1 MemGPT: Towards LLMs as Operating Systems
论文地址:MemGPT: Towards LLMs as Operating Systems
代码地址:https://github.com/letta-ai/letta
1.1 MemGPT
MemGPT(MemoryGPT)借鉴传统操作系统的分层内存管理思想(物理内存与磁盘间的分页机制),通过 “虚拟上下文管理” 技术,让固定上下文窗口的 LLM 具备 “无限上下文” 的使用错觉。其核心逻辑是:将 LLM 的上下文窗口视为 “物理内存”,外部存储视为 “磁盘”,通过函数调用实现信息在两者间的 “分页调入 / 调出”,同时管理控制流以优化上下文利用效率。
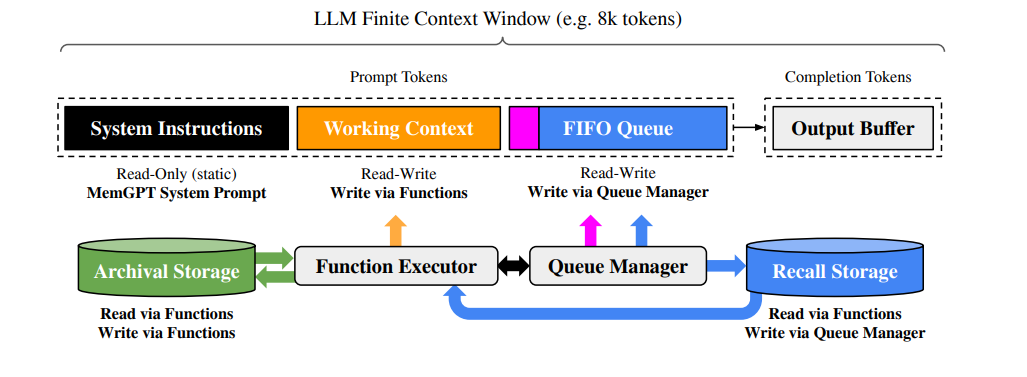
MemGPT 通过多层级内存设计与功能模块协作,实现上下文的智能管理,包括:
- 主上下文(Main Context):类比RAM。LLM 的Prompt Tokens,可被 LLM 推理直接访问,分为三部分:
- 系统指令:只读静态内容,包含 MemGPT 控制流、内存层级用途、函数调用规则;
- 工作上下文:固定大小可读写区块,存储用户关键信息(如偏好、事实)、智能体角色信息;
- FIFO 队列:滚动存储消息历史(用户 - 智能体对话、系统提示、函数调用记录),头部含已淘汰消息的递归摘要。
- 外部上下文(External Context):类比磁盘。超出主上下文窗口的信息,需通过函数调用调入主上下文才能使用,包含两类存储:
- 召回存储(Recall Storage):消息数据库,由队列管理器自动写入对话历史,支持分页搜索与重新调入主上下文;
- 归档存储(Archival Storage):支持向量搜索的数据库(如 PostgreSQL+pgvector),存储长文档、键值对等大规模数据,需显式函数调用访问。
核心功能模块
- 队列管理器(Queue Manager):
- 消息处理:接收新消息并追加到 FIFO 队列,拼接提示词令牌触发 LLM 推理,同时将消息与推理结果写入召回存储;
- 上下文溢出控制:当主上下文令牌数达到 “警告阈值”(如窗口的 70%),插入 “内存压力” 系统提示,引导 LLM 将关键信息存入工作上下文 / 归档存储;达到 “刷新阈值”(如 100%)时,淘汰部分消息(如 50% 窗口),生成新递归摘要并写入 FIFO 头部,淘汰消息永久保留在召回存储。
- 函数执行器(Function Executor):
- 解析 LLM 生成的输出,执行内存管理函数(如搜索外部存储、修改工作上下文、分页调入数据),并将执行结果(含错误信息)反馈给 LLM,形成 “决策 - 执行 - 反馈” 闭环。同时支持分页机制,避免单次检索结果溢出主上下文。
- 控制流与函数链(Control Flow & Function Chaining):
- 事件触发推理:用户消息、系统警告、定时任务等事件均会触发 LLM 推理,事件经解析后转为文本追加到主上下文;
- 多函数顺序执行:通过 “request heartbeat=true” 标志,支持 LLM 在返回用户响应前,连续调用多个函数(如多页文档检索、多跳键值对查询),提升复杂任务处理能力。
1.2 源码分析
1.2.1 内存层次结构 — 主内存 / 归档 / 检索层
Memory hierarchy(论文里的主内存 / 外部存储分层)是通过 Memory Blocks + Archival Memory 来实现的:
- 核心上下文(主内存)由 memory blocks 组成,每个 block 都是可编辑、可共享的小单元,在
client.blocks.create()与 agent 的block_ids字段绑定后,会被拼接进 agent 的in-context prompt中。
agent_state = client.agents.create(memory_blocks=[{"label": "human","value": "The human's name is Bob the Builder.","limit": 5000},{"label": "persona","value": "My name is Sam, the all-knowing sentient AI.","limit": 5000}],model="openai/gpt-4o-mini",embedding="openai/text-embedding-3-small"
)
- 外部上下文:超出 context 的长期存储(外部存储层)则通过
filesystem / folders / passages模块实现,文件内容会被分段、索引、存档,必要时由agent通过工具调用再取回到主内存。这样 Letta 就把 “有限的 prompt context” 和 “无限的外部持久存储” 分层管理。
# create the folder
folder = client.folders.create(name="my_folder",embedding_config=embedding_config
)# upload a file into the folder
job = client.folders.files.upload(folder_id=folder.id,file=open("my_file.txt", "rb")
)
MemoryBlock
MemGPT中定义了一些系列的Memory,都是基于MemoryBlock来实现的。而外部Memory直接通过FileProcess来实现。
class BasicBlockMemory(Memory):"""BasicBlockMemory is a basic implemention of the Memory class, which takes in a list of blocks and links them to the memory object. These are editable by the agent via the core memory functions.Attributes:memory (Dict[str, Block]): Mapping from memory block section to memory block.Methods:core_memory_append: Append to the contents of core memory.core_memory_replace: Replace the contents of core memory."""def __init__(self, blocks: List[Block] = []):"""Initialize the BasicBlockMemory object with a list of pre-defined blocks.Args:blocks (List[Block]): List of blocks to be linked to the memory object."""super().__init__(blocks=blocks)
调度
agent 的核心调度器,其中 内存调度(memory hierarchy 的 orchestrator) 主要体现在 “重建上下文窗口” 的逻辑,也就是把 Memory Blocks(主内存)、消息历史 和 归档/摘要 拼接起来,送进 LLM。
# letta/agents/letta_agent.pyclass LettaAgent:...async def step(...):# 每次 agent 前进一轮,都会检查/更新上下文...await self.rebuild_context_window()...async def rebuild_context_window(self):"""这里是核心的内存调度逻辑:1. 从数据库/存储里取出 agent 的 memory blocks(主内存块)2. 加载最近的对话消息(短期记忆)3. 检查上下文 token 使用量- 如果超过阈值,调用 summarizer 做摘要/驱逐4. 把这些拼接成 prompt,交给模型调用"""blocks = await self.get_attached_blocks()messages = await self.load_recent_messages()# 判断 token 是否超限if self.exceeds_context_limit(blocks, messages):summarized = await self.summarizer.summarize(messages)messages = summarized# 构造最终的上下文self.context = self.compose_context(blocks, messages)摘要
当上下文压力过大时,会通过LLM对内存进行摘要或驱逐,具体摘要的PE如下:
WORD_LIMIT = 100
SYSTEM = f"""Your job is to summarize a history of previous messages in a conversation between an AI persona and a human.
The conversation you are given is a from a fixed context window and may not be complete.
Messages sent by the AI are marked with the 'assistant' role.
The AI 'assistant' can also make calls to tools, whose outputs can be seen in messages with the 'tool' role.
Things the AI says in the message content are considered inner monologue and are not seen by the user.
The only AI messages seen by the user are from when the AI uses 'send_message'.
Messages the user sends are in the 'user' role.
The 'user' role is also used for important system events, such as login events and heartbeat events (heartbeats run the AI's program without user action, allowing the AI to act without prompting from the user sending them a message).
Summarize what happened in the conversation from the perspective of the AI (use the first person from the perspective of the AI).
Keep your summary less than {WORD_LIMIT} words, do NOT exceed this word limit.
Only output the summary, do NOT include anything else in your output."""
共享内存
共享内存的实现比较简单就是将内存块的id添加到agent的block_ids中即可。
# create a shared memory block
shared_block = client.blocks.create(label="organization",description="Shared information between all agents within the organization.",value="Nothing here yet, we should update this over time."
)# create a supervisor agent
supervisor_agent = client.agents.create(model="anthropic/claude-3-5-sonnet-20241022",embedding="openai/text-embedding-3-small",# blocks created for this agentmemory_blocks=[{"label": "persona", "value": "I am a supervisor"}],# pre-existing shared block that is "attached" to this agentblock_ids=[shared_block.id],
)# create a worker agent
worker_agent = client.agents.create(model="openai/gpt-4.1-mini",embedding="openai/text-embedding-3-small",# blocks created for this agentmemory_blocks=[{"label": "persona", "value": "I am a worker"}],# pre-existing shared block that is "attached" to this agentblock_ids=[shared_block.id],
)
1.2.2 队列管理器
MemGPT的队列管理器(queue manager) 对应的就是 对话消息队列 / buffer 的管理逻辑——也就是让 agent 的上下文只保留一部分最近的消息,把溢出的内容清理、归档或摘要。这个机制跟 MemGPT 论文里的 FIFO 队列 + 内存压力控制 是一一对应的。
- 消息存储。所有对话消息存到数据库里(Postgres/SQLite,表结构在 messages 表),而 agent 每次运行时不会直接加载全部,而是取最近一段窗口。
- 上下文重建时检查队列。从数据库里取最新的 N 条消息(相当于队尾元素)。如果 token 超限,调用 summarizer 对旧消息做摘要,然后替换队首部分(保持队列容量不爆炸)。
async def _rebuild_context_window(self, summarizer: Summarizer, in_context_messages: List[Message], letta_message_db_queue: List[Message]
) -> None:new_letta_messages = await self.message_manager.create_many_messages_async(letta_message_db_queue, actor=self.actor)# TODO: Make this more general and configurable, less brittlenew_in_context_messages, updated = await summarizer.summarize(in_context_messages=in_context_messages, new_letta_messages=new_letta_messages)await self.agent_manager.update_message_ids_async(agent_id=self.agent_id, message_ids=[m.id for m in new_in_context_messages], actor=self.actor)
- 驱逐/摘要策略。当消息数量或 token 数超过阈值时,触发 partial evict buffer summarization,把旧消息合并成一条 “总结消息”,再继续放回队首。
async def _partial_evict_buffer_summarization(self,in_context_messages: List[Message],new_letta_messages: List[Message],force: bool = False,clear: bool = False,) -> Tuple[List[Message], bool]:"""Summarization as implemented in the original MemGPT loop, but using message count instead of token count.Evict a partial amount of messages, and replace message[1] with a recursive summary.Note that this can't be made sync, because we're waiting on the summary to inject it into the context window,unlike the version that writes it to a block.Unless force is True, don't summarize.Ignore clear, we don't use it."""all_in_context_messages = in_context_messages + new_letta_messagesif not force:logger.debug("Not forcing summarization, returning in-context messages as is.")return all_in_context_messages, False# First step: determine how many messages to retaintotal_message_count = len(all_in_context_messages)assert self.partial_evict_summarizer_percentage >= 0.0 and self.partial_evict_summarizer_percentage <= 1.0target_message_start = round((1.0 - self.partial_evict_summarizer_percentage) * total_message_count)logger.info(f"Target message count: {total_message_count}->{(total_message_count - target_message_start)}")# The summary message we'll insert is role 'user' (vs 'assistant', 'tool', or 'system')# We are going to put it at index 1 (index 0 is the system message)# That means that index 2 needs to be role 'assistant', so walk up the list starting at# the target_message_count and find the first assistant messagefor i in range(target_message_start, total_message_count):if all_in_context_messages[i].role == MessageRole.assistant:assistant_message_index = ibreakelse:raise ValueError(f"No assistant message found from indices {target_message_start} to {total_message_count}")# The sequence to summarize is index 1 -> assistant_message_indexmessages_to_summarize = all_in_context_messages[1:assistant_message_index]logger.info(f"Eviction indices: {1}->{assistant_message_index}(/{total_message_count})")# Dynamically get the LLMConfig from the summarizer agent# Pretty cringe code here that we need the agent for this but we don't use itagent_state = await self.agent_manager.get_agent_by_id_async(agent_id=self.agent_id, actor=self.actor)# TODO if we do this via the "agent", then we can more easily allow toggling on the memory block versionsummary_message_str = await simple_summary(messages=messages_to_summarize,llm_config=agent_state.llm_config,actor=self.actor,include_ack=True,)
1.2.3 函数执行器
MemGPT的函数执行器是每个Agent的基础能力,在处理LLM的响应时进行函数调用。函数的具体执行是抛到了不同的Exector里面。
@trace_methodasync def _handle_ai_response()#省略一些检查和参数1. Execute the tool (or synthesize an error result if disallowed)tool_rule_violated = tool_call_name not in valid_tool_names and not is_approvalif tool_rule_violated:tool_execution_result = _build_rule_violation_result(tool_call_name, valid_tool_names, tool_rules_solver)else:# Track tool execution timetool_start_time = get_utc_timestamp_ns()tool_execution_result = await self._execute_tool(tool_name=tool_call_name,tool_args=tool_args,agent_state=agent_state,agent_step_span=agent_step_span,step_id=step_id,)
1.2.4 控制流与函数链
MemGPT的控制流与函数链是支撑Agent具备“可编程对话逻辑”的关键。核心由 step() 驱动,每次调用 agent.step() 就是一次事件循环。基本流程为:LLM输出 → 调度器解析 → 执行器执行 → 队列更新 → 下一轮继续。伪代码为:
# letta/agents/letta_agent.pyasync def step(self, user_input=None):# 1. 构建上下文await self.rebuild_context_window()1. 调用模型model_output = await self.model.generate(self.context, user_input)# 3. 根据输出类型决定控制流if model_output.function_call:response = await self.execute_function_call(model_output.function_call)else:response = model_output.text# 4. 更新队列(短期记忆)await self.message_queue.enqueue(response)return response1.3 要点总结
- 内存层次(Memory Hierarchy):Main Context Memory,External Memory和Archive / Summarized Memory;
- 内存调度:高频访问内容留在上下文,低频内容丢到外部存储;
- 队列管理:管理 输入消息流 与 函数调用结果,确保 LLM 每次看到的上下文是“最有用”的子集。






生成 PPT 的完整流程)
:适合存储对象的数据结构,优势与坑点解析)



相关)






)
