决策树
文章目录
- 决策树
- 决策树的基本思想
- 划分选择
- 信息增益
- 增益率
- 基尼指数
- 减枝处理
- 回归问题
- 对连续值的处理
- 对缺失值的处理
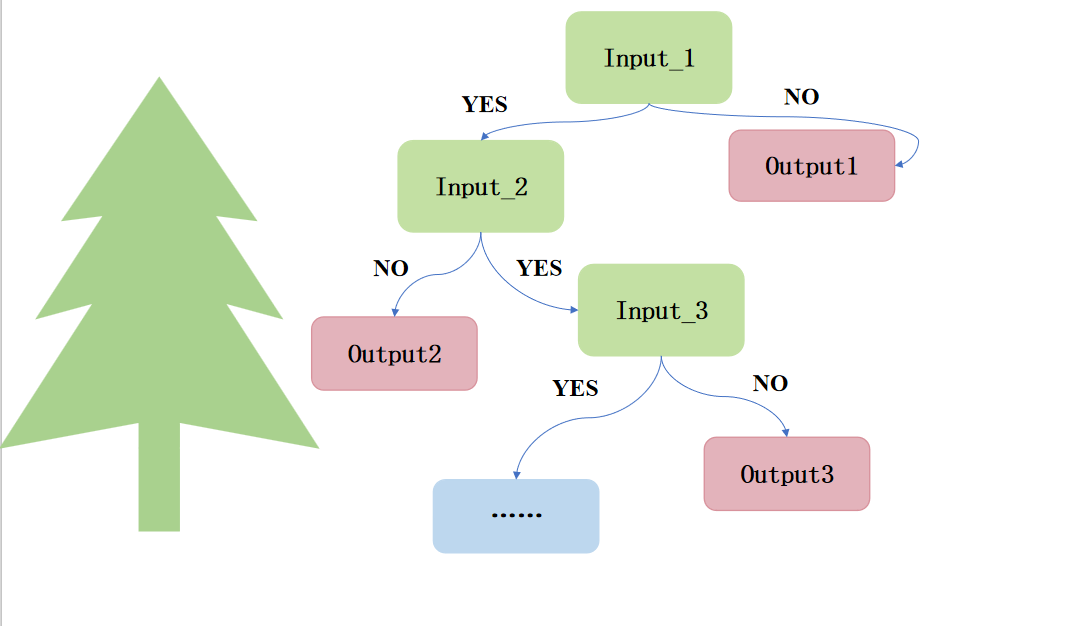
决策树的基本思想
决策树是基于树结构来进行决策的,通过对问题的判断与决策,得到最终决策。
一般的,决策树包括一个根结点、若干个内部节点和若干个叶结点,叶结点对应决策结果,其他每一个结点对应一个属性测试。决策树学习的目的是产生一颗泛化能力强的一棵树,其基本流程遵循简单而直观的"分而治之"(divide-and-conquer)策略.

划分选择
信息熵是度量样本集合纯度的最常用的一种指标,假定当前样本集合 D \mathcal{D} D中第 k k k类样本所占比例为 p k ( k = 1 , 2 , ⋯ , ∣ Y ∣ ) p_k\left(k=1,2,\cdots,|\mathcal{Y}|\right) pk(k=1,2,⋯,∣Y∣),则 D \mathcal{D} D的信息熵定义为:
Ent ( D ) = − ∑ k = 1 ∣ Y ∣ p k log 2 p k \text{Ent}(\mathcal{D})=-\sum_{k=1}^{|\mathcal{Y}|}p_k\log_2p_k Ent(D)=−k=1∑∣Y∣pklog2pk
信息熵越小,则$
\mathcal{D}$纯度越高。
信息增益
假定离属性 a a a上有 V \mathcal{V} V个可能的取值 { a 1 , a 2 , ⋯ , a V } \{a^1,a^2,\cdots,a^\mathcal{V}\} {a1,a2,⋯,aV},若使用 a a a来对样本集进行划分,就会产生 V \mathcal{V} V个分支节点,其中第 v \mathcal{v} v个分支节点包含了 D \mathcal{D} D中所有在属性 a a a上取值为 a v a^{\mathcal{v}} av的样本记为 D v \mathcal{D^v} Dv,通过对不同节点的按样本量占比赋予权重,可以最终得到信息增益:
Gain ( D , a ) = Ent ( D ) − ∑ v = 1 V ∣ D v D ∣ Ent ( D v ) \text{Gain}(\mathcal{D},a)=\text{Ent}(\mathcal{D})-\sum_{\mathcal{v}=1}^{\mathcal{V}}\left|\frac{\mathcal{D^v}}{\mathcal{D}}\right|\text{Ent}(\mathcal{D^v}) Gain(D,a)=Ent(D)−v=1∑V DDv Ent(Dv)
一般而言,信息增益越大代表划分纯度越高。
增益率
由于信息增益对可取值较多的属性有所偏好,为了减少由于这种偏好的不利影响,可以采取增益率作为最优划分:
KaTeX parse error: Expected 'EOF', got '_' at position 11: \text{Gain_̲ratio}(\mathcal…
其中:
IV ( a ) = − ∑ v = 1 V ∣ D v D ∣ log 2 ∣ D v D ∣ \text{IV}(a)=-\sum_{\mathcal{v}=1}^{\mathcal{V}}\left|\frac{\mathcal{D^v}}{\mathcal{D}}\right|\log_2\left|\frac{\mathcal{D^v}}{\mathcal{D}}\right| IV(a)=−v=1∑V DDv log2 DDv
称为属性 a a a的固有值。
基尼指数
基尼值定义为;
Gini ( D ) = ∑ k = 1 ∣ Y ∣ ∑ k ′ ≠ k p k p k ′ \text{Gini}(\mathcal{D})=\sum_{k=1}^{|\mathcal{Y}| }\sum_{k^{\prime}\ne k}p_kp_{k^\prime} Gini(D)=k=1∑∣Y∣k′=k∑pkpk′
基尼指数定义为:
KaTeX parse error: Expected 'EOF', got '_' at position 12: \text{Gini_̲index}(\mathcal…
减枝处理
减枝(pruning)是决策树学习算法中应对过拟合的主要手段。减枝有两种方式:预剪枝(prepruning)和后减枝(postpruning)。
预剪枝是指在决策树生成过程中,对每个结点在划分前先进行评估,若当前划分不能带来模型泛化能力提升(比如通过验证集精度、信息增益等指标判断 ),就直接将当前结点标记为叶结点,停止该分支的进一步划分生长。
后剪枝是指先不做干预,让决策树完整生长至叶子结点(即按常规构建流程生成一棵尽可能复杂的树 ),之后再从树的底层向上(或自顶向下等方式 )遍历结点,评估将某个分支剪掉(即把该分支替换为叶结点,类别按分支中样本多数类等方式确定 )后,模型在验证集上的泛化能力是否提升,若提升则剪枝,直至无法通过剪枝改善性能。
预剪枝是生成树过程中提前叫停分支生长,后剪枝是生成完整树后再反向优化 ,实际应用里需结合数据、计算资源等,选择合适策略平衡模型效果与效率 。相比预剪枝,后剪枝更能精准去除过拟合的分支,模型欠拟合风险低,但由于要先构建完整树,计算成本通常更高 。
回归问题
上面的讨论是基于离散属性对分类问题进行的决策树生成,现在对于连续性特征就不可以直接进行划分。
对连续值的处理
给定样本集合 D \mathcal{D} D和连续属性 a a a,假定 a a a在 D \mathcal{D} D上出现了 n n n个不同的取值,将这些值域大小排列记为 { a 1 , a 2 , … , a n } \{a^1, a^2, \dots, a^n\} {a1,a2,…,an} 。
然后,为构造候选的划分阈值,取每两个相邻不同取值的中点作为候选划分点。
具体来说,对于第 i i i 个和第 i + 1 i + 1 i+1 个取值( i = 1 , 2 , … , n − 1 i = 1, 2, \dots, n - 1 i=1,2,…,n−1 ),计算中点 t i = a i + a i + 1 2 t_i = \frac{a^i + a^{i + 1}}{2} ti=2ai+ai+1 ,这样就得到 n − 1 n - 1 n−1 个候选划分点,构成候选划分点集合 T a = { t 1 , t 2 , … , t n − 1 } T_a = \{t_1, t_2, \dots, t_{n - 1}\} Ta={t1,t2,…,tn−1} 。
有了候选划分点集合 T a T_a Ta 后,对于每个候选划分点 t ∈ T a t \in T_a t∈Ta,可将样本集合 D \mathcal{D} D 中所有样本依据属性 a a a 的取值,二分为两部分:
- 一部分是在属性 a a a 上取值小于等于 t t t 的样本,记为 D t − \mathcal{D}_t^- Dt− ;
- 另一部分是在属性 a a a 上取值大于 t t t 的样本,记为 D t + \mathcal{D}_t^+ Dt+ 。
这就把对连续属性的处理,转化为类似离散属性的“划分选择”问题——从 T a T_a Ta 中选一个最优的划分点 t ∗ t_* t∗ ,使得按 t ∗ t_* t∗ 划分后,能达到最优的划分效果(比如用信息增益、信息增益比、基尼指数等指标衡量,和离散属性选最优划分的逻辑一致,只是候选划分是基于连续值构造的“二分点” )。
例如:
Gain ( D , a ) = max t ∈ T α Gain ( D , a , t ) = max t ∈ T α Ent ( D ) − ∑ λ ∈ { − , + } ∣ D t λ D ∣ Ent ( D t λ ) \text{Gain}(\mathcal{D},a)=\underset{t\in T_\alpha}{\max}\text{Gain}(\mathcal{D},a,t)=\underset{t\in T_\alpha}{\max}\text{Ent}(\mathcal{D})-\sum_{\lambda\in \{-,+\}}\left|\frac{\mathcal{D}^{\lambda}_t}{\mathcal{D}}\right|\text{Ent}(\mathcal{D}_t^\lambda) Gain(D,a)=t∈TαmaxGain(D,a,t)=t∈TαmaxEnt(D)−λ∈{−,+}∑ DDtλ Ent(Dtλ)
对缺失值的处理
对于数据集中的缺失值,我们需要解决以下两个问题:
- 如何在属性缺失的情况下进行划分属性选择?
- 给定划分属性,若样本在该属性上值缺失,如何对样本进行划分?
对于问题一,解决的核心思路是:
只利用 “无缺失值样本” 计算划分指标(如信息增益、增益率等 ),并对指标按 “无缺失值样本占总样本的比例” 加权,最终选加权后最优的属性作为划分属性.
对于问题二,解决的核心思路是:
让缺失值样本 “以不同概率,划入所有可能的分支”.
给定训练集 D D D 和属性 a a a,令 D ~ \tilde{D} D~ 表示 D D D 中在属性 a a a 上没有缺失值的样本子集。
对问题(1),仅可根据 D ~ \tilde{D} D~ 判断属性 a a a 的优劣。假定属性 a a a 有 V V V 个可取值 { a 1 , a 2 , … , a V } \{a^1, a^2, \ldots, a^V\} {a1,a2,…,aV},令:
- D ~ v \tilde{D}^v D~v 表示 D ~ \tilde{D} D~ 中在属性 a a a 上取值为 a v a^v av 的样本子集;
- D ~ k \tilde{D}_k D~k 表示 D ~ \tilde{D} D~ 中属于第 k k k 类( k = 1 , 2 , … , ∣ Y ∣ k = 1, 2, \ldots, |\mathcal{Y}| k=1,2,…,∣Y∣)的样本子集;
显然满足集合关系:
D ~ = ⋃ k = 1 ∣ Y ∣ D ~ k , D ~ = ⋃ v = 1 V D ~ v \tilde{D} = \bigcup_{k=1}^{|\mathcal{Y}|} \tilde{D}_k, \quad \tilde{D} = \bigcup_{v=1}^{V} \tilde{D}^v D~=k=1⋃∣Y∣D~k,D~=v=1⋃VD~v
为每个样本 x \boldsymbol{x} x 赋予权重 w x w_{\boldsymbol{x}} wx,并定义以下指标:
ρ = ∑ x ∈ D ~ w x ∑ x ∈ D w x \rho = \frac{\sum_{\boldsymbol{x} \in \tilde{D}} w_{\boldsymbol{x}}}{\sum_{\boldsymbol{x} \in D} w_{\boldsymbol{x}}} ρ=∑x∈Dwx∑x∈D~wx
p ~ k = ∑ x ∈ D ~ k w x ∑ x ∈ D ~ w x ( 1 ≤ k ≤ ∣ Y ∣ ) \tilde{p}_k = \frac{\sum_{\boldsymbol{x} \in \tilde{D}_k} w_{\boldsymbol{x}}}{\sum_{\boldsymbol{x} \in \tilde{D}} w_{\boldsymbol{x}}} \quad (1 \leq k \leq |\mathcal{Y}|) p~k=∑x∈D~wx∑x∈D~kwx(1≤k≤∣Y∣)
r ~ v = ∑ x ∈ D ~ v w x ∑ x ∈ D ~ w x ( 1 ≤ v ≤ V ) \tilde{r}_v = \frac{\sum_{\boldsymbol{x} \in \tilde{D}^v} w_{\boldsymbol{x}}}{\sum_{\boldsymbol{x} \in \tilde{D}} w_{\boldsymbol{x}}} \quad (1 \leq v \leq V) r~v=∑x∈D~wx∑x∈D~vwx(1≤v≤V)
直观地看,对属性 a a a:
- ρ \rho ρ 表示无缺失值样本所占的比例;
- p ~ k \tilde{p}_k p~k 表示无缺失值样本中第 k k k 类所占的比例;
- r ~ v \tilde{r}_v r~v 表示无缺失值样本中在属性 a a a 上取值 a v a^v av 的样本所占的比例。
显然满足归一化条件:
∑ k = 1 ∣ Y ∣ p ~ k = 1 , ∑ v = 1 V r ~ v = 1 \sum_{k=1}^{|\mathcal{Y}|} \tilde{p}_k = 1, \quad \sum_{v=1}^{V} \tilde{r}_v = 1 k=1∑∣Y∣p~k=1,v=1∑Vr~v=1
基于上述定义,信息增益的计算式可推广为:
Gain ( D , a ) = ρ × Gain ( D ~ , a ) = ρ × ( Ent ( D ~ ) − ∑ v = 1 V r ~ v ⋅ Ent ( D ~ v ) ) \begin{aligned} \text{Gain}(D, a) &= \rho \times \text{Gain}(\tilde{D}, a) \\ &= \rho \times \left( \text{Ent}(\tilde{D}) - \sum_{v=1}^{V} \tilde{r}_v \cdot \text{Ent}(\tilde{D}^v) \right) \end{aligned} Gain(D,a)=ρ×Gain(D~,a)=ρ×(Ent(D~)−v=1∑Vr~v⋅Ent(D~v))
其中,由信息熵的基本定义:
Ent ( D ~ ) = − ∑ k = 1 ∣ Y ∣ p ~ k log 2 p ~ k \text{Ent}(\tilde{D}) = -\sum_{k=1}^{|\mathcal{Y}|} \tilde{p}_k \log_2 \tilde{p}_k Ent(D~)=−k=1∑∣Y∣p~klog2p~k
对问题(2),样本划分规则如下:
- 若样本 x \boldsymbol{x} x 在划分属性 a a a 上的取值已知,则将 x \boldsymbol{x} x 划入与其取值对应的子结点,且样本权值在子结点中保持为 w x w_{\boldsymbol{x}} wx;
- 若样本 x \boldsymbol{x} x 在划分属性 a a a 上的取值未知,则将 x \boldsymbol{x} x 同时划入所有子结点,且样本权值在与属性值 a v a^v av 对应的子结点中调整为 r ~ v ⋅ w x \tilde{r}_v \cdot w_{\boldsymbol{x}} r~v⋅wx。
直观地看,这就是让同一个样本以不同的概率划入到不同的子结点中去。









Playwright自动化-3-离线搭建playwright环境)






)


