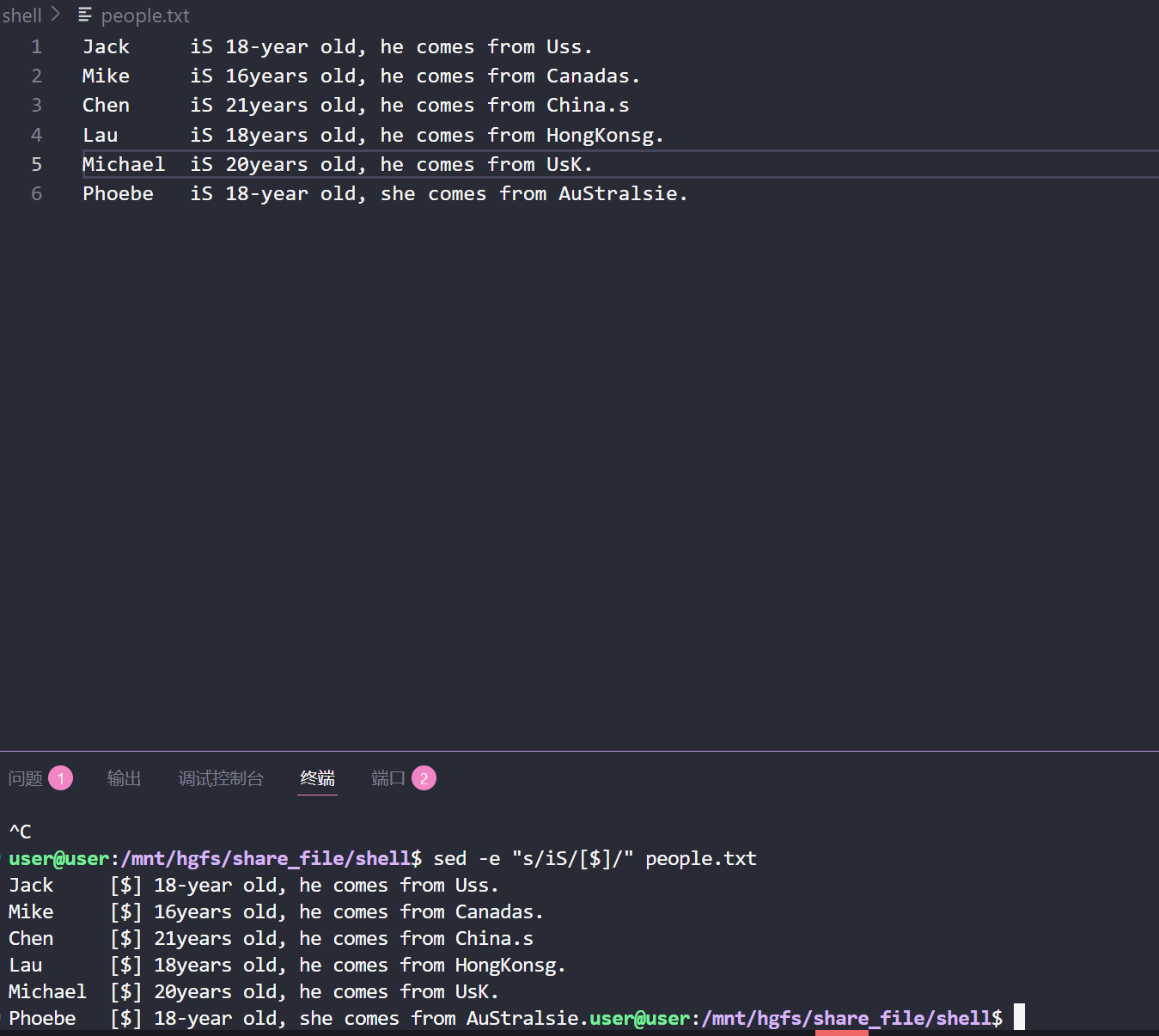
sed -e "s/iS/[$]/" people.txt 将文本中每一行出现的第一个 is 的左右两边加上 [ ]
(3)在指定行的前面插入 (i) 或者后面插入 (a) 一些信息:
sed ’3i abcd’ people.txt 意思是 ==> 在第 3 行的前面插入 abcd
sed ’2a abcd’ people.txt 意思是 ==> 在第 2 行的后面插入 abcd
sed ’1,4a abcd’ people.txt 意思是 ==> 在第 1 至 4 行的后面分别插入 abcd
sed ’/US/a abcd’ people.txt 意思是 ==> 在匹配 US 的行的后面插入 abcd
(4)将指定的行替换成其他信息:
sed "2c ok" people.txt 意思是 ==> 将第 2 行替换成 ok
(5)将指定的行删除掉:
sed ‘2d’ people.txt 意思是 ==> 将第 2 行给删掉
sed ‘/US/d’ people.txt 意思是 ==> 将匹配 / US / 的所有行给删掉
sed ’/<he>/d’ people.txt 意思是 ==> 将匹 配 he 的所有行给删掉,注意:之所以要用 <> 将 he 给括起来,是因为不想匹配 she,当然,<> 需要转义,写成 <>
(6)打印指定匹配的行,用命令 p:
sed ’/Chen/p’ people.txt -n 意思是 ==> 打印匹配 Chen 的行
sed ’/Chen/, /Lau/p’ people.txt -n 意思是 ==> 打印匹配 Chen 或者 Lau 的行
sed ’3,/UK/p’ people.txt -n 意思是 ==> 从第 3 行开始打印,直到匹配 UK 为止
sed ’/UK/,6p’ people.txt -n 意思是 ==> 从匹配 UK 的行开始打印,直到第 6 行为止
3.总结:
3.5 3代表开始5代表结束
& 代表he匹配的字符串
/A/ A为需要匹配的字符串
// 清空
s/A/a/ 替换
i 前面插入
a 后面插入
d 删除
p 打印
在正则表达式中 <> | {} () +若是单引号不需要加上\,双引号需要加上\










)








