目录
一、数据编排的定义与概念
1.数据编排的基本含义
2.数据编排与相关概念的区别
3.数据编排的重要性
二、数据编排的流程
1.需求分析:
2.数据源识别与连接:
3.数据抽取:
4.数据转换:
5.数据加载:
6.监控与优化:
三、数据编排的优势
四、数据编排面临的挑战
五、数据编排的工具
总结
Q&A常见问答
现在企业里数据量日益增多,但往往东一块西一块,散落在各处。想把这些数据真正用起来,变成对业务有用的东西,就得靠数据编排。说白了,数据编排就是把数据的来龙去脉管起来,让数据能顺利地流到需要它的地方。今天咱就聊聊,数据编排到底是个啥,它具体怎么干、有啥好处、会遇到哪些坎儿,以及市面上有啥趁手的工具。
文中示例数据编排工具>>>免费试用FDL
一、数据编排的定义与概念
1.数据编排的基本含义
简单来说,数据编排就是对数据的“一生”做个规划和管理。从它出生(产生)的地方,到它发挥作用(被使用)的地方,中间怎么走、怎么变,都得安排好。核心就是:把散在四面八方的数据捞出来,按业务需要的规矩收拾干净、变个样,然后稳稳当当地送到该去的地方。整个过程得保证数据是准的、是及时的、是完整的,这样才能真正支撑企业做决定、跑业务。
2.数据编排与相关概念的区别
数据编排常跟数据集成、数据治理这些词放一起,但它们各有侧重。
- 数据集成:主要解决“合”的问题,把不同源头的数据拼到一块儿,让大家能看到个统一的样子。
- 数据编排:管得更宽,不光要“合”,还得管数据怎么“动”(抽取、转换、加载),怎么“管”(调度、监控),重点是数据流动的整个过程。
- 数据治理:站得更高,定规矩:数据质量咋保证、安全咋管、合规咋做。说白了,数据治理是定战略定规则,数据编排是落地执行的具体战术之一。数据编排是在数据治理的大框框下,把数据集成和价值挖掘做实的法子。
3.数据编排的重要性
现在企业搞数字化,数据又多又杂,源头五花八门。要是没个好的数据编排,数据就真成一盘散沙了,看着多,用不上。我一直强调,数据编排能帮你:
- 把散乱的数据管起来,让它真正能流动、能共享。
- 让业务部门及时拿到靠谱的数据做分析、做决策。
- 提升整个企业的运营效率和竞争力。听着是不是很熟?很多效率问题就卡在数据不通上。
二、数据编排的流程
数据编排不是一锤子买卖,是个有章法的持续过程:
1.需求分析:
这是打地基的一步。得跟业务部门坐一块儿,好好聊聊:你们到底要啥数据?拿它干啥用(做报表、做分析、做预测)?对数据的快慢(及时性)、准头(准确性)有啥具体要求?把目标搞清楚了,后面才知道劲儿往哪使。
2.数据源识别与连接:
知道要啥了,下一步就是找“粮仓”——数据在哪?可能是内部数据库(MySQL,Oracle)、文件服务器、云存储(S3,OSS),也可能是外部API。找到后,得用合适的技术(比如JDBC连数据库,API调用连服务)把它们稳稳当当地连上,确保能稳定、安全地拿到数据。

3.数据抽取:
连上了,就该把数据“搬”出来了。怎么搬?
- 全量抽:适合数据量不大、变化不多的情况,一次全搬出来。
- 增量抽:数据量大、变化快?那就只搬上次之后新加的、改动的部分,省时省力。用过来人的经验告诉你,增量抽是常态,但得解决好怎么精准识别“变化”这个技术点。
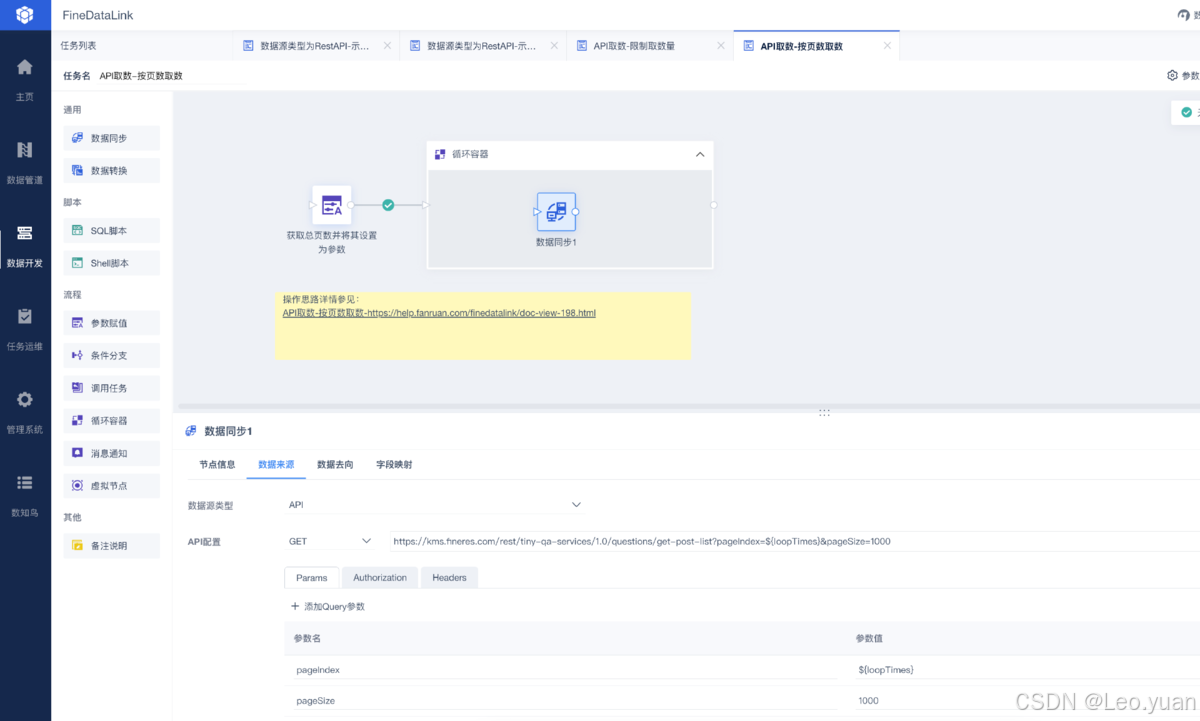
4.数据转换:
刚搬出来的“原料”数据,往往不能直接用,得“加工”:
- 清洗:把脏东西去掉——错的、重复的、缺胳膊少腿的(缺失值)。
- 整合:不同来源的数据,结构可能不一样,得把它们“对齐”、合并,弄成一个统一的、好用的样子。
- 计算/衍生:可能需要算点新东西出来,比如总和、平均值、增长率啥的。这一步的目标,就是把数据收拾成业务真正需要、能直接用的样子。
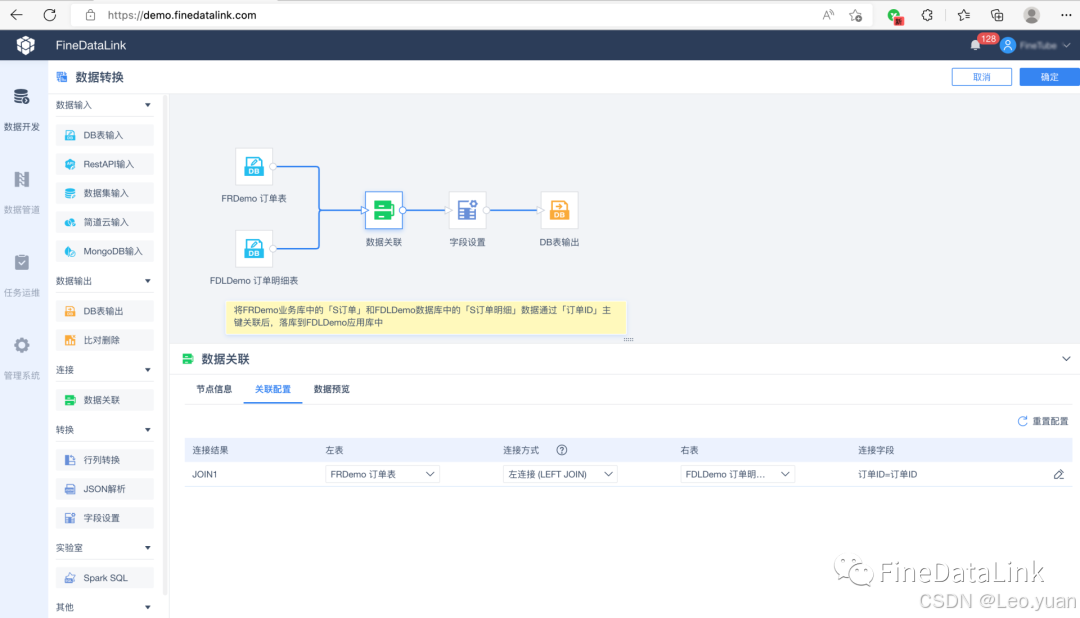
5.数据加载:
加工好的数据,得存到“目的地”——可能是数据仓库(像Hive,Redshift)、数据湖、或者直接给业务系统(BI平台、CRM系统)。加载时得考虑:
- 数据量多大?
- 业务需要多快看到新数据(实时?准实时?T+1?)
- 目标系统能不能扛住?选批量加载还是实时流式加载。
6.监控与优化:
流程跑起来不是终点。得盯着点:数据按时到了吗?量对不对?处理过程中出错没?性能咋样(会不会太慢)?根据监控到的情况,持续调优:改改配置、加加资源、优化下转换逻辑。数据编排是个动态活儿,得持续维护。
三、数据编排的优势
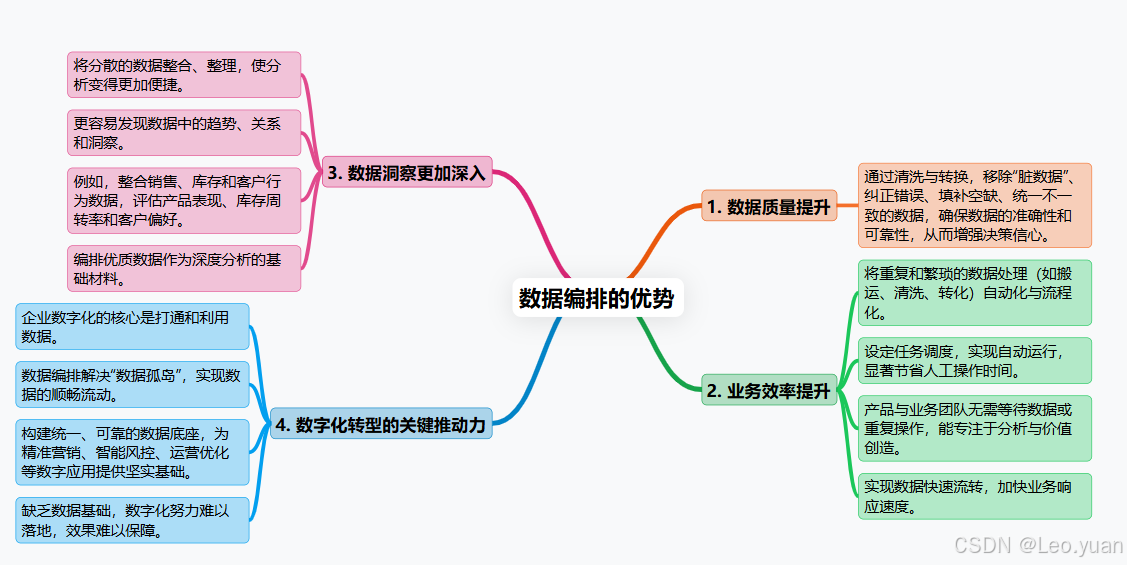
为啥要费劲搞数据编排?好处实实在在:
1.数据质量往上走:靠清洗、转换这些步骤,把数据里的“脏东西”筛掉,错误纠正,空缺补上,不一致的弄一致。数据干净了、准了,做决定心里才有底,不怕被错误数据带沟里。
2.业务效率提上来:把那些重复、繁琐的数据搬、洗、转的活儿自动化、流程化。设定好任务调度,到点自动跑,省下大量人工操作时间。业务人员不用等数据、折腾数据,能更专注在分析数据、创造价值上。数据流转更快,业务响应也能更及时。
3.数据洞察更透亮:把分散的数据规整到一起、收拾干净,分析起来才顺手。更容易发现数据里的门道、趋势和关联。比如,销售、库存、客户行为数据一整合,就能看清产品卖得好不好、库存周转快不快、客户喜欢啥。说白了,编排好的数据是深度分析的“好原料”。
4.数字化转型的助推器:企业搞数字化,核心之一就是打通数据、用好数据。数据编排正是解决“数据孤岛”、实现数据顺畅流动的关键手段。它帮着构建统一、可靠的数据底座,各种数字化应用(精准营销、智能风控、运营优化)才有坚实的数据基础。你懂我意思吗?没这个基础,数字化就是空中楼阁。
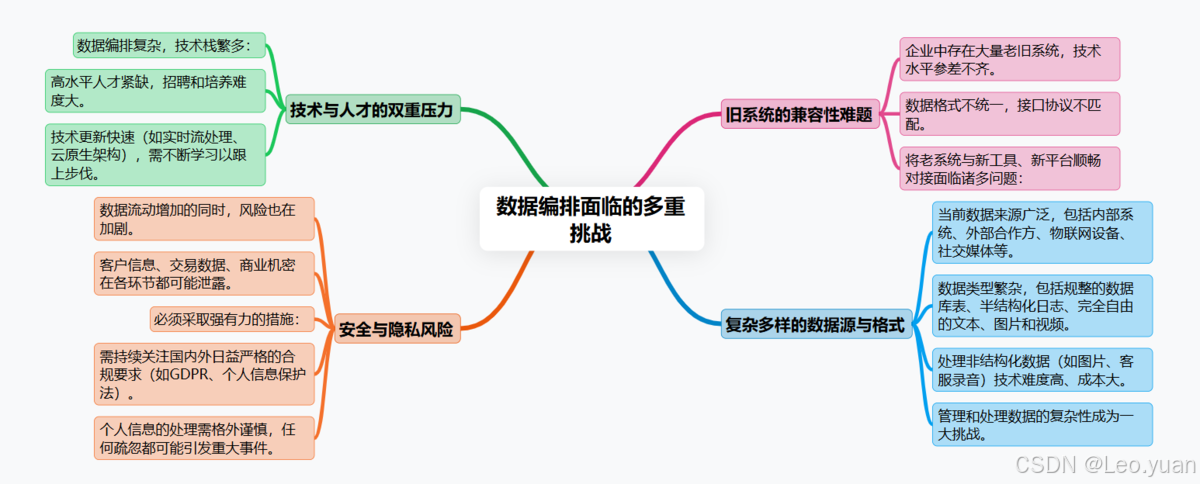
四、数据编排面临的挑战
路好走,但坑也不少,得心里有数:
1.数据太复杂:现在数据来源多(内部系统、外部合作方、物联网设备、社交媒体)、类型杂(规整的数据库表、半结构化的日志、纯自由的文本图片视频)。特别是处理那些非结构化数据(像图片、客服录音),技术难度和成本都更高。怎么有效管理、处理这种复杂性是个大挑战。
2.安全与隐私是红线:数据流动起来,风险也跟着动。客户信息、交易数据、商业机密,在抽取、传输、处理、存储的每个环节都可能泄露。必须上硬手段:数据传输加密、存储加密、严格的访问权限控制(最小权限原则)、操作审计日志。还得时刻盯着国内外越来越严的合规要求(GDPR、个人信息保护法),处理个人信息要特别小心。听着是不是很熟?一出事就是大事。
3.技术和人才跟不上趟:搞数据编排,技术栈不简单:得懂数据库、会点编程(SQL,Python)、熟悉数据处理框架、了解各种工具平台。市场上能玩转这些的熟手不多,招人难、培养人也费劲。技术更新还快(比如实时流处理、云原生架构),得持续学习。
4.老系统难兼容:企业里往往一堆老系统,用的技术五花八门,数据格式也不统一。让这些“老古董”和新工具、新平台顺畅对话,把数据抽出来、送进去,经常遇到接口不对、协议不通、性能跟不上等兼容性问题,很头疼。
五、数据编排的工具
工欲善其事,必先利其器。市面上主流工具盘点一下:
1.FineDataLink:国内选手,亮点在可视化拖拉拽设计流程,对新手友好;能连各种常见数据源;数据转换功能比较丰富;监控调度做得不错。适合想快速上手、整合能力要求高的场景。
作为一款低代码/高时效的企业级一站式数据集成平台,FDL在面向用户大数据场景下,可回应实时和离线数据采集、集成、管理的诉求,提供快速连接、高时效融合各种数据、灵活进行ETL数据开发的能力,帮助企业打破数据孤岛,大幅激活企业业务潜能,使数据成为生产力>>>免费试用FDL

2.TalendOpenStudio:开源免费,社区活跃,组件库丰富,能快速搭流程。图形化界面降低了使用门槛。但处理超大规模数据时,可能需要额外优化性能。
3.InformaticaPowerCenter:企业级老牌选手,功能全、性能强,尤其擅长处理超大规模、超复杂的数据流,支持分布式计算。但价格不菲,对硬件要求也高,一般是大企业的选择。
4.IBMDataStage:同样是重量级选手,性能强劲,适合高并发大数据量场景;和IBM自家产品(如Db2)集成好;监控管理功能全面。学习曲线比较陡峭。
5.MicrosoftSSIS:微软SQLServer亲儿子,和SQLServer无缝集成是最大优势;可视化设计界面易用;尤其适合微软技术栈(SQLServer,Azure)的企业。跨平台或连非微软系数据源可能稍弱。
6.PentahoDataIntegration(Kettle):开源工具,也叫Kettle;图形化操作,支持广泛的数据源和目标;插件扩展性强。处理极其复杂的业务逻辑时性能可能是个考验。
选工具关键看:你家数据啥情况(来源、类型、规模)?业务要啥(实时性要求、复杂度)?团队技术栈和技能咋样?预算多少?工具好不好学、好不好维护?我一直强调,没有最好的,只有最合适的。
总结
数据编排,说白了就是给企业数据的流动和管理立规矩、建管道。它有一套清晰的流程:从搞清楚业务要啥(需求分析),到找到数据源头连上线(源识别连接),把数据搬出来(抽取),收拾干净变个样(转换),再稳稳送到目的地(加载),最后还得盯着管着不断优化(监控优化)。
好处明摆着:数据更干净可靠了(提质量),处理数据的效率上去了(提效率),从数据里能看出更多门道了(强洞察),更是企业搞数字化转型离不开的“筑基”工程(撑转型)。
当然,路上有坎儿:数据本身又杂又乱(复杂性),安全和隐私一点马虎不得(安全隐私),懂行的技术人才不好找(人才缺),让老系统和新工具和谐共处也挺费劲(兼容难)。
好在工具不少,从开源的Talend、Pentaho,到企业级的Informatica、DataStage,还有国内顺手好用的FineDataLink,各有千秋。选工具得擦亮眼,看功能、看成本、看团队能不能玩转、看未来发展。
说到底,在数据就是竞争力的今天,把数据编排整明白了、整顺畅了,企业才能真正把数据用起来,变成决策的底气、业务的推力,在数字化的路上跑得更稳更快。
Q&A常见问答
Q:数据编排和数据挖掘是一回事吗?
A:不是一回事,但紧密相关。数据编排重点是管好数据流:怎么把数据从源头稳定、干净、及时地搬到分析平台。数据挖掘重点是从数据里挖金子:用算法模型发现规律、预测趋势。简单来说,数据编排是给数据挖掘打好地基、备好材料。没有编排好的高质量数据,挖掘就是空谈。
Q:选数据编排工具最该看啥?
A得综合掂量几个事:
- 功能匹配度:它能不能轻松连上你家的各种数据源(数据库、文件、API、云)?支持你需要的转换清洗操作吗?调度监控功能够用不?处理性能(速度、数据量)达标吗?
- 团队搞得定吗?工具好学吗(界面友不友好)?好维护吗?跟你家现有的技术栈(比如都用Java或者都在云上)搭不搭?需不需要专门招人或培训?
- 钱袋子问题:软件许可费多少?云服务怎么收费?后期维护升级、硬件资源投入要多少?开源工具虽然免费,但隐性成本(自己维护、二次开发)也得算。
- 扩展性和未来:业务量涨了、数据类型多了,这工具还能不能撑住?厂商靠不靠谱、技术更不更新?用过来人的经验告诉你,别光看眼前,长远点看。
Q:数据编排对搞数字化转型有多重要?
A:非常核心,可以说是“筑基”工程。企业数字化转型,核心目标之一就是数据驱动。但数据要是散着、脏着、流不动,拿啥驱动?数据编排就是解决这些痛点的:
- 打破数据墙:把各部门、各系统的数据连通,告别“孤岛”。
- 保障数据质:提供干净、可信的数据原料。
- 加速数据用:让业务系统、分析平台能及时拿到需要的数据。
- 支撑新应用:为实时分析、AI预测、个性化服务这些数字化场景提供可靠的数据流水线。你懂我意思吗?没它,数字化转型的地基就不牢。









:基于 Qt Widgets 搭建串口调试界面)



)
)



)
