生成式人工智能(Gen AI)的迅猛发展,对大型语言模型(LLM)的部署提出了更高的性能、灵活性和效率要求。
无论部署在何种环境中,红帽AI推理服务器都为用户提供经过强化并获得官方支持的vLLM发行版,配套智能LLM压缩工具,以及在Hugging Face平台上优化的模型仓库。结合红帽的企业级技术支持与灵活的第三方支持政策,为企业部署生成式AI应用提供强有力的支撑。
借助vLLM内核与先进并行技术,加速AI推理性能
红帽AI推理服务器的核心是vLLM推理引擎。vLLM因其高吞吐量与内存效率优异而广受认可,核心技术包括源自加州大学伯克利分校的PagedAttention(用于优化GPU内存管理)以及持续批处理(Continuous Batching),通常能带来数倍于传统推理方法的性能提升。该服务器还通常提供一个兼容OpenAI的API端点,便于快速集成。
为应对当前体量庞大、结构复杂的生成式AI模型,vLLM融合了多种先进的推理优化技术,包括:
张量并行(Tensor Parallelism,TP):将单个模型层拆分并并行分布到同一节点内的多个GPU上执行,从而降低延迟并提升计算吞吐能力。
流水线并行(Pipeline Parallelism,PP):将模型的不同层划分为若干阶段,分别部署在不同GPU或节点上,适用于单一多GPU节点也无法容纳的超大模型。
专家并行(Expert Parallelism,EP):针对混合专家(Mixture of Experts,MoE)模型进行专门优化,能够高效处理其独特的路由逻辑和计算资源分配。
数据并行(Data Parallelism,DP):支持将不同的推理请求分发至多个vLLM实例。在进入MoE层时,各数据并行引擎协同工作,将专家模块在所有数据并行与张量并行的工作器之间进行切分。此机制特别适用于如DeepSeek V3或Qwen3这类KV注意力头较少的模型,可避免张量并行造成的KV缓存冗余,提升资源利用率与扩展能力。
量化(Quantization):AI推理服务器内置的LLM Compressor提供统一的模型压缩库,支持权重+激活量化或仅权重量化,从而加速vLLM推理流程。vLLM同时提供自定义内核(如Marlin和Machete)以进一步提升量化模型的运行效率。
推测解码(Speculative Decoding):通过引入一个小型草稿模型预测多个未来token,主模型仅对其进行验证或修正,从而显著降低整体解码延迟,提高推理吞吐量,同时保持生成质量不受影响。
值得一提的是,上述优化技术通常可灵活组合使用,例如节点间应用流水线并行、节点内应用张量并行,以适应复杂的硬件拓扑结构,在大规模推理场景中高效扩展LLM的计算能力。
通过容器化实现部署可移植性
红帽AI推理服务器以标准容器镜像形式交付,具备出色的部署灵活性。这种容器化交付方式是实现混合云环境下可移植性的核心,确保无论部署在红帽OpenShift、红帽企业Linux(RHEL)、非红帽Kubernetes平台,还是其他标准Linux系统上,均可提供一致的推理运行环境。它为在任意业务场景中部署大型语言模型(LLM)奠定了标准化、可预测的基础,有效简化了跨异构基础设施的运维工作。
多加速器支持
红帽AI推理服务器自设计之初便将多加速器支持作为核心能力,能够无缝兼容多种硬件加速器,包括NVIDIA GPU、AMD GPU和Google TPU。通过构建统一的推理服务层,平台有效屏蔽底层硬件差异,带来极大的灵活性和优化空间。
这一能力让用户能够:
优化性能与成本:根据模型特性、延迟要求和成本预算,在最适合的加速器上运行推理任务,实现更高性能和资源利用效率。
保障未来适应性:支持新一代加速器的无缝集成,无需修改基础架构或应用代码,确保平台具备持续演进能力。
灵活扩展推理能力:可按需添加同类或异构加速器,轻松应对业务增长和模型复杂度提升。
降低厂商依赖:兼容多家加速器供应商,避免对单一硬件平台的绑定,增强采购灵活性与成本控制能力。
简化运维管理:在不同硬件上提供一致的管理接口,显著降低推理服务在异构环境中的运维负担。
凭借这一面向未来的架构设计,红帽AI推理服务器不仅满足当前生成式AI的高性能推理需求,也为企业构建可持续、可拓展的AI基础设施奠定坚实基础。
由红帽内部Neural Magic专业技术驱动的模型优化
高效部署大型语言模型(LLM)通常需要模型优化。AI推理服务器集成了强大的LLM压缩能力,利用已加入红帽的Neural Magic的前沿优化技术。通过SparseGPT等业界领先的量化与稀疏化方法,压缩器可在准确率几乎无损的前提下大幅减小模型体积和计算负担。这提升了推理速度与资源利用效率,显著降低内存占用,使模型即使在GPU资源受限的系统中也能顺畅运行。
通过优化的模型仓库实现简化访问
为进一步简化部署,AI推理服务器提供对一系列主流LLM(如Llama、Mistral和Granite系列)的优化模型仓库访问,托管于Hugging Face的红帽AI页面。
这些模型并非普通版本,而是经过集成压缩技术专门优化,适配vLLM引擎的高性能推理。用户可直接使用这些高效模型,大幅缩短部署时间,加快AI应用落地。
红帽AI推理服务器技术概览
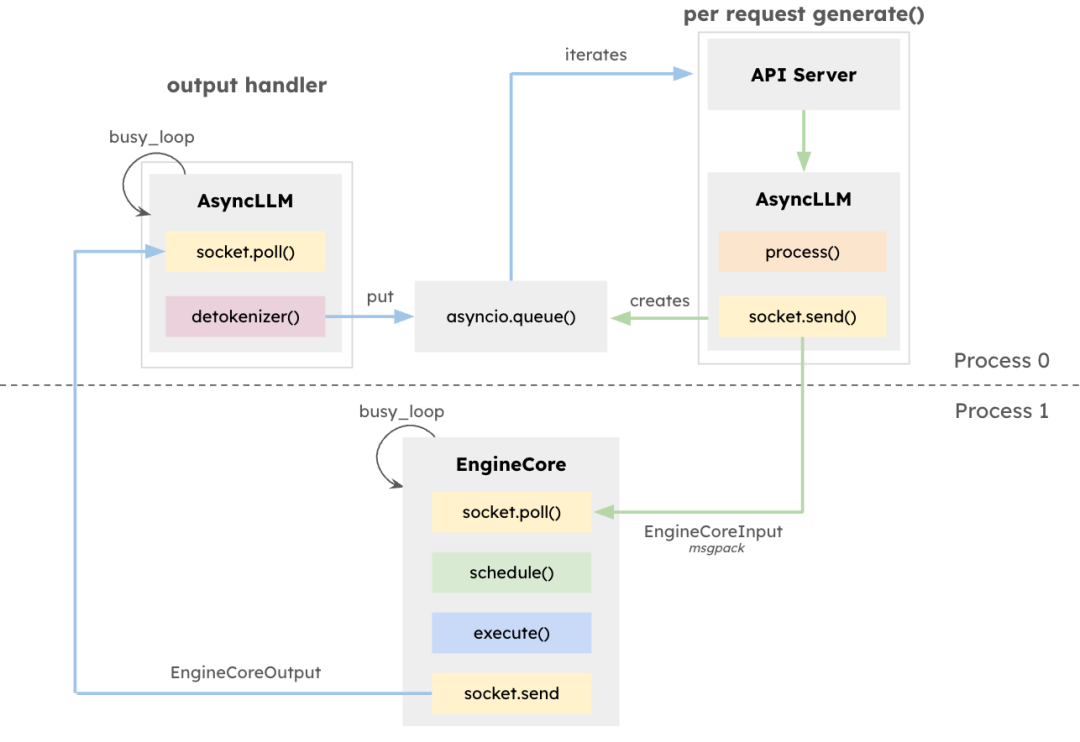
vLLM架构旨在最大化LLM推理的吞吐量并最小化延迟,尤其适用于高并发、请求长度多样的场景。核心组件EngineCore是专用推理引擎,负责前向计算调度、键值(KV)缓存管理以及多请求令牌的动态批处理。
EngineCore不仅降低了长上下文窗口管理的开销,还能智能预处理或交错处理短时延请求与长任务。这依赖于队列调度机制与PagedAttention——一种为每个请求虚拟化KV缓存的新方法。其结果是更高的GPU内存利用率与更少的计算空闲时间。
作为接口适配器,EngineCoreClient负责连接API(如HTTP、gRPC等)并将请求转发至EngineCore。多个EngineCoreClient可与一个或多个EngineCore通信,支持分布式或多节点部署。vLLM将请求处理与底层推理解耦,便于实施如多EngineCore负载均衡或根据需求扩展客户端等策略。
该架构不仅便于集成多种服务接口,还支持可扩展的分布式部署。EngineCoreClient可在独立进程中运行,通过网络连接EngineCore,从而实现负载均衡并降低CPU负载。
红帽AI推理服务器结合领先性能与灵活部署能力。其容器化特性赋予真正的混合云灵活性,支持在任意数据与应用所在环境中一致部署先进AI推理,打造企业AI负载的强大基础。



直方图均衡化,模板匹配,霍夫变换,图像亮度变换,形态学变换)

)


)






)



的浮点数精度计数异常问题解决思路)