
序言:
在这篇博客中我们将讲解线程的概念,如何理解线程,线程和进程的区别,线程的优缺点等,我相信你看完这篇博客后会以别样的视角重新理解线程,下面的内容全部是基于Linux操作系统的。
一、线程的概念
1.1、重新理解地址空间
在外面之前的博客中我们说过:进程 = 内核数据结构 + 自己的代码和数据。内核数据结构,代码和数据都需要保存在内存中。它们都经过内核页表或者用户页表进行映射到地址空间让我们的进程看见这些资源,换一句话来说地址空间不就是进程的 “窗口” 吗?,因为进程大部分的数据都需要直接或者间接(比如栈,加载的库,进程的代码和数据,内核的代码和数据等等)通过地址空间看见。
下面我们回答一些问题让我们的理解更加深刻:
缺页中断是怎么回事?
现在我们带入一个场景:
当我们malloc的时候,操作系统会做什么?
操作系统会根据我们需要的大小在我们的地址空间开辟一块空间(mm_struct的end和start指针上下移动就可以在地址空间开辟空间),但我们的操作系统并没有在我们的物理内存上为我们开辟真正的空间,如果当我们使用这一块空间的时候CPU上的MMU寄存器在进行虚拟地址和物理地址转化的时候失败触发中断CPU保护现场拿到中断号,然后去中断向量表去执行指定的中断方法(在物理内存上开辟空间,创建页表建立虚拟地址和物理地址的映射)执行完成再恢复现场去执行进程下面的代码)。
看完上面对缺页中断的处理方法,我们有一种体会:只要我们的进程有了虚拟地址那么我们就一定还会有物理地址,只是当我们申请空间的时候开辟还是当我们真实使用的时候才会去开辟。
那么我们得出来一个结论:进程有多少虚拟地址就代表进程有多少资源,换一句话来说地址空间就是资源的代表。
教材给进程的定义是:进程是承担分配系统资源的基本实体。
这句话应该如何去理解呢?
当我们创建一个进程的时候,操作系统会创建PCB,地址空间,用户页表等,这些都是需要占据CPU或者内存资源,所以进程是分配系统资源的基本实体。
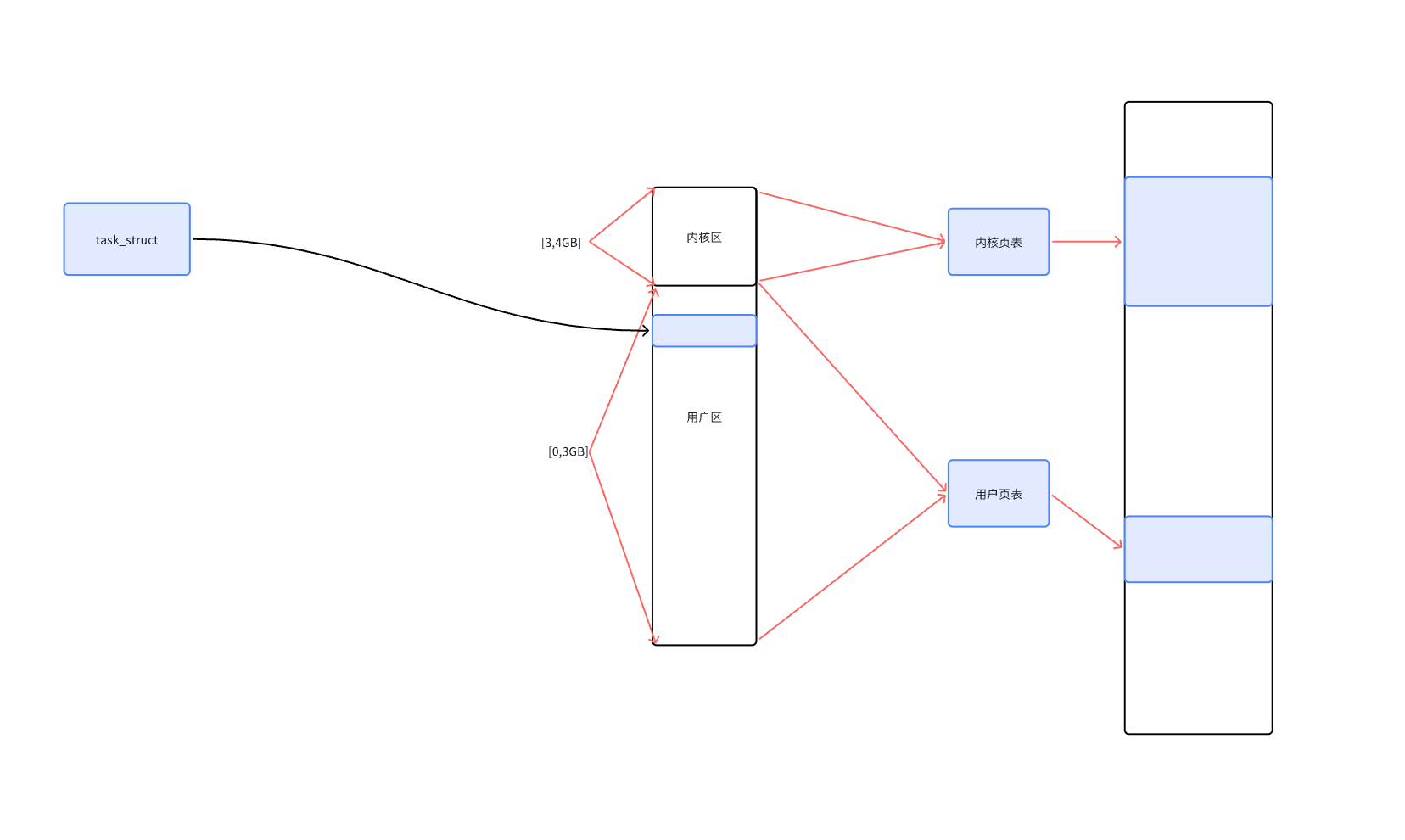
1.2、什么是线程?
如果现在我们在一个主进程创建一个 “进程”(这里的进程只需要PCB不需要创建地址空间等内核数据),这个“新进程”可以看见和使用主进程的系统资源。如果可以把资源划分给不同的PCB再让不同的PCB执行对应的资源,这就是线程的概念。
如何去划分资源?
地址空间就是资源的代表,划分地址空间不就相当于划分资源吗?,划分地址空间换一句话来说不就相当于划分虚拟地址范围,如果我们可以让不同的执行流去执行不同的函数不就相当于去划分了资源。
为什么执行不同的函数就相当于划分资源?
当我们的函数编译成汇编代码以后每一句代码都有自己的地址,这些地址不就是虚拟地址吗?换一句话来说函数就是虚拟地址的集合,函数天然就帮我们划分好了资源,当我们给不同的PCB不同的入口代码地址那么这些PCB可以并发的执行起来了。
教材给线程的定义是:线程是进程内部的一个执行流。
站在内核和资源的角度给线程的定义:线程是CPU调度的基本单位。
如何去理解我们之前说的进程?
我们之前说进程是一个执行流的,它有PCB内核结构也有进程的代码和数据加载到内存中,那这和我们上面说的线程不是一样吗?其实不一样,我们给进程的定义是:进程 = 内核数据结构 + 自己的代码和数据。
下面我们来看一副图来理解一下:
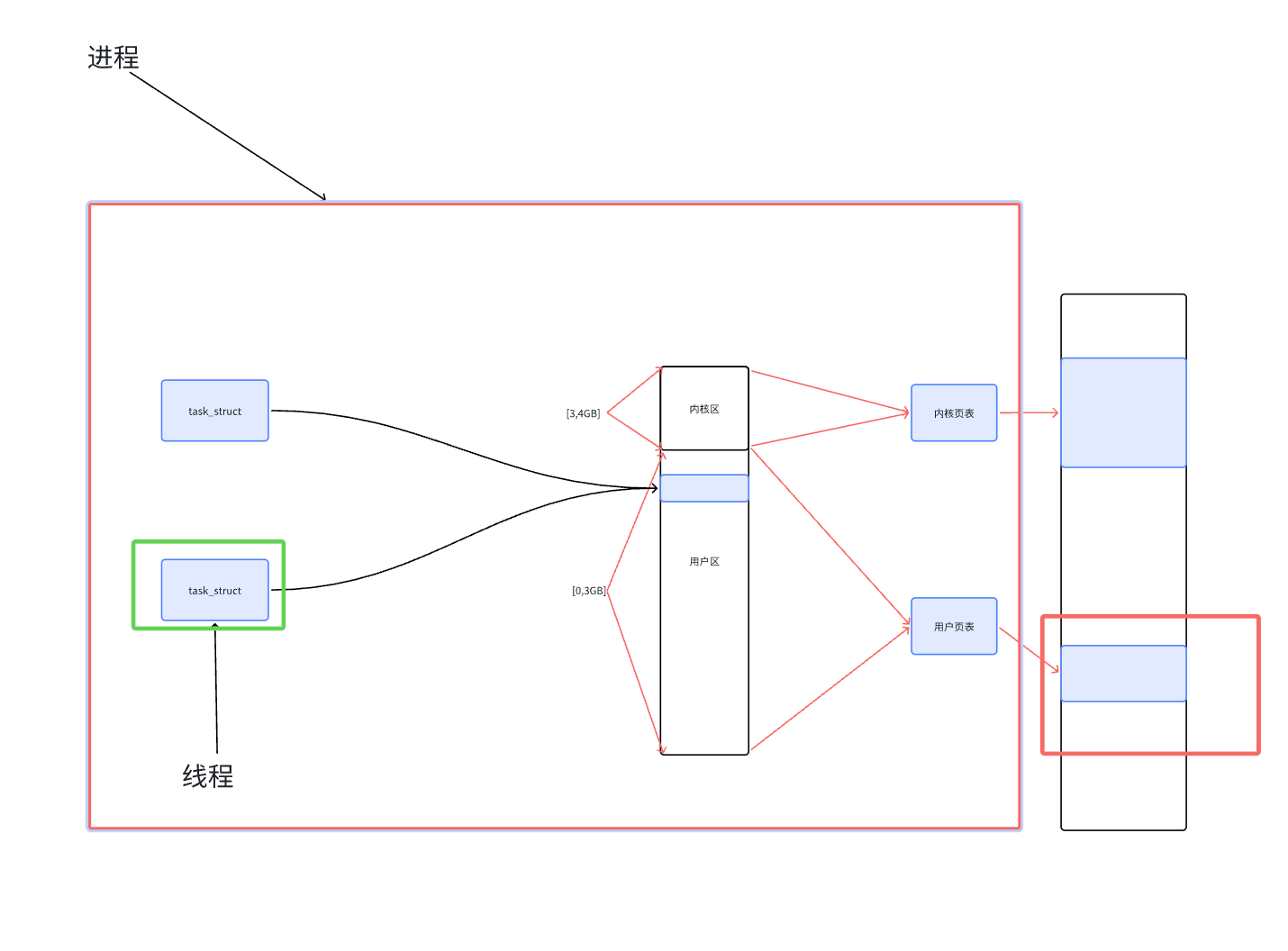
上面图上画红框的才是进程,画绿框的才是线程,我们可也有说进程中包含线程。我们之前说的那种进程是一种特殊的形式:单线程的进程。

站在操作系统和CPU的角度如何去理解线程?
在Linux中并没有为了线程单独设计内核数据结构而是用来以前进程的PCB,这样做的好处是操作系统的调度算法不需要再重新设计,因为PCB的结构没有改变,所以在系统看来都是一个一个的执行流,操作系统做进程调用的时候只要调度一个个的执行就好了。
Linux:一个个执行流的概念。
CPU:一种轻量级的进程,因为线程比任何的进程都要更小,换一句话来说 线程 <= 进程。
二、物理内存的管理
2.1、管理页的结构体
内存中一些空间正在被创建一些需要被销毁等,我们的内存这么大的空间我们如何去管理它呢?答案还是 “先描述,再组织” 。在我们内核数据结构中有struct page用来管理我们的内存空间。
下面我们来看一下struct page结构体:
struct page {unsigned long flags; /* Atomic flags, some possibly* updated asynchronously */atomic_t _count; /* Usage count, see below. */union {atomic_t _mapcount; /* Count of ptes mapped in mms,* to show when page is mapped* & limit reverse map searches.*/struct { /* SLUB */u16 inuse;u16 objects;};};union {struct {unsigned long private; /* Mapping-private opaque data:* usually used for buffer_heads* if PagePrivate set; used for* swp_entry_t if PageSwapCache;* indicates order in the buddy* system if PG_buddy is set.*/struct address_space *mapping; /* If low bit clear, points to* inode address_space, or NULL.* If page mapped as anonymous* memory, low bit is set, and* it points to anon_vma object:* see PAGE_MAPPING_ANON below.*/};
#if USE_SPLIT_PTLOCKSspinlock_t ptl;
#endifstruct kmem_cache *slab; /* SLUB: Pointer to slab */struct page *first_page; /* Compound tail pages */};union {pgoff_t index; /* Our offset within mapping. */void *freelist; /* SLUB: freelist req. slab lock */};struct list_head lru; /* Pageout list, eg. active_list* protected by zone->lru_lock !*//** On machines where all RAM is mapped into kernel address space,* we can simply calculate the virtual address. On machines with* highmem some memory is mapped into kernel virtual memory* dynamically, so we need a place to store that address.* Note that this field could be 16 bits on x86 ... ;)** Architectures with slow multiplication can define* WANT_PAGE_VIRTUAL in asm/page.h*/
#if defined(WANT_PAGE_VIRTUAL)void *virtual; /* Kernel virtual address (NULL ifnot kmapped, ie. highmem) */
#endif /* WANT_PAGE_VIRTUAL */
#ifdef CONFIG_WANT_PAGE_DEBUG_FLAGSunsigned long debug_flags; /* Use atomic bitops on this */
#endif#ifdef CONFIG_KMEMCHECK/** kmemcheck wants to track the status of each byte in a page; this* is a pointer to such a status block. NULL if not tracked.*/void *shadow;
#endif
};struct page结构体的成员变量
flags:用来存放页的状态,一共有32种状态。
_mapcount:这个页被多少个页表引用。
virtual:这个也在地址空间里的虚拟地址。
strcut page的大小大概是40多字节全部的页的struct page放在一起也不过40MB对内存资源的销毁并不大。
内存天然是4KB大小块划分的吗?
答案是不是的,内存是被操作系统分为4KB大小的块的,内存本身是一块连续的空间。
为什么要以4KB为大小?
这个是科学家经过测试出来的4KB的效率更高,当然也有很多其他的因素,比如历史,硬件等。
下面我想补充几个概念:
页框和页帧:现在在教材中页帧和页框的概念是相同的了,它们都表示在磁盘中或者在内存中4KB的存储空间。
页:表示4KB页框中存储的数据内容。
2.2、如何去申请空间?
在操作系统中我们可以认为管理struct page结构体通过数组的方式管理

那么我们如何去申请一块空间呢?
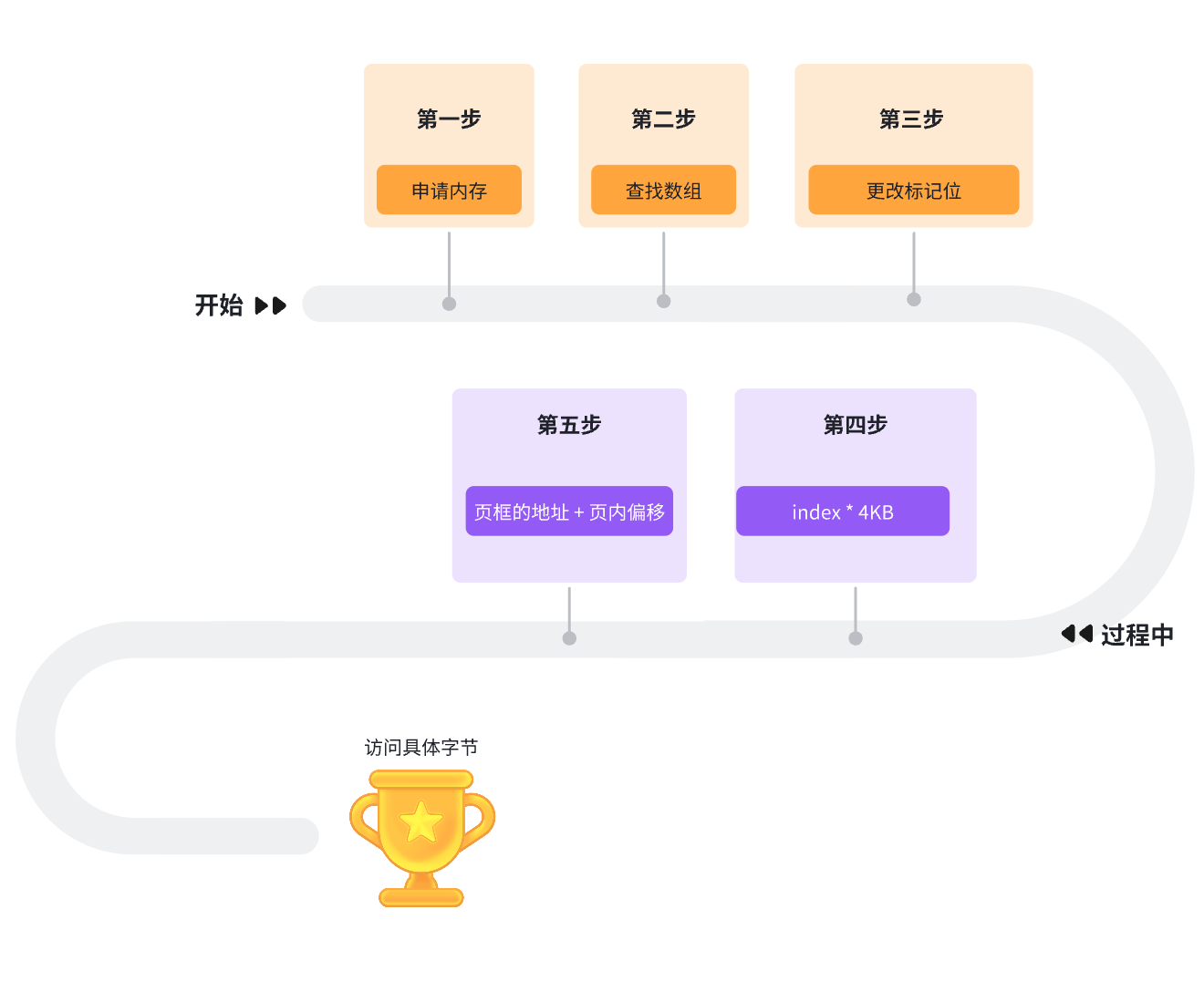
我们可以现在struct page数组中寻找到一个struct page我们知道了它的下标,再去更改struct page中的flag标志位将未占用改为占用,然后通过下标index * 4KB就可以找到内存中具体的页框地址。
申请内存的流程是:
如何去销毁对应的空间呢?
通过物理地址 / 4KB找到对应struct page的下标,再去更改struct page里的flag标记位,就可以了。
三、如何去理解页表?
按32位的机器来说,我们的内存有4GB如果按照我们说的左边是虚拟地址右边是物理地址的形式,那光光页表如果是全部映射的话就需要32GB(4GB * 8字节)的大小,在我们的操作系统里肯定会有很多的进程,我们的内存全部用来存页表都不够,这种方式显然是不可能是我们操作系统实现页表的方法。

那么我们的操作系统是如何实现对页表的保存的:多级页表的形式。
3.1、多级页表
32位机器中地址一共32位个比特位,操作系统把32个比特位分为三份,第一份为0~10位,第二份为11~20位,第三份为21~32位,它们三个分别承担了不同的任务。
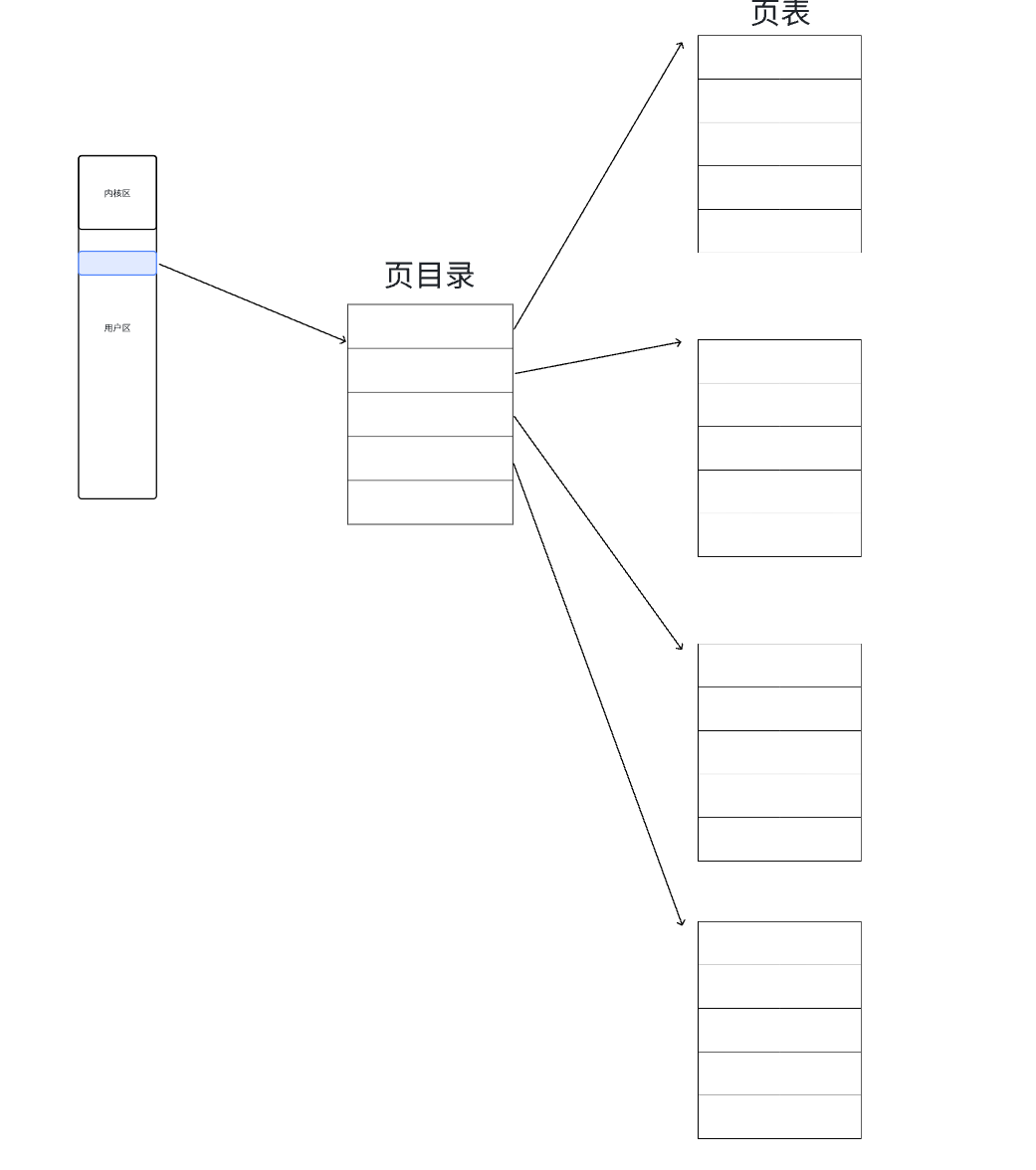
在页目录表项存储的是:页表的地址。
在页表表项存储的是:具体物理内存页框的地址。
前10为比特位作为索引去查找页目录找到对应的页表地址,再用中间10为比特位来作为索引查找页表找到对应的页框的地址,最后再用最后12位比特位来作为具体的页内偏移去访问具体的字节内容。
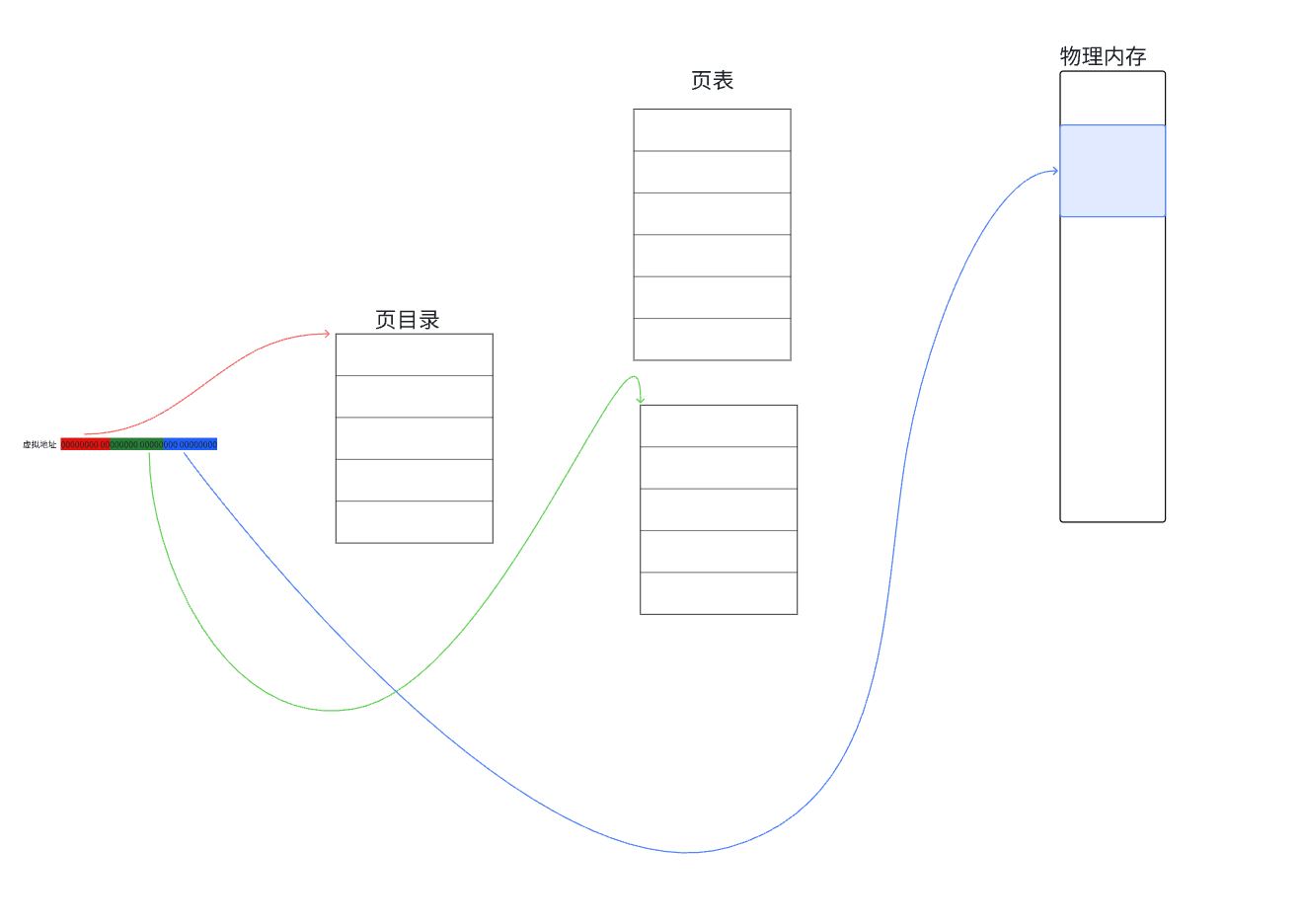
我们前面说过 具体的物理地址 = 物理内存页框地址 + 页内偏移,通过上面这种多级页表的方式就可以访问具体的字节。
下面我们来回答几个问题:
为什么页内偏移设置成地址的低12位?
这个问题的答案在前20位上,一个页框内的地址是不是前20位都是一样的,我们在访问一句代码的时候根据局部性原理我们很有可能访问这句代码周围的代码和数据,如果访问的数据是在附近的那么它们的前20位很可能是相同的它们只要低12位是不一样的,这也就说明它们在同一个页框中我们可以用尽量少次数的访问把它们全部找到效率高。
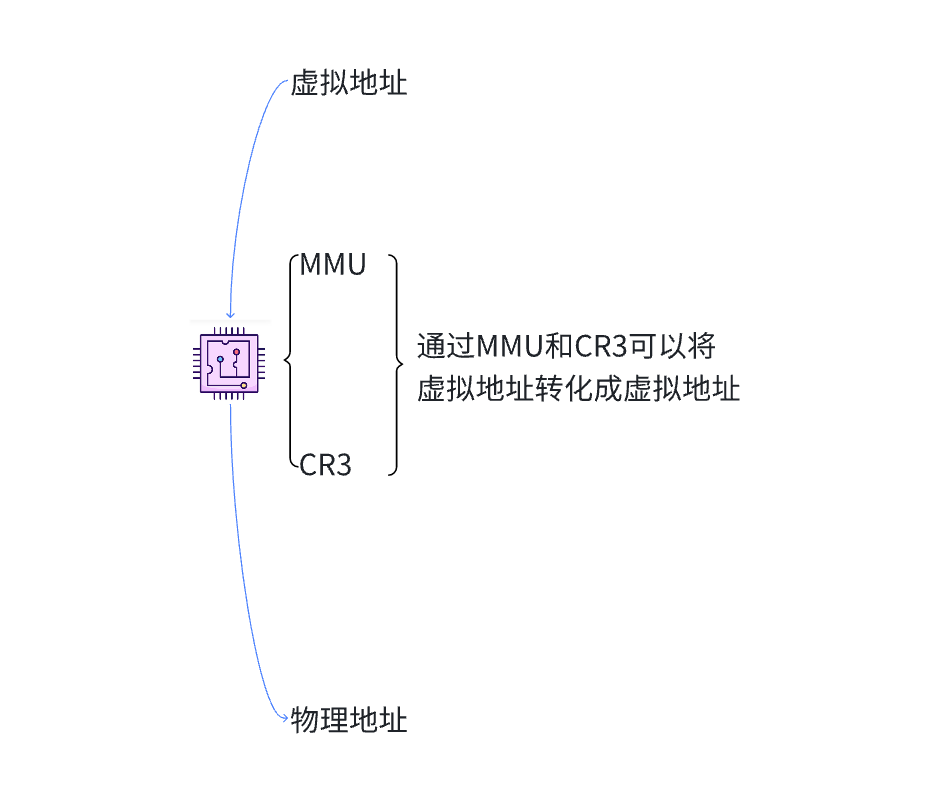
我们的用户用的全部都是虚拟地址通过什么去进行转化?
在我们的CPU中集成了MMU和CR3寄存器,CR3中存放的是页目录的地址,MMU可以根据CR3提供的页目录地址去查找页目录,页表进而将虚拟地址转化成物理地址。
MMU要先进⾏两次⻚表查询确定物理地址,在确认了权限等问题后,MMU再将这个物理地址发送到总线,内存收到之后开始读取对应地址的数据并返回。那么当⻚表变为N级时,就变成了N次检索+1次读写,这也就说明了多级页表的一个缺点:效率低。
多级页表和单张页表的优缺点:
多级页表:
优点:省空间。
缺点:如果页表分级比较多查找需要多次降低效率。
单级页表:
优点:效率高,只需要查找一次。
缺点:需要占据的内存大小比较大。
3.2、页表的优点
1、维护进程的独立性
如果没有页表,进程直接去访问物理空间,如果有恶意软件直接去改变其他进程的数据,就可能导致其他软件的错误导致进程被杀死,进而进程的安全性无法保证。
2、高效利用物理内存
离散分配:进程的虚拟地址空间可以映射到物理内存中不连续的页框(物理页),避免了传统连续内存分配导致的 “内存碎片” 问题,提高了物理内存的利用率。
按需加载:结合分页机制,进程无需将全部数据加载到物理内存即可运行(仅加载当前需要的页),实现了 “部分加载”,让有限的物理内存可以支持更多进程并发运行。
3、 支持内存共享与保护
共享内存:多个进程的页表可映射到同一物理页框(如共享库、进程间通信的共享内存区域),实现内存内容的共享,减少重复存储,节省物理内存。
权限控制:页表项(PTE)中包含权限位(如读、写、执行权限),操作系统可通过设置这些位限制对内存页的操作(如只读页禁止修改、数据页禁止执行),防止非法访问(如缓冲区溢出攻击)。
四、缺页中断怎么回事?
当我们给CPU一个虚拟地址的时候,它会先去到TLB(我们之前在《Linux Ext文件系统》中介绍过)中去寻找,没有找到,它再去把虚拟地址给MMU,MMU再去通过CR3提供的页目录地址去想你找对应的页表,也没有找到,这个时候触发软中断。
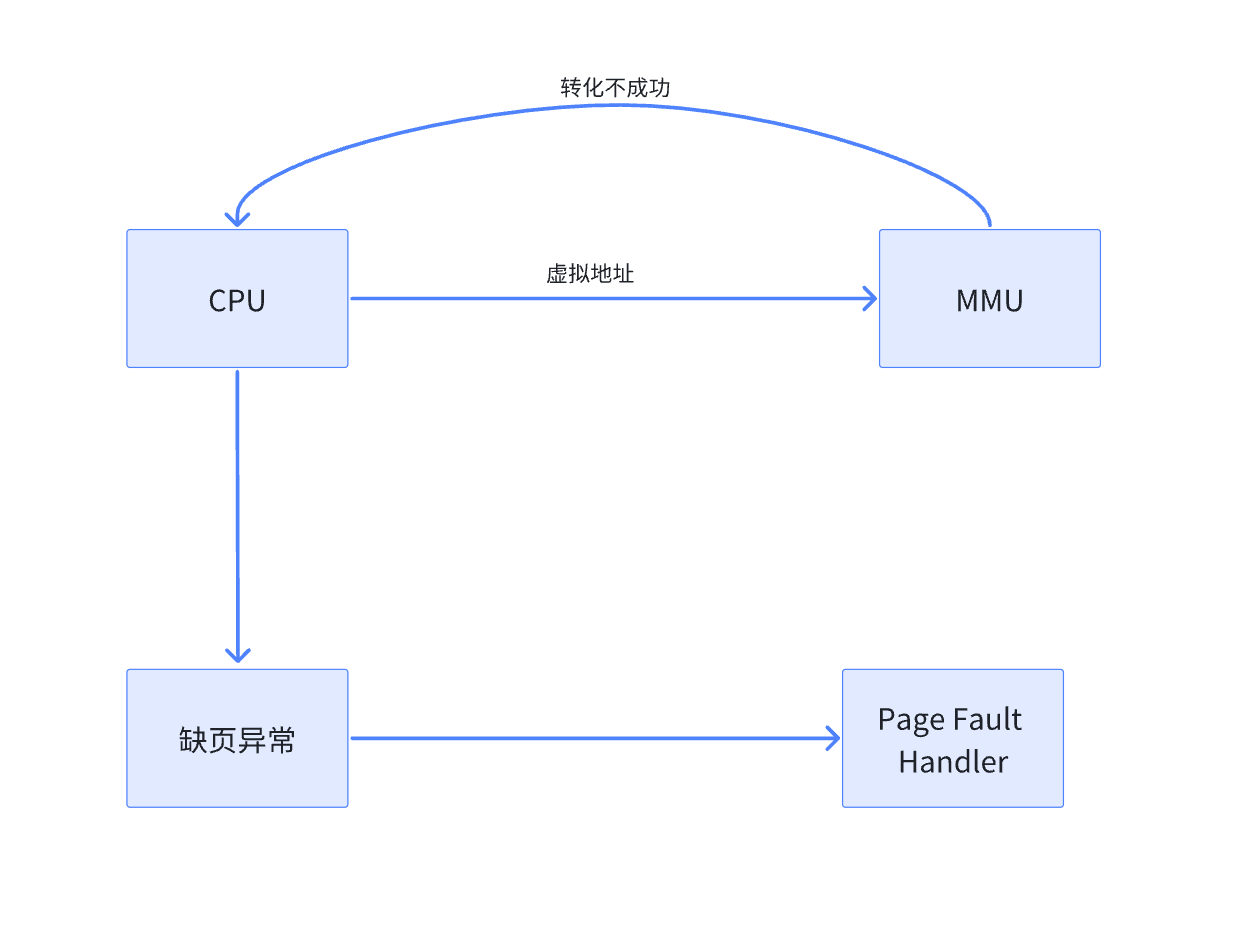
Page Falut Handler:在磁盘中找到对应的数据,在struct page中申请内存空间,将磁盘中的数据载入到内存中申请页表建立页表和物理内存的映射关系,然后返回。
=========================================================================
本篇关于Linux的文件理解与操作的介绍就暂告段落啦,希望能对大家的学习产生帮助,欢迎各位佬前来支持纠正!!!



)





)


)
-部署和使用指南)






