当程序需要等待外部操作时,是应该"干等"还是"边等边干"?为什么有些程序会卡住不动,而另一些却能流畅运行?这一切都取决于阻塞与非阻塞的编程选择!本文将为你揭示这两种模式的本质区别!
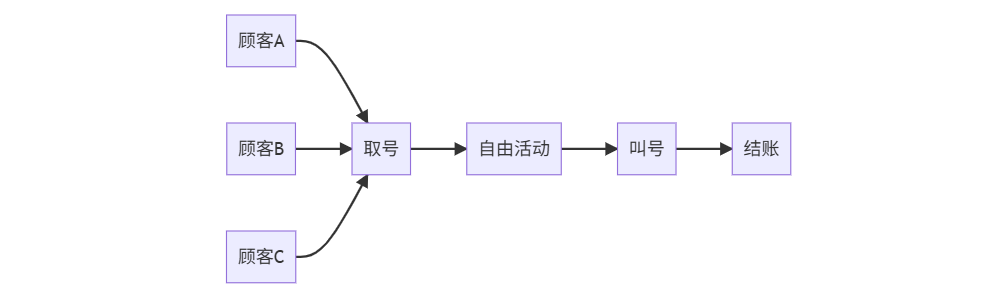
一、生活比喻:超市结账的两种方式
阻塞式等待:单通道排队

非阻塞式等待:取号系统
二、核心概念解析
1. 阻塞(Blocking):必须等待
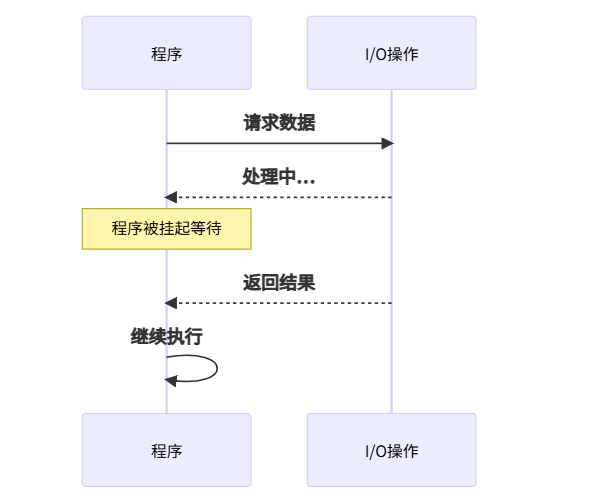
特点:
- ⛔ 程序执行被暂停
- ⏳ 必须等待操作完成
- 🧘 期间CPU不能做其他事
2. 非阻塞(Non-blocking):边等边做
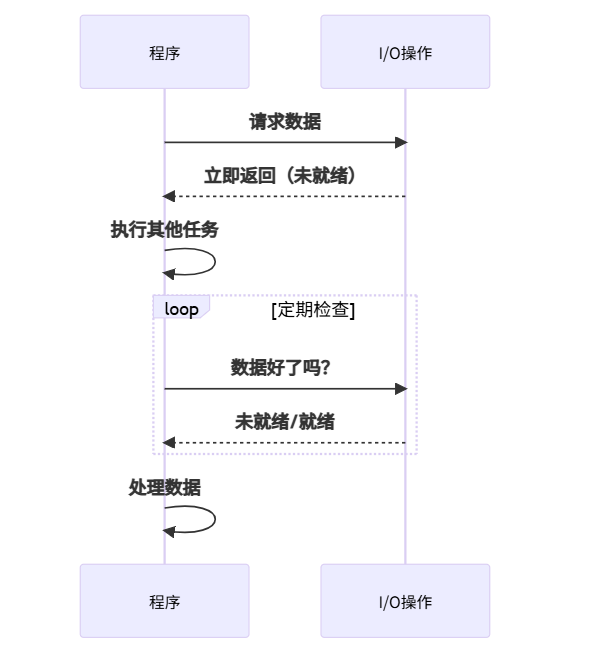
特点:
- 🚦 调用立即返回
- 🔄 需要主动轮询结果
- 💻 CPU可执行其他任务
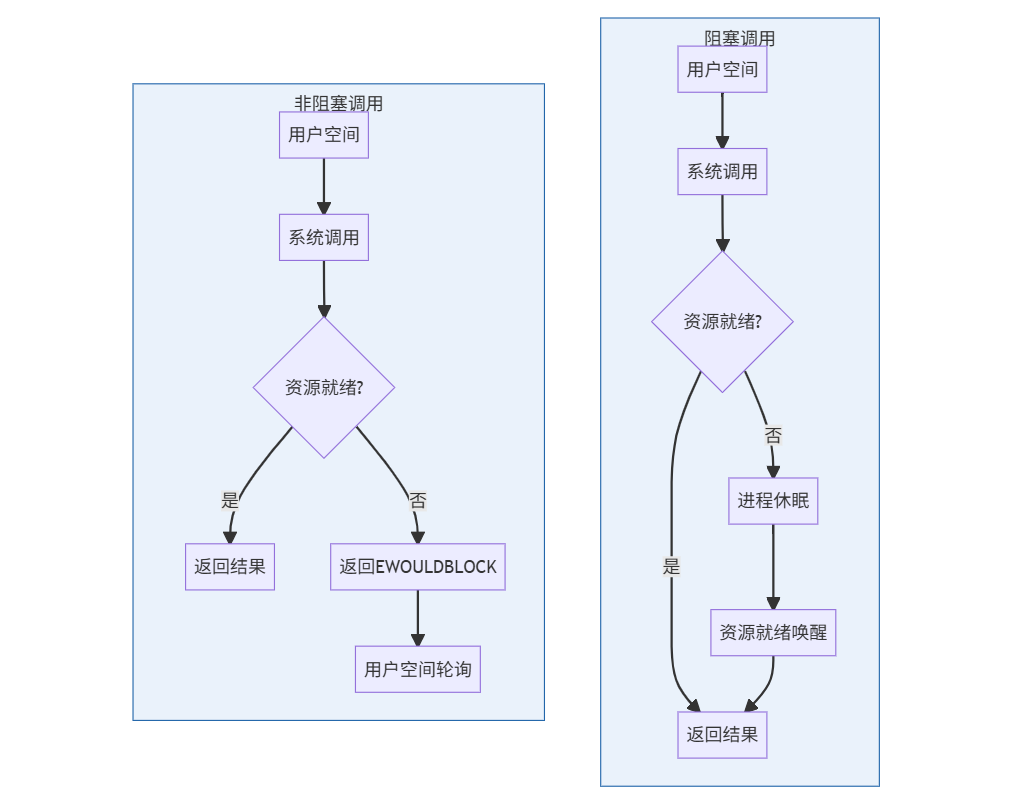
三、技术原理深度解析
操作系统层面的区别
四、代码对比:文件读取示例
阻塞式读取(Python)
print("开始读取文件...")
with open('large_file.txt', 'r') as f: data = f.read() # 程序在此阻塞直到读取完成
print(f"读取完成,大小:{len(data)}字节")
print("程序继续执行") # 输出顺序:
# 开始读取文件...
# (长时间等待...)
# 读取完成,大小:1024000字节
# 程序继续执行
非阻塞式读取(Python使用os模块)
import os
import time print("开始非阻塞读取...")
fd = os.open('large_file.txt', os.O_RDONLY | os.O_NONBLOCK) while True: try: # 尝试读取(非阻塞) data = os.read(fd, 4096) if data: print(f"读取到 {len(data)} 字节数据") else: # 文件结束 break except BlockingIOError: print("数据未就绪,处理其他任务...") # 模拟其他工作 time.sleep(0.1) os.close(fd)
print("程序结束") # 输出可能:
# 开始非阻塞读取...
# 数据未就绪,处理其他任务...
# 数据未就绪,处理其他任务...
# 读取到 4096 字节数据
# 读取到 4096 字节数据
# ...
五、核心区别对比表
| 特性 | 阻塞 🔒 | 非阻塞 🔓 |
|---|---|---|
| 调用返回 | 操作完成后返回 | 立即返回 |
| 程序状态 | 挂起等待 | 继续运行 |
| CPU利用 | 等待期间CPU空闲 | CPU可处理其他任务 |
| 编程复杂度 | 简单直观 | 较复杂(需轮询/回调) |
| 响应性能 | 延迟高 | 响应更及时 |
| 资源消耗 | 线程/进程占用内存 | 单线程可处理多任务 |
| 适用场景 | 简单应用、顺序处理 | 高并发、实时系统 |
| 典型代表 | 标准文件读写 | select/poll/epoll |
六、性能影响:阻塞 vs 非阻塞
服务器并发能力对比
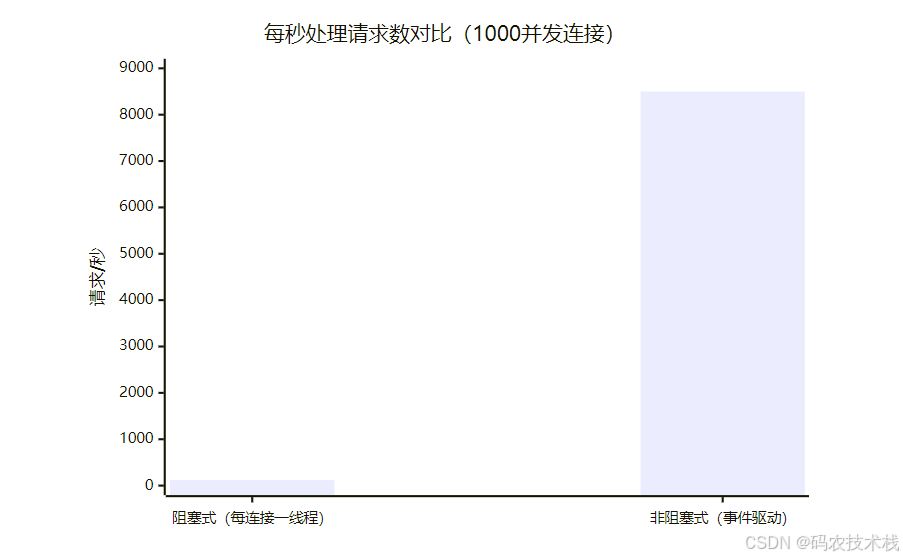
资源消耗对比
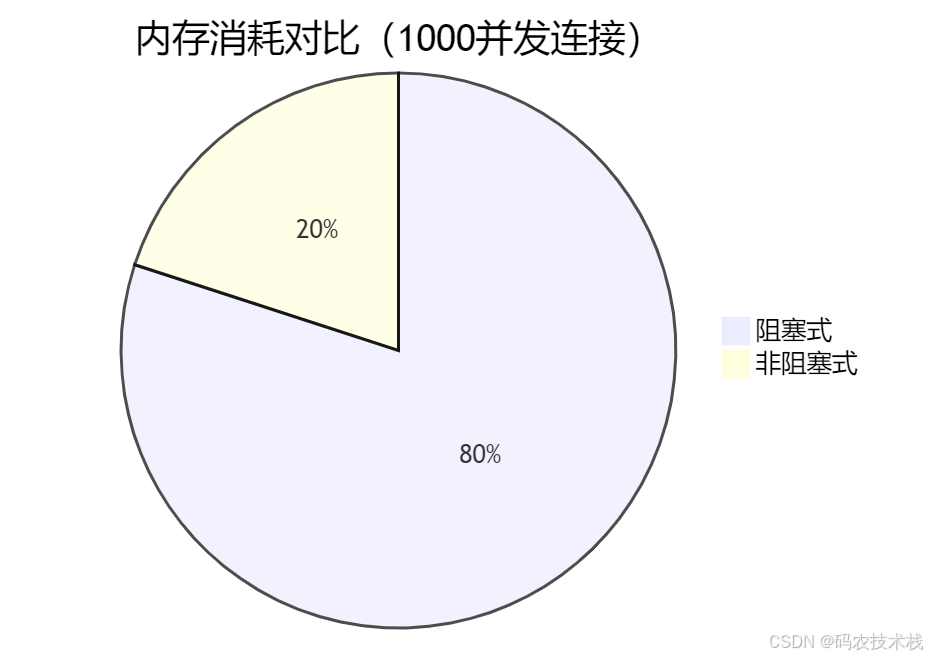
七、实际应用场景分析
何时使用阻塞?

典型案例:
- 数据分析批处理
- 命令行工具
- 单用户桌面应用
何时使用非阻塞?

典型案例:
- Web服务器(Nginx,Node.js)
- 聊天应用
- 股票交易系统
- 游戏服务器
八、现代非阻塞技术栈
主流语言的非阻塞实现
| 语言 | 阻塞API | 非阻塞API | 框架 |
|---|---|---|---|
| Python | open()/read() | asyncio/aiofiles | FastAPI, Sanic |
| Java | InputStream | NIO | Netty, Spring WebFlux |
| C++ | fstream | boost::asio | Beast, Seastar |
| Go | 无 | goroutine+channel | Gin, Fiber |
| Node.js | 无 | fs.readFile+回调 | Express, Koa |
非阻塞设计模式
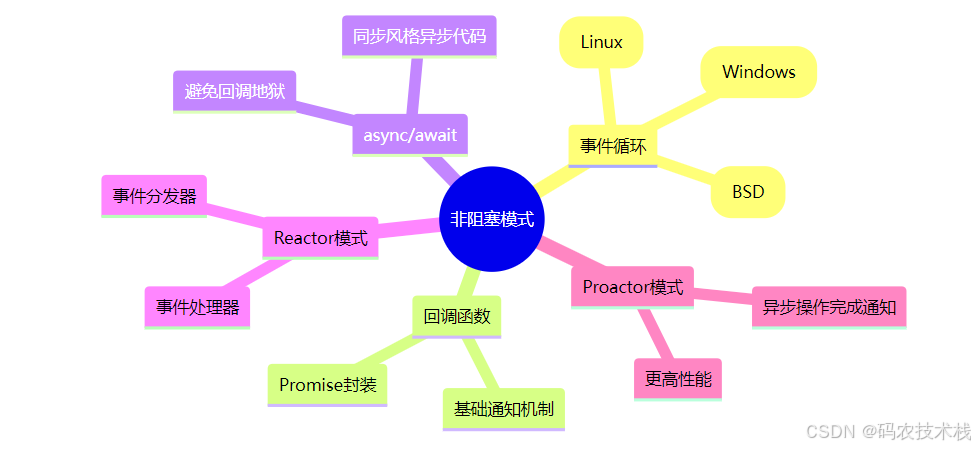
九、阻塞与非阻塞的混合使用
生产者-消费者模式

代码示例(Python queue):
import threading
import queue def producer(q): for i in range(5): q.put(i) # 阻塞如果队列满 print(f"生产: {i}") def consumer(q): while True: item = q.get() # 阻塞如果队列空 print(f"消费: {item}") q.task_done() q = queue.Queue(3)
threading.Thread(target=producer, args=(q,)).start()
threading.Thread(target=consumer, args=(q,)).start()
十、未来趋势:全异步编程
异步/等待(async/await)范式
import asyncio
import aiohttp async def fetch(url): async with aiohttp.ClientSession() as session: async with session.get(url) as response: return await response.text() async def main(): tasks = [ fetch('https://example.com'), fetch('https://example.org') ] results = await asyncio.gather(*tasks) for i, text in enumerate(results): print(f"网站{i+1}大小: {len(text)}字节") asyncio.run(main())
io_uring:Linux终极异步接口

优势:
- ⚡ 零拷贝数据传输
- 🚀 批量操作提交
- 💾 统一文件/网络I/O接口
十一、总结:选择指南
决策流程图
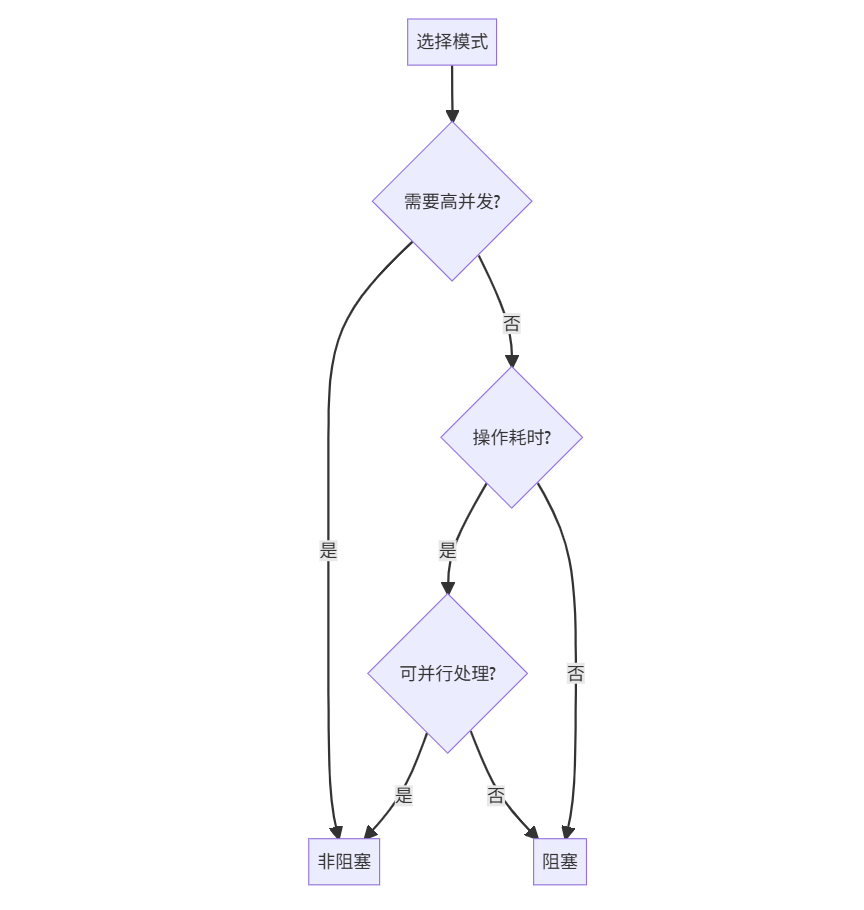
黄金法则
- I/O密集型应用 → 优先非阻塞
- CPU密集型应用 → 阻塞更简单
- 混合型应用 → 线程池+非阻塞I/O
- 新项目开发 → 考虑异步优先架构
💡 核心洞见:
- 阻塞是"不拿到结果不离开"
- 非阻塞是"先拿号,等会再来问"
- 选择取决于应用场景而非技术优劣
- 现代高并发系统主要依赖非阻塞模型
思考题:为什么数据库连接池要使用阻塞模式?评论区分享你的见解!
🚀 动手实验:体验两种模式的差异
# 阻塞式下载 import requests response = requests.get('https://example.com') # 非阻塞式下载(使用aiohttp) import aiohttp import asyncio async def async_download(): async with aiohttp.ClientSession() as session: async with session.get('https://example.com') as resp: return await resp.text() asyncio.run(async_download())
理解阻塞与非阻塞,你就掌握了高效编程的钥匙!现在就开始在你的项目中应用这些知识吧!
)
-部署和使用指南)

















