目录
1. 命名空间
1.1 命名空间的创建和使用
2. 输入输出
2.1 输出
2.2 输入
3. 缺省参数
3.1 全缺省
3.2 半缺省
4.函数重载
4.1 为什么C++支持重载而C语言不支持?
4.1.2 编译的四个过程
4.2 extern是什么
5.引用
5.1 引用的特性
5.1.1 引用的“隐式类型转换”
5.2 引用的使用场景
本栏目针对于C语言已经学习完毕的读者,只会讲C++特有的特性。
1. 命名空间
命名空间是C++为了防止全局变量、函数、类,因为作用域的不同导致的冲突,从而提出的解决方案,在一个命名空间内,变量、函数、类是相对独立的,不会对其他命名空间造成影响。
1.1 命名空间的创建和使用
命名空间内部可以创建变量和函数以及类;
命名空间可以嵌套使用;
相同的命名空间后面会被编译器合并;
#include<iostream>// 命名空间可以定义变量和函数
namespace N1
{int a = 0;void swap(){;}}// 命名空间的嵌套
namespace N2
{namespace N3 {// ....}
}// 相同命名空间,编译器会进行合并
namespace N2
{int b = 1;
}如果要使用命名空间内的变量或者函数或者类,那么一共有三种方式进行调用。
①直接使用命名空间::变量来调用;
②将某一个变量直接进行展开,后续使用变量的时候就不需要再加上命名空间了;
③将一个命名空间完全展开,命名空间内的所有内容,直接可以使用。
// 命名空间可以定义变量和函数
namespace N1
{int a = 0;void swap(){;}}// 命名空间的嵌套
namespace N2
{namespace N3{// ....int c = 1;}
}// 相同命名空间,编译器会进行合并
namespace N2
{int b = 1;
}int main()
{// 方式1printf("%d ", N1::a);// 方式2using N2::b; // 如果经常使用a,那么就直接展开aprintf("%d ", b);// 方式3// 全部展开N2内的所有内容using namespace N1;printf("%d ",a);swap();return 0;
}想要使用C++,就必须使用std库,我们可以直接使用:将标准库全部展开,到那时还是有一个缺陷,就是后续项目中如果定义一个和std库内容相同的函数或者变量,那么就会出现重复命名的问题。
using namespace std;2. 输入输出
2.1 输出
利用上面的命名空间的知识,我们可以顺便介绍一下c++的输入输出。首先需要包含c++的输入输出库,后续才能使用相关的函数。
#include<iostream>输出流:cout,这是在标准库中的一个函数,也可以叫做标准输出流,利用上面所学的知识,我们可以有三种方式来完成hello world的输出。
方式一:
在平时练习中,我们可以直接将标准库展开,然后直接使用cout,将想要输出的内容直接输出到输出流中,这里的endl,是换行的意思,我们可以使用c语言的\n来替代这个功能。
#include<iostream>
// 直接将std全部展开
using namespace std;
int main()
{cout << " hello world " << endl;cout << " hello world \n ";
}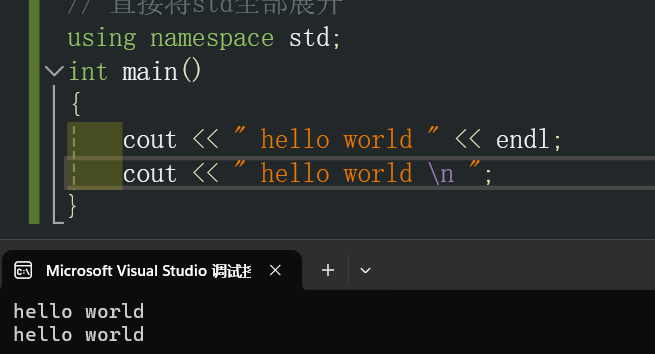
这样做就会产生一个缺陷,如果你定义的变量中含有和std库中相同的变量名称,这样就会命名混淆从而导致报错。
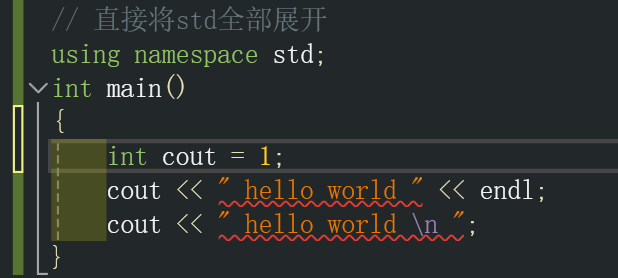
方式二:
在平时的项目中,为了避免命名冲突,我们直接使用std::cout的方式进行输出,虽然一定程度避免了命名冲突,但是书写起来比较麻烦。
#include<iostream>
int main()
{std::cout << " hello world " << std::endl;std::cout << " hello world \n ";
}方式三:
居中的办法就是,只展开后续会用到的函数:
using std::cout;
using std::endl;
#include<iostream>
int main()
{cout << " hello world " << endl;cout << " hello world \n ";
}注意:细心的读者可能发现了,c++的输出和c语言的输出不太一样,c++是直接根据输出内容的类型直接判断输出的类型,而不是像c语言一样,需要提前指定类型,再根据指定的类型输出,这就是后面面向对象需要学习的函数的重载。
2.2 输入
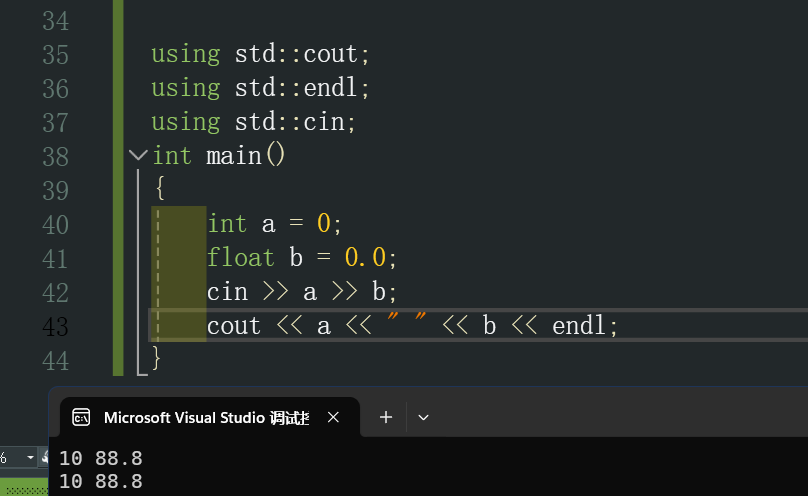
这里用到了std库的cin函数,这里和cout一样,都是可以流式输入,注意>>箭头的方向
using std::cout;
using std::endl;
using std::cin;
#include<iostream>
int main()
{int a = 0;float b = 0.0;cin >> a >> b;cout << a << " " << b << endl;
}
3. 缺省参数
正常情况下,在函数有形参的时候需要这样调用:
#include<iostream>
using namespace std;void Func(int a)
{// cout << a << endl;
}int main()
{Func(10);
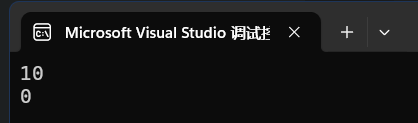
}在c++中需要注意的是,在函数形参中提供默认参数,当没有传入实参的时候,就会使用默认参数。
#include<iostream>
using namespace std;void Func(int a = 0)
{// cout << a << endl;
}int main()
{Func(10);Func();
}
3.1 全缺省
顾名思义,全部形参都可以不写,叫全缺省,也可以按照顺序缺省后2个或者3个形参。
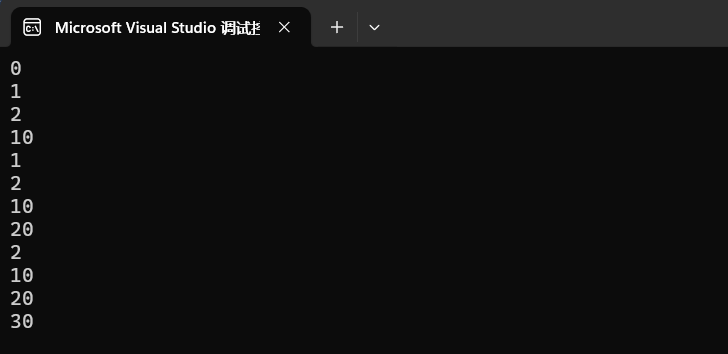
// 全缺省
void Func1(int a = 0, int b = 1, int c = 2)
{// cout << a << endl;cout << b << endl;cout << c << endl;
}int main()
{Func1();// 全缺省Func1(10); // 缺省b,c形参Func1(10,20);// 缺省c形参Func1(10,20,30);// 不缺省
}
3.2 半缺省
形参中部分参数没有指定缺省值,例如下面代码,a没有指定缺省值,那么传入实参的时候必须至少有一个参数是传给a的,如果后面有其他参数,则继续传给b,c;
// 半缺省
void Func1(int a, int b = 1, int c = 2)
{// cout << a << endl;cout << b << endl;cout << c << endl;
}int main()
{Func1(10); // 缺省b,c形参,必须得传入一个Func1(10,20);// 缺省c形参Func1(10,20,30);// 不缺省
}这种半缺省必须是从右往左进行缺省:
间隔缺省是错误的。
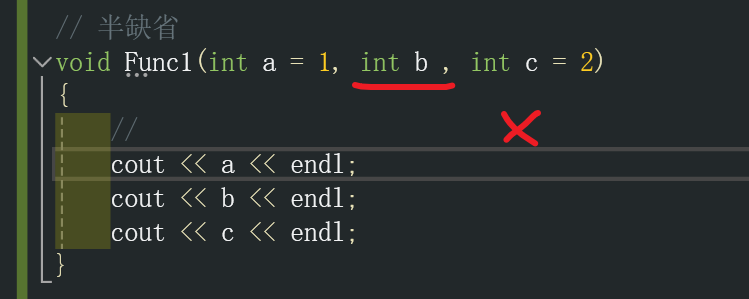
从左往右缺省是错误的。

传参是从左往右依次传参。
4.函数重载
c++允许在同一作用域中声明几个功能类似的同名函数,这些同名函数的形参列表(参数个数或类型或顺序)必须不同,常用来处理功能类似,数据类型不同的问题。
int func()
{
}// 参数个数不同
int func(int a)
{
}// 参数类型不同
int func(long a)
{
}// 参数顺序不同
int func(long a ,int b)
{
}
int func(int b, long a)
{
}对返回值完全没有要求。

如何调用重载函数:

4.1 为什么C++支持重载而C语言不支持?
下面使用linux的环境来进行解释
list.h
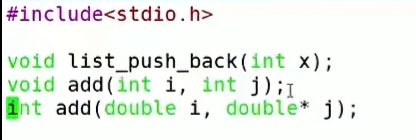
list.c

test.c

使用gcc命令编译:
gcc -o listc list.c test.c发现报错

究其原因就是C语言的编译器是不支持重载的:
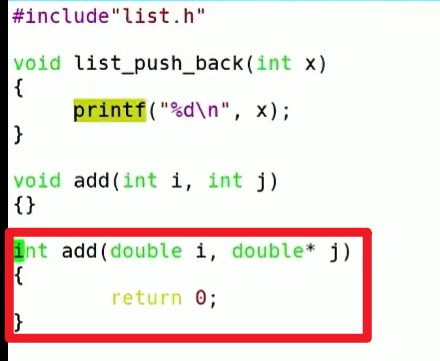
我们使用g++命令进行编译,发现通过编译了;
g++ -o listcpp list.c test.c
这就涉及到编译器编译的四个过程:
4.1.2 编译的四个过程
①预处理:宏替换,去掉注释,展开头文件,条件编译;
②编译:检查语法问题,将源代码转换成汇编代码;
③汇编:将汇编代码转换成二进制机器码;
④链接:将两个目标文件链接在一起,生成可执行文件。
例如在test中执行一个Func1函数,转换成汇编指令就是:
call Func1 (0EE11DBH),括号内的是这个函数的地址,也可以说这个函数第一个变量的地址。

回到上面的函数,同理我们只观察汇编阶段的汇编码;在test.o文件中我们需要调用list_push_back这个函数,那么其实就是call list_push_back(函数地址),但是问题来了,此时在test函数中仅仅只包含了头文件,也就是说仅仅对这个函数进行了声明,那么这个函数实际的地址,这里是不知道的;每一个object文件中都在维护一个符号表,记录每一个函数以及对应的地址,test.o这个文件的符号表仅仅只有main函数的地址。
反之在list.o文件中,我们可以看到这里是完成了两个函数的实现,所以符号表里就存放着两条数据,分别是这两个函数的地址。
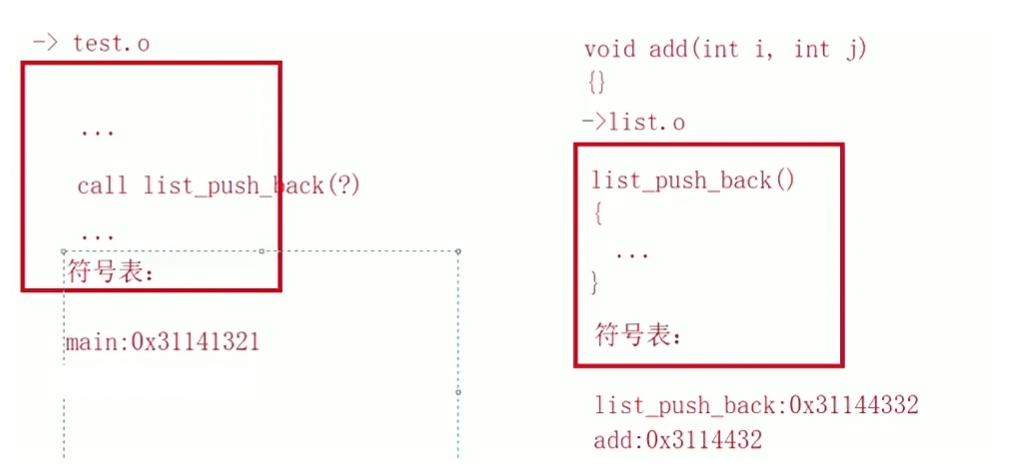
上面括号内的问号表示,在编译的时候,这个函数只有声明没有定义。在链接的时候会其他目标文件的符号表中找到该函数的地址。
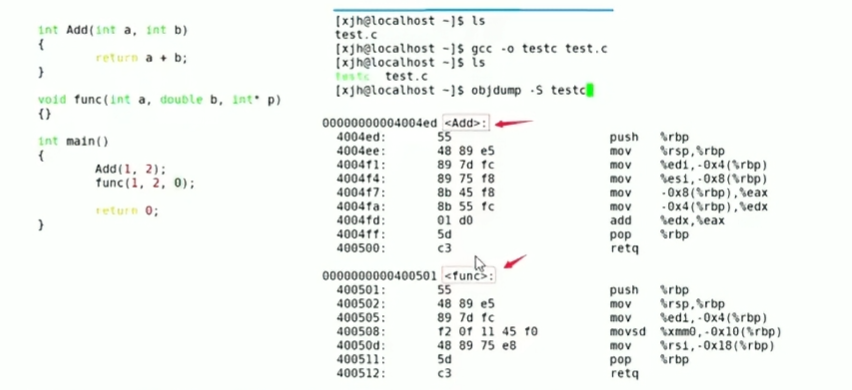
言归正传,在C语言中,函数名是必须是独一无二的,函数的名字没有修饰,也就是说,当去list.o的符号表去找地址的时候,突然发现ADD的地址有两个,那么此时就不知道到底是哪一个的地址。
在C++中函数名是有修饰的,函数名由下面几部分组成:
①前缀:_Z
②函数字符个数:例如add就是3
③函数名称
④形参类型的首字母:add形参首字母就是ii、func形参首字母是idpi,p代表指针,pi代表int类型的指针。
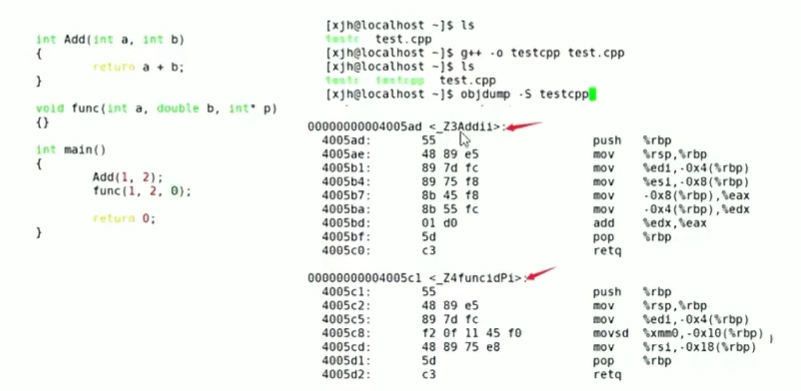
回到上面的代码,我们直接将生成的汇编代码进行展示:下图是cpp的汇编代码,虽然函数名都是add,但是仍然可以根据命名修饰进行区分,从而找到相对应的函数地址。

那么c语言就不同了,我们可以发现下图是c语言的汇编代码,我们可以发现add完全没有任何函数名修饰,这就意味着,如果有两个相同的函数名,当在链接的时候,编译器无法区分这两个函数的地址,因为函数名都相同,那么在符号表中就无法进行区分。

4.2 extern是什么
extern C就是按照C语言进行编译,假如有一个C++编写的程序编译成了库文件供别人调用,其他C++程序是可以完全调用的,但是如果C语言程序就无法调用,这是因为我们编译的规则是不同的,如果这个程序是C++写的,那么要求C语言能够正确编译,需要在函数声明加上extern "C",如下图绿框所示:
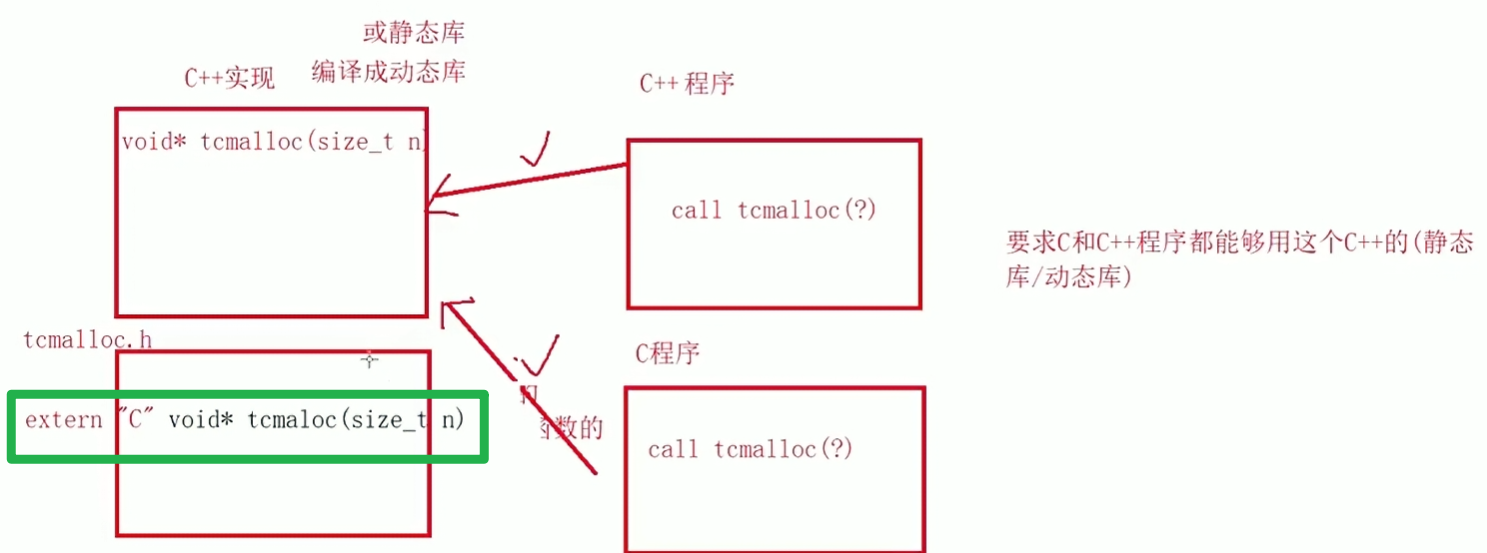
这里的具体意义是,按照C的形式去符号表内找这个函数的地址。
5.引用
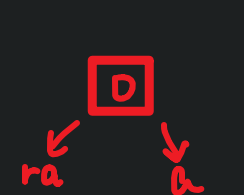
引用就是给变量取了一个别名,不会额外开辟内存空间。
#include<iostream>
using namespace std;
int main()
{int a = 0;int& ra = a; // ra是a的引用,给a起了一个别名
}
5.1 引用的特性
①一个变量可以有多个引用,但是只会占用一个空间;
②引用声明的时候必须初始化;
③第一次给引用初始化的时候,就永远是这个变量的引用,后续无法改变。
#include<iostream>
int main()
{int a = 1;int& ra = a;int b = 2;ra = b; // 此时ra仍然是a的引用,a的值被改成了2}此时ra的类型是int,而不是int&,因为ra只是a的别名,类型和a一样。
如果代码改成下面这样的,就会出现问题:
#include<iostream>
int main()
{const int a = 1;int& ra = a; // 此时报错}const int a只是可读的,int& ra是可读可写的,如果将前者直接转换成后者,就会报错。
那么反过来就对了,a可读可写,ra只可读,类似于一个大海能填满溪流,但是溪流不能填满大海。
#include<iostream>
int main()
{int a = 1;const int& ra = a; // 此时ok}5.1.1 引用的“隐式类型转换”
首先看下面的代码,将a赋值给double类型的引用,是不可以的,在前面加了一个const修饰就可以了,这是为什么呢?
#include<iostream>
int main()
{int a = 1;double& b= a; // 此时不行const double& c= a; // 此时ok}当变量赋值的时候会产生一个临时变量,这个变量具有常性(只能读不能改),那么事实上a赋值给这个临时变量,临时变量再赋值给double类型的引用,此时只读赋值给可读可写,一定会有问题。
反之在double& 前加一个const修饰,这里的引用就会变成可读的,那么可读赋值给可读就是合理的。
5.2 引用的使用场景
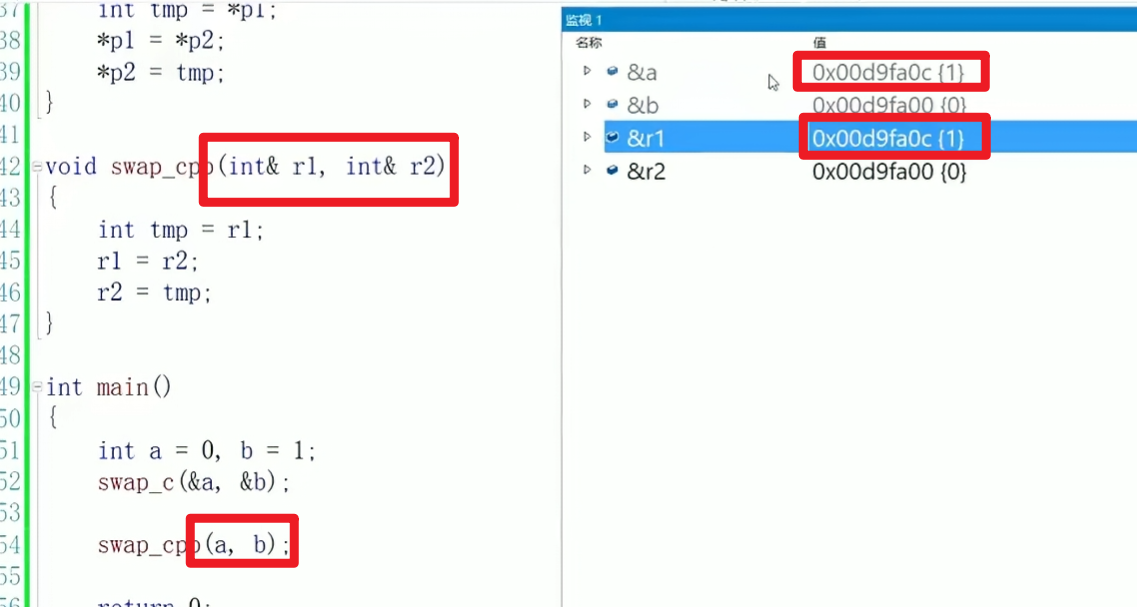
我们写一个比较常见的交换函数,分别使用c语言和c++的特性,注意形参和实参的变化。
int& a其实就是取实参的引用,此时引用和实参指向一个地址,因此可以直接交换。
#include<iostream>
using namespace std;void c_swap(int* a, int* b)
{int tmp = *a;*a = *b;*b = tmp;
}
void cpp_swap(int& r1, int& r2)
{int tmp = a;a = b;b = tmp;
}int main()
{int a = 10;int b = 20;c_swap(&a, &b);cpp_swap(a, b);
}
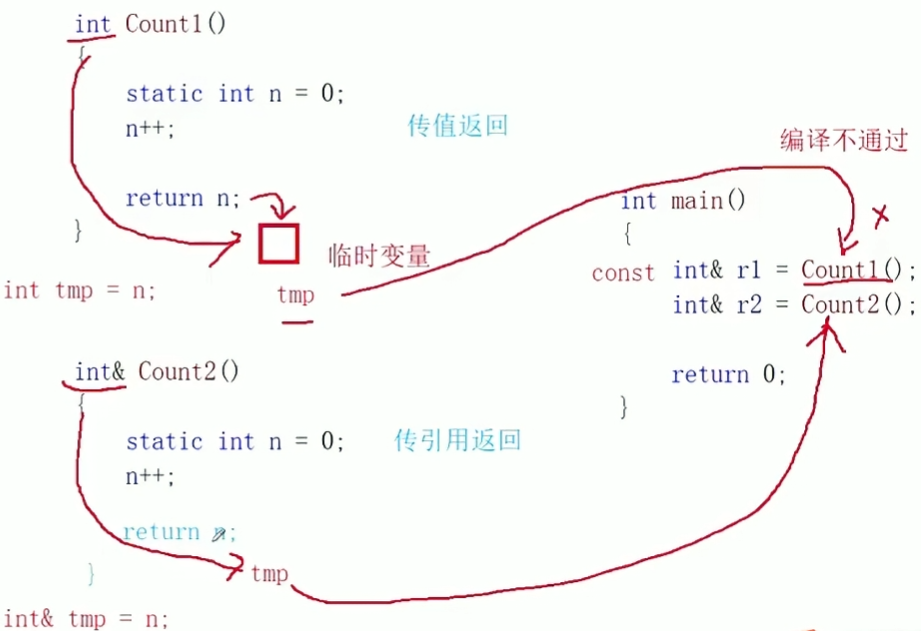
再举一个例子,count1返回的是一个临时变量,是只读的,所以给r1的时候会报错,此时r1需要加上const类型才能对应,(只读-只读),count2直接返回引用,所以类型能够匹配,所以这是没问题的。




)












语法 glue函数)

