这篇论文主要讲了两方面
1.为了解决模型在正常标注的现实图像上训练的缺陷问题、提出了新的模型训练数据和训练方法
- 真实标记图像存在缺点:标签噪声(深度传感器可能存在空洞、玻璃等物体反射导致精度不准确)、标签细节粗糙(深度图边缘不明确,导致预测可能会过渡平滑)、人工标注费时费力成本高
- 合成数据的优点:细节标记清晰、深度为真实值、且获取方便快捷
- 合成数据的缺陷:与真实图像之间存在分布差异,合成图像场景覆盖范围有限,场景是单一的,是通过预定义形成的固定场景类型,毕竟最终要部署识别的是真实图像,所以仅用合成数据不能在真实图像上得到很好的效果。
针对以上优缺点,作者提出了一种结合了合成图像和真实图像的训练方法,使得模型既能获得清晰的细节和真实的深度,又能省去人工标注并完美覆盖真实场景。其训练流程如下图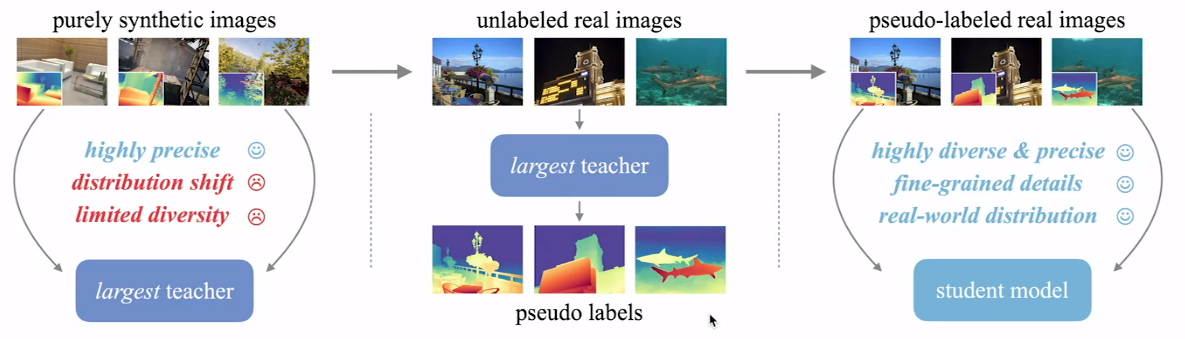
- 先完全使用生成图像在最大的模型上进行训练得到最大的教师模型,这个模型是高度精确的、但和真实世界图像数据分布不一致、且图像多样性有限。
- 然后使用该模型识别未经标记的真实图像,得到伪标记的真实图像。
- 这些伪标记图像作为数据集参与最终学生模型的训练,得到最终高度多样和精确、很好的粒度细节、真实的世界分布。
- 这样训练的学生模型能更好地处理真实世界的图像数据,完成深度估计等视觉任务。
2.针对现有评估基准、提出了新的评判标准
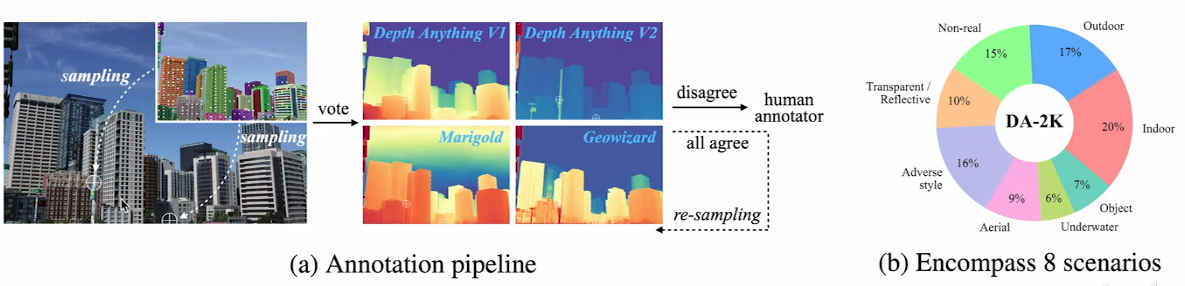
- 现有评估基准使用的图像数据是存在大量噪声的,如下图左所示镜子内部深度在评估时使用的标注数据错误而模型识别出的深度正确,右图显示有部分细节处存在噪声和空洞,而模型则能很好识别这些细节。

- 新的评估标准中在目标图像中取大量样本点,在这些样本点中取两两为一对,使用四个模型对这些点的相对远近进行投票,如果四个模型所认为的远近都一致则通过,否则交由人工判断。
- 新的评估标准中的图像多样性也非常丰富,如右图所示。



![[C/C++学习] 7.“旋转蛇“视觉图形生成](http://pic.xiahunao.cn/[C/C++学习] 7.“旋转蛇“视觉图形生成)












目录)


